基于預訓練語言模型的語法錯誤糾正方法
2022-12-01 08:04:56韓明月王英林
上海交通大學學報 2022年11期
韓明月, 王英林
(上海財經大學 信息管理與工程學院,上海 200433)
自數據集CoNLL13和CoNLL14[1-2]將語法錯誤糾正(GEC) 作為公開任務以來,語法錯誤自動糾正方法的相關研究工作大量涌現.GEC 任務的目標是對英語學習者所書寫的文本進行語法錯誤的自動識別與糾正.GEC系統可以給予英語學習者快速有效的寫作評估反饋,促進學生的自主學習,同時也可幫助教學者提高教學效率,避免教學資源浪費等問題.
傳統的GEC方案針對特定的錯誤類型,比如介詞錯誤、冠詞錯誤、主謂一致錯誤等,將GEC看作文本分類或序列標注問題[3],在糾正動詞形式錯誤、搭配有誤等具有無限候選的語法錯誤類型時存在局限性.為同時糾正所有類型的語法錯誤,現有相關工作主要分為兩個方向.一是將GEC看作標注問題[4-5],根據語法知識以及規則,人工構建一個囊括所有錯誤類型的標注體系,從而進行序列標注任務的學習.推斷時所有詞的標簽可同時生成,因此該方法具有推斷速度快的優勢.二是將GEC任務看作“翻譯”問題,翻譯模型將源語言翻譯成目標語言,GEC模型將英語學習者書寫的文本看作“源語言”,將糾正無誤的句子看作“目標語言”,從而通過序列到序列的生成方式處理所有類型的語法錯誤.本研究屬于第二個方向,需要在大規模的平行語料上訓練“翻譯”(糾正)系統[6-9],這意味著GEC系統將耗費昂貴的標注成本以及較高的訓練時間成本.在解決GEC任務低資源問題的方案中,較為常見的是通過增加噪聲以及“回譯”的方式人工合成平行語料[10-11],從而進行預訓練來改善模型的最終表現.然而,合成的語法錯誤與實際相差較大,如隨機插入、刪除、替換某個詞,且這些方案仍然依賴較長的訓練時間.
從BERT[12]和RoBERTa[13]等預訓練語言模型中獲取語言特征,可以廣泛應用于下游的自然語言處理相關任務,大幅度改善下游任務的表現.由于生成任務的自回歸特性,GEC、文本摘要、機器翻譯等自然語言生成任務在類似于BERT的預訓練語言模型上微調后的改善幅度有限.所以GEC任務與語言模型結合的常見案例大多是利用語言模型對GEC系統輸出進行語言分數排序,尚未充分利用自監督語言模型抽取的語言特征.對此,本文基于掩碼式序列到序列的預訓練語言生成模型(MASS)[14]來解決GEC問題,MASS以編碼-解碼為框架來重建原文本,適用于文本生成式的下游任務,利用MASS已提取的語言特征,在GEC的標注數據上微調模型,從而提出一種新的GEC系統(MASS-GEC),具體貢獻如下:① 從生成式的語言模型中遷移學習來解決GEC問題,在公開數據集上達到較好表現;②為GEC任務提供新視角,即通過預訓練生成式語言模型的運用來緩解GEC任務所面對的低資源問題,節省標注成本和訓練時間成本;③通過后處理的方式,利用無監督的主謂一致糾正模型來增強GEC系統的表現,并對本系統的各個模塊進行消融分析.
