基于多尺度特征與通道特征融合的腦腫瘤良惡性分類模型
2023-01-07 05:42:20姜林奇寧春玉余海濤
中國光學 2022年6期
姜林奇,寧春玉,余海濤
(長春理工大學 生命科學技術學院, 吉林 長春 130022)
1 引 言
根據2018年全球癌癥統計報告可知,大腦及神經系統癌變發生率約為2.9人/(年·10萬人),約占全身腫瘤的1.6%,死亡率高達2.5%[1]。根據病因可以將大腦及神經系統癌變分為原發性和繼發性。其中,膠質瘤(glioma)作為最常見的原發性腦腫瘤被廣泛關注。根據磁共振腫瘤成像所呈現的特點,可將其惡化的程度分為低級別膠質瘤(Low Grade Gliomas, LGG)和高級別膠質瘤(High Grade Gliomas, HGG)[2]。如果醫生不能準確地對腫瘤的惡化程度進行分類,隨著時間的推移良性腫瘤很有可能會惡化成惡性腫瘤。因此,腫瘤的良惡性分類尤其重要[3]。
基于傳統機器學習的圖像分類方法通過提取圖像的紋理信息,比如形狀特征、顏色等,再利用支持向量機(Support Vector Machines, SVM)或其他分類器實現分類[4-6]。 Raju等人[7]采用貝葉斯模糊聚類方法進行腦腫瘤分割,并利用HCS(Harmony-Crow Search)優化算法來訓練multi-SVNN分類器的權重,計算圖像特征,得到的分類精度為93%。Narmatha等人[8]提出了將模糊算法與Brain-storm優化算法相結合的Fuzzy Brain-storm optimization 算法用于腦腫瘤圖像的分割與分類。該方法有效地縮短了圖像的分割時間,但最終的分類準確率僅為93.85%。
傳統的圖像分類方法在圖像特征的選擇上更依賴于操作者的先驗知識,工作量大并且過程較復雜。近幾年,深度學習(Deep Learning,DL)作為一種新興技術被廣泛應用于圖像分割、圖像分類、圖像識別等任務中[9-12]。面對圖像特征復雜的醫學圖像,學者們提出將DL引進到醫學影像領域當中[13-14]。
目前,腦腫瘤分類系統可分為非端到端式和端到端式。非端到端的分類系統是指由多個獨立部分組成的系統,卷積神經網絡(Convolutional Neural Network,CNN)擔任其中一個或多個部分。Sharif等人[15]提出一種基于深度學習的方法來實現腫瘤的分割與分類。該方法使用預訓練后的Inception V3網絡對分割結果圖進行特征提取,并將分別由傳統方法和深度學習提取的特征進行拼接,通過粒子群優化算法(Particle Swarm Optimization,PSO)進行特征向量的優化,最后,通過Softmax分類器進行分類,得到了96.90%的準確率。