基于多源異構數據融合的電力工程知識圖譜架構算法
2022-12-01 06:00:30趙軍董勤偉戴威
電子設計工程 2022年23期
趙軍,董勤偉,吳 俊,戴威
(國網江蘇省電力有限公司,江蘇 南京 210000)
隨著我國經濟的發展,配電網絡的配置和規模受用電需求的增長而不斷發生改變,如何對配電網絡進行科學的管理、及時發現潛在故障的誘因、快速確定故障的類型與解決方案成為了業界關注的焦點[1-3]。為了保障供電安全,較多先進的監測設備和管理措施被應用在現代電力系統中,尤其是數據中臺的建設促使電力行業數據實現了邏輯集中,使得各類電力系統所產生的數據得以有效采集、存儲、處理和分析[4-8]。除了上述數據外,來自互聯網等其他領域的公開數據逐漸被應用在電網安全風險評估、安全維護等應用領域[9]。
隨著數據來源的增多,海量、異構數據的高效處理成為制約電力行業數字化發展的瓶頸。如何進行電力行業內部數據與外部數據的有效融合,成為相關學者的研究課題之一[10-11]。目前為止,網絡本體語言、資源描述框架被提出用來進行異構數據的表示,并取得了一定的進展。2012 年,知識圖譜由谷歌公司提出,因其嚴謹、強大的數據表示能力以及完善的各類配套工具,成為多源數據融合的重要方法之一[12-16]。
針對以上問題,該文開展了電力工程知識圖譜架構算法研究。通過構建電力工程知識圖譜將電力行業與外部數據進行系統性整理,同時理清相關專業概念,便于相關從業者查詢;針對多源、異構數據,采用CRF 算法把非結構化文本信息通過分詞以及提取詞向量的手段轉化為結構化信息;最終將典型相關分析(CCA)和深度神經網絡相結合,通過逐層語義匹配,構建出深度語義匹配模型。
1 算法框架
電力工程知識圖譜的構建目的在于對電力系統中的各項數據進行系統性地整理、分析,從而發現電力系統管理中的不足和潛在故障誘因,提高電網管理和應急保障能力。知識圖譜是一種由節點和邊線構成的圖數據結構,每一個節點代表電力系統中一類信息來源,通過連線的方式表征來自不同信息源數據之間的邏輯關系,進而得到實體關系網絡。而多源異構數據的融合,有效提升了電力數據的數據挖掘能力,進而提高預測電力故障的精度。通過基于多源異構數據融合的電力工程知識圖譜架構算法,可以有效提高電力系統管理的綜合能力。
基于多源異構數據融合的電力工程知識圖譜架構算法主要分為兩個部分,如圖1 所示。第一個部分為知識圖譜構建,首先整理相關領域的專業術語,并將其轉化為知識圖譜的節點,再以各專業概念之間的邏輯關系為各節點的連線;第二個部分為非結構化的概念和信息的結構化轉換與數據融合。

