基于層次匹配的維吾爾文關鍵詞圖像檢索
2022-12-30 07:51:38宋志平朱亞俐吾爾尼沙買買提徐學斌庫爾班吾布力
計算機工程與設計 2022年12期
宋志平,朱亞俐,吾爾尼沙·買買提,徐學斌,2,庫爾班·吾布力,2+
(1.新疆大學 信息科學與工程學院,新疆 烏魯木齊 830046;2.新疆大學 多語種信息技術重點實驗室,新疆 烏魯木齊 830046)
0 引 言
文檔圖像檢索方法分為基于光學字符識別[1](optical character recognition,OCR)的檢索和基于圖像特征的檢索,基于OCR的檢索方法高效快捷,但是檢索系統復雜,對手寫體文檔圖像及少數民族語言文檔圖像而言,目前無成熟的OCR系統,而基于關鍵字的檢索方法它能快速確定所需信息的準確位置,無需進行字符識別、系統結構簡單,能夠帶給用戶與OCR檢索幾乎相同的檢索體驗,是OCR系統的一種非常有效的互補方法。白淑霞等[2]將語言模型與詞袋模型(bag-of-visual-words,BoVW)的框架相結合,提出了一種基于LDA的主題模型,改進了蒙古文圖像關鍵詞檢索框架。魏宏喜等[3]建立了基于詞定位法的蒙古文圖像檢索系統,關鍵詞圖像通過文字輪廓、投影特征和筆畫的交集來表達,最后將視覺特征集成到BOVW模型[4]中并用于檢索任務。周文杰[5]采用形態學梯度算法對維吾爾文文檔圖像進行切割,使用切分后的單詞圖像LBP紋理特征實現檢索。李靜靜等[6]在粗匹配階段采取模板匹配,之后將HOG特征用于精細匹配,最后利用SVM分類器對關鍵詞進行精確檢索。
基于層次匹配的維吾爾文關鍵詞檢索方法,首先對預處理后的文檔圖像進行單詞切分,生成單詞數據庫,并使用分塊灰度共生矩陣算法對單詞圖像庫進行淺層檢索,過濾掉部分無關單詞圖像后形成候選單詞庫;其次利用預先訓練好的VGG16網絡特征提取器對淺層檢索回的候選單詞庫進行深層精確檢索,具體框架如圖1所示。
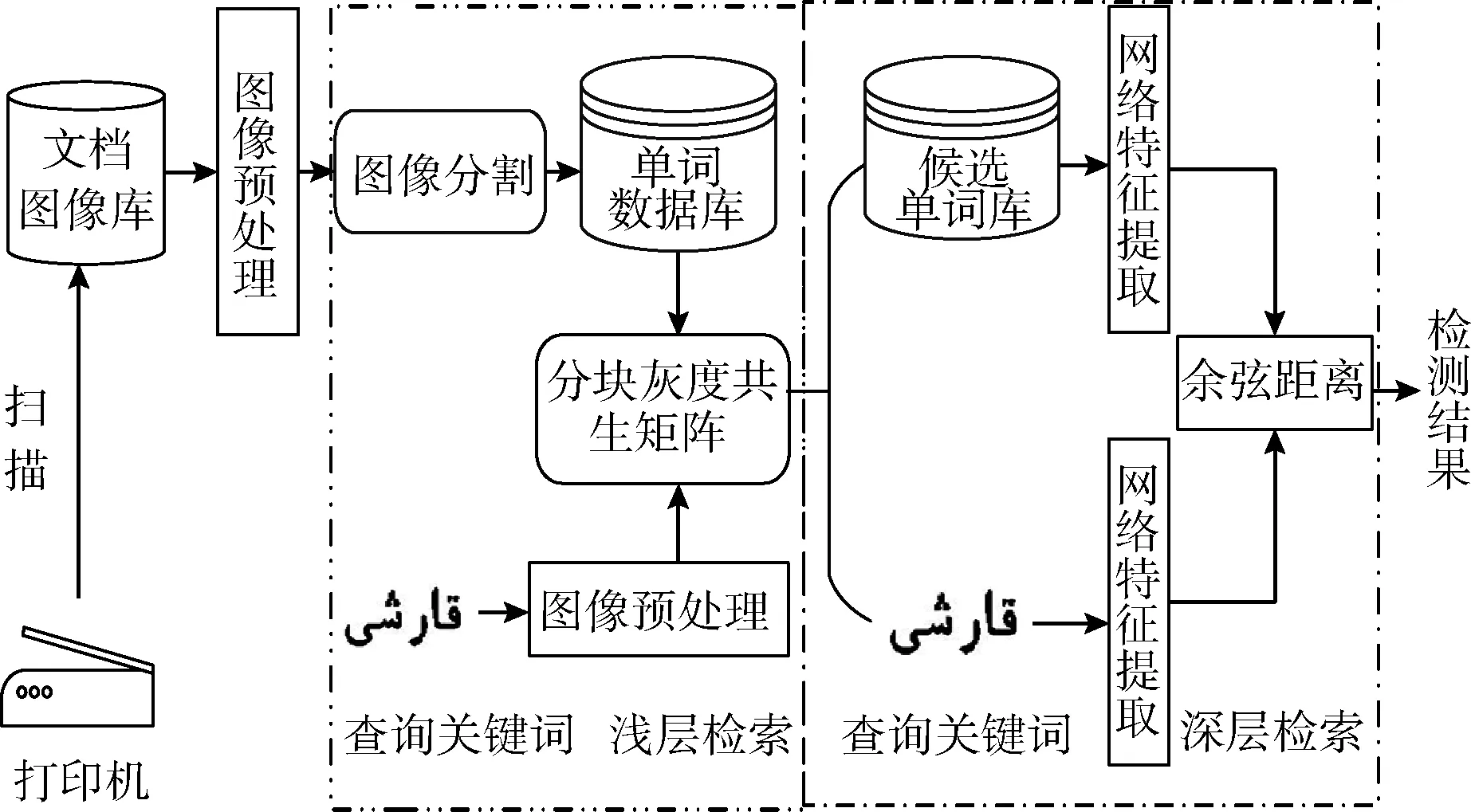
圖1 基于關鍵詞的文檔圖像檢索系統框架
