基于循環(huán)顯著性校準(zhǔn)網(wǎng)絡(luò)的胰腺分割方法
2022-12-03 14:31:08邱成健劉青山宋余慶劉哲
自動化學(xué)報 2022年11期
邱成健 劉青山 宋余慶 劉哲
胰腺癌具有侵襲性強(qiáng)、轉(zhuǎn)移早、惡性程度高、發(fā)展較快、預(yù)后較差等特征,根據(jù)美國癌癥協(xié)會報道,其5 年生存率低于10%,死亡率非常高[1].胰腺癌已成為嚴(yán)重威脅人類健康的重要疾病,并對臨床醫(yī)學(xué)構(gòu)成巨大挑戰(zhàn).胰腺的準(zhǔn)確分割對胰腺癌檢測識別等任務(wù)起著至關(guān)重要的作用.胰腺處于人體后腹部的解剖位置,其臟器影像常被遮擋不易識別,且其形狀和空間位置多變,在腹部CT 圖像中所占比例較小,其準(zhǔn)確分割問題亟待解決.
近年來,由于深度神經(jīng)網(wǎng)絡(luò)的發(fā)展以及全卷積網(wǎng)絡(luò)(Fully convolutional network,FCN)[2]的出現(xiàn),醫(yī)學(xué)圖像分割準(zhǔn)確率取得了較大提升.針對不同患者間胰腺形態(tài)差異性較大的解剖特征,基于單階段深度學(xué)習(xí)分割算法極易受其較大背景區(qū)域影響,導(dǎo)致分割準(zhǔn)確率下降.現(xiàn)階段常用解決方法是基于由粗到細(xì)的分割算法[3-6],通過粗分割階段輸出掩碼進(jìn)行定位,只保留胰腺及其周圍部分區(qū)域作為細(xì)分割階段網(wǎng)絡(luò)輸入,減小背景區(qū)域?qū)δ繕?biāo)區(qū)域影響,提高分割精度.由粗到細(xì)的分割算法雖然減少了腹部影像背景區(qū)域?qū)δ繕?biāo)區(qū)域的干擾,但是針對形態(tài)和空間位置多變的胰腺小器官增強(qiáng)前景區(qū)域同樣重要.同時粗分割階段僅保留了定位框的位置信息,卻丟失了胰腺輸出分割掩碼的先驗特征信息,從而細(xì)分割階段缺少粗分割階段上下文信息,有時會獲得相比粗分割階段更差的分割結(jié)果,如圖1 所示.此外,由于在CT 影像中胰腺與鄰近器官密度較為接近、組織重疊部分界限分辨困難,未合理利用相鄰切片預(yù)測分割掩碼上下文信息常導(dǎo)致誤分割現(xiàn)象,如圖2 所示.結(jié)合相鄰預(yù)測分割掩碼容易看出,中間切片存在誤分割區(qū)域(紅色部分),合理利用預(yù)測分割掩碼切片上下文信息能夠校準(zhǔn)誤分割區(qū)域.
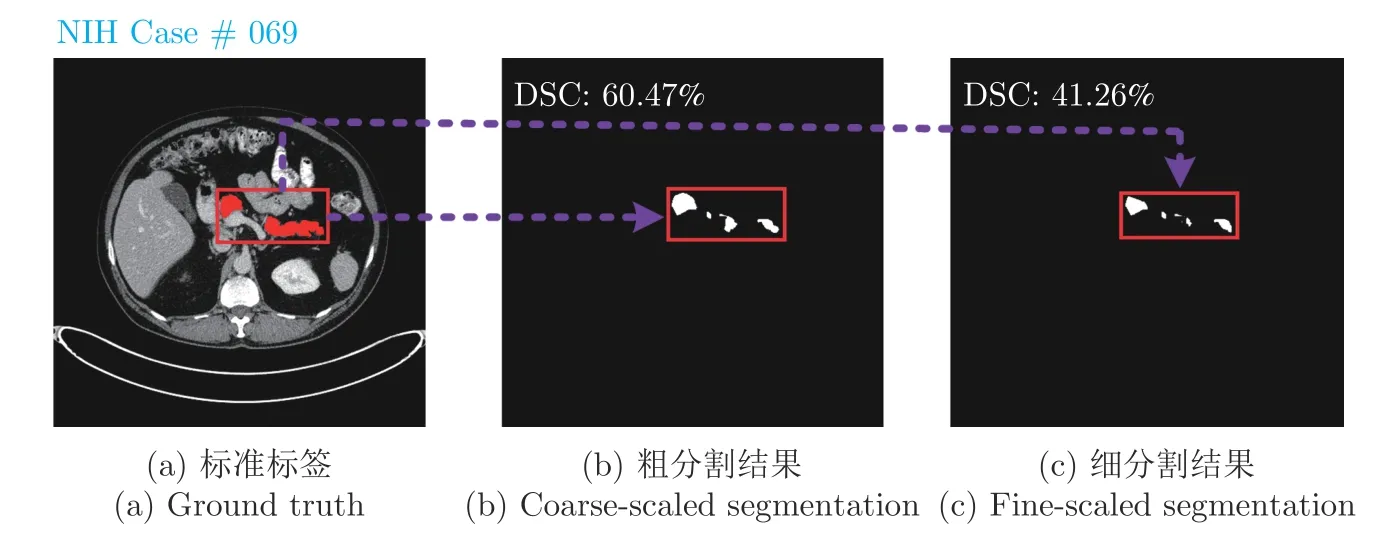
圖1 粗細(xì)分割存在問題示例Fig.1 A failure case of the coarse-to-fine pancreas segmentation approach

圖2 誤分割示例Fig.2 An example of false segmentation
針對胰腺細(xì)分割階段缺少粗分割階段上下文信息的問題,文獻(xiàn)[3]提出了固定點的分割方法.訓(xùn)練階段使用胰腺標(biāo)注數(shù)據(jù)訓(xùn)練粗分割網(wǎng)絡(luò),然后使用粗分割網(wǎng)絡(luò)的預(yù)測結(jié)果對原CT 圖像進(jìn)行定位、剪裁,只保留胰腺及其周圍部分區(qū)域作為細(xì)分割網(wǎng)絡(luò)輸入,通過反向傳播,優(yōu)化細(xì)分割結(jié)果.測試階段,固定細(xì)分割網(wǎng)絡(luò)參數(shù),使用細(xì)分割網(wǎng)絡(luò)預(yù)測掩碼獲得定位框并剪裁CT 圖像,再次輸入細(xì)分割網(wǎng)絡(luò),迭代此過程獲得優(yōu)化的分割掩碼,以此緩解缺少階段上下文信息的問題.但是此分割方法本質(zhì)上僅循環(huán)利用細(xì)分割定位框的位置信息,缺少對分割掩碼的循環(huán)利用,缺少聯(lián)合訓(xùn)練,導(dǎo)致分割效果提升有限.
針對如何合理利用切片上下文信息解決胰腺與鄰近器官密度較為接近、組織重疊部分界限分辨困難導(dǎo)致的誤分割問題,研究者提出了利用卷積長短期記憶網(wǎng)絡(luò)(Convolutional long short-term memory,CLSTM)[7]和三維分割網(wǎng)絡(luò)的方法[8-10].文獻(xiàn)[8] 將相鄰CT 切片輸入到卷積門控循環(huán)單元(Convolutional gated recurrent units,CGRU)[11],使當(dāng)前隱藏層輸出信息融合到下一時序隱藏層中,通過前向傳播,當(dāng)前隱藏層可獲得融合之前切片上下文信息的輸出表示.文獻(xiàn)[9]通過雙向卷積循環(huán)神經(jīng)網(wǎng)絡(luò),同時利用當(dāng)前層前后切片上下文信息進(jìn)行胰腺分割.但是目前大多數(shù)基于卷積循環(huán)神經(jīng)網(wǎng)絡(luò)的分割方法在利用切片上下文信息時,只能按照輸入切片順序、逆序或結(jié)合順序和逆序的方式.這些方式嚴(yán)重依賴輸入序列順序,并且相隔越遠(yuǎn)的切片在前向傳播過程中能夠共享的上下文信息越少.與前述方法不同,文獻(xiàn)[10]將鄰近切片輸入三維卷積神經(jīng)網(wǎng)絡(luò),有效利用切片上下文信息,改善了分割結(jié)果.但基于三維卷積神經(jīng)網(wǎng)絡(luò)的分割方法,受限于三維訓(xùn)練數(shù)據(jù)量過少和顯存消耗過大,大多數(shù)方法是基于局部三維塊的分割.雖然局部塊中切片上下文信息得到了合理利用,但是全局三維信息卻缺乏連續(xù)性,導(dǎo)致分割掩碼存在過多噪點.相比于三維圖像分割方法需要解決三維圖像數(shù)據(jù)量過少及參數(shù)量過多帶來的顯存問題,基于卷積循環(huán)神經(jīng)網(wǎng)絡(luò)的二維圖像分割方法存在的問題可以通過設(shè)計算法解決.
根據(jù)以上分析,本文針對現(xiàn)有基于由粗到細(xì)的二維胰腺分割方法中存在的問題,設(shè)計了循環(huán)顯著性校準(zhǔn)網(wǎng)絡(luò),其結(jié)合更多的階段上下文信息和切片上下文信息.通過設(shè)計的卷積自注意力校準(zhǔn)模塊跨順序利用切片上下文信息校準(zhǔn)每一階段的胰腺分割掩碼,循環(huán)使用前一階段的胰腺分割掩碼定位目標(biāo)區(qū)域,增強(qiáng)當(dāng)前階段的網(wǎng)絡(luò)輸入,完成分割任務(wù)的聯(lián)合優(yōu)化.提出的方法在公開數(shù)據(jù)集上進(jìn)行了實驗驗證,結(jié)果表明其有效地解決了上述胰腺分割任務(wù)中存在的問題.本文的主要貢獻(xiàn)如下:
1)提出循環(huán)顯著性校準(zhǔn)網(wǎng)絡(luò),循環(huán)利用前一階段胰腺分割掩碼顯著性增強(qiáng)當(dāng)前階段胰腺區(qū)域特征,通過聯(lián)合訓(xùn)練獲取更多的階段上下文信息.
