基于Segnet網絡和遷移學習的全景街區影像變化檢測
2022-12-13 00:33:54余曉娜陳朋弟
重慶大學學報 2022年11期
余曉娜,黃 亮, ,陳朋弟
(1.昆明理工大學 國土資源工程學院,昆明 650093;2.云南省高校高原山區空間信息測繪技術應用工程研究中心,昆明 650093)
街區作為城市建筑物的主要組成部分,精確、實時地對道路街區進行變化提取,對于城市規劃和土地利用調查具有十分重要的作用。例如,在城市發展中所出現的居民區改造、工業區向郊區遷移、商業區整改等。全景街區影像研究通過不同時期影像的獲取,可以對城市街道的違建、違停進行排查,保證一個規整有序的城市環境。對全景街區影像進行變化檢測,不僅能輔助城市的違章排查、災后評估,還能檢測出城市土地利用的變化情況,為政府在城市建設方面提供科學合理的理論參考。全景街區影像是指通過車載相機所采集到的360°街區全視場影像[1]。但是由于全景影像所包含的地物復雜,不僅包括建筑物上的玻璃幕墻,還包括一些廢墟、電線桿、交通燈等,所以傳統的方法不適用于全景街區影像的變化檢測。
目前,有很少一部分學者對全景街區影像的變化檢測鄰域進行研究。主要原因是對全景街區的變化檢測存在“語義鴻溝”問題[2-3]。軒永倉等基于FCN網絡模型實現圖像像素級的預測,為復雜場景圖像的語義分割做了良好鋪墊[4]。Wu C等運用貝葉斯理論和基于規則的方法,提高了場景變化檢測準確率[5]。Arabi Mohammed El Amin等提出了一種基于CNN特征的衛星圖像變化檢測方法,并得到較高精度[6]。劉文濤等通過級聯式FCN和空洞卷積的方法,實現建筑物屋頂的精確分割和提取[7]。魏楊等基于深度學習識別出初步候選區,其次通過Fast R-CNN網絡框架,實現農作物蟲害的精準識別[8]。鄧國徽提出的基于改進的FCN網絡模型算法準確地識別出施工場地[9]。Nicolas等通過引入多核卷積,并基于SegNet框架執行準確的語義分割,最終實現全景影像的準確標記[10]。雖然深度學習在遙感領域的應用比較廣泛,也得到了比較理想的效果,但目前國內外對于全景街區影像的變化檢測研究則相對較少。
筆者采用全景街區影像作為實驗數據,并結合深度學習和遷移學習的思想,提出了基于Segnet網絡的全景街區影像變化檢測。相比傳統方法,采用SegNet進行語義分割,可以更好地區分出不同地物目標,更加準確地進行地物提取。采用遷移學習的思想,可以大大縮短訓練時間,提高實驗精度,還為全景街區影像的變化檢測研究提供理論參考。該方法在語義層次上檢測到區域的變化情況,對現實中的街道違建排查、土地利用情況以及城市規劃方面有重要意義。
