
基于測井資料與優化通用向量機的煤層氣含量預測模型
2022-12-01 08:53:20丁海琨張占松郭建宏譚辰陽周雪晴朱林奇
煤礦安全 2022年11期
關鍵詞:模型
陳 濤,丁海琨,張占松,郭建宏,譚辰陽,周雪晴,朱林奇
(1.長江大學 油氣資源與勘探技術教育部重點實驗室,湖北 武漢 430100;2.長江大學 地球物理與石油資源學院,湖北 武漢 430100;3.中國石油測井公司國際合作處,陜西 西安 710077;4.中國科學院深海科學與工程研究所,海南 三亞 572000)
煤層含氣量是煤儲層評價研究的關鍵參數之一,是煤層產能評價、生產布局及資源挖潛的關鍵所在。而煤層含氣量受成藏地質構造、地質水文特征、煤變程度、煤質工業組分、煤層有效埋深和凈厚度、儲層壓力及滲透率、煤層頂底板巖性及厚度等眾多因素的影響[1-3],是眾多因素耦合作用的產物。目前,對煤儲層含氣量的定量評價大致可分為數值模擬[4-7]、基于測井參數[8-11]和實驗組分[12-14]及地震屬性[15-16]的單參變量或多參變量線性回歸預測法、參數井繩索取心現場解吸測試和人工智能4 大類。然而,參數井繩索取心法費用成本高難以實現;線性回歸法對于非均質性極強的煤儲層難以實現高精度評價;由于三相態含氣量數值模擬技術亟待突破,數值模擬很難實現生產精細評價。近年來,基于機器學習和深度學習的方法越來越多地應用到非均質性極強的非常規儲層參數評價中,用于挖掘數據隱藏的非線性關系,如循環神經網絡、BP 神經網絡、SVM 神經網絡、決策樹、長短期記憶網絡及融合智能算法等[17-21],研究表明,這些技術的引入對煤層含氣量預測的可信度及可靠性較好。然而,BP 神經網絡對樣本量有一定要求,且受參數影響大,導致訓練復雜性大,局限性明顯;隨機森林抗干擾能力較強,在處理特征遺失及不均衡數據時泛化性好,但對超出訓練集數據鄰域的樣本會出現預測盲區,很可能使在進行建模時某些高頻噪聲的樣本出現過擬合影響模型泛化性;支持向量機無需復雜的拓撲結構,對小樣本適應強,具有很強的魯棒性,但受噪聲樣本影響較大。而采用通用向量機[22](GVM)算法作為核心建模技術,很大程度上平衡了上述問題;有研究表明:在少量訓練樣本甚至缺失訓練樣本的情況下,訓練出來的回歸模型仍然具有良好的魯棒性和泛化性[22-23]。為此,基于煤層含氣量測井響應相關性結合地球物理理論進行曲線重構,再通過對Elastic Net 方法添加正則化項施加懲罰來選取敏感特征變量,解決多重共線性問題和冗余參數;提出用改進的量子粒子群優化算法(IQPSO)對GVM 模型關鍵參數進行尋優,最優化處理建模的每個關鍵環節進而使模型整體性能提升,以此構建泛化性好、強魯棒性的煤層含氣量高精度預測模型,并用實際區塊數據驗證方法的適應性和有效性。