2)設(shè)計了卷積自注意力模塊,使得胰腺所有輸入切片預(yù)測分割掩碼之間可以平行地進(jìn)行跨順序上下文信息互監(jiān)督,校準(zhǔn)預(yù)測分割掩碼.
3)在NIH (National institutes of health)和MSD (Medical segmentation decathlon)胰腺數(shù)據(jù)集進(jìn)行了大量實驗,實驗結(jié)果驗證了提出方法的有效性及先進(jìn)性.
1 相關(guān)工作
由粗到細(xì)的兩階段分割方法.由粗到細(xì)的兩階段分割方法主要分為兩類:基于傳統(tǒng)算法和基于深度學(xué)習(xí)的方法.前者主要使用如超像素、圖譜等傳統(tǒng)算法獲得粗分割結(jié)果,再通過隨機(jī)森林、Graphcut 等方法獲得細(xì)分割結(jié)果[12-13];后者主要是基于深度學(xué)習(xí)的粗細(xì)分割方法[14],基于數(shù)據(jù)驅(qū)動、自動化學(xué)習(xí)模型參數(shù),進(jìn)行像素級別分類,因其高精度和穩(wěn)定性,逐漸取代傳統(tǒng)由粗到細(xì)的分割方法.
基于深度學(xué)習(xí)的粗細(xì)分割方法在粗分割訓(xùn)練階段,輸入CT 切片MC,經(jīng)過粗分割卷積神經(jīng)網(wǎng)絡(luò)f(MC,θC),預(yù)測結(jié)果記為NC,與真實標(biāo)簽(Ground truth)Y進(jìn)行損失計算,通過反向傳播優(yōu)化粗分割結(jié)果.在細(xì)分割訓(xùn)練階段,針對粗分割網(wǎng)絡(luò)預(yù)測結(jié)果,使用最小外接矩形算法獲得胰腺位置坐標(biāo)(px,py,w,h),對CT 輸入MC進(jìn)行剪裁,獲得感興趣區(qū)域MF作為細(xì)分割網(wǎng)絡(luò)f(MF,θF)的輸入;獲得細(xì)分割網(wǎng)絡(luò)輸出預(yù)測結(jié)果NF并還原圖像大小,記為Y P,與真實標(biāo)簽(Ground truth)Y進(jìn)行損失計算,通過反向傳播優(yōu)化細(xì)分割結(jié)果.其中,上標(biāo)參數(shù)C、F分別表示粗分割階段和細(xì)分割階段; (px,py),w,h分別表示外接矩形框的左上角坐標(biāo),寬和高;θC,θF分別表示粗、細(xì)分割網(wǎng)絡(luò)參數(shù).
在測試階段,將CT 切片輸入訓(xùn)練好的粗細(xì)分割網(wǎng)絡(luò)即可獲得測試結(jié)果.粗細(xì)分割方法中使用的網(wǎng)絡(luò)主要是基于UNet[15],FCN[2]以及基于這兩個基礎(chǔ)結(jié)構(gòu)的改進(jìn)網(wǎng)絡(luò).本文在粗細(xì)分割方法的基礎(chǔ)上針對胰腺解剖性質(zhì)提出基于循環(huán)顯著性校準(zhǔn)網(wǎng)絡(luò)的胰腺分割方法,均使用UNet[15]作為基礎(chǔ)骨干網(wǎng)絡(luò).
胰腺分割方法.傳統(tǒng)醫(yī)學(xué)圖像分割常用方法有水平集[16]、混合概率圖模型[17]和活動輪廓模型[18]等.隨著深度學(xué)習(xí)的發(fā)展,基于卷積神經(jīng)網(wǎng)絡(luò)(Convolutional neural network,CNN)的分割方法由于其較高的精確度和較好的泛化性逐漸取代傳統(tǒng)方法.目前大多數(shù)基于深度學(xué)習(xí)的胰腺分割方法核心思想來源于FCN[2],FCN 改進(jìn)了卷積神經(jīng)網(wǎng)絡(luò),用卷積層替代最后的全連接層,同時將淺層語義特征通過上采樣與深層特征相融合,補(bǔ)充分割目標(biāo)的位置信息,提高了分割準(zhǔn)確率.另一種常用于胰腺分割的方法采用“編碼器-解碼器”結(jié)構(gòu)[15],編碼器負(fù)責(zé)逐層提取漸進(jìn)的高級語義特征,解碼器通過反卷積或上采樣的方法逐層恢復(fù)圖像分辨率至原圖大小,同一層次編碼器和解碼器通過跳躍結(jié)構(gòu)相連接.
由于胰腺形狀、大小和位置多變,上述單個階段基于FCN 或“編碼器-解碼器”結(jié)構(gòu)的分割網(wǎng)絡(luò)難以獲得準(zhǔn)確分割結(jié)果.文獻(xiàn)[3]首先提出了基于卷積神經(jīng)網(wǎng)絡(luò)由粗到細(xì)的兩階段分割算法,使用粗分割掩碼的位置信息剪裁細(xì)分割階段網(wǎng)絡(luò)的輸入,減小背景區(qū)域?qū)σ认賲^(qū)域分割的影響.相比于文獻(xiàn)[3],文獻(xiàn)[19]更進(jìn)一步,在使用由粗到細(xì)的兩階段分割算法的同時,通過設(shè)計輕量化模塊減少了粗細(xì)分割階段模型的參數(shù);而文獻(xiàn)[20]則直接以中心點為基礎(chǔ)剪裁圖像作為細(xì)分割網(wǎng)絡(luò)的輸入.文獻(xiàn)[21]利用肝臟、脾臟和腎臟的位置信息定位胰腺器官,這不同于上述直接通過粗分割定位胰腺器官的方法.文獻(xiàn)[22]提出基于由下至上的方法,首先使用超像素分塊進(jìn)行粗分割,然后基于超像素塊集成分割結(jié)果.文獻(xiàn)[23]使用最大池化方法融合CT 切片三個軸信息,獲取候選區(qū)域,在候選區(qū)域中從邊緣至內(nèi)部聚合分割結(jié)果.文獻(xiàn)[24]提出基于圖譜的粗細(xì)分割方法,改善了分割結(jié)果.近來,文獻(xiàn)[25]提出了一種基于強(qiáng)化學(xué)習(xí)的兩階段分割算法.首先,使用DQN (Deep Q network)回歸胰腺坐標(biāo)位置,剪裁只保留胰腺及其周圍部分區(qū)域;然后,細(xì)分割階段使用可行變卷積網(wǎng)絡(luò)獲得分割結(jié)果.
以上方法均取得了較為準(zhǔn)確的分割結(jié)果,但是將胰腺分割粗細(xì)兩階段分開訓(xùn)練,細(xì)分割階段缺少粗分割階段上下文信息的問題,依然難以用有效的方式處理.文獻(xiàn)[3]在測試階段使用固定點算法,固定細(xì)分割模型參數(shù),循環(huán)利用當(dāng)前階段預(yù)測分割掩碼獲取定位框位置信息作為下一階段輸入的先驗,以此達(dá)到使用之前階段上下文信息的效果.此方法本質(zhì)上只迭代使用細(xì)分割定位框位置信息,缺乏粗分割輸出分割掩碼的有效利用.
合理使用切片上下文信息解決胰腺誤分割,同樣至關(guān)重要.文獻(xiàn)[8,26]首先使用卷積神經(jīng)網(wǎng)絡(luò)提取特征,然后利用卷積長短期記憶網(wǎng)絡(luò)[7]提取切片上下文信息分割胰腺,但切片上下文信息不能夠跨順序、平行化共享,并且前向傳播存在信息丟失的問題.文獻(xiàn)[27]使用對抗學(xué)習(xí)思想,分別使用兩個判別器約束主分割網(wǎng)絡(luò),捕獲空間語義信息和切片上下文信息,但對抗網(wǎng)絡(luò)的不穩(wěn)定性使得訓(xùn)練和測試結(jié)果波動性較大.文獻(xiàn)[28]使用相鄰切片局部塊作為輸入,編碼器部分使用三維卷積以遞進(jìn)的方式逐層融合切片上下文信息,解碼器部分使用二維轉(zhuǎn)置卷積輸出中間切片分割掩碼.由于CT 切片之間層厚和層間距的差異性,且局部塊輸入未使用任何插值方法,捕捉到的三維切片上下文信息具有不一致性和局部性.文獻(xiàn)[10,29-30]使用三維分割方法獲取切片上下文信息,受限于顯存和三維數(shù)據(jù)量,全局三維信息缺乏連續(xù)性.