1 全景街區影像變化檢測
筆者研究了基于Segnet網絡和遷移學習的全景街區影像變化檢測。首先,對數據集“TSUNAMI”做預訓練;其次,對訓練集進行分類歸并,分類歸并的主要依據是地物的光譜、紋理等特征;然后,通過Segnet網絡對實驗數據進行語義分割,得到語義分割結果圖;最后,對2幅語義分割結果圖進行差值運算,得到最終的變化結果圖,并對實驗結果進行精度評價。與傳統的方法相比,先對數據做訓練,對訓練模型做信息的分類歸并,再進行語義分割,較傳統方法得到較高精度。采用Segnet網絡做語義分割使變化信息提取更加準確,并對類和類之間的區分也更加明顯。另一方面,Segnet網絡和遷移學習相結合,大大減少了實驗的工作量,縮短實驗時間,提高實驗結果的精度。該方法不僅適用于全景街區影像的變化檢測,也適用于道路、建筑物、交通標志等信息的提取,有較大發展潛力,其技術路線圖如圖1所示。
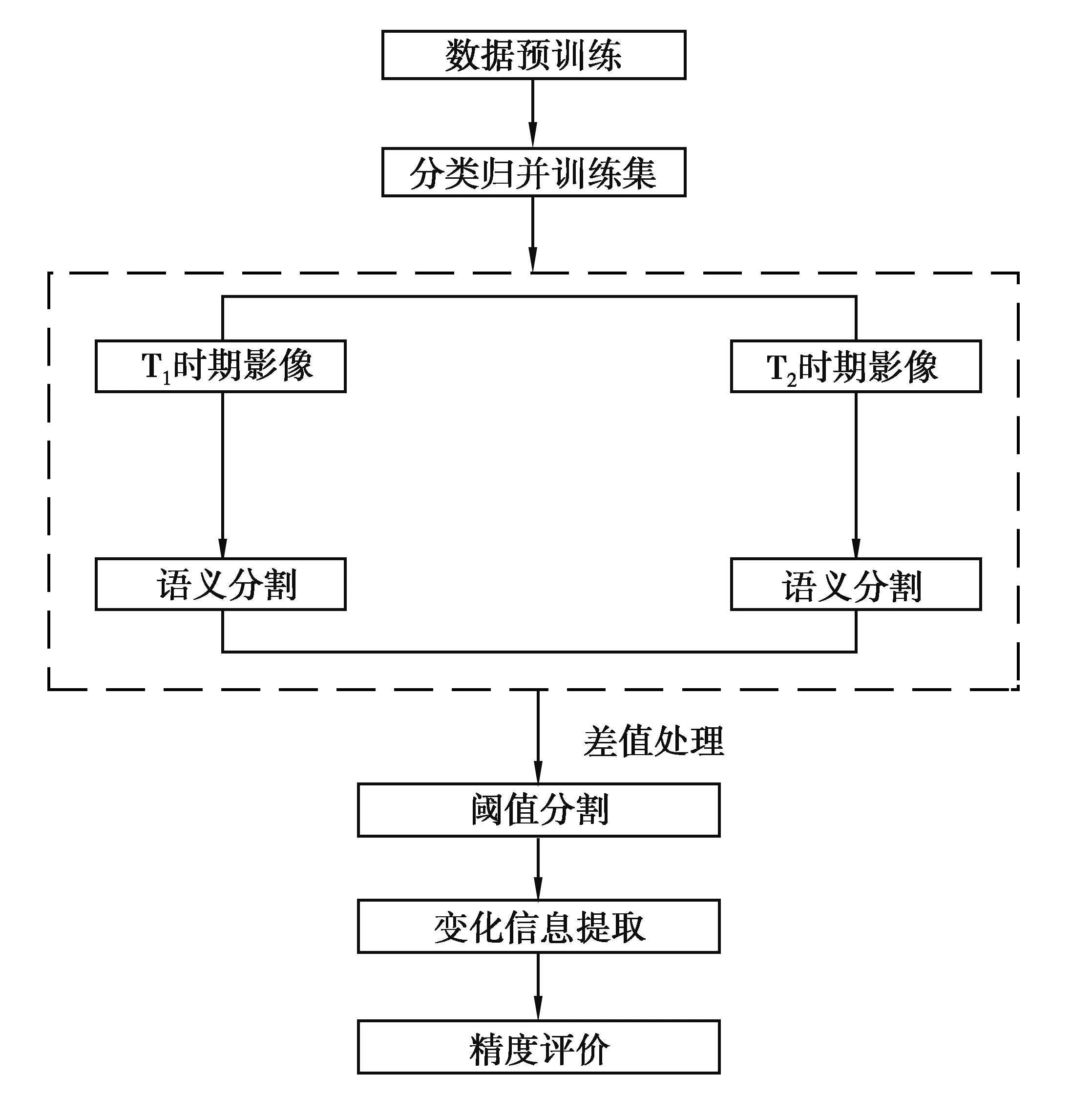
圖1 技術路線圖Fig. 1 Technical roadmap
1.1 Segnet神經網絡
Hinton G.E.在2006年第一次提出了深度學習的概念[11]。深度學習中常見的網絡結構有CNN、FCN、PSPNet、U-Net、Segnet等,研究選取了目前應用比較成熟且廣泛的Segnet網絡模型作為實驗模型。Segnet網絡的核心主要包括一個編碼網絡和一個與之對應的解碼網絡。Segnet網絡沿用了FCN圖像語義分割的思想,并且該網絡是基于像素級別的端到端網絡架構。Segnet沿用了FCN網絡模型的思想,將VGG16中的全連接層去掉,將編碼(encoder)信息和解碼(decoder)信息直接連接,編碼網絡和解碼網絡作為整個網絡結構的核心部分,其優點是保留了影像中大量有用的特征信息,使實驗過程中需要訓練的參數大大減少,縮減了實驗數據的訓練時間,最重要的是得到了相對較高精度的語義分割圖像。
Segnet神經網絡結構如圖2所示:Segnet的網絡結構主要包括卷積層(convolution)、歸一化層(batch normalisation)、激活函數(ReLU)以及池化層(pooling)。
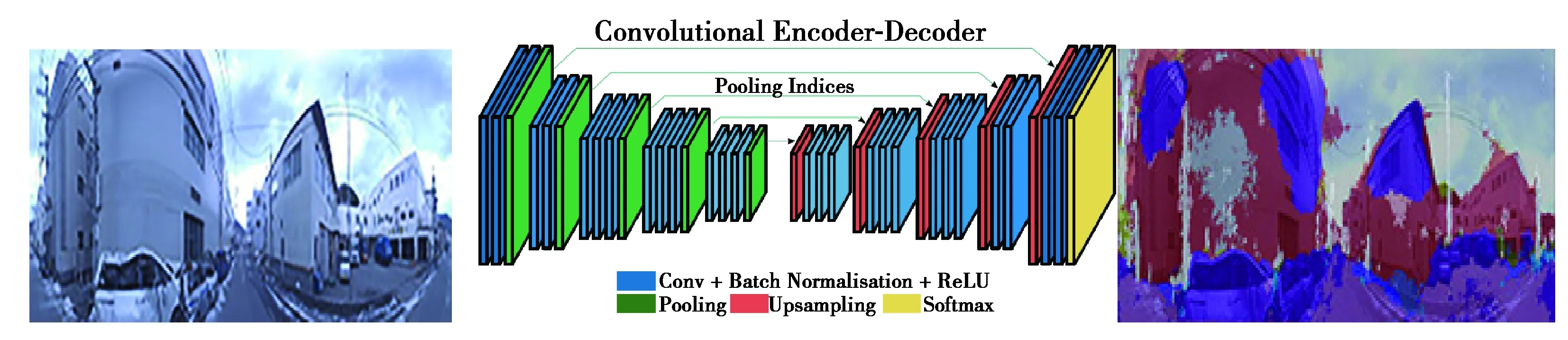
圖2 Segnet神經網絡結構圖Fig 2 Segnet neural network structure
