采用GPU加速的無人機光通信系統對準技術
2022-12-28 04:49:36徐聲振田明倪小龍于信白素平
長春理工大學學報(自然科學版) 2022年6期
關鍵詞:實驗
徐聲振,田明,倪小龍,于信,白素平
(長春理工大學 光電工程學院,長春 130022)
目前輕小型無人機平臺(重量不超過25公斤、飛行高度不超過150米)在社會民生中的實時監測和評估方面具備特別優勢,且具有廣闊的應用前景。而隨著航空遙感技術的發展,遙感數據的傳輸和存儲已成為亟待解決的嚴重問題,微波通信等傳統方法傳輸速率有限,針對這些問題[1-3],自由空間光通信是一種有效的解決方案。自由空間激光通信系統的關鍵技術之一就是實現高精度的動態跟蹤[4]。目前信標理論定位已經在國內外進行了深入的研究,例如神經網絡[5]、小波分析[6],但是計算和實時處理的性能不能滿足系統要求。此外,近年來美國、歐洲、日本等國家投入了大量的人力、物力對空間激光通信進行了研究,空間激光通信經過多年探索也取得了突破性進展[7],而我國空間激光通信研究起步較晚[8],且針對輕小型無人機的光通信技術研究較少,因此,開展輕小型無人機的光通信技術研究具有重要的研究意義。如何實現小體積、輕量化、低功耗的無線光通信終端,同樣也是輕小型無人機領域面臨的重要問題。
本文采用大疆六旋翼輕小型無人機作為光通信平臺,基于嵌入式平臺設計并制作小型無人機平臺光通信載荷。此外,本文在保證信標光斑亞像元細分定位精度條件下,采用圖像處理器(Graphic Processing Unit,GPU)并行計算來加速灰度質心算法以實現高速率捕獲、瞄準和跟蹤,最終實現高穩定性、低誤碼率的無線光通信。實驗證明經過GPU并行加速的光斑定位跟蹤方法相比傳統方法計算速度更快,設計的輕小型無人機光通信載荷具有體積小、重量輕、能耗低的優點。
1 光通信對準系統
圖1為光通信對準跟蹤系統的原理圖。它主要由地端激光發射系統、圖像采集系統、PID控制系統、無人機飛控系統以及嵌入式設備等組成。地端激光發射系統由激光器、三軸電機等構成。圖像采集系統由CMOS相機、75 mm變焦鏡頭等組成。PID控制系統由二軸控制云臺、嵌入式設備等構成。無人機飛控系統主要由主控器、GPS-Compass Pro、PMU和LED四個模塊構成。
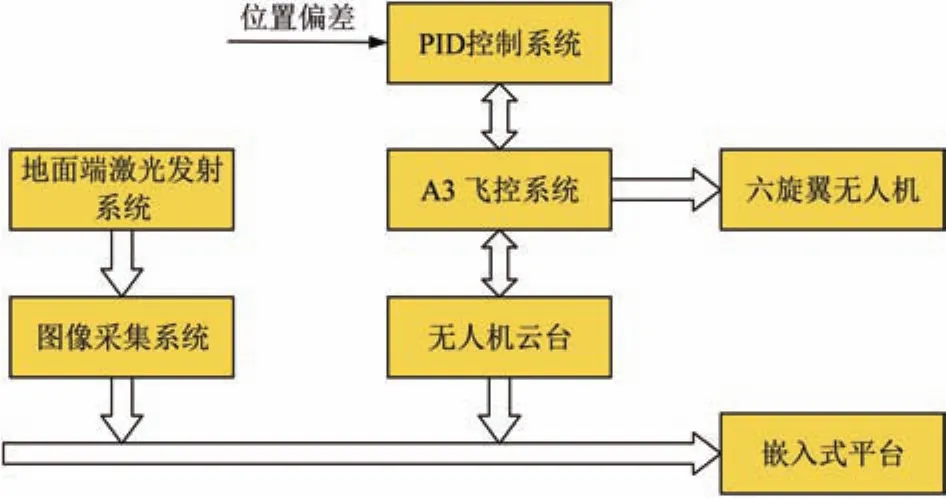
