基于機器學習算法的股指期貨價格預測模型研究
2022-12-07 13:31:24楊學威
軟件工程 2022年12期
楊學威
(青海民族大學經(jīng)濟與管理學院,青海 西寧 810007)
1 引言(Introduction)
宏觀經(jīng)濟背景、金融市場發(fā)展水平和投資者心理預期等多種復雜因素共同驅動金融工具價格變化,使得金融時序價格具有非平穩(wěn)性、非線性和高噪聲的復雜特性[1]。在國內金融市場高速發(fā)展的背景下,金融時序價格預測成為一個亟待解決的難題。伴隨著人工智能技術的進步,機器學習算法為金融時序價格預測帶來了新的研究思路,學界和業(yè)界也致力于運用機器學習算法預測各類金融工具短期趨勢并構建量化擇時策略,以期獲取超額投資收益。
隨著國內量化投資的興起,眾多金融機構已將機器學習廣泛應用于產(chǎn)品定價、風險管理、量化選股、策略管理等領域。對于非線性、非平穩(wěn)、更新頻率快的金融市場數(shù)據(jù),相較于傳統(tǒng)統(tǒng)計分析方法,機器學習算法能夠迅速挖掘出市場上更多潛在信息。本文選用支持向量回歸(Support Vector Regression,SVR)、長短期記憶網(wǎng)絡(Long Short-Term Memory,LSTM)、隨機森林(Random Forest,RF)、極端梯度提升樹(Extreme Gradient Boosting,XGBoost)四種常用的機器學習算法構建滬深300股指期貨價格預測模型,并利用貝葉斯算法對模型進行超參數(shù)優(yōu)化,比較其預測效果,為量化擇時策略開發(fā)提供價格預測基礎。
2 機器學習算法(Machine learning algorithms)
2.1 支持向量回歸
SVR模型利用支持向量機分類的原理,通過在損失函數(shù)中加入松弛變量提高模型回歸擬合性能[2]。SVR模型能有效處理多維度樣本,能夠擺脫神經(jīng)網(wǎng)絡預測模型的局部最優(yōu)問題,達到唯一的全局最優(yōu)解。SAPANKEVYCH等[3]系統(tǒng)梳理并總結了SVR模型在時間序列預測的相關研究文獻。王洪平[4]運用SVR模型根據(jù)金融機構貸款余額預測貨幣供應量。肖陽等[5]基于三種不同的核函數(shù)建立了SVR多因子選股模型,并通過網(wǎng)格搜索和交叉驗證法確定了模型參數(shù)的最優(yōu)取值,回測結果表現(xiàn)優(yōu)異,其中高斯核函數(shù)績效表現(xiàn)最優(yōu),年化收益達到24.76%。
2.2 長短期記憶網(wǎng)絡
