基于子空間的可解釋性多變量異常檢測
2022-12-01 01:06:10宋潤葵鄭揚飛郭紅鈺
計算機測量與控制 2022年11期
宋潤葵,鄭揚飛,郭紅鈺,李 倩
(華北計算技術研究所 系統八部,北京 100083)
0 引言
異常檢測是數據挖掘任務中的一種子類型,不同于其他的數據挖掘任務,比如聚類、分類等任務,異常檢測針對的是少數的、罕見的、不確定的事件、對象。其應用領域十分廣泛,比如計算機網絡入侵檢測[1],銀行欺詐[2],醫療異常檢測[3],工業異常檢測[4]等。由此可見針對異常檢測算法的研究具有重要意義。在異常檢測任務中,異常的種類通常有3種:點異常,條件異常,群體異常。按照數據類型劃分有:統計性數據,如文本,網絡流;序列型數據,如傳感器數據;空間型數據,如圖像,視頻。本文主要針對的就是統計型數據上的點異常。
由于異常檢測任務的特點,目前主要的研究都是針對于無監督異常檢測的。目前國內外對異常檢測的方法研究可以分成各種類型:比如有基于線性模型的,如主成分分析(PCA)[5],最小協方差行列式(MCD)[6],基于偏離的異常檢測(LMDD)[7];比如有基于衡量相似度的,如k最近鄰居(kNN)[8]、AvgKNN[8]、MedKNN[8],基于旋轉的異常點檢測(ROD)[9];比如有衡量連接性的,如基于連接的異常點因子(COF)[10];比如有衡量密度的,如局部異常因子(LOF)[11];比如有概率方法,如基于角度的ABOD[12]; 比如基于神經網絡的,如單目標對抗生成主動學習方法(SO_GALL)[13],多目標對抗生成主動學習方法(MO_GALL)[13],DeepSVDD[14]。這些方法都是在固定的全局特征空間上進行異常點挖掘的,此外這些方法都忽略掉了一個與異常點檢測同等重要的問題,就是異常點解釋。在許多應用場景中,用戶更關心為什么檢測到的異常點和其他的對象比起來是異常的。鑒于上述問題,本文的整體思路是在對子空間進行統計性檢驗處理的基礎上,整合一個對象在多個子空間的異常值得分最終判斷異常性,并提出關鍵子空間等概念,進一步對異常性加以解釋。
1 在子空間中搜索異常點
1.1 相關概念與維度災難問題
通常,異常檢測的任務就是對于給定的數據集DB,計算出數據集中所有對象o的一個排名,用對象排名的先后來表示對象的異常性。數據集中的屬性空間,即數據集中的所有屬性組成的集合使用D來表示,其中D={0, 1, …,d-1},總共d個屬性。因此對象o的所有屬性可以定義為o={o0,o1, …,od-1}。
假設使用rank函數來計算對象的異常值得分。一個理想的異常檢測方法,應該使得一個異常點o和一個正常的對象p的異常值得分,rank(o)遠小于rank(p),這樣才可以將異常點與其他對象顯著區分開。而傳統的一些方法可能會無法檢測出一些隱藏在子空間中的異常點,因為rank(o)≈rank(p)。這一現象可以由這類數據集中存在分散的子空間來解釋,對于每個對象而言只有部分屬性子集是相關的,其余屬性提供的或多或少是隨機值。假如使用所有屬性來計算對象之間的距離,就會出現維度災難問題。下面簡單闡述一下這個問題,現使用函數distanceD(o,p)來表示對象o,p在空間D上的距離,使用歐幾里得距離來計算,如式(1)所示,其中變量i表示對空間D上的所有屬性進行遍歷:
(1)
隨著空間D的屬性數d增長,數據集DB中的對象o與其他對象之間的距離越來越相似,如式(2)所示。
(2)
因此在這樣的全局空間中,對象距離變得沒有意義,最終就會導致rank(o)≈rank(p)。
1.2 鄰域N(o, S)的選擇
在進行子空間選擇之前,需要先介紹一個概念鄰域N(o,S),其中S表示一個子空間,意思是在子空間S內與對象o距離一定范圍內所有其他對象的集合。即N(o,S)={p|distanceS(o,p)<ε(|S|)}。其中|S|表示子空間S的維度。ε(|S|)隨著子空間的維度而變化。首先根據超球體的體積計算公式,可以得知d維子空間的體積公式如式(3)所示,其中ε可以理解為半徑,在這里一般設置為0.5。Γ(·)是伽馬函數,Γ(n+1)=n·Γ(n),Γ(1)=1,Γ(1/2)=π1/2。
(3)
根據上述公式,進一步定義函數h(d),如式(4)所示,其中n為數據集DB中數據的個數。
(4)
可以看出當n固定不變時候,h(d)函數是隨著d單調遞增的。在此基礎上可以定義ε(|S|),如式(5)所示,可以看出通過這樣的設計,使得ε(|S|)在2維子空間以上,隨著維度的增加而增加,這也為后續在多個不同維度的子空間中計算異常值得分做好鋪墊。
(5)
當使用python來實現上述過程時,可以利用numpy包。使用numpy.sqart和numpy.sum函數來計算對象之間的距離,使用numpy.where函數來返回距離在ε(|S|)范圍內的數據索引。
1.3 子空間的選擇
為避免1.1節中提到的問題,在本節中將介紹如何為每一個對象選擇出一系列的子空間,在這些子空間中,對象o和它的鄰域N(o,S)有明顯的區分性,規定使用RS(o)來表示這些子空間組成的集合。
首先,本文提出使用統計顯著性測試來選擇出需要的子空間S,進而組成RS(o)。因為對象是被分散的子空間所隱藏,所以此步的目的在于,通過在對象的鄰域N(o,S)中測試數據的潛在分布,來排除掉均勻分布的子空間。如圖 1給出的簡單例子,子空間S={0,1,2,3}就是需要排除掉的子空間,在這樣的子空間中,對象分布較為分散,幾乎可以視為均勻分布,三角形和正方形表示的異常點被隱藏在其中,而子空間S={0,1}和子空間S={2,3}就可以很好的分別分辨出三角形和正方形表示的異常點,而子空間S={0},這類稠密的子空間不會影響對異常值得分的計算所以不會被測試排除掉。具體的,在本文中采用的統計顯著性測試方法為KS-檢驗。KS-檢驗可以用來測試兩組數據有多大概率符合相同的分布,在這里用來判斷給定的數據有多大概率符合均勻隨機分布。
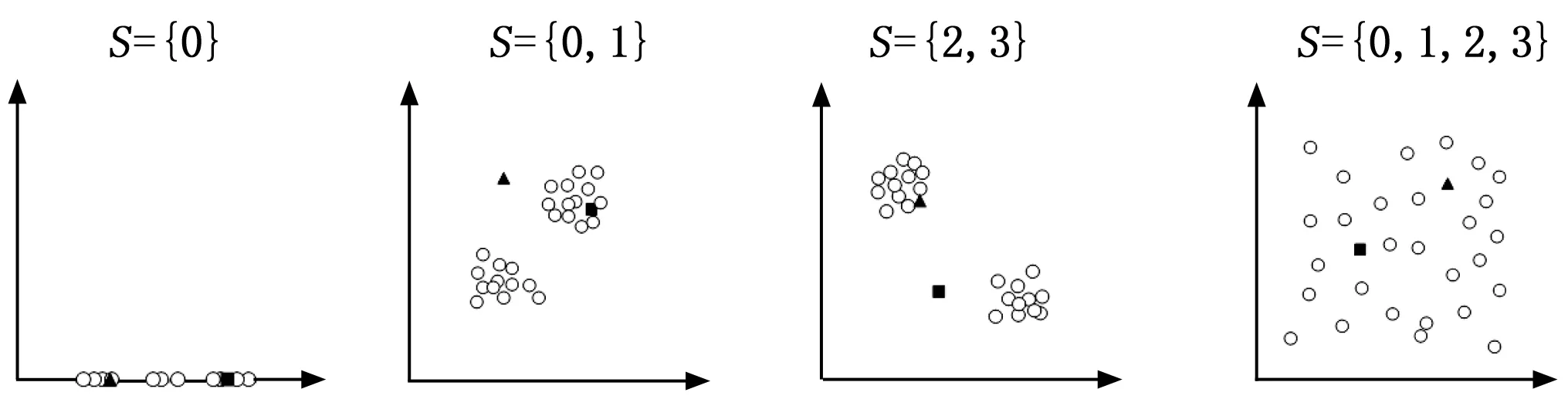
圖1 不同子空間案例
具體而言,本文定義零假設H0:S在鄰域N(o,S)中是隨機均勻分布的。備擇假設H1:S在鄰域N(o,S)中是非均勻分布的。確保P(H0被拒絕|H0是真)≤α,其中α是顯著性水平,一般設置為0.01。也就是說,拒絕H0的概率最大為1%,打個比方,在100個均勻分布的子空間中只有1個子空間可能會被判斷為需要的子空間。