從圖2可以看出,Segnet網絡結構是一個對稱的網絡模型,網絡的左邊表示編碼網絡,右邊表示解碼網絡。Segnet網絡的基本工作原理:在網絡結構中,pooling層與upsampling層主要進行影像分割,在整個網絡結構中,特征地物的提取主要依靠位于左邊的卷積層來完成,然而在提取的過程中,pooling層的主要作用是使圖片逐漸變小,這個過程被稱為編碼;右邊的網絡架構主要進行反卷積和upsampling操作,反卷積主要是使得圖像的分類特征得以體現,而upsampling層主要是將分割后的影像恢復和原始輸入圖像一樣的大小,這個過程稱為解碼過程。通過編碼網絡不斷提取特征,隨之傳輸到相應的解碼網絡,對分割圖像進行解碼,最后再通過softmax分類器輸出最終的語義分割結果圖。
通過卷積運算,使影像中有用的特征信息更加突出,而忽略及削減影像中次要的信息,達到抑制噪聲的目的。連接在卷積層之后的稱為池化層,一般來說,池化層中特征圖的個數和卷積層的特征圖個數是保持一致的,兩者之間是一一對應的關系。其中Maximum pooling、Mean pooling、Random pooling以及Pyramid pooling等是目前常用的池化方法[12-14]。
在Segnet的訓練過程中,由于線性表達無法滿足樣本的多樣性,以及實驗過程中的復雜分類識別任務和訓練數據集過大等原因,通常采用ReLU函數進行擬合。ReLU激活函數是目前大多數卷積神經網絡所采用的激活函數,ReLU函數具有計算靈活、收斂快等特點,主要解決梯度下降的問題。其數學表達式為
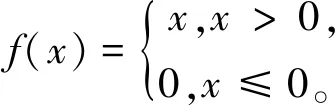
(1)
當輸出信號大于0時,輸出等于輸入;當輸出信號小于等于0時,輸出等于0。歸一化層一般用于激活函數之前,最主要的作用是使學習的速度加快。
2010年,Zeiler等提出了反卷積的概念[15]。從網絡結構上來說,反卷積層相當于一個上采樣的過程,在訓練過程中,通常由于全連接層的維度太大,訓練的時候會出現參數增加而增大計算量的情況,為了解決這個問題,通常引入反卷積層。這樣做的主要原因是因為反卷積層能把圖像丟失的信息找回來,這樣能最大限度的保留上下文信息,使得訓練結果更加準確。
由于測試數據集較少,于是通過對圖像的拉伸、旋轉、平移等操作,增大數據集,把需要測試的數據集放進已經訓練好的網絡模型中,這樣不僅縮短了訓練時間,而且得到了較高的精度。
1.2 遷移學習
