機器學習在量子通信資源優化配置中的應用*
2022-12-05 11:12:54陳以鵬劉靖陽朱佳莉方偉王琴
物理學報 2022年22期
關鍵詞:模型
陳以鵬 劉靖陽 朱佳莉 方偉 王琴?
1)(南京郵電大學,量子信息技術研究所,南京 210003)
2)(南京郵電大學,寬帶無線通信與傳感網教育部重點實驗室,南京 210003)
在未來量子通信網絡的大規模應用中,如何根據當前用戶實際情況實現資源優化配置,比如選擇最優量子密鑰分發協議(quantum key distribution,QKD)和最優系統參數等,是實現網絡應用的一個重要考察指標.傳統的QKD 最優協議選擇以及參數優化配置方法,大多是通過局部搜索算法來實現.該方法需要花費大量的計算資源和時間.為此,本文提出了將機器學習算法應用到QKD 資源優化配置之中,通過回歸機器學習的方式來同時進行不同情境下的最優協議選擇以及最優協議的參數優化配置.此外,將包括隨機森林(random forest,RF)、最近鄰(k-nearest neighbor,KNN)、邏輯回歸(logistic regression)等在內的多種回歸機器學習模型進行對比分析.數據仿真結果顯示,基于機器學習的新方案與基于局部搜索算法的傳統方案相比,在資源損耗方面實現了質的跨越,而且RF 在多個回歸評估指標上都取得了最佳的效果.此外,通過殘差分析,發現以RF 回歸模型為代表的機器學習方案在最優協議選擇以及參數優化配置方面具有很好的環境魯棒性.因此,本工作將對未來量子通信網絡實際應用起到重要的推進作用.
1 引言
量子密鑰分發(quantum key distribution,QKD)是量子保密通信的核心,其安全性基于物理學基本原理,原則上能夠為遠距離通信的雙方(Alice和Bob)提供無條件安全的信息保障.第一個QKD 協議由Bennett和Brassard[1]于1984 年提出,此后簡稱BB84 協議,其安全性已經得到嚴格的數學證明[2,3],也是目前應用最為廣泛的一種QKD 協議.原始的BB84 協議需要采用理想的單光子源,但是在實際應用中,大多采用弱相干光源(weak coherent source,WCS),該類光源中的多光子成分使得竊聽方(eve)實施光子數分離攻擊(PNS)成為可能.為了解決PNS 攻擊,科學家提出了誘騙態方法[4?6].此外,探測端的測信道漏洞也是Eve 攻擊的對象[7?10].為了關閉探測器端的諸多側信道漏洞,加拿大Lo等[11]和英國Braunstein等[12]于2012 年各自獨立地提出了測量設備無關量子密鑰分發(measurement-device-independent,MDI)協議.MDI-QKD 結合誘騙態方案可以免疫所有針對探測段的攻擊手段,因此提出之后受到了廣泛的關注[13?18].在實際應用中,MDI-QKD的安全密鑰率和傳輸距離受統計起伏效應影響嚴重.在此背景下,雙場量子密鑰分發協議(twin-field quantum key distribution,TF-QKD)于2018年被Lucamarini等[19]提出.TF-QKD 保留了MDIQKD的測量設備無關特性,并打破了無中繼量子信道碼率-距離限制(PLOB 界)[20,21],進一步提高了量子通信的實用性能,這也使其成為目前關注度最高的QKD 協議之一[22?24].
在實際執行量子密鑰分發之前,首先需要根據用戶實際情況選擇合適的密鑰分發協議[25,26],同時對選定的量子密鑰分發協議進行相關參數的優化配置[27],從而確保通信雙方之間能夠實現最優的安全密鑰共享,本文將這個過程稱之為最優協議選擇以及最優參數配置.傳統的解決方案可以使用遍歷收索方法或維度下降局域收索(LSA)優化算法[28].但是以上方法在實際應用時需要消耗大量的計算資源和計算時間,無法滿足實時量子通信的需求.另一方面,由于機器學習在數據處理方面的優勢,其常被用于協助解決量子信息中的部分問題[29,30].鑒于此,本文考慮使用機器學習方案替代上述傳統方案,即通過機器學習實現回歸模型來建模傳統方案.仿真結果表明,相較于傳統方案,機器學習方案大幅減少了時間資源消耗,因而顯示出在實時量子通信應用中的巨大應用前景.
