基于生成對抗網絡的花卉識別方法
2022-12-13 01:14:00崔艷榮卞珍怡高英寧
江蘇農業科學 2022年22期
關鍵詞:模型
崔艷榮, 卞珍怡, 高英寧
(長江大學計算機科學學院,湖北荊州 434023)
由于花卉種類繁多、結構復雜,花卉識別在計算機視覺和圖像處理領域仍然是一個挑戰。傳統的花卉特征提取方法有GrabCut切割算法[1]、快速魯棒特征(SURF)、局部二進制模式(LBP)[2]和灰度共生矩陣(GLCM)[3]等方法,存在費時費力、主觀性強、模型泛化能力差且無法處理海量數據等問題。
近幾年,深度學習在計算機視覺、自然語言處理等方面獲得了重大突破,已廣泛應用于圖像識別領域[4]。林君宇等將多輸入卷積神經網絡和遷移學習應用到花卉識別領域,取得了95.3%的識別率[5]。吳麗娜等在LeNet-5網絡模型基礎上調整連接方式和池化操作,并使用隨機梯度下降算法進行花卉識別,取得了96.5%的花卉識別率[6]。劉嘉政對Inception_v3模型進行深度遷移學習,對其結構進行微調,在自定義數據集上取得了93.73%的準確率[7]。關胤采用152層殘差網絡結構進行花卉識別,并結合遷移學習訓練,取得了較好的識別效果[8]。Cao等采用基于殘差網絡和注意力網絡的加權視覺注意力學習塊進行花卉識別,在flowers17上取得了85.7%的識別率[9]。裴曉芳等將resnet18網絡模型的全連接層替換為卷積層,融入了混合域注意力機制,采用Softmax進行花卉識別[10]。
現有深度學習模型都需要大量的數據進行訓練,計算機視覺領域中用于數據增強并減少過擬合的傳統采樣方法包括旋轉、裁剪、翻轉、顏色轉換等[11]。在很多情況下,這些方法生成的圖像僅為原始數據的簡單冗余副本。生成對抗網絡(generative adversarial network,GAN)很好地解決了該問題,其模型中的生成器(G)和判別器(D)交替訓練完成后,G可以生成大量高質量的模擬樣本以進行數據增強,GAN廣泛適用于圖像超分辨率重建、人臉圖像生成與復原、圖像轉換、視頻預測等領域[12]。
目前,很少有人將GAN應用到花卉識別領域。本研究提出一種基于改進Wasserstein生成對抗網絡[13](attention residual WGAN-GP,ARWGAN-GP)的花卉識別方法。使用殘差網絡構建G和D,解決了網絡過深時出現的梯度消失問題,減小了模型計算量,G和D分別融入了注意力機制[14],快速有效地提取了花卉顯著區域特性,且通過融合損失函數進一步優化GAN模型,生成高質量花卉樣本,將判別器應用到花卉識別網絡,使得花卉識別準確度顯著提高。