圖1 光通信對準系統原理圖
實驗中由地端激光發射系統的高功率固體激光器產生標準高斯分布的激光光束,并使其出現在工業相機拍攝的視場角范圍內;再在嵌入式設備上運行大疆Onboard SDK中編寫的主程序,通過圖像采集系統調用安裝在嵌入式平臺中的相機SDK驅動包內動態鏈接庫函數打開相機攝像頭;嵌入式設備讀取相機圖像數據并進行預處理,圖形處理器加速質心算法算出光斑質心從而得到位置偏差數據,最后采用PID三環控制云臺對準跟蹤光斑質心。
2 光通信對準系統關鍵算法
2.1 灰度質心算法
目前光斑的亞像素質心定位算法主要有:高斯曲面擬合算法,數字相關亞像素算法和灰度重心算法等[9]。灰度重心法也叫密度質心算法,對于亮度不均勻的目標,可按目標光強分布求出光強權重質心坐標作為跟蹤點。在計算機中圖像是以矩陣的形式呈現出來的,因此對圖像質心的計算實質上就是對各種矩陣進行計算。
設一幀灰度圖像中有i、j兩個方向,i、j方向像素點的數量分別為m、n,像素點(i,j)處的灰度值為f(i,j),則圖像質心位置坐標(x0,y0)的表達式為:
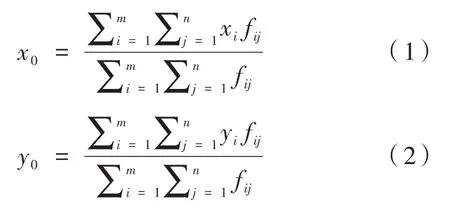
僅使用質心算法不能有效地提高光斑質心定位精度,需先用閾值去除噪聲的影響。設置閾值的意義是,將低于閾值的像素看作是噪聲,不參加質心計算,高于閾值的像素作為目標,減去閾值后參與質心運算[10]。
對于分辨率大小為m×n的灰度圖像,超過閾值T的像素的灰度值直接參與質心運算,小于閾值T的則不參與運算,相應的灰度值表示為:

本文使用這種帶有閾值檢測的質心跟蹤算法,且剔除背景噪聲的干擾,實現光斑圖像的高精度探測定位[11]。但是,采用傳統的中央處理器來計算這種質心算法運行時間較長,無法達到實時性要求。因此采取了圖形處理器并行優化質心算法以達到實時計算質心的目的。
2.2 圖像預處理
為了進一步提高算法的質心探測誤差,還需要采用自適應直方圖均衡化(Adaptive Histogram Equalization,AHE)和中值濾波(Median Filter)函數對圖像進行預處理。
直方圖均衡化是一種最常用的圖像增強方法,因為其簡單且在幾乎所有類型的圖像上性能都比較好,它是一種非線性的圖像拉伸。直方圖均衡化根據輸入灰度級的概率分布重新映射圖像的灰度級來執行操作[12]。通過使用一個累積分布函數(CDF)映射函數來實現均衡化的目的。對于直方圖H(i),它的累積分布H'(i)是:

均衡化后像素的強度值可以通過一個簡單的映射過程來獲得:
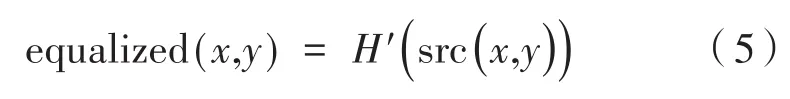
恢復后的累積分布直方圖對原始圖像的像素進行灰度映射,得到處理后的圖像。和普通的直方圖均衡化算法不同,AHE算法通過計算圖像的局部直方圖,然后重新分布亮度來改變圖像對比度,從而改進圖像的局部對比度[13]。
在圖像處理中,圖像去噪是一項必不可少的預處理任務,可提高圖像質量[14]。中值濾波法是一種非線性平滑技術,可用于處理AHE算法所帶來的椒鹽噪聲。
中值濾波的處理過程如圖2所示,實驗中選取3×3矩陣窗口作為濾波的卷積模板,即將矩陣中3行3列共9個像素值順序排列,取中值16替代原像素值3作為當前元素的像素值。

圖2 中值濾波示意圖
3 并行優化
3.1 算法并行優化
為了便于程序進行處理,將灰度質心算法公式分解為三部分依次進行計算,分別為公式(1)或公式(2)的分母A,公式(1)的分子B和公式(2)的分子C。
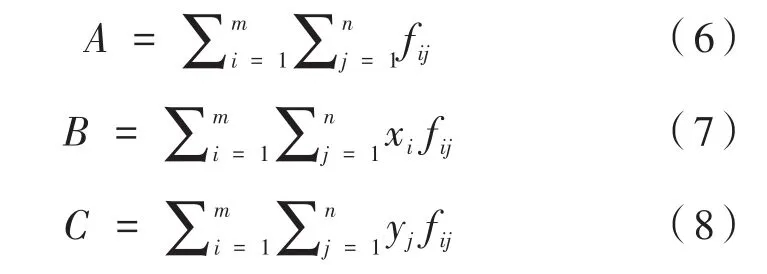
以公式(6)的計算過程為例,首先由Host端程序將圖像像素數據從中央處理器(CPU)中以一維數組的形式復制到圖形處理器(GPU)的全局存儲器(Global Memory)中,再進一步分配到GPU中每個block的共享內存中供Device端程序進行并行計算。計算之前先判斷圖像灰度值是否大于閾值,大于則灰度值不變,否則將灰度值設為0。然后將保存在一維數組里的像素值分割成大小相等的n個數據塊,GPU中每個thread只需要對某一小塊數據進行簡單的求和計算,計算完成后再利用歸約算法將每個block中所有thread的計算結果歸約成一個結果保存在block(0)中,完成后由 Host端程序將所有 block(0)結果從GPU顯存拷貝至主內存。最后CPU計算所有block之和,即可得到公式(6)的計算結果。公式(7)和公式(8)的計算只需要在每個線程對數據塊內的所有像素進行求和運算前乘以每個像素對應的行坐標或列坐標。