1 煤層含氣性測井響應分析
1.1 數據來源
研究數據來自華北沁水煤田東南部柿莊南區塊3 號煤層,是目前勘探開發的熱點地區。由于受地質構造、聚煤沉積環境、水文地質條件、煤層氣成因及來源的差異性響應,儲層平面非均質性極強,含氣量測井響應特征復雜,高精度評價難度大[24]。樣品源于勘探區12 口關鍵井280 組有效煤心樣品深度部分。樣品含氣量及常規測井響應數據(部分)見表1。

表1 樣品含氣量及常規測井響應數據(部分)Table 1 CBM content of samples and conventional logging data(part)
1.2 含氣量與測井參數之間相關性分析
研究表明,煤層含氣量與有機質和無機質2 種單一組分的相對豐度存在函數關系,有機質含量在某一特定地區保持相對穩定,而無機組分在區塊內會發生顯著的橫向和縱向變化,并表現為測井響應的差異性。測井的縱向分辨率相對較高,不同儲層蘊含復雜的地質儲層信息,煤層含氣量響應具有特殊性及復雜性。煤層含氣量與測井參數交會圖如圖1。
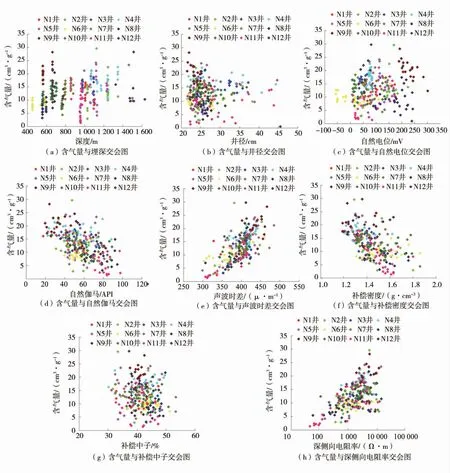
圖1 煤層含氣量與測井參數交會圖Fig.1 Cross plot of coal seam gas content and logging parameters
煤層含氣量根本影響因素是煤變程度。理論上,煤層埋深一定程度上影響烴熱分解能力,同時很大程度上決定了煤層氣的封堵條件,淺煤層含氣量隨埋深增加而升高,當埋深達到某一臨界深度后,受地質構造、后期的封閉條件及聚煤沉積環境等影響含氣量解吸緩慢甚至出現降低趨勢,可見煤巖埋深對含氣量評價是受研究區地質因素影響較大的不穩定變量。井徑曲線主要反映地層的脆性指數及機械強度,與煤巖類型緊密相關,煤層含氣后對煤巖類型影響甚微,即含氣量對井徑曲線敏感性較弱。煤巖是電阻率較高的非導電介質,擴散和吸附作用產生自然電位,其本身與含氣量敏感性較弱,但自然電位異常幅度很大程度上取決于黏土含量、泥漿濾液及煤巖厚度等影響,一定程度上表現為含氣量的差異性。煤巖骨架自身放射性較低,其放射性取決于成煤過程吸附的黏土礦物等外來礦物,一方面黏土礦物含量越高,對應煤巖有效孔隙空間就越少,含氣量就越低,同時黏土吸附削弱了煤巖的吸附能力,降低了其比表面積,致使煤層含氣量一定程度上降低。聲波時差可反映煤巖的抗壓強度和致密程度,含氣后聲波能量嚴重衰減,表現為聲波時差明顯增大甚至出現“周波跳躍”現象,聲波時差對含氣量較敏感。煤本身基質密度較低,理論上其密度響應值與煤層致密程度緊密相關,煤層越致密其孔隙空間越小,含氣量也就越小,實際上受擴徑及黏土含量影響單井表現往往并不是這樣,甚至出現相反的的趨勢。補償中子反映煤儲層的含氫指數,理論上含氣量越高中子測井值衰減越劇烈,補償中子越小,但受擴徑、泥餅、泥質及炭質夾矸等一系列因素影響較大,單井有時表現并不明顯。煤層電阻率很大,但電阻率響應值還受煤巖厚度、井眼尺寸、泥漿侵入、孔隙填充及夾矸等較多因素影響,研究區總體上煤層含氣量與深側向電阻率呈正相關。