1 改進Wasserstein生成對抗網絡方法
1.1 生成對抗網絡
GAN是一種生成模型,包括G和D,GAN旨在訓練G合成模擬樣本G(z)以混淆D,D試圖區分生成樣本和真實樣本。G和D之間的最小-最大博弈目標函數如式(1):
(1)
其中:x采樣于真實數據分布Pr(x);z采樣于隨機噪聲分布Pg(z);D(G(z))為D判別輸入為G生成數據的概率;D(x)為D判別輸入為原始數據的概率。
使用交叉熵散度來度量不同樣本間的距離,會導致GAN產生梯度消失問題。王怡斐等提出使用Wasserstein距離比較樣本之間的差異性,改善了GAN梯度消失的缺陷,使得網絡訓練更加穩定[15]。式(2)為WGAN的優化目標函數。
L=-Ex~Pdata(x)[D(x)]+Ez~Pz(z)[D(G(z))]。
(2)
但WGAN對權重參數裁剪過于簡單,又會導致梯度爆炸,生成的樣本質量仍然不理想。Liu等提出了新的改進方法,采用梯度懲罰的方法進行權重優化,以達到加快網絡訓練且生成高質量樣本的目的[16]。模型損失函數如式(3)所示:

(3)
LG=-Ez~Pz(z)[D(G(z))];
(4)

(5)
式(3)前2項為WGAN的優化目標函數;x為原始數據分布Pdata(x)的輸入樣本;z是采樣于Pz(z)中的隨機噪聲;最后一項為梯度懲罰項;λ為梯度懲罰項參數;ε采樣于標準均勻分布。
1.2 注意力機制
由于卷積神經網絡只關注圖像數據中的局部依賴性,在計算長距離特征時效率極低,傳統的生成對抗網絡可以捕獲到圖像中的紋理特性,但很難學習到圖像中特定的結構和幾何特征。在生成對抗網絡中添加注意力機制,可以計算圖像像素之間的相關性,并建立長距離依賴性,進一步提取到花卉樣本的全局特征,生成的圖像可以顯示更多的細節。注意力機制原理如圖1所示。

圖1中X表示卷積后的特征圖,將x輸入到3個1×1卷積層來獲得特征空間f(x)、g(x)、h(x),將f(x)和g(x)執行相應計算得到βji,如式(6)~(9):
Sij=f(xi)T?g(xj);
(6)
f(xi)=Wfxi;
(7)
g(xj)=Wgxj;
(8)
(9)
式中:f(x)為像素提取;Wf為f(x)的權重;g(x)為全局特征提取;Wg為g(x)的權重;?表示矩陣乘法;N為特征圖數;βji表示注意力圖;注意力機制輸出層見式(10)(11):
(10)
h(xi)=Whxi。
(11)
