社交媒體Web Archive的技術架構設計
2022-12-27 13:56:50陳超天
圖書館學刊 2022年11期
陳超天
(廣州圖書館,廣東 廣州 510632)
大數據概念提出人阿爾文·托夫勒(Alvin Toffler)早在1980年指出 “社會記憶永久存在”[1]。Web Archive(網絡信息資源存檔,簡稱WA)則是實踐意義上的社會記憶。對于社會記憶的管理與塑造是網絡意識形態工作的重中之重。傳統意義上的WA是指一種在 “原生性” 網絡信息資源的整個生命周期內對其進行有目的地評價、選擇、采集、描述、元數據表示、存儲、發布和維護等一系列工作,以確保其當前可用和未來價值增值的管理活動[2]。筆者所討論的社交媒體Web Archive則是僅對于社交媒體方面的內容進行這些管理活動。
社交媒體(SocialMedia)一般意義上是指建立在互聯網技術基礎上的互動社區[3]。其數據有著數據來源(用戶)龐雜[4]、非結構化[5]、數量大(占互聯網大數據的80%[6])、具有完善的研究框架(如SNA)等特征。
1 社交媒體的影響力
社交媒體對于世界的政治、經濟、文化都有著極強的影響力。在政治方面,David S.Morris在ACM上指出,Twitter等社交媒體平臺在特朗普當選美國總統的競選過程中發揮了關鍵作用[7]。在經濟方面,學者常通過針對社交媒體的情緒分析維護商業名譽[8]。在文化方面,清博大數據2018年12月19日微信公眾號影響力總榜[9]可知各類社群媒體篇均閱讀量大多已為10萬以上,榜首月總閱讀量已達到0.7億次,也即年總閱讀量約為8.4億次,遠遠超越了普通紙質資源和普通電子資源的文化影響力。此外,其還能作為歷史研究的研究基礎[10]。
基于社交媒體在各領域的巨大價值,國際社會早已建立了諸如美國國會圖書館Twitter檔案館項目[11]、英國國家圖書館的UKWA[12]等先驅WA項目。WA項目在國內外發展迅速,截至2018年4月,據維基百科不完全統計,國際上已有約80余個成功實施的WA項目。在國內相關領域,白美程等通過普賴斯邏輯曲線增長理論指出,國內WA項目領域整體已從引入期和發展期過渡到相對成熟的探索期[13]。因此,構建適應我國發展實際的可持續的社交媒體WA項目是必要的。
2 構建可持續的社交媒體WA項目
2.1 明確社交媒體的控制主體與執行主體
2.1.1 社交媒體的控制主體
2.1.2 社交媒體的執行主體
社交媒體的執行主體應以圖書館、檔案館為主,以民間機構及個人為輔。圖書館、檔案館是國外社交媒體WA項目的現行執行主體,但卻存在隱私權法律法規變更、成本愈加增大、品種單調、不能完全開放給公眾使用等問題。哪怕國際上最有代表性的社交媒體WA項目——美國國會圖書館Twitter存檔項目也不例外。在諸如美國加州第568號法案(著名的 “橡皮檫” 法案[15])、《通用數據保護條例》(General Data Protection Regulation,簡稱GDPR)[16]等保護用戶的 “被遺忘權” 的法律與條例被頒布后,社交媒體WA項目更是舉步維艱。《中華人民共和國網絡安全法》[17]頒布后,基于民間有著良好的珍貴文獻(包括紙質和電子文獻)保存習慣,民間機構與個人通過Pagefreezer,WebPreserver等統一化保存解決方案也能在合乎現有法律法規的前提下對于官方社交媒體WA項目提供補充。
2.2 社交媒體WA技術架構設計
2.2.1 存儲架構設計
存儲架構設計是目前所有WA項目建設時最先需要考慮的技術問題,其整體架構設計主要需要考慮如何規劃存儲空間、如何確定存儲數據的格式以及如何保證 “被遺忘權” 。
2.2.1.1 存儲空間規劃
存儲架構設計是目前所有WA項目建設時最先考慮到的技術問題。不妨將整體架構設計問題細化為幾個容易解決的問題——存儲哪些內容、所需存儲空間是否能夠承受、如何規劃存儲空間、存儲數據的格式如何以及如何保證 “被遺忘權” 。
以合法為前提,應盡可能存儲所有可開放獲取的原始社交媒體數據,而不是加工后的成品數據或需要額外授權的媒體數據(如付費、隱私等)。盡管IFLA在國際圖聯圖書館員和其他信息工作者道德規范中說明,圖書館員和其他信息工作者的目標是為用戶提供公平、快速、經濟和有效的信息訪問[18]。但實際情況是,國際上包含美國國會圖書館(Library of Congress,簡稱LOC)、中國國家圖書館、澳大利亞國家圖書館等WA項目執行主體在內的多家機構,都逐漸開始僅收集政治或社會性事件的社交媒體數據[19-20],而不再選擇全量保存原始數據或不再開放訪問。眾所周知,已經匯聚成專題的數據的潛在可挖掘價值遠不如原始數據大。是什么原因導致各大執行主體放棄收集全量數據呢?是成本。在能夠承受成本的前提下,理應盡可能多、盡可能全地存儲原始數據。這樣才能在未來希望研究新的主題時,更好地建立專題數據研究庫。那么,我們是否能夠存儲如此海量的數據呢?
