基于OpenPose的人體姿態估計技術研究綜述
2023-01-02 12:07:22馬子越彭瑞陽孫曉晗王鈺澤李欣悅孔祥勇
軟件導刊 2022年11期
馬子越,彭瑞陽,孫曉晗,王鈺澤,李欣悅,孔祥勇
(上海理工大學健康科學與工程學院,上海 200093)
0 引言
20 世紀以來,人體姿態估計作為計算機視覺技術中一個具有重要研究意義的領域,已逐漸融入人們的生活當中。例如,無人駕駛環境中對行人的姿態估計、電影和視頻制作中動作特效的設置等。此外,該技術在醫療健康領域發展前景和應用空間更為廣闊。
人體姿態估計是從處理后的圖像或視頻中定位與提取人體關鍵點,進而完成對人體關節和肢干的重構。并且在環境改變、人數增加、對象互動、位置交叉、空間遮擋、大小不一等多種不確定的條件下均具有較高的適應性。
2017 年,Zhe 等[1]提出多人實時關鍵點的OpenPose 算法用于估計人體動作、面部表情、手指運動等,作為首個基于深度學習的姿態估計應用,推動了人體姿態估計發展。
1 人體姿態估計技術發展
1.1 技術分類
根據維度深度信息,可將主流姿態估計算法分為2D姿態估計和3D 姿態估計。其中,3D 姿態估計對攝像頭、傳感器等設備要求較高。該方法常通過微軟Kinect 攝像頭捕捉人體25 個骨骼關鍵點,以獲得關鍵點的空間三維坐標。然而,2D 姿態估計相較于3D 姿態估計而言,前者的發展更為迅速,目前已大量應用于多種綜合場景。
根據圖像中檢測的目標人數又可將2D 姿態估計分為單目標人體姿態估計和多目標人體姿態估計。相較于單目標人體姿態估計,多目標人體姿態估計需要增加相應的算法以解決被檢測目標對象空間位置不確定、實際數量未知的問題。目前通常會選擇自頂向下(Top-down)或自底向上(Bottom-up)的方法。其中,自頂向下方法“先人后點”,精度較高;自底向上方法“先點后人”,速度較快。本文選取了部分使用經典人體姿態估計算法的文章,并按照發表時間進行了整理分類,具體數據如表1所示。
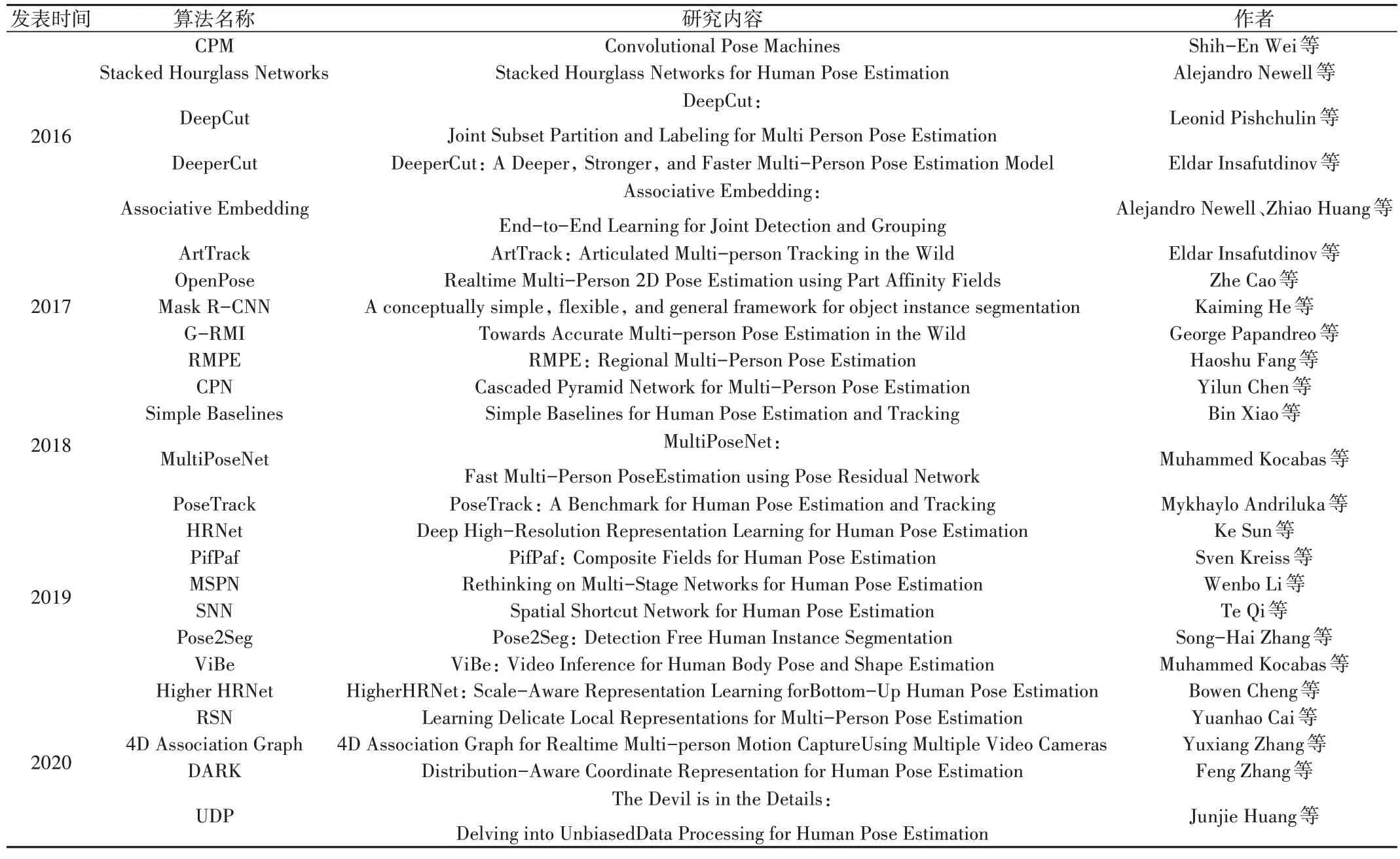
Table 1 Some classical algorithms for human pose estimation表1 人體姿態估計的經典算法部分列舉
1.2 經典算法
經典算法主要包括自底向上或自頂向下、單目標或多目標、單階段或多階段檢測算法。
1.2.1 自底向上或自頂向下方法