式中:Wh是h(x)的權重。為使網絡學習提取到特征圖的局部和全局特征,將自注意力層Oi輸出乘以系數λ并將其添加到特征圖,獲得注意力機制的最終輸出yi。其中λ是一個可學習參數,初始值設為0。
yi=λOi+xi。
(12)
1.3 生成對抗網絡模型
1.3.1 生成器 原始生成器結構為簡單卷積神經網絡,模型訓練速度較快,但模型生成樣本質量不好,會出現棋盤效應;且隨著網絡深度的增加,會出現梯度消失,使得網絡無法訓練。本研究使用殘差網絡來構建生成器,采用最近鄰插值代替反卷積進行上采樣操作,將上采樣和殘差網絡融合在一起來解決該問題。上采樣殘差塊如圖2所示,輸入樣本經過批量歸一化以加快模型訓練速度,采用最近鄰插值進行上采樣,通過2層卷積提取特征;且在輸入樣本的同時經過最近鄰插值法進行上采樣,通過1層卷積提取特征,將2個特征圖輸出進行融合,得到上采樣殘差塊的最終輸出。

花卉圖像背景復雜,存在大量噪聲干擾,使得生成器生成的花卉樣本效果較差。在生成器淺層網絡中加入注意力機制,可以關注生成花卉樣本的邊緣區域特征,在深層網絡中添加注意力機制,進一步合成花卉樣本的紋理細節特征。本研究在生成器中加入注意力機制來提取有效花卉樣本區域特征,進一步合成高質量的花卉樣本。注意力機制結構如圖3所示。

生成器輸入采樣于隨機分布的128維噪聲,通過全連接層轉換為16 384維向量,經過維度轉換大小變為(4,4,1 024)。通過5個上采樣殘差塊進行上采樣,將特征圖大小依次擴大2倍,除第1層上采樣殘差塊通道數不變,其他依次縮小為1/2,特征圖大小變為(128,128,64)。在每個上采樣殘差塊后依次添加1個注意力模塊進一步提取樣本特征,提升模擬樣本的清晰度,注意力機制不更改樣本大小。最后通過1層卷積層,得到一個維度為(128,128,3)的模擬樣本。卷積層激活函數為ReLU,輸出層激活函數為Tanh。圖4為G結構圖。
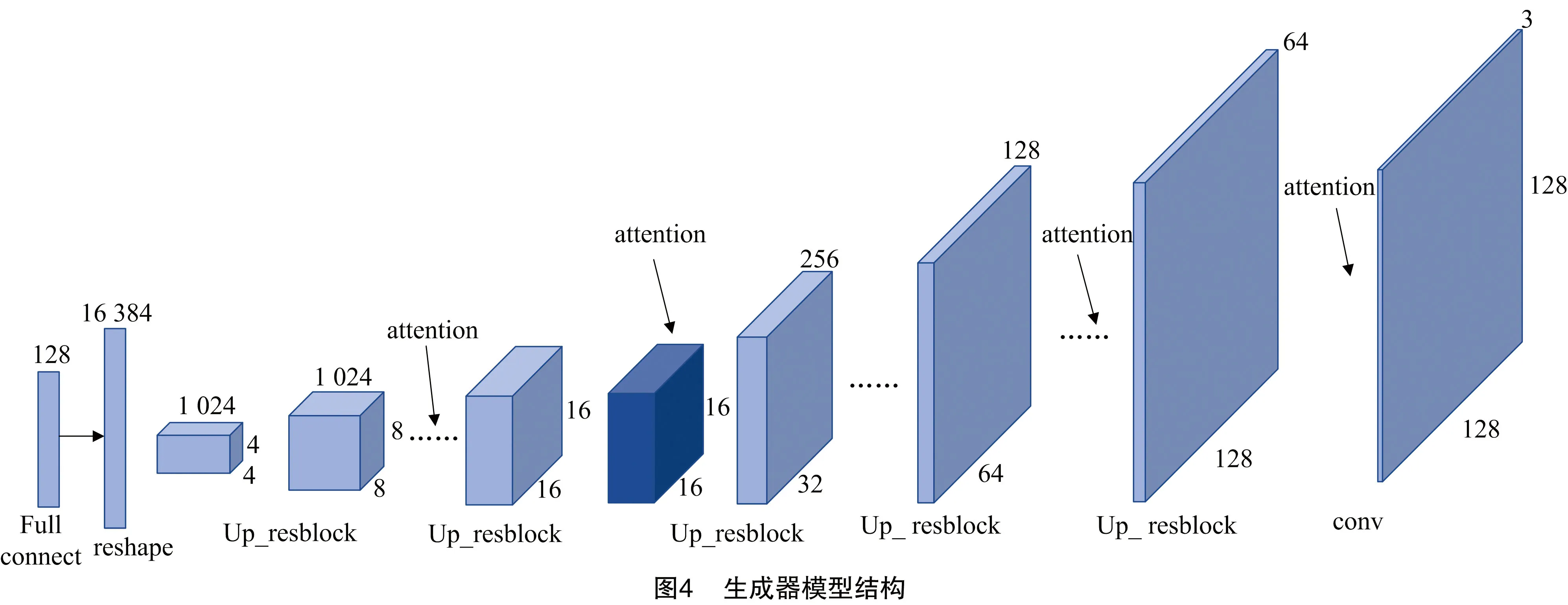
1.3.2 判別器 判別器模型結構和生成器模型結構對應,采用下采樣殘差塊進行特征提取,融入注意力機制進一步提取花卉區域樣本特征,將維度為(128,128,3)的真實樣本和模擬樣本傳入判別器,通過5層下采樣殘差塊進行特征提取,使得特征圖數不斷增加,圖片大小不斷減小。在每層下采樣殘差塊后依次添加1層注意力模塊進行特征提取,約束模擬樣本的細節特征,提高模擬樣本的真實性,且注意力機制不改變特征圖大小。最后通過卷積層得到(4,4,1 024)的特征圖,通過全連接層進行判斷。D中卷積層均為Leaky ReLU激活函數。圖5為D結構圖,圖6為下采樣殘差塊結構圖。
