基于膠囊網絡的WiFi手勢識別方法
2022-12-30 04:14:10管同元卓豪輝吳茗蔚
無線電工程 2022年12期
關鍵詞:模型
張 夢,管同元,卓豪輝,吳茗蔚
(浙江科技學院 信息與電子工程學院,浙江 杭州 310023)
0 引言
非接觸手勢識別具有巨大的應用市場,采用攝像頭[1-2]、雷達[3-4]以及傳感器[5-6]等方式雖然取得了一定成效,但仍存在光照敏感、設備昂貴以及操作不便等弊端。與之相比,基于WiFi信道狀態信息(Channel State Information,CSI)的手勢識別具有成本低、擴展性強和不受光照條件影響等優點。近年隨著深度學習的發展,許多基于深度學習的WiFi手勢識別方法被提出。CrossSense[7]通過漫游網絡實現了跨場景的手勢識別;EI[8]使用對抗網絡實現了6種動作的識別;劉佳慧等[9]使用長短期記憶網絡(Long-Short Term Memory,LSTM)實現了對4種手勢的識別。上述深度學習方法通過直接建立CSI數據與動作間的映射取得了良好成效。但直接建立原始信號與手勢映射的模式,限制了對信號動力學的理解。對此,Widar3.0[10]提出身體速度譜(Body-coordinate Velocity Profile,BVP)這一概念并結合CNN-GRU深度學習模型,在手勢識別問題上取得了良好成效。王熾等[11]在BVP基礎上提出3D-CNN模型實現對6種手勢識別。理論上,深度學習模型訓練期間用到的標記數據越充分,所得到的模型效果越好。但數據的收集和標注需要耗費極大的人力和物力,由于難以收集到足夠多的數據,最終導致訓練出來的模型性能不佳。另一方面,手勢和不同個體間的差異會直接導致BVP數據在格式上出現差異。雖然可以通過重采樣進行標準化處理,但標準化后的BVP特征與CSI不再是直接映射關系,模糊了其對手勢的表達。
為解決上述2個問題,本文基于膠囊網絡(Capsule Network,CapNet)[12]結構簡單、不會因池化丟失信息的優點并結合門循環單元[13](Gated Recurrent Unit,GRU)提出了一種基于CapNet的遷移學習模型GRU-CapNet,將圖像識別領域中訓練好的模型遷移到WiFi手勢識別任務中,以提升手勢識別準確率。另外,還提出一種改進的BVP估計算法,通過動態計算CSI手勢數據的分割模式,直接得到格式統一的BVP特征數據,避免了重采樣導致映射關系不直接的問題。在公開數據集和家用小型轎車場景下分別進行了試驗,結果驗證了所提方法的有效性。
1 BVP估計算法及其改進
CSI是估計通信鏈路的信息,頻率為f的子載波的CSI可表示為[14]:
H(f)=‖H(f)‖ej∠H(f),
(1)
式中,H(f)為單個子載波的CSI;‖H(f)‖和∠H(f)表示CSI的幅度與相位。移動物體會導致信號產生多普勒頻移(Doppler Frequency Shift,DFS),同時信號傳播過程存在多徑效應。多徑效應下,頻率為f的子載波在t時刻的CSI可通過DFS來描述[15]:
(2)
式中,Hs為不包含DFS的靜態分量總和;Pd表示包含DFS的動態信號集合;αl表示復雜衰減;φ(f,t)為相位偏移。通過共軛相乘、減去均值以及功率調整操作,可以得到含有顯著DFS的分量[16]。隨后,通過短時傅里葉變換即可得到多普勒頻移分布(Doppler Frequency Shift Profile,DFSP)。
1.1 BVP估計算法
以人的朝向為x軸正方向,所在位置為原點建立坐標系。BVP通過式(3)計算[10]:
(3)
式中,M為各接收端與發射端建立的鏈接數;V為BVP數據;D(i)和c(i)為不同鏈接中的DFSP和傳播衰減;EMD(·,·)為2個分布的EMD距離[17];η為稀疏正則化系數;‖·‖0用于度量非零量的個數;A(i)表示第i條鏈接上速度與多普勒頻移的映射矩陣,其滿足公式[10]:
(4)
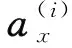
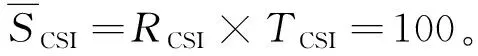
(5)
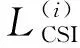
1.2 基于動態CSI分割模式的BVP估計算法
CSI數據長度會因手勢及手勢執行對象間的差異而變化,進而導致BVP的序列長度發生變化。為了消除這種差異,Widar3.0中[10]通過重采樣來統一BVP序列長度,其流程如圖1(a)所示。
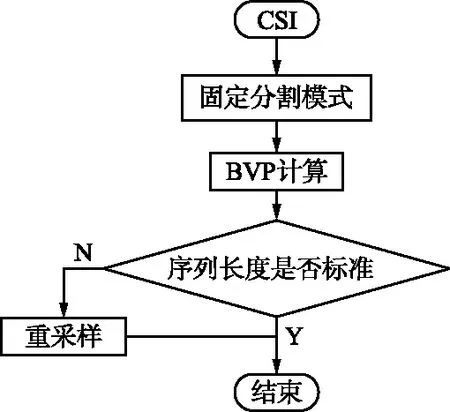
(a) 固定分割模式
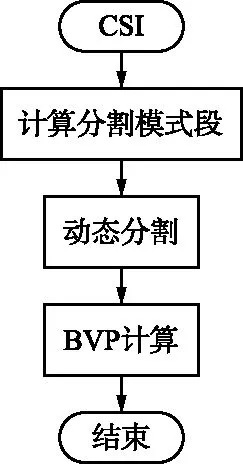
(b) 動態分割模式圖1 不同分割模式BVP計算流程Fig.1 BVP calculation process under different segmentation models

(6)
動態分割模式較固定分割模式相比,其在最初階段通過標準BVP序列長度計算CSI模式段長度。因此,可直接得到標準格式的BVP數據,進而建立起原始CSI數據與BVP特征之間的直接映射關系。同時,動態分割模式下不再需要進行額外的重采樣操作,進而提升了BVP的計算效率。
2 基于膠囊網絡的手勢識別方法
卷積神經網絡(Convolutional Neural Network,CNN)在分類、檢測等視覺任務領域取得了很好的效果[18]。CNN可以根據應用場景自動提取圖像的適當特征,但其在訓練過程中需要大量地標記數據。本文使用遷移學習來解決上述問題,遷移學習就是將源領域的學習模型遷移到目標領域,其不要求源域數據和目標域數據具有相同分布,因此可以將圖像識別領域訓練好的模型應用到WiFi手勢識別任務中。
2.1 膠囊網絡及動態路由
與傳統的CNN不同,傳統CNN在進行池化操作時存在丟失實體在區域內位置信息的缺陷,而膠囊網絡通過向量來表示相應的特征,不會丟失實體在區域內的位置信息[12]。其核心部分為基礎膠囊(Primary Caps)和數字膠囊(Digit Caps)。