如果需要盡可能多地存儲原始數據,所需的存儲空間筆者認為是完全能夠承受的。以2013年LOC TwitterWA項目白皮書[21]內的存儲方案為例,其存儲的方式分為三步:每收集1小時的數據上傳一次臨時服務器、檢查新生成的文件完整性并歸檔至數據磁帶、刪除臨時服務器內的文件。該項目2006年至2010年的1700億條全量源數據也不過66.2TB,而2022年7月Quantum Ultrium LTO 9數據磁帶的單價約1200元人民幣,每個可存儲45TB數據,也即存儲6份LOC Twitter項目的5年備份也不過1萬元人民幣而已。按照第六次全國縣級以上公共圖書館評估中省級(副省級)圖書館等級必備條件可知[22],1萬元僅為東部省級一級圖書館的年度最低撥款的16.7‰。如果僅是全量保存數據的,這是中國任意一個省級(含副省)館都完全能夠承受。但若全部數據都存放在數據磁帶,又會面臨和LOC一樣的問題——如何保證讀取速度。
計算機存儲介質的存取數據越快、可靠性越高,則價格一般也就越貴。目前業界高可用系統的存儲方案一般以訪問頻次將數據分為三類處理:熱數據、溫數據、冷數據。訪問頻次越高代表數據越 “熱” ,越要把昂貴的存儲介質分配給它。但是對于WA數據而言,大多是低價值密度數據,必然會存在海量的長時間內不會被訪問的數據。如果放在磁帶庫讀取過于慢、放在廠家的高可用存儲又太貴、放在圖書館自有的較廉價的存儲可能又不夠穩定。IPFS(Inter Planetary File System,星際文件系統)則在可靠性、讀寫速率、成本三者之間達成了平衡。IPFS是一種結合了區塊鏈、版本控制系統Git、BitTorrent、系統分布式哈希和自認證文件系統的分布式文件存儲協議。國內已有學者嘗試性地將IPFS運用于短視頻分享平臺的構建上,并取得了良好的理論數據結果[23]。綜上,將不同價格的存儲整合在一起(見表1),則可建立起一套以熱度區分的存儲空間規劃方案。
幾天過后,成績發下來了,其他成績還行,唯有英文不及格。媽媽若有所悟地說:“這也難怪,孔夫子不懂英文,下次我再去求求上帝保佑就好了”
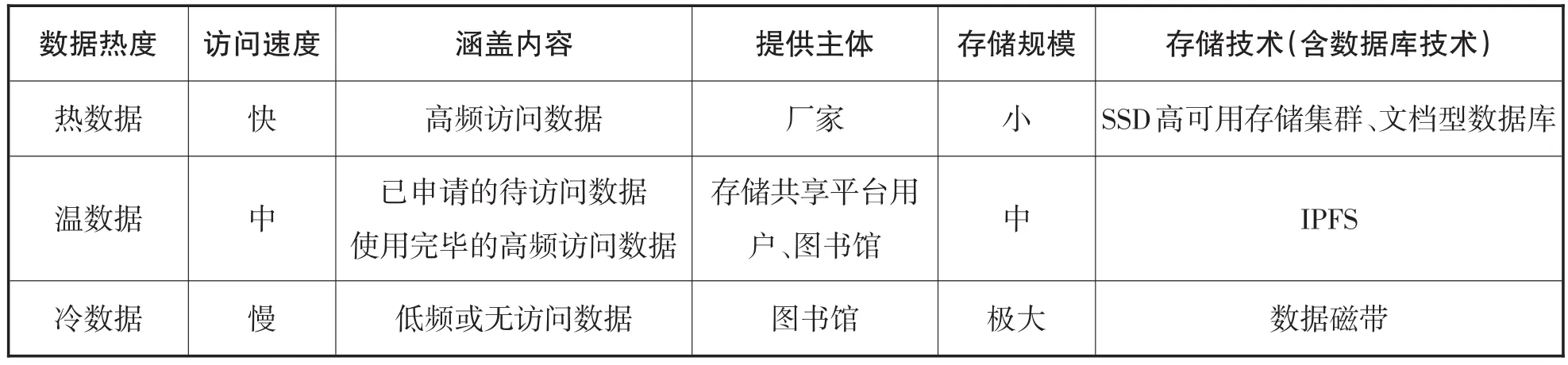
表1 以熱度區分的存儲空間規劃方案
2.2.1.2 確定存儲數據的格式
抖音、微博、知乎的社交媒體的數據一般由人員信息(發布人員、交互人員)、發布內容(含多媒體信息,如文本、視頻、地點等)、交互行為(如點贊、轉發等)共3個部分組成。不妨針對上述3個部分建立實體,以人員、內容、行為為基礎構建最基礎的通用元數據內容標準來進行儲存。因為原始數據較為完整,用戶需要使用時,可實時通過ETL框架抽取并建立特殊的專題格式或者其他類型的數據形式。當專題數據擁有商業或科研價值后,如果有用戶愿意支付存儲的成本,可再以該專題的特有格式建立數據更新機制,保證專題數據的穩定性。