2 機器學習方案
監督機器學習過程可以簡單解釋為通過特征數據到標簽數據的映射,去學習一個具有指定數據預測功能的機器學習模型,即基于某種機器學習算法F(x)通過X →Y的映射過程去學習獲取具有數據預測功能的ML 模型f(x).以幾種主流的量子密鑰分發協議:BB84-,MDI-以及TF-QKD為問題背景,并主要從數據的獲取和機器學習模型的構建兩方面來介紹本文工作.
2.1 ML 標簽數據與特征數據的獲取
為簡單起見,本文在評價最優QKD 協議時暫不考慮系統安全等級等因素,僅把安全密鑰速率(R)作為評定特定情境下最優QKD 協議的關鍵指標.在實際QKD 過程中,R值與下面幾種系統因素緊密相關:探測器的暗記數率(Y0)、探測效率(η)、本底誤碼(ed),通信發送方發送的光脈沖數(N),通信雙方間的通信距離(L).將系統參數組合成5 維向量X=[Y0,ed,η,N,L],并將其作為ML的特征數據格式.
在討論ML 所需標簽數據格式之前,首先對獲取仿真數據過程中所涉及到的3 種主流QKD 協議及其誘騙態方法進行簡要論述.對于BB84 協議,使用的是三強度誘騙態方法[5].在該方案中,參數優化過程所涉及到的主要配置參數包括:信號態強度μ、誘騙態強度ν、發送信號態脈沖的概率Pμ、發送誘騙態脈沖的概率Pν、信號態制備在Z 基的概率Pzμ、誘騙態制備在X 基的概率Pxν.對于MDI 協議,使用的是四強度誘騙態方法[31],參數優化涉及到的配置參數主要包括:信號態強度μ、誘騙態強度ν和ω、發送信號態μ的概率Pμ、發送誘騙態ν的概率Pν、發送誘騙態ω的概率Pω.對于TF 協議,使用的是四強度誘騙態方法[32],對應系統參數包括:信號態強度μ、誘騙態強度ν,ω及其對應選擇概率Pμ,Pν,Pω,以及失敗概率?等.
為了在ML 標簽數據格式中表征所選的最優協議,本工作將3 種協議對應編號1,2,3,并將其作為標簽向量的一個維度.則不同協議的標簽格式有:YBB84=[μ,ν,Pμ,Pν,Pzμ,Pxν,1],YMDI=[μ,ν,ω,Pμ,Pν,Pω,2],YTF=[μ,ν,ω,Pμ,Pν,Pω,?,3].研 究發現BB84 協議和MDI 協議的標簽向量格式均為6維,而TF 協議的標簽向量格式為7 維.為了構建統一格式的標簽向量,采用占位法來抹平上述差異,即YBB84=[μ,ν,Pμ,Pν,Pzμ,Pxν,NUM,1],YMDI=[μ,ν,ω,Pμ,Pν,Pω,NUM,2].進一步地,得益于占位方式的使用,不同協議能夠很好的保證參數維度的一致性,這更有利于本工作推廣到其他多種不同的QKD 協議.
在標簽數據格式和特征數據格式構建完成之后,需要獲取通用的特征數據和標簽數據.根據實際經驗,本文將特征數據格式中的5 個系統參數限制到表1 所示的特征范圍中.本工作在5 個系統參數的特征范圍內進行等間隔的取值,以間隔n為例,則可以生成n5特征數據.這里需要注意一點,對于本底誤碼的取值而言,TF 協議是其他兩個協議的4 倍.隨后利用不同QKD 協議的密鑰生成公式,并結合LSA 算法優化不同協議的配置參數,以獲取3 份數據量大小為n5的標簽數據.接著通過比較不同協議的密鑰率大小,將3 個協議關聯起來,即直接根據密鑰率R將無效數據剔除后的YBB84,YMDI和YTF,這3 份標簽數據合并為一份標簽數據Y.至此,便得到了ML 所需的特征數據X和標簽數據Y.

表1 系統參數的特征范圍Table 1.Characteristic range of system parameters.
2.2 數據集劃分及回歸模型構建
特征數據和標簽數據統稱為ML 數據集,經過上述的相關操作整個數據集的大小在10 萬量級.隨后本工作采用歸一化(normalization)操作來加速ML 模型對數據集的學習擬合,表示為núm=(num– min)/(max– num).從數據集中隨機劃分出80%用于ML 模型訓練的訓練集和20%用于ML 模型性能評估的測試集.后續,在訓練集上先后進行隨機森林、最近鄰、邏輯回歸等ML 模型的學習訓練.鑒于RF 模型取得了最佳的預測效果,接下來僅以RF為例,介紹其構建的主要過程.