LSTM模型屬于循環(huán)神經(jīng)網(wǎng)絡(Recurrent Neural Network,RNN)的一種,其特殊之處在于RNN僅有記憶暫存的功能,而LSTM兼具長短期記憶功能,解決了RNN存在的長期依賴問題。自HOCHREITER等[6]提出LSTM之后,GERS等[7]又加入了遺忘門對LSTM結構進行完善,自此形成應用至今的LSTM完整結構。AHMED等[8]將損失函數(shù)與LSTM模型組合構建外匯損失函數(shù)長短期記憶模型(FLFLSTM),預測外匯市場歐元美元匯兌價格,并與其他模型進行對比分析,其研究表明,在外匯市場FLF-LSTM模型預測效果優(yōu)于其他模型。GIANG等[9]提出了兩種基于LSTM的股價預測模型,在美國、德國和越南三個股票數(shù)據(jù)集上的實驗結果表明,此模型在預測股價波動趨勢方面優(yōu)于其他模型。LI等[10]利用差分整合移動平均自回歸模型(ARIMA)和LSTM,選取三種股票市場指數(shù)的13 個技術指標構建價格預測模型,預測其收盤價并與其他模型進行對比分析,研究結果表明LSTM模型預測精度優(yōu)于其他模型。
2.3 隨機森林
RF作為近年新興起的、高度靈活的集成算法,具有不易陷入過擬合、抗噪能力強、不用做特征選擇、能夠平衡誤差和處理高維數(shù)據(jù)且數(shù)據(jù)集無須標準化及訓練速度較快等優(yōu)點。SIVAMANI等[11]基于社交媒體情感分析,利用包括RF在內的機器學習算法研究投資者情緒對公司股價的影響,研究表明:公眾對公司的主觀感知可以作為驅動其股價增長的因子。GHOSH等[12]采用RF和LSTM作為訓練算法,證明了它們在預測標普成分股價格定向變動方面的有效性。
2.4 極端梯度提升樹
XGBoost是陳天奇博士在梯度提升決策樹算法的基礎上,提出的一種改進算法。XGBoost利用并行化提高其運行速度,同時引入了損失函數(shù)的二階偏導,預測效果更具一般性。衣靜[13]通過將集合經(jīng)驗模態(tài)分解(EEMD)與XGBoost算法結合,構建了EEMD-XGBoost組合模型,利用模型預測深證綜合指數(shù)的日收盤價,并對模型進行分析優(yōu)化。LIU等[14]通過XGBoost篩選評價指標,利用遺傳算法優(yōu)化BP神經(jīng)網(wǎng)絡,構建上證50ETF期權價格預測模型。谷嘉煒等[15]提出XGBoost-ESN的股價預測組合模型,并使用網(wǎng)格搜索法對XGBoost模型和回聲狀態(tài)網(wǎng)絡模型(ESN)進行參數(shù)優(yōu)化。研究結果表明,改進的XGBoost-ESN組合模型能有效減少預測誤差,對股票價格預測的精度更高。
3 模型基本原理(Model fundamentals)
3.1 SVR模型
SVR模型算法原理如下。

其中,φ(?)為映射函數(shù),φ(xi)是將x映射到高維特征空間的特征向量。