對于一個普通輸入,構建一個包含T×D個通道的卷積層,其中T為基礎膠囊通道的數量,D為每個膠囊的維度。通過卷積計算,即可得到長和寬為L×W的T×D個輸出通道,這樣便創建了L×W×T個維度為D的基礎膠囊。
數字膠囊由s個膠囊組成,每個膠囊代表一個類別,通過計算每個膠囊的二范數來表示當前類別的概率,二范數最大的膠囊即表示模型的預測類別。基礎膠囊通過動態路由算法來確定與數字膠囊的關聯,任意數字膠囊的輸入通過式(7)計算[12]:
(7)
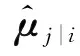
(8)
經過r次迭代,膠囊之間的路由權重便得以建立。
2.2 GRU-CapNet
BVP特征反映了速度在時間和空間上的變化,包含了速度在時間上的信息。為了防止卷積神經網絡丟失時間維度上的信息,本文綜合使用了循環神經網絡和CNN。通過組合GRU和CapNet,并使用遷移學習遷移在Mnist數據集上預訓練的CapNet,提出了一種基于CapNet遷移學習的GRU-CapNet(tf)網絡,其結構如圖2所示。之所以選擇GRU與CapNet有如下考慮:
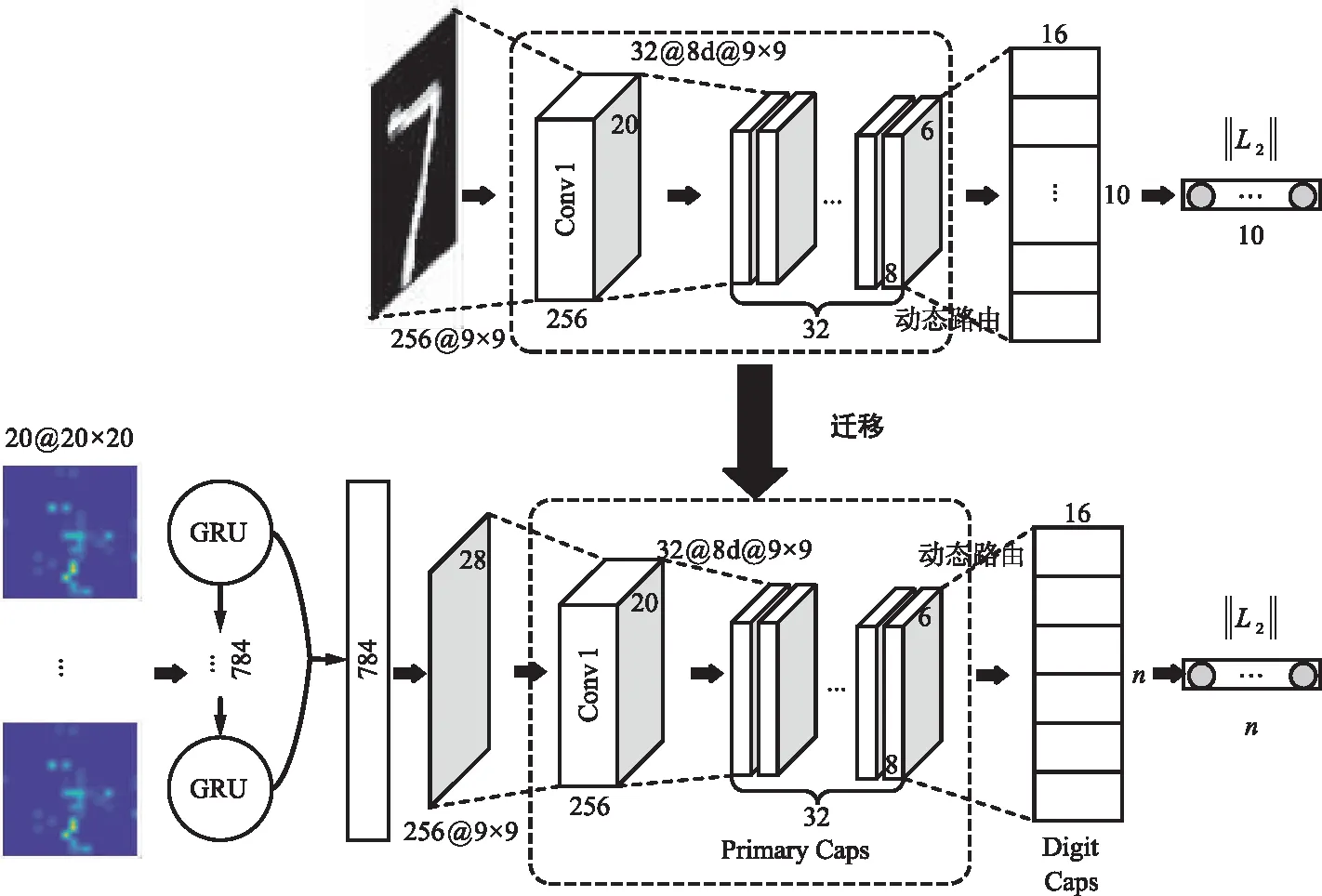
圖2 GRU-CapNet結構Fig.2 GRU-CapNet structure
① GRU與LSTM相比在時序建模方面的性能與LSTM相當,但涉及的參數更少,在數據受限的情況下更容易訓練(后續試驗部分會進行驗證);
② CapNet相較于圖像識別領域的其他模型,如:AlexNet[18],VGG-19[19],ResNet[20]等,克服了池化操作帶來的信息損失且結構更加簡單。而本文的出發點在于通過遷移學習讓模型在有限數據集下能夠充分訓練獲得更高的準確率,而遷移學習過程中模型無法進行完全遷移,需要針對具體應用進行微調。也就是說模型中的部分參數需要重新進行訓練,那么在這種情況下,CapNet作為一種結構更為簡單的模型所涉及到需要重新訓練的參數更少,因此更加符合本文需求。
對于輸入格式是20×20×20的手勢BVP序列,首先使用包含784個單元的GRU提取BVP數據的時序特征。隨后將得到的特征向量重塑成28×28的特征映射圖并且進行歸一化處理,輸入到在Mnist數據集上預訓練過的膠囊網絡遷移結構中。遷移結構包含Conv1卷積層和基礎膠囊層,第1層Conv1卷積層是由256個9×9卷積核組成的普通卷積層,卷積核的步長為1并使用ReLU作為激活函數;第2層基礎膠囊層,其中包含了32個8d膠囊,每個膠囊卷積核大小是9×9,步長為2,同樣使用ReLU作為激活函數。
緊隨遷移結構的是數字膠囊層,數字膠囊層由n個16d的數字膠囊組成,每個數字膠囊的值由基礎膠囊層的輸出通過動態路由算法計算得到。最后,通過計算數字膠囊層中每個數字膠囊的二范數來表示在不同類別上的概率。由于數字膠囊層膠囊的個數n與手勢分類的類別有關,需要針對不同類別修改數字膠囊的個數,因此數字膠囊層無法直接遷移已訓練好的權重,需要進行重新訓練,即微調(Fine Tuning)。