隨機森林(random forests,RF)[33]是基于Bagging(bootstrap aggregation)集成算法的典型范例,其基本單元是決策樹(decision tree)[34][35],直觀理解就是眾多決策樹構成一片隨機森林.在機器學習任務中,隨機森林既可以用于分類任務又可以用于回歸任務,本文主要是利用RF 算法訓練一個回歸模型.RF 回歸模型,是由眾多回歸決策樹集成而來的.回歸樹在訓練時,每確定一個節點,就會將特征數據對應的特征空間進行一次劃分,劃分形成的單元會以該單元內的均值作為其輸出值.RF 中除了森林這一重要概念之外,還有隨機的概念.隨機主要有兩種含義:其一,從訓練集中隨機有放回的拿取樣本數據用于決策樹的學習,有放回的隨機抽取就是Bagging 算法的直觀體現;其二,隨機選取特征向量中的特征用于決策樹的學習.隨機的樣本數據、隨機的特征選擇,導致RF 中的決策樹各不相同,而RF 最終輸出的結果則取決于不同決策樹回歸輸出的均值.圖1 展示了本工作中RF 回歸模型的算法框架.
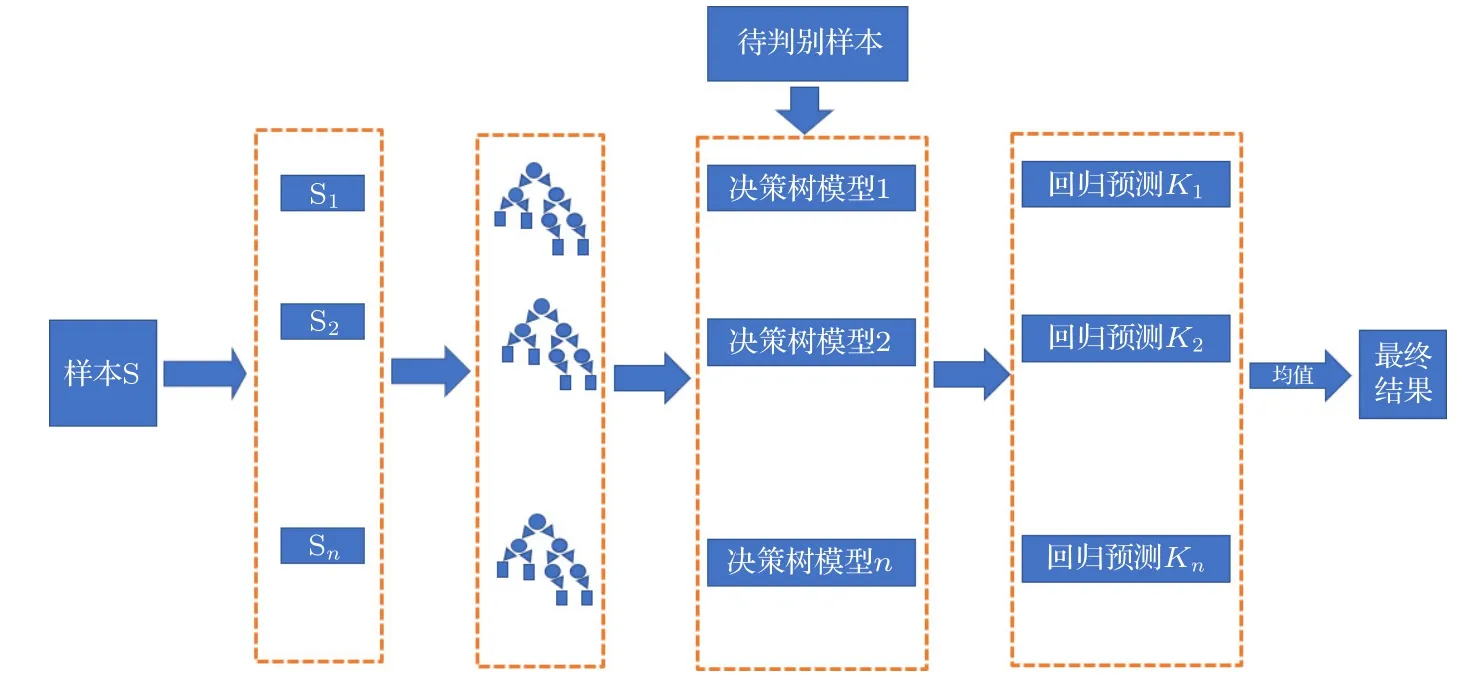
圖1 隨機森林回歸模型的算法框架.Fig.1.The algorithm framework of random forest regression model.