針對現(xiàn)有胰腺分割方法中缺少階段上下文信息的問題,以及在使用循環(huán)卷積神經(jīng)網(wǎng)絡(luò)分割胰腺的過程中,利用相鄰切片上下文信息存在順序依賴并且隨著相鄰切片間隔距離的增加導(dǎo)致全局信息正相關(guān)減少的問題,本文提出了一種循環(huán)利用階段上下文信息和切片上下文信息的二維胰腺圖像分割網(wǎng)絡(luò).首先,將相鄰CT 切片作為粗分割網(wǎng)絡(luò)輸入,獲得粗分割掩碼;然后,通過最小矩形框算法對獲得的粗分割掩碼進(jìn)行胰腺區(qū)域坐標(biāo)定位;接著,使用粗分割掩碼作為權(quán)重增強(qiáng)細(xì)分割階段輸入切片的胰腺區(qū)域特征,獲取細(xì)分割掩碼,細(xì)分割掩碼以同樣的方式增強(qiáng)下一階段分割網(wǎng)絡(luò)的輸入;最后,循環(huán)迭代上述過程直到達(dá)到指定停止條件.通過此方法,有效降低了分割平均誤差,提高了分割方法的穩(wěn)定性.
2 本文方法
針對當(dāng)前由粗到細(xì)的兩階段胰腺分割算法利用階段上下文信息和切片上下文信息存在的問題,本文提出了循環(huán)顯著性校準(zhǔn)網(wǎng)絡(luò).其采用UNet 和卷積自注意力校準(zhǔn)模塊作為骨干網(wǎng)絡(luò),接受相鄰橫斷位胰腺CT 切片輸入;當(dāng)前階段卷積自注意力校準(zhǔn)模塊利用切片上下文信息校準(zhǔn)UNet 輸出掩碼的同時,利用自身輸出掩碼顯著性增強(qiáng)下一階段UNet網(wǎng)絡(luò)輸入;循環(huán)UNet 和卷積自注意力校準(zhǔn)模塊,聯(lián)合階段上下文信息和切片上下文信息提升分割性能,整體網(wǎng)絡(luò)架構(gòu)如圖3 所示.
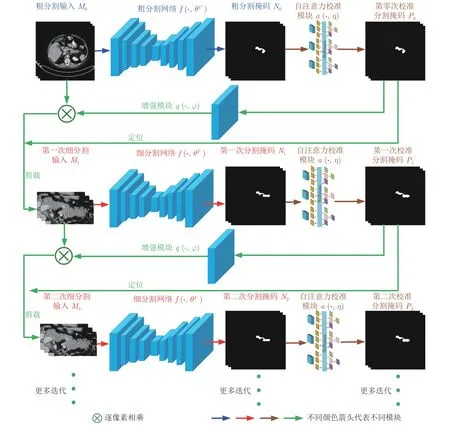
圖3 循環(huán)顯著性校準(zhǔn)網(wǎng)絡(luò)Fig.3 Recurrent saliency calibration network
2.1 循環(huán)顯著性校準(zhǔn)網(wǎng)絡(luò)
本文聚焦于聯(lián)合階段間和胰腺序列圖像切片上下文信息提升分割準(zhǔn)確率.為了合理利用當(dāng)前階段胰腺分割掩碼的位置和形狀等先驗信息,顯著增強(qiáng)下一階段分割網(wǎng)絡(luò)的輸入;同時,通過平行、跨順序直接利用相鄰切片分割掩碼改善自身明顯誤分割現(xiàn)象,提出循環(huán)顯著性校準(zhǔn)網(wǎng)絡(luò),其分割迭代過程如圖4 所示.循環(huán)顯著性指每個階段的校準(zhǔn)分割掩碼P經(jīng)增強(qiáng)模塊g(P,φ)特征提取后獲得像素矩陣,此像素矩陣為胰腺前景相關(guān)矩陣.使用此像素矩陣和下一階段輸入圖像M進(jìn)行像素對像素相乘,顯著增強(qiáng)胰腺區(qū)域,抑制背景區(qū)域.
選擇UNet 基礎(chǔ)分割網(wǎng)絡(luò)模型f(·,θ)作為骨干網(wǎng)絡(luò),該模型的輸入為胰腺的相鄰CT 切片,記為X,通過基礎(chǔ)分割網(wǎng)絡(luò)模型推斷出輸出掩碼N.由于胰腺與鄰近器官密度較為接近、組織重疊部分界限分辨困難,容易導(dǎo)致基礎(chǔ)分割網(wǎng)絡(luò)出現(xiàn)誤分割現(xiàn)象.因此,本文基于切片上下文信息設(shè)計了卷積自注意力校準(zhǔn)模塊a(·,η),校準(zhǔn)基礎(chǔ)分割網(wǎng)絡(luò)輸出的分割掩碼N,卷積自注意力校準(zhǔn)模塊的輸出表示為P;為了能夠獲取更加準(zhǔn)確的胰腺位置,設(shè)置了固定分割掩碼像素閾值0.5,來二值化P,其輸出表示如式(1)所示.
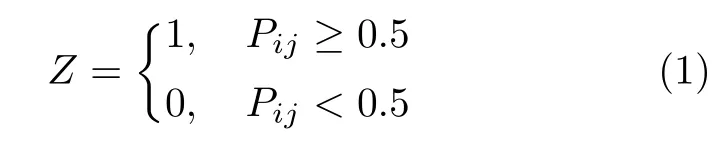
其中,i、j為分割掩碼中像素值位置坐標(biāo).
通過對式(1)的輸出Z應(yīng)用最小矩形框算法獲得包圍胰腺分割掩碼框的位置坐標(biāo) (px,py,w,h),位置坐標(biāo)獲得過程如圖5 所示.其中,藍(lán)色框為單個連通區(qū)域分割結(jié)果的定位,綠色框為整合多段分割結(jié)果的定位.
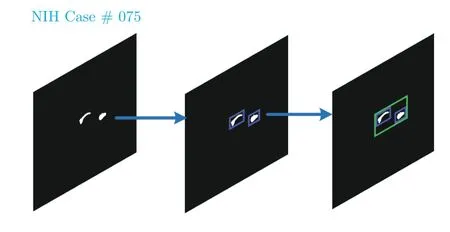
圖5 基于最小矩形框的定位過程Fig.5 The process of localization based on minimum rectangle algorithm
為改善下一階段分割過程中缺少當(dāng)前階段上下文信息的問題,使用校準(zhǔn)模塊輸出分割掩碼P作為潛在變量輸入到顯著性增強(qiáng)模塊g(P,φ),提取特征概率作為下一階段分割網(wǎng)絡(luò)輸入X的先驗空間權(quán)重,并結(jié)合上述定位坐標(biāo) (px,py,w,h)增強(qiáng)并縮小下一階段網(wǎng)絡(luò)的輸入,顯著減小背景區(qū)域?qū)Ψ指畹挠绊?對于在整個腹部圖像中區(qū)域占比較小,形狀和位置多變的胰腺器官來說,此過程極為重要,其顯著增強(qiáng)了胰腺區(qū)域,弱化了不相關(guān)區(qū)域.過程如式(2)所示.
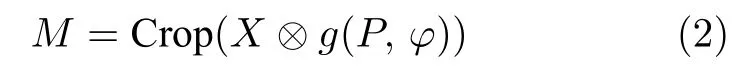
其中,M為增強(qiáng)并縮小的下一階段輸入;?表示對應(yīng)像素點相乘;Crop 表示利用定位坐標(biāo)(px,py,w,h)對各階段輸入做剪裁.θ,η,φ為相應(yīng)模塊共享網(wǎng)絡(luò)參數(shù).
圖4 右圖是圖4 左圖的展開形式,其中M0作為胰腺初始輸入圖像和X相同,其大小遠(yuǎn)大于其他階段的網(wǎng)絡(luò)輸入Mt(t >0),所以第一次粗分割階段和其余分割階段網(wǎng)絡(luò)參數(shù)θ應(yīng)加以區(qū)分,分別使用θC和θF表示.在循環(huán)迭代過程中,由于各分割階段輸入X不變,并且輸入X需與顯著性增強(qiáng)模塊g(P,φ)輸出作逐像素相乘,為了保持g(P,φ)是一個輸入輸出同大小的模塊,設(shè)置卷積核大小為3×3,步長為1,填充為1.
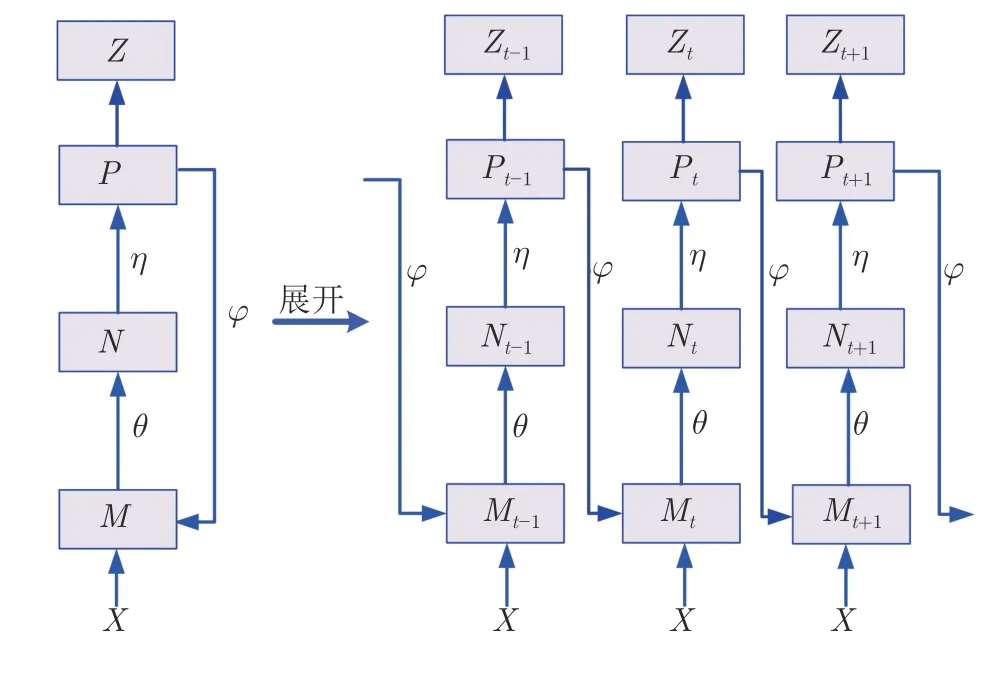
圖4 迭代過程Fig.4 Iteration process
整個循環(huán)迭代分割過程如式(3)所示.