1.3.3 損失函數及模型訓練 為使得G可以生成清晰度更高的,且具有多樣性的高質量花卉樣本,生成器采用融合損失函數,將對抗損失、注意力損失和重構損失進行加權融合。判別器損失函數采用式(3)計算。
1.3.3.1 對抗損失 對抗損失為wgan-gp的生成器損失函數。如式(4)所示,改善了GAN和WGAN訓練時出現的梯度消失,訓練解決不穩定和生成花卉樣本效果不佳的缺陷。


1.3.3.2 注意力損失 為更好地提取花卉樣本的局部和全局性特征,生成紋理清晰、視覺上和真實樣本高度相似且具有多樣性的模擬樣本,引入注意力損失,如式(13)所示。
(13)
式中:yi表示注意力機制輸出,同式(12);θi表示注意力機制輸出層的權重,淺層的注意力層輸出可用信息較少,權重較小,深層輸出權重較大,經對比試驗驗證,權重參數依次選為1,1,1,2,2,G(z)為生成模擬樣本。
1.3.3.3 重構損失 重構損失為生成樣本與真實花卉樣本之間的L1距離,可以較好地反映生成花卉樣本的真實性,如式(14)所示。
Lrec=Ex~Pdata(x),z~Pz(z)[‖G(z)-x‖1]。
(14)
式中:x為原始數據分布Pdata(x)的輸入樣本;z是采樣于Pz(z)中的隨機噪聲。
融合目標損失函數為式(15)所示。
Llos=δ1LG+δ2Latt+δ3Lrec。
(15)
式中:δ1,δ2,δ3為損失函數的權重。經對比試驗分析得到,δ1為1,δ2為0.05,δ3為10時效果最好。
G的訓練需要固定D參數,隨機噪聲經過生成器進行一系列的上采樣后生成模擬樣本,將其送入到D進行判別,盡最大可能使D判別生成的樣本為真實樣本。D需要送入生成樣本和真實樣本進行參數優化,根據式(15)和式(3)計算生成器融合損失值和D的損失值,采用Adam算法進行參數調整,融合損失函數值主要為引導生成器生成更高質量的樣本,D損失函數值可以表現網絡模型的訓練情況,當該值趨于穩定收斂時,表明網絡模型訓練近似達到最優,此時生成器加權損失函數也趨于穩定,生成的模擬樣本質量更高。交替對抗訓練G和D,為防止過擬合,加快模型收斂,G和D訓練次數設為1 ∶k。
1.4 花卉識別模型
