基于Fisher Score 與最大信息系數混合模型的三電平逆變器故障特征選擇方法
2023-01-08 16:48:54任曉紅劉顯策韓向棟
電子設計工程 2023年1期
杜 磊,任曉紅,劉顯策,韓向棟,俞 嘯
(1.兗州煤業股份有限公司興隆莊煤礦,山東濟寧 273500;2.中國礦業大學物聯網(感知礦山)研究中心,江蘇 徐州 221008)
逆變器作為直流信號轉換為交流信號的關鍵器件,被廣泛應用于礦井提升機和皮帶變頻控制系統等電力控制裝置中[1]。多電平逆變器具有電壓輸出中的諧波失真較低、波形更接近正弦波、有效避免發生電位漂移并且對負載的影響較小等優點[2-3]。在工業領域中,中性點鉗位三電平逆變器經常被用到[4-5]。基于三電平輸出的開關狀態遵循單位電平跳變的原則,控制開關管的通斷可降低功率損耗[6]。絕緣柵雙極晶體管(Insulated Gate Bipolar Transistor,IGBT)是中性點鉗位型三電平逆變器中常用的電源開關,可在高電壓、高溫和高頻率下長時間導通和關斷[7-8]。
但若長時間處于過壓高溫狀態,逆變器IGBT 會出現故障,故障會影響到整個煤礦運行。因此,有效且及時的診斷IGBT 運行狀態尤其重要。
由于逆變器設備本身電路結構復雜、運行環境的復雜性以及多變性,逆變器IGBT 故障信號具有非平穩和非線性特點,導致逆變器的故障特征難以準確提取,進而影響故障診斷與識別的有效性[9-10]。工程上經常通過多角度提取反映逆變器系統各種運行狀態的多種類型特征信息,以提高故障診斷和故障識別的準確率。但在提取多類特征信息的同時可能會帶來特征維數增多以及特征之間冗余問題[11]。為了挖掘原始故障特征數據集中的關鍵特征和潛在信息,采用適當的特征選擇方法對逆變器功率管IGBT 多故障特征進行選擇,這對故障診斷更加重要。
特征選擇是以從原始特征集中剔除相關性弱的特征,進而篩選出一組最能表征有效信息的子特征集為目標[12-13]。根據特征子集的搜索策略,可以將特征選擇方法劃分為兩大類[14],即裝式方法(Wrappers)[15]和過濾式方法(Filters)[16]。這兩類方法是單一的特征選擇方法,遇到多故障特征選擇時,影響故障分類準確率。隨著智能算法在高維特征數據中的應用,混合特征選擇方法已慢慢被應用到特征選擇中[17]。這種混合特征選擇方法不僅可以提高分類準確率還能夠減少計算時間。
1 相關理論介紹
1.1 Fisher Score算法
Fisher Score 是對樣本故障特征進行評價的一種標準。其主要思想是在選擇故障特征子集時,選擇使得異類數據點間距離大,而同類別的數據點之間距離小的故障特征子集。
假設訓練樣本xk∈Rm,k=1,2,3…,多類之間的類間散度計算公式如式(1)所示:

針對多故障類型的重疊性和分布不均勻問題,改進Fisher Score 算法,其計算公式如式(2)所示:

式中,N為除去重復特征值的樣本總數,分母表示類內散度之和,nj為第j類的數據樣本數。
1.2 最大信息系數
采用Fisher Score 算法只能確定逆變器不同故障特征的重要度,但是,多故障特征子集中的冗余度以及特征與特征彼此之間的相關性無法確定。最大信息系數是一種基于信息論的方法,它不僅可以挖掘不同特征之間的線性和非線性關系,還可以度量特征之間的非函數關系;采用最大信息系數對逆變器功率管IGBT 故障特征之間的相關性進行表征與計算。
假設兩個隨機變量X={xi,i=1,2,3,…,n}和Y={yi,i=1,2,3,…,n},n為樣本數,互信息I(X∶Y):

式中,p(x)是X邊緣概率分布密度,p(y)是Y的邊緣概率分布密度,p(x,y)是兩個變量的聯合概率密度。
定義在X×Y網格的最大互信息值為max(I(X∶Y)),則最大信息系數計算公式如式(4)所示:

式中,B是x×y網格劃分上限值。
若n個樣本的特征集F={f1,f2,…,fk},其中,k為特征數,對于任意兩類特征fi和特征fj相關性為Mic(x,y),若Mic(x,y)值越大,則特征fi和特征fj之間的冗余性就越大。若Mic(x,y)為零,此時,特征fi和特征fj之間彼此相互獨立。
在此基礎上,定義冗余特征:對于特征集為F,特 征fi和特征fj的Fisher Score 值Fi>Fj,且Mic(x,y)>0.8,則特征fj是特征fi的冗余特征。
2 Fisher Score 與最大信息系數混合模型
為了能夠更好地選擇出最有效的敏感故障特征子集,建立了一種Fisher Score 與最大信息系數混合模型。該模型具體流程如圖1 所示。

圖1 Fisher Score與最大信息系數的混合模型流程
3 基于Fisher Score 與最大信息系數混合模型的特征選擇方法框架
所提出的基于Fisher Score 與最大信息系數混合模型的三電平逆變器故障特征選擇方法框架如圖2所示,特征選擇過程分為以下三個步驟。

圖2 基于Fisher Score與最大信息系數混合模型的特征選擇方法框架圖
步驟1:三相電流信號預處理,在希爾伯特黃變換(HHT)方法的基礎上,采用噪聲自適應完備總體平均經驗模態分解CEEMDAN(Complete EEMD with Adaptive Noise)方法分別對三相電流信號樣本數據集進行分解和重構,以去除電流信號中的噪聲信號。
步驟2:特征提取,采用Hilbert 變換,對三電平逆變器三相電流進行希爾伯特邊際譜和希爾伯特包絡譜變換,得到其對應的三個邊際譜和三個包絡譜;對于每個希爾伯特邊際譜,計算表1 中的前13 種統計特征,且計算三相電流Park 矢量變換后的模值和相角兩種特征。則得到41 維(13×3+2)特征集;對于每個希爾伯特包絡譜,計算表3 中前11 種統計參數,則得到33 維(11×3)特征集;對于每一個三相電流信號樣本,得到原始特征集維數74 維(11×3+13×3+2)。
步驟3:敏感特征選擇,對原始特征集進行Fisher Score 值計算,并根據值的大小按照降序進行排序,計算特征間的最大信息系數,進行二次排序調整,并采用隨機森林分類算法對排序調整后的特征集進行分類,根據隨機森林分類準確率篩選敏感故障特征子集。
4 實驗驗證與結果分析
4.1 實驗設置
基于Matlab/Simulink 環境下,搭建三電平逆變器電路原理仿真模型,實驗采用電感和電阻的不同組合來模擬負載變化,其負載組合參數設置如表1所示,負載組合設置了10 種電阻和電感組合類型,且這10 種組合代表10 種工況。在恒定的電壓頻率比下,采集電機在加速和勻速狀態下的三相電流數據,采集時間是4 s,頻率是10 kHz。通過仿真模型控制端模擬正常與故障共13 種狀態,且采集13 種狀態下的三相電流數據樣本,每種狀態下的電流信號劃分378 個周期,每個周期為一個樣本,10 種工況共有10×13×378 個樣本,且構建仿真原始數據集Case1(10×13×378 個樣本)。

表1 仿真數據采集參數設置
利用直流電源、NPC 三電平逆變器、示波器、電阻電感等器材搭建了NPC 三電平逆變器電流信號采集實驗臺。采用電阻與電感組合表示負載,實驗設置4 種負載類型,即4 種工況,如表2 所示。在電機為加速和勻速狀態下,采集三相電流信號,采集頻率仍設置為10 kHz,采集時長20 s,重復采集了5 次。通過實驗臺控制端采集正常狀態和12 種故障狀態下的三相電流數據,每一種狀態下的電流數據劃分378 個周期,將每個周期作為一個樣本,4 種工況下,共有19 656(13×378×4)個樣本,重復采集了數據5次,得到總樣本數是98 280(5×4×13×378)個,即將總樣本構建原始數據集Case2(5×4×13×378 個樣本),即Case2 表示實驗原始數據集。

表2 實驗數據采集參數設置
4.2 實驗結果分析
采用CEEMDAN 方法分別對仿真和實驗臺采集的三相電流信號樣本集進行分解和重構,以去除噪聲信號。逆變器三相電流經過CEEMDAN 分解得到10 個本征模態函數(IMF)分量。對于CEEMDAN 變換之后的IMF 分量中一般含有虛假分量,而虛假分量不僅不能反映信號特征信息,而且會干擾其他的IMF 分量,采用相關分析方法剔除虛假分量。根據IMF 分量與原始信號特征信息間的相關系數,判斷虛假IMF 分量,若相關系數小于0.2,則判斷為虛假IMF 分量。
CEEMDAN 分解出的10 個IMF 分量與特征相關系數對應關系如圖3所示。根據相關系數計算,后6階IMF 分量的相關系數小于0.2,屬于虛假IMF 分量,不能表征原始信號的信息特征,該實驗選擇前4 階IMF分量,并將其重構為CEEMDAN 分解之前信號。