正如圖 1中所展示的那樣,隨著子空間中包含的屬性數量增加,逐漸成為了隨機均勻分布的子空間,對象之間的距離逐漸變得相似。因此對子空間的選擇就可以轉變為對屬性的選擇,只要有均勻隨機分布的屬性被包含進這個子空間,就可以排除掉這個子空間。對于一個d維的全局空間D來說,它包含的非空子空間的個數為2d-1,也就是算法的搜索空間大小,由此可見,搜索空間隨著維度的增加呈指數級增長,因此算法采用了增量處理和剪枝策略。如圖2所示,從空集開始,每次添加一個屬性進入子空間中,使用加粗字體表示新加入的屬性,然后根據新加入的屬性判斷這個子空間是否是隨機均勻分布的,在每次判斷新的子空間時候,需要重新計算一次在這個子空間中對象o的鄰域N(o,S)。圖中箭頭旁邊給出的序號是算法的搜索順序(為了增加圖片的可讀性,搜索順序沒有全部標出),可以看出在這里采用了深度優先搜索,并且根據原始數據的屬性順序對屬性進行編號,添加屬性的時候按照編號升序的過程添加,避免了對相同屬性構成的子空間的重復性搜索。至于剪枝策略,在搜索過程中,如果發現某個子空間是隨機均勻分布的,則停止更深的搜索。
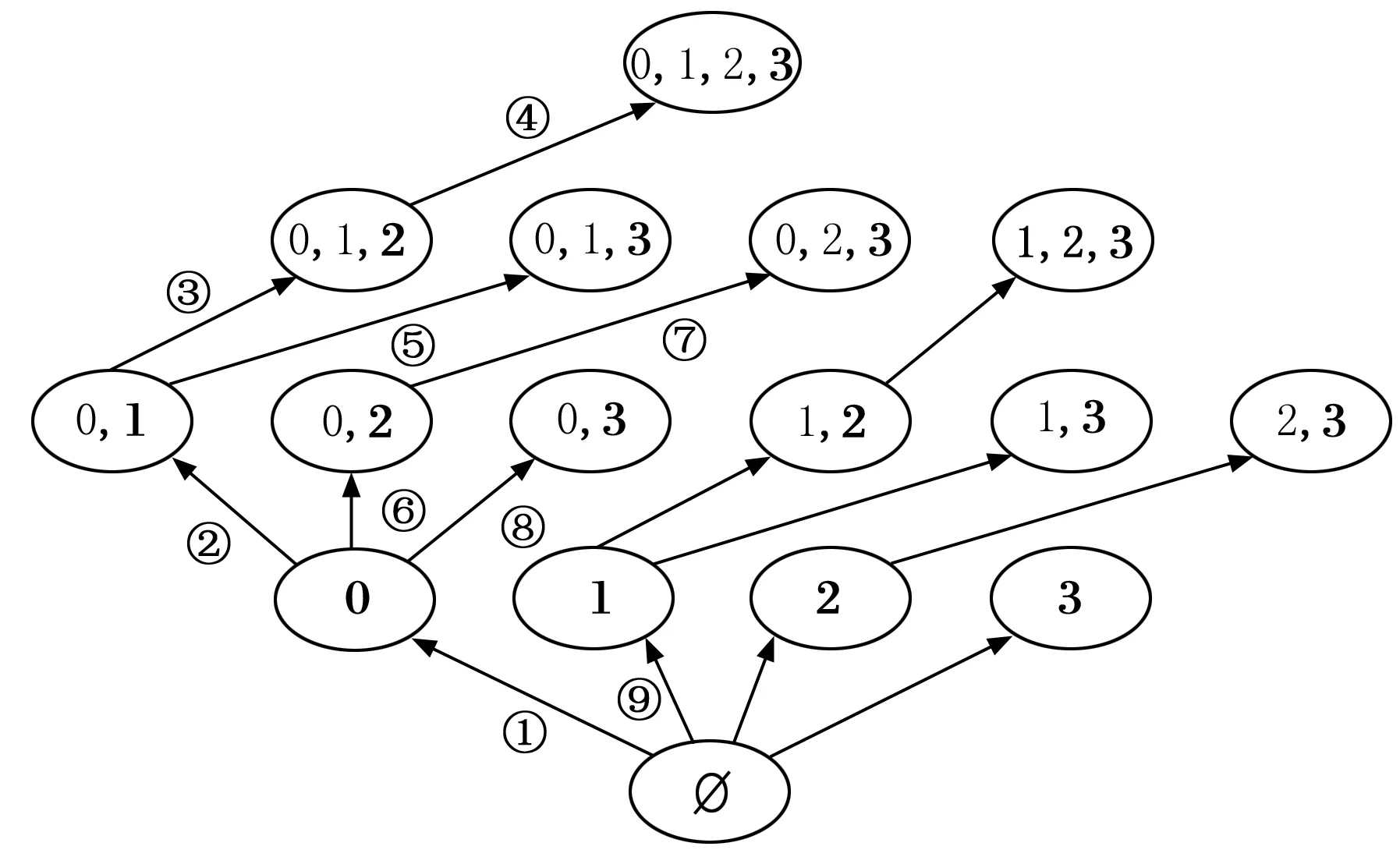
圖2 子空間搜索策略
當使用python來實現上述的統計顯著性測試時,只需使用scipy包中的stats.kstest函數,第一個參數為新添加的屬性在鄰域內對應的數據,第二個參數使用’uniform’,第三個參數使用(0,1),所以需要確保輸入的數據經過預處理后范圍在0和1之間。
1.4 子空間中異常值得分的計算
本文中使用對象在子空間中的密度來評估對象的異常值得分,一個對象的低密度值會導致一個較低的異常值得分,也即是對象更為異常。因為對象可能會在多個不同的子空間中展開計算,所以需要設計一個在多個子空間中可比較的異常值計算方法。因為數據的整體密度分布是未知的,所以考慮使用核密度估計來估計對象o的密度den(o,S)。每個對象o對總體密度產生局部影響,使用核函數K(x)來定義這個局部影響,在這里采用Epanechnikov核函數,即K(x)=1-x2,x<1。核函數中的變量x=distanceS(o,p)/ε(|S|),可以看出其為放縮后的對象o和對象p之間的距離。h函數如上文的式(4)所示,用來將每個對象o的影響放縮到最大距離。最終,如式(6)所示,對鄰域內所有對象計算后求和,取均值。與簡單的計算鄰域內對象數量的方法相比,核密度估計方法對每個對象的影響進行了加權,ε(|S|)的存在使得為每個維度的子空間都選擇了不同的帶寬參數,增加了任意維度子空間下異常性的可比較性。直觀來看,隨著維度的增加,每個對象的影響也跟著增加,這可保證隨著數據空間變得稀疏仍保持較優的密度估計。
(6)
當計算完對象o在不同的子空間下的den(o,S)以后,計算這些值的均值μ和標準差σ,然后找出那些den(o,S)<μ-2σ的。根據切比雪夫不等式可知,只有少數的對象會和均值差出兩個標準差,這表示他們的異常性會比較高。關于對象o和均值μ,標準差σ的偏差按式(7)計算,可以看出一個對象o,如果它的密度與均值密度μ相比很低的話,dev(o,S)的值就會很高。
(7)
最終,對象o的單一子空間中異常值得分函數的定義如式(8)所示,可以看出整體上對象o的異常值得分函數實現了兩個需求:第一是可以適應不同維度的子空間,第二是考慮到利用與均值的統計偏差來處理對象偏差。較低的密度和較高的偏差(即dev(o,S)≥1)都暗示對象有更高的異常性,即score_s(o,S)值更低。當偏差值小于1時,直接將異常值得分設為1,這樣的設置有利于后續整合多個子空間下的異常值得分。