實驗中所有程序均由C++語言編寫,GPU加速部分程序采用了英偉公司提供的CUDA編程模型,并且編譯生成為便于主程序調用的靜態庫。整個過程采用跨平臺編譯器CMake編譯并生成可執行文件。由于從相機讀取得到的圖像格式是1 024×1 280分辨率的單通道8位灰度圖,所以一張圖片總共有1 310 720個像素點。GPU是以一維數組的形式讀取Mat類圖像的像素灰度值,也就是要對1 310 720個一維數組元素進行計算。在CUDA中,數據是從主內存復制到顯存的Global Memory,而數據的復制過程往往耗時較長,可以通過增加線程的數量來提高顯存的帶寬。Jetson Xavier NX中每個block的最大線程(thread)數是1 024個,如果采用單個block,則每個線程要計算1 280個數值。為了充分地利用GPU資源,計算調用了32個block,每個block均調用256個thread參與并行計算。這樣總共有8 192個thread同時對一維數組中的數值進行求和運算,大大提高了程序的并行效率。
通常顯卡的內存都是DRAM,因此對顯卡內存訪問最有效的途徑是連續訪問。當并行執行線程時,每個線程都運行在一個連續的全局顯卡內存塊上,但當一個線程正在等待數據時,GPU切換到另一個線程,另一個線程將從另一個位置的全局顯卡中轉移內存塊中的數據,如圖3所示。
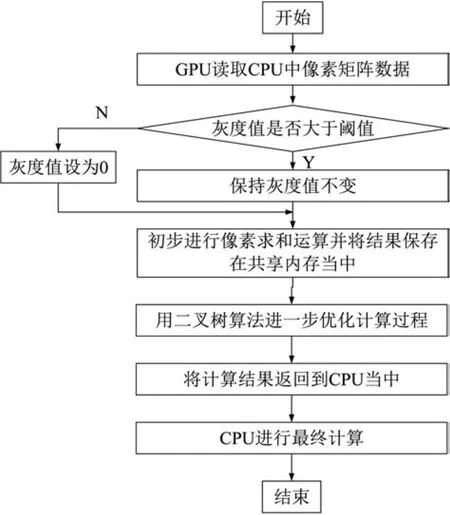
圖3 并行優化流程圖
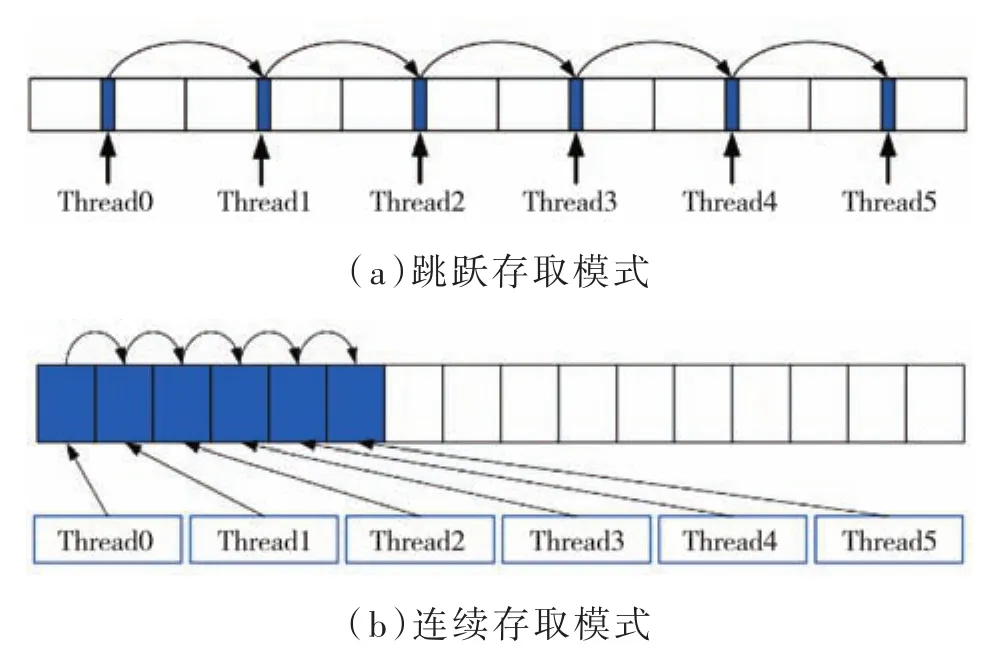
圖4 存取模式對比
綜上分析,雖然看起來每個線程對一塊連續的地址計算,但實際上執行時,當一個線程在等待內存的數據時,GPU會切換到下一個線程,因此,在同一個線程中連續存取內存,在實際執行時反而不是連續了[15],而是跳躍式的存取模式。因此,需要采用全局內存訪問合并技術,將顯存的存取模式改進為連續存取模式,提高線程數據訪問的效率。
3.2 二叉樹算法改進
上述程序是通過一個線程(Thread 0)實現了一個Block塊中所有像素點灰度值的累加。為了進一步提高程序的并行化程度,將每個Block塊中的加法都進行并行化。本文采用了二叉樹算法用于質心算法中的并行加法計算。
