基于工程錄井數據的井漏智能診斷方法*
2022-12-08 14:16:52陳凱楓楊學文宋先知
石油機械 2022年11期
關鍵詞:模型
陳凱楓 楊學文 宋先知 陳 冬 張 偉 韓 亮 邢 星
(1.中國石油塔里木油田分公司2.中國石油大學(北京))
陳凱楓,楊學文,宋先知,等.基于工程錄井數據的井漏智能診斷方法.石油機械,2022,50(11):16-22.
0 引言
井漏是鉆井過程中常見的井下風險,它往往突然發生且處理起來十分復雜,還可能會誘發溢流、井塌等其他井下風險。實現井漏高效準確診斷對于鉆井作業的安全性和經濟性具有重要意義。
綜合錄井法[1]是應用最廣泛的井漏診斷方法,它通過實時監測錄井參數是否超過閾值來診斷井漏,但閾值設定依賴于經驗,主觀性較強,導致井漏診斷準確率有限;亓和平等[2]采用聲波液位測量裝置對井漏后井下環空液面進行了實時監測;唐世春[3]采用立管壓力法對井漏的層位進行了準確診斷,但當存在多個漏層時診斷效果不佳;門菲[4]和張學洪等[5]通過分析選取井漏表征參數,基于案例推理技術建立了井漏風險診斷模型,但不適用于探井較少的區塊;D.M.SCHAFER等[6]設計了高分辨率流量計來檢測井漏,但僅依靠單一參數導致效果不佳。傳統方法僅采用一個或幾個因素進行井漏識別,需要提前設定閾值,存在較高的誤判和漏判,且時效性不高。井漏是一種隨機的復雜非線性問題,人工智能方法可很好解決這個問題。HOU X.X.等[7]綜合考慮地質、鉆井液性能和鉆井參數,利用神經網絡對井漏等級進行了預測;侯艷偉等[8]基于地質和工程異常參數利用模糊數學對井下事故進行判斷;LI Z.J.等[9]基于神經網絡和支持向量機等算法,輸入泵壓、流量和地應力等工程和地質參數建立了井漏診斷模型,這些模型雖然精度較高,但需要實時輸入地質參數導致其應用受限。國內外企業已研發了一批較為成熟的井漏事故診斷系統,如DrillEdge鉆井風險識別系統[10]、e-Drilling自動化鉆井系統[11]、NDS鉆井風險管理系統[12]、KDS井涌井漏監測系統[13]和ALS-K井涌井漏快速探測系統[14]等,但需要與隨鉆測量工具配合使用。因此亟需建立基于實時工程錄井數據的井漏智能診斷模型,以提高井漏診斷效率和準確率。
