基于BERTScore 指導的文本摘要技術
2022-12-01 06:00:26劉高軍王一如王昊
電子設計工程 2022年23期
劉高軍,王一如,王昊
(1.北方工業大學信息學院,北京 100144;2.CNONIX 國家標準應用與推廣實驗室,北京 100144)
從文本的大量內容中提取出核心摘要具有重要意義[1],根據提取方式的不同,其主要分為生成式文本摘要和抽取式文本摘要[2]。對于生成式文本摘要,很多非神經系統通過使用選擇并壓縮的方法[3]提高摘要結果的事實準確性[4],通過使用序列到序列模型生成最終摘要,以上方法得到的結果可能存在語法錯誤[5],甚至出現與原文相悖的內容[6]。對于抽取式文本摘要,通過對整篇文章進行句子抽取并排序得到最終摘要[3],利用分類器決定是否抽取出文本中的某個句子[7],以上提到的抽取方法會出現過度抽取的情況,并且通常詞級別的抽取式文本摘要得到的結果可讀性較差[8]。
為解決上述問題,文中使用了基于BERTScore反饋的強化學習模型將兩種摘要方法相融合。首先為降低文本中干擾信息的影響,利用卷積模型以及Bihop 注意力機制抽取出文本的重要信息,其抽取結果在生成摘要階段結合注意力機制進行壓縮,在訓練過程中計算壓縮結果與參考摘要的BERTScore 值,該值作為反饋指導模型更新策略梯度參數和當前狀態,進而指導下一步抽取行為,以此不斷提升模型在抽取階段的性能。使用BERTScore 能夠處理其他基于N-gram 的評估指標對表示相同含義的不同詞匯評分低的問題,進而保證了摘要結果的多樣性并增強了整個模型的健壯性和對語義的重視程度。同時,文中的模型中加入了Gumbel-Softmax 可微再參數化技術,改善了模型不可微的情況。
1 模型設計
文中先用抽取式模型過濾原文本中的干擾信息,然后用生成式方法對抽取出的內容壓縮,得到精簡摘要,完整模型如圖1 所示。模型使用基于策略梯度的強化學習將兩種摘要方式相融合,并利用BERTScore 作為強化學習的反饋調整策略梯度參數和當前狀態,該狀態將作為下一步抽取行為的依據。BERTScore 更關注文本內容,得到的摘要結果也更為準確,因此文中的模型在提升了篩選重要信息能力的同時,得到了與原文內容更相符的摘要結果。Gumbel-Softmax 可微再參數化技術的加入用于解決抽取式模型不可微的情況。
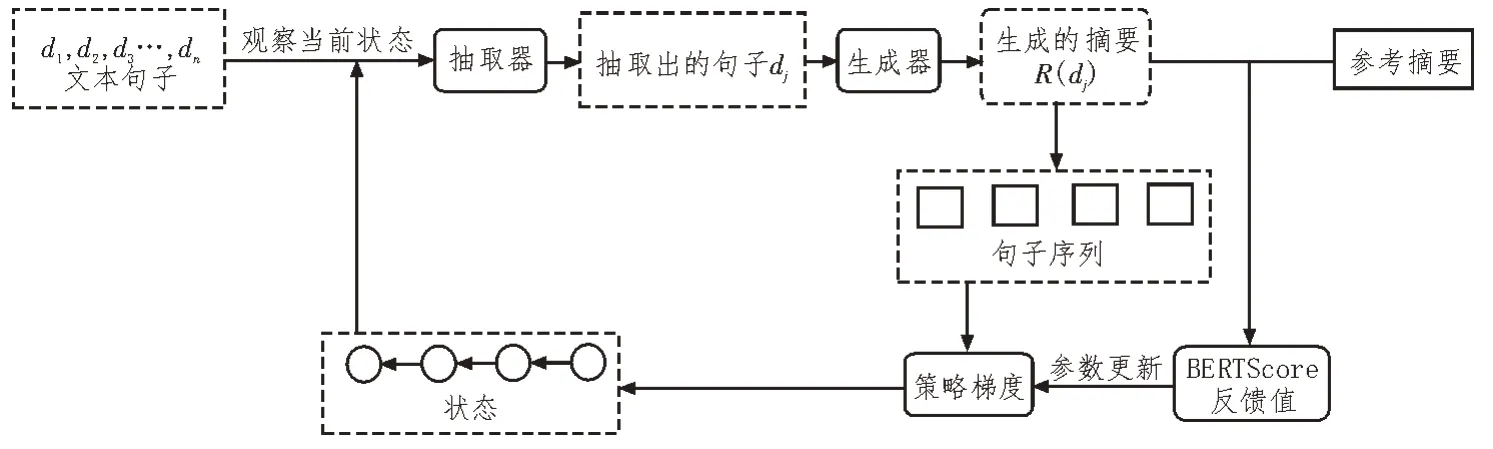
圖1 完整模型圖
1.1 句子的表示與抽取
首先利用時序卷積模型得到文本中每個句子的表示,再由BERT 預訓練的詞向量矩陣Wemb得到每個詞的分布向量表示,并經過一維單層卷積過濾器獲得詞與前后內容的依賴關系。使用由LSTM-RNN 訓練的指針網絡從已得到句子矩陣表示的文本內容中篩選出重要句子,如式(1)所示:

整個網絡中結合了Bi-hop 注意力機制,其中第一層注意力機制用于確定包含重要信息的句子,第二層用于計算每個句子被抽取的概率,以上步驟如圖2 所示。