3 試驗結果與分析
為驗證本文提出方法的有效性,在公開室內數據集和家用小型轎車應用場景下采集到的數據集上分別進行了試驗。試驗過程中,計算機操作系統為Win10,CPU分別為Intel i7-9700和Intel i5-6500;GPU為NVIDIA Tesla K80;有關BVP計算的試驗程序均在Matlab R2016b上實現;有關手勢識別模型的訓練和測試試驗程序在Python 3.7.9上實現,使用到的相關庫及版本號為:Numpy 1.19.2,Pandas 1.2.4,TensorFlow 2.1.0。
3.1 公開數據集試驗
本節試驗所用數據集來自Widar 3.0:DataSet提供的室內CSI手勢數據,其包含16志愿者×6手勢×5位置×5朝向×5次重復共12 000個CSI手勢數據,6種手勢分別為推&拉、右掃、拍手、劃動、畫圓以及畫Z。
3.1.1 特征提取算法對比試驗
試驗分別使用動態CSI分割模式與固定CSI分割模式在公開CSI數據集上計算對應的BVP特征集。為了方便表示,稱固定CSI分割模式所得BVP特征集為BVPSet,動態CSI分割模式所得BVP特征集為DBVPSet。為了驗證本算法的通用性,分別在GRU[13],LSTM[9]模型以及引言中所提基于BVP提出的CNN-GRU[10],3D-CNN[11]模型和本文所提GRI-CapNet(tf)模型上使用五折交叉驗證進行測試。即將BVP數據分為5份,分別取其中一份作為測試集,剩下的作為訓練集進行訓練,最終計算出這5次結果的平均值作為試驗結果。為了保證每份數據不會出現偏斜的情況,采用同分布采樣保證每份數據在各個手勢類別上的分布一致,最終所得結果如表1所示。
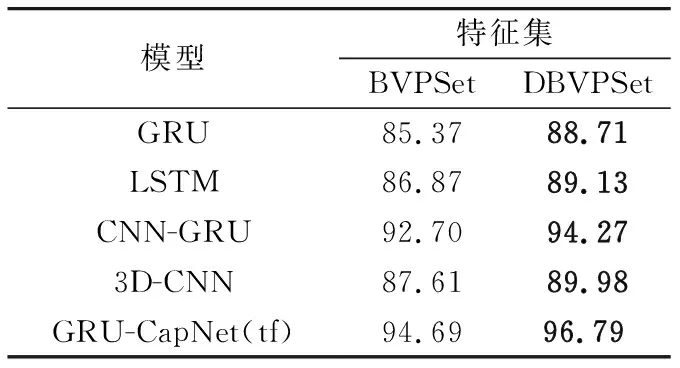
表1 特征集準確率Tab.1 Accuracy of feature set 單位:%
結果表明,不同模型在DBVPSet上所得識別準確率均優于在BVPSet上所得識別準確率,準確率分別提升1.57%~3.34%。因此可以說明基于動態CSI片段分割的BVP估計算法能夠有效地提高數據支撐度,增強BVP與CSI間的映射關系。進一步,統計了在DBVPSet上不同模型的識別延遲與內存占用情況,如表2所示。
在計算資源有限的前提下,可用資源與服務的有效派發是一個重要問題.依據分布式計算、并行計算、虛擬化等技術,云計算能夠有效地將服務器和計算機資源以統一的資源池形式進行有機融合,根據用戶需求動態高效地進行資源分發,提高了資源利用率和降低了使用成本[1].這種基于共享架構的計算模式,需要按照用戶的不同需求進行響應并保證服務質量(Quality of Service, QoS),實現靈活的資源分配.因此,合理且高效的云計算資源調度分配模型的設計,對于提高資源利用率和實現良好的用戶體驗至關重要.