1 基于維吾爾文單詞圖像檢索研究
1.1 圖像采集與預處理
由于在將紙質書文本掃描成電子文檔圖像的過程中,由于環境設備等因素的影響,阻礙了圖像有效信息的提取。因此本文通過圖像預處理方法來增強圖像質量,其中預處理操作包括灰度化(加權平均法)、噪聲去除(中值濾波)及傾斜校正(Hough)。預處理前后效果如圖2(a)、圖2(b)所示,經過預處理后的圖像筆跡較之前更清楚,內容結構更易于識別,這說明經過預處理后的圖像特征比灰度圖片更明顯。由于本文使用的數據集是純文本版面,因此采用徐學斌等[7]提出的基于聚類+連體段判別法完成對維吾爾文印刷體文檔圖像的單詞切分,效果如圖2(c)所示。

圖2 文檔圖像預處理
1.2 單詞圖像增廣
基于深度學習的探究需要大量的數據樣本來訓練網絡[8,9]。但多數情況下是沒辦法得到足夠的數據,因此數據增廣技術有利于深度學習模型的訓練,同時數據增廣技術可以從已有的數據中獲得新的樣本,從而有效改善模型的表達能力[10]。維吾爾文單詞圖像方面的樣本數據較少,除了字體字號的變化外,沒有其它的數據樣本,因此本文采取數據增廣的方法,來提升單詞圖像樣本的多樣性。
本文通過對115張純文本維吾爾文文檔圖像進行單詞切分,形成單詞圖像總數為24 460張單詞數據庫,其詞匯量為1233,選取了其中詞頻最高的200個類,之后分別從每個類中選取10張單詞圖像對其采用旋轉、剪切、遮擋、加噪、模糊等幾何圖像變換方法,將其擴充為原來的10倍,并用于網絡模型的訓練。之后在網絡訓練中采用概率p=0.5進行在線數據增廣方法,來增加訓練數據集樣本的多樣性,離線增廣部分效果如圖3所示。
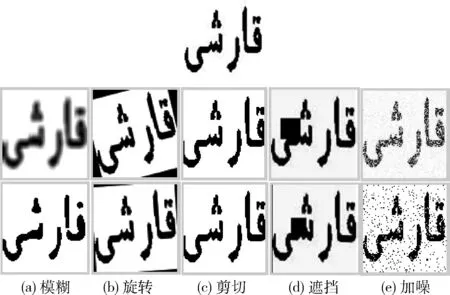
圖3 單詞圖像增廣
2 特征提取
2.1 灰度共生矩陣
灰度共生矩陣(gray level co-occurrence matrix,GLCM)[11]是一種具有方向選擇性的特征統計方法。通過灰度空間特征對圖像在方向、相鄰區間、變化幅度等信息進行描述。其一般表示量是:能量、熵、對比度、相關性、紋理方差等6個主要特征量,對圖像灰度空間變化信息進行描述。本文主要采用能量、熵、對比度和相關性4個最具有代表性的紋理參數作為本文的紋理特征,具體計算如下:
(1)對比度,又稱慣性矩,它能測量圖片中的矩陣分布和局部變化,反應圖中局部的紋理信息
(1)
(2)角二階矩,又稱能量,它能反映圖像灰度分布和紋理厚度
(2)
(3)熵,它表示了圖像的信息測度,圖像內容的隨機性和圖像紋理的復雜性
(3)
(4)相關性,也稱為同質性它被用于衡量灰度級在行或列方向上的相似性,因此該值反映了局部的灰度關聯值
(4)
其中,i為矩陣行數,j為矩陣的列數,P(i,j) 表示矩陣在i行j列處的值。μx,μy,σx,σy分別是Px和Py的均值和方差,Px是共生矩陣中每列元素之和,Py是共生矩陣每行元素之和。
2.2 改進的灰度共生矩陣
在圖像檢索中使用灰度共生矩陣特征參數時,通常選擇一個或多個特征參數來度量圖片的相似性。其次GLCM在進行紋理提取時,往往不考慮基元的形狀,不適合由大基元組成的紋理,會導致很多有價值的紋理信息被忽略。
為了突出圖像的中心位置,從而提高圖像檢索效率,本文在原有算法的基礎上改進了灰度共生矩陣算法[12]。首先將M×N大小的單詞圖像調整到N×N大小的圖像,然后再將圖像分成3×3共9個相同大小的子塊,之后計算每個子塊00、450、900、1350,4個方向的GLCM特征參數作為子塊的紋理特征,將提取到的各個子塊紋理特征進行串聯得到3×3×16=144維紋理特征代替原始的GLCM特征去表達圖像紋理信息,這樣能夠把較大的共生矩陣數組化為較小的共生矩陣數組,同時還可以避免出現過多的紋理特征被忽略的情況,能夠對圖像有效區域的紋理信息進行細致描述。
2.3 VGG16網絡
目前常用的深度網絡有AlexNet[13]、VGGNet[14]、GoogleNet[15]、ResNet[16];VGG16[17]網絡由13個卷積層5個池化層和3個全連接層構成,3×3卷積核取代5×5卷積核提取更細致的圖像特征,其模型參數較少而且結構簡單規整,并能更好進行特征提取;因此本文選取了VGG16作為特征提取網絡VGG16網絡結構如圖4所示。