ARWGAN-GP訓練完成后,G可以生成紋理清晰,視覺上和真實樣本高度相似且具有多樣性的模擬樣本,判別器可以快速提取花卉樣本特征。將訓練好的生成對抗網絡模型進行調整,以解決花卉識別準確度低的問題。圖7為花卉識別網絡模型。本研究遷移判別器網絡參數到花卉識別網絡,大幅度減小了花卉識別網絡訓練時間,且進一步提高了花卉識別率,替換全連接層為新設計的全連接分類層,使用softmax激活函數進行花卉識別。對花卉識別模型進行適當的參數調整以適應新任務的要求,使用交叉熵損失函數和Adam算法調整網絡參數,采用生成器生成的模擬樣本作為訓練集訓練花卉識別網絡。
2 結果與分析
2.1 試驗環境與數據集
本研究試驗平臺為Windows10,GPU為NVIDIA GEFORCE GTX 1080,深度學習架構為keras和Tensorflow。選擇Oxford 102花卉數據集作為數據樣本,包含102種花卉,共8 189張圖片,將花卉樣本等比例縮放為128×128像素,示例如圖8所示。訓練集和測試集的比例設置為9 ∶1。
2.2 試驗設計
2.2.1 ARWGAN-GP模型訓練及驗證 本研究使用oxford102花卉數據集訓練ARWGAN-GP,迭代次數為20 000,批處理樣本數為32,G和D學習率分別為0.000 1和0.000 4,G和D優化更新次數為1 ∶3。使用G為每張花卉數據對應生成大量模擬樣本作為訓練集,訓練本研究的花卉識別網絡。
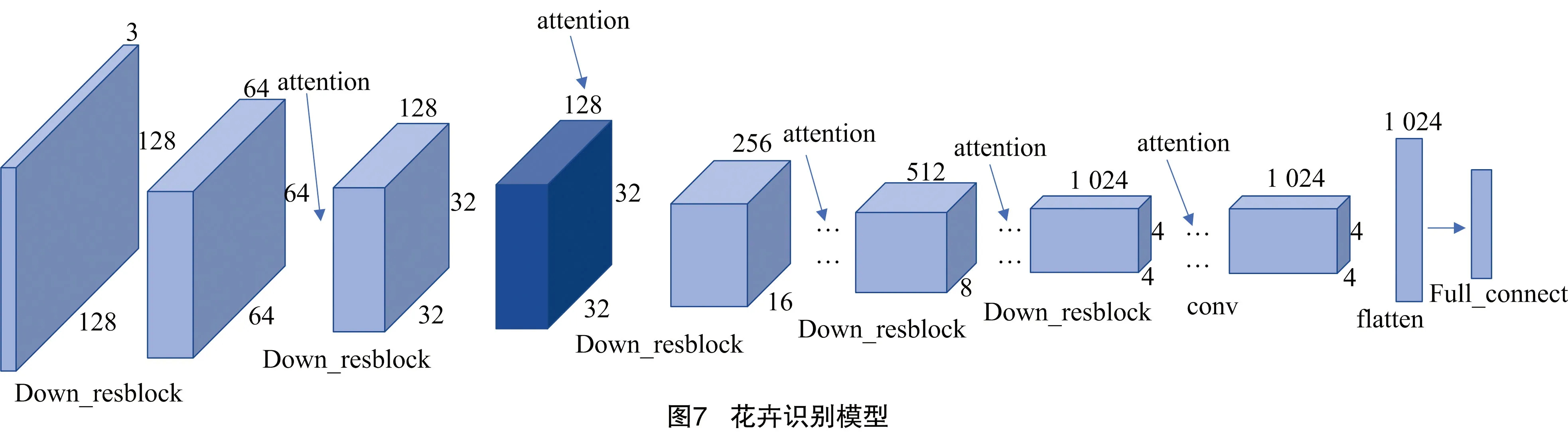

圖9為ARWGAN-GP在不同迭代次數時判別器損失函數值。在模型開始訓練階段,D損失函數值震蕩幅度較大。此時,G生成樣本能力較弱,融合損失函數值和D損失函數值不斷引導G生成更高質量的樣本,經過多次迭代后,D損失函數值震蕩范圍縮小,下降到較小值且趨于收斂,表明此階段為模型學習階段。隨著試驗的進行,模型不斷學習優化,當訓練次數達到10 000次時,D損失函數值趨于穩定收斂,表明ARWGAN-GP得到了充分的訓練,模型已經達到最優。此時,G可以生成高質量的模擬樣本。訓練完成后,使用G生成大量模擬花卉樣本。
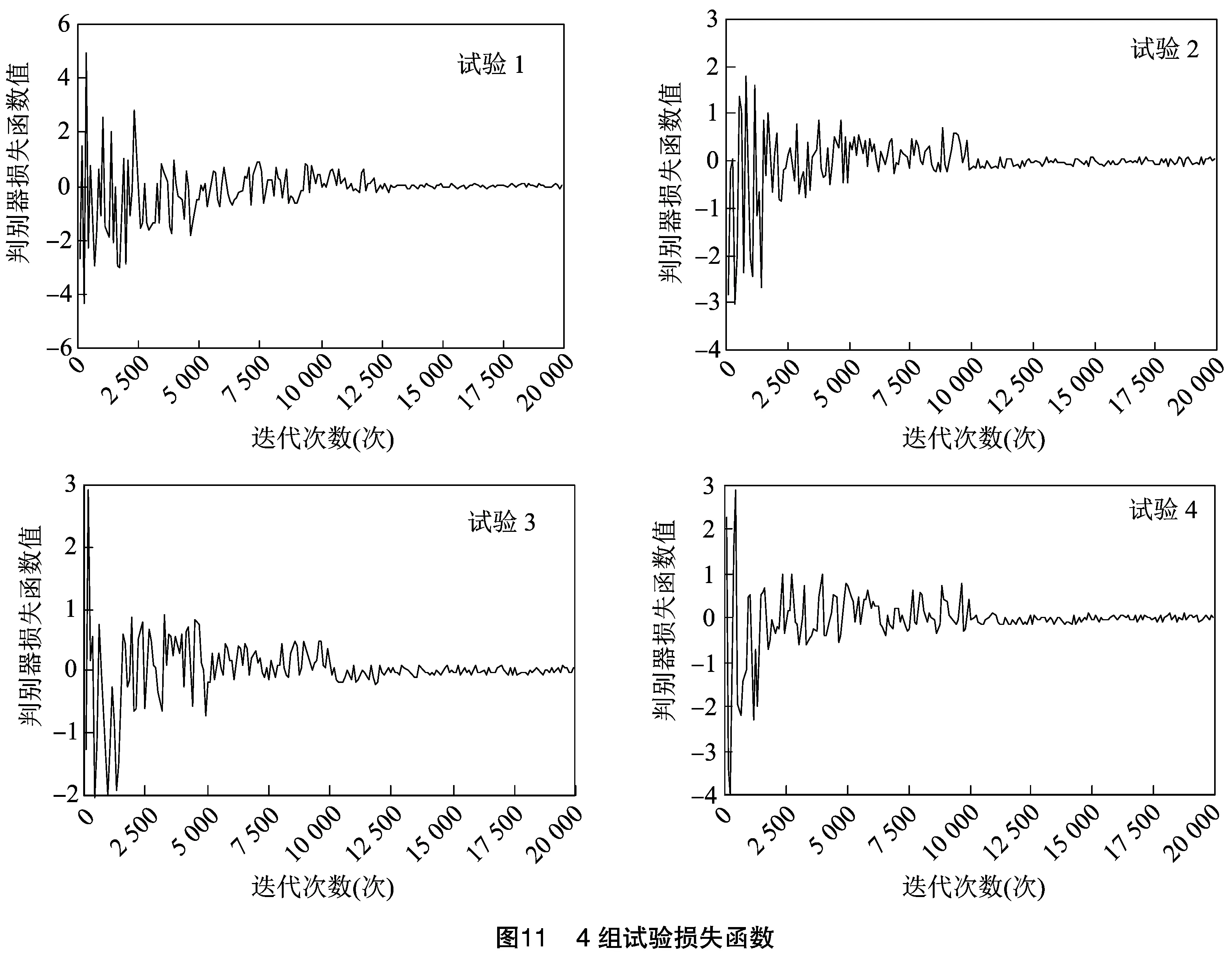
為驗證本研究生成的對抗網絡結構和融合損失函數的有效性,設置以下對比試驗進行驗證。試驗1、2、3均采用WGAN-GP模型,試驗1網絡結構以本研究生成器結構為基礎,去掉注意力機制,并采用反卷積神經網絡代替上采樣殘差塊結構。試驗2網絡結構以本研究生成器結構為基礎,并去掉注意力機制,試驗4為本研究生成對抗網絡模型,試驗3和試驗4均使用本研究生成器結構。判別器結構均與生成器相對應。生成花卉樣本如圖10所示。

圖10表明模型訓練完成后,生成器可以生成紋理清晰、視覺上和真實樣本高度相似且具有多樣性的模擬樣本。