(8)
最終一個對象o的最終異常值得分可以按式(9)來計算。因為score_s(o,S)函數的范圍是0到1,并且值越低表示對象的異常性越高,所以采用乘積的方式可以很好的讓數值低的子空間對整體提供更大貢獻,更加凸顯異常點和正常對象之間的差異。
rank(o)=Πs∈RS(o)score_s(o,S)
(9)
1.5 算法整體流程
經過上文的詳盡介紹之后,本節將在總體上對算法進行表述,代碼風格參考了python代碼,比如有關子空間的操作使用python中集合set的操作實現,對象數據,數據集等使用python中的ndarray數據結構進行操作。對于數據集DB中的每一個對象o都進行算法1的操作。算法2計算對象o,在所有通過測試的子空間的den(o,S)值。可以看出算法2使用遞歸的方式實現上文中的深度優先搜索以及剪枝策略。當得到所有對象的異常值得分后,按照值升序的順序給對象進行排列,異常值得分越低代表對象越為異常,可以把異常值得分看作對象使異常點的概率值,也可以按照異常檢測算法的常規處理方法,按照比例給對象賦予標簽。
算法1:SMAD_o
輸入:對象o,用o在數據集中的索引來表示;數據集X,即上文中經過處理后的數據集DB。
輸出:對象o最終的異常值得分,即文中的rank(o)
1)初始化S=set();
2)按照算法2計算,結果保存到all_den變量中;
3)計算均值μ和標準差σ;
4)按照式(7)計算;
5)按照式(8)計算;
6)按照式(9)計算;
算法2:den_o
輸入:對象o,用o在數據集中的索引來表示;子空間S。
輸出:所有通過測試的子空間的den(o,S)的結果
1)D_diff =D-S;
2)for i in D_diff:
(1)if(屬性i的索引值小于子空間S中的索引值最大的屬性):
continue;按屬性索引值升序處理,避免重復性的計算
(2)S_temp =S|i;
(3)根據1.2,1.3章節計算鄰域N(o, S_temp),并進行子空間測試;
(4)if(通過子空間測試):
計算den(o, S_temp);
調用算法2,參數o,S_temp;
else:
break
1.6 算法復雜度分析與優化實現
正如上文中提到的算法采用了剪枝策略,所以在這里主要分析的是最壞情況時間復雜度。首先對于每個對象o,都需要為其尋找子空間,當在最壞情況時,自下而上的剪枝策略沒有發揮作用,此時所有的子空間都是非均勻分布的,這需要進行的子空間判斷次數為2d。然后在計算密度的時候,產生了n次計算。最后,所有對象都需要進行上述步驟,總的來說的時間復雜度是O(2d·n2)。可以看出最壞情況的總體時間復雜度,一部分是指數級的,一部分是平方級的,所以下面提出了進一步的算法實現優化。