Khan等人[16]提出一種基于極限學習機(Extreme Learning Machine, ELM)的自動分類方法。該方法利用預訓練過的VGG16提取圖像特征,然后通過ELM對融合的魯棒特征進行分類,有效減少了特征選取與融合的時間。Rehman等人[17]提出將3D CNN模型用于腦腫瘤的檢測,利用預訓練的VGG19網絡用于特征提取,利用前反饋神經網絡(Feed-forward Neural Network,FNN)選取最佳特征用于分類。該方法取得了較高的準確率,但腫瘤檢測過程耗費時間較長。以上非端到端的分類系統對腦部腫瘤的分類準確率都有所提升,但此類系統大多基于圖像分割,分類過程復雜,故會引入較多干擾因素,不可避免地會對分類結果造成影響。
端到端的分類系統是指僅通過卷積神經網絡實現對腫瘤圖像的分類。Seetha等人[18]針對腦腫瘤區域結構異化的問題,提出利用小卷積核提取腫瘤區域的細微特征,實現對腫瘤良惡性分類,最終得到了97.50%的準確率。趙尚義等人[19]提出了3D U-Net模型的分類算法。該方法在原始UNet 網絡中引入了特征融合層,將淺層特征與深層特征相融合,實現了基于分割網絡U-Net的分類系統。但該方法沒有對淺層特征與深層特征的特征通道權重進行重新分配,過分表達冗余特征,導致最終的分類準確率僅達到91.67%。端到端式的分類系統基于設計好的網絡結構,利用深度學習自動提取圖像特征,降低了分類過程復雜性。但是上述用于腦腫瘤的分類方法沒有充分利用圖像的全局、局部顯著特征以及特征圖的通道特性,識別準確率還有待進一步提高。
針對上述問題,本文提出一種基于多尺度特征與通道特征融合的腦腫瘤良惡性自動分類方法(Improved MDCA-ResNeXt),利用ResNeXt網絡結構的分組卷積策略,在增加網絡寬度的同時提升了網絡提取特征信息的能力,并通過多尺度特征提取模塊融合全局特征與局部顯著特征,通過通道注意力機制模塊提升網絡對病灶區域的關注度,減少冗余信息對分類結果造成的影響,最終達到提高腫瘤良惡性分類精度的目的。
2 基于Improved MDCA-ResNeXt的腦腫瘤良惡性分類模型
2.1 MDCA-ResNeXt網絡
在對圖像特征信息復雜、數據特征維度高的醫學圖像進行分類時,不僅要考慮網絡提取特征信息的能力,還需要考慮訓練過程的計算復雜度等問題,經過多番考慮,本文選用ResNeXt[20]網絡作為腦腫瘤圖像分類任務的主干網絡,對其進行改進,以提高網絡分類能力、降低參數冗余度、減少計算時間。