綜上分析,研究區煤儲層雙重孔隙結構、強儲層非均質性導致煤層含氣量與測井參數響應極為復雜,為充分挖掘測井響應特征蘊含的儲層信息,提高含氣量評價精度,根據測井原理結合其對含氣性的響應特征分析,計算了9 個衍生參數,分別為復合參數M 和N、三孔隙度差比值C 和B、自然電位幅度差值△SP、雙電阻率差比值△lg(R)和Ra 及雙電阻率對數值lg(RD)和lg(RS),計算公式為:

式中:GR 為自然伽馬,API;DEN 為補償密度,g/cm3;RD 為深側向電阻率,Ω·m;AC 為聲波時差,μs/m;CNL 為補償中子,%;SP 為自然電位,mV;SSP為靜自然電位,一般取泥巖基線值,mV;RS 為淺側向電阻率,Ω·m。
計算含氣量及測井以及其衍生參數之間的Pearson 相關系數,但Pearson 相關系數往往偏重于線性相關程度而忽略了含氣量與測井參數之間的非線性關系。含氣量與測井及其衍生參數相關性熱圖如圖2。由圖2 可知,各測井參數之間存在多重共線性,會降低模型穩定性,且冗余信息很大程度上給模型帶來噪聲干擾,難以進行含氣量高精度評價,因此特征變量的選取非常有必要。

圖2 含氣量與測井及其衍生參數相關性熱圖Fig.2 Heat diagram of correlation between gas content and conventional logging parameters
2 建模方法理論
為充分挖掘儲層信息并解決多重共線性問題,研究引入適合GVM 神經網絡建模的Elastic Net 分析方法優選建模特征變量,并針對GVM 模型參數進行優化建立穩健的含氣量預測模型。
2.1 Elastic Net 特征變量選擇
彈性網絡(Elastic Net,EN)是2005 年由ZouH[25]等在研究嶺回歸(RR)和拉索回歸(LASSO)理論基礎上提出的一種新魯棒正則化方法。式(8)為ElasticNet 方法代價函數懲罰項,其將拉索回歸和嶺回歸懲罰項加權組合。該方法繼承LASSO 回歸的稀疏性的同時很好地解決了共線性問題。Elastic Net 方法被證實具備很好群組效應和稀疏性,對異常值及重尾誤差具有很好的魯棒性,尤其適用于小樣本數據變量篩選。
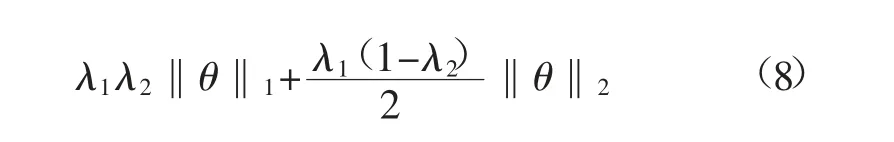