2.2.1.3 “被遺忘權” 的保護
社交媒體WA項目中用戶 “被遺忘權” 的保護也是諸多法律學界、圖書情報學界學者[24]的關注重點。 “被遺忘權” 在我國的實現方式是通過用戶的舉證來刪除用戶曾公開的或被公開信息。盡管IFLA曾呼吁在歷史記錄中保存個人身份信息[25],但對于大規模的社交媒體WA項目,最好能對人員信息實體附加可舉證但不可破解的特征,如將用戶ID等內容通過摘要函數隱藏起來等。一方面,當WA項目用戶使用數據時無法將已經通過摘要函數隱藏的用戶信息還原成實際可讀的信息,保證了讀者的隱私權;另一方面,用戶能夠通過原有的ID信息舉證自身對于信息的擁有權,從而向項目方提出刪除申請,保證了讀者的 “被遺忘權” 。需要注意的是,中國關于 “被遺忘權” 的法律條文,沒有對刪除的時間進行要求。對于用戶提出的刪除請求,項目執行主體完全可以維護一條刪除消息隊列,根據技術架構特點和存儲數據的冷熱流動情況定期完成刪除操作。
綜上所述,筆者從幾個方面簡要描述了整體的存儲架構,但實際上仍存在部分問題沒有被提及,比如如何讓用戶加入基于IPFS的存儲共享平臺、整體存儲架構與圖書館無關、整體服務與系統的運營成本由誰承擔等。這些問題應該通過社交媒體WA項目的開放平臺架構設計來解決。
2.3 開放平臺架構設計
無論是出于商業、科研、政治安全還是其他的原因,所有的社交媒體WA項目的最終目的還是為了提供給用戶使用。在上述提到的存儲結構設計的基礎上,還需要有完整的數據層、業務層、前端展示層,才能完成從數據儲存到用戶的使用。
在數據層,需要實現存、轉、納、用4個功能。首先,存是指能夠被動接收或主動拉取社交媒體數據存入數據磁帶,保證所有的社交媒體數據至少有一個以上的數據磁帶備份。其次,轉是指當有數據被申請調用時,能夠支持冷數據(數據磁帶)向溫數據(IPFS)的轉換,也即將數據磁帶里的數據轉換到IPFS內可供快速讀寫的分布式數據。再次,納是指參加WA項目的所有圖書館或志愿參加的其他用戶能夠支持IPFS的存儲介質需要納入整體的IPFS體系中。最后,用是指能夠提供數據ETL功能的能力接口,可供用戶調用ETL接口生成知識圖譜、社交網絡分析等高級應用。此外,需要注意的是,負責統籌項目圖書館僅需要保存不可直接使用的極度廉價的數據磁盤內的全量源數據。當有科研任務到達時,需要支付代幣作為酬勞,而志愿加入IPFS的圖書館或其他機構或用戶提供存儲空間并獲得代幣。當志愿加入的個體不足時,數據層應該按照使用量從低到高的順序刪除IPFS體系內的數據。IPFS的特性是,覆蓋網絡越大整個存儲系統越穩定,需要用于 “激勵” 參與用戶的代幣(同樣任務情況下)越少。這樣就能保證在用戶增多的情況下,成本變少。