首先,將基于空洞卷積的多尺度特征提取模塊(Multi-scale Feature Extraction Module based on Dilated Convolution, MD)代替一般的卷積層,擴大第一層卷積層的感受野,同時保留HGG圖像中增強區域的局部顯著特征,將全局特征與局部顯著特征融合;其次,添加通道注意力機制模塊(Channel Attention Module,CA),引入特征通道信息,對特征通道重新分配,減少特征冗余引起的影響,提高腫瘤區域在整幅圖像中的關注度;最后,簡化ResNeXt網絡,減少ResNeXt結構個數,避免因網絡過深導致的過擬合現象。圖1為本文提出的MDCA-ResNeXt網絡結構。
2.1.1 ResNeXt結構
ResNeXt結構采用Inception結構[21]中的拆分-轉換-合并的思想,沿用ResNet[22]的殘差結構,構造重復的多分組卷積層。ResNeXt結構的本質是分組卷積,它通過變量基數C來控制組的數量,從而達到兩種策略的平衡。圖2為C=32的Res-NeXt結構。圖中“彎曲的箭頭”表示殘差結構的恒等映射,⊕表示逐個像素點相加。
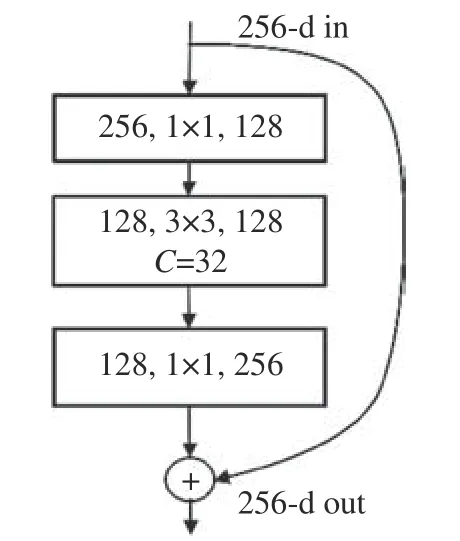
圖2 C =32的ResNeXt結構[20]Fig. 2 ResNeXt structure with C =32[20]
ResNeXt結構的運算過程可用數學公式表達為:
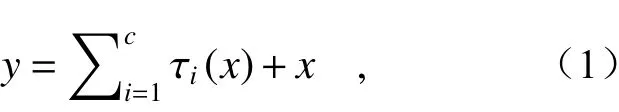
其中τ表 示 1×1→3×3→1×1一系列的卷積操作。
2.1.2 多尺度特征提取模塊
空洞卷積(dilated convolution)[23]相對于正常卷積模板多一個膨脹率d,它表示在卷積核中插入權重為0的行和列的數量。圖3為不同膨脹率的空洞卷積。當d=1時,卷積模板的感受野與3×3的 卷積模板相同;當d=2時,卷積模板的感受野與5 ×5的 卷積模板相同;當d=3時,卷積模板的感受野與7 ×7的卷積模板相同。
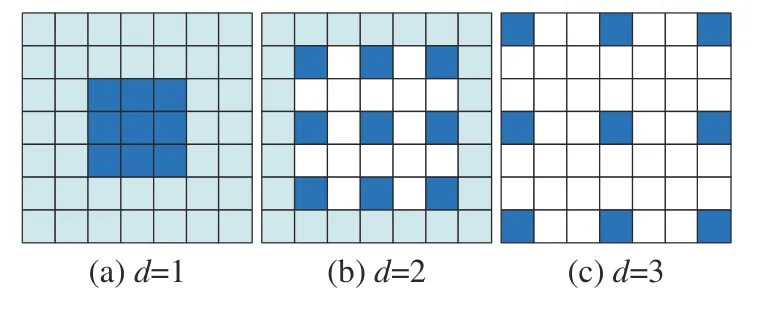
圖3 不同膨脹率的空洞卷積Fig. 3 Dilated convolution results with different dilation rates
圖4為本文提出的MD模塊,該模塊的第一層卷積層包括了1 ×1的普通卷積模板以及卷積尺寸為 3×3、 膨脹率d分別為1 ,2,3的空洞卷積模板。第二層的卷積層是由1 ×1卷積模板組成,其作用是將上一層的輸出特征圖拼接在一起,得到同時包含全局與局部顯著特征信息的特征圖。
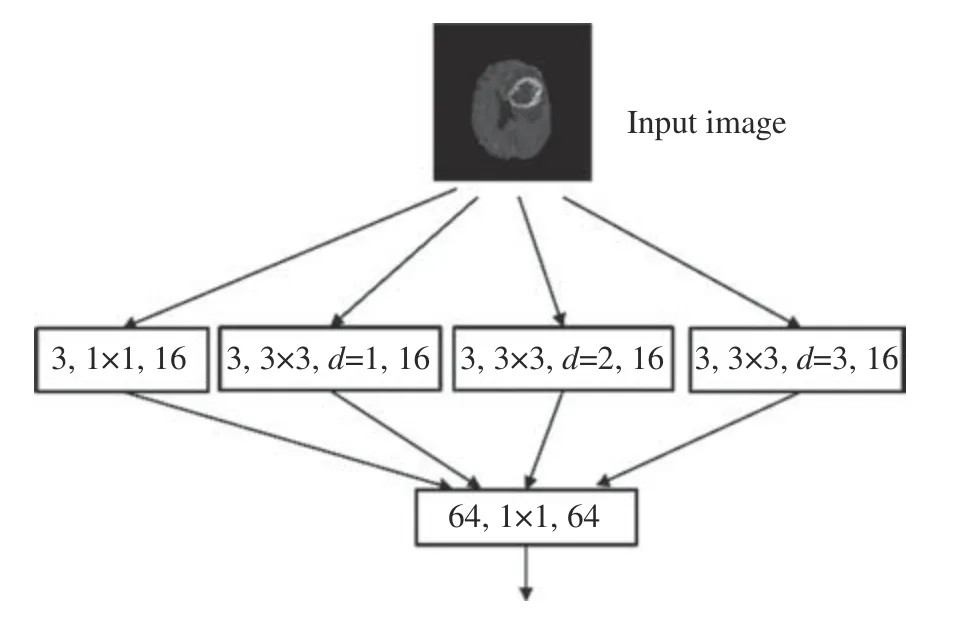