筆者針對以上井漏診斷方法所存在的問題,分析并總結了井漏事故發生機理,將相關性分析和經驗知識相結合優選井漏表征參數,基于現場實時工程錄井數據,利用隨機森林(Random Forests,RF)、支持向量機(Support Vector Machine,SVM)、BP神經網絡(error Back Propagation Neural Network,BP)和邏輯回歸(Logistic Regression,LR)4種機器學習算法分別建立多錄井表征參數的井漏智能診斷模型,并分析各表征參數的相對重要性,對準確及時發現井漏風險和保障鉆井安全有重要意義。
1 井漏機理與表征參數
1.1 井漏機理
根據漏失原因井漏可分為2種:一是鉆遇滲透率大或裂縫發育的地層,鉆井液在壓差作用下通過這些漏失通道向地層中滲漏;二是由于鉆井液密度過高,液柱壓力大于地層破裂壓力導致地層被壓漏,形成人工漏失通道造成鉆井液向地層滲漏[15]。
1.2 井漏的表征參數
井漏發生時會導致工程參數發生明顯變化,只依靠一種參數的變化來識別井漏并不準確,要結合多種參數變化來綜合判斷[16]。
(1)鉆井液總池體積:鉆井液地層內滲漏導致井筒內鉆井液減少,上返至地面的鉆井液體積減少,故鉆井液總池體積減少。
(2)鉆井液出入口流量差:井漏時井筒中部分鉆井液流入地層中,出口流量減少,入口流量與出口流量的差值為正,若不及時處理,流量差會進一步增加。
(3)立管壓力:井漏時鉆井液上返速度降低,與環空間摩阻減小,導致立壓降低。
(4)大鉤載荷:由于鉆井液密度和地層流體密度存在差異,一般情況下鉆井液密度大于地層流體密度,密度差產生的浮力變化會造成大鉤載荷波動。
(5)泵壓:漏失時鉆井液流入地層導致上返流體減少,舉升壓力減小導致泵壓降低。
(6)鉆速:在鉆遇裂縫發育或溶洞地層時,鉆頭破巖阻力減小,鉆速會突然加快。
2 數據處理
本文所使用的工程錄井數據來自于國內某油田,采用特征工程方法對工程錄井數據進行了清洗、相關性分析及歸一化等處理,建立用于人工智能模型訓練測試的數據集。
2.1 數據清洗