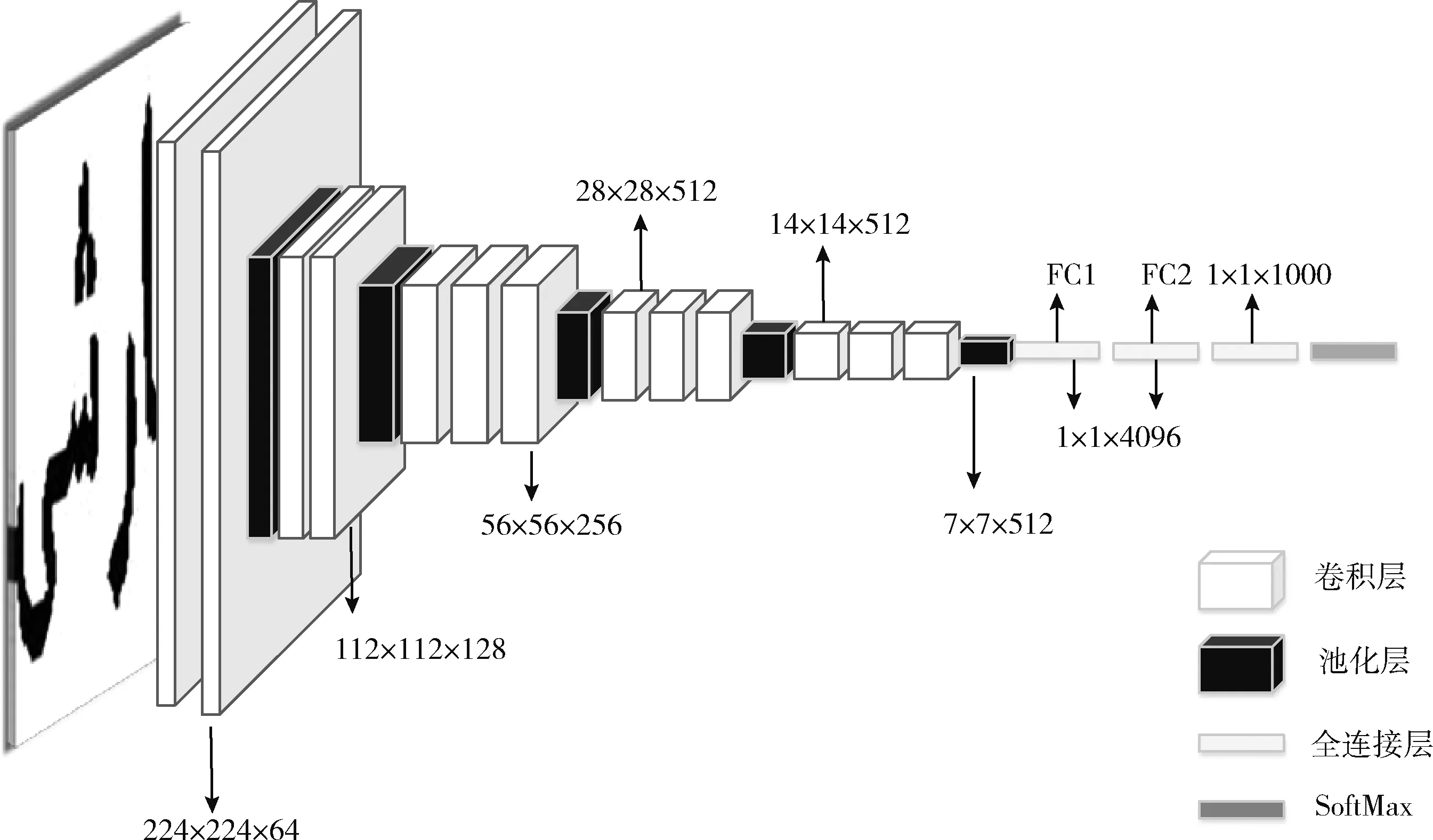
圖4 VGG16網絡結構
2.4 網絡遷移
遷移學習是指將模型通過源域學習的知識遷移運用到目標域中,即將以往的知識遷移到另一個新的領域中。劉詩琪[18]通過將深度學習與遷移學習結合提出tr-RCNN模型
結合RBM與CNN兩種模型有效解決了小樣本航拍圖像分類問題。劉嘉政[19]結合CNN和遷移學習用于花卉圖像識別,取得了很好的效果。由于維吾爾文單詞數據集屬于小樣本數據集,因此本文首先在源域Kannada語手寫體數據集上對VGG16網絡模型進行預訓練至參數收斂,之后將訓練參數作為目標域維吾爾文單詞數據集的初始化參數,并對網絡模型參數進行微調(Finetune)至充分擬合,最后將全連接層的輸出作為單詞圖像的特征表示,如圖5所示。
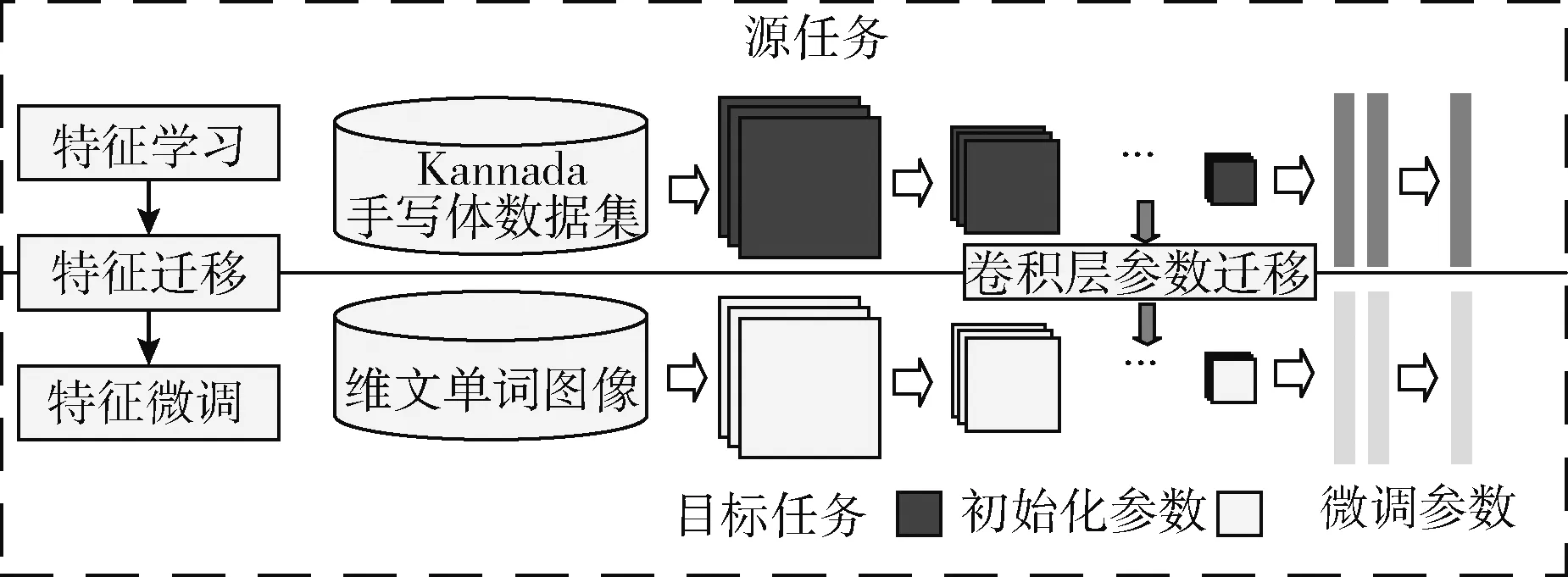
圖5 VGG16網絡微調
2.5 相似性度量
本文采用余弦相似性算法來對圖像檢索的結果進行評估。余弦距離也稱為平行傾斜率。它計算倆矢量間的空間余弦,以測定倆矢量間的大小差。它的應用范圍比較廣闊,能解決任意維度向量比較的問題。而對于圖像來說,圖像本身就是一個一個富含大量特征的載體,同時這些特征又有著很高很復雜的維度空間,和別的算法不同的是,余弦相似性算法[20]將數據映射為高維空間中的向量從方向上區分差異性,而不考慮空間位置等因素,圖6為余弦距離。
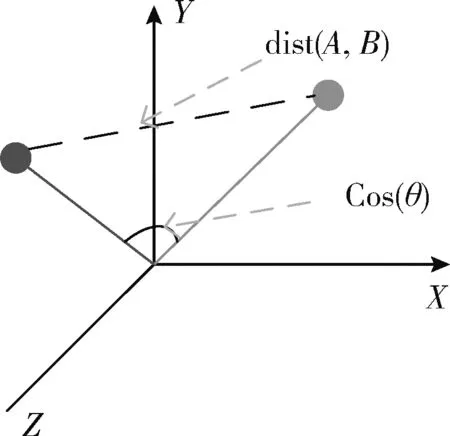
圖6 余弦距離
假設向量a1=[A11,A22,……,Ann] 和向量a2=[B11,B22,……,Bnn] 是兩個n維向量,那么向量a1與a2的夾角θ
的余弦計算公式為
(5)
3 實驗結果與分析