如圖5中Block(0,0)所示,每個block中的每個格子都代表了一個線程中的所有像素點灰度值之和,第一輪迭代開始時,設置步長offset為1,掩碼 mask為 1,則 Thread 0和 Thread 1相加,Thread 2和Thread 3相加,以此類推。當第二輪迭代開始時,設置步長為2,則Thread 0和Thread 2相加,Thread 4和Thread 6相加,以此類推。每迭代一輪步長和掩碼更新一次且所有線程需要進行一次同步,以此類推,直至迭代結束,每個block最終都通過線程Thread 0完成歸約并將結果保存在其共享內存shared[0]中。
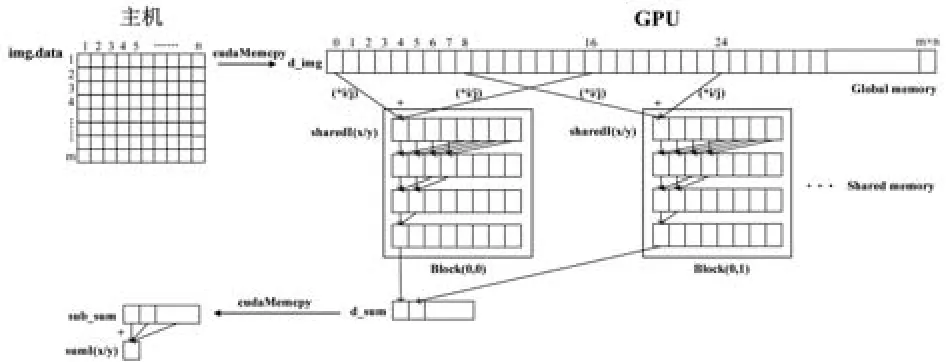
圖5 二分法并行歸約算法圖
除了改進顯存存取模式之外,還可以通過使用共享內存來改善全局內存合并訪問。如圖5所示,程序共申請了3組共享內存,分別用來保存每個線程在每一輪迭代過程中對這3條公式依次計算所產生的結果。程序總共啟用了32個block,而每條公式都有32個歸約結果,故總共有96個結果保存在各個block的共享內存當中,這96個數據傳輸到CPU中計算出每個公式的最終結果。
為了驗證并行優化后質心計算的加速效果,實驗采用了NVIDIA嵌入式設備Jetson Nano和Jetson Xavier NX對程序進行了測試。分別設置了兩組對照實驗,即采用傳統方法(CPU)計算圖像質心和采用并行優化方法計算質心。用這兩種方法分別在Nano和NX中對100張光斑圖像進行計算,光斑圖像為8位單通道灰度圖,分辨率1 024×1 280。程序的運行結果如圖6所示,在Nano上采用傳統質心計算方法的運行時間約37 ms,而并行優化算法后只需要約8 ms。而在NX上傳統方法運行時間約17.5 ms,并行優化后約3.4 ms,可見采用這種GPU-CPU異構體系結構可以大幅減少算法的運行時間。
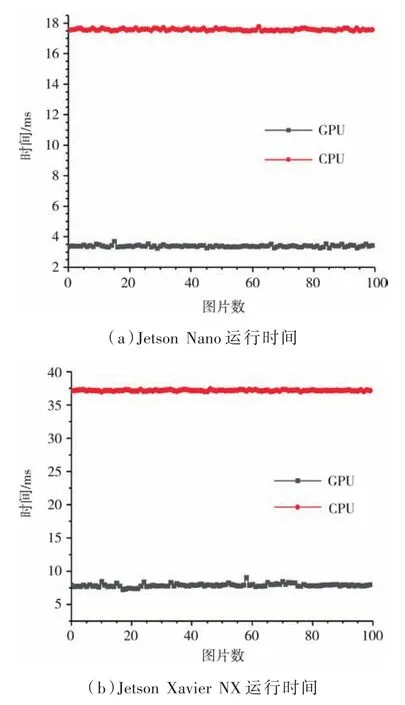
圖6 GPU和CPU運行時間對比
4 實驗與結果分析
為了測試采用GPU加速的無人機實時對準跟蹤技術的準確性和可行性,實驗采用搭載Jetson Xavier NX的Ronin-MX云臺在大疆經緯Matrice 600 Pro輕小型無人機平臺上進行了實驗驗證。圖7(a)為實驗中采用的無人機,自重9.6 kg,最大起飛重量為15.1 kg,滿載時可飛行18 min,要求掛載的激光通信設備總重量要保持在6 kg以內。設計的光通信載荷外形如圖7(b)所示,內部結構如圖7(c)所示,主要包括攝像機、姿態傳感器、嵌入式設備、焦距鏡頭、激光器等。圖7(d)為光通信地面端跟蹤實驗設備圖。