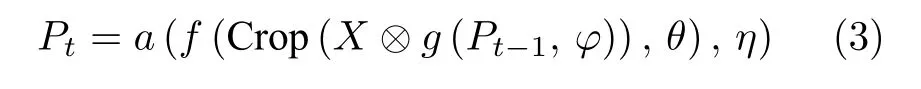
根據(jù)以上分析可以看出,整個網(wǎng)絡(luò)運算過程是可微的,結(jié)合所有階段損失函數(shù)進(jìn)行聯(lián)合訓(xùn)練.本文采用DSC (Dice-S?rensen coefficient)作為損失函數(shù),如式(4)所示.
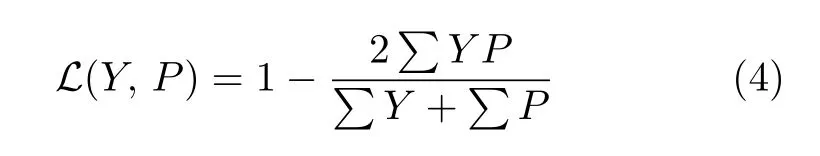
其中,Y是真實標(biāo)簽,P為各階段預(yù)測分割掩碼.
結(jié)合各階段分割網(wǎng)絡(luò)和卷積自注意力校準(zhǔn)模塊,DSC 聯(lián)合損失函數(shù)如式(5)所示.
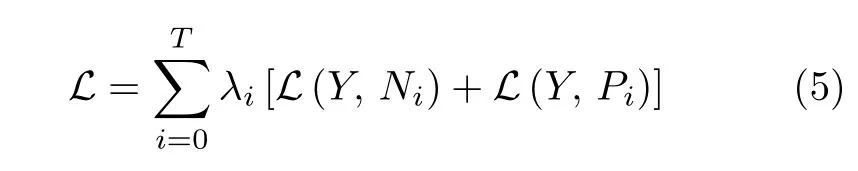
其中,T為循環(huán)分割次數(shù)停止閾值.由于粗分割階段和其余分割階段胰腺切片輸入大小不一致,粗分割階段主要用于獲取胰腺的初步定位和粗分割掩碼,故設(shè)置較小的權(quán)重參數(shù),且滿足3λ0=λ1=λ2=···=λT=3/(3T+1).
2.2 卷積自注意力校準(zhǔn)模塊
針對胰腺與鄰近器官密度較為接近、組織重疊部分界限分辨困難而導(dǎo)致的誤分割問題,本文提出在循環(huán)顯著性校準(zhǔn)網(wǎng)絡(luò)每個分割階段嵌入卷積自注意力校準(zhǔn)模塊,其合理利用切片上下文信息校準(zhǔn)胰腺相鄰切片誤分割區(qū)域.
本文設(shè)計的卷積自注意力校準(zhǔn)模塊基于自注意力機(jī)制[31].自注意力機(jī)制在處理序列信息輸入時,能夠跨順序、平行化地與序列輸入中其他時間點輸入進(jìn)行直接交互.但由于自注意力機(jī)制使用的線性變換忽略了圖像像素之間的空間關(guān)系,本文提出卷積自注意力校準(zhǔn)模塊,使用卷積操作替換線性變換.卷積自注意力校準(zhǔn)模塊如圖6 左圖所示(圖中以批次大小3 為例),圖6 右圖為圖6 左圖中獲得單張校準(zhǔn)分割掩碼的計算過程,其余兩張切片校準(zhǔn)分割掩碼獲得過程計算方式類似,圖中P表示預(yù)測分割掩碼的熱力圖顯示,中間是顏色條,其取值范圍在[0,1.0]之間.為了描述和解釋的方便,將卷積自注意力校準(zhǔn)模塊中所有標(biāo)量以向量或者矩陣的形式表示如下.
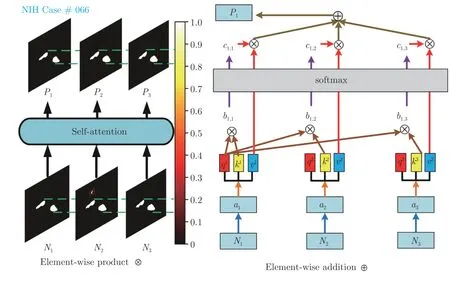
圖6 卷積自注意力校準(zhǔn)模塊網(wǎng)絡(luò)圖Fig.6 Network of convolution self-attention calibration module
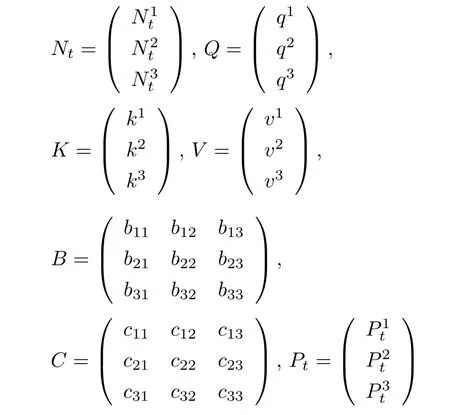
其中,Nt為分割網(wǎng)絡(luò)f(Mt,θ)輸出的相鄰分割掩碼;Q為查詢特征向量;K,V為鍵值對特征向量;B為相似度度量矩陣;C為像素權(quán)重矩陣;Pt為校準(zhǔn)模塊輸出掩碼.
為了提取多樣性的特征表示,首先將相鄰分割掩碼Nt中的每一個元素分別通過 3×3 卷積,獲得輸出α1,α2,α3; 然后將輸出特征α1分別通過3 個不同的1×1卷積,獲得的查詢特征向量q1和鍵值對特征向量k1,v1;輸出特征α2,α3以與α1相同的方式獲得 (q2,k2,v2)和 (q3,k3,v3),其中所有3×3 和 1×1 卷積都保持輸出和輸入大小一致.下面通過Q、K、V來表示輸出掩碼Pt獲得的過程,如式(6)~式(8).

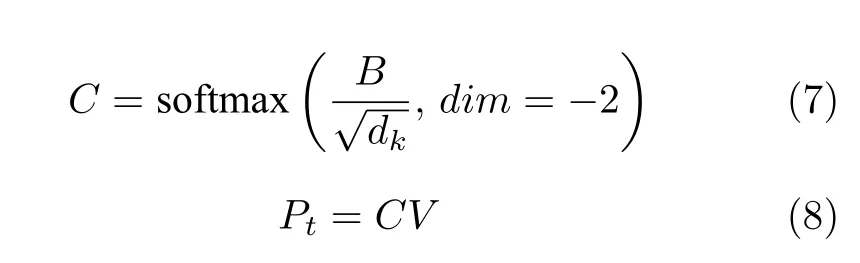
B為Nt中的每個元素的特征查詢向量分別與其他元素的鍵向量作相似度度量獲得的矩陣,表示其他元素對當(dāng)前元素的影響程度,這里相似度度量是像素對像素的乘法操作,dk為鍵向量維度.C通過 s oftmax 函數(shù)對相似度度量矩陣進(jìn)行歸一化,dim=-2表示對倒數(shù)第二個維度進(jìn)行歸一化;獲得像素權(quán)重矩陣以后,與Nt中的每個元素的值向量v像素對像素相乘,再進(jìn)行融合獲得最終輸出表示Pt.分別用式(9)~式(15)表示詳細(xì)計算過程,其中卷積操作都擁有不同的參數(shù).
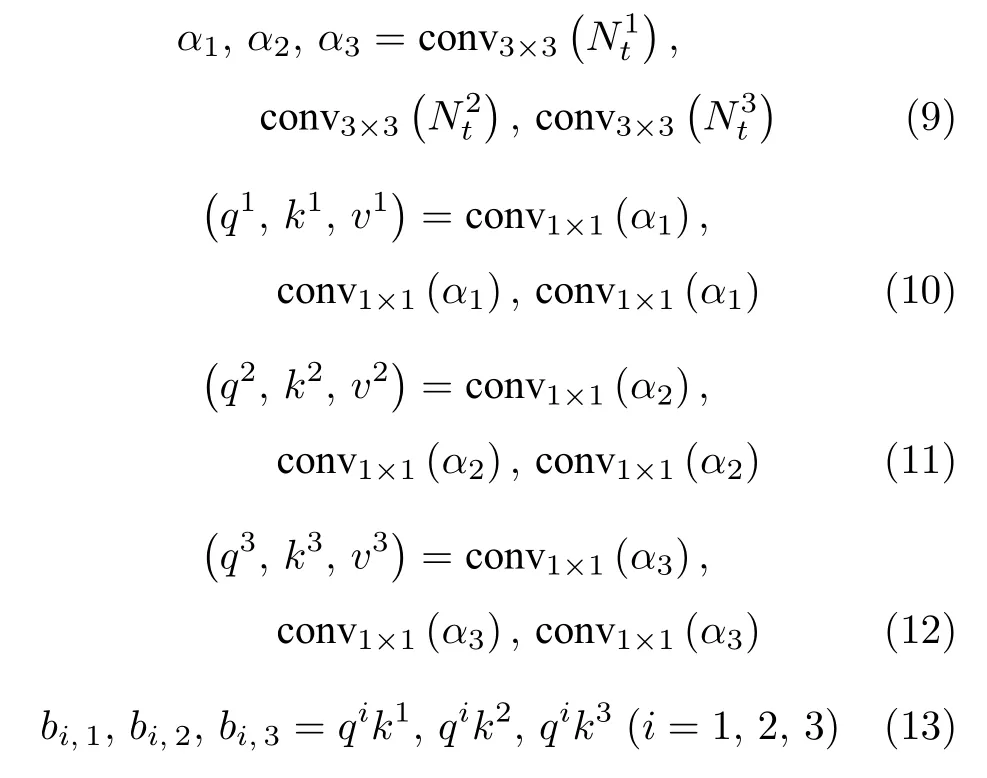
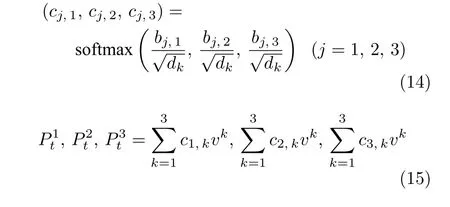
3 實驗結(jié)果與分析項
3.1 數(shù)據(jù)集及預(yù)處理
本文實驗使用NIH[22]胰腺分割數(shù)據(jù)集和MSD[32]胰腺分割數(shù)據(jù)集.NIH 數(shù)據(jù)集總共包含82位受試者的CT 樣本,每位受試者樣本中CT 切片數(shù)量最少181 張,最多466 張,每一張切片大小為512×512像素,切片厚度在0.5 mm 到1.0 mm 之間;MSD數(shù)據(jù)集總共包含281 位受試者的CT 樣本,每位受試者樣本中CT 切片數(shù)量在37 到751 之間,每一張切片大小為 5 12×512 像素.