1 相關工作
1.1 GEC的低資源問題
近來的研究將GEC視為低資源的機器翻譯任務,盡管有一些公開的標注語料,如NUCLE[15]、Lang-8[16]、FCE[17]、Write&Improve組合LOCNESS[18]等,但由于較高的標注成本以及訓練翻譯模型的語料規模要求,這些標注數據仍有限.已有研究利用不同的策略人工合成平行語料,從而解決GEC的低資源問題.合成語料主要有兩種思路:① 參照機器翻譯的相關工作,利用回譯模型[19-20],促使模型學習到正確文本至語法錯誤文本的生成方式,應用在大規模正確的語料上,獲取人工合成的平行語料;② 通過引入噪聲[7]的方式擾動正確文本,從而獲取人工合成的平行語料,如對正確文本隨機增、刪、替[7],或從拼寫檢查工具所得到的混淆詞集來生成擾動等[11].利用以上方式人工合成的平行語料盡管可以改善GEC系統的表現,但是這些語法錯誤的分布仍與真實的語法錯誤分布存在較大差距,并且訓練時間長.
1.2 GEC與語言模型的結合
BERT[12]等預訓練語言模型能從大規模的語料中進行學習,根據上下文提取文本深層次的語言特征,在諸多下游的自然語言理解任務中有較好的表現.相對于GEC,BERT與語法錯誤識別 (GED) 的結合更為普遍,GED可被直觀地視為序列標注問題,從而直接作為BERT的下游任務.而GEC與預訓練語言模型的結合,更注重于通過語言模型對GEC系統輸出候選進行語言質量排序[8, 21-24].然而這些方式未充分利用到語言模型能從大規模語料中提取語言特征的能力.對此,以主框架是編碼-解碼結構的預訓練生成式語言模型MASS為基礎,利用遷移學習到的語言知識來解決GEC任務.
2 基于MASS的GEC系統
所提GEC系統以MASS在大量未標注的語料上通過特定語言學習目標進行訓練后的參數為初始參數,在GEC標注數據集上微調模型.參照已有工作,為GEC系統增加了預處理技巧和后處理技巧,以改善系統的表現,系統的整體流程如圖1所示.圖中:si(i=1, 2, …,m)為模型的輸入,即待糾錯的詞序列;ti(i=0, 1, …,n)為模型的輸出,即糾正后的詞序列;m,n分別為輸入序列和輸出序列的長度.