對于缺失值,基于數據類別的分布規律和重要性采取不同處理方法,當特征缺失率超過70%時直接刪除;若缺失值占比較低,特征符合均勻分布則采用均值補全,特征符合線性分布則用中位數補全。對于異常值,將其轉換為空值后利用均值或中位數對空值補全。
2.2 參數相關性分析
相關性分析是特征選擇的一種重要方法,能夠衡量各參數與目標值間的相關性程度,優選相關性強的特征作為輸入,有利于降低模型復雜度,提高模型訓練速度和泛化能力。
采用Pearson相關系數衡量各個變量與目標變量之間的相關性強度,其計算公式為:
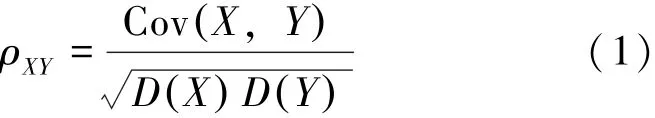
式中:X、Y為變量,Cov X,Y( )為X、Y的協方差,D X()為X的方差,D Y()為Y的方差,ρXY為X、Y的Pearson相關系數。
特征與井漏的相關性如圖1所示。通過計算各工程錄井參數與井漏間的Pearson相關系數,結合井漏表征規律對輸入參數進行優選。最終選取總池體積、立管壓力、進出口流量差、大鉤載荷、鉆時、鉆井液密度和井斜方位角等7種特征參數作為模型輸入參數。
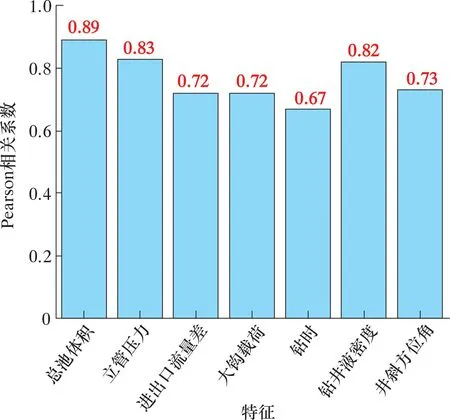
圖1 特征與井漏的相關性Fig.1 Correlation between characteristics and lost circulation
2.3 數據集建立
鉆井過程中井漏屬于小樣本事件,數據樣本存在嚴重失衡導致在模型訓練過程中預測結果更偏向于比例較大的非井漏。為解決數據比例不平衡問題,選取井漏井段和其上部非井漏井段建立數據集,井漏與非井漏數據比例為4∶6,其中井漏標簽為1,非井漏標簽為0。
2.4 數據歸一化處理
不同特征的量綱和單位差異巨大,嚴重影響數據分析和模型預測結果,因此利用數據標準化處理消除不同量綱與單位之間的影響。原始數據經數據標準化處理后落在特定區間,有利于模型訓練和對比。本文采用最大-最小歸一化方法對數據進行處理,計算公式如下:
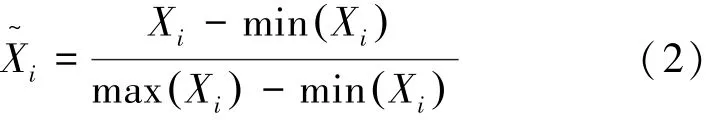
3 井漏診斷模型建立
3.1 算法原理
3.1.1 隨機森林算法