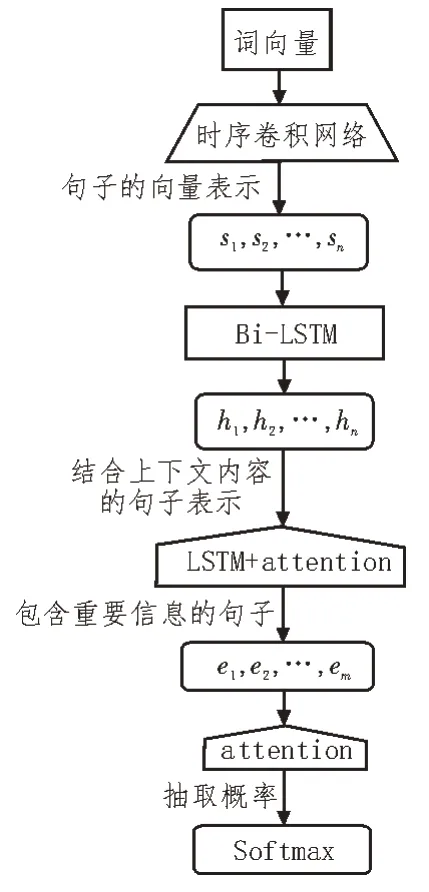
圖2 句子的表示及抽取過程
1.2 摘要的生成
由于在抽取階段已過濾文本中的干擾信息,生成摘要階段是對上一階段抽取出的包含重要內容的句子進行分析與壓縮,因此該部分使用結合注意力機制的seq2seq 模型就可得到準確且精簡的摘要結果。文中模型加入了結合雙線性乘法注意力機制的編碼器-解碼器結構,如式(2)所示。針對生成式文本摘要會出現的OOV(Out-of-Vocabulary)問題,模型中使用了copy 機制。
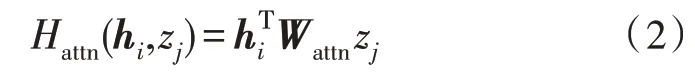
其中,hi是結合了上下文內容的句子向量,zj是抽取出的句子,Wattn是注意力權重矩陣。
1.3 結合BERTScore的強化學習模型
1.3.1 BERTScore計算
當前的文本摘要研究任務中常根據評估指標Rouge 的情況微調模型,該指標在評估摘要結果時只考慮句子表層詞匯的匹配情況,并未考慮句子內容,導致摘要結果的事實準確性不可控。文獻[8]提出的從文本內容的角度評估翻譯結果精確性的方法可改善翻譯任務中與上述問題相似的情況,因此文中的模型加入了結合BERTScore 的強化學習模型,將抽取式文本摘要與生成式文本摘要相融合,即利用actor-critic 策略梯度將句子級別的BERTScore 評估結果作為反饋指導抽取行為,并學習句子的顯著性特征。模型的整個過程與馬爾可夫決策過程(MDP)相似:抽取器作為強化學習的agent,在每一步(t)抽取之前先觀察當前狀態,并將上一步(t-1)的摘要評估結果作為反饋,指導當前的抽取行為。
模型中計算預測摘要與參考摘要匹配情況的BERTScore 更加注重語言的多樣性,能夠關注到表示相同語義的相似詞匯。文獻[10]的研究表明,此評估方式的結果與人工判斷有很高的一致性。BERTScore包括的Recall(RBERT)、Precision(PBERT)和F1(FBERT)均通過計算文本向量的余弦相似度得到:

1.3.2 反饋值的計算
模型中首先直接用BERTScore 評估預測摘要與參考摘要的內容匹配情況,并將該值作為強化學習模型的反饋指導抽取行為,同時考慮到基于N-gram的評估指標Rouge 常用于評估文本摘要的詞匯匹配度,故文中嘗試將兩種評估方式相結合,從詞匯匹配情況以及內容匹配角度共同評估預測摘要的效果,從而更全面地考量模型的性能,并更好地指導抽取行為,聯合反饋值計算公式如下:其中,λ是BERTScore 和Rouge 的調和參數。

2 可微再參數化技術
針對模型抽取器部分不可微的情況,文中使用了Gumbel-Softmax 函數替換計算抽取概率的Softmax函數,公式如下:

式中,x表示抽取出的句子,θ是訓練參數。Gumbel-Softmax 函數是為解決模型不可微問題的可微再參數化技術,它允許通過轉化Gumbel 分布的樣本選擇變量值,該函數可表示為:
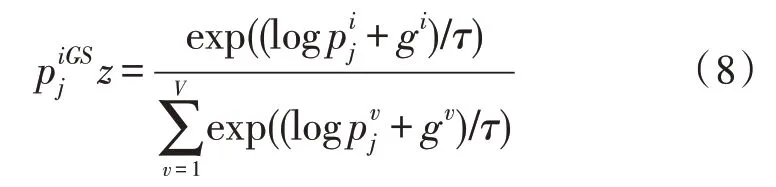