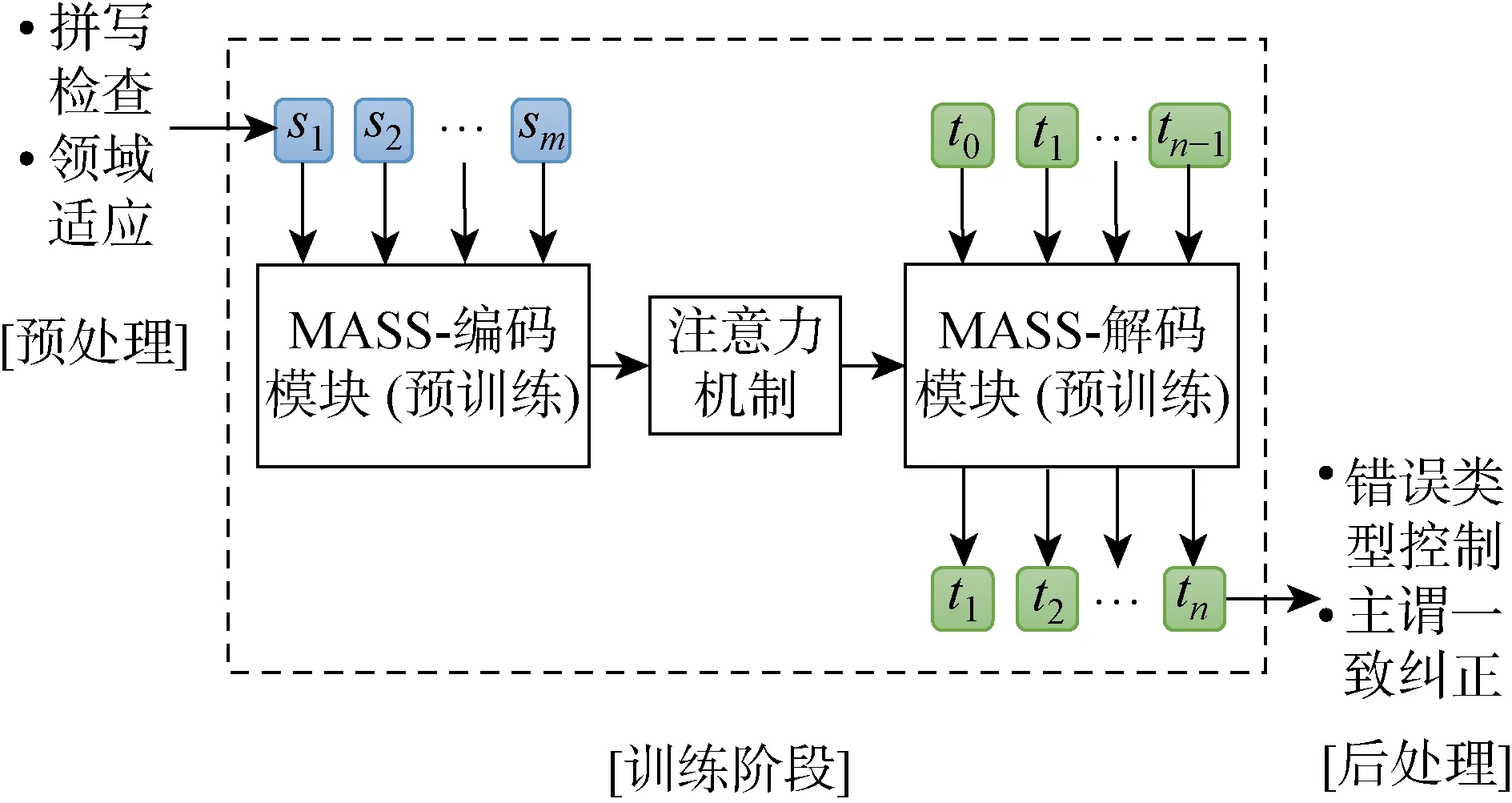
圖1 基于 MASS 的GEC系統整體框架Fig.1 Overview of grammatical error correction system based on MASS
2.1 MASS模型
與只訓練編碼或解碼的工作不同,Song等[14]提出的MASS預訓練語言生成模型能夠在大規模文本上同時訓練編碼和解碼結構,兼具語言理解和語言生成能力,適用于低資源的文本序列生成任務.
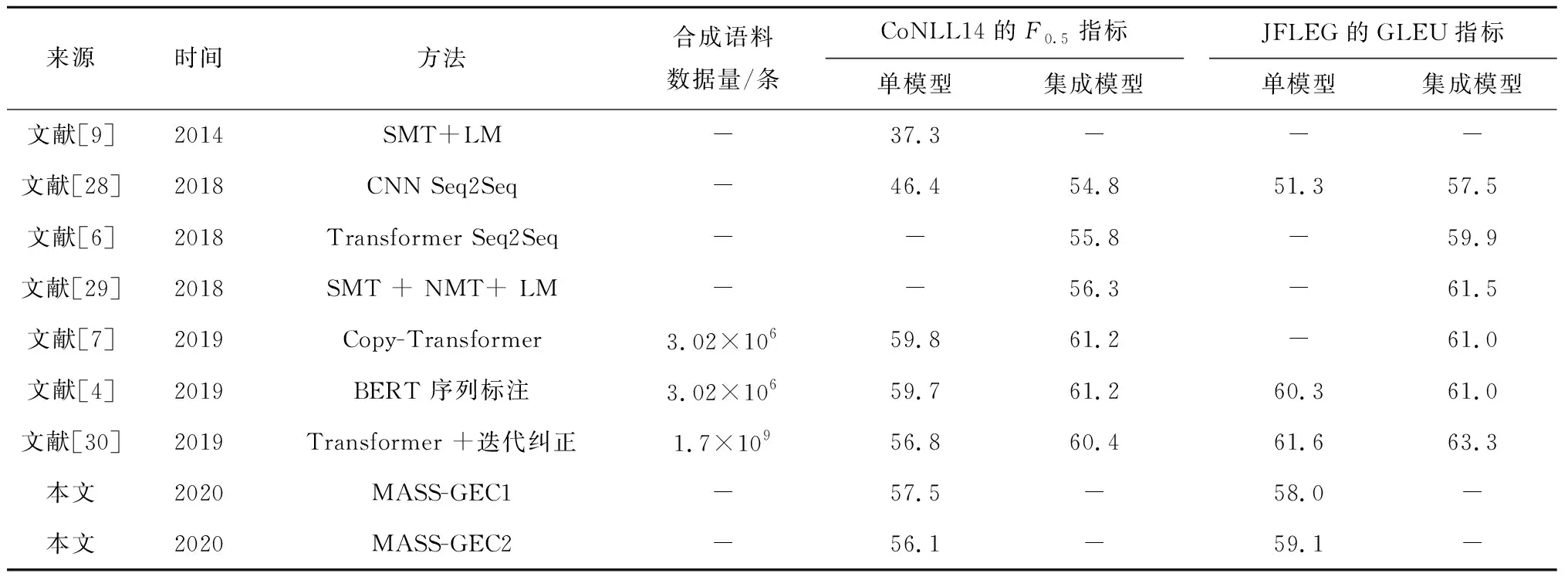
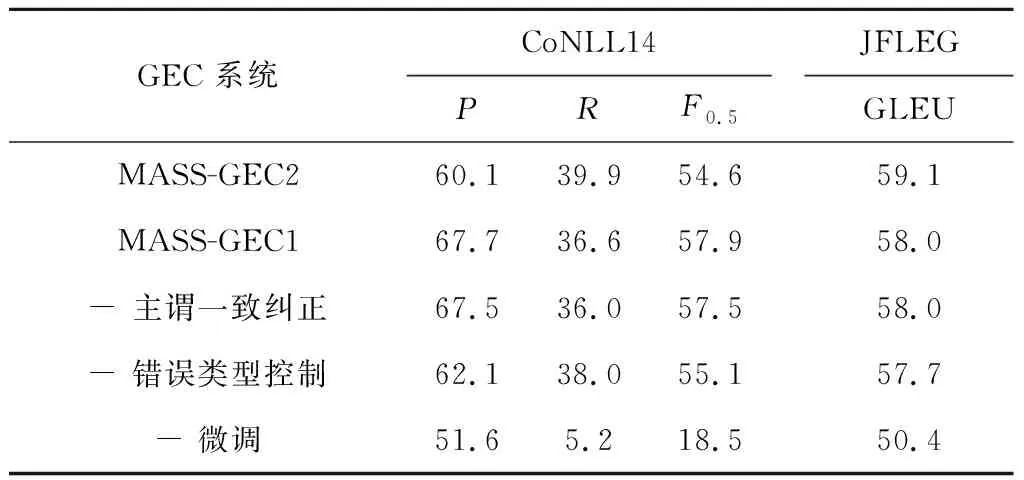
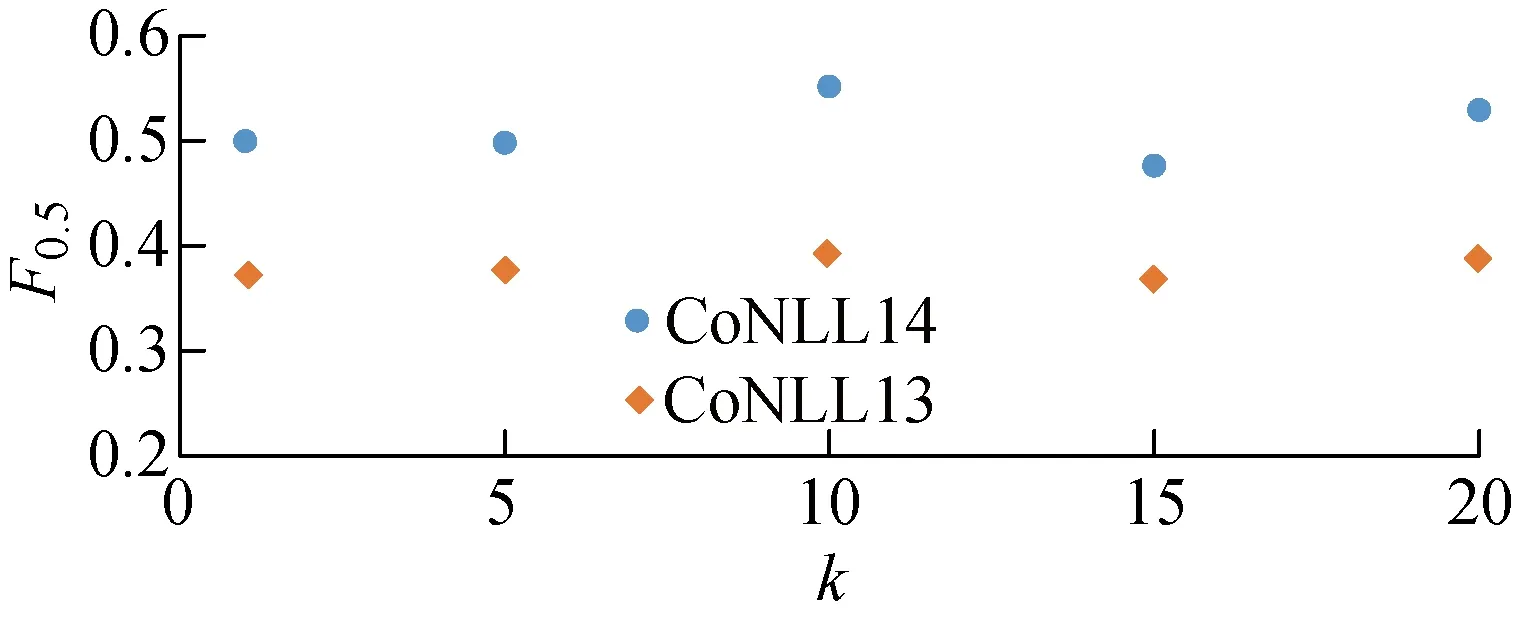
給定原句x∈X,xu:v表示將句子x從位置u到位置v的部分遮蓋住,其中 0 其中:θ為模型參數;P′為生成概率;t為當前生成詞的位置索引. MASS模型中的超參數k=v-u代表連續的遮蓋長度.當k=1時,MASS模型等價于BERT[12]模型;當k=l,即所有連續的遮蓋長度為句子長度時,MASS模型等價于GPT模型.由此也可推斷MASS模型同時具有語言理解和生成能力,適用于本文GEC任務.因此提出MASS-GEC系統,充分利用MASS在大規模語料中所學習到的語言特征提取能力,來解決GEC任務. 首先,若直接將可能包含語法錯誤的原始文本輸入模型,則出現拼寫錯誤的單詞會被映射為“UNK”,喪失部分信息.如果利用拼寫檢查技術先對原始文本進行拼寫檢查則可以避免此類問題.因此,在輸入模型之前,使用一個基于上下文感知的拼寫錯誤糾正模型[25]對輸入文本進行拼寫檢查;此外,評估的測試集CoNLL14與標注語料NUCLE領域匹配,參考文獻[6],將NUCLE標注語料進行復制以增強MASS-GEC模型在CoNLL14數據集上的表現. 