本文實驗在Windows10環境下展開,處理器型號為Intel Core I5-8300,運行內存8 GB,具體程序是在python3.7開發環境下編程調試,并借助OpenCV-3.4.2.16開發平臺實現。文檔圖像數據庫源于《馬列主義經典著作選編》維吾爾語版,為模擬不同的辦公環境,采用不同的打印機將紙質書籍掃成文檔圖像,建立了1000張文檔圖像,隨機選取了115張文檔圖像并切分成24 460張單詞圖像庫,并在其中選取10個具有豐富意義的關鍵詞圖像作為查詢關鍵詞圖像,并在數據庫中進行檢索實驗。檢索性能的評價指標有準確率(precision)、召回率(recall)、F值,指標計算公式如下:
TP(true positive):檢索為關鍵詞;實際也為關鍵詞;
FP(false positive):檢索為關鍵詞;實際是非關鍵詞;
TN(true negative):未被檢索到的關鍵詞;實際是非關鍵詞;
FN(false negative):未被檢索到的關鍵詞;實際是關鍵詞
precision=TP/(TP+FP)*100%
(6)
recall=TP/(TP+FN)*100%
(7)
F=precision*recall*2/(precision+recall)
(8)
3.1 基于灰度共生矩陣的淺層檢索實驗
本文首先在維吾爾文單詞數據集上,評估了灰度共生矩陣算法在維吾爾文文檔數據集上的性能。表1展示了原始灰度共生矩陣算法的檢索性能,其中準確率平均值為39.04%,召回率的平均值為48.29%,F值平均值為42.27%。第5個查詢關鍵詞的檢索準確率在這10個關鍵詞圖像中效果最好為55.81%。表示共檢索到43個單詞圖像其中目標關鍵詞包含24個。準確率最差的是第1個查詢關鍵詞,為25.39%,即共檢索回63個單詞圖像,其中正確單詞圖像為16個。而第9個單詞圖像召回率在這10個查詢詞中最好,為66.00%,表示共標注50個關鍵詞圖像,其中33個被召回。第3個查詢關鍵詞圖像召回率最低,為32.14%。即共標記56處關鍵詞圖像,其中召回18處。
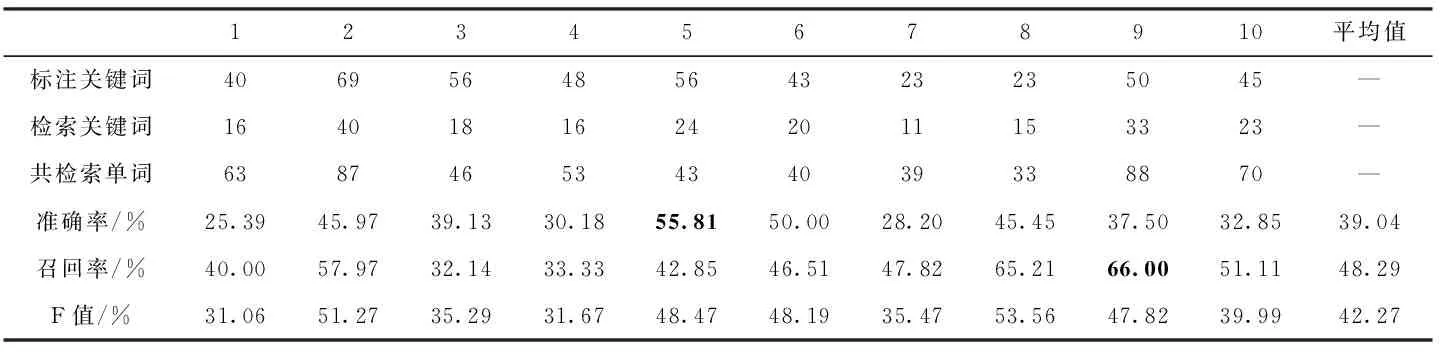
表1 基于灰度共生矩陣的關鍵詞圖像檢索實驗