對于一個對象o而言,在式(6)的計算過程中,在多個子空間中會發生重復的距離計算,所以可以把歐幾里得距離計算步驟中的,求差值和求平方的過程提前到算法1的步驟(2)的前面,并把結果作為參數傳入算法2。對于n個對象的處理而言,可以看出對象和對象的處理之間是沒有數據交換的,只有在最后的階段需要根據所有對象的異常值得分進行排序,因此可以采用同步并行算法。使用python編程時,可以使用multiprocess包,它是一個基于進程的并發程序包,可以最大程度利用處理器的多線程處理能力。一個簡單的實現方法就是直接實例化一個Pool對象,初始化參數使用os.cpu_count(),按照計算機的處理器數量來生成并發池中的進程。這個函數提供了一種簡單的實現數據并行的方法,利用starmap函數可以將多個輸入變量傳入函數中,使得同一時間有多個相同的函數傳入了不同的參數在不同進程中處理。調用close()和join()函數,當所有任務完成后,并行自動退出,然后即可進行后續的異常對象排序。對于,時間復雜度隨著維度d而指數級增長的現象,結合集成學習的方法,對全局空間做無放回的隨機采樣,先生成若干個小規模的空間,然后把這幾個小規模的空間交給算法獨立處理,結果同樣按照式(9)的思想進行乘積結合。
2 基于子空間的可解釋性
2.1 概念提出
在上文的子空間概念的基礎上,在本節研究可解釋性。因為上文中異常點的判斷是綜合多個子空間后的結果,所以在這里需要先明確對象o是子空間S的異常點這一概念。參照圖 2把不同維度的子空間看作一層L,規定層數自底向上遞增,即L0,L1…。因為在上文中對每個對象都選取了合適的子空間,并計算了score(o,S),此時在每個子空間下,對屬于該子空間的score(o,S)進行升序排序,摘取排在前面的10%的對象組成集合,并與算法1中步驟6輸出的結果前10%的對象組成的集合做交集運算,運算結果中的對象即可視為這個子空間S的異常點。在此定義的基礎上,下面提出一些相關概念。
特殊異常點:假設對象o是子空間S的一個異常點,如果在S的任何一個子集里,對象o都不是異常點,則o是S中的特殊異常點。強異常點:如果子空間S包含一個或更多的異常點,而在S的任何子集里都沒有異常點存在,則稱子空間S為強異常空間,此時S中的任何異常點o都叫做強異常點。從定義中可以看出強異常點一定是特殊異常點。弱異常點:如果對象o是子空間S里的一個特殊異常點,如果o不是最強異常點,則o是一個弱異常點。可以看出,特殊異常點專注于對單一對象的解釋,利用最小的屬性子空間來解釋對象的異常。強異常點和弱異常點的概念更關注異常點之間的關系。強異常空間是較為重要的概念,因為它的子集都不包含異常點。
利用上述概念,便可以很好的增強算法結果的可解釋性。比如為每個異常點找到合適的子空間使其在那個子空間下成為特殊異常點。強異常空間,從低到高層來看是首個包含異常點的子空間,所以它和強異常點可以體現更為關鍵的異常情況。強異常點和弱異常點放在一起可以解釋異常點之間存在的某些關系。
2.2 基于子空間的可解釋性算法流程
為了減少算法的重復性計算,改善算法的效率,可以在算法1中的步驟(6)后把對象o在每個子空間S中的score(o,S)暫存起來。以子空間為單位,把屬于這個子空間的異常點都放一個集合中o_set。以子空間維度升序進行排序并放入列表L中。對于算法1中檢測出的每個異常點,在排序好的子空間序列L上從前到后的進行搜索,當在一個子空間對應的集合o_set中搜索到這個異常點后,即可認定這個異常點在當前子空間下是特殊異常點。