在數據層之上的業務層,需要有一套完整的類似于BOINC的分布式計算平臺,需要能夠基于數據層提供的接口和協議完成計算任務的分發,且實現用戶激勵機制。當用戶量和使用量增加時,所需要的技術支撐成本也將增加。隨著項目的使用群體越來越多,總會超出執行主體能夠承受的極限。因此,需要考慮建立一種可持續的存儲和開放平臺技術架構,能夠實現使用群體越多成本越低的目標。美國加州大學伯克利分校運營的伯克利開放式網絡計算平臺(Berkeley Open Infrastructure for Network Computing,簡稱BOINC)和IPFS是目前最為符合使用群體越多成本越低的開放平臺和存儲底層技術架構。BOINC采用的是具有分散通信、計算和存儲但又控制集中的分布式計算網絡。用戶自愿加入網絡后,可以將個人PC的算力共享給BOINC,而BOINC會將用戶做出的貢獻轉化為積分(或者可以稱為代幣)。在此過程中,算力任務在分布式計算引擎的規劃下,下發給各個節點進行運算,最終整合為項目所需的計算結果。IPFS也支持通過開發方式增加代幣激勵機制。隨著項目的使用群體越來越多,每個科研或商業項目的平均成本就會降低,而由于使用用戶負擔了項目的成本,作為執行主體的圖書館只需要支撐整個平臺的 “交易” 服務即可。
代幣機制的運營一般基于一個已存在的用戶群體,需要能夠有一套完整的代幣消耗閉環,而圖書館就是一個能夠提供用戶群體和閉環的完美執行主體。中國有969個擁有 “一級圖書館” 等級的公共圖書館和147所雙一流高校的高校圖書館[26],公共圖書館擁有龐大的用戶群體,而高校館擁有龐大的科研用戶群體。以高校項目資金為代幣購買方,以圖書館用戶群體為算力與存儲基礎,輔以圖書館的冷數據存儲和較高要求的高可用存儲集群,足以支撐起整體的技術框架運營。
故此,結合存儲結構設計部分的內容,可以建立一個整體架構(如圖1)。
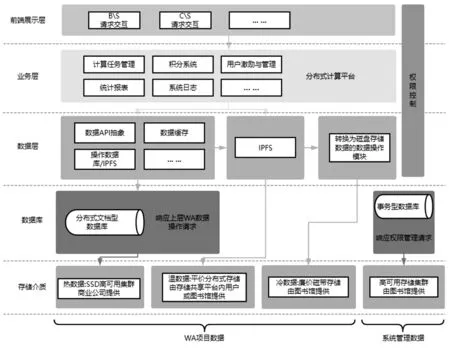
圖1 系統架構
3 未來展望
盡管類似于BOINC的分布式科研計算平臺已經在學術界非常著名,但是在國內圖書館界還少有人知曉。不僅如此,我國雖然擁有較大的圖書館用戶群體,但愿意志愿提供存儲與算力的用戶應不會太多。因此,在項目開展的前期,作為執行主體的圖書館不僅需要支出構建整個平臺的存儲和算力成本,還需要提供強有力的運營推廣支持。
猜你喜歡
文苑(2019年20期)2019-11-16 08:52:12
文苑(2018年17期)2018-11-09 01:29:40
小太陽畫報(2018年1期)2018-05-14 17:19:25
商用汽車(2016年11期)2016-12-19 01:20:16
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