圖4 MD模塊Fig. 4 MD module
2.1.3 通道注意力機制模塊
圖5為注意力機制[24]中的通道注意力機制模塊(Channel Attention Module,CA),該模塊通過建立特征圖之間的通道關系,生成通道注意力圖,對特征通道重新分配權重,提高網絡對輸入圖像中重要信息的關注度,降低網絡對冗余信息的關注度。其計算過程如下:
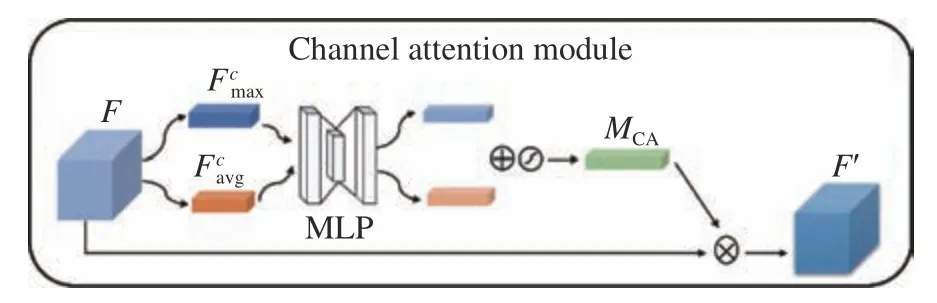
圖5 CA模塊Fig. 5 CA module
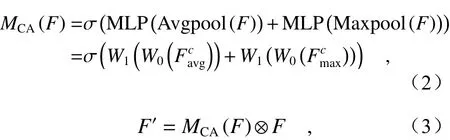
其中, Avgpool 和 Maxpool 分 別表示對輸入特征F進行全局平均池化操作和全局最大池化操作,MLP表示多層感知器(Multi-layer Perceptron, MLP),W0和W1為MLP層之間的共享權重,其維數分別為:W0∈RC/r×C,W1∈RC×C/r,r表示降維系數,σ表示sigmoid函數,?表示像素點相乘。
2.2 基于MDCA-ResNeXt網絡的優化策略
在設計分類模型過程中,網絡結構對圖像特征的提取起著關鍵作用,但是在訓練過程中需要設置的超參數也會影響網絡的學習能力。此外,提高網絡的學習能力是一個比較漫長、復雜的過程。在腦腫瘤的前期分類任務中,本文作者提出了學習率的線性衰減策略、圖像的標簽平滑策略以及基于醫學圖像的遷移學習策略3種優化策略的組合[25]。為了提高網絡的學習能力,減少訓練的迭代次數,本文采用相同的優化策略對MDCAResNeXt網絡進行優化,經過優化的網絡簡記為Improved MDCA-ResNeXt網絡。預訓練過程中網絡的訓練迭代次數為50,批次大小為8,優化算法為帶有動量隨機梯度下降優化算法(Stochastic Gradient Descent with Momentum, SGDM),初始學習率為0.01,學習率衰減迭代次數分別為30和40,標簽平滑系數為0.01,采用Cheng等人[26]提供的CE-MRI數據庫作為預訓練數據集。該數據庫包含了T1C模態下233名病人的3 064張腦腫瘤MRI切片圖像,其中包含了1 426張膠質瘤圖像、930張腦膜瘤圖像和708張垂體瘤圖像。
3 實驗設計
3.1 實驗數據
3.1.1 BraTS數據庫