遷移學習于1990年出現在機器學習領域[16-17]。遷移學習的實質就是運用已有的知識解決相關領域問題的一種方法,最終實現知識在相關領域之間的遷移。在深度學習的過程中,為了克服實驗數據樣本過少,導致模型泛化能力不足,網絡出現過擬合的現象,需引入遷移學習。采用遷移學習需要注意2個問題:一是新的學習中需要識別的類別在預訓練模型中訓練過;二是預訓練模型應該具有足夠的泛化能力。在計算機視覺和遙感影像處理領域,遷移學習的應用是很常見的,遷移學習能夠優化網絡訓練模型,減少數據集訓練的時間,解決卷積神經網絡在訓練時樣本較少的問題,遷移學習的廣泛應用在一定程度上也能擴大卷積神經網絡的應用領域。一般來說,按照遷移學習研究的內容不同,將遷移學習分為4種[18]:以實例為研究對象、以特征為研究對象、以參數為研究對象以及基于關聯規則的遷移學習。遷移學習示意圖如圖3所示。
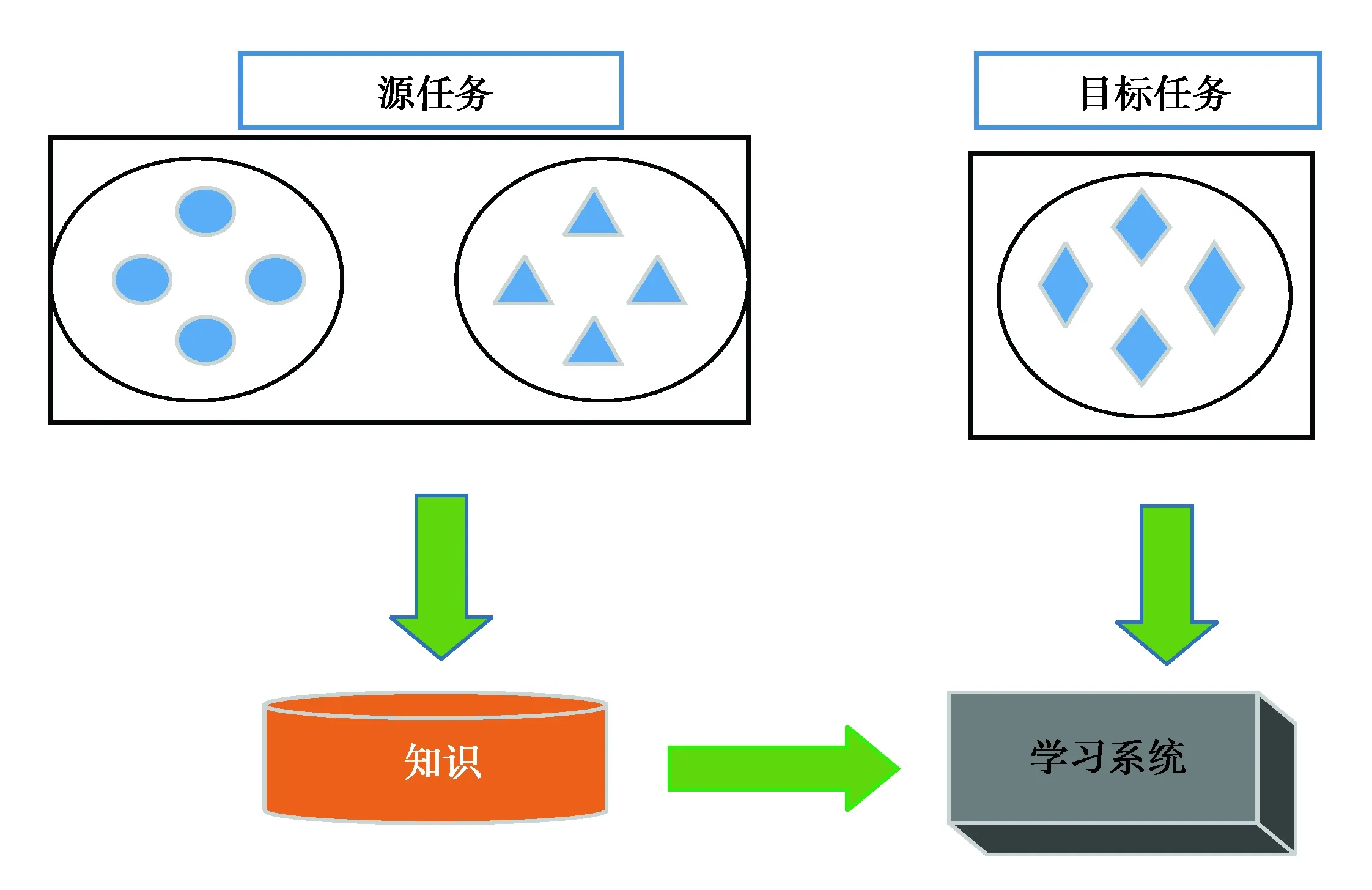
圖3 遷移學習示意圖Fig 3 Schematic diagram of migration learning
2 實驗結果及分析
2.1 數據來源
數據來源于日本東北大學情報科學研究所,是日本某一地區海嘯前后的全景街區影像。該數據獲取使用與GPS數據匹配的車輛,其具體做法是在一輛車上安裝全方位攝像頭,通過車頂上的GPS傳感器,在一個城市的街道上相隔一段時間,采集2次數據,得到2組全方位街區影像。分別在海嘯前和海嘯后進行數據采集,得到如圖4所示的全景街區影像。選取2組原始影像作為實驗數據,其中圖4表示的是典型的全景街區影像,而圖5表示的是空曠郊區的影像,選取這2組影像,目的是驗證方法對不同類型的全景街區影像都適用。圖4、圖5中2組影像的大小都為1 024像素×224像素,通過目視判讀,可以看出圖4中包括了建筑物、天空、電線桿、道路、車輛等地物。圖5中包括了建筑物、天空、車輛、空地等基本地物,從影像中可以看出,不同的拍攝環境及拍攝條件,得到的同一地區影像的光譜特征、紋理特征存在較大差異,這一現象給實驗帶來巨大挑戰。實驗選擇最大似然法、SVM作為Segnet的對比實驗。

圖4 第一組實驗數據Fig. 4 Data of the first experiment

圖5 第二組實驗數據Fig 5 Data of the second experiment
2.2 實驗結果分析
研究首先采用機器學習的方法對原始圖像進行變化檢測:基于ENVI對2組影像進行處理,分別采用了最大似然法和支持向量機的方法對原始數據進行分類,將得到的分類數據相減,得到的結果如圖6(b)、6(c)和圖7(b)、7(c)所示;采用提出方法得到的變化檢測結果如圖6(d)和圖7(d)所示。其中圖6為原始數據一的變化檢測結果圖,圖7為原始數據二的變化檢測結果圖。然后將相減結果與參考圖6(a)、圖7(a)分別進行精度評價。