后處理技巧被廣泛應用于GEC模型,如移除一句話中超過一定數目的編輯以及對不同編輯進行組合選擇語言模型上表現最好的編輯組合作為最終的編輯修正結果等.參照Choe等[25]的工作,將訓練好的GEC模型在開發集上進行驗證,分別記錄不同錯誤類型的糾正效果,測試時,選擇放棄該模型表現較差的錯誤類型.對于預測的文本,采用ERRANT (https:∥github.com/chrisjbryant/errant) 工具獲得不同錯誤類型的糾正效果. 主謂一致錯誤、介詞錯誤等特定類型的語法錯誤頻繁出現在英語學習者的寫作文本中,并且很容易通過人工合成的方式生成質量較高且較為符合實際情況的語法錯誤,不需要任何標注成本.因此,對MASS-GEC系統的糾正輸出進行主謂一致糾正. 在合成標注數據時,以0.3的概率隨機將一個詞性為“VBZ”或“VBP”的動詞改為與其相反的動詞單復數形式,每個單詞的標簽代表對應位置單詞的主謂一致識別結果,標簽集合為{0,1,2},其中“0”代表該位置的單詞沒有主謂一致錯誤,“1”代表該位置的動詞應該被改成第三人稱單數形式,“2”代表該位置的動詞應該被改成復數形式.由此,將主謂一致糾正看成序列標注問題,使用BERT與BILSTM的組合框架,在Europaral-v6.en數據集(約28萬條數據)上訓練3輪,將預測標簽根據一定的語法規則轉換成糾正后的結果.這里使用的詞性標注工具和詞干化工具均來自NLTK (http: ∥www.nltk.org/)語料庫.在CoNLL14測試集上,修正除主謂一致外的其他錯誤后,評估所提出的主謂一致糾正模型結果為F0.5=65.4,F0.5是常用于強調查準率的分類系統的評估指標,此結果優于當前GEC模型的最佳表現(可看作所有語法錯誤類型的平均表現),一定程度上證明了通過主謂一致糾正后處理來改善GEC系統表現的可能性. 在兩個公開的GEC任務上測試MASS-GEC模型表現,分別是: (1) CoNLL14[2].該任務針對于英語學習者的寫作文本進行語法錯誤的識別與糾正,相較于只處理5種語法錯誤的CoNLL13任務,CoNLL14涵蓋了28種語法錯誤類型,增加了任務的復雜性.