式中:λ1為懲罰項相對于擬合錯誤的重要程度,大于0;λ2為2 種范數正則化的比例,取0~1;‖θ‖1為L1正則化;‖θ‖2為L2正則化。
2.2 通用向量機(GVM)
通用向量機(GVM)模型是廈門大學趙鴻教授在2016 年基于蒙特卡羅(Monte Carlo,MC)算法提出來的一種機器學習新方法[22]。該模型結合BP 神經網絡的經驗風險最小化策略和支持向量機(SVM)的經驗風險最小化策略,采用MC 算法調整模型權值直至獲得最優模型。該模型被證實具有很好的泛化能力,對小樣本具有良好的預測效果,且模型對單個樣本的微小波動具有更強的魯棒性,模型抗噪聲干擾能力強。
GVM 模型主要超參數為隱含層節點數和敏感度控制參數β,通過將β 控制在一定范圍內就可以使模型對輸入向量的微小波動保持強魯棒性,這樣就可以用更多的隱藏層節點增強模型泛化能力的同時有效抑制過擬合。同時采用鏡面對稱思想固定輸出權值矩陣W2,通過基于權值偏導數的蒙特卡羅(Derivative Monte Carlo,DMC)算法[23]來調整權值Wβ、W1和Wb,優化模型,減小式(9)代價函數使得模型整體逐步收斂到穩定最優解。

式中:COST 為代價函數;RMSE 為均方根誤差;N 為樣本個數。
2.3 改進的量子粒子群算法(IQPSO)
GVM 模型性能取決于權值向量、偏置向量及控制向量。蒙特卡羅算法優化GVM 網絡參數采用單步變異方式,1 次僅優化1 個權值,且隱含層節點數同條件下一般來說至少10 倍于BP 神經網絡,是以犧牲訓練時長和模型收斂速度來增強模型的魯棒性與穩定性。本質上來講,優化GVM 模型網絡參數就是搜索最優網絡參數使得式(9)取得最小極值。PSO算法就是解決此類問題行之有效的經典方法。
PSO 算法是由Eberhart 等[26]于1995 年模擬鳥群覓食行為提出的一種全局最優化算法,因其簡單可行、收斂快、穩健性好等優點被廣泛應用于各領域最優化問題中。但該算法星環狀結構信息交互方式導致搜索尋優過程中由于其種群多樣性自進化消失快而過早收斂,在解決形如式(9)這種多局部極值問題中很難跳出局部最優。基于此,將量子比特系統引入粒子群算法,并根據代價函數動態調整比特量子旋轉角和交叉變異概率對量子粒子群算法[27](QPSO)進行改進提出一種新的量子粒子群算法,使得粒子以更大概率跳出局部最優同時兼顧泛化及求精能力。
綜上,利用Elastic Net 方法優選建模特征變量,針對研究所用小樣本不均衡數據選擇具有優勢的GVM 網絡建立神經網絡模型,考慮到GVM 模型存在的缺陷及粒子群算法(PSO)參數尋優對本研究適應性差,提出了改進的量子粒子群算法對決定模型性能的關鍵控制參數進行全局優化,通過此三者緊密聯合構建高精度、強魯棒性和穩定性的煤層含氣量預測模型。