圖3 IMF分量與信號特征相關系數對應關系
采用Hilbert 變換算法對前4 階IMF 分量重構之后的信號進行變換,得到三相電流對應的三個Hilbert 邊際譜和三個Hilbert 包絡譜;對于每個希爾伯特邊際譜,計算與表3 標題不符統計特征,且計算三相電流Park 矢量變換后的模值和相角兩種特征。則得到41維(13×3+2)特征集;對于每個希爾伯特包絡譜,計算表3 中前11 種統計參數,則得到33 維(11×3)特征集;綜上所述,對于每一個三相電流信號樣本,得到原始特征集的維數為74 維(11×3+13×3+2)。

表3 15種統計特征
首先,采用Fisher Score 計算方法評估特征指標重要度,并進行排序;再采用最大信息系數評價特征與特征之間相關度,并將相關度低的特征調整到最后;借助隨機森林算法的強大分類能力,采用隨機森林分類器篩選敏感特征子集。
為了驗證所提出的特征選擇方法具有更好的有效性和可靠性,開展了對比實驗,選擇仿真數據樣本數24 570×74 個樣本(Case3),實驗臺數據樣本數為63 960×74 個樣本(Case4)。故障類別數為13 種,特征數為74,選擇mRMR 算法和reliefF 算法與所提出的特征選擇方法(Fisher-MIC)進行對比實驗,采用隨機森林算法進行故障分類,根據故障分類準確率的高低判斷特征選擇算法的效果。不同特征選擇方法的特征選擇效果如圖4 和圖5 所示。
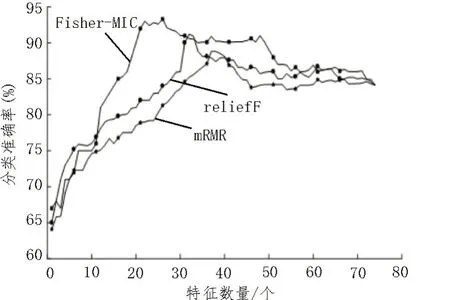
圖4 仿真數據集不同特征選擇方法的特征選擇效果圖

圖5 實驗數據集不同特征選擇方法的特征選擇效果圖
根據圖4 和圖5 可知,三種特征選擇方法在三電平逆變器仿真數據集和實驗數據集上的分類準確率整體都呈現先上升后下降的趨勢。三種方法篩選出的特征集,輸入分類器中,分類準確率不同。其結果如表4 和表5 所示。
根據表4 和表5 可知,對比Fisher-MIC、reliefF 和mRMR 三種特征選擇方法,對于Fisher-MIC 特征選擇方法,仿真數據和實驗數據測試分類準確率都比其他兩種特征選擇方法下的分類準確率高。仿真實驗和實驗臺實驗結果表明,Fisher-MIC 特征選擇方法相比其他兩種特征選擇方法有較好的效果,所選擇出的敏感特征子集能夠更好地反映逆變器功率管IGBT 相應故障狀態的特征信號。

表4 13種統計特征仿真數據集測試結果

表5 13種統計特征實驗數據集測試結果
5 結論
為了提高三電平逆變器故障識別準確率,提出了一種基于Fisher Score 與最大信息系數的混合模型的三電平逆變器特征選擇方法,該方法采用希爾伯特黃變換對三相電流信號進行時頻域變化,得到包絡譜和邊際譜,并將經過計算的統計特征集構建原始特征集;采用Fisher Score 方法對原始特征集進行相關故障特征重要度排序;且采用最大信息系數對特征之間的相關性進行評價,進而對特征排序結果進行調整;以故障分類準確率為評判依據,基于隨機森林算法對Fisher Score 與最大信息系數混合模型進行修正,進而實現敏感故障特征篩選。進行了仿真實驗和實驗臺實驗。實驗結果表明,所提出的方法在篩選有效的故障特征上效果明顯,與傳統的reliefF 和mRMR 特征選擇方法相比,所提出的特征選擇方法有利于逆變器故障診斷識別分類,且故障識別準確率分別提高了2.1%和1.3%。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
汽車維修與保養(2019年7期)2020-01-06 03:30:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年11期)2018-08-04 03:25:42
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
汽車維護與修理(2016年10期)2016-07-10 08:17:41
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
汽車維修與保養(2015年6期)2015-04-17 03:31:50