決策樹是隨機森林基本單位,主要由根節點、內部節點和葉子節點3部分組成[17]。隨機森林算法通過集成學習思想將多個決策樹集成,將不同決策樹結果進行統計,以數量最多的結果作為模型預測結果。其結構如圖2所示。
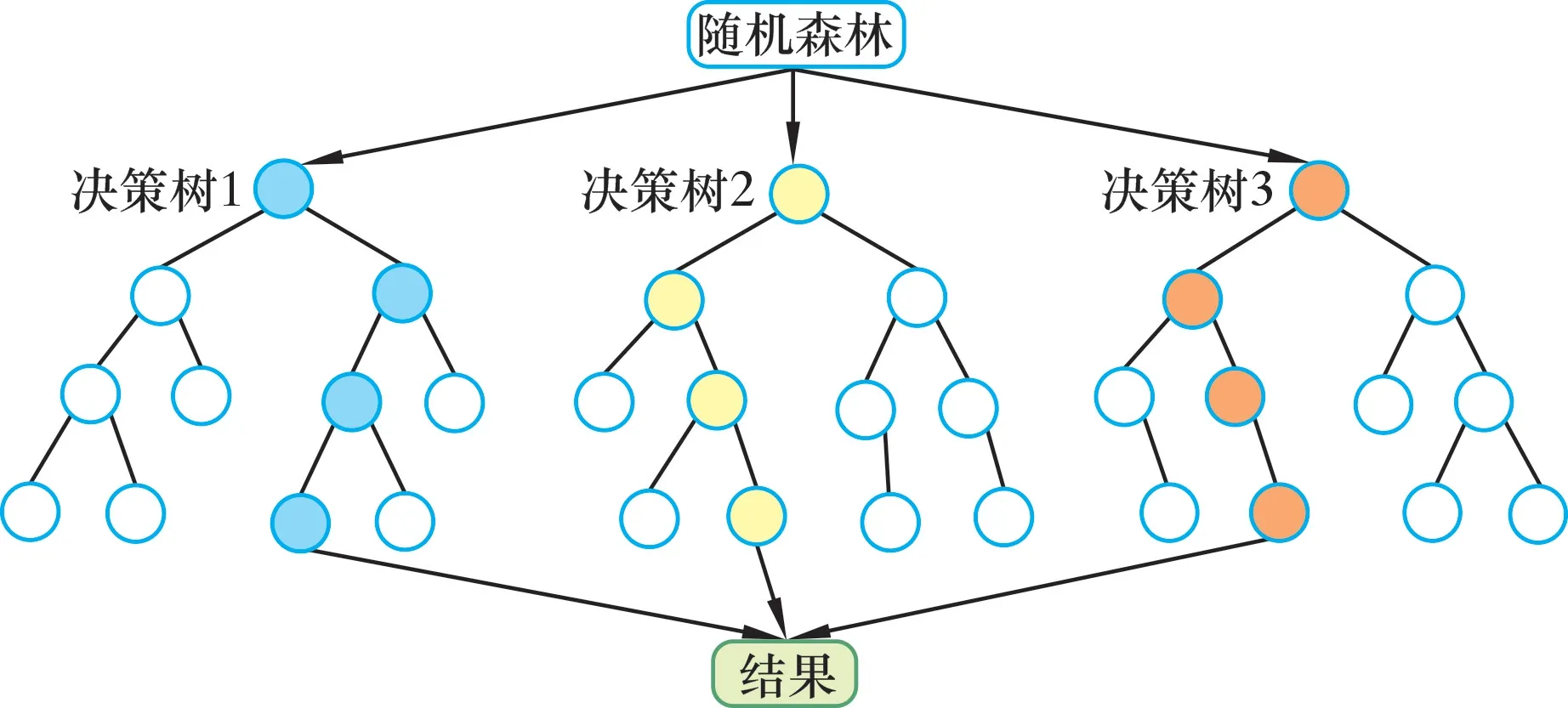
圖2 隨機森林算法示意圖Fig.2 Schematic diagram of random forest algorithm
3.1.2 支持向量機[18]
支持向量機的基本思想是尋找一個可將數據區分且幾何距離最大的“超平面”,當數據集為非線性問題時,通過核函數將線性不可分數據映射到高維空間中,轉換為高維空間線性可分數據,并在高維空間求解最佳分類超平面。當數據集線性可分時,其超平面方程為:

則空間中點x到最佳分類超平面的距離為:
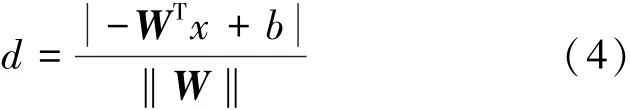
式中:W為平面法向量,x為點x的坐標,b為平面的截距,d為點x到平面的距離。
3.1.3 BP神經網絡
神經元是神經網絡的基本組成單位,其接收輸入后通過加權計算總輸入并與閾值進行比較,利用激活函數對其進行非線性處理得到最終輸出[19]。BP神經網絡將神經元逐層組織連接,并利用誤差逆向傳播算法進行訓練,不斷調整網絡權重和閾值,將誤差降到最低[20]。神經元及BP神經網絡模型結構如圖3所示。
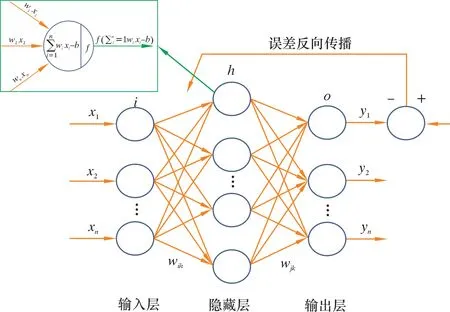
圖3 神經元與BP神經網絡結構Fig.3 Neuron and BP neural network structure
3.1.4 邏輯回歸
邏輯回歸原理是將線性回歸的結果輸入到sigmoid函數中,并設置一個適當的閾值,如果樣本類別概率大于閾值,則劃分為1,小于閾值則劃分為0。

3.2 模型評價指標
井漏診斷是二分類問題,由于井漏和非井漏數據量不平衡,造成準確率偏高,所以綜合多個指標來衡量模型的泛化能力。本文采取準確率、漏警率和虛警率評價井漏診斷模型的性能。
準確率(Accuracy)是指分類模型診斷正確的樣本數量占整個診斷樣本數量的比例,其表達式如下:
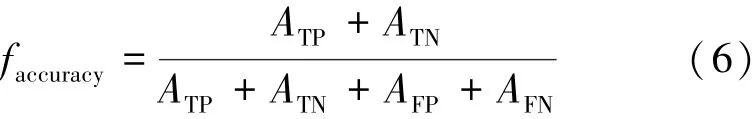