3 模型構建及性能分析
3.1 模型構建
3.1.1 特征參數選取
根據Elastic Net 方法,在進行變量篩選前對數據做標準化處理,消除特征參數間的差異性,避免因此導致特征丟失。由式(8)可知,EN 特征篩選2個核心參數為正則化參數λ1(λ1>0)和權重調節系數λ2(0<λ2<1)。為獲得最佳Elastic Net 參數,在python平臺Elastic NetCV 模塊中,先將數據隨機等分為3組,網格搜索采用3 折交叉驗證確定最佳權重調節系數為λ2=0.32,再根據均方差MSE 隨不同懲罰系數的變化曲線基于最小MSE 準則確定正則化參數λ1。3 折交叉驗證下不同正則化參數MSE 變化曲線(λ2=0.32)如圖3,最佳正則化系數為λ1=0.58。
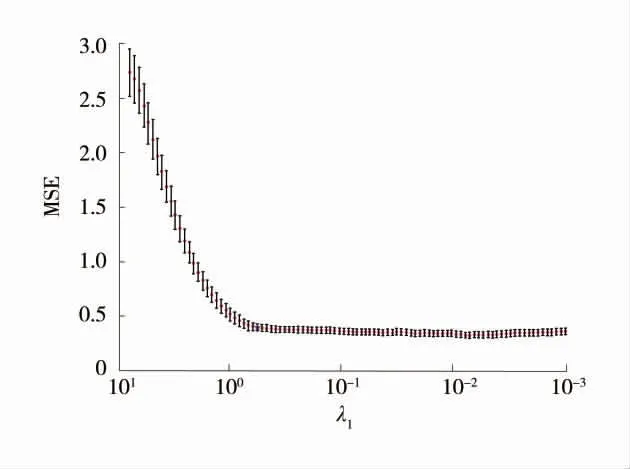
圖3 3 折交叉驗證下不同正則化參數MSE 變化曲線(λ2=0.32)Fig.3 MSE variation curves of different penalty coefficients under 3-fold cross validation(λ2=0.32)
基于所選最佳EN 方法系數(λ2=0.32,λ1=0.58),EN 方法通過最小角回歸算法(Least Angle Regression, LAR)迭代計算19 個測井及其衍生參數稀疏系數[27],將稀疏系數為0 的冗余變量濾除即為特征參數,該方法降維的同時很好地解決了多重共線性問題。特征參數貢獻率如圖4。
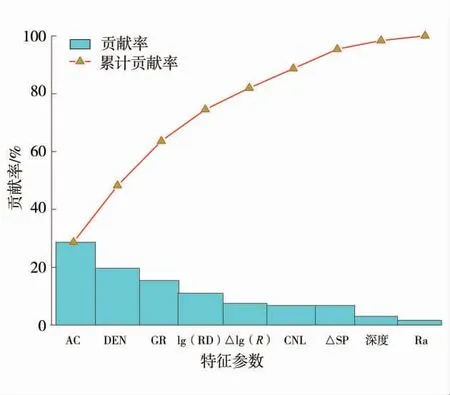
圖4 特征參數貢獻率Fig.4 Contribution rate of characteristic parameters
由圖4 可知,AC、DEN、GR、lg(RD)、CNL、△lg(R)、△SP 7 個參數對模型精度總貢獻率達到95.38%,因此選取這7 個參數作為GVM 模型的優選特征。
3.1.2 網絡結構確定
在進行GVM 模型權值向量、偏置向量及控制向量尋優前首先要確定模型結構,即要確定隱藏層節點個數。隱藏層節點個數對模型性能的影響如圖5,MAPE 為平均絕對百分比誤差,表征模型偏差程度。隨著隱藏層節點個數的增加,模型精度越來越好,模型訓練時長開始緩慢增加,當隱藏層節點數超過105 時,模型性能反而下降,精度開始降低,且訓練時長急劇增長。基于以上分析,隱藏層節點數為105。
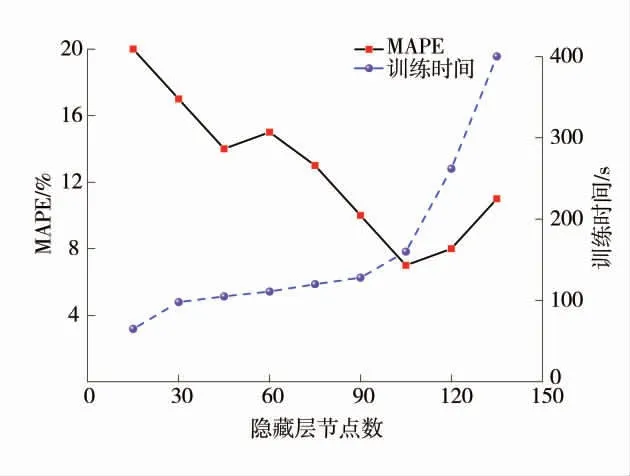
圖5 隱藏層節點個數對模型性能的影響Fig.5 Contribution rate of characteristic parameters