該方法目的在于構建最優關鍵點檢測路徑。Chen等[2]提出的級聯金字塔網絡結構(Cascaded Pyramid Network,CPN)和Xiao 等[3]提出的Simple Baselines 算法均采用自頂而下的檢測方法進行多人關鍵點估計。其中,CPN 網絡對每一個區域框中的人體關鍵點進行回歸處理,輸出的關鍵點準確率較高;Simple Baselines 則較為簡單地構造一個實現2D 到3D 人體關鍵點的回歸過程神經網絡。
1.2.2 單目標檢測算法
該類方法以Wei 等[4]提出的卷積姿態機(Convolutional Pose Machines,CPM)和Newell 等[5]提出的堆疊沙漏網絡結構(Stacked Hourglass Networks,SHN)為基礎。其中,CPM 算法基于順序化全卷積網絡結構,將深度學習應用于表達圖片的特征和空間信息,并在每一個階段都添加了中間監督訓練環節,在確保處理精度的同時又處理了各關鍵點之間的遠距離關系;SHN 算法則表達了多尺度的空間信息,先對圖像下采樣,再上采樣,然后加入中繼監督訓練預測損失,實現了對圖片所有尺度下的信息采集和各種空間關系的識別。隨后,Newell 等[6]在堆疊沙漏基礎上提出了聯合嵌入算法(Associative Embedding),生成每個關節點的檢測熱圖和聯合嵌入預測標簽,該算法解決了多階段人體姿態估計不連續問題。
1.2.3 多目標檢測算法
Insafutdinov 等[7]提出ArtTrack 算法,通過簡化關節模型圖以加快識別過程,利用前饋卷積網絡承擔大部分計算量,在時間和空間雙維度上實現了多人姿態估計。Fang等[8]提出區域多人姿態檢測(Regional Multi-Person Pose Estimation,RMPE)較好地解決了區域框不精確的問題。Kocabas 等[9]提出基于姿態殘差網絡的多人姿態估計(Multi-Person Pose Estimation using Pose Residual Network,MultiPoseNet)算法處理姿態識別中的人檢測、關鍵點檢測、人分割和姿態估計4 大問題,首先通過兩個相互獨立的網絡分別完成圖片中人體和人體關鍵點檢測,然后利用殘差網絡進行聚類分析,以保證較高的處理精度和性能。Andriluka 等[10]提出多人姿態估計和跟蹤(Multi-Person Pose Estimation and Tracking,PoseTrack)算法,該算法受語義分割的啟發改進了OpenPose 模型的一些缺陷,支持在單個公式中聯合建模,但估計踝關節和腕關節的性能有所降低。He等[11]提出Mask R-CNN 算法,增加了一個分支為各目標生成預測分割掩碼便于后期進行實例分割、姿態估計,但該算法運算速度較慢。Papandreou 等[12]提出遠程方法調用(G-Remote Method Invocation,G-RMI)算法,該算法通過引入熱圖—偏移聚合方法提取人體關鍵點。
