基于多模態融合的視頻情感分析技術
2022-12-13 03:38:22陳詩漢馬洪江何松澤
成都信息工程大學學報 2022年6期
陳詩漢, 馬洪江, 王 婷, 何松澤
(成都信息工程大學計算機學院,四川 成都 610200)
0 引言
近年來隨著社交媒體的快速發展以及智能手機的普及,多模態數據呈爆炸式增長,如圖像、視頻等。多模態數據是用戶交流和記錄生活的媒介,通常蘊涵著豐富的個人情感。從多模態數據中挖掘和理解情感信息,即多模態情感分析(multimodal sentiment analysis,MSA),已經成為一個熱門的研究課題。相較于傳統的文本情感信息提取,對于視頻這類的多模態數據提取會存在很多困難,因為其包含了語音、文本以及圖像信息。而且傳統的基于單模態情感分析的機器學習方法在多模態情感分析這類任務上存在較大的局限性[1]。
鑒于人可以用不同的方式表達情感,包括使用不同的聲調或面部表情,對于這些多模態數據,同一數據段中的不同模態會相互補充[2],為語義和情感消歧提供額外幫助。因此可以使用多模態融合相關技術來識別人類的情感[3]。多模態融合技術是一種從海量多模態數據中提取整合信息并可用于提高信息處理效率的技術[4],現已被廣泛用于處理結構化數據和文本數據[5]。目前該領域的大部分工作都集中在早期或晚期融合上。早期的融合模型采用簡單的網絡架構,Zadeh等[6]提出了一個張量融合網絡,在更深層融合了不同的模態表征。薛其威等[7]通過多模態特征融合對無人駕駛系統車輛進行檢測,在KITTI數據集上其平均檢測精度為84.71%。另外,Sun等[8]優化了模態表征之間的相關性以進行融合,然后將融合結果傳遞給下游任務。
受深度學習的影響,各類相關研究層出不窮,其中注意力機制獲得廣泛關注,LSTM(long short-term memory)被用于隨時間捕獲模態之間的交互。顏增顯等[9]利用多模態通道注意力網絡來融合不同模態的特征進行人臉反欺騙算法研究,在CASIA-SURF數據集上獲得良好的效果。王旭陽等[10]利用注意力機制與時域卷積網絡建立多模態融合的模型,在CMU-MOSI數據集上相較于基線有了較大的提升。Tsai等[11]提出一種可以動態調整模態之間的權重,為多模態融合提供可解釋性的方案。受模態分離領域進步的推動,Hazarika等[12]將模態特征投影到專有和公共特征空間中,以捕捉不同模態的獨有和共享特征以方便后期進行融合。雖然這些研究中能達到的效果比較有限,但也為后續相關研究做好了相應的鋪墊。Makiuchi等[13]提出了一種基于Transformer的模型將語音和文本數據進行融合,在IEMOCAP數據集上得到73.0%的準確率。Byun等[14]也提出了一種利用深度學習融合語音和文本數據進行情感識別的模型,在自行構建的韓語數據集上達到了95.97%的準確率。還有黃歡等[15]設計了一個AV-MSA模型,利用交叉投票機制將視覺與音頻信息融合進行情感分析,在IEMOCAP和WB-AV數據集上取得了較好的效果,這些研究表明情感識別任務可以從多模態中受益。
在MSA任務中進行信息抽取以及信息融合的時候可能會丟失實際信息并額外引入每種模態攜帶的噪聲。為減少這個問題帶來的影響,一種互信息(mutual information,MI)方法被用于評估成對的多維變量(即各個模態)之間的依賴關系,并且可有效去除與下游任務無關的冗余信息[16]。由于互信息在處理時,會存在信息丟失的問題[17]。本文基本互信息方法提出了一種多模態融合最大化模型(multi-modal fusion max,MMFM),其核心是在多模態融合中分層最大化互信息。
