基于BIFPN-GAN特征融合的圖像修復算法研究
2022-12-30 04:01:16陳明舉石浩德劉婷婷鄧元實
無線電工程 2022年12期
李 蘭,陳明舉*,石浩德,劉婷婷,鄧元實
(1.四川輕化工大學 人工智能四川省重點實驗室,四川 宜賓 643000;2.國網四川省電力公司電力科學研究院,四川 成都 610072)
0 引言
圖像修復利用已知信息實現對丟失信息的修補,在文物保護、影視制作、刑事案件的偵破和老照片的修復等領域發揮著重要的作用[1-2]。近年來,得益于深度學習強大的表征學習能力,深度神經網絡技術已成為圖像修復模技術的研究熱點。基于生成對抗的深度學習網絡(Generative Adversarial Network,GAN)[3]通過生成器與判別器的相互競爭,強迫生成器與判別器不斷改進,能夠同時利用圖片的淺層紋理信息與深層語義特征,獲得較好的圖像修復性能[4]。
Pathak等[5]首次提出了基于GAN的上下文編碼器(Context Encoder,CE)圖像修復方法,該方法采用結構與紋理編解碼器,結合重建損失,對低分辨率的圖像進行修復,得到了清晰的修復結果。為了進一步提高生成對抗網絡的修復性能,Yu等[6]將內容感知層的前饋生成網絡(Contextual Attention,CA)引入到生成對抗網絡中,從已知的圖像區域中匹配相似的補丁,來細化修復后的結果,從而得到更清晰的修復結果。文獻[7-8]分別通過將Partial Convolution與Gated Convolution來自動學習掩碼的分布,進一步提升了修復效果。Nazeri等[9]的Edge Connect(EC)采取2階段結構網絡分別實現結構邊緣與紋理信息的修復,以增強修復圖像內容的真實性。然而,由于生成對抗串聯耦合框架的不穩定性,從破損的圖像中得到合理的結構邊緣信息能力有限,圖像效果有限。為了有效實現圖像結構與紋理信息的修復,Liu等[10]采用紋理和結構的共享生成器,提出了一種混合了結構和紋理的Mutual Encoder-Decoder(MED)圖像修復網絡。Guo等[11]將圖像修復分成紋理合成和結構重建2個子任務,提出了一種新的用于圖像修復的雙流網絡——Conditional Texture and Structure Dual Generation(CTSDG),以進一步提升圖像修復的性能。
現有的圖像修復生成對抗網絡著重于紋理與結構信息實現圖像的修復,在信息重構過程中缺乏結構信息與紋理的交互,當待修復區域較大時,這些方法在語義信息上較容易產生歧義,會出現簡單的擴展和復制,生成的圖片細節不夠豐富,容易出現混亂和變形,產生主觀效果不理想的修復結果。鑒于此,本文在生成對抗網絡的基礎上,構建一種基于BIFPN多尺度特征融合的雙流圖像修復網絡,實現結構與紋理信息的相互交互。同時,為了增強修復圖像的全局一致性,設計了紋理和結構估計的馬爾可夫判別器與基于語義的聯合損失函數,并通過實驗證明其有效性。
1 基于雙流網絡結構的破損圖像修復網絡
本文采用的圖像修復方法被實現為一個生成對抗網絡,借助于雙流網絡[11]的思想,采用了2個編碼器和解碼器實現圖像紋理和結構信息的生成,構建一個多尺度特征融合網絡使生成的紋理和結構信息得到細化,有助于生成更合理的圖像。采用基于語義信息的損失函數,以實現修復圖像在視覺上真實、語義上合理。BIFPN-GAN圖像修復的結構如圖1所示。
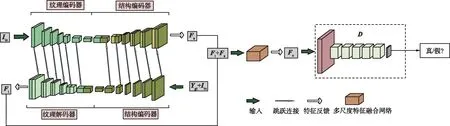
圖1 BIFPN-GAN圖像修復的結構Fig.1 Structure of BIFPN-GAN image inpainting
1.1 雙流結構的生成器網絡
本文的生成器以U-Net網絡為主干網絡,對圖像的結構與紋理信息分別進行編碼(下采樣)和解碼(上采樣),采用的雙流生成器結構細節如圖2所示。在編碼階段,將受損圖像及其結構圖像投影到隱變量空間,并通過跳躍連接[12]將多個尺度上的特征信息連接起來,通過低級和高級特征來生成更復雜的預測。其中,左分支關注紋理特征,右分支關注目標結構特征。在解碼階段,紋理解碼器通過從結構編碼器借用結構特征來合成結構約束下的紋理信息,而結構解碼器通過從紋理編碼器獲取紋理特征來恢復紋理引導下的結構信息。紋理編碼器的輸入通道數為2,包含破損圖和掩碼;結構編碼器的輸入通道數為3,包含破損邊緣檢測圖(由邊緣檢測算法[13]檢測)、破損灰度圖和掩碼。