1.2.4 多階段檢測算法
Li 等[13]提出多階段人體姿態估計算法(Multi-stage Pose Estimation Network,MSPN)和Qi 等[14]提出的脈沖神經網絡(Spiking Neural Network,SNN)均為多階段網絡。其中,通過MSPN 優化單階段結構,將相鄰階段的特征相互聚合,采用多分支監督管理方式優化結果;SNN 算法相較于卷積神經網絡降低了算法的能量消耗,但容易發生過激活或欠激活現象,導致準確度下降。
為了解決上述問題,Pishchulin 等[15]提出了線性規劃建模的DeepCut 算法,但該算法會導致計算量增加。Insafutdinov 等[16]對這一方法進行改進后提出了DeeperCut算法,通過壓縮待選節點數量,基于各節點間的距離排查重要節點是否存在重復,以減少算法的時間損耗。Sun等[17]提出高分辨率網絡結構(High-Resoultion Net,HRNet),通過跨子網絡多尺度融合并聯網絡,使算法能夠持久保持高分辨率特征工作,提升了姿態識別的精確度。Cheng 等[18]提出Higher HRNet 算法解決了多人姿態估計人物尺度變化的影響,相較于HRNet 分辨率更高,通過結合多分辨率監督和多分辨率聚合,能夠精準定位小型人體的關鍵點。Kreiss 等[19]使用部分強度域(Part Intensity Field,PIF)和部分親和域(Part Association Field,PAF)預測關鍵點的位置及關系,使算法在低分辨率、多人數、場景擁擠混亂等情況下仍具有良好的檢測效果。Cai等[20]提出殘差階梯網絡(Residual Steps Network,RSN)將相同空間大小的內部特征進行聚合,使每一個殘差階梯網絡的基本單元(Residual Steps Block,RSB)利用內部特征間信息進行準確定位。Zhang 等[21]提出分布感知的關鍵點坐標表示法(Distribution-Aware coordinate Representation of Keypoints,DARK),通過編碼關鍵點坐標,提升算法的性能。Huang等[22]提出無偏數據處理(Unbiased Data Processing,UDP)方法,采用單位長度代替像素大小度量圖像,在編碼、解碼過程中解決了統計誤差,進一步提升了算法的準確度。