在本文實驗中,所有CT 切片的HU (Housefield unit)值根據(jù)統(tǒng)計結(jié)果被限制在 [-120,340],并把CT 切片及其對應(yīng)標(biāo)簽歸一化到[0,1]之間,同時隨機(jī)做 [-15°,15°] 隨機(jī)旋轉(zhuǎn).
3.2 實驗方法細(xì)節(jié)及評價指標(biāo)
實驗使用Pytorch 1.2.0 版本,在Ubuntu 16.04 操作系統(tǒng)的2 塊RTX 2080ti 獨立顯卡進(jìn)行訓(xùn)練,訓(xùn)練時批次大小設(shè)置為3,使用ReLU[33]作為激活函數(shù),Adam[34]作為優(yōu)化方法,學(xué)習(xí)率lr=1.0×10-4,受限于顯存大小,訓(xùn)練階段最大迭代次數(shù)T設(shè)置為4.實驗使用4 折交叉驗證方法確保結(jié)果的魯棒性.數(shù)據(jù)集被平均分為4 份,每次選擇其中的3 份作為訓(xùn)練集,另1 份作為驗證集.共實驗4 次,計算平均DSC 準(zhǔn)確率,作為最終結(jié)果.
訓(xùn)練過程.訓(xùn)練過程中需要通過反向傳播算法最小化損失函數(shù)(式(5)).值得注意的是:訓(xùn)練過程前期,由于網(wǎng)絡(luò)參數(shù)的隨機(jī)初始化,各階段產(chǎn)生了錯誤分割掩碼,所以訓(xùn)練初始階段使用標(biāo)準(zhǔn)標(biāo)簽作為上下文先驗,增強(qiáng)并剪裁下一分割階段網(wǎng)絡(luò)的輸入.
測試過程.測試過程和訓(xùn)練過程不同,測試階段缺少標(biāo)準(zhǔn)標(biāo)簽,所以使用各階段分割掩碼作為先驗信息,增強(qiáng)并縮小下一階段的輸入;同樣,測試過程中不需要優(yōu)化參數(shù),對于中間結(jié)果可以丟棄,所以迭代次數(shù)的閾值不再限于GPU 顯存,理論上可以無上界.本文設(shè)定測試的循環(huán)分割次數(shù)停止閾值T為6,因為實驗的觀察結(jié)果表明,當(dāng)?shù)螖?shù)較大時分割準(zhǔn)確率提升有限.
實驗采用DSC 作為評價指標(biāo),如式(16)所示,真實標(biāo)簽和分割掩碼交集的兩倍與真實標(biāo)簽和分割掩碼并集的比值.其中,Y是真實標(biāo)簽,P為預(yù)測分割掩碼.
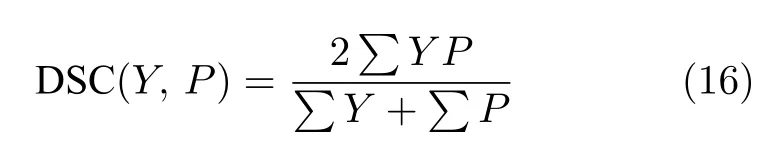
3.3 實驗對比分析
本節(jié)基于公開數(shù)據(jù)集(NIH 和MSD)設(shè)置不同實驗對照組,驗證基于循環(huán)顯著性校準(zhǔn)網(wǎng)絡(luò)的胰腺分割方法.主要分為5 部分:1)階段上下文信息有效性分析;2)切片上下文信息有效性分析;3)結(jié)合階段上下文信息和切片上下文信息的循環(huán)顯著性校準(zhǔn)網(wǎng)絡(luò)有效性分析;4)輸入切片數(shù)目對分割結(jié)果的影響;5)網(wǎng)絡(luò)模型參數(shù)量及時間消耗.
3.3.1 階段上下文信息有效性分析
本節(jié)對比實驗展示階段上下文信息對于分割性能的影響,分別進(jìn)行了兩部分實驗.
1)針對粗細(xì)分割分開訓(xùn)練、粗細(xì)分割聯(lián)合訓(xùn)練以及循環(huán)顯著性網(wǎng)絡(luò)聯(lián)合訓(xùn)練進(jìn)行對比實驗.粗細(xì)分割聯(lián)合訓(xùn)練以及循環(huán)顯著性網(wǎng)絡(luò)聯(lián)合訓(xùn)練都使用了顯著性增強(qiáng)模塊利用階段上下文信息,其中每一分割階段都去掉了卷積自注意力校準(zhǔn)模塊.實驗結(jié)果如表1 所示.其中粗細(xì)分割聯(lián)合訓(xùn)練相比于粗細(xì)分割分開訓(xùn)練在兩個數(shù)據(jù)集上都展示了更高的平均分割準(zhǔn)確率和更低的標(biāo)準(zhǔn)差,其主要因為顯著性增強(qiáng)模塊顯著性增強(qiáng)胰腺區(qū)域并聯(lián)合粗細(xì)分割階段上下文信息進(jìn)行聯(lián)合優(yōu)化;而循環(huán)顯著性網(wǎng)絡(luò)聯(lián)合訓(xùn)練相比于粗細(xì)分割聯(lián)合訓(xùn)練帶來的分割效果提升,來源于使用更多的階段上下文信息聯(lián)合訓(xùn)練.由上述分析可知,更多的階段上下文信息對于胰腺分割準(zhǔn)確率提升有重要貢獻(xiàn).

表1 粗細(xì)分割分開訓(xùn)練、聯(lián)合訓(xùn)練和循環(huán)顯著性聯(lián)合訓(xùn)練分割結(jié)果Table 1 Segmentation of coarse-to-fine separate training,joint training and recurrent saliency joint training
2)針對循環(huán)顯著性網(wǎng)絡(luò)測試階段進(jìn)行分析,如表2 所示.隨著第1 次迭代,在NIH 數(shù)據(jù)集上,胰腺的平均DSC 準(zhǔn)確率從76.81%上升到84.89%,標(biāo)準(zhǔn)差從9.68%降到5.14%;在MSD 數(shù)據(jù)集上,胰腺的平均DSC 準(zhǔn)確率從73.46%上升到81.67%,標(biāo)準(zhǔn)差從11.73%降到8.05%.由于粗分割階段分割掩碼上下文信息的引入,平均DSC 準(zhǔn)確率和穩(wěn)定性都有較大的提升.但是,后續(xù)迭代過程中,由于分割掩碼先驗信息對于較準(zhǔn)確分割結(jié)果作用的減少,在兩個數(shù)據(jù)集上平均DSC 準(zhǔn)確率和標(biāo)準(zhǔn)差僅僅小幅度上升和下降;但對于最小DSC 分割準(zhǔn)確率提升明顯,分別從40.12%上升到最高的62.82%、47.76%上升到最高的64.47%,有效提升了胰腺分割困難樣本的DSC 分割準(zhǔn)確率.