本文使用的BraTS2017和BraTS2019數據庫分別為2017年和2019年舉辦的多模態腦腫瘤分割挑戰賽提供的開源數據庫。BraTS2017數據庫中包含210例HGG和75例LGG,BraTS2019數據庫包含259例HGG和76例LGG。數據庫中每個病例都包括FLAIR、T2、T1和T1C 4種模態的MRI序列,每個序列包含155張切片圖像,圖像分辨率為240 pixel×240 pixel。圖6、圖7為4種模態下的HGG和LGG腫瘤圖像。通過對比不同模態MRI圖像可知,添加了造影劑的T1C模態能夠更加凸顯病灶區域的特征,因此本文選用該模態下的圖像作為原始輸入。
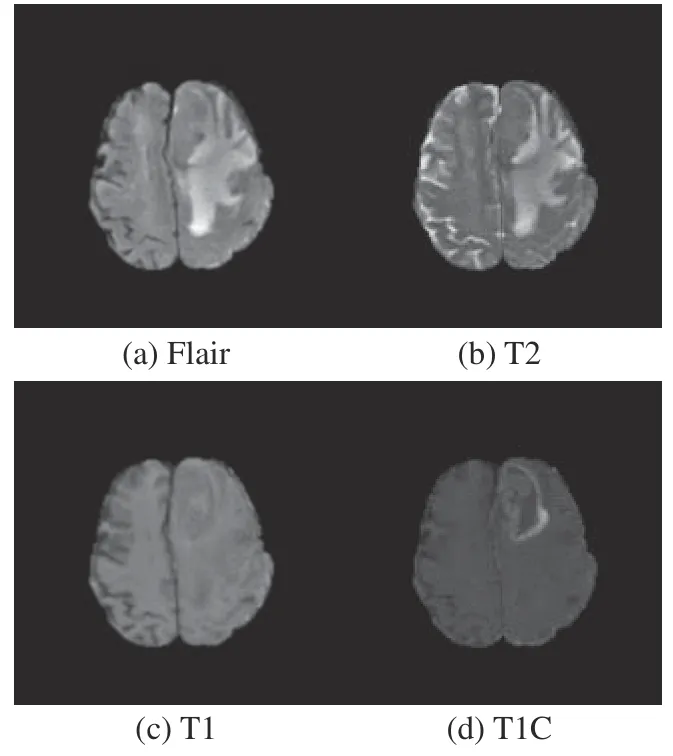
圖6 4種模態下的HGG圖像Fig. 6 HGG images in four modalities
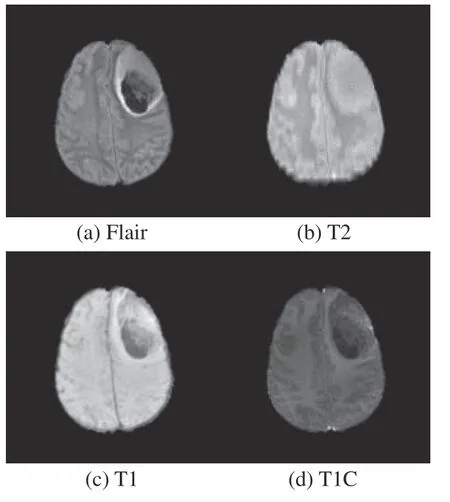
圖7 4種模態下的LGG圖像Fig. 7 LGG images in four modalities
3.1.2 數據預處理
圖8為去噪前后對比圖。圖8(a)中矩形虛線框內圖像中含有一些不均勻的信號,這是由于設備老化等問題造成的灰度變化不均。這種現象稱為偏置場效應。如果在圖像預處理階段不對其進行處理,很容易造成網絡對圖像的錯誤判斷,所以本文使用優化后的N3(Nonparametric nonuniform intensity normalization)[27]算法——N4ITK算法[28]對原始圖像數據進行偏置場校正。圖8(b)是N4ITK算法校正后的MRI圖像,可見虛線框內的亮度變得比較均勻。
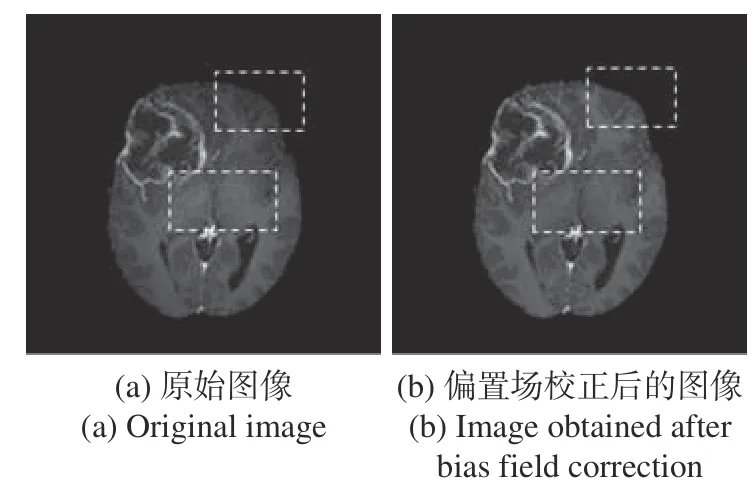
圖8 去除噪聲前后對比圖Fig. 8 Comparison before and after preprocessing
在分類任務中,不同類別下的圖像數量分布不均可能會造成過擬合,因此需要對LGG樣本進行數據擴充。本文利用隨機翻轉、旋轉等操作對LGG樣本進行擴充。并通過對訓練集中的圖像進行隨機旋轉、隨機擦除[29]等數據增強操作來增加數據集中來自同一病例的切片圖像的差異性,從而提高網絡分辨能力的魯棒性。
3.1.3 實驗數據集
為了驗證所提出的分類模型對膠質瘤圖像的分類能力,本文將數據增強后的BraTS2017和BraTS2019數據集分別劃分成5個圖像數量相等的子集,進行五折交叉驗證實驗。表1所示為實驗數據集的分布情況。
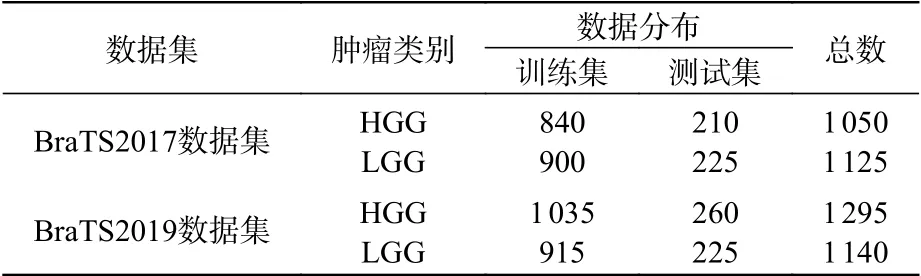
表1 實驗數據集分布Tab. 1 Distribution of experimental datasets
3.2 實驗環境及參數設置