本文提出一種基于多模態融合的分層MI最大化模型,用于多模態情感分析。其中多模態融合最大化發生在輸入和融合模塊,可以減少有價值任務相關信息的丟失。在公開的情感數據集上進行的實驗,獲得較好的效果。
1 方法
1.1 概述
在多模態情感分析任務中,模型的輸入是從視頻片段中提取的單模態原始序列Xm,其中m表示向量維數。文中,m∈{t,v,a},其中t,v,a分別表示3種不同類型的模態——文本、視覺和聲音。目標是從這些輸入向量中提取和整合關于任務相關的情感信息,形成統一的表示,并將其用于對反映情感強度的真值y進行準確預測。
1.2 整體架構
整體框架結構如圖1所示,輸入的信息包括視頻、文本和語音3種。首先,模型使用特征提取器和編碼器分別將3種原始輸入處理為數字序列向量Xv,Xa,Xt。然后,編碼后的數據主要經過融合網絡和MI最大化兩部分進行處理,分別對應著圖1中的實線和虛線標記。其中,在融合部分融合網絡將不同模態信息兩兩交互,將單模表示轉換為融合結果K,再通過回歸多層感知器(multi-layer perception,MLP)進行最終的預測。在互信息部分,MI最大化是為了估計和提升輸入層和融合層的MI下界。這兩個部分同時工作用于產生后續識別任務以及互信息相關的損失,通過模型學習將任務相關信息融入融合結果,并提高主任務中預測的準確性。
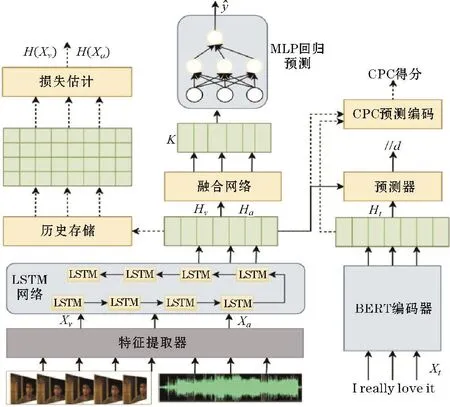
圖1 模型總體結構
1.3 模態編碼
模態編碼負責將多模態順序輸入Xm編碼為單位長度表示為 Hm具體來說,對于文本信息,使用BERT[18](bidirectional encoder representation from transformers)對輸入句子進行編碼,并從最后一層的輸出中提取頭部嵌入作為Ht。對于視覺和聲學的內容,采用兩種特定于模態的單向LSTM[19]捕捉這些模態的時間特征。
1.4 模態間MI最大化
互信息是信息論中的一個概念,用于估計變量對之間的關系[20],定義為

其中x與y為不同的隨機變量。
Alemi等[21]首先將與MI相關的優化結合到深度學習模型中。另外在其他研究中也有證明MI最大化的優勢[22]。然而,由于在高維空間中直接進行MI幾乎是不可能的,所以很多工作都是直接優化MI的下界。文中,是在輸入級別和融合級別應用MI下界,并根據要估計的項的數據特征和數學屬性制定這些界限的估計方法。
MI可以評估視頻中不同模態間的依賴程度,通過將MI最大化可以實現多模態間更好的融合。對于視頻V,將來自單個視頻剪輯的模態表示對標記為X和Y(它們之間通常存在相關性),在先驗分布已知時,可以將X和Y的先驗分布化為P(X)=∫VP(X,Y|V)P(V),P(Y)=∫VP(Y|V)P(V),聯合分布為P(X,Y)=∫VP(X,Y|V)P(V)。因存在相關性,可以利用MI過濾掉與任務無關的噪聲來提高性能。基于以上分析,為實現多模態更大程度的融合并且保持模態內容不變,本文利用一個易于處理的MI下限,而不是直接計算MI,并參照Baber等[23]采用的較為準確且直接的MI下限,其近似于真值條件分布p(y|x),如式(2)所示。
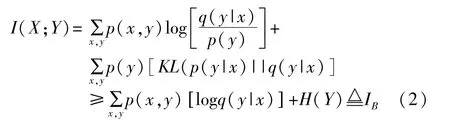