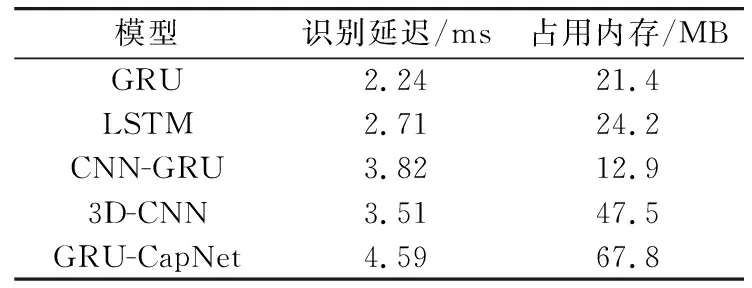
表2 識別延遲和內存占用Tab.2 Identify latency and memory usage
從各模型占用內存與識別延遲可以看到,本文提出的GRU-CapNet模型雖然占用內存最大,但其識別延遲僅為4.78 ms,與其他模型僅存在不超過2.5 ms的差異,因此可認為各模型的識別延遲處于相近水平。結合表1和表2也可以驗證,GRU相對于LSTM有接近的性能(DBVPSet上識別準確率僅相差0.42%),同時涉及到的參數更少(占用內存相比LSTM減少2.8 MB)。
為了更全面地比較改進前后特征提取算法的差異,使用2臺設備進行對照試驗分別統計了不同標準長度下的BVP平均計算延遲和準確率。其中,設備1使用Intel i7-9700處理器,設備2使用Intel i5-6500處理器,其余軟硬件配置均相同。計算延遲與識別準確率分別如表3和圖3所示。
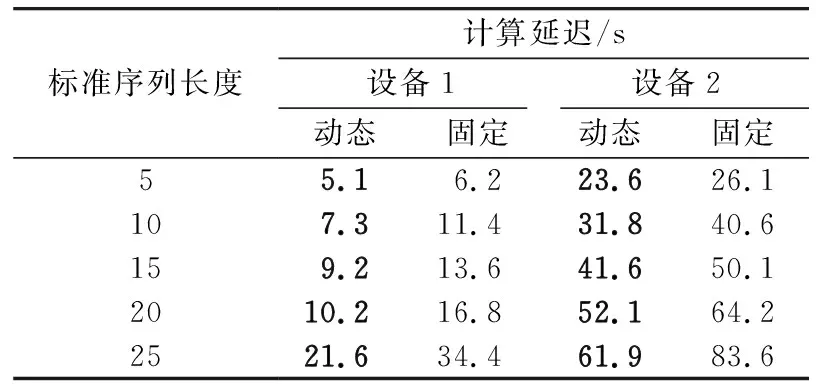
表3 計算延遲統計Tab.3 Calculating latency statistics
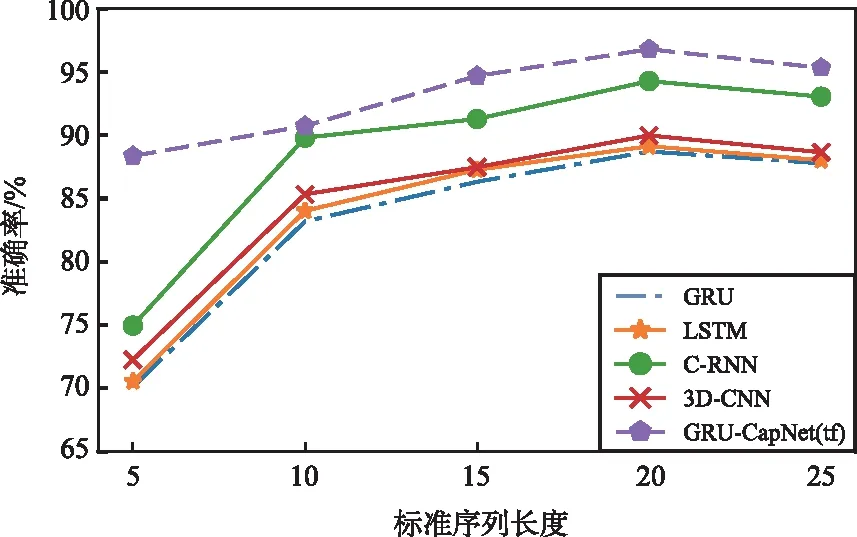
圖3 識別準確率Fig.3 Recognition accuracy
顯然,在動態CSI分割模式下,不同設備上BVP計算延遲均顯著減少,且減少程度隨著BVP標準序列長度的增加逐漸加大,最高減少了21.7 s。這是因為隨著標準序列長度的增加,重采樣計算所需計算的采樣點逐漸增多;而在動態CSI分割模式下不再需要進行重采樣操作,所以大幅減少了BVP計算延遲。
各模型識別準確率隨標準序列長度的增加出現先增后減的趨勢,在取值為20時均達到最大。這是因為序列較短與過長情況下BVP的時間特征過度壓縮和過于分散,從而引起特征包含的有效信息不足。所以選定20作為標準序列長度,此時計算延遲在不同設備上分別減少了6.6,12.1 s。