本文基于Pytorch深度學習模型框架,采用Python作為編程語言,在操作系統為Windows 10、GPU為NVIDIA Tesla K40m的實驗平臺搭建了基于Improved MDCA-ResNeXt網絡模型的腦腫瘤圖像良惡性分類框架。網絡訓練過程中的訓練迭代次數為30,批次大小為8,優化算法為SGDM,初始學習率為0.01,學習率衰減迭代次數為20,標簽平滑系數為0.01,網絡初始化參數為遷移學習得到的。
3.3 評價指標
本文采用準確率(Accuracy)、靈敏度(Sensitivity)、特異度(Specificity)、陽性預測值(Positive Predictive Value)以及陰性預測值(Negative Predictive Value)對分類結果進行性能評價。上述指標分別記為ACC、SEN、SPE、PPV及NPV,計算公式如式(4)~式(8)所示。

式中α 和β分別表示真實標簽與預測標簽相同的HGG和LGG樣本個數,δ和 γ分別表示真實標簽與預測標簽不相同的HGG和LGG樣本個數。
3.4 實驗結果與分析
3.4.1 網絡結構消融實驗
本小節將僅含有MD模塊的MD-ResNeXt網絡和僅含有CA模塊的CA-ResNeXt網絡與MDCA-ResNeXt網絡進行對比,以驗證MDCAResNeXt的有效性。為了保證實驗結果的科學性,所有網絡的初始化參數均由相同的隨機數種子生成,實驗數據集為BraTS2017。
圖9(彩圖見期刊電子版)為MD-ResNeXt、CA-ResNeXt和MDCA-ResNeXt 3個網絡在5個交叉驗證集中獲得的分類結果評價圖,圖中數字為評價標準的平均值,線段為標準差。從圖9可以看出,MDCA-ResNeXt對HGG樣本和LGG樣本的分辨能力,相較于MD-ResNeXt和CA-Res-NeXt都有提升,并且標準差相對較小,說明MDCA-ResNeXt在不同驗證集的表現都相對穩定,魯棒性強。
為探究MDCA-ResNeXt工作機制的有效性,對特征圖進行了可視化處理,圖10和圖11分別為HGG樣本、LGG樣本的原始圖像和特征可視化圖。在圖10(a)中,腫瘤區域位于右側大腦顳部,并且核心腫瘤的外圍有增強區域包裹,在圖像中表現為高頻信號。圖10(b)~10(e)分別表示4種網絡結構在同一層輸出的特征圖。對比圖10(b)和圖10(c)可以看出,MD-ResNeXt相較于Res-NeXt更好地保留了腦部組織結構,對腫瘤的增強區域有積極的“響應”;對比圖10(b)和圖10(d)可以看出,CA-ResNeXt相較于ResNeXt更好地突出了腫瘤的增強區域,減少了冗余的特征信息;對比圖10(c)和圖10(e)可以看出,MDCA-Res-NeXt只對腫瘤的增強區域有積極的“響應”,相較于MD-ResNeXt減少了對冗余信息的“響應”,充分說明了在網絡結構中添加CA模塊可以有效地避免冗余特征信息對分類結果造成的影響;對比圖10(d)和圖10(e)可以看出,相較CA-ResNeXt,添加了MD模塊的MDCA-ResNeXt能夠較好地體現腫瘤區域的圖像特征。