表2中數據為分塊后的灰度共生矩陣算法的檢索結果,其檢索平均準確率為39.90%,而這些正確的關鍵詞圖像,占所標注關鍵詞圖像總個數的87.72%,F值平均值為52.49%。其中第5個關鍵詞準確率在這10個查詢關鍵詞中最高,為60.00%,即表示共檢索回70個單詞圖像,其中目標關鍵詞包含42個。相反也有準確率較差的關鍵詞,第6個關鍵詞準確率在這10個詞中最差,為12.82%,即共檢索到312個單詞圖像,其中目標關鍵詞圖像包含40個。召回率效果最好的是第2個關鍵詞,為100%,代表標注關鍵詞圖像全部召回,而召回率最差的是第5個關鍵詞,為75.00%,即標注56個目標關鍵詞圖像其中成功召回42個目標關鍵詞圖像。
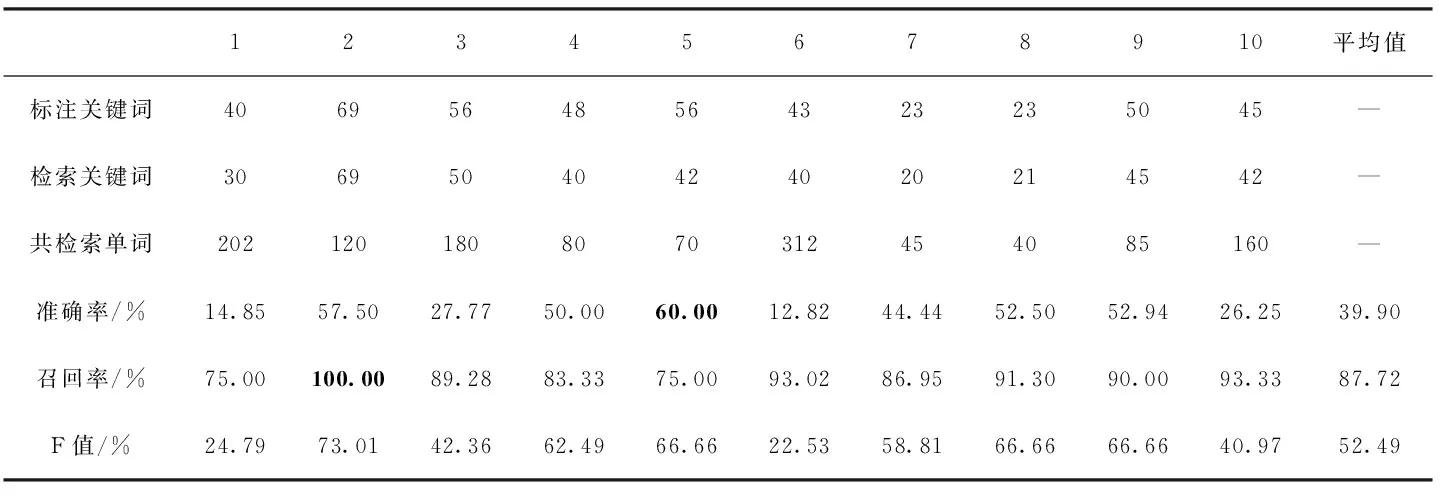
表2 基于改進的灰度共生矩陣淺層檢索結果
由表1和表2結果可以得出,采用分塊后的灰度共生矩陣算法相較于原始的灰度共生矩陣算法在準確率和召回率上都有大幅提升。但無論是改進前還是改進后的特征,其準確率都普遍偏低且其波動較大,召回率都偏高且波動較小。經分析得出灰度共生矩陣算法中僅簡單利用了圖像的像素紋理信息對單詞圖像進行快速篩選, 以保證盡可能多的目標關鍵詞被召回。然而并未提取到圖像更深層次特征去表征圖像間細微的差別,僅僅對數據庫中一些不相關的單詞圖像和切分錯誤的單詞圖像進行過濾,以保證盡可能多的召回目標單詞圖像。
3.2 基于VGG16網絡的深層檢索實驗
本節第一組實驗是在沒有淺層檢索的基礎上,只用VGG16卷積神經網絡特征在維吾爾文關鍵詞圖像數據庫進行檢索。其結果見表3:準確率平均值為70.29%,召回率平均值為57.98%,F值平均值為60.37%。第5個關鍵詞的準確率最好達到92.85%,即表示共檢索回28個單詞圖像其中26個檢索正確,而第10個關鍵詞準確率最低,為40.00%,表示共檢索回100個單詞圖像其中正確檢索回40個關鍵詞圖像;對于召回率而言第9、第10這2個關鍵詞效果最好均達到80%以上,即代表標注關鍵詞圖像大部分都被召回。