SVR的損失函數(shù)度量:
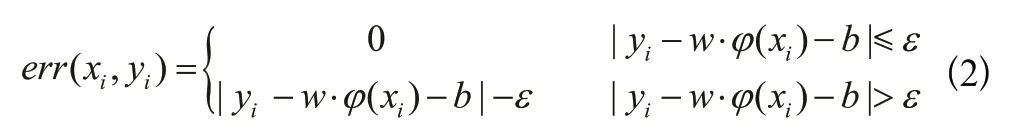
損失函數(shù)度量在加入松弛變量后:

其中,K(?)為核函數(shù),核函數(shù)的選擇也是SVR算法的關鍵問題之一。表1中給出了SVR模型常用的幾種核函數(shù)。本文選用金融時序研究經(jīng)常使用的高斯核徑向基函數(shù)(RBF),它具有出色的性能,被廣泛應用于分類和回歸問題。

表1 常用核函數(shù)Tab.1 Commonly used kernel functions
3.2 LSTM模型
LSTM通過對RNN模型結構的優(yōu)化,能有效避免RNN存在的梯度爆炸或梯度消失問題[16]。LSTM與RNN的區(qū)別在于,RNN結構簡單,只有一個tanh層,而LSTM內部結構包含四個交互層:遺忘門、輸入門、內部記憶單元、輸出門。標準RNN結構如圖1所示,LSTM結構如圖2所示。
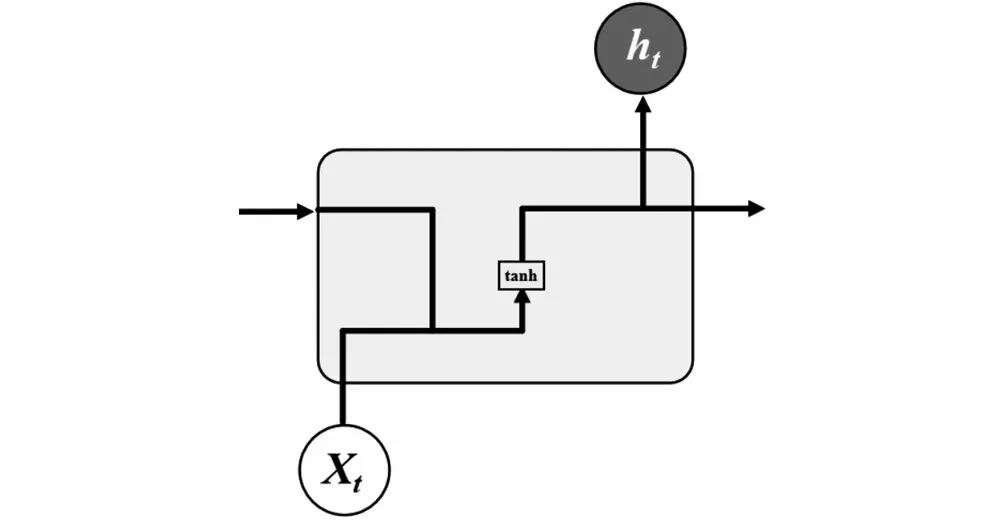
圖1 標準RNN結構Fig.1 Standard RNN structure
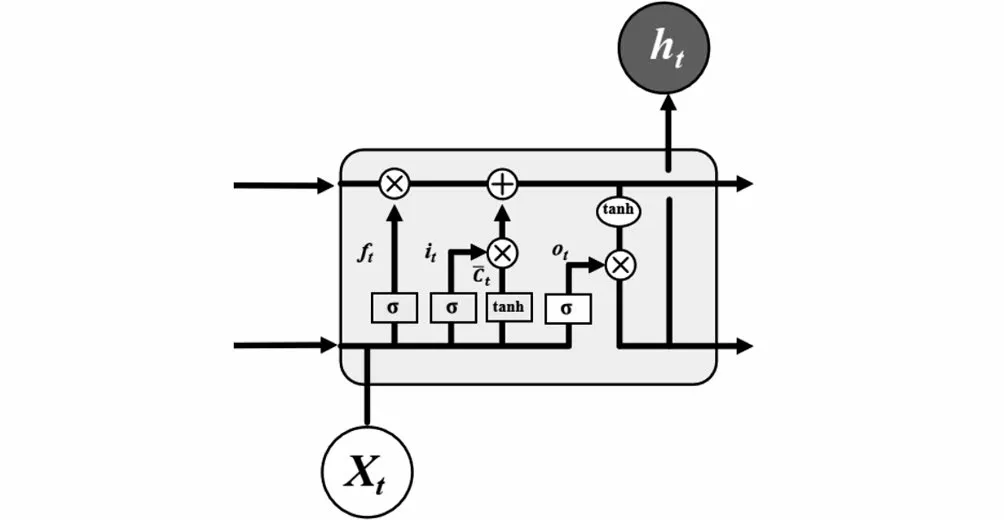
圖2 LSTM結構Fig.2 LSTM structure
LSTM中的第一步是通過遺忘門決定信息的丟棄和保留,其結構如圖3所示,算法表達式(5)如下:
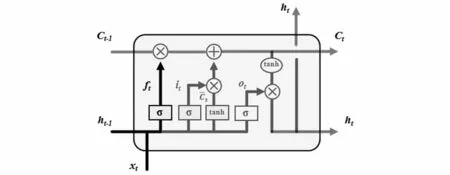
圖3 遺忘門結構Fig.3 Forget gate structure
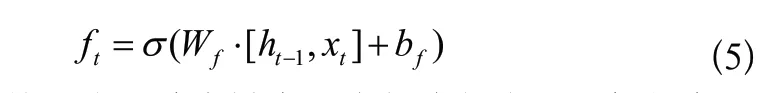
LSTM中的第二步是確定被存放在細胞狀態(tài)中的新信息,其結構如圖4所示,算法表達式(6)如下:
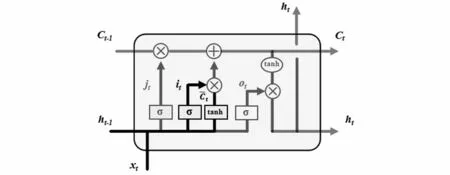
圖4 輸入門結構Fig.4 Input gate structure
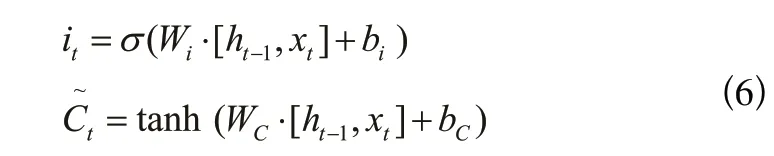
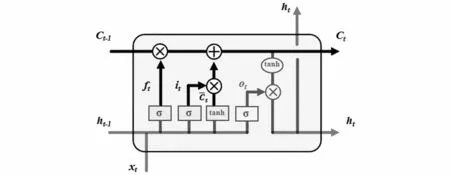
圖5 更新狀態(tài)結構Fig.5 Update state structure
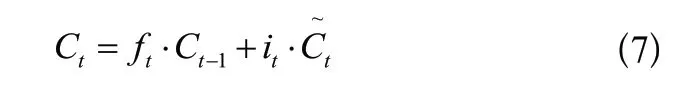
LSTM中的第四步是輸出信息,輸出前需先進行過濾,其結構如圖6所示,算法表達式(8)如下:
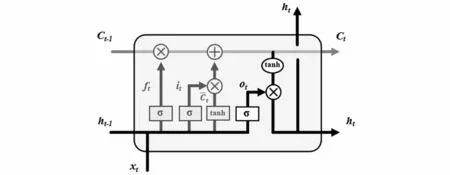
圖6 輸出門結構Fig.6 Output gate structure
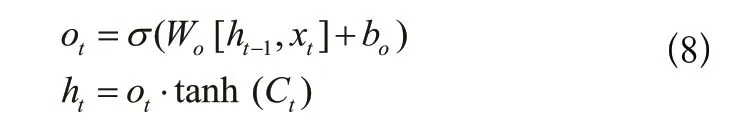