RF 在訓練集上進行學習擬合時,需要對其算法的一些參數進行調優,才能獲取預測效果最好的回歸模型.這里主要使用網格搜索(GridSearch)和交叉驗證(CV)的方法來對Sklearn 中的隨機森林Regressor 模型進行調參.GridSearch 可以理解為在指定參數范圍內按照一定步長將候選參數所有可能的取值進行排列組合,即生成“網格”.而交叉驗證則是將訓練集進一步切分,以常見的K折交叉驗證法為例,訓練集中的K-1 份使用網格參數進行訓練,訓練集中剩余的1 份則用于評估,重復K次并選出K次平均評分最高時的網格參數,進而完成參數調優.本工作中RF 回歸模型的最終調參結果是:n_estimators為90、max_depth為56,min_samples_split為1.其中,第1 個參數用于指定RF 原始訓練集有放回隨機抽取樣本數據所生成的子數據集個數;第2 個參數用于指定生成決策樹的最大深度;第3 個參數用于指定決策樹節點可分的最小樣本數.在完成RF 回歸模型的構建后,對特征數據X中5 個系統參數的重要性進行評估.結果表明:距離L對RF 模型的影響最大;其他幾個系統參數的重要性相對較小,具體的重要性比重如圖2 所示.

圖2 系統參數對隨機森林回歸模型的重要性.Fig.2.Importance of system parameters to RF regression model.
3 方案評估與討論
在測試集上對已獲ML 模型進行性能評估時,需要注意標簽數據Y中包含了協議標號和該協議對應的配置參數.不同于分類模型直接獲取協議標號,本工作的回歸模型需要對回歸預測的協議標號進行取整操作才能正確的實現協議分類.下面簡要介紹3 種常用回歸模型的性能評估指標,并對本文的RF,KNN,LR 模型進行比較分析.
平均絕對誤差(mean absolute error,MAE),用于評估回歸模型預測結果和真實結果差異的平均值,其值越小說明ML 模型對數據的擬合效果就越好,可以表示為:均方誤差(mean squared error,MSE),用于計算預測結果和真實結果對應樣本點誤差平方和的均值,其值越小說明ML 模型在數據預測方面的性能就越好,可以表示為:決定系數(coefficient of determinationRsquared,Rsquared),一般被認為是衡量線性回歸相對較好的指標,其取值范圍在0—1 之間,越靠近1 說明ML 模型對數據的擬合效果就越好,可以表示為:上述表達式中的N為測試集數據量、yi為測試集中的真實結果、yi為ML 模型使用測試集預測出來的結果、這里將回歸模型的評估指標以及預測準確率如表2 所示.
由表2 可知,基于相同訓練集獲取的RF 回歸模型相較于KNN和LR 模型,在MAE,MSE,R2預測準確率等性能指標上都取得了最好的表現,這也說明RF 適用于最優協議選擇和參數優化配置的任務.此外,將ML 方案和傳統方案在個人電腦上的具體耗時情況如表3 所示.個人電腦的硬件配置為:Intel(R)Core(TM)i1-9750H CPU @2.60GHz;NVIDIA GeForce GTX 1650;16 GB DDR42667 MHZ.具體的時間資源損耗統計過程,本工作在指定某一用戶需求下,先后使用兩種不同方案進行時間統計.機器學習方案:在獲取訓練完成的模型后,將需求數據輸入模型,模型可以在短短數秒之內給出協議選擇以及參數配置.傳統方案:根據提供的用戶需求數據,采用LSA 優化并獲取3 個協議的安全碼率,之后對3 個協議的碼率大小進行比對,將成碼率最大的協議作為最優協議.該過程的時間損耗主要集中在采用LSA 對協議參數進行優化獲取最佳碼率這個過程,耗時超過24 h.從表3 結果來看,兩種方案選擇的協議相同且協議配置參數的殘差在0.025 以內,但是兩者的耗時卻存在著巨大的差異,這進一步表明機器學習在很大程度上滿足了簡化并加速量子通信資源配置的目的.