圖7 光通信跟蹤對準實驗設備圖
激光器選用夏普GH0631IA2GC激光二極管,生成的激光波長為638 nm,光斑形狀為圓形。相機型號選用MindVision CMOS類型常規面陣黑白工業相機MV-SUA134GM-T,有效像素130萬,圖像分辨率1 280×1 024,像元尺寸4.8μm ×4.8μm,相機接口為USB3.0且支持Linux驅動。所使用的實驗平臺為NVIDA公司的Jetson Xavier NX開發套件,搭載48個Tensor Cored的384核NVIDA Volta GPU,同時配備6核NVIDIA Carmel ARM 64位CPU及8 GB LPDDR內存。Jetson Xavier NX采用基于Ubuntu18.0.4的Linux環境,支持NVIDIA CUDA并行架構和各類SDK擴展包,同時輔以跨平臺編譯器Cmake。它體型小巧、性能卓越,非常適合搭載在無人機吊艙內部作為控制核心。
在程序對相機得到的灰度圖像進行質心計算之前,為了增強圖像對比度和平滑噪聲,需要調用OpenCV2中自適應直方圖均衡化函數和中值濾波函數進行圖像預處理。自適應直方圖均衡化函數的對比度參數為2,塊的大小為8×8;中值濾波函數內核大小(ksize)為 3,即取 3×3的矩形窗口。圖像預處理后的激光光斑圖像效果經過比例放大后如圖8所示。自適應直方圖均衡化處理后雖然圖像對比度增強了,但光斑邊緣模糊且背景中出現了很多椒鹽噪聲,而采用中值濾波函數對圖像噪聲進行平滑處理后,噪聲明顯變少且光斑邊緣形狀也更加清晰。

圖8 圖像預處理
實驗中通過讀取相鄰兩個采樣數據之間的時間差值即可知使用傳統方法(CPU)計算整個閉環控制系統后的單次運行時間,如圖9所示,運行時間約39.35 ms,而對算法并行優化后的系統單次運行時間約32.38 ms,速度可達每秒31幀;由于讀取相機圖像像素程序的運行時間約28.4 ms,控制程序運行時間約0.5 ms,可見采用GPU并行優化后的光斑質心跟蹤對準方法可以有效減少質心計算時間(時間減少了約7 ms),進而縮短閉環回路控制時間,提高控制系統的閉環帶寬。
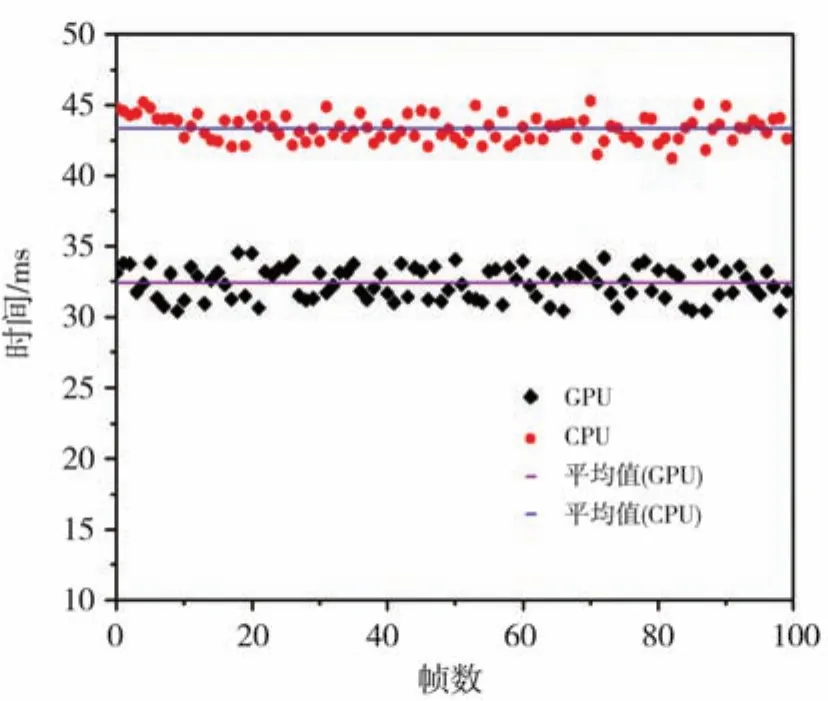
圖9 單幀圖像運行時間對比圖