3.3 RF模型
隨機森林是一種集成學習算法,即利用引導聚集算法(Bagging)和決策樹算法(CART)成決策樹的過程;它通過采集多個樣本集,利用決策樹對每個樣本集建模,將所有決策樹組合起來構建成隨機森林,取所有決策樹的結果平均值作為隨機森林輸出。由于各個決策樹之間的具有明顯的差異度,因此組合出的隨機森林具有良好的泛化能力。隨機森林的構造過程如圖7所示。
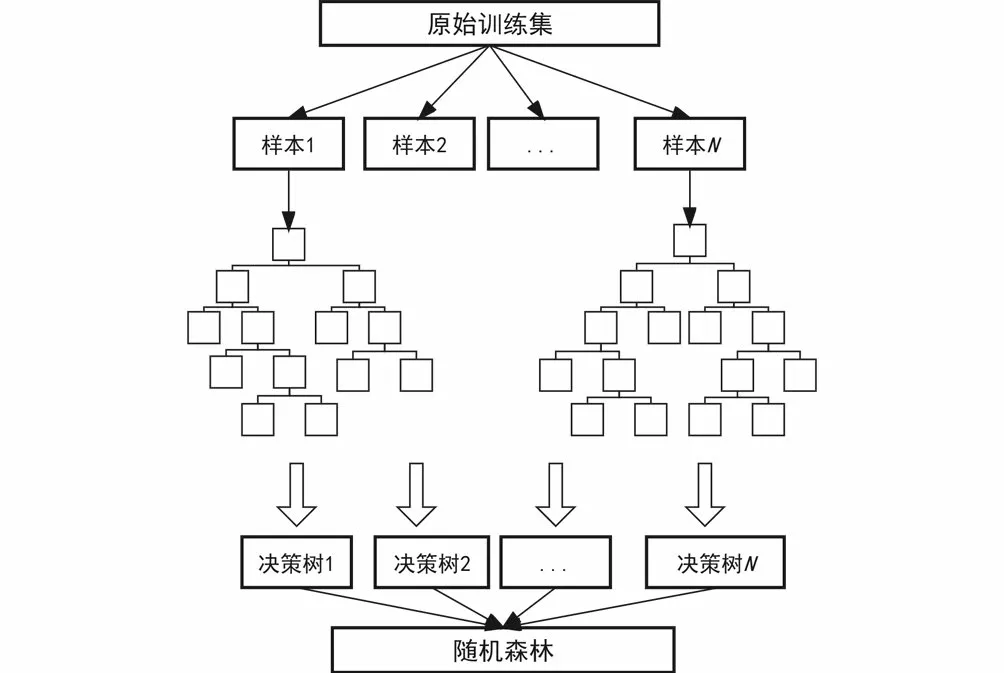
圖7 隨機森林構造過程Fig.7 Random Forest construction process
3.4 XGBoost模型
XGBoost模型通過建立K個回歸樹,使用貪心算法、二次優(yōu)化保證每個決策樹葉子節(jié)點的預測值都是最優(yōu)解,利用交叉驗證選擇最好的參數(shù),加入正則化防止過擬合;具有效率高、效果好、能處理大規(guī)模數(shù)據(jù)、支持自定義損失函數(shù)等優(yōu)點[17]。
XGBoost屬于Boost集成學習方法,應用串行的基學習器,其中第k個學習器的學習目標是前k-1 個學習器與目標輸出的殘差,最終的學習器表示如下:
XGBoost的目標函數(shù)會加入正則化項,決策樹會在后期進行決策樹剪枝防止過擬合,加入正則化項后的目標函數(shù)如下:
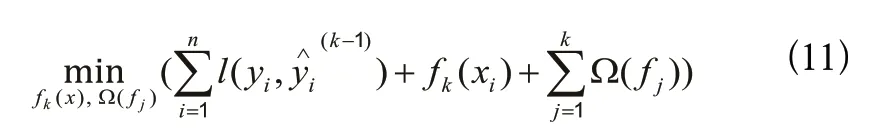
正則化項表示如下:
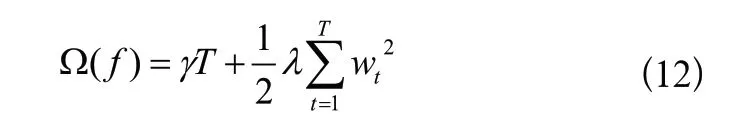
其中,T是基回歸樹的葉子節(jié)點總數(shù),是基回歸樹的第t個葉子節(jié)點的輸出值,γ、λ是正則化項的系數(shù),屬于超參數(shù)。
當訓練第k個基回歸樹時,前k-1個基回歸樹的正則化項是一個常數(shù),我們單獨把它們提取到C(常數(shù))中,目標函數(shù)變成:

將上面推出來的損失函數(shù)帶回目標函數(shù),化簡得到公式(16):

這是T個關于wt的獨立二次函數(shù),讓每一個二次函數(shù)取最小值,即
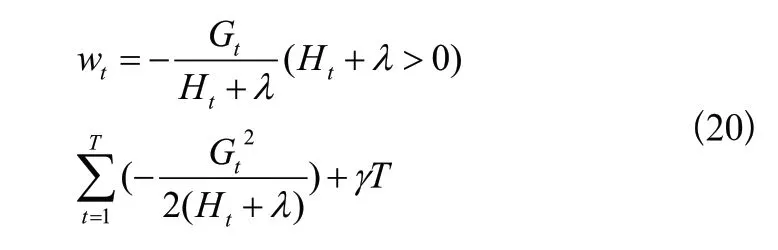
確定基回歸樹結構的方法主要是遞歸地確定葉子節(jié)點是否適合被延伸。對于某個我們想要延伸的葉子節(jié)點tx,計算其延伸前的目標函數(shù)值:
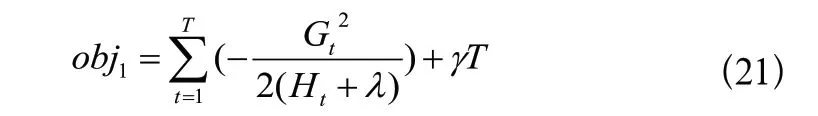
利用貪心算法遍歷所有特征的所有可能取值,計算每個取值延伸后的目標函數(shù)值,tx分割出兩個新的葉子節(jié)點t1與t2:
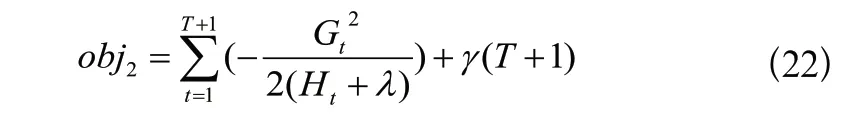
兩者求差,表示分割后的信息增益:
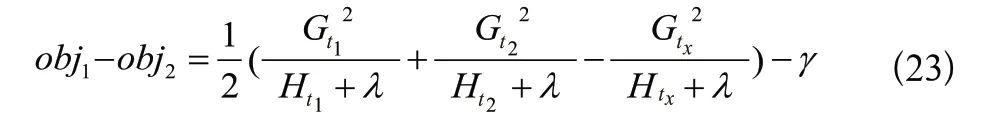
取信息增益最大的分割為該葉子節(jié)點的最優(yōu)解。可以設置信息增益取值下限,限制樹生長過深,同時通過設置樹的最大深度上限防止過擬合。
4 模型建立與超參數(shù)優(yōu)化(Model building and hyperparameters optimization)
本文選取滬深300股指期貨主力連續(xù)合約(IF9999)自2012 年1 月4 日至2022 年7 月29 日的開盤價、收盤價、最高價、最低價、成交量、成交額作為數(shù)據(jù)集,以約9∶1的比例將2,569 條交易數(shù)據(jù)劃分為訓練集與測試集。本文的訓練數(shù)據(jù)的窗口長度選擇收盤價序列ADF檢驗AIC最小準則計算出的默認滯后階數(shù)25,即用過去25 天的開盤價、收盤價、最高價、最低價、成交量、成交額作為輸入特征,未來1 天的收盤價作為標簽,進行模型訓練。
由于輸入指標開盤價、收盤價等與成交量的量綱不同,數(shù)量級上的差異會對預測模型收斂帶來不利影響,因此需要對原始數(shù)據(jù)中各項輸入指標進行歸一化處理,參照常用歸一化處理方式如下:
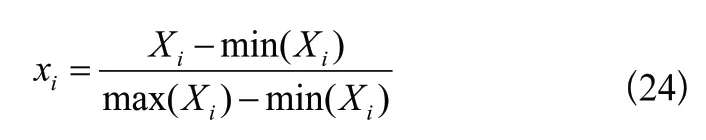
其中,xi是歸一化之后的輸入數(shù)據(jù),分別表示該指標中的最大值與最小值。
為了保持輸入數(shù)據(jù)和輸出數(shù)據(jù)在同一量綱,更真實客觀地利用模型評價指標對模型預測能力進行評價,需要對輸出數(shù)據(jù)進行反歸一化處理,參照常用反歸一化處理方式如下:
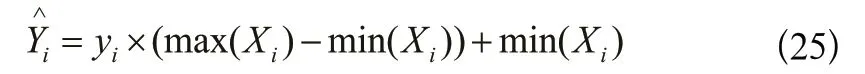
模型評價指標參照前人時序數(shù)據(jù)回歸算法預測研究經(jīng)驗,選取R2、均方誤差(MSE)、平均絕對誤差(MAE)、對稱平均絕對百分誤差(SMAPE)、適應度函數(shù)(LOSS)作為模型評價指標:
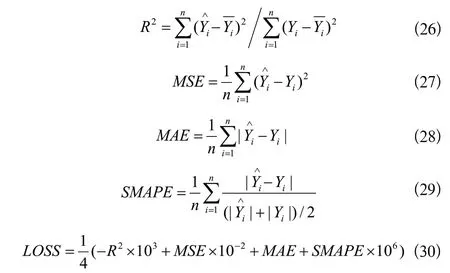
4.1 SVR預測模型構建
在構建SVR預測模型時,利用Python中Scikit-learn模塊的SVR類實現(xiàn)回歸預測,選擇徑向基函數(shù)(RBF)作為核函數(shù),模型在訓練集上的預測效果如圖8所示。
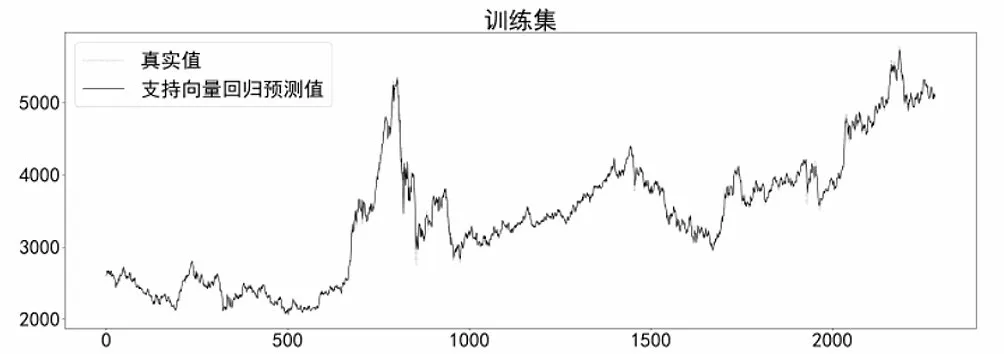
圖8 SVR模型在訓練集上預測效果Fig.8 Prediction effect of SVR model on the training set
4.2 LSTM預測模型構建