在這一部分,使用VGG16網絡特征進行關鍵詞檢索,準確率普遍較高,其原因是由于網絡根據大量的數據樣本可以學習到更深層的內在特征表示,對圖像內容的表達更準確,而其召回率普遍較低,經分析發現,雖然我們通過了數據增廣來增加圖像數據的多樣性,但只是對原有數據集進行改變,本質上對數據特征多樣性變化不夠,從而導致網絡模型不能很好學習到維吾爾文單詞特有的紋理輪廓等特征信息,難免會檢索回與目標查詢詞無關的圖片。由此可以看出單一特征的檢索效果都不盡如人意,無法從不同角度衡量圖像;但對不同特征進行融合可以很好的解決這一問題,因此本文在灰度共生矩陣淺層檢索的基礎上,采用VGG16網絡特征對淺層檢索回的候選單詞圖像庫進行二次精確檢索,實驗效果見表4。表4中的數據是在結合分塊灰度共生矩陣,與卷積神經網絡在維吾爾文關鍵詞圖像二次檢索的結果。其中準確率平均值為94.15%,召回率平均值為82.03%,F值平均值為86.80%。從表4結果中可以看出第5、第9、第10這3個查詢關鍵詞的準確率均達到100%,即表示檢索回的單詞圖像均為目標關鍵詞圖像;對于召回率而言,第2個關鍵詞召回率為100%,表示標注關鍵詞圖像全部召回;與表2淺層檢索結果相比其準確率平均值提升了54.25%,召回率方面降低5.69%,與表3結果相比平均準確率和召回率分別提高23.86%和24.05%。
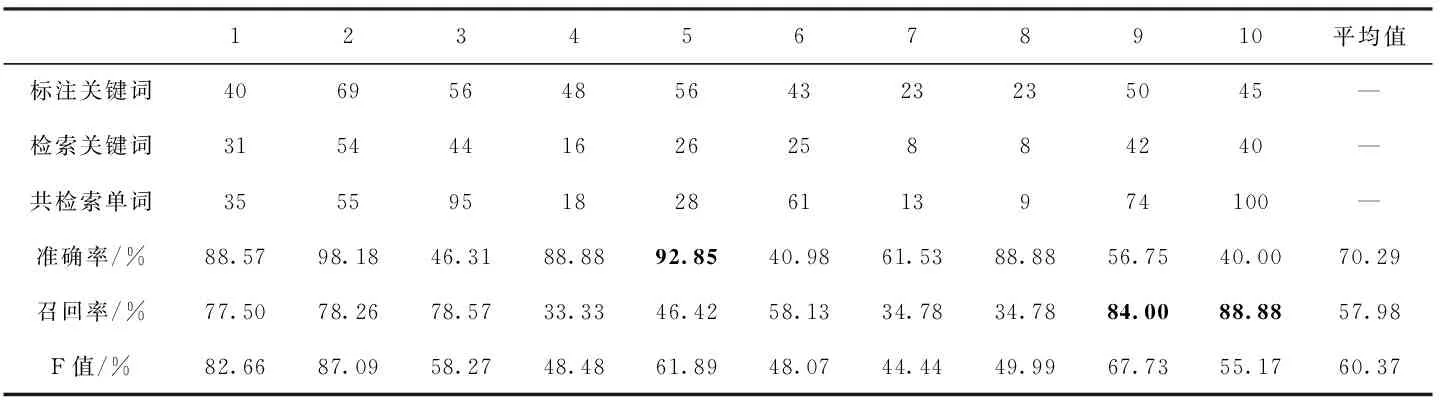
表3 基于VGG16的關鍵詞檢索結果
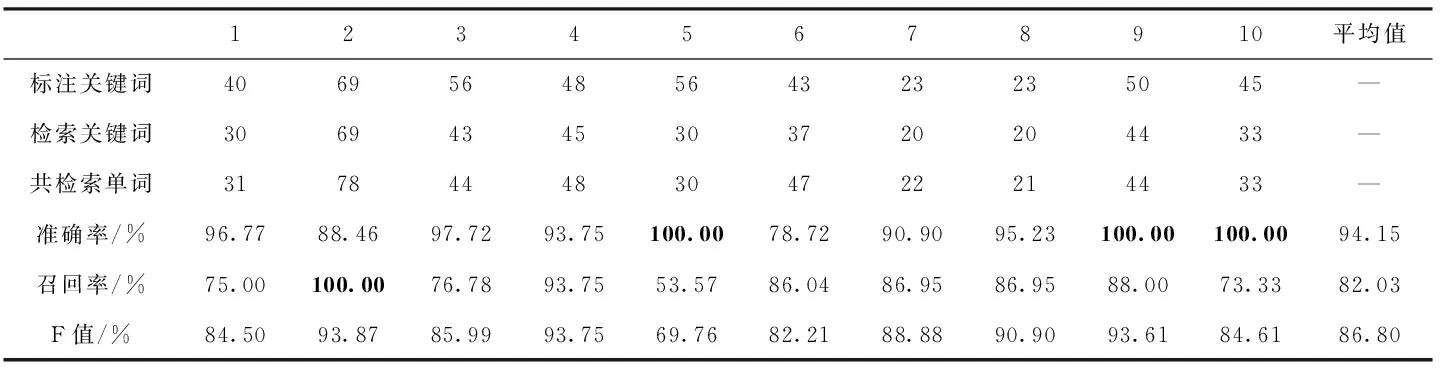
表4 基于分塊灰度共生矩陣+VGG16的關鍵詞深層檢索結果
從表4結果可以總結出,采用層次匹配的檢索方法將分塊灰度共生矩陣與卷積神經網絡特征進行分層次融合,在提取到圖像更深層次空間域特征的同時,兼顧到圖像底層紋理信息。與表2淺層檢索結果相比通過損失較小的召回率的情況下極大提高了檢索的準確率,其結果明顯優于表2和表3單一特征的檢索效果。顯然通過將圖像底層特征與高層空間域特征有效的結合可以更全面地表達關鍵詞圖像信息進一步提高了檢索性能;同時驗證了本文方法在維吾爾文文檔圖像檢索中的有效性。