3 訓練和實驗
針對CNN/DailyMail 的驗證集,對實驗中的參數均進行了調整,文中使用了32 個樣本的小批量數據進行所有的訓練,Adam 優化器的學習率在機器學習階段為0.001,在強化學習階段為0.000 1。文中首先訓練抽取器和生成器直到二者均收斂于極大似然函數的目標,然后使用強化學習訓練上述訓練好的子模塊。在用到LSTM-RNNs 的部分均使用了256 個隱藏單元,對于模型中的極大似然訓練模型,文中使用BERT 預訓練語言模型取代由Word2vec[11-12]初始化的詞向量矩陣,并且該詞向量矩陣將根據訓練情況更新。
3.1 實驗數據
文中使用的數據集是包含了美國有線新聞網(CNN)以及每日郵報(Daily Mail)共約一百萬條新聞語料的CNN/Daily Mail。實驗中使用的是該數據集的未匿名版本,并對該數據進行適當的處理,其中包含了訓練文本、驗證文本和測試文本。
3.2 評價指標
結合文本摘要任務通用的評價指標[13],文中使用Rouge-1(R-1)、Rouge-2(R-2)、Rouge-L(R-L)評估預測結果的質量。考慮到文中將BERTScore 評估函數加入到模型中,因此為體現該評估函數對模型效果的影響,將FBERT作為評價指標評估摘要內容質量。
3.3 實驗結果及分析
3.3.1 模型總實驗
為了驗證文中模型在文本摘要任務的優良性,將其與不同摘要方法進行對比,表1 為各不同模型的實驗結果對比情況。
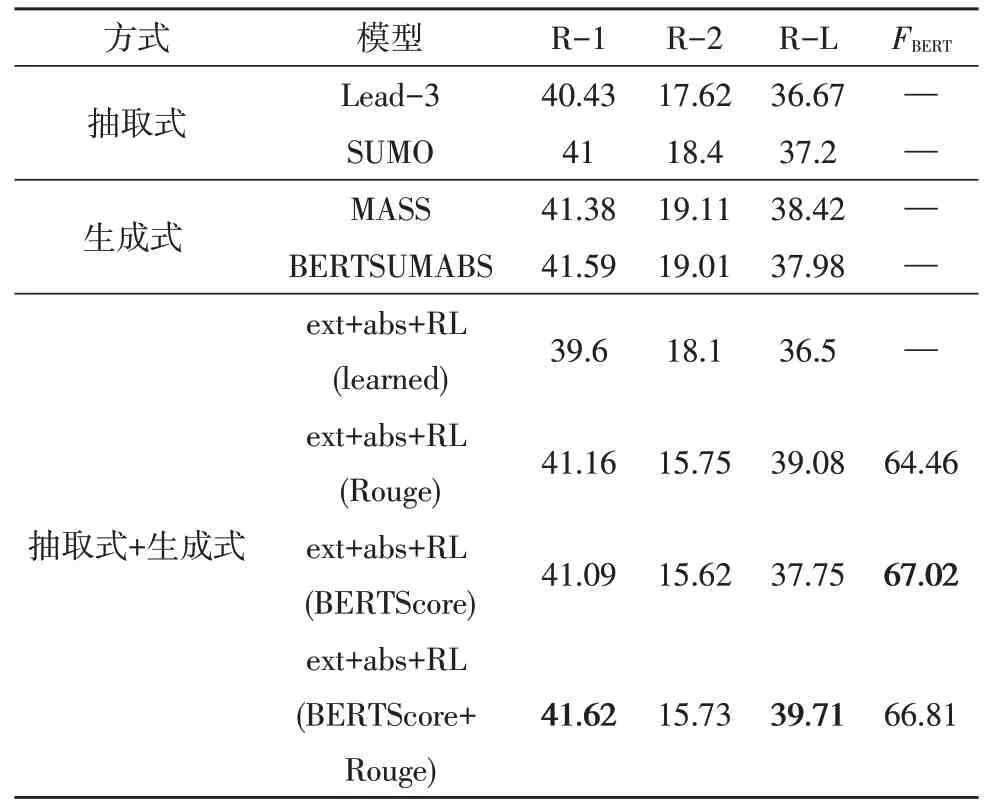
表1 各模型在CNN/DailyMail的實驗結果
1)抽取式文本摘要
表1 中第一部分是抽取式文本摘要實驗結果對比,其中Lead-3 算法得到的摘要是文本的前三句。SUMO[14]是以樹歸納的角度得到的抽取式文本摘要,證明了文檔結構對抽取式文本摘要有重要作用。
2)生成式文本摘要
表1 中第二部分是生成式文本摘要實驗對比結果,MASS[15]提出了基于文本摘要源句中單詞的中心度為指導的復制機制,因此更關注源句中的單詞。BERTSUMABS[16]證明了篇章級編碼對任務的重要性并且沒有使用其他機制就得到了較好的實驗結果。
3)抽取式與生成式相結合
表1 中第三部分是將抽取式文本摘要與生成式文本摘要相結合的實驗結果對比,并且對比的模型均是使用強化學習優化整個模型,差別在于使用的反饋不同,ext+abs+RL(learned)[17]使用損失函數計算反饋值,由于計算反饋值的過程不是基于N-gram 的方式,且此實驗結果受Rouge 評估方式影響,因此得到的Rouge 結果不理想。使用Rouge 作為反饋的ext+abs+RL[3]模型得到了相比上述模型更好的結果,而使用文中提出的以BERTScore 作為反饋的模型得到的摘要結果,相比于Rouge 作為反饋的模型,其基于N-gram 評估的角度分值較低,這是由于生成式文本摘要根據對句子的理解生成新的句子,該句子中可能包括原句中沒有的詞匯。