圖1 電力工程知識圖譜架構算法的總體框架
2 電力工程知識圖譜架構算法
2.1 電力系統多源異構信息模型構建
伴隨著國家電網建設規模的增大,電網數據呈現大幅增長的趨勢,且數據類型繁多,具體表現為:不同的采集周期所呈現出來的數據信息略有不同;電網數據地域化特征明顯,由于不同地區所開展業務的情況不同,相關數據考核指標也略有不同;配電站、輸電網絡等內部數據,以及來自互聯網等外部數據促使電網數據來源廣泛。
為了改善傳統數據存儲、分析技術的不足,構建了電力系統多源異構數據信息模型,將電力數據劃分為三個類別:電網數據、用戶數據和社會數據。電網數據覆蓋了電能的產生、傳輸、故障檢修和質量評估,涉及到電力生產系統、供電電壓自動采集系統、故障搶修管理系統以及數據采集控制系統等;用戶數據主要是指采集系統數據、充電樁數據、CMS 系統數據等;社會數據主要是指公共服務系統數據、氣象系統數據和地理系統數據,具體如表1 所示。

表1 電力系統數據分類表
為了降低文本等非結構化數據轉化成結構化數據的難度,電力系統多源異構數據信息模型在進行數據采集和輸出時,應具有統一的格式。該文將電力系統多源異構數據信息模型的數據物理結構設計成三級形式:表頭、索引和存儲,如圖2 所示。
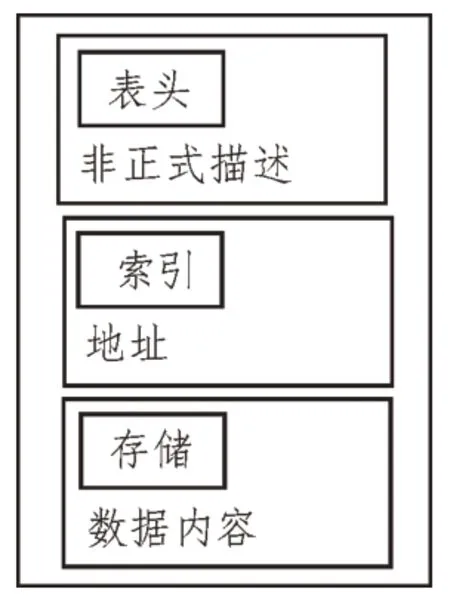
圖2 多源異構數據信息模型的數據物理結構
無論是電網數據、用戶數據還是社會數據,均存在大量的文本信息。文本信息與數字信息不同,屬于非結構化信息,并不能直接進行特征提取;且由于文本信息通常是連續的文本序列,并摻雜著大量、無實際意義的語氣詞,因此需要進行中文分詞。該文采用CRF 算法,利用事先標記好的樣本數據進行模型訓練,進而將概率最大的詞作為分詞結果輸出。
2.2 電力系統異構數據融合
由于電力系統中某些模態的數據實例數目較少,造成了特征提取不準確的現象,該文采用遷移學習來解決數據實例較少的域的特征學習。其具體過程為:將典型相關分析(CCA)和深度神經網絡相結合,通過分詞后的多源異構模態數據的逐層語義匹配,構建滿足域私有網絡和域共有網絡的深度語義匹配模型。
深度神經網絡通常包含:輸入層、隱藏層和輸出層,這些層也包含了多種分支。該文使用深度置信網絡作為多源異構數據融合算法的基本模型,其由多個受限玻爾茲曼機組成,采用逐層正向、反向進行網絡參數的訓練。在文中將典型相關分析融入深度置信網絡中,參與源域數據和目標域數據的相關性分析。而深度置信網絡可作為初始參數的預訓練,以提高模型的性能和收斂速度。