一般來說,GVM 模型要求激活函數f 滿足非線性、有界性和連續性。考慮一般情況,利用先驗樣本數據特征對GVM 模型常見3 種傳遞函數性能進行模擬對比,不同傳遞函數運算效率對比如圖6。由圖6 可知,對于特征空間3 種傳遞函數都具有可行性,相對而言tanh 函數運行效率高且對DMC 算法來說其參數變異區間較廣,容錯率較高。因此將tanh 函數作為GVM 模型的傳遞函數。
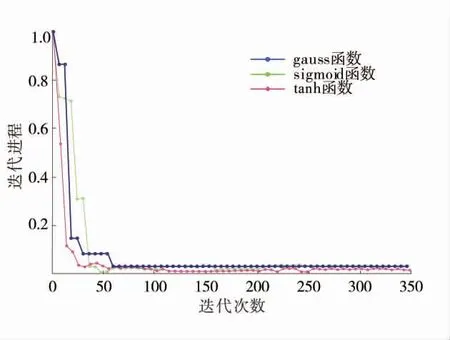
圖6 不同傳遞函數運算效率對比Fig.6 Contribution rate of characteristic parameters
3.1.3 網絡參數優化
利用IQPSO 算法優化GVM 網絡參數,每個量子粒子代表1 組GVM 網絡參數(Wβ、W1和Wb),將式(9)作為IQPSO 算法的適應度函數。GVM 參數尋優圖如圖7。
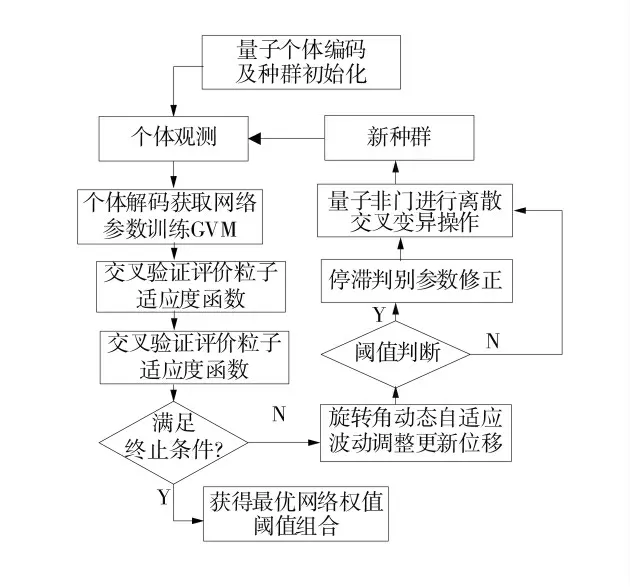
圖7 GVM 參數尋優圖Fig.7 GVM parameter optimization diagram
算法具體流程步驟如下:
步驟1:初始化。利用式(10)量子比特編碼每個粒子qi,并初始化參數,IQPSO 初始化參數見表2。包括種群規模N,最大進化代數Imax,停滯判別參數ω,交叉驗證誤差判別閾值ε,量子門旋轉角范圍[θmin,θmax],變異概率范圍[pmmin,pmmax]。
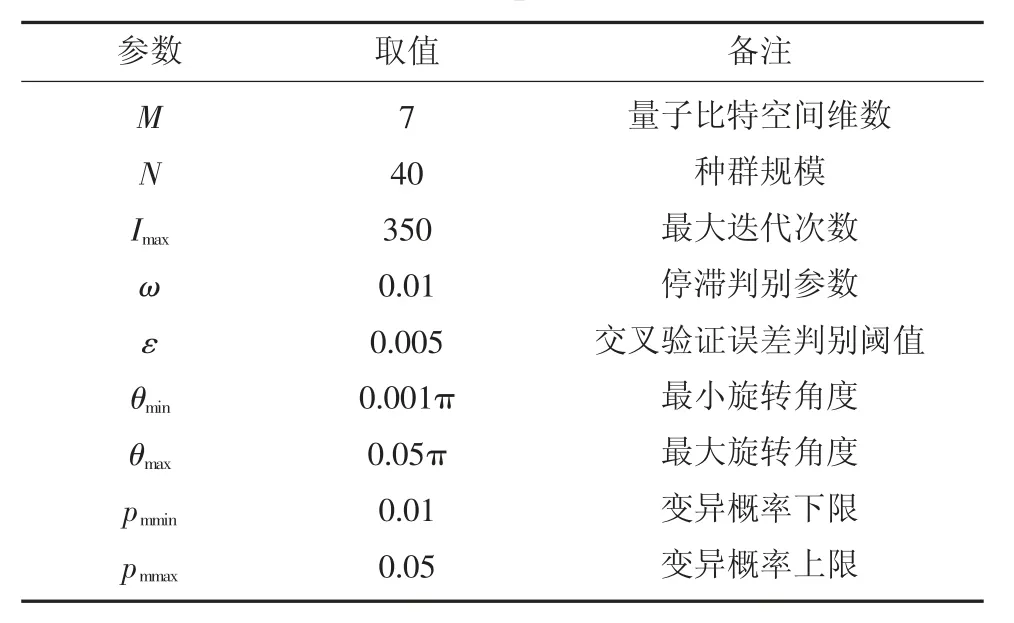
表2 IQPSO 初始化參數Table 2 Initialization parameters of IQPSO
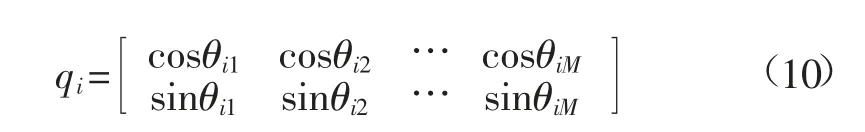
式中:[cosθij,sinθij]T為1 個量子比特;M 為量子比特空間維數;θ 為量子粒子相位。
步驟2:隨機觀測每個粒子生成二進制解并進行解空間轉換。
步驟3:采用3 折交叉驗證評價每個粒子適應度函數,保存全局最優解Pg=(pg1,pg2,…,pgM)和當前每個粒子的局部最優解PL=(pL1,pL2,…,pLM)。并判斷交叉驗證誤差判別閾值ε 和最大進化代數Imax,若滿足則進行步驟4,否則進行步驟6。
步驟4:采用二進制引力搜索算法[28]量子旋轉門策略結合式(10)更新量子相位向量θi=(θi1,θi2,…,θiM),進而更新個體位移。
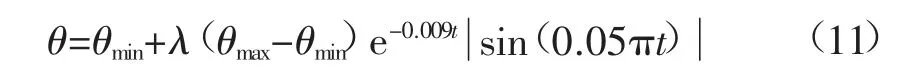
式中:λ 為控制θ 調整幅度的常量,經反復實驗模擬取值e0.036效果最佳;t 為時間。