在實際場景中,Kocabas 等[23]提出了基于背景更新的運動目標檢測(Visual Background Extractor,ViBe)算法,該算法在保證像素模型時間和空間連續性的情況下,能夠對視頻中的人體進行姿態估計。Zhang 等[24]提出人體分割算法(Pose2Seg),利用像素分割技術將人體姿態估計應用于實際中。Zhang 等[25]提出4D 關聯圖模型(4D Association Graph),利用圖網絡對人體姿態進行實時捕捉,構建一種可同時處理時間、空間等多維度的4D 關聯圖以優化實時捕捉的關節點。
2 OpenPose基本模型
OpenPose 在多人圖像中主要使用了自底向上的方法對人體姿態進行估計,該方法不會隨著檢測人數增加而影響檢測速度,部分親和域技術可形成局部關聯場,確定某些姿勢是否隸屬于同一個人,從而建立人體各關鍵點之間的聯系,以提高檢測精度。
圖1 為OpenPose 實現人體姿態估計的流程。其中,圖(a)為輸入,圖(b)為身體部分位置的二維置信度映射圖集S,圖(c)為部分親和的二維向量場集L,圖(d)為人體關鍵點。

Fig.1 Openpose human posture estimation process圖1 OpenPose人體姿態估計流程
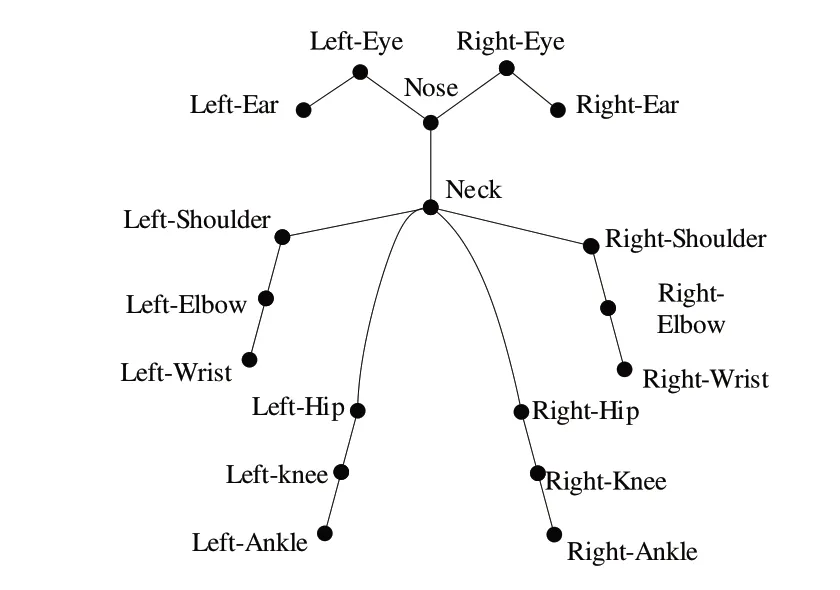
Fig.2 Key point of human skeleton圖2 人體骨骼關鍵點
如圖2 所示,OpenPose 提供了18 個人體關鍵點,設置了兩分支、多階段結構的CNN 框架。其中,第一分支預測置信圖,輸出圖像特征;第二分支預測部分親和域,輸出空間特征。同時,采用多級級聯、連續重復及在每個階段設置中間監管損失函數的方式優化預測結果。
3 OpenPose優化模型
3.1 優化底層特征提取方式
傳統OpenPose 模型通常基于VGG-19 網絡,使用標準卷積提取底層特征。然而,深度可分離卷積(Depthwise Separable Convolutions,DSC)擁有更輕量級的參數,可提升運行速度。Sandler 等[26]提出基于深度可分離卷積的計算機視覺神經網絡(MobileNet)模型,在小幅度降低精度的情況下,大幅度減少了模型計算量。文獻[27-31]將深度可分離卷積結構引入OpenPose 模型中,對底層特征提取方式進行優化,通過減少單個卷積層的計算量、模型參數、卷積層等方法,在不損失精度的條件下,提升了模型運行速度,解決了由于運算量過大,而無法在移動設備或嵌入式設備上運行的問題。
