電力業務流轉數據庫中分布式數據一致性算法
2023-01-08 16:49:00明哲,余蕓,甘杉
電子設計工程 2023年1期
明 哲,余 蕓,甘 杉
(南方電網數字電網研究院有限公司,廣東廣州 510000)
電力業務流轉數據庫中分布式數據的處理對電力業務的管理效率有較大的影響,傳統方法采用在數據庫中復制數據的方式完成電力業務流轉數據的處理,以此保證電力數據的一致性,但是該方式會增加電力系統的內存開銷,不僅降低業務流轉的速度,而且還加大了電力系統的存儲負荷[1-2]。
為了解決上述問題,該文設計了新型的電力業務流轉數據中分布式數據一致性算法,采用數據分層異步復制方式優化現有算法中的數據復制方式,提高電力業務流轉數據處理效率。
1 封鎖協議和解鎖協議
傳統的數據庫分布式數據一致性算法在應用時,數據復制和轉發過程中沒有設置相應的驗證行為,導致電力業務數據轉發時出現目標誤識或者不識的故障[3-4],為了解決以上問題,在算法中融入了兩個階段的協議,分別是對電力業務流轉數據的封鎖和解鎖協議。
在數據庫中設置協議可以避免一些不安全的行為,如部分隱藏的危險電力業務數據跟隨通過驗證的數據成功傳輸到數據庫中,對電力業務流轉數據的安全造成威脅。兩個協議具有唯一性,一個周期內的電力業務流轉數據轉發,只能申請一個封鎖協議,只有對此封鎖協議解鎖后,才可以重新申請數據封鎖協議,避免出現解鎖密鑰不匹配,電力業務自動銷毀的情況。具體的封鎖和解鎖協議與數據庫和電力業務流轉數據之間的關系如圖1所示。
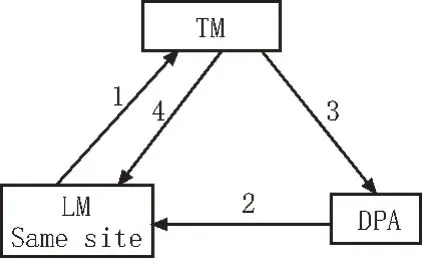
圖1 協議與數據庫和電力業務之間關系圖
其中,TM 表示電力業務流轉數據管理器;LM 表示接收數據庫;DPA 表示數據處理管理器[5]。
封鎖協議利用集中式封鎖技術完成部署,數據流轉過程中,由數據庫向電力系統內的鎖管理器申請一個封鎖空間,并獲取鎖空間權限。此操作完成后,利用鎖管理器發送的數據封鎖的辨識碼,并向封鎖字典獲取解鎖密鑰,但是此密鑰此時只秘密地存儲并轉發到解鎖協議中,封鎖協議不具有查看的權限[6-7]。然后獲取需要向數據庫中通信的電力業務流轉數據條,獲取后直接將數據條封鎖,封鎖數據條數量與業務數據流轉數量保持一致,禁止私自增加或者減少電力業務流轉數據的數量。最后釋放封鎖的數據流,目的是向解鎖協議和數據庫發送待通信通知[8-9]。
解鎖協議利用并發控制技術完成部署,解鎖流程為首先獲取電力業務流轉數據封鎖協議的封鎖空間序列號,然后對應序列號驗證此封鎖協議是否是正規的封鎖信息,如果不是,立即銷毀;如果是,則進行下一步操作。其次,獲取封鎖協議自帶的解鎖密鑰。獲取密鑰時,解鎖協議需攜帶封鎖釋放數據和解鎖密鑰。最后解密封鎖協議封裝的電力業務流轉數據,完成后釋放電力業務流轉發數據的鎖空間[10-12]。
2 分布式數據一致性分析
2.1 分布式數據一致性控制分析
電力業務流轉數據庫分布式數據一致性算法的目的是在不更改數據庫中主體數據的前提下,對電力業務流數據與數據庫中已存在的數據進行匹配,如果存在相同電力業務流轉數據,則對數據庫內的主體和副本數據進行更改,如果不存在,則直接存入即可[13]。算法必須記錄所有傳入數據庫內的電力業務流轉數據的轉發時間戳和RD 地址,為后期數據庫內電力信息的調用奠定基礎。算法的具體計算原理如圖2 所示。