圖2 雙流結構生成器結構細節Fig.2 Detailed structure of the dual-flow structure generator
1.2 基于BIFPN的多尺度特征融合網絡
為了增強修復圖像的結構和紋理的一致性,將輸出的結構和紋理特征進一步融合,如圖3所示,其中Ft為解碼器輸出的紋理特征,Fs為結構特征。為了實現在融合過程中結構與紋理信息之間的相互約束,減少重建損失、感知損失與風格損失,采用改進的BIFPN的多尺度特征融合網絡,使融合后的圖像更接近原始真實圖像。采用跳躍連接來防止融合過程中造成語義損壞,將一對卷積和反卷積無縫嵌入特征融合結構中以提高計算效率。通過對上下文的學習,使紋理和結構特征信息的感知與消息交互,增強圖像局部特征之間的相關性,并保持圖像整體的一致性。
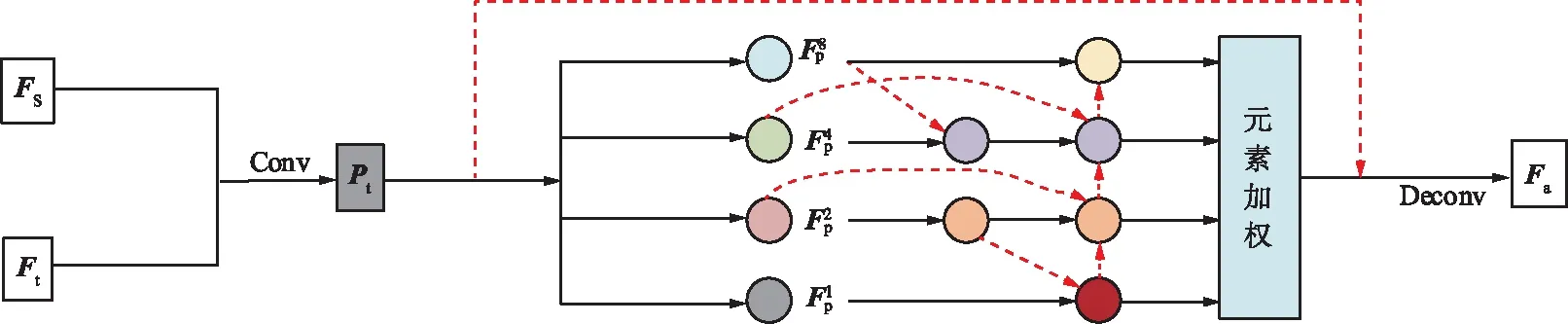
圖3 基于BIFPN的多尺度特征融合網絡Fig.3 Multi-scale feature fusion network based on BIFPN
處理的具體公式如下:
Pt=σ(g(C(Ft,Fs))),
(1)
式中,C(·)為通道連接;g(·)為由核大小為3的卷積層實現的映射函數;σ(·)是Sigmoid激活函數。通過Pt,可以自適應地把Ft和Fs合并,得到完整的特征映射圖Fp。一般地,特征圖可以表示為:
(2)
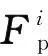
W=Softmax(GW(Fp)),
(3)
W1,W2,W4,W8=Slice(W),
(4)
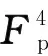
(5)
(6)
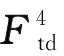
(7)
采用了深度可分離卷積[14-15]提高效率,并將批歸一化處理和激活函數ReLU添加到每次的卷積后面。
1.3 馬爾可夫判別器
受全局和局部判決的思想[16-17]的啟發,采用譜歸一化馬爾可夫判別器,通過估計紋理和結構的特征來區分真實圖像和生成圖像,在判別器上應用了譜歸一化[18],改善了生成對抗網絡訓練不穩定的問題。判別器由5層卷積層和1層全連接層構成,利用卷積-歸一化層-激活函數提取圖像高級特征,具體參數如表1所示。
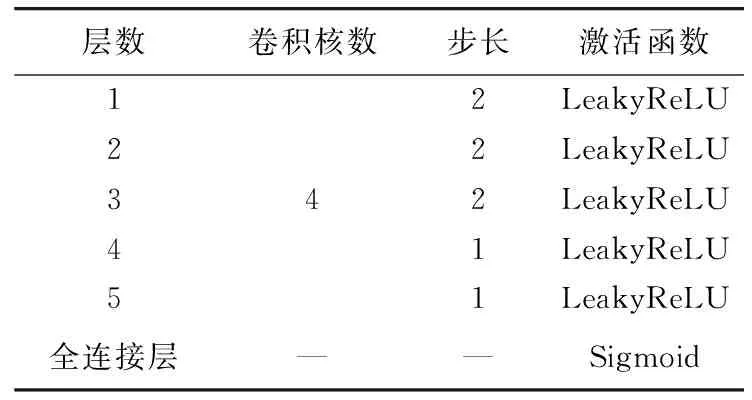
表1 判別器參數Tab.1 Discriminator parameters
1.4 基于語義的聯合損失函數
損失函數采用基于語義的聯合損失函數,包括特征內容損失、重建損失、感知損失、風格損失和對抗性損失,以獲得視覺上真實、語義上合理的修復網絡。
1.4.1 特征內容損失
邊緣圖像是單通道黑白圖像,因此,針對彩色圖像的損失函數并不適用。面對復雜的邊緣信息,需要特征匹配來控制生成器生成紋理細節與真實圖像相似度更高的結果。因此,設計了DenseNet[19]提取特征的特征內容損失,公式如下:
(8)
1.4.2 重建損失