漏警率(Missing Alarm Rate)指未被識別的井漏樣本占實際井漏樣本的比例,其表達式為:
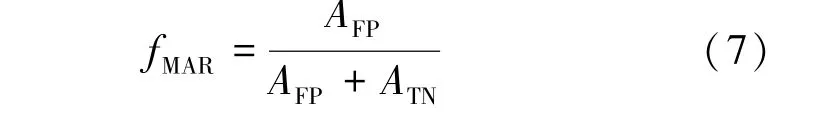
虛警率(False Alarm Rate)指識別為井漏的樣本中實際為非井漏樣本的比例,其表達式為:

式中:ATP表示將正類預測為正類的樣本數量,ATN表示將負類預測為負類的樣本數量,AFP表示將負類預測為正類的樣本數量,AFN表示將正類預測為負類的樣本數量。
3.3 井漏診斷模型建立
基于建立的井漏數據集,選取其中75%用于訓練驗證,25%的樣本用于測試,利用隨機森林、支持向量機、BP神經網絡和邏輯回歸算法分別建立井漏智能診斷模型。
3.3.1 隨機森林模型
對于隨機森林模型,利用網格搜索算法對隨機森林模型的分類器數量、葉子節點最小樣本數、樹的最大深度和內部節點劃分最小樣本數等參數進行調整尋優,各模型參數設置及優選結果如表1所示。
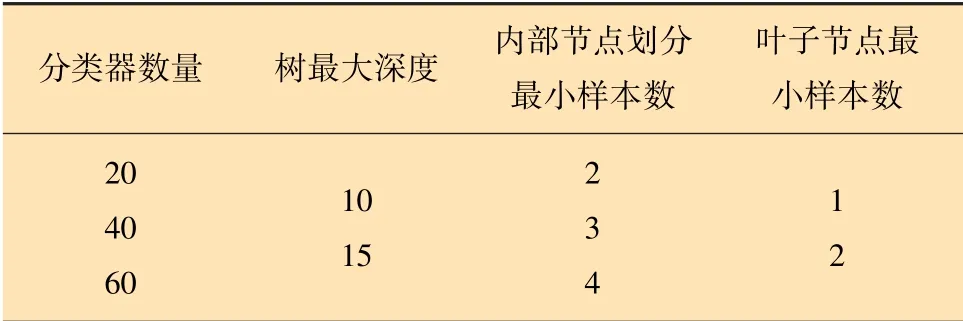
表1 隨機森林模型參數組合Table 1 Parameter combination of random forest model
不同參數組合下隨機森林模型在測試集上的準確率、漏警率、虛警率如圖4所示,其橫坐標為不同參數組合下的隨機森林模型。當分類器數量為40、樹的最大深度為15、內部節點劃分最小樣本數為2、葉子節點最小樣本數為1時,隨機森林模型的效果最佳,準確率為98%,漏警率為3%,虛警率為1%。
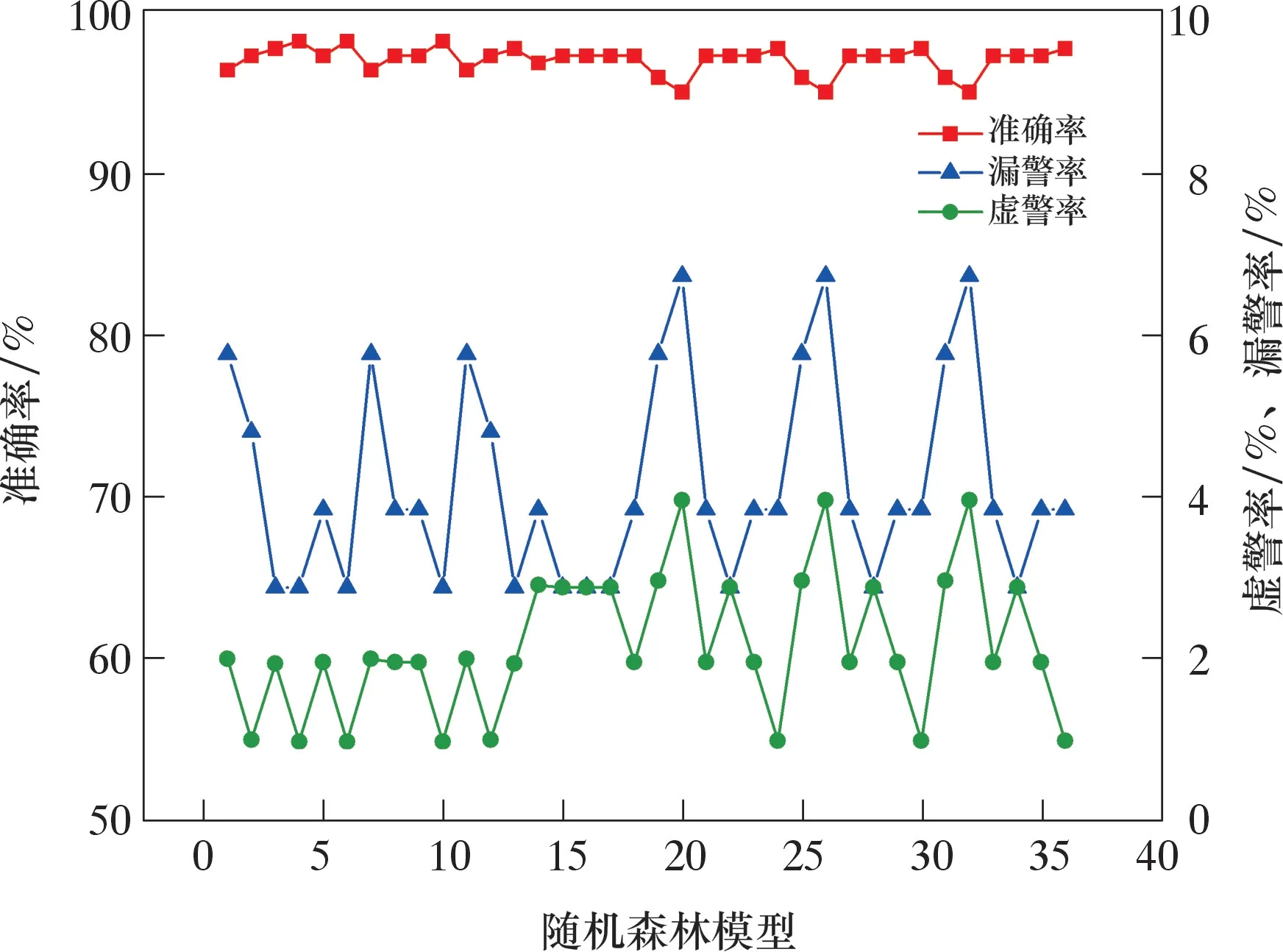
圖4 隨機森林模型在不同參數組合下的評價指標對比Fig.4 Comparison of assessment indicators of random forest model with different parameter combinations
3.3.2 支持向量機模型
對于支持向量機模型,通過預訓練優選出徑向基核(Radial Basis Function,RBF)作為核函數,利用網格搜索算法對支持向量機模型的懲罰因子、核函數系數、誤差容忍度等參數進行調整尋優,模型各參數范圍及優選結果如表2所示。