評價指標是GEC系統提出的糾正編輯與黃金編輯的匹配情況,模型表現用F0.5來衡量,這意味著對GEC系統的評估更側重于查準率. (2) JFLEG[26].在GEC的任務中,JFLEG更關注語言的流利程度.評估標準是GLEU,類似于機器翻譯中的BLEU,是基于系統輸出糾正結果與參考糾正結果n元語法重疊度的評估指標. 對于GEC任務,使用的標注數據集及數據量為NUCLE (5.72萬條)、 Lang-8 (104萬條)和FCE (3.32萬條).參考文獻[6],將NUCLE數據集復制10倍,放入訓練集中以進行領域適應,最后去除未進行任何語法錯誤修改的樣本.最終使用的訓練集大小約為82.6 萬條數據,分別使用JFLEG-dev和CoNLL13作為兩個測試任務的開發集,以進行模型以及超參數的選擇. 訓練中使用預訓練的生成式語言模型MASS (https:∥github.com/microsoft/MASS) 作為基準模型,代碼使用fairseq的序列到序列框架 (https:∥github.com/facebookresearch/fairseq)執行,詞向量和隱藏層維度均為768,編碼模塊和解碼模塊均為6層12頭的注意力,詞典和BERT保持一致.使用Adam算法優化模型,預熱步數為 4 000,批量處理的單位為64,學習率為 0.000 5,每個實驗訓練10輪,選擇在開發集上表現效果最好的1輪模型作為最終的模型. 實驗結果顯示,最終確定的模型結果來自第1輪或者第2輪,這說明在MASS強大的語言特征提取的前提下,只需要在GEC數據集上微調即可得到較為滿意的GEC模型.實驗中使用MASS提供的預訓練模型的小參數量版本和大參數量版本進行微調,分別命名為MASS-GEC1和MASS-GEC2.將MASS-GEC1系統表現與已有工作進行對比,結果如表1所示.特別地,額外使用由Bryant等[18]于2019年提出的W&I標注數據集來進行訓練的GEC系統[5, 26-27]在CoNLL14數據集上表現為當前最佳,為了與已有工作公平對比,本文沒有增加該標注數據集進行訓練.