深度學習的目標檢測算法綜述
2022-12-21 10:04:08柴立臣馮中營
信息記錄材料 2022年10期
寧 健,馬 淼,柴立臣,馮中營
(太原工業學院理學系 山西 太原 030008)
0 引言
深度學習是對人工神經網絡進行改進形成的,為一種常用的人工智能技術,其中含多個隱藏層。這種技術主要是對低層特征進行一定模式的組合而形成高層次的特征,為數據分析提供支持[1]。在這場深度學習中,這種神經網絡有很高應用價值,目前人工智能中有著非常重要的地位。
目標檢測,主要是根據目標的相關特征對圖像進行分割,從而實現目標識別目的。基于深度學習的目標檢測算法在步驟上包括雙階段(two-stage)和單階段(onestage)兩種目標檢測框架。前一種框架在處理過程中先確定出樣本的候選框,接著對樣本通過CNN網絡分類;后一種框架在處理時不產生候選框,直接在一定回歸分析基礎上實現目標檢測。對比分析可知這兩種方法的特性明顯不同,前者所得結果更準確,不過實時性差,后者速度上占優。各經典算法及主流特征提取網絡出現的時間[2],如圖1所示。

圖1 各經典算法及主流特征提取網絡出現的時間
1 基于區域提取目標檢測框架
區域提取算法的核心框架是卷積神經網絡CNN,對這種網絡的研究可追溯至神經認知機,神經認知機的主要特征表現為具有深度結構,屬于一種研究相對深入的深度學習算法。根據相關資料可知這種網絡中,隱含層是S層和C層組合形成的,在運行過程中二者分別用于提取和接收圖像特征的功能。20世紀80年代 LECUN等[3]對這種模型進行改進和優化,建立起功能更強大的LeNet-5網絡,然后通過其識別手寫數字,結果發現其可以很好地滿足應用要求。LeNet-5的主要特征為引入了池化層來篩選輸入特征,這樣可以顯著提高網絡的性能。LeNet-5對CNN網絡發展起到很大促進作用,并決定了其基本結構,通過這種網絡進行圖像處理時,可獲得其平移不變特征。卷積神經網絡主要由兩部分組成,一部分是特征提取(卷積、激活函數、池化),另一部分是分類識別(全連接層),圖2便是手寫文字識別卷積神經網絡結構圖。

圖2 手寫文字識別卷積神經網絡結構圖
1.1 R-CNN
采用滑動窗口策略對圖片進行反復特征提取,雖然能夠盡量提取圖片信息,但是窮舉法導致識別結果多了很多其他信息,效率太低。GIRSHICK等[4]提出區域卷積神經網絡R-CNN(Region CNN),如圖3所示。R-CNN算法和改進前網絡相比取得了50%的性能提升,但其也有缺陷存在:基于傳統方法確定出候選區,這樣降低了其處理實時性;卷積神經網絡需要分別對各候選區來特征提取處理,實際存在大量的重復運算,也顯著降低算法效率。

圖3 R-CNN目標檢測算法步驟
1.2 Fast R-CNN
GIRSHICK等[5]在研究過程中提出一種優化的Fast R-CNN模型,如圖4所示。Fast R-CNN和R-CNN相比,訓練時間從84 h減少到9.5 h,測試時間從47 s減少到0.32 s,并且在PASCAL平臺上測試的準確率提高到66%~67%之間。且在學習訓練過程中,綜合了分類損失和回歸損失,這樣可顯著改善學習效果。然后根據要求輸出相關分類和定位信息,對中間層信息不需要特定性的保存,有利于節約存儲資源。梯度可利用池化層來高效的傳播。Fast R-CNN使人意識到了候選區域+卷積神經網絡在提高檢測實時性方面的優勢,對比分析可知多類檢測可在改善處理實時性基礎上,也提高了處理準確性,不過其依然存在局限性,如處理過程中基于傳統方法生成候選區。

圖4 Fast R-CNN目標檢測步驟
1.3 Faster R-CNN
為了解決上述算法的問題,2015年微軟研究院的REN等[6]以及Ross團隊推出快速R-CNN,如圖5所示,在處理過程中簡單網絡目標識別速度為17 fps,在PASCAL VOC上準確率為59.9%,復雜網絡的為5 fps,準確率也達到78.8%。在這種模型中加入邊緣提取網絡,這樣使得生成候選區域,特征提取,分類以及定位相關的環節被納入到整體框架中,有利于提高模型的標準性水平。在對此網絡進行改進時,應用區域生成網絡(RPN)取代其中的搜索方法。設計輔助生成樣本的RPN網絡,算法在目標檢測時的流程為,先由RPN對候選框進行判斷,確定出其是否為目標,接著判斷目標的類型。在各環節都可以共享提取的特征信息,因而有利于提高處理效率,同時占據的空間減小,可以更快地生成候選框,而算法的精度并不受到影響。不過進一步分析可知RPN網在處理時可獲得多尺寸的候選框,這樣在處理時感受野和目標尺寸會產生不匹配問題,在目標平移變化情況下無法實現檢測目的。

圖5 Faster R-CNN目標檢測算法步驟(左)和RPN基本結構(右)
1.4 Mask R-CNN
為了處理two stage算法應用中存在的問題,HE等[7]對上述問題進行分析,建立了Mask R-CNN模型,取得了很好地識別效果。處理時面臨的任務為3個,包括分類+回歸+分割,如圖6所示。基于全卷積網絡預測候選框的掩膜,可使得目標空間結構相關的信息都很好的保留,實現目標像素級分割定位。