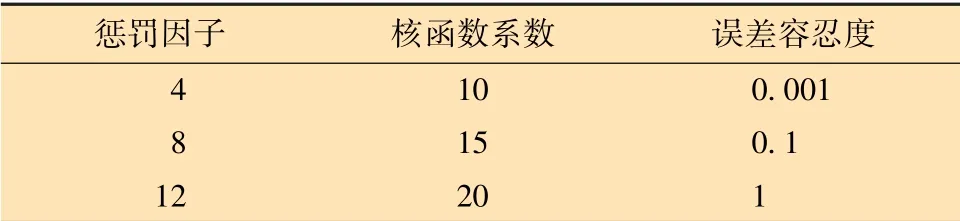
表2 支持向量機模型參數組合Table 2 Parameter combination of support vector machine model
不同參數組合下支持向量機模型在測試集上的準確率、漏警率和虛警率如圖5所示,其橫坐標為不同參數組合下的支持向量機模型。當懲罰因子為12、核函數系數為15、誤差容忍度為0.001時,支持向量機模型的效果最佳,準確率為96%,漏警率為2%,虛警率為6%。

圖5 支持向量機模型在不同參數組合下的評價指標對比Fig.5 Comparison of assessment indicators of support vector machine model with different parameter combinations
3.3.3 BP神經網絡模型
對于BP神經網絡模型,隱藏層激活函數為relu,輸出層激活函數為sigmoid,選用Adam優化器,建立BP神經網絡井漏智能診斷模型,利用網格搜索算法對隱藏層神經元數量、訓練迭代輪數和學習率等超參數進行調整尋優,參數設置及優選情況如表3所示。
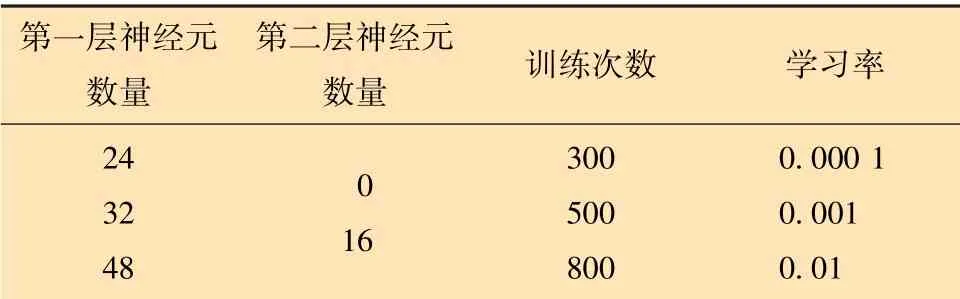
表3 BP神經網絡模型參數組合Table 3 Parameter combination of BP neural network model
不同參數組合下BP神經網絡模型在測試集上的準確率、漏警率和虛警率如圖6所示,其橫坐標為不同參數組合下的BP神經網絡模型。當第1層隱藏層神經元數量為32個、第2層隱藏層神經元數量為16個、訓練迭代輪數為800、學習率為0.001時,BP神經網絡模型的效果最佳,其井漏診斷準確率為88%,漏警率為7%,虛警率為16%。
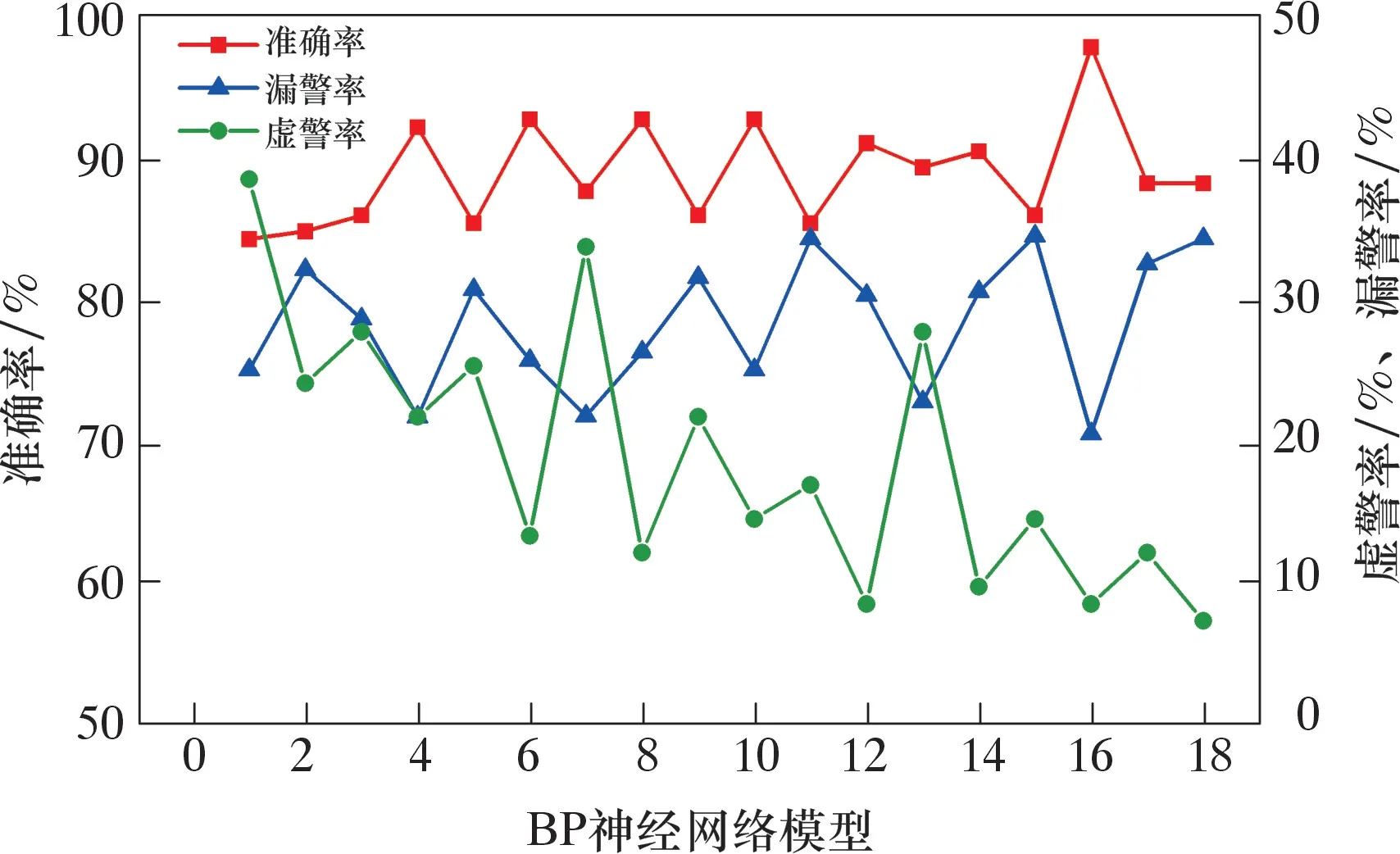
圖6 BP神經網絡模型在不同參數組合下的評價指標對比Fig.6 Comparison of assessment indicators of BP neural network model with different parameter combinations