將重建損失添加到改進的基于BIFPN多尺度特征融合網絡的目標函數中,有助于指導特征融合網絡朝著接近實際數據的可能配置進行。采用Iout和Igt之間的距離L1作為重建損失,公式如下:
Lrec=‖Iout-Igt‖1。
(9)
1.4.3 感知損失
由于重建損失難以捕捉高層語義,本文引入感知損失Lperc來評估圖像的全局結構。感知損失模型為ImageNet[20]上預訓練的VGG-16[21],Igt為原始圖像,Iout為生成器的輸出,L1為特征空間中Iout和Igt之間的距離:
(10)
式中,φi(·)為給定輸入圖像I*通過VGG-16第i層池化層得到的的激活映射。
1.4.4 風格損失
為了確保風格一致性,進一步設計了風格損失。風格損失計算特征圖之間的距離Lstyle:
(11)
式中,φi(·)=φi(·)Tφi(·),表示由激活映射φi構造的Gram矩陣。
對抗性損失是為了保證重建圖像的視覺真實性以及紋理和結構的一致性,其中D為判別器,將對抗損失引入馬爾可夫判別器中,為網絡增加了新的正則化,用于判別圖像的真假,定義如下:
EIout,Eoutlog[1-D(Iout,Eout)],
(12)
式中,Egt為原始圖像邊緣映射。
綜上所述,聯合損失函數如下:
Ljoint=λfmLfm+λrecLrec+λpercLperc+λstyleLstyle+λadvLadv,
(13)
式中,λfm=10;λrec=10;λperc=0.1;λstyle=250;λadv=0.1。
2 實驗結果與分析
2.1 實驗環境與評價指標
實驗所使用的硬件環境為Windows 10,NVIDIA TITAN XP 12 GB。軟件環境為Python3.6,pytorch。
本文將修復結果進行主客觀2方面分析。客觀評價方面,采用峰值信噪比(Peak Signal to Noise Ratio,PSNR)和結構相似性 (Structural Similarity Index,SSIM)作為評價指標。其中,PSNR用來評估2張圖像中對應的像素點之間的誤差,單位dB,數值越大表示失真越小;SSIM用來評估2張圖像在亮度、結構和對比度3個方面的整體相似性,其結果越接近1表明相似性越高[2]。
2.2 實驗數據集及預處理
本文采用了在研究中廣泛采用的CelebA和Places2數據集來評估本文的方法,并遵循它們最初的訓練。從文獻[22]中獲取不規則掩碼,首先使用2×10-4的學習率進行初始訓練,批大小處理為16,使用Adam優化器進行了優化,然后以5×10-5的學習率對模型進行微調,并且凍結生成器的BN層,判別器以生成器1/10的學習率進行訓練。
如何使學生自主學習,從而使實驗過程不再因為有限的課堂時間而流于形式,使學校有限的的實驗資源能夠得到充分利用,結合作者在材料實驗教學過程中所遇到的問題和實驗過程中學生的現狀,以及學校對實驗有效教學的重視程度,淺談微課在材料實驗教學中的幾點應用。
2.3 實驗結果與分析
為了驗證本文方法的圖像修復性能,將本文方法分別與EC,MED和CTSDG算法進行對比。帶有掩碼的CelebA和Places2數據集修復結果如圖4所示,前2行為約25%破損區域,第3行為約10%破損區域,第4行為約40%破損區域。