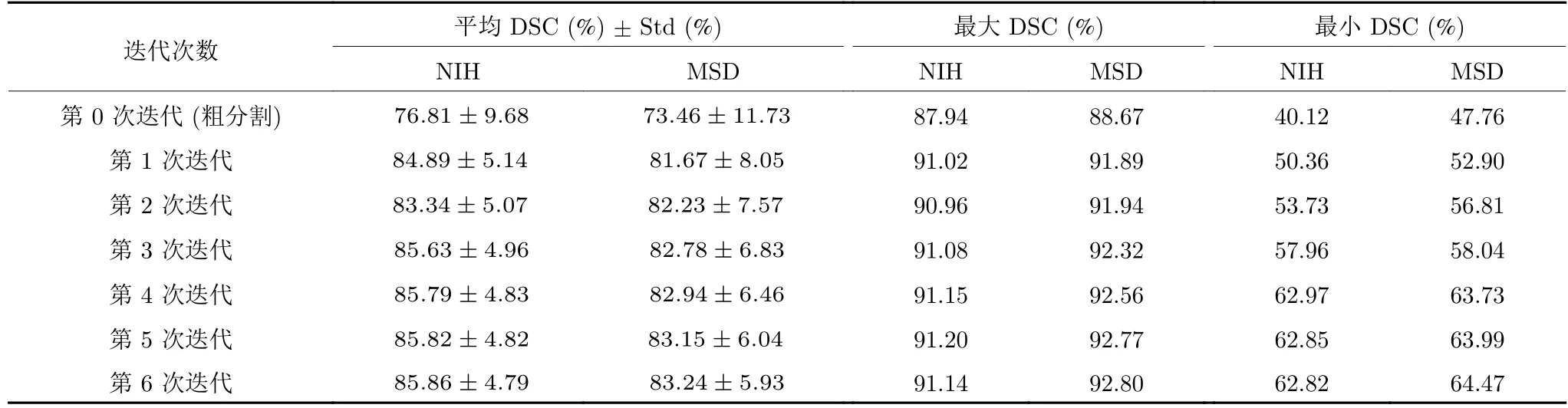
表2 循環(huán)顯著性網(wǎng)絡(luò)測試結(jié)果Table 2 Test results of recurrent saliency network segmentation
3.3.2 切片上下文信息有效性分析
本節(jié)對比實驗展示切片上下文信息對于胰腺分割性能的影響,分別進(jìn)行了兩部分實驗.
1)針對粗細(xì)分割以及循環(huán)顯著性網(wǎng)絡(luò)聯(lián)合訓(xùn)練在添加和未添加卷積自注意力校準(zhǔn)模塊利用切片上下文信息情況下,進(jìn)行實驗結(jié)果分析,如表3 所示.相對于未添加卷積自注意力校準(zhǔn)模塊的粗細(xì)分割聯(lián)合訓(xùn)練,添加了卷積自注意力校準(zhǔn)模塊的粗細(xì)分割聯(lián)合訓(xùn)練在NIH 數(shù)據(jù)集上,胰腺平均DSC 準(zhǔn)確率提升了1.64%,標(biāo)準(zhǔn)差下降了0.40%;在MSD數(shù)據(jù)集上,胰腺平均DSC 準(zhǔn)確率提升了1.29%,標(biāo)準(zhǔn)差下降了0.88%.在兩個數(shù)據(jù)集上,胰腺最小DSC 分割準(zhǔn)確率也有所上升.同樣,循環(huán)顯著性網(wǎng)絡(luò)聯(lián)合訓(xùn)練在添加卷積自注意力校準(zhǔn)模塊(本文方法)時,相比于未添加卷積自注意力校準(zhǔn)模塊,其分割性能在分割準(zhǔn)確率和穩(wěn)定性上均提升明顯.由此可以看出,卷積自注意力校準(zhǔn)模塊能夠利用切片上下文信息改善胰腺分割結(jié)果.

表3 添加校準(zhǔn)模塊結(jié)果對比Table 3 Comparison results of adding calibration module
2)針對本文方法中校準(zhǔn)模塊分別基于卷積自注意力或者基于卷積循環(huán)神經(jīng)網(wǎng)絡(luò)在分割胰腺時進(jìn)行實驗對比,如表4 所示.將本文方法框架中卷積自注意力校準(zhǔn)模塊分別換成單層卷積長短期記憶循環(huán)神經(jīng)網(wǎng)絡(luò)(CLSTM)[7]、單層卷積門控單元(ConvGRU)[11]和單層軌跡門控循環(huán)單元(TrajGRU)[35]等卷積循環(huán)神經(jīng)網(wǎng)絡(luò),進(jìn)行實驗對比.從兩個數(shù)據(jù)集的實驗結(jié)果可以看出,基于卷積自注意力的校準(zhǔn)模塊不管是在胰腺平均DSC 分割準(zhǔn)確率、標(biāo)準(zhǔn)差或者最大、最小分割準(zhǔn)確率上都要好于部分基于卷積循環(huán)神經(jīng)網(wǎng)絡(luò)的校準(zhǔn)模塊[7,11,35].

表4 胰腺分割基于CLSTM 和自注意力結(jié)果對比Table 4 Comparison results based on CLSTM and self-attention mechanism in pancreas segmentation
3.3.3 循環(huán)顯著性校準(zhǔn)網(wǎng)絡(luò)有效性分析
為進(jìn)一步說明本文所提方法在胰腺分割方法中的優(yōu)勢,本文方法與當(dāng)前具有代表性的方法進(jìn)行了比較.
NIH 胰腺數(shù)據(jù)集上實驗結(jié)果如表5 所示,本文方法與其他具有代表性的胰腺基準(zhǔn)分割方法進(jìn)行了比較.相比于其他二維胰腺分割方法[3,19-23,26,36],在以下兩方面改進(jìn):1)聯(lián)合訓(xùn)練利用更多的階段上下文信息;2)使用卷積自注意力校準(zhǔn)模塊校準(zhǔn)每一階段胰腺分割掩碼.平均DSC 分割準(zhǔn)確率從最高的85.40%提升到87.11%,顯著改善了胰腺平均分割結(jié)果;最大分割準(zhǔn)確率從最高的91.46% 上升到92.57%.相比于三維胰腺分割方法[5,10,29-30,37],本文提出的卷積自注意力校準(zhǔn)模塊充分利用切片上下文信息,顯著減少參數(shù)量(GPU 顯存消耗)的同時,達(dá)到三維分割同等效果,提高了運算效率,并且將胰腺平均分割準(zhǔn)確率從最高的86.19%提升到87.11%,最大分割準(zhǔn)確率從最高的91.90%上升到92.57%.
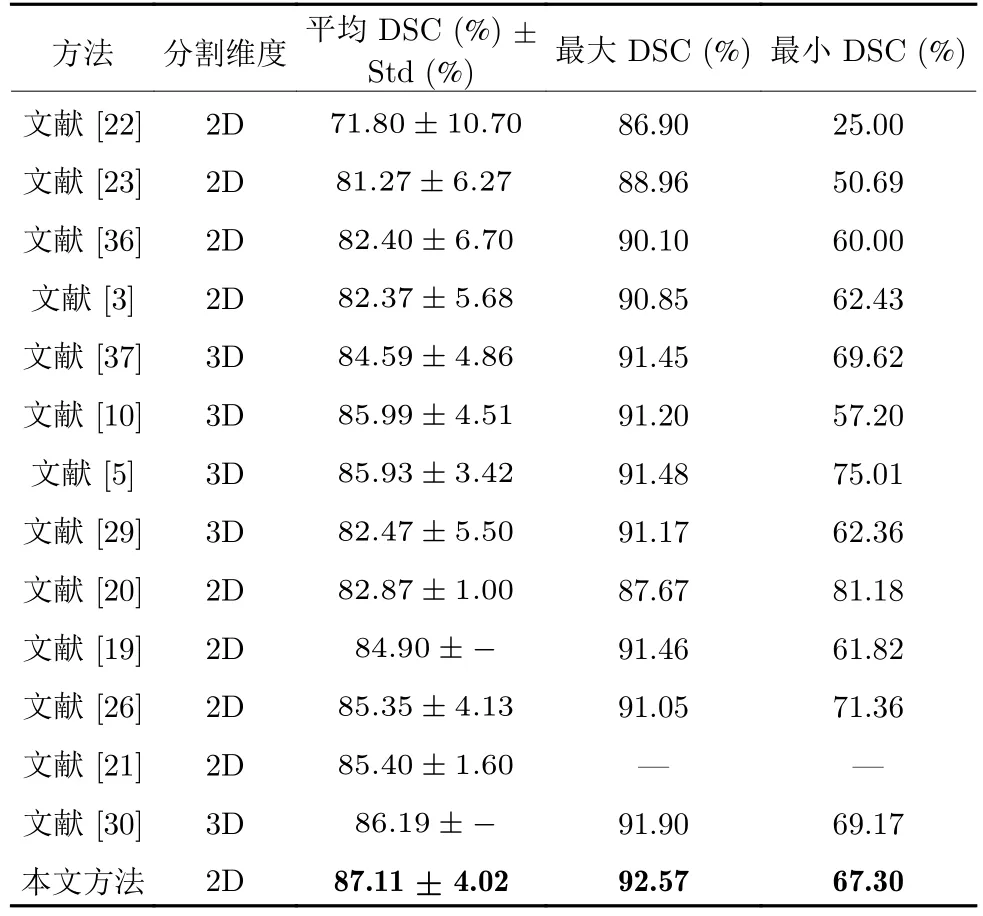
表5 NIH 數(shù)據(jù)集上不同分割方法結(jié)果比較(“——”表示文獻(xiàn)中缺少參數(shù)說明)Table 5 Comparison of different segmentation methods on NIH dataset (“——” indicates a lack of reference in the literature)
MSD 胰腺數(shù)據(jù)集上實驗結(jié)果如表6 所示,本文方法與具有代表性的胰腺基準(zhǔn)分割方法進(jìn)行了比較.相比于二維分割方法[28],平均DSC 分割準(zhǔn)確率從84.71%提升到85.13%,標(biāo)準(zhǔn)差從7.13% 降到5.17%,顯著提升了胰腺分割方法的穩(wěn)定性;最小分割準(zhǔn)確率從58.62% 上升到68.24%,提高了困難樣本的分割準(zhǔn)確率.相比于三維胰腺分割方法[38-40],平均DSC 分割準(zhǔn)確率從最高的84.22%提升到85.13%;最大和最小分割準(zhǔn)確率均有所提升.