3.3.4 邏輯回歸模型
對于邏輯回歸模型,利用網格搜索算法對邏輯回歸模型的優化參數、multi_class、正則化強度的倒數C和誤差容忍度等參數進行調整尋優,模型各超參數設置如表4所示。最終基于邏輯回歸算法建立最優的井漏智能診斷模型。不同參數組合下邏輯回歸模型在測試集上的準確率、漏警率和虛警率如圖7所示。
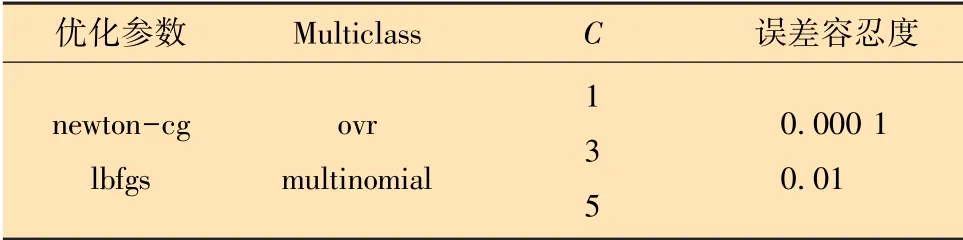
表4 邏輯回歸模型參數組合Table 4 Parameter combination of logistic regression model
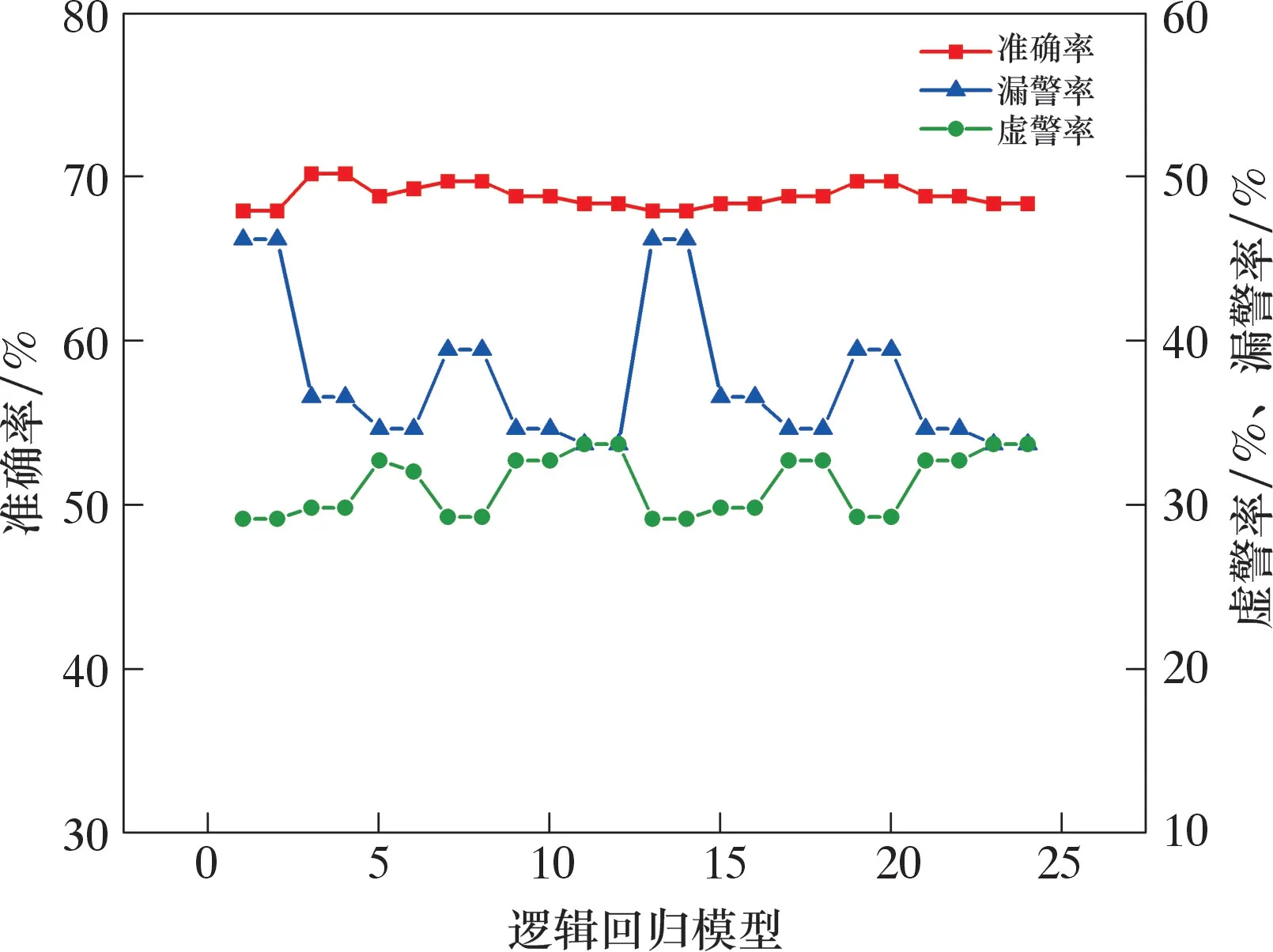
圖7 邏輯回歸模型在不同參數組合下的評價指標對比Fig.7 Comparison of assessment indicators of logistic regression model with different parameter combinations
其橫坐標為不同參數組合下的邏輯回歸模型。當優化參數為Newton-cg、multi-class為ovr、正則化強度的倒數C為3、誤差容忍度為0.000 1時,邏輯回歸模型的效果最佳,準確率為70%,漏警率為37%,虛警率為30%。
3.3.5 4種機器學習模型對比
將采用最優參數的4種機器學習模型在測試集上的表現效果進行對比,如圖8所示。在井漏診斷準確率方面,最優的隨機森林模型在測試集上為98%,支持向量機模型為96%,BP神經網絡模型為88%,邏輯回歸模型為70%;在井漏診斷漏警率方面,最優的支持向量機模型為2%,隨機森林模型為3%,遠遠低于BP神經網絡和邏輯回歸模型;在井漏診斷虛警率方面,最優的隨機森林模型在測試集上虛警率為1%,遠低于支持向量機、BP神經網絡和邏輯回歸模型。由此可見,隨機森林模型的井漏診斷效果更好,其在測試集上的泛化能力相對較好,能夠有效地診斷井漏風險,且漏警率和虛警率相對較低。
3.3.6 隨機森林適配性及特征重要性分析