圖6 第一組實驗結果圖Fig 6 The first set of experimental results
對于第一組實驗結果,最大似然和SVM方法的精度分別為65.1%和72.1%,提出方法的精度為81.4%。從變化的結果圖中可以看出:與參考圖對比,最大似然法和SVM的方法對建筑物墻體和道路的分類比較差,尤其是影像最左邊的墻體及墻體上的窗戶,都出現了錯分現象,道路的分類主要存在的問題是邊界線沒有提取出來,仍然有錯分的情況。對比圖4,可以看出造成這種現象最主要的原因是光譜差異,圖4中變化前和變化后的影像光譜差異明顯,并且主要體現在建筑物和道路上。造成這種現象的原因可能是數據獲取時天氣、光照等條件存在差異。而提出的方法對于建筑物和天空的分類結果比較好,一個比較大的問題是在變化后的影像中,對于車輛的提取結果較差,但是總體精度有所提高。

圖7 第二組實驗結果圖Fig 7 The second set of experimental results
對于第二組實驗結果,最大似然和SVM 2種方法的精度分別為66.5%和70.6%,提出的方法精度為82.2%。從變化的結果圖中看出:與參考圖對比,最大似然法存在的問題是對建筑物的分類結果較差,基本整個建筑物都被錯分為其他地物,主要原因是紋理信息比較相像。SVM方法的優勢在于對道路的提取有很好的效果,整個道路都被提取出來,且沒有出現噪聲和碎小的圖斑,但是整個天空出現了較大部分錯分的情況。參照圖5,可以初步推斷造成這種現象的原因是變化前后的影像中,天空的光譜差異較明顯。對于提出的方法,分類結果明顯改善,但是也存在對地物邊界識別不明顯的問題,盡管如此,提出方法較最大似然法和SVM的變化檢測精度有較大提高。根據以上變化檢測結果,可以得出結論:雖然機器學習方法在遙感影像變化檢測中應用也較廣泛,但是仍然不適用于全景街區影像的變化檢測。
研究采用漏檢率、錯檢率以及總體精度作為精度評價的指標。其中漏檢率指實際變化了,但是被檢測為未變化的像元數占總像元的比例;錯檢率是指實際未變化,但被檢測為變化的像元數站總像元數的比例;總體精度指正確變化的像元數占總像元數的比例[19]。研究方法與機器學習的方法相比,其分類的精度和變化檢測的精度都得到了明顯提高。在第一組實驗數據中,基于Segnet網絡的變化檢測方法較其他2種方法,精度分別提高了16.3%和9.3%;在第二組實驗數據中,基于Segnet網絡的變化檢測方法較其他2種方法,精度分別提高了15.7%和11.6%。