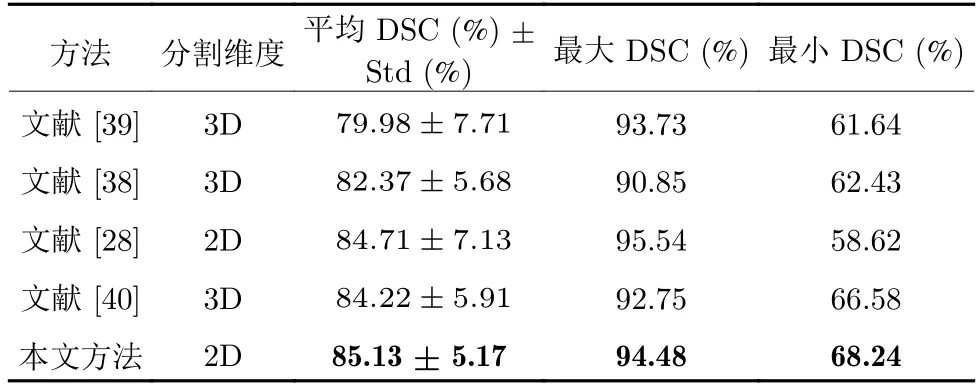
表6 MSD 數(shù)據(jù)集上不同分割方法結(jié)果比較Table 6 Comparison of different segmentation methods on MSD dataset
本文方法在NIH 及MSD 胰腺數(shù)據(jù)集上箱線圖如圖7 所示.本文對部分結(jié)果進(jìn)行了展示,如圖8、圖9 所示.選取了5 個受試者樣本,同一行為同一個受試者不同切片的胰腺分割結(jié)果.藍(lán)色實線代表預(yù)測結(jié)果,紅色實線代表真實標(biāo)簽.從圖中可以看出,本文方法分割結(jié)果和真實標(biāo)簽非常接近.
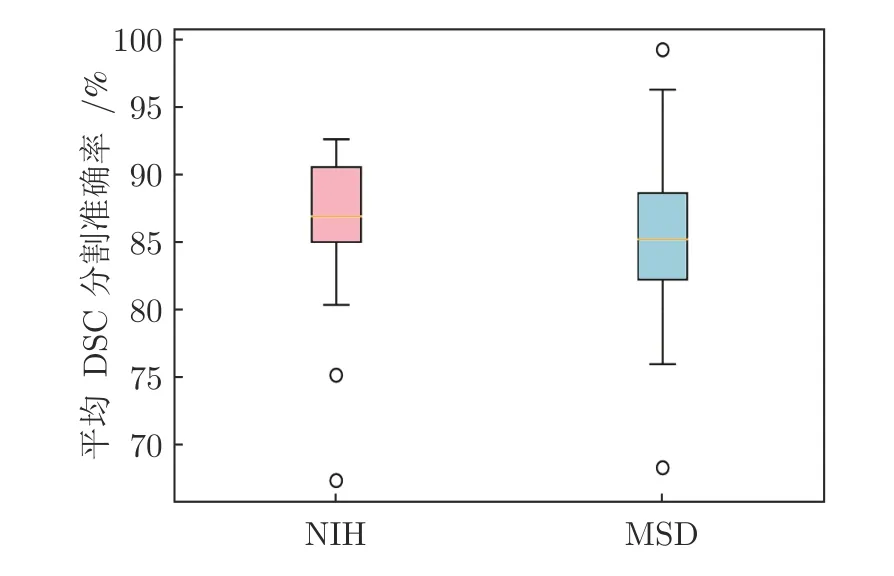
圖7 本文方法在NIH 數(shù)據(jù)集及MSD 數(shù)據(jù)集上箱線圖Fig.7 Box plot of the method in this paper on NIH dataset and MSD dataset
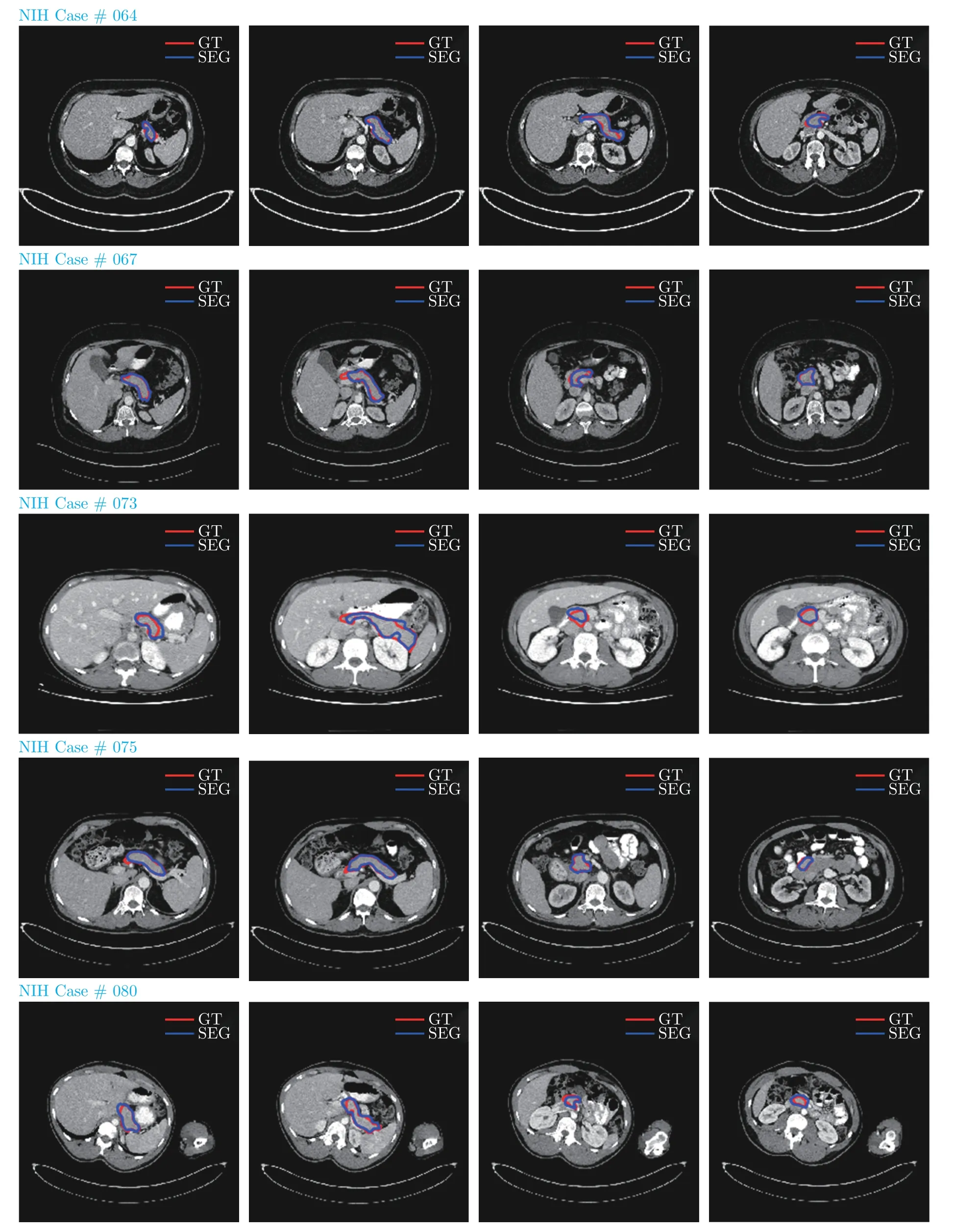
圖8 NIH 數(shù)據(jù)集分割結(jié)果對比Fig.8 Comparison of segmentation results on NIH dataset
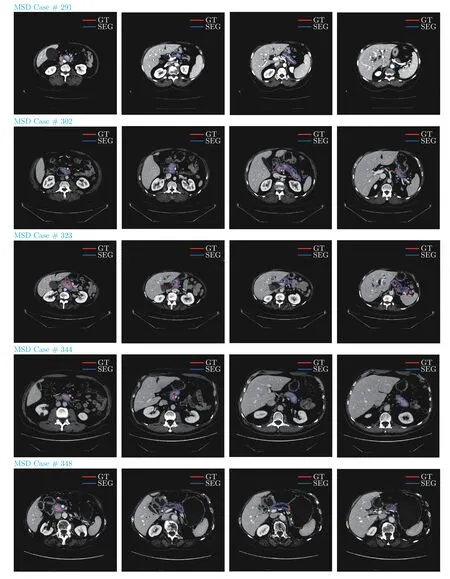
圖9 MSD 數(shù)據(jù)集分割結(jié)果對比Fig.9 Comparison of segmentation results on MSD dataset
3.3.4 輸入切片數(shù)目對分割結(jié)果的影響
為進(jìn)一步說明胰腺輸入切片數(shù)目對本文方法的影響,將切片數(shù)目輸入分別設(shè)置為3、5、7 進(jìn)行實驗比較,如表7 和表8 所示.隨著胰腺輸入切片數(shù)目的增加,平均DSC 分割準(zhǔn)確率和最大DSC 分割準(zhǔn)確率均有小幅度提升,最小DSC 分割準(zhǔn)確率提升更為明顯.可以看出,增加切片數(shù)目對于分割困難樣本具有較大的幫助.對于胰腺器官邊界模糊的困難樣本、胰腺周圍脂肪與十二指腸灰度分布較為接近的困難樣本以及切片中分割目標(biāo)較小的困難樣本,結(jié)合更多的切片數(shù)目能夠明顯提升目標(biāo)分割精度.