文中以BERTScore 作為反饋考量的是文本內容的匹配情況,而并非只考量句子表層詞匯的匹配情況,因此文中模型在評價指標FBERT角度得到的分值要高于上述模型,這也與人工總結文本的結果更相似。以BERTScore 和Rouge 共同作為反饋的模型(λ=0.5)既考慮了句子表層的詞匯匹配情況,又考慮了文本內容的匹配情況,因此得到的摘要結果在Rouge 方面有一定的提升(與ext+abs+RL(Rouge))相比,在評估指標Rouge 角度提升效果為R-1:+0.46;R-2:-0.02;R-L:+0.63,與ext+abs+RL(BERTScore)相比,在評估指標Rouge 角度提升效果為R-1:+0.53;R-2:+0.11;R-L:+1.96。在評估指標FBERT方面,與ext+abs+RL(Rouge)相比,提高了2.35,由此可見,將Rouge與FBERT聯合作為強化學習的反饋能夠優化整個模型,并得到與參考摘要更相近的結果。
3.3.2 對比實驗
為了驗證文中模型使用結合BERTScore 的強化學習模型的有效性,針對上文提到的調和參數λ值設置對比實驗,評估指標avg 由R-1、R-2、R-L和FBERT三者計算均值得到,對比實驗中λ分別取值為0、0.25、0.5、0.75、1,與各取值相對應的實驗結果如圖3所示。

圖3 參數對比實驗
其中,λ為式(6)中BERTScore 和Rouge 的調和參數,avg 為評估指標R-1、R-2、R-L和FBERT的均值。
由圖3 中對比實驗結果可看出,當λ=0.5 即均衡考慮詞匯匹配情況和內容匹配情況時,生成的摘要效果最好,因此,當模型使用BERTScore 和Rouge 共同作為強化學習的反饋進行實驗時,取λ=0.5。
4 結束語
文中在利用強化學習將抽取式與生成式兩種摘要方法相融合的基礎上,使用BERTScore 評價指標作為模型的反饋,避免了使用Rouge 評價指標忽略不同詞匯表示相同語義的情況,并且文中嘗試將BERTScore 和Rouge 聯合作為反饋,以最大化理解文本內容的同時權衡詞匯匹配度,得到了與人工總結盡可能相似的文本摘要。文中使用Gumbel-Softmax可微再參數化技術優化了模型中抽取器不可微的問題。未來,仍需要繼續探索文本摘要的評價方法以及加強對文本內容的重視,以得到效果更好的文本摘要。
猜你喜歡
科學大眾(2022年11期)2022-06-21 09:20:52
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
電子制作(2018年18期)2018-11-14 01:48:06
臺聲(2016年2期)2016-09-16 01:06:53
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2014年1期)2014-02-28 21:59:13
中華胰腺病雜志(2012年3期)2012-11-07 05:18:45