本研究采用PSNR(峰值信噪比)、SSIM(結構相似性)和損失函數來對生成樣本質量進行評價,PSNR值越大表明生成樣本的質量越好,SSIM值越大表明生成樣本的視覺效果越好。表1為PSNR和SSIM評估值。

表1 生成樣本質量評估
圖11為4組試驗的損失函數圖。
由圖10、圖11和表1可看出,試驗1在迭代到 12 500 次時,模型損失函數趨于穩定收斂,生成的花卉樣本存在部分模糊情況,這是由于生成對抗網絡訓練并沒有充分學習到花卉樣本特征,PSNR值為24.48 dB,SSIM為0.788 2。試驗2相較于試驗1模型收斂速度加快,表明使用上采樣殘差塊加快了模型訓練速度,且提高了模型特征提取能力,使得生成對抗網絡生成樣本能力得到進一步提升,PSNR值為25.74 dB,SSIM值為0.816 4,生成的花卉樣本目標邊緣更加清晰,視覺效果較好,質量更高。試驗3在試驗2基礎上又加入了注意力機制,進一步關注有效花卉區域樣本特征,使得生成的花卉樣本紋理理細節更加清晰,PSNR為26.89 dB,SSIM為0.834 7。試驗4使用改進的融合損失函數,使得網絡進一步關注有效花卉區域,網絡模型訓練更加穩定,得到更高的PSNR和SSIM,生成花卉樣本紋理更清晰,視覺效果更好,質量更高,進一步說明本研究生成對抗網絡結構和融合損失函數的有效性。
2.2.2 花卉識別網絡訓練及生成樣本評估 花卉識別網絡使用Adam優化器調整模型參數,迭代次數為5 000,學習率為0.001,批處理樣本數為64,使用原始訓練集訓練花卉識別網絡。花卉識別網絡識別準確度如圖12所示。當網絡迭代到3 000次時,花卉識別率趨于穩定,達到92.49%,網絡達到最優狀態。

為測試生成器生成樣本的數量對花卉識別率的影響,設計了6組對比試驗,使用訓練完成的生成器為每張花卉數據對應生成50、60、70、80、90、100張模擬樣本作為訓練集訓練本研究的花卉識別網絡。試驗結果如圖13所示。
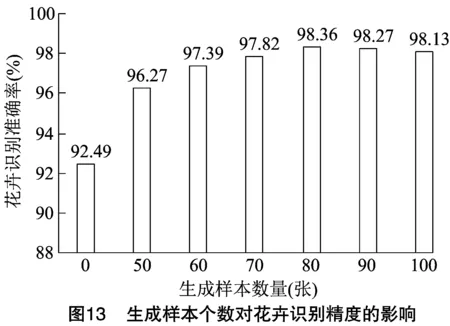
由圖13可以看出,使用生成樣本作為訓練集使得準確率得到了很大提升,表明ARWGAN-GP模型生成的樣本紋理清晰、視覺上和真實樣本高度相似且具有多樣性模擬樣本的有效性。隨著生成模擬樣本數量的增多,對花卉數據集的增強效果逐漸趨于穩定,當花卉樣本數達到80張時,花卉識別率逐漸趨于穩定,達到98.36%,此時模型已經處于收斂狀態。