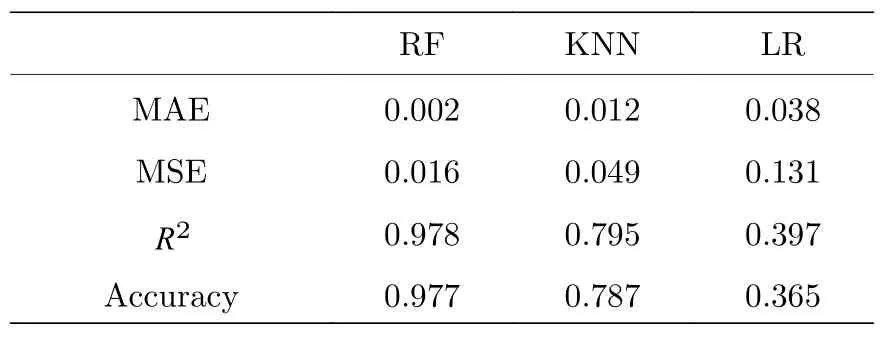
表2 不同回歸模型的評估對比Table 2.Evaluation and comparison of different regression models.

表3 時間資源損耗記錄表Table 3.Time resource wastage table.
為了更加直觀地展示RF 方案的可行性,接下來就RF的殘差和混淆矩陣進行可視化分析.圖3為RF 回歸模型在訓練集和測試集上的殘差圖,這里的殘差分析針對的是協議的配置參數,即標簽數據Y向量中處于第一維的配置參數.圖3 中的藍色點為訓練集上的殘差情況,綠色點為測試集上的殘差情況.經統計,多數偏差都低于0.025,這表明RF 機器學習方案具有相對較好的魯棒性.圖4展示了協議選擇的混淆矩陣,主對角線的協議選擇為正確的選擇情況.從圖4 可以看出,RF 模型在不同情境下都能以較大的概率做出正確的協議選擇.通過對混淆矩陣可視化數據的相關計算,可以求得RF 回歸模型的預測準確率在98%左右,這也與表2 中通過函數接口計算的準確率基本相當.

圖3 隨機森林回歸模型的殘差圖Fig.3.Residual diagram of RF regression model.
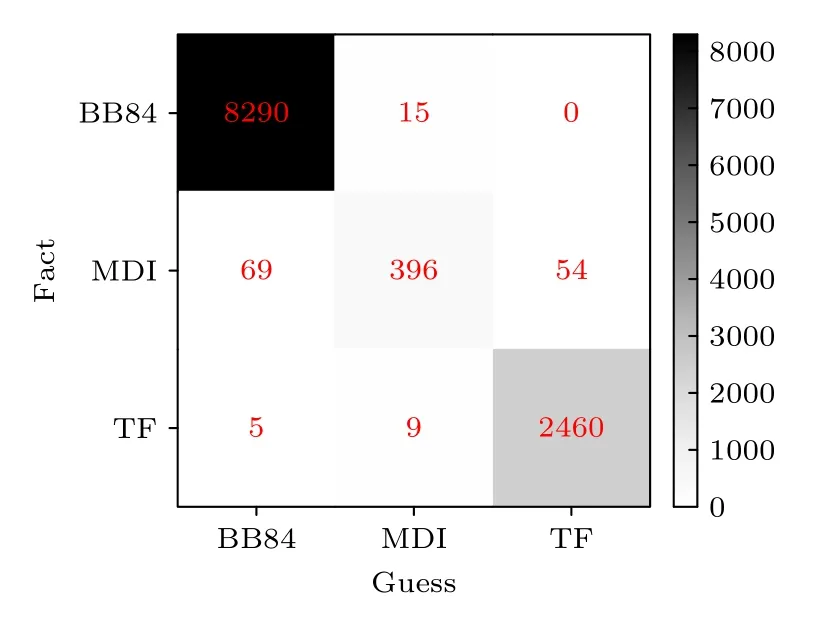
圖4 隨機森林回歸模型的混淆矩陣Fig.4.Residual diagram of RF regression model.
4 總結與展望
本文提出了基于機器學習的最優協議選擇以及優化參數配置的新方案,相較于傳統方案而言,新方案大幅度地減少了時間資源損耗,通過殘差分析證明機器學習方案具有較好的魯棒性.此外,本文詳細地介紹了機器學習方案的流程,主要是通過監督學習去實現滿足協議選擇以及參數配置功能的回歸模型.在構建的多個回歸模型中,RF 模型取得了最佳的表現:均方誤差為0.002、平均絕對誤差為0.016、R2為0.978.綜上,本工作的研究對未來即時量子通信網絡的大規模應用以及多協議高速QKD的發展都有很好的參考價值.
感謝南京郵電大學通信與信息工程學院張春輝老師和周星宇老師的幫助與討論.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