圖2 一致性算法原理
電力業務流轉數據庫中數據一致性校驗的關鍵是使數據庫中不存在重復或冗余的電力業務流轉數據信息,分布式數據一致性算法判斷數據庫中是否存在相同電力業務流轉數據信息的過程,如下所示:

其中,ts(MD)表示數據庫中主體數據的時間戳信息;ts(RD) 表示數據庫中副本數據的時間戳信息;Update(RD) 表示封信副本信息的數據;B表示數據復制算法;Read(RD)表示讀取數據庫中副本數據信息[14]。
電力業務流轉數據庫中數據一致性算法在一致性校驗時,不僅校驗的是電力業務數據內容,而且還依次校驗了電力業務信息流中包含的分布式數據,如節點數量、屬性、目錄地址、RD 地址等數據,以此防止發生更新不相同的數據時造成數據丟失的情況。算法確定數據庫中數據一致性后,在執行算法時,必須先刪除數據庫中冗余數據的全部注冊信息的主參數和基本參數后,再存儲新數據。為了防止因為算法校驗錯誤,導致數據庫中數據丟失,數據庫中待刪除數據信息副本的所有參數會臨時存儲一段時間[15-16]。
數據庫中數據一致性算法的能耗計量公式如式(1)所示:

式(1)中,co表示電力業務流轉數據量;c1表示數據庫和電力傳輸業務流轉數據初始化的時間;X表示傳輸速率。
2.2 分布式數據分層復制分析
分布式數據分層復制操作的核心是分別處理數據庫中主本和副本的數據,一方面可以將電力業務分布式數據流存儲到數據庫中,另一方面又可以備份數據庫中已經更新的分布式數據,保障數據庫內信息的安全。
該文采用的分布式數據分層復制操作的指導算法為Directory 協議,此協議操作簡單,可以快捷完成電力業務流轉數據復制的工作。數據信息復制的工作主要包括讀取和寫入兩個操作行為,當數據庫中不存在重復的分布式數據時,此協議只需要讀取通信的數據,讀取后判斷此業務流轉數據信息是否與數據庫中分布式數據相同,如果不存在相應的數據,直接寫入到數據庫中即可。如果數據庫存在分布式數據,則協議首先需要對數據庫中原始的分布式數據進行讀取和刪除操作,再寫入轉發的電力業務流轉數據,完成分布式電力業務的復制。
3 實驗分析
通過以上的論述和分析,完成了電力業務流轉數據庫中分布式數據一致性算法的設計。為了檢驗算法的可行性,設計了對比實驗。
3.1 實驗準備
測試前需要提前準備一個存在大量數據業務的電力系統、獨立的30 條電力業務數據條以及一個內存空間足夠大并且存有數據的數據庫,作為測試樣本。將文獻[3]基于信息分散算法的分布式數據實時存儲方法、文獻[4]基于一致性算法的電力系統分布式經濟調度方法以及該文方法三個算法分別隸屬于三臺計算機。計算機內錄入數據庫,連接電力系統,開始實驗測試,記錄開始時間。
實驗測試的流程是同時啟動三臺計算機,并且同時向三臺算法隸屬的電力系統部署和發送需要傳輸的電力業務流轉數據信息。當三個系統全部完成電力業務流轉數據庫操作后,保存所有算法工作產生的數據記錄,關閉系統、斷開數據庫連接、關閉計算機,結束實驗,進行實驗結果分析。
3.2 能耗和經濟開銷分析
實驗結束后,根據計算反饋的基本信息對比三個算法通信過程中的能耗和經濟開銷,如圖3 所示。