在構建LSTM預測模型時,利用Python中Keras模塊自帶的LSTM函數(shù)實現(xiàn)回歸預測,模型包含輸入層、LSTM層、全連接層、輸出層。batch_size設置為500,迭代100 次,設置全局隨機種子,使用Adam優(yōu)化器進行優(yōu)化,模型在訓練集上的預測效果如圖9所示。
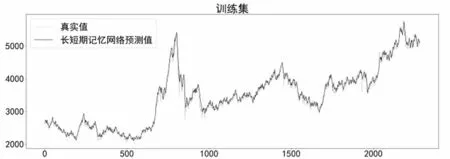
圖9 LSTM模型在訓練集上預測效果Fig.9 Prediction effect of LSTM model on the training set
4.3 RF預測模型構建
在構建RF預測模型時,利用Python中Scikit-learn模塊的RandomForestRegressor實現(xiàn)回歸預測,設置子決策樹最大樹深max_depth為10,子決策樹數(shù)量n_estimators為200,最小樣本葉子數(shù)量min_samples_leaf為20,分割所需最小樣本數(shù)min_samples_split為20,模型在訓練集上的預測效果如圖10所示。
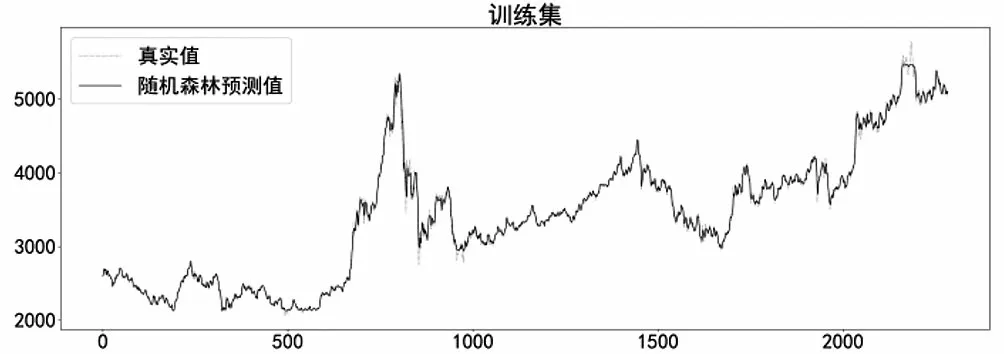
圖10 RF模型在訓練集上預測效果Fig.10 Prediction effect of RF model on the training set
4.4 XGBoost預測模型構建
在構建XGBoost預測模型時,利用Python中XGBoost模塊的XGBRegressor實現(xiàn)回歸預測,設置懲罰項系數(shù)gamma為200,子決策樹最大深度max_depth為20,子決策樹數(shù)量n_estimators為100,隨機采樣比例subsample為0.6。模型在訓練集上的預測效果如圖11所示。
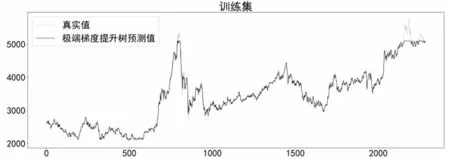
圖11 XGBoost模型在訓練集上預測效果Fig.11 Prediction effect of XGBoost model on the training set
4.5 貝葉斯優(yōu)化
貝葉斯優(yōu)化算法是一種“黑箱”算法,不需要提前設置目標函數(shù)的表達式,即可尋找全局最優(yōu)解,非常適合本文四種算法的超參數(shù)優(yōu)化。
算法的主體框架不斷迭代目標函數(shù)后驗概率分布與極小值點的過程,使目標函數(shù)極小值不斷減小,最終得到最優(yōu)超參數(shù)。算法思路如下。
第一步:定義優(yōu)化目標。
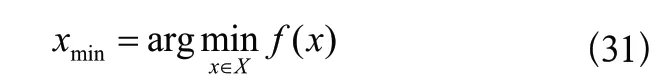
其中,xmin是待優(yōu)化的超參數(shù),f(x)是待優(yōu)化的目標函數(shù)。
第二步:對觀測點進行高斯過程處理。