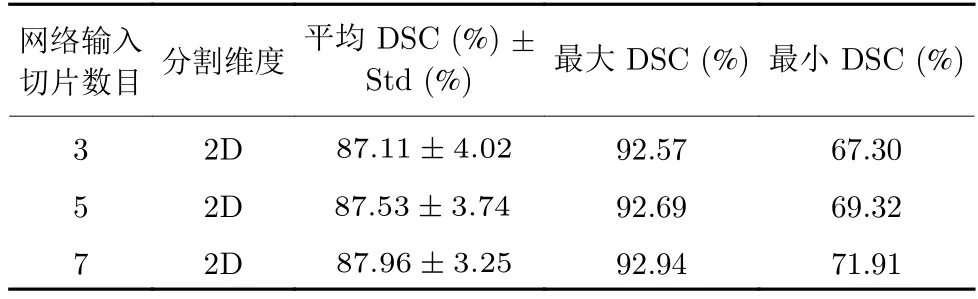
表7 NIH 數(shù)據(jù)集不同網(wǎng)絡(luò)輸入切片數(shù)目分割結(jié)果比較Table 7 Comparison of the segmentation of different network input slices on NIH dataset
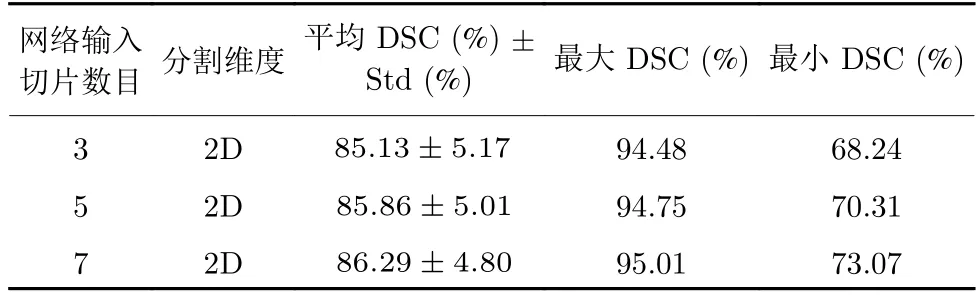
表8 MSD 數(shù)據(jù)集不同網(wǎng)絡(luò)輸入切片數(shù)目分割結(jié)果比較Table 8 Comparison of the segmentation of different network input slices on MSD dataset
3.3.5 網(wǎng)絡(luò)參數(shù)量及時間消耗
本文使用UNet 作為基礎(chǔ)骨干網(wǎng)絡(luò),除粗分割階段,后續(xù)分割階段共享網(wǎng)絡(luò)參數(shù),減少了參數(shù)量.相比于FCN[2]經(jīng)典分割網(wǎng)絡(luò),提出的分割模型具有更少的參數(shù)量,如表9 所示.雖然相比于單階段的UNet[15],3D UNet[41],AttentionUNet[42]和UNet++[43]等分割網(wǎng)絡(luò),參數(shù)量有所增加,但是單階段的分割方法分割精度較低;相比于Fix-point[3]使用FCN 作為骨干網(wǎng)絡(luò)并且利用三個軸狀面分別訓(xùn)練模型分割胰腺,本文參數(shù)量顯著減少;相比于GGPFN[28],雖然參數(shù)量有所增加,但是分割精度有所提升.
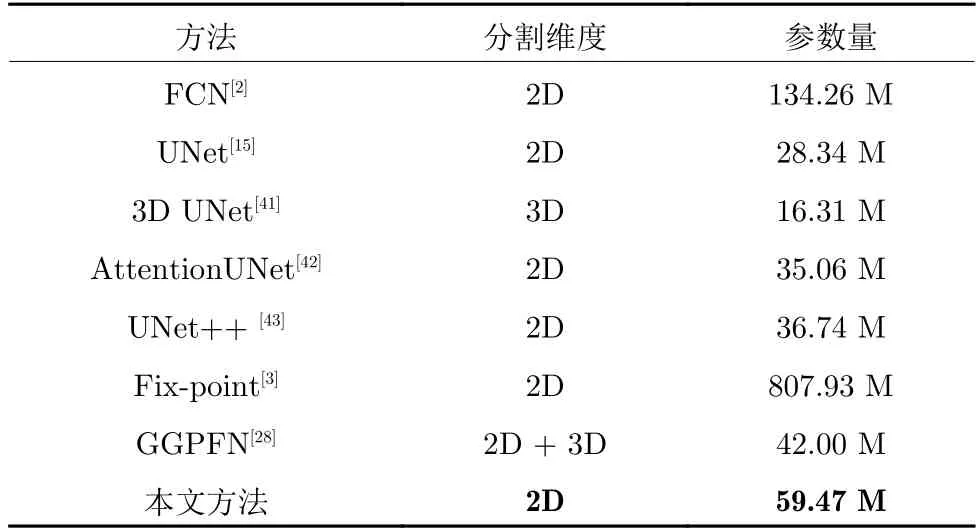
表9 不同分割方法參數(shù)量比較Table 9 Comparison of the number of parameters of different segmentation methods
文獻(xiàn)[44]使用胰腺器官的三個軸狀面作為輸入訓(xùn)練模型,并且分割階段使用額外兩個模型融合視覺特征,增加了時間消耗,如表10 所示.文獻(xiàn)[23]在三個軸狀面上分別進(jìn)行定位、分割,在Titan X(12 GB)GPU 上訓(xùn)練了9~12 個小時.文獻(xiàn)[22]使用由下至上的方法,首先使用超像素分塊,然后基于超像素分塊集成分割結(jié)果,每個階段分開訓(xùn)練.而本文胰腺分割方法使用端到端的訓(xùn)練方法,降低了每個病例的平均測試時間.文獻(xiàn)[3]使用固定點方法,分別使用三個FCN 訓(xùn)練胰腺的三個軸狀面輸入圖像,循環(huán)使用細(xì)分割掩碼位置信息優(yōu)化分割掩碼,顯著增加了時間消耗.相比于上述方法,本文胰腺分割方法雖然增加了循環(huán)顯著性模塊和校準(zhǔn)模塊,但循環(huán)顯著性模塊和校準(zhǔn)模塊設(shè)計簡單并且基于矩陣運算,運算時間增加不明顯,并且本文方法僅基于橫斷面作為輸入,使用UNet[14]而非FCN[2]作為分割骨干網(wǎng)絡(luò),顯著減少參數(shù)量及前饋傳播時間.相比于文獻(xiàn)[36]基于循環(huán)卷積神經(jīng)網(wǎng)絡(luò)使用多切片作為輸入,本文方法訓(xùn)練及測試時間有所增加,但分割精確度提升明顯.
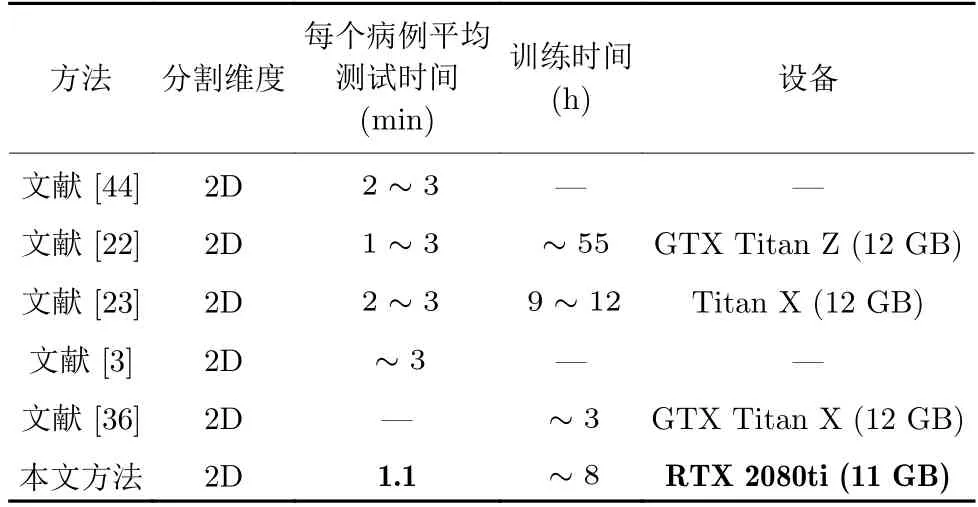
表10 不同分割方法時間消耗比較(“——”表示文獻(xiàn)中缺少參數(shù)說明)Table 10 Comparison of time consumption of different segmentation methods (“——” indicates a lack of reference in the literature)
4 總結(jié)與展望
針對胰腺分割面臨的問題,本文提出了基于循環(huán)顯著性校準(zhǔn)網(wǎng)絡(luò)的胰腺分割方法.其主要貢獻(xiàn)在于:1)利用更多的階段上下文信息聯(lián)合訓(xùn)練,改善了傳統(tǒng)由粗到細(xì)胰腺分割方法僅使用粗分割階段輸出掩碼定位框坐標(biāo)信息作為細(xì)分割網(wǎng)絡(luò)輸入的先驗,導(dǎo)致缺少階段上下文信息的問題;2)使用卷積自注意力校準(zhǔn)模塊跨順序、平行化利用相鄰切片上下文信息的同時,自動校準(zhǔn)每一分割階段輸出掩碼,解決了胰腺與鄰近器官密度較為接近、組織重疊部分界限分辨困難導(dǎo)致的誤分割問題.和其他胰腺分割方法相比,本文方法顯著提高了樣本平均DSC分割準(zhǔn)確率并改善了困難樣本分割結(jié)果.本文方法可用于輔助醫(yī)療診斷,后續(xù)研究將考慮如何進(jìn)一步利用更多的階段上下文信息及切片上下文信息改善分割結(jié)果的同時,使用模型蒸餾方法輕量化模型框架.
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
建筑創(chuàng)作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
祝您健康(1987年2期)1987-12-30 09:52:28