圖3 能耗和經濟開銷實驗圖
圖3 中,樣本1-5 中均包含了300 個傳輸數據。由圖3 可知,文獻[3]算法在整個完成任務周期內能耗開銷和經濟開銷都是最高的,該文設計算法的開銷是最低的。因為在電力業務流轉數據庫操作中一定會存在能耗開銷和經濟開銷,設計算法降低了隸屬系統的能耗和經濟開銷,保證電力業務傳輸的利益。
3.3 收斂速度分析
分析數據庫接收500 個電力業務流轉數據后,得到三個算法傳輸電力業務流轉數據的收斂速度,結果如圖4 所示。
根據圖4 可知,三個算法傳輸電力業務流轉數據的收斂時間均為7 s,但是圖中三個算法最終匯聚的點不同,此匯聚點表示算法一致性收斂的速率。其中,該文設計算法的收斂速度最快,文獻[3]算法的收斂速度最慢。因此,根據三個算法完成任務的時間和電力業務流轉數據收斂速度,可以證明該文設計的電力業務流轉數據庫中數據一致性算法具有最佳收斂特點,并且工作效率優于現有的一致性算法。

圖4 不同算法一致性收斂速度實驗圖
3.4 響應延遲時間分析
關于算法的響應速率實驗結果,如圖5 所示。

圖5 不同算法響應延遲時間示意圖
圖5 展示的是三個算法在向數據庫中傳輸電力業務流轉數據的響應延遲情況,由圖可知,三種算法在響應過程中,隨著傳輸電力業務流轉數據量的增加,算法的響應延遲效果越明顯。根據電力業務管理規定,業務流轉數據庫的響應延遲時間不大于2 s,即為系統處于正常運行狀態。傳輸10×103個電力業務流轉數據時,文獻[3]算法和該文設計算法的響應延遲時間均在2 s 以內,該文設計算法延遲時間更低,在0.5 s 左右,文獻[4]算法達到3.9 s,無法正常運行。但是在經歷了20×103個電力業務流轉數據轉發時,文獻[3]算法的響應延遲已經達到了2.7 s,該文設計的算法響應延遲持續為0.5 s 左右。在完成所有的電力業務流轉發到數據庫中的任務后,該文設計算法的響應延遲時間最高為1 s,但是兩個對比算法的響應延遲時間持續上升。由此可以證明設計的電力業務流轉數據庫中數據一致性算法的響應延遲達到了認證標準,具有一定的可用性。
3.5 誤傳率分析
最后對數據庫中接收到的數據進行檢驗,查看所有算法轉發的30 條電力業務數據成功轉發的條數,為保證實驗的嚴謹性,將誤傳率實驗次數設置為8 次,由此得到數據轉發的誤傳率,得到的誤傳率實驗結果如圖6 所示。

圖6 誤傳率實驗結果
由圖6 可知,文獻[4]算法在通信電力業務數據時,誤傳率最高;文獻[3]算法對應數據庫次之,且誤傳率均高于該文算法,該文設計算法誤傳率最高為0.10%。
綜合上述實驗結果可知,該文設計的電力業務流轉數據庫中數據一致性算法具有較高的通信收斂速度,傳輸的響應延遲和誤傳率均符合應用標準。
4 結束語
電力業務流轉數據庫中分布式數據一致性算法不僅可以加強電力領域相關業務的管控,而且提高了電力業務的處理效率。集中式控制和并發式控制封鎖協議涵蓋了目前電力業務流轉數據一致性算法驗證的多種狀態,避免電力業務流轉數據庫中出現格式單一匹配錯誤、數據多次轉發情況的發生。在該文電力業務流轉數據庫中分布式數據一致性算法分析的基礎上,可以進一步對一致性算法進行優化或者更改,應用在電力業務流的其他工作程序中,達到電力業務處理流程節能、高效的效果。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
公民與法治(2022年5期)2022-07-29 00:47:28
教學考試(高考物理)(2021年5期)2021-11-08 10:31:22
中醫眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
財經(2017年2期)2017-03-10 14:35:35
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