第三步:不斷循環(huán)上述過程,最終實現(xiàn)xmin=xt+1,可得到最優(yōu)化的超參數(shù)。
按照上述貝葉斯優(yōu)化過程,構建優(yōu)化流程如圖12所示。
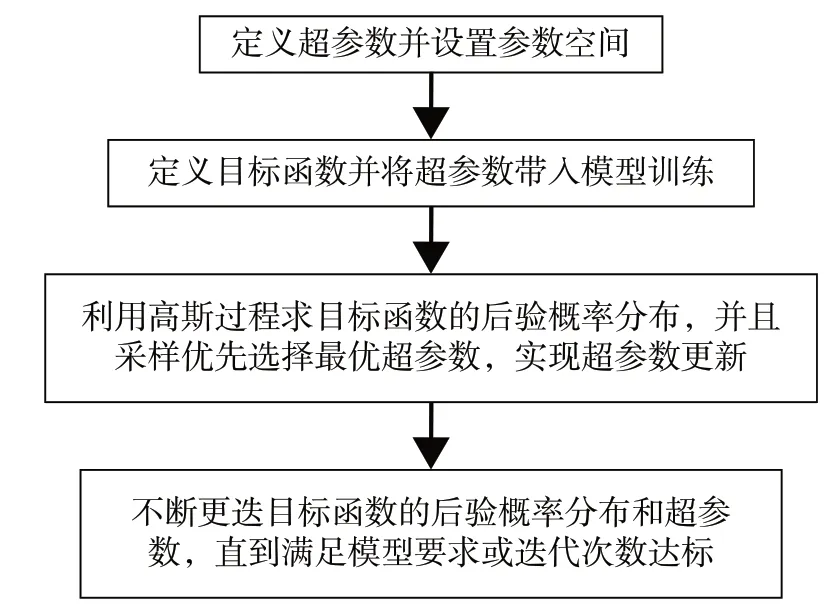
圖12 貝葉斯優(yōu)化過程流程圖Fig.12 Flowchart of Bayesian Optimization process
貝葉斯優(yōu)化過程中,設置優(yōu)化次數(shù)為200 次。SVR模型優(yōu)化參數(shù)為懲罰因子C和核函數(shù)參數(shù)gamma;LSTM模型優(yōu)化參數(shù)為全連接層葉子節(jié)點數(shù)dense_units、學習率learning_rate、隱含層葉子節(jié)點數(shù)lstm_units_1;RF模型優(yōu)化參數(shù)為子決策樹最大深度max_depth、單個決策樹使用特征比例max_features、最小樣本葉子數(shù)量min_samples_leaf、分割所需最小樣本數(shù)min_samples_split、子決策樹數(shù)量n_estimators;XGBoost模型優(yōu)化參數(shù)為懲罰項系數(shù)gamma、學習率learning_rate、子決策樹最大深度max_depth、最小葉子節(jié)點樣本權重和min_child_weight、子決策樹數(shù)量n_estimators、L1正則化系數(shù)reg_alpha、L2正則化系數(shù)reg_lambda、隨機采樣比例subsample。各個模型優(yōu)化后在測試集上的表現(xiàn)如圖13至圖16所示。

圖13 優(yōu)化后SVR模型在測試集上預測效果Fig.13 Prediction effect of the optimized SVR model on the test set

圖14 優(yōu)化后LSTM模型在測試集上預測效果Fig.14 Prediction effect of the optimized LSTM model on the test set
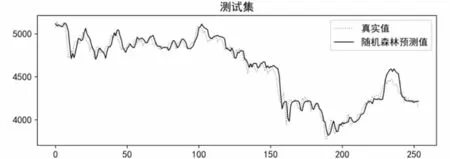
圖15 優(yōu)化后RF模型在測試集上預測效果Fig.15 Prediction effect of the optimized RF model on the test set
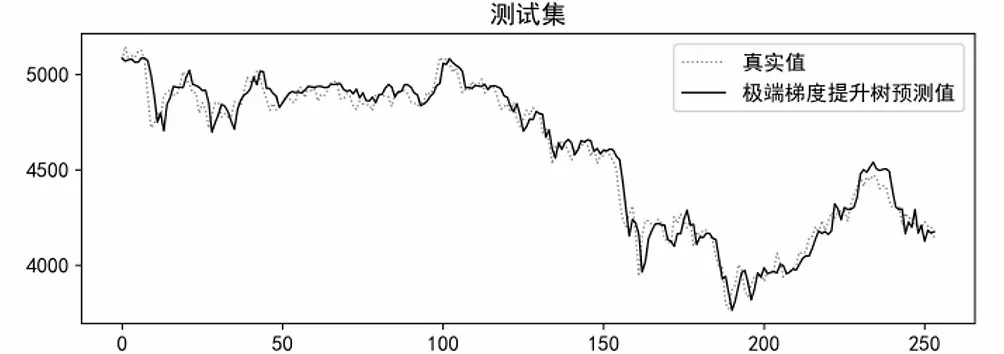
圖16 優(yōu)化后XGBoost模型在測試集上預測效果Fig.16 The predicted effect of the optimized XGBoost model on the test set