深度可分離卷積將原OpenPose 中的一個標準卷積層因式分解為一個Depthwise 卷積和一個Pointwise 卷積。其中,Depthwise 卷積核與輸入的每個通道進行卷積;Pointwise 與上層輸出的不同通道特征圖進行線性組合,從而將不同通道位于同一位置的特征信息進行高效利用和組合。圖3(a)為標準卷積層的標準卷積核結構,卷積核K的長度和寬度均為DK,輸入通道數為M,輸出通道數為N。
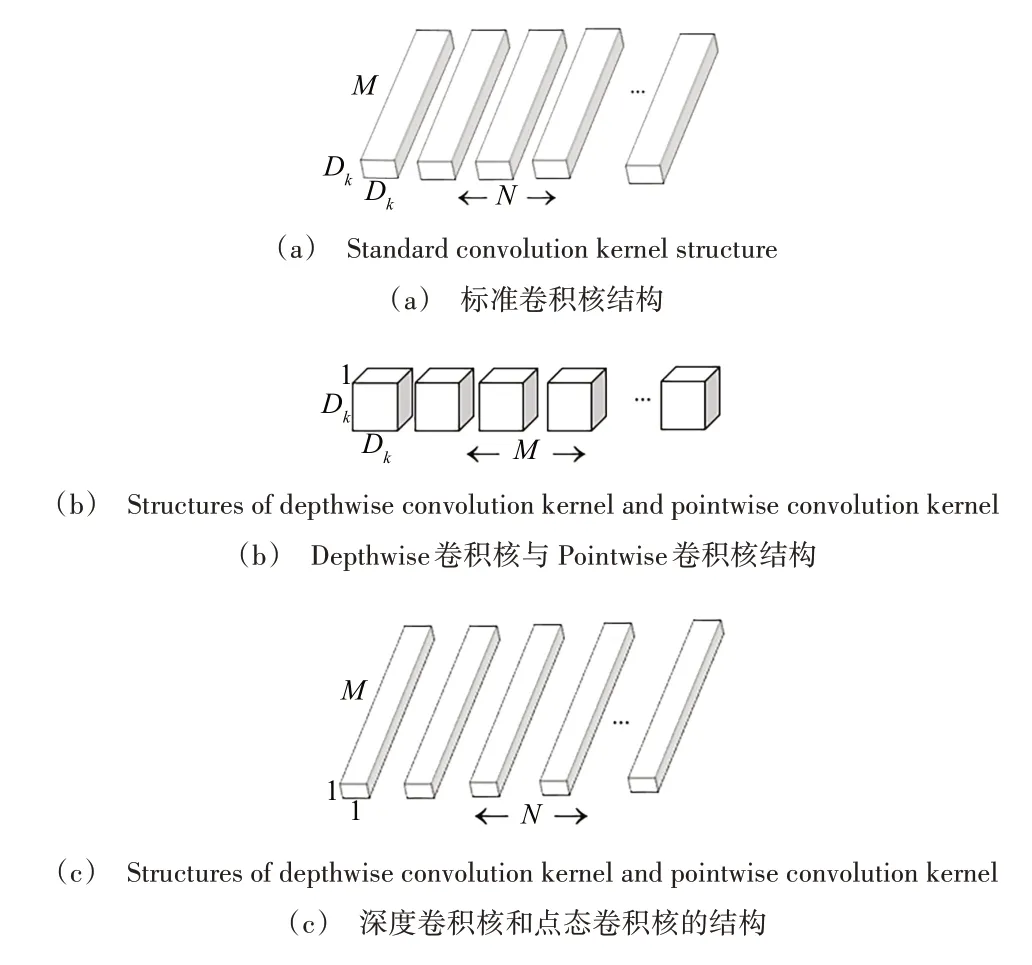
Fig.3 Convolution kernel structure圖3 卷積核結構
此外,采用殘差網絡算法提取底層特征代替傳統模型的VGG-19 網絡也可提升OpenPose 模型的檢測精度和訓練速度。朱洪堃等[32]將底層特征提取網絡更換為Res-18網絡,通過添加二階項融合的殘差網絡提取底層特征,對比性能后發現改進后的模型在精度和速度上均有所提升。馮文宇等[33]使用了自適應軟閾值的殘差網絡,顯著增加了模型的檢測精度且未明顯影響檢測速度。
3.2 優化數據分類方法
在提取人體關節點數據后,還需進行分類處理才可用于判斷行為特征。目前,基于傳統機器學習分類器算法的應用較為廣泛,主要包括支持向量機(Support Vector Machine,SVM)、深度神經網絡(Deep Neural Networks,DNN)、極限學習機(Extreme Learning Machine,ELM)、決策樹(Decision Tree,DT)、K 近鄰(K-NEearest Neighbors,KNN)等。本文主要介紹了SVM 和ELM 兩種分類算法。
3.2.1 SVM
SVM 是一種二分類模型,對于小樣本集具有較好的訓練效果,并可高效處理OpenPose 提取的高維數據集。為了將它適應于多分類任務,蘇超等[34]采用間接法構建基于決策樹的SVM 多類分類器(ST-SVM)優化分類方法,將所有信息循環二分直到每個結點歸屬到唯一類別。袁鵬泰等[35]為了提高SVM 分類器準確度,將改進Yolo 算法先行引入OpenPose 算法中,避免了在無人處識別關節點信息。李夢荷等[36]為實現多人行為識別,將特征矩陣輸入SVM分類器中進行分類,以提高識別準確度。蔡文郁等[37]通過原始視頻圖像中的關鍵點數據提取跌倒特征向量,經過SVM 初級分類器分類后,再利用CNN 分類器進行二次分類,以降低模型計算量。
3.2.2 ELM