說明Segnet網絡適用于全景街區影像的變化檢測,Segnet網絡在全景街區影像變化檢測中的應用,為街道違建、違章、違停排查,災后評估提供了有力的理論支撐,對于城市的科學規劃和輔助政府決策作出了重大貢獻,其對比結果如表1和表2所示。

表1 第一組實驗結果精度對比Table 1 Comparison of the accuracy of the first set of experimental results %

表2 第二組實驗結果精度對比Table 2 Comparison of the accuracy of the second set of experimental results %
第一組實驗結果中最大似然法、支持向量機、基于Segnet網絡的漏檢率分別為4.9%、5.7%、10.6%,錯檢率分別為30.0%、22.2%、8.0%;第二組實驗結果中最大似然法、支持向量機、基于Segnet網絡的漏檢率分別為1.5%、2.6%、2.5%,錯檢率分別為32.0%、26.7%、15.3%。
3 結 論
針對采用傳統方法難以得到高精度的全景街區變化信息的問題,提出了一種基于Segnet和遷移學習的全景街區影像變化檢測方法。在實驗過程中,實驗數據主要是2組變化前后的全景街區影像,并采用了最大似然法以及SVM作為對比實驗,得出以下結論:
1)從實驗結果圖中可以看出,道路和天空的變化信息的提取精度相對較高,而建筑物由于受紋理信息復雜性和相鄰地物的干擾,其檢測的精度相對較低。
2)2組實驗中最大似然法、SVM、Segnet的總體精度分別為65.1%、72.1%、81.4%和66.5%、70.6%、82.2%,提出方法較最大似然法和支持向量機的方法精度明顯提高。在災后評估、街區違建違停排查、城市道路合理規劃、土地利用變化等領域有著重要的作用。
3)基于Segnet神經網絡和遷移學習的思想,通過對已有訓練集的改進,使最終精度較機器學習的方法有了很大提高,但是并沒有達到最佳效果。針對數據集重新制定訓練集,并對數據重新進行實驗,以得到更高精度是下一步將開展的工作。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
兒童故事畫報(2019年5期)2019-05-26 14:26:14
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