其中q(y|x)是預測的概率分布,KL是用于度量兩個概率分布相似度的指標,H(Y)是Y的微分熵,IB為Baber等使用的MI下界。當q(y|x)=p(y|x)時,界值和真值之間沒有差距。在每一對模態(X,Y)中,其中一個模態視為X,則另外一個模態視為Y。然后訓練一個預測器q(y|x)來逼近p(y|x)。本文在實驗過程中優化了不同模態對的邊界—文本與視覺、文本與聲學、視覺與聲學。另外,在消融研究部分檢查了設計的有效性。將q(y|x)公式化為多元高斯分布qθ(y|x)=N(y|μθ1(x),(x)I),兩個神經網絡由 θ1和 θ2參數化為分別預測均值和方差。損失函數為:
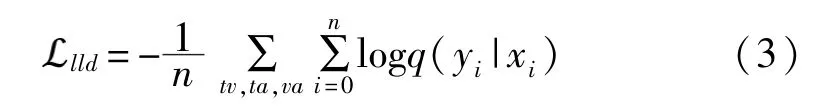
其中n是訓練中的批量大小,tv,ta,va表示3個預測變量的可能性之和。
本文采用情感極性(非負/負)作為分類標準,它是數據集中的一個自然屬性,可以平衡估計精度和計算成本。對于熵項H(Y),使用高斯混合模型(Gaussian mixed model,GMM)來求解計算,這是一種常用的未知分布近似方法。GMM為不同的屬性類別建立了多個高斯分布。多元正態分布的熵為:

式中k是GMM中向量的維數,det(∑)是協方差矩陣∑的行列式。基于數據集中兩個極性類別的頻率幾乎相等,本文采用來自Huber等[24]使用的GMM熵的下界和上界,公式如下:
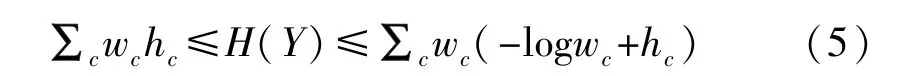
其中hc是c類的子分布的熵,wc為c類子分布的先驗概率。取下界作為近似值,得到MI下界的熵項:
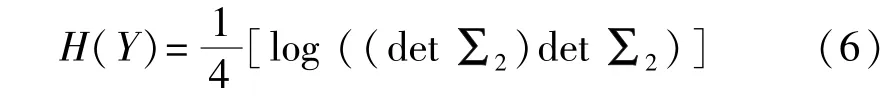
另外,在訓練時,根據統計理論,應該增加批量大小以減少估計誤差,可以通過包含最近歷史的數據來間接擴大采樣批次。在實驗過程中將這些數據存儲在歷史數據存儲器中,MI下限最大化的損失函數由式(7)給出:
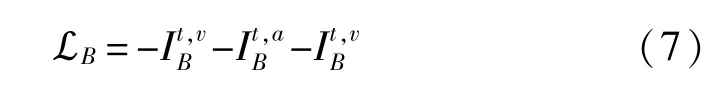
1.5 融合層面的MI最大化
為捕獲模態之間的模態不變線索,在融合結果和輸入模態之間重復MI最大化。目標是產生融合結果K=F(Xt,Xv,Xa)的融合網絡F。由于已經有了從Xm到K的生成路徑,考慮一條相反的路徑,即從K構造Xm,m∈{t,v,a}。可以使用分數函數作用于歸一化的預測和真值向量來衡量它們的相關性:

其中Gφ是參數φ的神經網絡,它從K生成Hm的預測,通過將同一批次中該模態的所有其他表示視為負樣本,將這個分數函數合并到噪聲對比估計框架[25]中,即
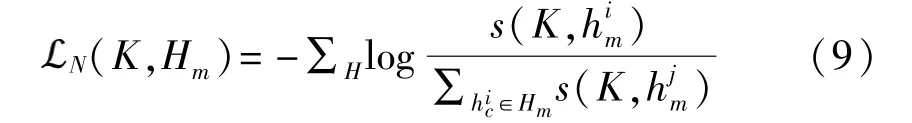
等式(9)實際上視為二分類交叉熵損失,H是一組樣本,公式中分數上下兩部分可以視為正負樣本對,當正樣本對之間的互信息更大,負樣本對之間的互信息更小時,符合互信息最大化要求,因此通過優化該損失,可以讓互信息最大化。由于對比預測編碼(contrastive predictive coding,CPC)可以學習更多的全局結構,在模型中,融合結果K反向預測跨模態的表示,以便可以將更多模態固有信息傳遞給K。此外,通過將每個模態的預測對齊,使模型能夠決定它應該從每種模態中接收到多少信息。損失函數為
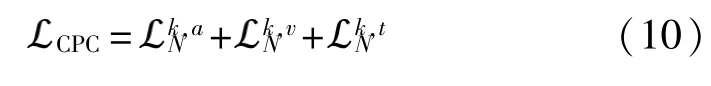
1.6 訓練
訓練過程包括兩個階段:在第一階段,近似p(y|x)與q(y|x)通過最小化多模態預測變量的負對數似然。在第二階段,將之前的MI下界作為輔助損失添加到主要損失中。在獲得最終預測及真值y后得到任務損失:
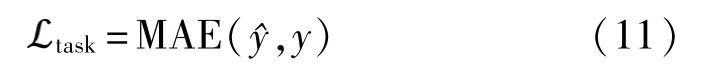