3.3 與現有方法對比
為進一步驗證本文提出方法的性能,和已有的Hu+MBLBP+OSVM[5]和模板匹配+HOG+OSVM[6]維吾爾文關鍵詞檢索方法作比較,3種方法的準確率、召回率和F值等對比情況見表5。由表5可知本文方法檢索平均準確率為94.15%,平均召回率為82.03%。相較于Hu+MBLBP+OSVM關鍵詞檢索方法,本文方法在準確率上提升了7.45%,召回率提升了3.73%,而相較于模板匹配+HOG+OSVM關鍵詞檢索方法,本文方法在準確率上提高了2.41%,在召回率上提升了2.72%。可以看出相較于前兩種基于經典特征與SVM的檢索方法,本文方法在準確率、召回率上均有明顯提升。

表5 基于維吾爾文關鍵詞圖像檢索結果對比
4 結束語
本文針對傳統圖像特征在維吾爾文文檔圖像上檢索效果不理想等問題,提出結合灰度共生矩陣與卷積神經網絡的維吾爾文關鍵詞圖像層次檢索方法,通過將傳統手工特征與深層空間域特征進行分層次融合,在淺層檢索召回率略有損失的情況下極大提高關鍵詞圖像檢索的準確率,同時隨著對關鍵詞檢索研究的深入,基于關鍵詞的維吾爾文文檔圖像檢索已然成為一個極具挑戰的研究熱點,尤其是關鍵詞圖像特征選取的研究,因此下一步工作將更加深入分析維吾爾文單詞圖像特點,尋找新的特征進行融合進而提高系統檢索性能。
其次,本文的研究主要是建立在印刷體的維吾爾文純文本文檔圖像上,而現實中的文檔圖像還包含表格、圖片等信息,因此,需增加具有復雜布局的文檔圖像以及手寫體的文檔圖像,同時單詞切分方法也有待改進,實驗中的測試關鍵詞數目以及文檔圖像規模還會繼續擴大,降低偶然因素對檢索結果的影響。
猜你喜歡
閱讀(快樂英語中年級)(2024年9期)2024-10-23 00:00:00
時代英語·高三(2024年3期)2024-09-03 00:00:00
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
意林(繪英語)(2017年5期)2017-05-15 02:17:23