對于強異常點的計算,同樣在L上,從前向后遍歷每次取出一個子空間S,判斷其真子集是否在L中。由數據結構可知判斷過程只需向前搜索,每次對比的子空間為S_t,以python代碼風格來表示,需要判斷S_t&S是否與S_t相同,如果相同說明S_t是的S真子集。經過判斷后如果沒有真子集,則S是強異常空間。然后移除這個S的所有超集,可以直接使用issuperset()函數來判斷超集。繼續取下一個子空間S,重復上述過程,直到L遍歷完成。
對于弱異常點的計算,由定義可知,從特殊異常點中刨除強異常點就可得到弱異常點。即,由特殊異常點構成的集合,與強異常點構成的集合做差集,剩下的異常點就是對應子空間的弱異常點。
2.3 可解釋性算法的可擴展性與非侵入性
上文中已經講述了特殊異常點,強異常點,弱異常點的概念,并介紹了算法的主體思想,即按維度升序來對每一個子空間做處理。上述概念與算法思想可以輕松的擴展與移植到其他的算法之中,非侵入性是指對原始算法不產生其他影響,只作為附加算法,增加一些附加步驟,來增強結果的可解釋性。
對于一種異常檢測算法M,可以先在全局屬性空間計算異常點,將結果組成集合R_set,然后再對全局空間劃分成不同維度的屬性子空間,同樣以維度升序的方式,在每個子空間執行算法M,都生成了一個結果集合r_set,對R_set和r_set做交集運算,其結果作為當前子空間的最終的異常點檢測結果。然后同樣可以按照2.2章節來算出特殊異常點,強異常點和弱異常點。
3 實驗
3.1 實驗平臺軟硬件條件
本章節全部實驗的運行環境為win10操作系統,CPU是i7-6700HQ,內存16 GB,IDE使用PyCharm2021.2.1,python版本號3.8.5,主要使用的python包有:numpy 1.19.5;pandas 1.2.2;scipy 1.6.2;scikit-learn 0.24.1。
3.2 評價指標
異常檢測問題可以看作為一種特殊的二分類問題,所以本文中使用廣泛使用的AUC,P來評價算法的有效性。AUC即ROC曲線(接受者操作特征曲線)與x軸和y軸圍成的面積,P即查準率或精度。在介紹這兩個指標之前需要先介紹一下如表 1所示的混淆矩陣。在做異常檢測時候,可以把異常點當作正例,把其他點當作反例。

表1 混淆矩陣
在混淆矩陣的基礎上,可以得到查準率P的定義,如式(10)所示,可見P值越高越好,理想狀態下,最佳時候為1。
(10)
ROC曲線的縱軸是TPR(真正例率),橫軸是FPR(假正例率),分別如式(11)和(12)所示。在此基礎上,即可繪制出ROC曲線,理想狀態下,TPR高,說明異常點被漏檢的少;FPR低,說明被誤認為是異常點的少,AUC值趨近于1。
(11)
(12)
3.3 數據集選取
實驗采用的數據集來源為ODDS[15],ODDS的數據集主要是在UCI[16]中的分類任務用數據集的基礎上對數據的標簽做了處理,將標簽中的少數類標記成異常點,并把數據集封裝成mat類型文件,使用X變量來表示對象的各維度的數據,使用y變量表示對象的標簽,方便異常檢測任務的直接使用。下面選取了ODDS網站中的13個多維點異常數據集,這些數據集來源于多個不同的應用領域,比如醫療領域的數據集:annthyroid,Arrhythmia,breastw,cardio,lympho,pima,vertebral分別是甲狀腺疾病,心律不齊,乳腺癌疾病心電圖淋巴管造影術糖尿病和脊柱的數據,此外還有雷達數據,玻璃數據,紅酒數據等。數據集的基本情況如表2所示,可以看出選取的數據集樣本個數,數據維度,異常點比例變化范圍很廣。異常點比例將應用于給異常點打標簽進而計算查準率。