3.1.2 遷移學習對照試驗
為了驗證遷移學習的效果,本節進行了遷移前后的對照試驗,3.1.1節中已驗證DBVPSet數據集數據支撐度更高,本節遷移學習相關試驗均在DBVPSet上進行,同樣地采用五折交叉驗證。為方便對比,使用GRU-CapNet(raw)表示未使用遷移學習的GRU-CapNet原始模型,其路由迭代次數均設置為3。訓練過程中遷移前后模型GRU-CapNet(raw)與GRU-CapNet(tf)在測試集上準確率(Accuracy)隨訓練迭代次數的變化情況如圖4所示。
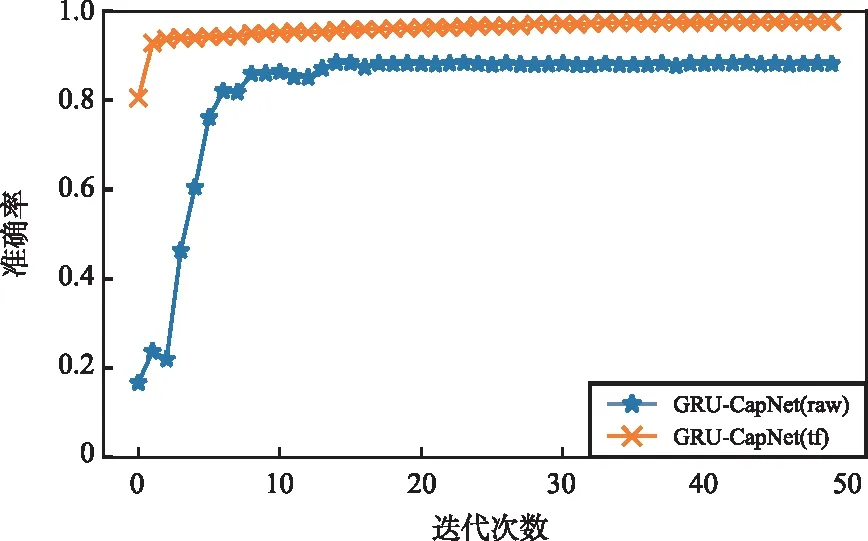
圖4 準確率變化曲線Fig.4 Accuracy variation curve
由圖4可知,在相同情況下,使用遷移學習使得模型在訓練過程中的準確率提升速度更快。同時可以發現,在使用遷移學習過后,僅需少量訓練迭代模型識別準確率即可超過90%,最終準確率相比未使用遷移學習的模型提升了大約8%。訓練過程中GRU-CapNet(raw)與GRU-CapNet(tf)的損失(Loss)隨訓練迭代次數的變化趨勢如圖5所示。
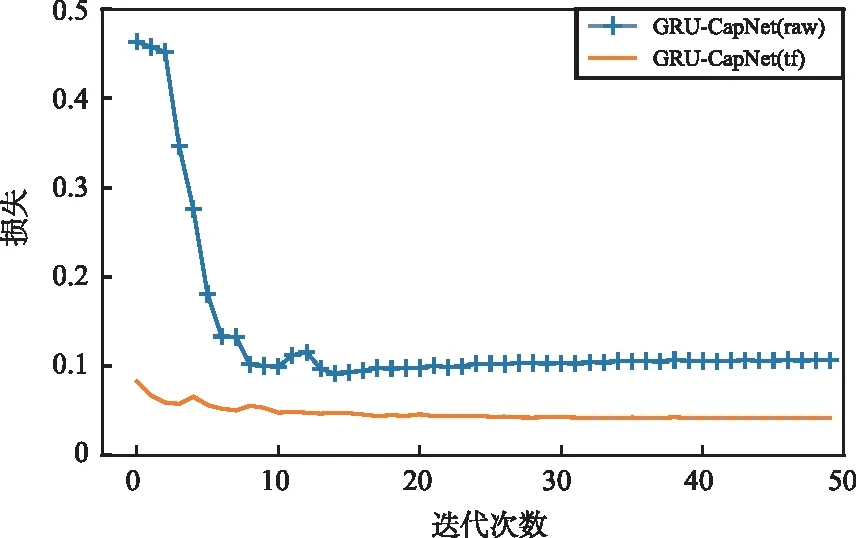
圖5 損失變化曲線Fig.5 Loss variation curve
損失隨著訓練迭代次數的增加呈現下降的趨勢,最終趨于穩定。其中,GRU-CapNet(raw)的損失穩定在0.1左右,GRU-CapNet(tf)的損失穩定在0.04左右。相較于未使用遷移學習的原始模型而言,使用遷移學習后模型的整體損失更低,同時初始損失處于較低區間內。最終GRU-CapNet(raw)與GRU-CapNet(tf)模型五折交叉驗證的平均結果如表4所示。