為驗證本研究生成花卉樣本進行數據增強和花卉識別網絡的有效性,分別設置3組花卉識別網絡和6組數據集進行試驗驗證。采用傳統方法對原始數據集進行隨機裁剪、旋轉、縮放、偏移,等比例放大80倍,數據集設為D1,使用 “2.2.1”節4組試驗訓練完成后生成的樣本數據,分別對應生成80張花卉樣本,分別設為數據集D2、D3、D4、D5,花卉識別網絡分別采用“2.2.1”節的試驗1、試驗2、試驗4的判別器結構,并對最后的全連接層進行修改,花卉識別網絡分別設為Conv、DownRes、VaDownRes。試驗結果如表2所示。

表2 不同條件下花卉識別率
由表2可知,在不采用數據增強時,在3個分類網絡上花卉識別平均準確率為91.21%,在D1數據集進行訓練得到了92.75%的平均花卉識別率,而在D2數據集上進行訓練則取得了95.14%的平均花卉識別率,相較于前2組數據集有較大提高。這是由于CNN對于旋轉、縮放、偏移、裁剪等存在相應的不變性,在采用裁剪、旋轉、縮放、偏移進行數據增強時,部分生成的樣本數據和真實樣本特性相同,僅僅是對真實數據的簡單復制,生成的模擬樣本數據多樣性不足,使得網絡識別效果不理想。而生成對抗網絡進行訓練時,生成器和判別器通過交替訓練不斷學習花卉樣本特性,不斷擬合花卉數據,當模型訓練完成后,生成器可以生成紋理清晰、視覺上和真實樣本高度相似且具有多樣性的模擬樣本,大幅度提高了花卉識別準確度。對比試驗分析得到,在D5數據集上訓練得到的花卉識別率要高于在D2、D3、D4數據集上訓練得到的結果,表明本研究生成的對抗網絡結構和融合損失函數具有有效性,進一步說明采用生成對抗網絡生成模擬花卉樣本可有效進行數據增強。
由表2可以看出,在6個花卉數據集上,DownRes模型的平均花卉識別率為94.70%,高于在Conv模型上的平均花卉識別率93.15%,表明使用下采樣殘差塊構建花卉識別網絡相較卷積神經網絡大幅度提高了花卉特征提取能力,進一步說明花卉識別網絡采用下采樣殘差塊提取花卉樣本特征更高效。在花卉識別網絡融入注意力機制后,VaDownRes模型的平均花卉識別率得到了較大提高,進一步說明融入注意力機制后,使得花卉顯著區域特征提取能力得到提高,大幅度提高了花卉的識別準確率。
2.2.3 花卉識別方法對比試驗 設置以下試驗驗證本研究方法的有效性。
試驗1:文獻[17]提出使用CNN來進行花卉識別,與傳統的花卉識別方法不同,該方法使用CNN自動學習花卉樣本特性。
試驗2:文獻[18]提出在CNN添加注意力機制進行花卉識別,使用CNN自動提取樣本特征,通過注意力機制進一步提取深度特征。