如圖4 所示,相較于傳統神經網絡模型,ELM 網絡隨機設定輸入層與隱含層的鏈接權值W 和隱含層神經元的偏置O,隱含層節點個數N 設置完成后即可固定不變。在執行過程中,無需人工調整算法參數,避免了反復迭代造成的時間損耗。張青等[38]通過對150 個圖像的100 次迭代測試發現,ELM 網絡的測試精度和運行速度都顯著優于BP 神經網絡[39]。
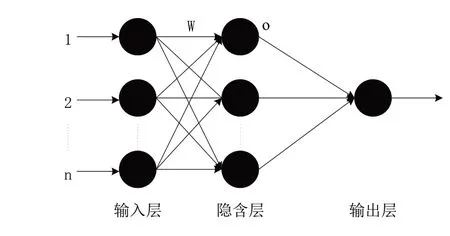
Fig.4 ELM network computing principle圖4 ELM網絡計算原理
4 模型存在的不足
目前,人體姿態估計技術仍在不斷發展,基于Open-Pose 模型的人體姿態估計應用也在不斷更新,如表2所示。盡管對底層特征提取方式、數據分類方法等多方面均有所優化,但在實際應用中,仍暴露出許多問題:
(1)檢測精度會因人體姿態的不同而變化。
(2)精度和速度在一些模型中無法同時得到提升。通常,為了提高模型運行速度會減少模型參數,造成模型精度下降。
(3)各優化模型相較于傳統OpenPose 模型而言,均基于實際應用背景下的特定數據集,并不具有通用性,應用場景相對單一。

Table 2 Some algorithms for human pose estimation optimization表2 人體姿態估計優化的部分算法
5 結語
人體姿態估計技術是計算機視覺技術中具有重要研究意義的領域之一,尤其在醫療健康領域中具有更加廣闊的發展前景。人體姿態估計有關的研究報告大部分側重于對基本模型、方法的歸納和介紹[40-41],研究人員可初步了解人體姿態估計的部分經典算法,但很少有結合實際應用背景對算法進行分類的研究。為此,本文在對人體姿態估計算法進行分類列舉、詳細介紹后,系統地介紹了由OpenPose 算法演變而來的改進模型。首先,對25 種算法進行細致梳理和介紹。然后,對OpenPose 算法進行了具體闡述,并基于不同優化對象,選取了7 種應用于實際的OpenPose 優化模型進行深度分析。最后,總結基于Open-Pose 的改進算法的不足之處,為未來人體姿態估計技術的研究提供思路。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
中學生數理化·中考版(2022年12期)2022-02-16 07:36:56
今日農業(2021年8期)2021-11-28 05:07:50
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
海峽科技與產業(2016年3期)2016-05-17 04:32:12