其中MAE(mean absolute error)代表平均絕對誤差損失。最后來計算所有這些損失的加權和以獲得該階段的主要損失:
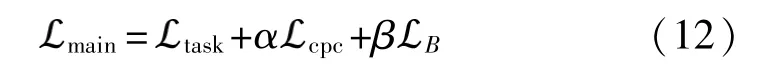
其中α、β是控制 MI最大化影響的超參數。
2 實驗
2.1 數據集
采用數據集為關于多模態情感分析研究的公開數據集,即 CMU-MOSEI[26],它包含來自 YouTube的23454個電影視頻剪輯。
2.2 基本設置與指標
本文分別采用P2FA[27]和COVAREP[28]工具包對于圖像和音頻內容進行特征提取。而對于文本內容,使用預訓練好的BERT模型來獲得詞向量,最后在GPU上訓練模型。評測指標如下:平均絕對誤差(MAE),它是預測值和真值之間的平均絕對差值,衡量預測偏斜程度的皮爾遜相關性(pearson correlation,Corr),七分類準確度(seven-classclassification accuracy,Acc-7),二分類準確度(binary classification accuracy,Acc-2)和F1分數。
2.3 模型比較
為了解本文模型的相對性能,將模型與許多具有較好效果的基線進行比較,如 TFN[14]、LMF[29]、MFM[16]、MULT[11]、ICCN[30]和 MISA[13]。
2.4 結果
實驗結果見表1所示,對于Acc-2和F1值有兩組評估結果,左邊值為積極情緒結果,右邊值為消極情緒結果,可以發現MMFM與許多基線方法相比具有更優的結果。具體來說,本文模型在 CMU-MOSEI上的Acc-7、Acc2、F1得分都優于其他模型。對于其他指標,MMFM的性能也非常好。這些結果初步證明了本文的方法在多模態情感分析任務中的有效性。
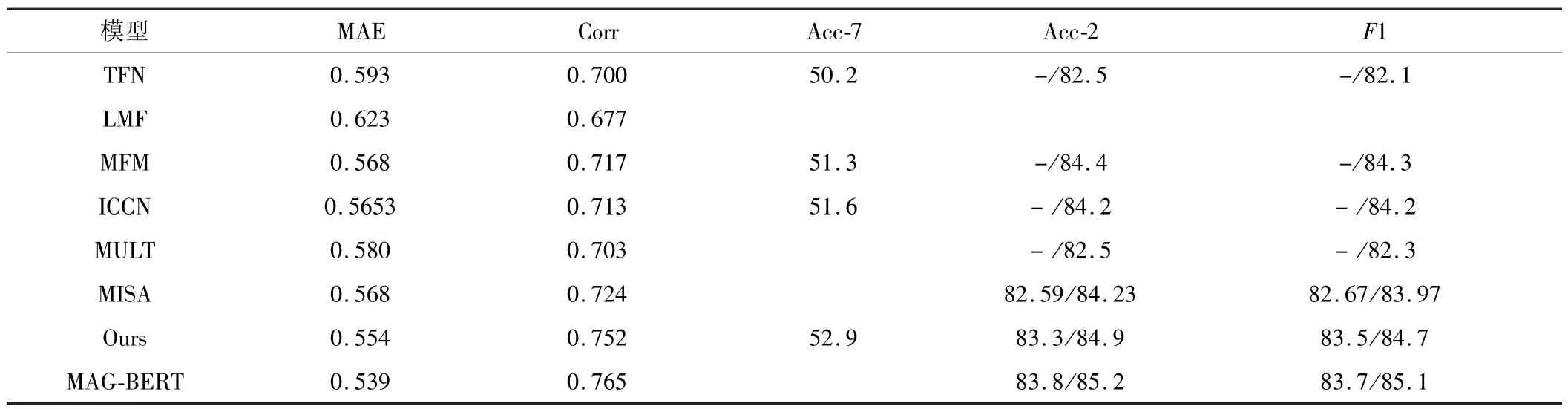
表1 CMU-MOSEI數據集上的運行結果
2.5 消融研究
為體現模型中提出的損失函數和相應估計方法的優勢,本文在CMU-MOSEI上進行了一系列消融實驗,表2為不同消融設置下的結果。首先,消除了一個或幾個MI損失項,包括模態間的MI下限(IB)和CPC損失。從表2中可以注意到去除部分MI損失后明顯的性能下降,它顯示了多模態融合最大化模型的效果。此外,通過將多模態MI中的當前優化目標對替換為單個對或其他對組合,無法獲得更好的結果,也驗證設計的合理性。然后測試熵估計,當停用歷史記憶并僅使用當前批次評估中的μ和∑時,出現“NaN”值,表示訓練過程崩潰。因此,基于歷史的估計具有保證訓練穩定性的優點。最后,將GMM替換為統一的高斯分布,其中μ和∑在所有樣本上進行估計,不管它們的極性類別如何,結果發現所有指標都有明顯下降,這意味著基于自然分類的GMM可以更準確地估計熵項。

表2 模型消融研究結果
3 結論
從模型在數據集上的表現來看,本文提出的多模態最大化融合框架在針對多模態情感識別的問題上取得一定的效果。且進一步的消融研究結果驗證了模型的有效性。在未來,將多模態應用于情感分析會有較好的發展潛力以及較高的應用價值,相信這項工作可以更多激發多模態情感分析的創造力。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
小學教學參考(2015年20期)2016-01-15 08:44:38
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