圖10 HGG的原始圖像和特征可視化圖Fig. 10 Original image and feature visualizations of HGG

圖11 LGG的原始圖像和特征可視化圖Fig. 11 Original image and feature visualization of LGG
在圖11(a)中,腫瘤區域位于左側大腦顳前部,而良性的膠質瘤在圖像中呈現低頻信號,并且腫瘤外圍沒有出現增強區域。對比圖11(b)、圖11(c)、圖11(d)和圖11(e)可以看出,MDCAResNeXt網絡能夠更有效地保存腦腫瘤圖像的特征信息,能夠更好地區分HGG樣本和LGG樣本。
3.4.2 經典網絡對比實驗
為驗證本文提出的MDCA-ResNeXt網絡以及優化后的Improved MDCA-ResNeXt網絡在腦腫瘤良惡性分類任務中的優勢,本文設置了兩組對比實驗,一組實驗是將ResNet網絡、Res-NeXt網絡和SENet網絡[30]應用在BraTS2017和BraTS2019數據集中,把3種經典網絡的分類結果與MDCA-ResNeXt網絡進行比較;另一組是將優化后的3種經典網絡與Improved MDCA-Res-NeXt網絡的分類結果進行對比。
根據表2和表3可知,MDCA-ResNeXt的分類結果與其他3個經典網絡相比都是最高的。對比不同網絡的SPE值和NPV值可以看出,MDCA-ResNeXt提高了對LGG樣本的分類能力。從表4和表5可以看出,本文提出的Improved MDCA-ResNeXt的各項分類評價標準同樣都是最高的。

表2 優化前BraTS2017數據集的分類結果評價表Tab. 2 Evaluation of classification results on BraTS2017 before optimization

表3 優化前BraTS2019數據集的分類結果評價表Tab. 3 Evaluation of classification results on BraTS2019 before optimization
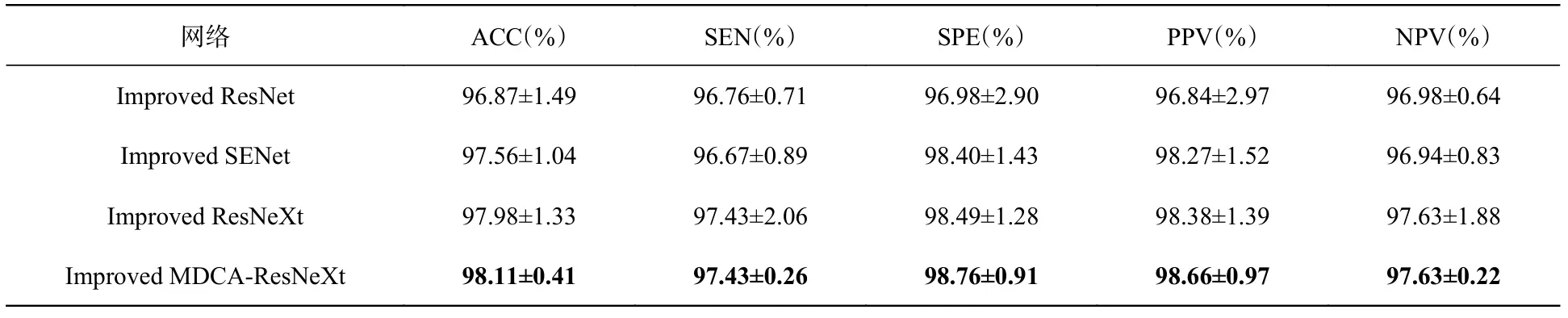
表4 優化后BraTS2017數據集的分類結果評價表Tab. 4 Evaluation of classification results on BraTS2017 after optimization