試驗3:采用文獻[19]提出的方法,利用預訓練模型resnet50在花卉圖像上進行遷移微調,重新構建新的分類層,在本研究原始數據集上進行重新訓練。
試驗4:采用文獻[9]提出的方法,以resnet50為基礎框架構建基于注意力機制驅動的殘差網絡,并通過全局平均池化和全連接層實現花卉分類,在本研究原始數據集上重訓練。
試驗5:使用花卉數據集訓練ARWGAN-GP,訓練結束后使用生成器網絡進行數據增強,且遷移D參數到花卉識別網絡,對其參數微調,使用增強數據重新訓練花卉識別網絡模型。
不同試驗下花卉識別準確度如表3所示。

表3 不同試驗下花卉識別準確度
由表3可知,試驗1基于CNN進行自動提取花卉特征可以達到83.00%的準確度。試驗2在CNN的基礎上添加注意力機制,相比單獨使用CNN進行花卉識別,該方法利用注意力機制融合花卉樣本的局部和全局特征,進一步學習捕獲到深度花卉特征,在一定程度上提高了準確率。試驗3使用深度殘差網絡進行花卉識別,相比使用CNN提高了花卉識別準確度,這是由于為了提高網絡的識別率,需要增強網絡深度,但這會導致梯度消失,而殘差網絡改善了該缺陷,殘差網絡更容易優化,收斂更快且準確度更高。試驗4在深度殘差神經網絡的基礎上加入了注意力機制,相比試驗3提高了花卉識別率,加入注意力機制后,可以有效提取花卉顯著區域特征,減小噪聲干擾,增強了網絡的學習能力,使得準確度更高。試驗5采用本研究提出的花卉識別網絡模型,相比前4組試驗,該方法更進一步提高了花卉識別準確度,這是由于前4組試驗的數據量偏小,很難達到較好的收斂效果。而本研究采用殘差網絡和注意力機制構建生成對抗網絡,并使用融合損失函數,使得生成對抗網絡充分提取到了花卉樣本特征,使用訓練結束的ARWGAN-GP模型進行數據增強,使得樣本得到了有效擴充,且遷移D參數到花卉識別網絡,加快了花卉識別網絡模型的收斂速度,使用生成數據進行訓練花卉識別網絡,進一步提高了模型的識別率。
3 結束語
本研究提出了一種基于改進生成對抗網絡的花卉識別方法。使用殘差網絡構建生成器和判別器,解決了網絡深度加深時出現的梯度消失和訓練不穩定問題,使得網絡收斂更快;融入了注意力機制,可以快速有效地提取花卉顯著區域特征,減小了噪聲干擾,且改進了損失函數,進一步提高生成對抗網絡的能力;ARWGAN-GP訓練結束后,采用生成器進行數據增強,遷移判別器參數到花卉識別模型,并進行參數微調,加快了模型的收斂速度,進一步提高了模型的識別準確度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