(a) 原圖

(b) 待修復圖

(c) EC

(d) MED

(e) CTSDG

(f) 本文圖4 不同算法修復結果對比Fig.4 Inpainting results of different algorithms
本文使用2種評價圖像的客觀定量評估標準PSNR和SSIM對修復結果圖像進行評估,從不同破損區域的修復結果中隨機選取超過100張修復結果圖像進行定量分析。不同算法的修復性能比較如表2所示。由表2可以看出,本文方法具有更高的圖像質量結果,并且本文方法比EC,MED,CTSDG算法所用的修復時長都要少,具有更高效的修復性能。
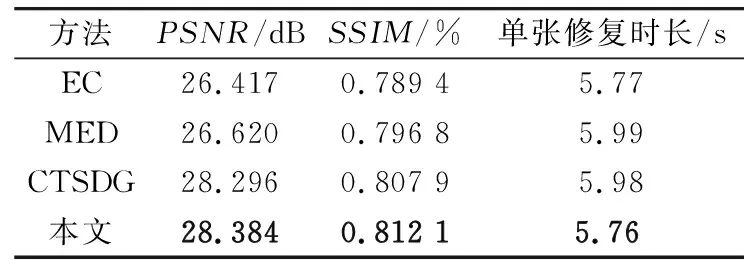
表2 不同算法的修復性能比較Tab.2 Inpainting performance comparison of different algorithms
圖像修復本質是一個病態的任務,對于未知的大區域破損圖像的修復區域結果往往是不確定的,與原圖一樣的修復也是非常具有挑戰性的,所以修復的目標一般是以人主觀視覺上是否可以判斷修復后的圖像是否為修復圖像為依據,即修復的目標為是否在圖像視覺上能保證其結構的連貫與自然。因此,進一步進行主觀評價,從圖4可以看出本文的方法具有更好的修復效果,如眼睛、房屋的房頂等,可以更清晰合理地得到人臉和風景的細節。圖5隨機展示了2張Places2數據集中修復的邊緣圖及其效果。

(a) 原圖

(b) 破損圖

(c) 破損邊緣圖

(d) 生成的邊緣圖

(e) 修復結果圖5 基于BIFPN圖像融合算法的圖像修復Fig.5 Image inpainting based on BIFPN image fusion algorithm
3 消融實驗
為了提高重建結構和紋理的一致性,設計了基于BIFPN的特征融合網絡,針對此部分設計消融實驗。將生成的紋理和結構特征進行簡單融合,所得到的修復結果作為基準來與所設計的基于BIFPN多尺度融合網絡進行對比。消融實驗結果對比如圖6所示。

(a) 破損圖

(b) 參考圖

(c) 簡單融合結果

(d) BIFPN結果圖6 消融實驗結果對比Fig.6 Results comparison of ablation experiment
由圖6可以看出,使用簡單的融合模塊(通道級聯后是卷積層)獲得的結果可以觀察到模糊的邊緣以及信息的缺失,特別是邊界附件,如門、窗口、床沿等。為了使比較更加具體,表3給出了定量分析結果,表明BIFPN多尺度融合有助于提高性能。
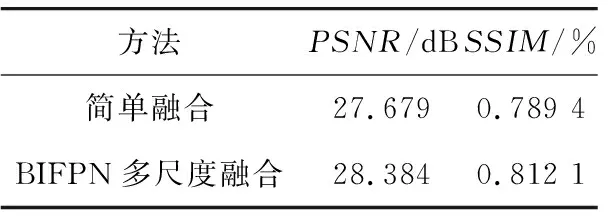
表3 消融實驗定量分析表Tab.3 Quantitative analysis table of ablation experiment
4 結束語
本文對數字圖像修復進行了研究,為了使圖像重建過程中其結構信息與紋理信息得到充分有效的利用,在改進的雙流網絡結構上構建了一種基于BIFPN多尺度圖像融合網絡的圖像修算法,實現了修復性能更好的圖像修復效果。為了增強修復圖像的全局一致性,設計了紋理和結構估計的馬爾可夫判別器與基于語義的聯合損失函數,并通過實驗證明其有效性。實驗結果顯示,在CelebA數據集和Places2數據集中,本文提出的算法修復的圖像不僅具有更高的客觀評價指標和更少的修復的時間,還可以達到較好的主觀視覺效果。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
哲學評論(2021年2期)2021-08-22 01:53:34
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中華詩詞(2019年7期)2019-11-25 01:43:04
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