采用式(11)符合θ“粗中有細”的調整策略,有效提高模型性能同時平衡其泛化能力。
步驟5:停滯參數ω 判斷,若滿足則利用量子非門進行離散交叉變異操作更新進化種群使粒子以更大概率快速跳出局部極值。
步驟6:在IQPSO 算法優化基礎上,執行GVM模型DMC 加速變異算法進一步提升模型全局尋優能力,直至達到算法停止條件輸出最優解。
3.2 模型性能
為驗證改進策略,基于上述優選的7 個特征測井參數分別用MC 算法、DMC 算法、PSO 尋優策略及本文方法優化GVM 網絡參數建立煤層含氣量預測模型。建模過程將280 組樣本數據隨機等分為4組,1 組作為測試集不參與建模驗證模型泛化性,其余3 組進行3 折交叉驗證用于確定模型參數。對建模集(訓練集和驗證集)和測試集進行測試對比,用3 次交叉驗證平均均方根誤差和擬合優度衡量模型整體性能,并對各模型進行測試對比,各算法適應度函數收斂曲線如圖8。
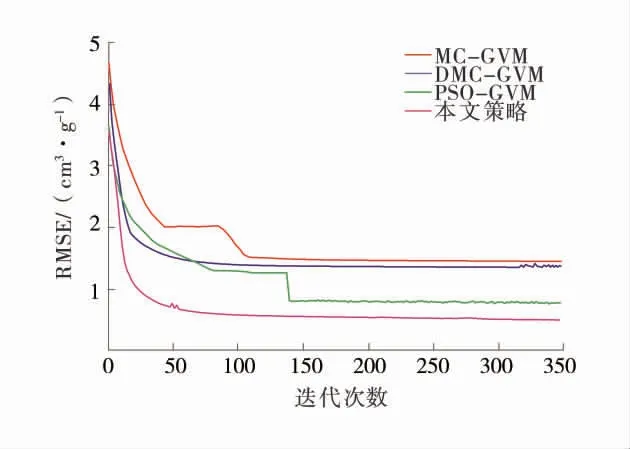
圖8 各算法適應度函數收斂曲線Fig.8 Convergence curves of fitness function of each algorithm
由圖8 可知,在其他條件相同的情況下,尋優策略其尋優能力優于其它3 種方法,而在收斂速度上DMC 算法是最快的。同時還可看出,MC 算法和DMC 算法盡管收斂速度稍快,但對于研究目標函數全局尋優能力較差,收斂精度稍差,PSO 算法盡管一定程度上增強了全局尋優能力,還是陷入了局部最優值。而尋優策略,雖多次早熟收斂,但隨著迭代次數增加逐步收斂并在后收斂到全局最優達到不錯的收斂精度。由此可見,結合IQPSO 和DMC 算法的GVM 網絡參數尋優策略雖然在收斂速度上略有損失,但極大提升了模型精度。
通過擬合優度、均方根誤差、平均絕對百分比誤差和相對分析誤差4 個指標,可以綜合全面地評估模型性能。各評價模型的預測精度評價指標見表3。
由表3 結果可見,不論是訓練集還是驗證集,IQPSO 算法優化策略GVM 模型預測精度均優于其他3 種方法。可見采用的GVM 網絡核心參數優化策略可有效改善模型性能,提高模型預測精度。同時測試集可以看出,訓練得到的模型其測試集平均均方根誤差為0.648,平均絕對百分比誤差8.69%,相對分析誤差3.23,相對其他3 種方法均有大大的提升,說明該算法泛化性強,能有效抑制過擬合。

表3 各評價模型的預測精度評價指標Table 3 Evaluation index of prediction precision of each model