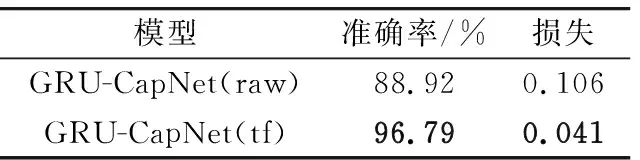
表4 五折交叉驗證平均結果Tab.4 5-fold cross-validation average results
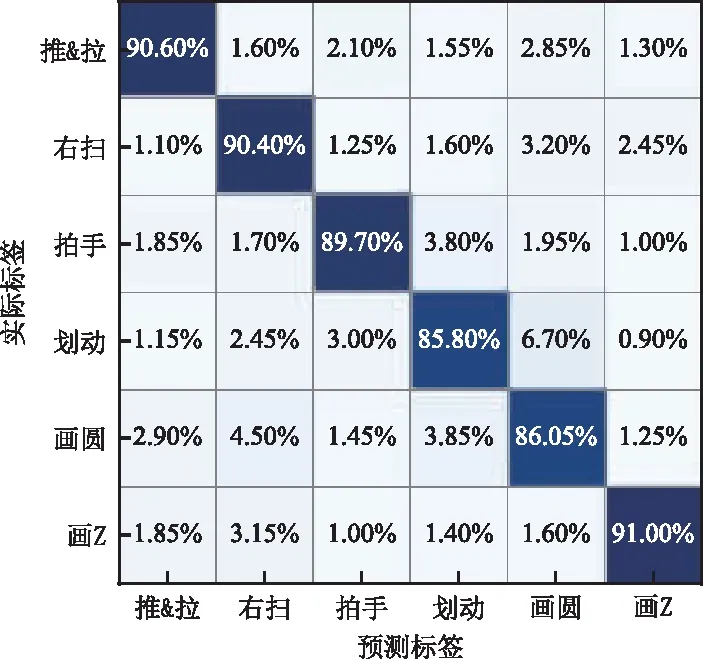
圖6 GRU-CapNet(raw)混淆矩陣Fig.6 Confusion matrix of GRU-CapNet (raw)
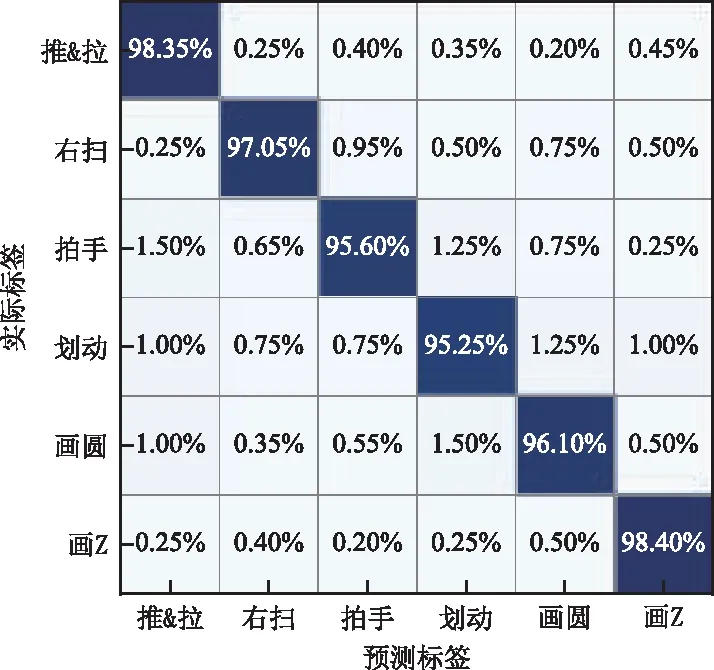
圖7 GRU-CapNet(tf)混淆矩陣Fig.7 Confusion matrix of GRU-CapNet (tf)
3.2 車輛應用場景試驗
本節在家用小型轎車場景下應用本文所提有關方法針對駕駛員手勢識別進行了相關試驗。
3.2.1 數據采集
試驗環境為家用小轎車,車輛型號為雪佛蘭科魯茲。采用一臺路由器作為發送設備,3臺安裝有Intel 5300網卡的筆記本電腦作為接收設備。發包頻率為1 000 Hz,發送設備與接收設備以及被測對象的布局如圖8所示。
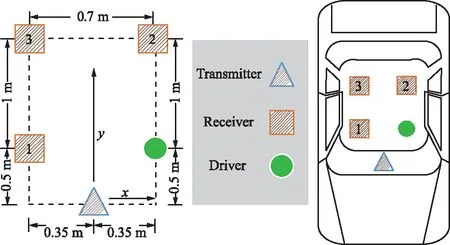
圖8 試驗環境Fig.8 Test environment
測試手勢分別為揮手、畫圓、畫Z和推&拉4種,圖9為不同手勢動作的示意圖。共有14位志愿者參與了數據采集,每人每種手勢采集了20個數據樣本,最終獲取共計1 120個手勢CSI數據。

(a) 揮手

(b) 畫圓

(c) 畫Z
(d) 推&拉圖9 手勢示意Fig.9 Hand gestures
3.2.2 結果與分析
使用動態CSI分割模式的BVP估計算法對采集到的駕駛員手勢數據進行處理,然后通過GRU-CapNet(tf)模型進行識別分類。試驗過程中使用五折交叉驗證,同時與3.1.1節中使用到的其他模型進行對比試驗,其結果如表5所示。