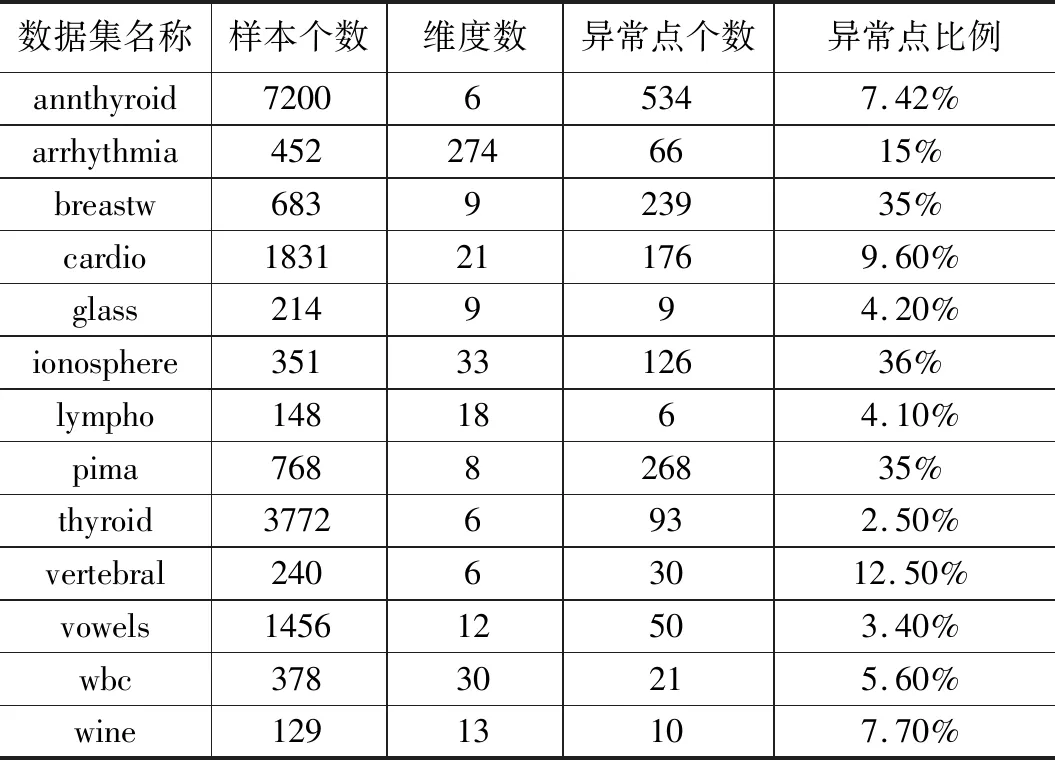
表2 數據集信息
3.4 對比方法設置
本文選取了10種不同類型的對比方法,按照方法英文縮寫名升序排序分別是ABOD、CBLOF[17]、DeepSVDD、FB[18]、HBOS[19]、LODA[20]、LOF、MO_GALL、ROD、SO_GALL。上述對比方法的主要實現來源于趙等人的文章[21]。
ABOD方法是指基于角度的異常檢測,其把一個對象關于所有鄰居的加權余弦值的方差作為異常值得分,方法包含一個超參數鄰居個數,在這里設置為10。CBLOF方法是基于聚類的異常點檢測,在這里使用KMeans聚類方法,聚簇數設置為8,α和β參數分別設置為0.9和5,用來劃分大、小聚簇,然后根據對象所在聚簇的大小和其離最近的大聚簇的距離來評估異常性。DeepSVDD方法是一個深度方法,使用了自動編碼器,程序的基本參數設置如下,隱藏層神經元個數64,32,隱藏層激活函數relu,輸出層激活函數sigmoid,優化器選擇adam,迭代次數100,批大小設置32,丟棄概率0.2。HBOS即基于箱線圖的異常檢測,參數設置如下:桶的個數設置為10,α設置為0.1,tol設置為0.5。LOF方法參數設置如下:鄰居數量設置為20,采用歐式距離。FB是指feature bagging,使用多個基檢測器在數據集的子集上進行檢測,并取平均值,參數設置上,選擇LOF作為基檢測器,檢測器數量10。LODA是輕量化在線異常檢測方法,參數設置如下:桶的個數設置為10,隨機劃分的數量設置為100。MO_GALL參數設置如下:子生成器個數10,迭代次數20,生成器學習率0.000 1,鑒別器學習率0.01。SO_GALL參數設置如下:迭代次數20,生成器學習率0.000 1,鑒別器學習率0.01。
3.5 實驗設計與結果分析
實驗開始前,需要對輸入數據做預處理,預處理方法選用sklearn.preprocessing.MinMaxScaler函數,將數據范圍調整到0和1之間,并保持數據的形狀與原數據一致。每個算法在每個數據集上運行10次,再取平均值作為最終結果。如表3給出的是本文方法SMAD與其他10種方法在13個數據集上的AUC,并在下方給出了每個方法在多個數據集上的平均AUC,使用加粗字體表示在該數據集上的最佳結果。可以看出本文方法SMAD在部分數據集上結果是最佳的,在其他數據集上結果沒有太大劣勢,這類數據集的一個特點是異常點比例偏低。從總體上看,本文方法在平均AUC上最高的,可見對子空間進行選擇這一過程產生了實質性效果。表 4中給出了不同算法在數據集上的查準率的對比,給出了每個方法在數據級上的平均查準率,并用加粗字體表示該數據集上的最優結果。可以看出,總體上與表3體現出了相似的結果,本文方法在平均查準率上是最佳的,在低異常點個數的數據集上算法的查準率相對來說都會變差,尤其是幾個深度學習方法劣勢較為明顯。表5給出了不同算法在數據集上的運行時間對比結果,以及在每個數據集上不同算法的平均運行時間,并用加粗字體標記出運行時間最長的算法。