由表1可知,MASS-GEC1在GEC任務中表現不錯.作為單個模型,MASS-GEC1在CoNLL14數據集上F0.5值達到57.5,遠遠高于2014年公開任務提交系統中的最佳表現.當前表現最好的單個模型是由Zhao等[7]于2019年提出的Copy-Transformer,考慮到GEC是一個特殊的“翻譯問題”,即目標序列中的詞和源序列中的詞在很大程度上重復,該模型在預測每個位置時,結合復制概率以及序列到序列模型的預測分布來確定最終的預測結果.相較于Copy-Transformer MASS-GEC1在F0.5指標上低2.3%.然而,本文沒有使用大規模人工合成語料 (約 3 000 萬條) 進行預訓練,因此擁有一定的訓練時長優勢. 表1 不同的GEC系統結果對比Tab.1 Comparison of results of different grammatical error correction systems MASS-GEC2在JFLEG測試集上的GLEU指標達到59.1,在未使用合成語料預訓練的單個GEC模型上實現了效果的提升.值得注意的是,不同規模的MASS模型在兩個任務上的表現有差別,MASS-GEC2模型在JFLEG上表現優于MASS-GEC1,而在CoNLL14數據集上則相反,這可能是JFLEG任務更注重流利程度,更大的模型框架可以捕捉更深層次的語義,因此更適用于JFLEG任務. 消融實驗結果如表2所示,表中:P為查準率;R為查全率.表中帶“-”的模型含義是在前一行的基礎上去掉本行的模塊,最后一行的結果代表拼寫檢查在兩個數據集上的表現.使用標注語料在MASS模型上微調之后,模型在CoNLL14上的F0.5=55.1,在JFLEG上的GLEU 為57.7.如果使用錯誤類型控制,移除在開發集上糾正效果較差的錯誤類型,則F0.5能提升2.4%,而GLEU提升不明顯.主謂一致糾正后處理在兩個任務上的改善作用均不明顯,這可能是由于當前的GEC已然具有較好的主謂一致糾正能力,或者主謂一致糾正處理影響了原來GEC系統正確的糾正預測. 