5 優(yōu)化后結果分析(Analysis of the results after optimization)
利用貝葉斯優(yōu)化對各個算法模型進行優(yōu)化訓練后,其超參數(shù)選擇如表2所示。

表2 貝葉斯優(yōu)化后超參數(shù)選擇Tab.2 Hyperparameters selection after Bayesian optimization
根據(jù)表3可以看出,優(yōu)化前RF和XGBoost預測效果顯著優(yōu)于SVR和LSTM,優(yōu)化后各個算法模型預測效果較為均衡,而貝葉斯優(yōu)化對于SVR算法預測效果提升最為明顯。SVR算法經(jīng)過貝葉斯優(yōu)化后,MSE降低了99.54%,MAE降低了94.63%,SMAPE降低了95.06%。可以看出,優(yōu)化后的SVR算法預測值最接近真實值,預測精度最高。

表3 優(yōu)化前后評價指標對比Tab.3 Comparison of evaluation indicators before and after optimization
6 結論(Conclusion)
本文利用四種機器學習算法對滬深300股指期貨主力連續(xù)合約收盤價進行預測研究,驗證了機器學習算法對金融時序數(shù)據(jù)預測的可行性。通過對比貝葉斯優(yōu)化前后預測效果,驗證了貝葉斯優(yōu)化對于機器學習算法預測效果提升的可得性。研究結果表明,RF和XGBoost可以實現(xiàn)對金融時序數(shù)據(jù)的準確預測,而貝葉斯優(yōu)化可以顯著提升SVR算法的預測精度。
本文具有選用輸入指標過于簡略、模型優(yōu)化方法較為單一的局限性,可通過引入價值、技術、動量、反轉、情緒等多種指標構建模型輸入,引入遺傳算法、粒子群算法、鯨魚優(yōu)化算法等多種超參數(shù)優(yōu)化方法提高模型魯棒性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產(chǎn)導刊(2022年5期)2022-06-01 06:20:14
中老年保健(2021年12期)2021-11-30 02:58:01
建材發(fā)展導向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導向(2021年7期)2021-07-16 07:07:52
中學生數(shù)理化(高中版.高二數(shù)學)(2021年12期)2021-04-26 07:43:48
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