隨機森林是用隨機方式建立并包含多個決策樹的分類器。每棵決策樹從所有數據和所有特征中有放回地隨機采樣選取特征子集,且特征子集中的特征可隨機組合,每棵決策樹進行獨立訓練,并將各個樹輸出類別的眾數定為隨機森林的最終輸出。由于特征采樣的隨機性,大多數決策樹模型中不含或只含少量異常數據,導致隨機森林模型對異常值不敏感并具有較強的抗干擾能力,即使存在一些特征遺失,仍可以保持一定的準確度,且對于不平衡的數據集來說隨機森林在一定程度上可以平衡誤差,所以其在井漏診斷的問題上表現較好。
此外,隨機森林模型可以基于基尼指數計算出輸入特征的重要程度來評價各輸入特征的貢獻大小,7個輸入特征的相對重要性如圖9所示。由圖9可以看出,總池體積、立管壓力、進出口流量差、鉆井液密度和大鉤載荷5個特征的相對重要性占比超過80%,表明這5種參數是隨機森林模型準確診斷井漏的主控參數。鉆時和井斜方位角的相對重要性雖然占比不大,但其對隨機森林模型準確率的提升具有重要作用。
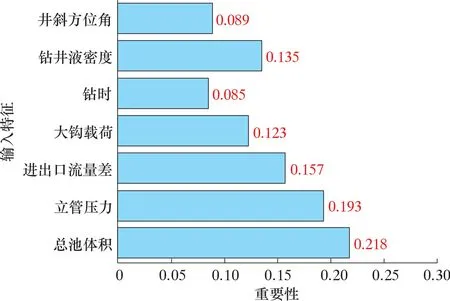
圖9 各輸入特征的重要性Fig.9 Importance of each input characteristics
4 結論
井漏機理復雜,影響因素眾多,本文基于國內某油田的工程錄井數據,利用4種機器學習算法建立了不同的井漏智能診斷模型,主要結論如下:
(1)分析了工程錄井參數與井漏之間的相關性,結合鉆井經驗知識優選出總池體積、立管壓力、大鉤載荷、鉆時、進出口流量差、鉆井液密度和井斜方位角7種特征參數作為模型輸入。
(2)基于隨機森林、支持向量機、BP神經網絡和邏輯回歸4種算法分別建立了井漏智能診斷模型,其中隨機森林模型的表現效果最好,能夠準確地識別井漏井段,準確率為98%,漏警率為3%,虛警率為1%,滿足現場工程需要。
(3)分析了隨機森林模型在解決井漏問題中的優點和各輸入特征的相對重要性,結果表明總池體積、立管壓力、進出口流量差、鉆井液密度和大鉤載荷5種特征參數是隨機森林模型準確診斷井漏風險的主控參數。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