典型相關分析可以將不同數據域中相關的特征,通過矩陣映射到某個特征子空間,由此可將強相關性的特征提取出來。考慮到電力行業數據和外部數據存在多個數據源,且不同數據源的體量大小不一,使用典型相關分析來提取不同數據源之間的共享特征,進而實現遷移學習。在這一過程中,不同數據源的共生數據CS、CT的隱層特征在轉換矩陣的作用下被提取出來,并得到相關匹配系數矩陣。具體過程如下:
1)利用棧式自動編碼機對源域以及目標域進行編碼,通過編碼結果將跨域共生數據提取出來,進而得到其對應的隱層特征。
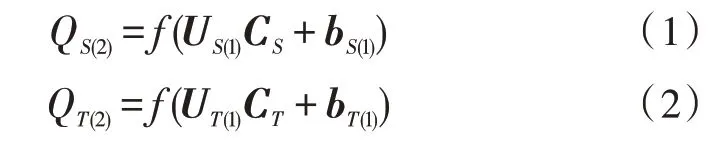
在以上兩式中,US(1)、UT(1)分別表示源域和目標域的網絡權重矩陣,bS(1)、bT(1)分別被用來表示源域和目標域相應的偏置向量,f()為Sigmoid 非線性激活函數;
2)將編碼后的源域和目標域進行典型相關分析,根據共生數據特征可得到這兩個數據域之間的最大相關系數矩陣US(2)和UT(2)。利用最大相關系數矩陣可將源和目標域的共生數據特征映射到語義共享子空間中;
3)為了增強源域與目標域之間的相關性,需要對深度置信網絡模型參數進行優化。在深度置信網絡模型反向傳播過程中,即從目標域到源域的過程,使用矩陣US(2)和UT(2)對域網絡參數(US,bS,UT,bT)進行微調。
在圖3 所示的遷移學習模型中,目標函數的作用被設定為:1)最小化源域和目標域的重構誤差;2)最大化跨域深度網絡的相關性。因此目標函數的表達式為:
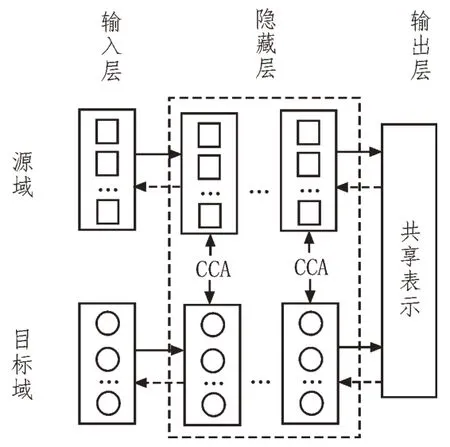
圖3 基于深度學習的異構遷移學習模型框架

上式中,HS(US,bS)、HT(UT,bT)分別表示為源域和目標域在編碼后,經過深度置信網絡訓練后的重構誤差。p與源域、目標域的最大相關系數矩陣VT、VS的投影向量有關,其代表兩者之間的相關匹配函數。利用最大相關系數矩陣的投影向量VT、VS,可進一步地將源域和目標域的共生數據最大化轉換為特征相關性最大化的問題。
目標函數中共有六種參數:WS、bS、WT、bT、VT、VS。若同時優化這六種參數,則會帶來極大的計算量。該文使用拉格朗日乘子與隨機梯度下降法分別對(WS、bS)、(WT、bT)和(VT、VS)進行優化。由于目標函數中(VT、VS)僅存在第三部分,因此可以給定源域和目標域的(WS、bS)、(WT、bT),對(VT、VS)進行拉格朗日轉換,即可求得VT和VS。而(WS、bS)、(WT、bT)的優化,則需要給定相關系數矩陣[VT,VS]。源域和目標域的優化過程相同,這里僅敘述源域的優化。在深度學習訓練反向傳播過程中,利用梯度下降算法對WS、bS進行調整,具體為:

以上兩式中,μS表示學習率。
3 測試與驗證
該文采用江蘇省某地區近三年的電力系統數據作為原始數據進行方案驗證,數據涉及電力行業數據和外部數據兩個部分。其中,電力行業數據涉及了項目合同主數據、項目執行過程數據和用戶評價數據等;外部數據涉及三年內氣象數據、當地經濟效益數據等。文中將這些數據隨機分成四種數據集對所提出的多源異構數據融合算法進行驗證。上述四種數據集中均含有1 000 個文本實例,每種實例使用不同語言描述。為了驗證該文所述算法的性能,將對照組算法設定為典型相關分析和深度匹配網絡兩種算法。實驗組和對照組均使用相同的硬件配置:英特爾酷睿i7-7500U 的處理器、2.70 GHz 的主頻、32 GB 的內存配置,軟件平臺則是使用Matlab。
圖4 展示了實驗組和兩種對照組算法在四種數據集作為訓練數據下的結果。從圖中可以看出,該文方案在四種數據集下的精度均優于典型相關分析和深度匹配網絡,平均精度分別高出8.32%和11.7%。這是因為文中所述的基于多源異構數據融合算法在本質上是面向域私有網絡和域共有網絡的深度語義匹配模型,通過將典型相關分析和深度學習網絡結合,可利用多層非線性轉換來挖掘多層特征結構。遷移學習的應用可彌補跨域數據實例的語義誤差,實現源域到目標域的知識遷移。
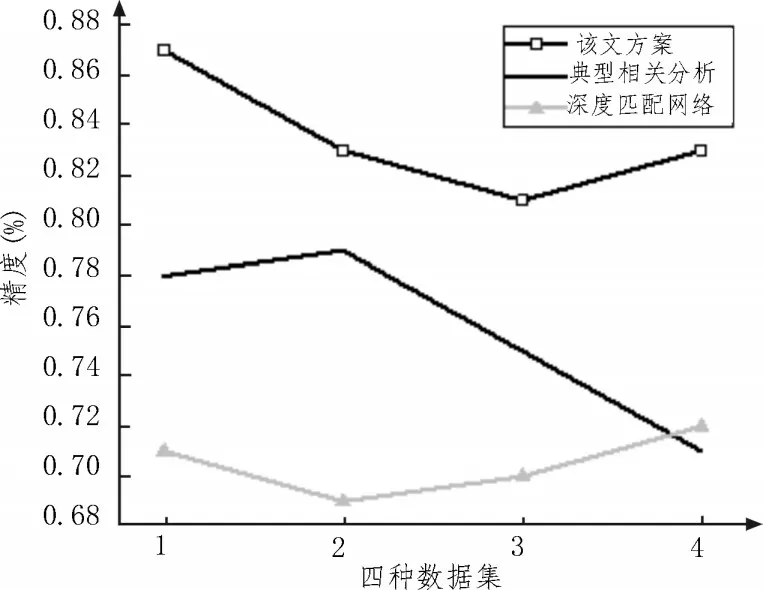
圖4 實驗組和對照組對比
圖5 分別展示了深度學習網絡中隱藏層層數和神經元個數對語義誤差的影響。從圖中可以看出,隨著隱藏層層數和神經元個數的增加,語義誤差均呈現出快速下降趨勢。值得注意的是,隨著隱藏層層數的增加,語義誤差下降的速度更快。且當神經元個數為50 時,語義誤差曲線基本趨于平穩,這表示結果已收斂。隱藏層層數和神經元個數的增加均有助于提高多層相關匹配效果,可有效彌補異構模態數據之間的語義偏差。
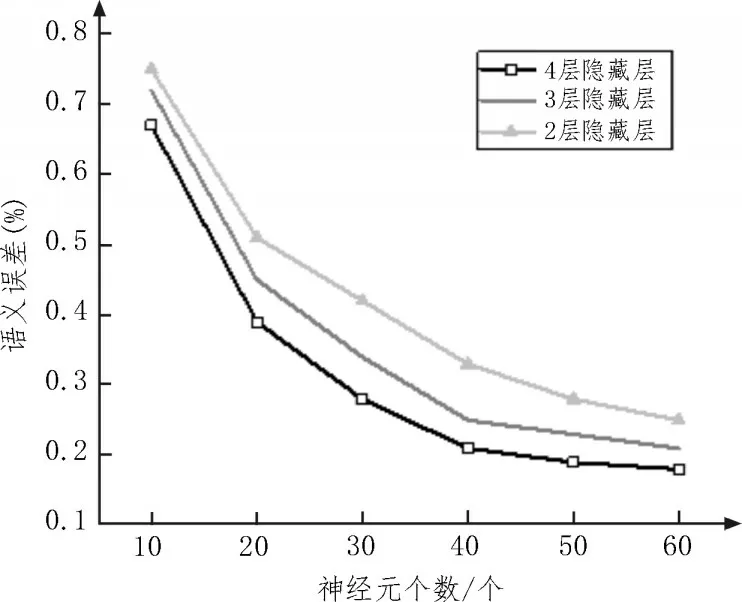
圖5 隱藏層層數和神經元個數對語義誤差的影響
4 結束語
該文采用知識圖譜將電力行業以及外部數據進行系統性整理,并將相關概念進行網絡化關聯,然后又將典型相關分析和深度學習網絡相結合,構建了一種多源異構數據的融合算法。測試和試驗結果表明,該文所述方案具有一定的可行性和優越性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