表5 優化后BraTS2019數據集的分類結果評價表Tab. 5 Evaluation of classification results on BraTS2019 after optimization
根據以上4個分類結果評價表可以得出以下結論:首先,本文提出的MDCA-ResNeXt網絡是以ResNeXt為主干網絡進行的改進,改進后的網絡能夠有效區分良惡性腦腫瘤,并且提高了網絡在不同分類任務的魯棒性;其次,本文采取3種優化策略的組合可以提高網絡的分類準確率和泛化能力。
3.4.3 其他先進方法的對比結果
為充分說明本文提出的基于Improved MDCA-ResNeXt網絡的腦腫瘤良惡性分類模型的性能,將本文方法與其他先進方法進行對比,對比結果如表6所示。
表6中,文獻[7]和文獻[8]為傳統機器學習的分類方式,文獻[19]、[15]、[16]和[17]為深度學習的分類方式。上述對比方法中大多是基于分割結果圖進行腫瘤分類的,而圖像分割是基于圖像像素點進行的0-1分類過程,對分割算法和分割模型的性能要求更高,并且分割結果會直接影響分類結果。除此之外,先分割后分類的方法,增加了分類過程中的不可控因素。基于此,本文提出的Improved MDCA-ResNeXt分類算法在腫瘤良惡性分類任務中更具有優勢,分類準確率更高。
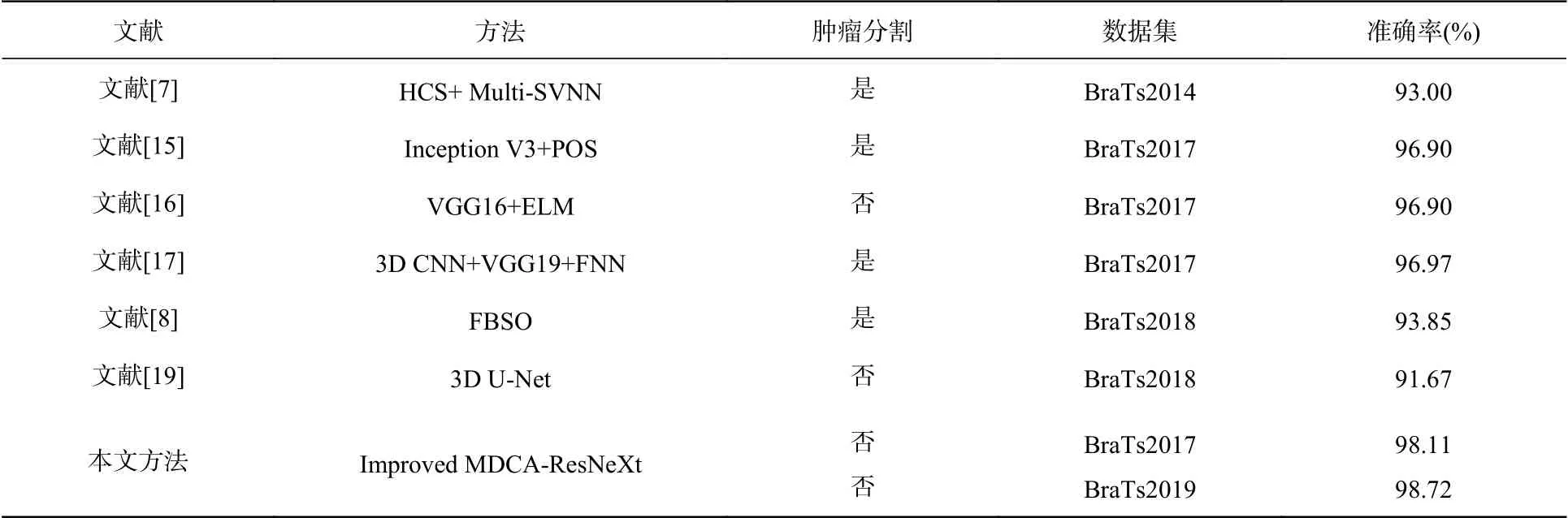
表6 先進方法分類結果對比表Tab. 6 Comparison of classification results of advanced methods
4 結 論
本文提出一種基于Improved MDCA-ResNeXt網絡的腦腫瘤良惡性分類方法,不僅能將原始圖像中細微的局部特征和全局特征相融合,保留HGG的腫瘤增強區的特征信息,還能將特征圖的特征通道重新排列,提高網絡對腫瘤區域的關注度,降低網絡對冗余特征的關注度;采用學習率的線性衰減策略、圖像標簽平滑策略以及基于醫學圖像的遷移學習策略的組合優化策略可提高網絡的學習能力和泛化性能。在BraTS2017和BraTS2019數據集上的實驗結果表明,本文方法相較經典網絡和其他先進方法的分類準確率、魯棒性有所增強,其中準確率分別達到 98.11%和98.72%。在未來的研究工作中需要進一步優化網絡結構,可以考慮引入新的技術,減少具有相似性的冗余特征對分類結果的影響和計算消耗,進一步提升分類準確率、降低運算時間。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46