表2 MASS-GEC系統的消融實驗結果Tab.2 Results of ablation experiment on MASS-GEC NUCLE標注語料與CoNLL14任務的領域相匹配,參考文獻[6],對訓練數據集進行調整,將NUCLE語料復制k(k∈{1,5,10,15,20}) 倍,觀察模型的表現,結果如圖2所示.GEC系統在k=10 時表現最佳,當k繼續增大時,模型表現變差,推測當k>10 時,模型對NUCLE語料存在過擬合.因此,在實驗部分令超參數k=10. 圖2 不同領域適應規模下MASS-GEC系統的表現Fig.2 Performance of MASS-GEC system with regard to different domain adaption sizes 將GEC看作低資源的文本生成任務,基于預訓練語言模型MASS提出MASS-GEC系統,在公開數據集上達到較好的效果.研究結果為GEC任務提供新的視角,即在不進行大規模合成語料預訓練的情況下,通過生成式語言模型的運用來緩解GEC任務所面對的低資源問題.此外,通過后處理的方式,用錯誤類型控制以及無監督的主謂一致糾正模型來增強GEC系統的表現,并對本系統的各個模塊進行消融分析.未來將著眼于GEC的解釋維度,考慮結合反事實自動生成模型,為主謂一致等特定類型的語法錯誤提供系統生成的解釋,有利于進一步提升英語學習者的自主學習效率.2.2 拼寫檢查與領域適應
2.3 錯誤類型控制
2.4 主謂一致糾正
3 GEC實驗
3.1 數據集
3.2 訓練過程及參數設置
4 實驗結果及分析
4.1 GEC結果
4.2 消融實驗結果分析
4.3 不同規模的領域調整結果分析
5 結語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2020年4期)2020-05-30 12:35:30
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