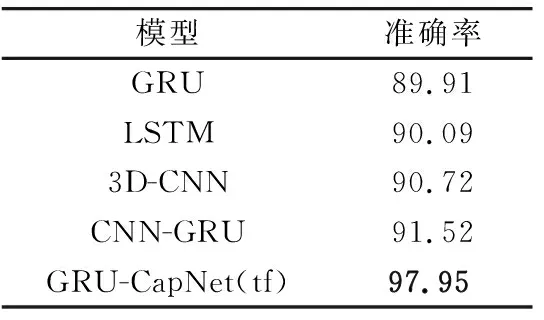
表5 各模型識別準確率Tab.5 Recognition accuracy of different models 單位:%
在車輛應用場景下,GRU-CapNet(tf)的駕駛員手勢識別準確率達到了97.95%,較其他模型提升6.63%~8.04%。GRU-CapNet(tf)對4種手勢的分類混淆矩陣如圖10所示。其中,推&拉動作的識別準確率最高,達到98.93%,揮手的識別準確率為98.57%,畫Z的識別準確率為97.5%,畫圓的識別準確率最低為96.79%。
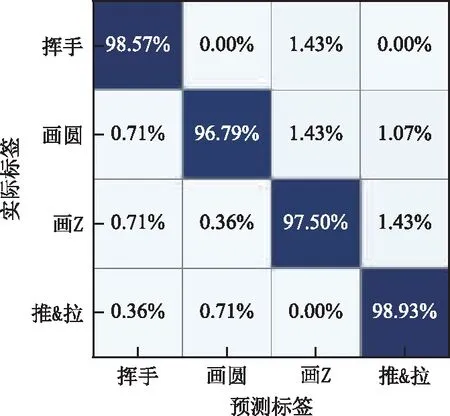
圖10 混淆矩陣Fig.10 Confusion matrix
從結果可知,本文所提方法在有限數據集上得到的性能遠高于其他方法。這是因為遷移的預訓練模型在源領域已經充分訓練,相較于從0開始訓練其初始狀態已處于較高水平,因此所得結果遠高于其他方法。
4 結束語
本文提出了一種基于膠囊網絡遷移學習的WiFi手勢識別方法GRU-CapNet。同時在已有BVP估計算法的基礎上提出了一種基于動態CSI分割模式的BVP估計算法。通過試驗證明,基于遷移學習的GRU-CapNet模型在數據集受限條件下性能顯著高于其他模型,在駕駛員手勢識別應用場景下對手勢的識別準確率達到97.95%,為手勢識別方法提供了新的思路;改進的BVP估計算法能夠明顯提升數據支撐度且顯著減少計算延遲。在接下來的工作中,將針對BVP計算過程中延遲較高的問題進行進一步研究,以提升整體識別過程的實時性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