從表格結果可以看出本文算法的運行時間介于其他幾個機器學習算法和以DeepSVDD為代表的深度學習方法之間。子空間的搜索過程給算法的整體運行時間帶來了一定的負面影響,尤其是在數據維度很高的時候,運行時間會較為明顯的增加,不過與深度學習這類方法相比,本文算法的計算過程還是相對較為簡單的。此外受制于實驗平臺的CPU物理核數影響,算法的并行實現沒有帶來較為明顯的運行時間的改善。

表3 不同算法在數據集上的AUC對比結果
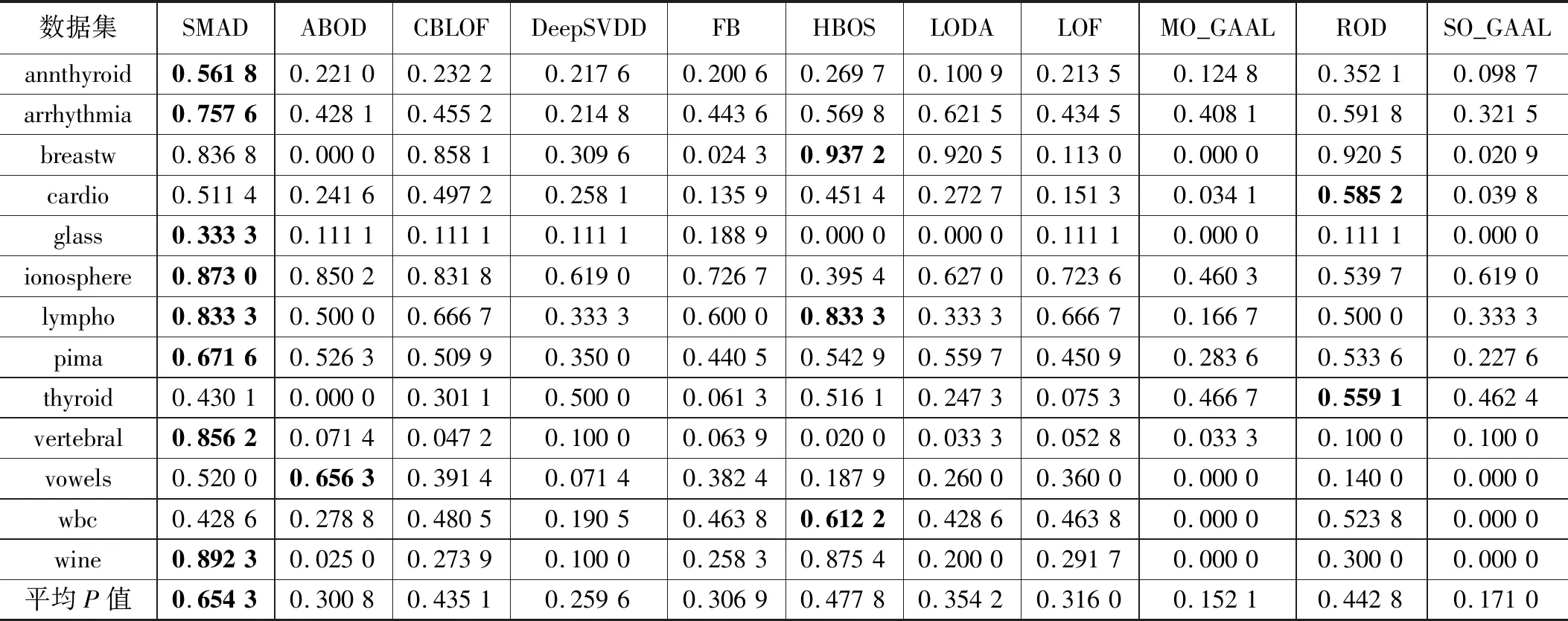
表4 不同算法在數據集上的P值對比結果
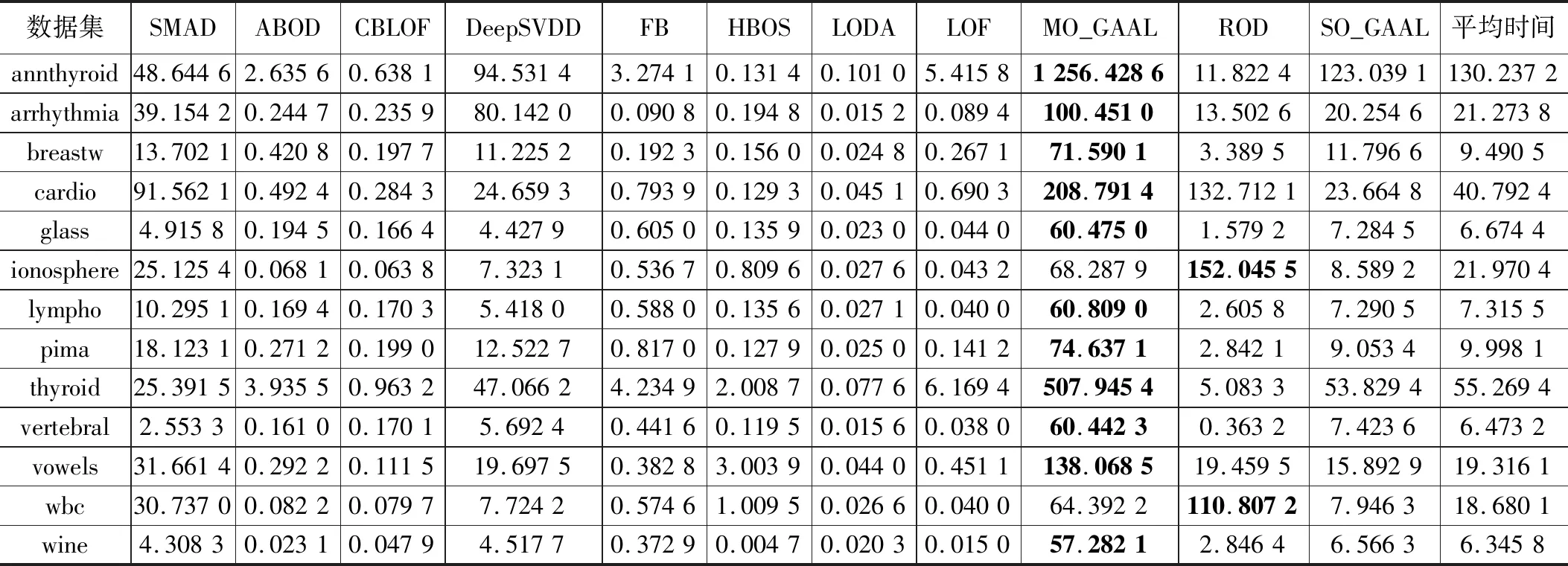
表5 不同算法在數據集上的運行時間對比結果
綜合表 3、表 4和表 5實驗結果,以及考慮到算法的無參數特性,可以確定本文提出的算法在實際應用場景中適合在周期性的數據批處理過程中使用。
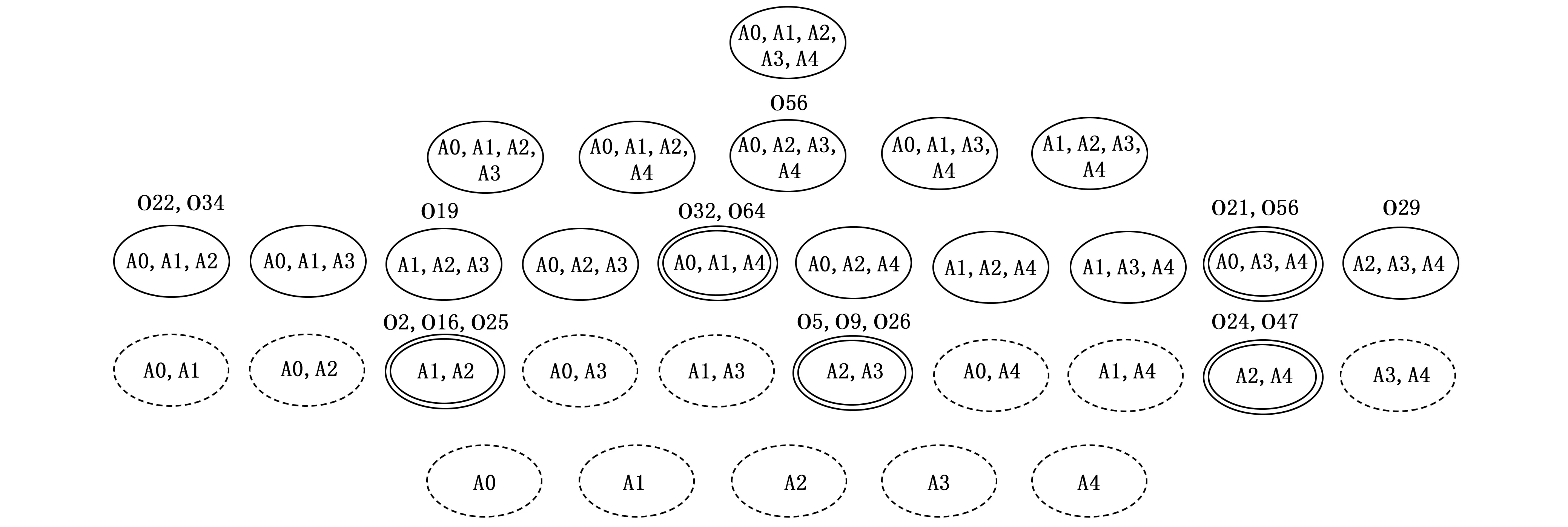
圖4 可解釋性圖例
因為AUC相比查準率可以更好的評估算法的綜合性能,為了更好的展示本文算法的優勢,圖 3以折線圖的方式給出了這11中方法在這13個數據集上的AUC結果。可以看出本文的算法的折線基本集中在上方,可見其有效性。
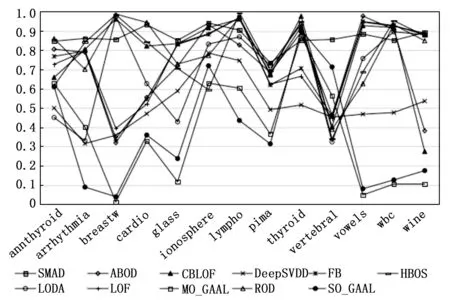
圖3 不同算法在數據集上的AUC折線圖
3.6 可解釋性算法結果展示
在這一章節中,使用ionosphere數據集來呈現可解釋性算法的結果。ionosphere數據集是來自于拉布拉多鵝灣的一個雷達系統的數據。其有17個脈沖數,每個脈沖數使用2個屬性來表示,對應于由復雜電磁信號產生的函數返回的復數值,一共34個屬性,其中一個屬性的數據是全0的,所以舍棄掉該屬性,剩余33個屬性。為了展示的簡潔性,圖 4以樹形圖的方式展示了在部分屬性上的部分對象的結果,使用橢圓表示一個子空間,A0~A4表示5個屬性,虛線的橢圓表示該子空間不包含任何異常點,雙實線的橢圓表示該子空間是強異常空間,單實線的子空間表示該子空間不包含強異常點,但可能包含弱異常點。橢圓上方用字母‘O’加數字的形式表示在該子空間下發現的異常點,根據第2章節的講解,可知雙實線橢圓上方標出的是強異常點,單實線橢圓上方標出的是弱異常點,可見這一形式可以很好的改善用戶對異常點之所以異常的理解。
4 結束語
針對多維特征數據中,部分異常點被分散的特征空間所掩蓋而無法檢出的問題,以及當前方法可解釋性不佳的情況,本文提出了基于子空間選擇的異常檢測算法。利用統計性檢驗選擇子空間,結合多個子空間的結果作為最終的異常值,并在子空間的基礎上提出了對異常點的解釋方法。在公開數據集上的測試展現了算法較佳的檢測性能。在未來的研究中,將進一步針對算法的執行效率進行優化,如引入VP樹等數據結構來加快搜索速度。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
兒童故事畫報(2019年5期)2019-05-26 14:26:14
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