GVM 模型集BP 神經網絡模型和SVM 模型優點于一體,為驗證模型對所研究問題的有效性及驗證模型的魯棒性,將本文模型、基于本文優化策略的7×9×1 結構的BP 神經網絡模型和SVM 模型及傳統多元回歸法對研究區同一盲井3 號層進行含氣量預測,A13 井3 號煤層含氣量預測成果如圖9。

圖9 A13 井3 號煤層含氣量預測成果Fig.9 Prediction results of 3# coalbed methane content in A13 well
由圖9 可以看出,多元回歸模型明顯存在“高值偏低,低值偏高”的有偏現象,整體上均比神經網絡含氣量模型差,且多元回歸法預測結果整體為1 條直線,并不符合煤層強非均質性的特點,因此不合理,參考價值不大;神經網絡預測含氣量整體上形態走勢相近,一定程度上符合煤層強非均質性的特點,BP 神經網絡含氣量模型對樣本量要求高且訓練難度大,也存在有偏現象誤差較大;796~797 m 為夾矸段,理論上含氣量為低值,而支持向量機含氣量模型表現為平穩直線且與正常響應段近乎持平,且796.6~797.6 m 存在明顯擴徑,盡管經過擴徑校正,但仍無法消除曲線失真對含氣量建模的影響。可以看出,支持向量機含氣量模型抗井徑失真能力明顯不如通用向量機含氣量模型和BP 神經網絡含氣量模型;在煤層上下測井響應半幅點突變段通用向量機含氣量預測精度明顯優于通用向量機模型和BP神經網絡模型。綜合盲井驗證結果分析,提出的基于彈性神經網絡測井參數優選和改進量子粒子群結合變異蒙特卡洛算法優化通用向量機模型效果最好,模型穩健性好、魯棒性強,能滿足該地區含氣量高精度計算要求,為煤層氣生產提供總體上有力支撐與指導,同時為煤層含氣量高精度預測提供了新方法策略。
4 結 語
1)經過常規交會圖和含氣量相關性熱圖分析各測井及其衍生參數與煤層含氣量相關性可知煤層含氣量響應特征明顯,不同測井參數的含氣量響應差異較大,各測井參數間存在不同程度的多重共線性。
2)在煤層含氣量預測建模過程中,引入彈性網絡進行屬性約簡解決冗余信息對含氣量建模精度的影響,真實定量化表征測井參數與煤層含氣量間的非線性關系。從實際結果可知,該特征參數優選策略符合地球物理測井理論,是行之有效的去冗余化方法,提升了建模精度。
3)針對煤儲層非均質性強且煤層含氣量小樣本不均衡特點引入通用向量機算法,通過試驗調整并確定了最優的GVM 模型拓撲結構參數,然后使用改進的量子粒子群算法優化GVM 模型權值建立最終煤層含氣量預測模型。將該模型與相同策略下的支持向量機、BP 神經網絡及傳統多元回歸模型進行對比,建模效果優于其他方法,能有效滿足勘探區含氣量高精度要求及生產指導,可進行推廣使用。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