圖6 Mask R-CNN目標檢測算法步驟
1.5 其他Two-Stage檢測算法
2017年卡內基梅隆大學提出A-Fast-RCNN算法[8],其引入了對抗學習策略,據此獲得一個遮擋和變形樣本對網絡進行訓練,從而更好地對遮擋和變形情況下的目標進行識別。2017年12月,Face++提出一種大mini-batch的目標檢測算法MegDet,可以高效地利用多塊GPU聯合訓練,大大縮短訓練時間,同時解決了批標準化統計不準確的問題,達到更高的準確率。2017年12月Face++提出檢測算法LI等[9],應用了大內核而獲得符合要求的特征圖,可使得ROI子網絡處理過程中占用的資源顯著減少,平衡物體檢測中的精確度和速度。R-CNN相關的兩階段算法由于RPN結構的存在,雖然檢測精度不斷提高,但是其速度卻遇到瓶頸,比較難于滿足特定條件下的實時性需求。
2 基于回歸的目標檢測框架
為了進一步提高目標檢測的實時性,出現了YOLO(you only look once)和SSD(single shot multibox detector)等基于回歸的目標檢測框架,這樣不僅可以確保算法的可靠性,還能最大程度上提高其運算速度。
2.1 YOLO
2015年美國計算機研究者REDMON等[10]建立YOLO算法,通過這種算法進行處理時,對應的流程情況如圖7,其在預測過程中主要運用到圖形全局信息,因而相應的處理過程顯著簡化。將輸入圖像尺寸進行還原,設置了7×7網格單元。通過CNN提取的特征進行學習訓練,輸出結果為目標的類別信息。然而該方法也存在一定的局限性,具體體現在定位不準、召回率不甚理想,尤其是在近距離的物體檢測中不十分適用,從總體來看此方法的泛化能力相對弱。
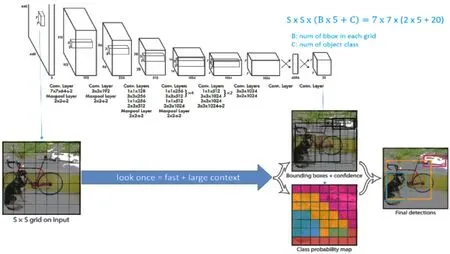
圖7 YOLO流程
2.2 YOLOv2和YOLO9000
基于YOLO有2個改進版,YOLOv2和YOLO9000,它們有效彌補了以往方法的不足,可以減小召回率和定位誤差。前者(如圖8所示)主要是運用了Faster R-CNN的思想,在具體應用過程中采用錨框機制,同時還使用了典型的K-Means聚類方式獲得更為理想的錨框模板。這種算法的特殊性還體現在通過增加候選框的預測,引入更為科學的定位方法,從而有效彌補了以往算法召回率低的問題,現階段這種方法已經在實踐中得到大量應用。YOLO9000是基于YOLOv2形成的一種算法,該算法的最大優勢體現在能夠檢測超過9 000個類別的模型,其主要貢獻點在于提出了一種分類和檢測的聯合訓練策略。

圖8 YOLOv2訓練過程及流程
2.3 YOLOv4
YOLOv4(如圖9所示)算法是也是基于YOLO形成的一種新方法,相對來說,前者更具先進性。其采用了近些年卷積神經網絡領域中最優秀的優化策略,因此在很多場合中都非常適用,比如在數據處理、主干網絡等場合中均有不同程度的優化。在YOLOv4中,借鑒了跨階段局部網絡CSPNet(cross stage partial networks),對Darknet53做了一點改進。CSPNet解決了其他大型神經網絡框架梯度信息重復這一瓶頸,其采用特殊的方式將梯度完全集成到特征圖中,故而采用這種方法能夠有效減少模型的參數量和FLOPS數值。因此與其他的算法相比,其有更高可靠性,推理速度也非常理想;同時顯著減小了模型尺寸。

圖9 YOLOv4流程
2.4 SSD
LIU等[11]建立此算法,如圖10所示。SSD的主要特征表現為融合了以上兩種算法的回歸和錨盒機制,在各卷積層的特征圖上進行定位預測,輸出的為統一的boxes坐標,對對應的類別置信度主要是通過小卷積核進行預測分析。進行整體多尺度的邊框回歸分析,這樣可以提高算法的處理速度,而定位準確性不受到明顯影響。然而其利用多層次特征分類,因此在應用中也存在一定不足,比如對于小目標檢測困難。

圖10 SSD和YOLO網絡結構對比
2.5 其他One-Stage檢測算法
RetinaNet網絡架構采用FPN網絡的結構,其主要創新點在于提出了一個新的損失函數Focal Loss,主要用于解決正負樣本極不平衡這一不足。在網絡預測中,正負樣本比相差大,并且負樣本大多為簡單樣本,大量的簡單樣本損失累積會導致訓練緩慢,所以對預測錯誤的樣本添加權重,從而使簡單樣本損失降得更大,從而優化了訓練。
M2Det使用主干網絡加多級金字塔網絡MLFPN(multilevel feature pyramid network)來提取圖像特征,接著采用特定的方法預測密集的包圍框,通過NMS得到最后的檢測結果。
3 結論
深度學習目標檢測有多方面性能優勢和很廣闊的應用場景,同時也面臨著很多困難與挑戰。本文以具有代表性的目標檢測算法為主線,綜述了這種檢測技術的進展和思考。參考上下文特征的多特征融合,在此基礎上,結合RNN展開更為深入的探討。當前這種目標檢測算法雖然應用非常廣泛,然而同樣存在諸多局限性,如何減少復雜背景干擾以提高檢測的準確性,基于深度學習目標檢測技術的研究值得更深層次的研究。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
海峽科技與產業(2016年3期)2016-05-17 04:32:12
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