圖10顯示了采用GPU加速質心算法后,在Jetson Xavier NX上測得的包括分配內存、傳輸數據及GPU與CPU計算的時間。像素矩陣數據從CPU復制到GPU的時間(包括分配內存)約0.7 ms,GPU中并行計算及CPU計算最終結果的時間約0.1 ms,GPU將計算結果返回到CPU的時間(包括釋放內存)約2.5 ms;采用并行優化算法后計算質心總共耗時約3.4 ms,可見采用GPU并行優化灰度質心算法后,如果能進一步優化數據傳輸過程,程序運行速度仍能有所提升。
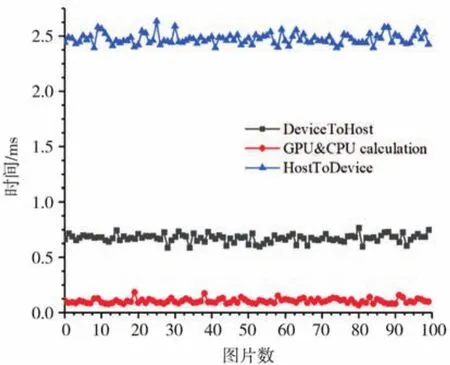
圖10 計算和數據傳輸時間
實驗通過PID控制算法控制Ronin MX云臺橫滾軸和仰俯軸電機運動的角速度,最終實現光斑質心與圖像中心點重合并保持穩定狀態。經過調試,最終的PID參數設置如下:比例增益值kp為113,積分增益值ki為0.5,微分增益值kd為11。將實驗測量得到的階躍響應離散數據用Matlab軟件繪制出來,經過擬合后得到的橫滾軸階躍響應曲線如圖11所示。仰俯軸PID控制參數同橫滾軸一致。圖11中橫坐標表示系統的采樣數(視頻幀數),由圖9可知每幀圖像用時約32.38 ms,縱坐標表示光斑質心在橫滾軸方向上的像素點位置相對值。分析實驗數據可知,采用PID控制算法后,系統的上升時間tr為0.069 s,峰值時間td為0.109 s,調整時間ts為0.454 s,最大超調量為0.521,系統的震蕩次數為2次,系統的穩態誤差(脫靶量)穩定在0.1 mrad(about four pixel)以內。
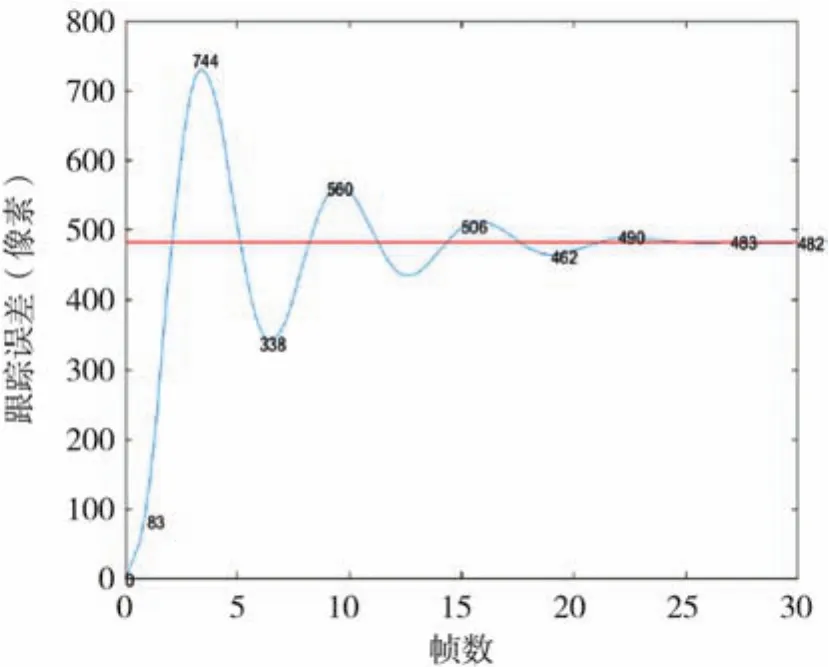
圖11 階躍響應曲線圖
5 結論
本文在研究了灰度質心算法定位光斑質心從而實現激光通信的理論基礎上,采用圖形處理器并行優化的方法對算法的計算過程進行了加速,經過加速的算法運行時長從原來的11 ms縮短至不到4 ms,加速效果顯著。并且,本文還設計了搭載Jetson Xavier NX的光通信載荷在大疆無人機上進行激光通信系統對準跟蹤的實驗驗證。實驗結果表明,采用圖形處理器加速的無人機光通信系統對準跟蹤技術具有快速性、準確性和穩定性,對準跟蹤光斑質心的脫靶量小于0.1 mrad,光斑質心跟蹤幀率可達到31 FPS,滿足了光通信系統的要求。
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
