融合遞增詞匯選擇的深度學習中文輸入法
2023-01-09 04:09:28任華健郝秀蘭徐穩靜
電信科學 2022年12期
任華健,郝秀蘭,徐穩靜
融合遞增詞匯選擇的深度學習中文輸入法
任華健,郝秀蘭,徐穩靜
(湖州師范學院浙江省現代農業資源智慧管理與應用研究重點實驗室,浙江 湖州 313000)
輸入法的核心任務是將用戶輸入的按鍵序列轉化為漢字序列。應用深度學習算法的輸入法在學習長距離依賴和解決數據稀疏問題方面存在優勢,然而現有方法仍存在兩方面問題,一是采用的拼音切分與轉換分離的結構導致了誤差傳播,二是模型復雜難以滿足輸入法對實時性的需求。針對上述不足提出了一種融合了遞增詞匯選擇算法的深度學習的輸入法模型并對比了多種softmax優化方法。在人民日報數據和中文維基百科數據上進行的實驗表明,該模型的轉換準確率相較當前最高性能提升了15%,融合遞增詞匯選擇算法使模型在不損失轉換精度的同時速度提升了130倍。
中文輸入法;長短期記憶;詞匯選擇
0 引言
英語等拉丁語系用戶可以通過計算機鍵盤直接輸入想要的詞句,然而由于漢字總量十分龐大,直接輸入并不現實,中文用戶需要借助輸入法進行漢字輸入。輸入法的核心任務是將用戶輸入的按鍵序列轉化為相應的漢字序列。理想情況下,輸入法的轉換結果應與用戶期望輸入的漢字序列相同。輸入法的轉換準確率和轉換速度直接影響著輸入效率和用戶體驗。
輸入法內核的轉換任務與語音識別、機器翻譯相似,可以看作一項序列解碼任務。傳統的統計機器學習算法采用元語法語言模型[1]計算詞網格中最優路徑的概率。該模型需要通過增大值學習語料中的長距離特征,但過大的值會帶來數據稀疏問題,在實踐中普遍采用三元語法語言模型。相較于傳統模型,基于深度學習算法的語言模型具有能夠在學習長距離特征的同時不易受數據稀疏問題制約的特點,因此獲得了廣泛研究。在機器翻譯[2]、語音識別[3]、情感分析[4-5]等自然語言處理任務中,基于深度學習算法的模型取得了更高的性能。近幾年來張量處理單元[6](tensor processing unit,TPU)等硬件方面的研究進展為深度學習模型的應用提供了更加廣闊的前景。
然而基于深度學習的模型仍然難以直接應用在輸入法的轉換任務中。與語音識別和機器翻譯多由云服務器提供不同,輸入法需要運行在多樣化的用戶設備上并提供實時交互服務。即使有很多輸入法廠商提供了云候選,但是其轉換結果因為時延較高,往往只能作為次后選。一個能夠適用于輸入法轉換任務的深度學習模型需要滿足以下兩點要求:能夠為每次用戶的按鍵輸入提供低時延的轉換結果;能夠在轉換完成后允許用戶對候選結果進行編輯。
首先,輸入法轉換任務的輸入序列是逐個獲得的,并且需要在每一次收到按鍵信息后立即返回詞網格中的最優路徑。現存的優化手段[7-8]普遍著眼于提升對序列進行批處理時的速度。文獻[9]的方法融合了前綴樹,但是無法保證在最壞情況下運算時間仍然能夠滿足實時應用的需求。其次,輸入法在給出轉換結果后,允許用戶以手動選擇候選詞的方式對詞網格進行編輯。這一特點限制了多種端到端模型[10-11]的使用,因為它們都沒有提供允許用戶編輯部分轉換結果的方法。
為滿足輸入法轉換任務的要求,本文提出了一個新的基于深度學習算法的輸入法模型。在該模型中,用戶輸入首先被切分成拼音音節,通過維特比解碼器構造出相應的詞網格。然后通過融合遞增詞匯選擇的長短期記憶[12](long short-term memory,LSTM)語言模型計算最優路徑的概率。該語言模型在解碼過程的第步構建一個輸入法總詞匯表的子集V。由于V中詞匯的數量通常在總詞匯量的1%以下,僅在V上執行softmax運算,模型消耗的時間相較基線模型有了大幅降低。
1 相關工作
早期相關研究常采用基于統計語言模型[13]或統計機器翻譯[14]的方法。近年來出現了采用深度學習算法的研究。文獻[15]將輸入法轉換任務看作機器翻譯,使用了一個融合注意力機制的編碼器-解碼器模型完成音字轉換任務,并使用信息檢索技術對模型的聯想輸入功能進行了增強。文獻[16]在基于LSTM的編碼器-解碼器模型基礎上,通過在線詞匯更新算法擴充輸入法詞匯表,提高了轉換準確率。文獻[17]通過在輸入法中增加輸入上下文的編碼模塊,提高了模型在簡拼模式下的表現。文獻[18]使用一個字符級中文預訓練語言模型作為輸入法核心完成音字轉換,并獲得了當前最高性能(state-of-the-art,SOTA),同時研究了基于預訓練語言模型的輸入法在簡拼場景下的表現。現有模型普遍比較復雜,需要在GPU的支持下才能運行,文獻[15]則是將輸入法轉換任務和聯想功能等功能全部架設在云服務器上。本文工作的重點是在計算資源有限的用戶設備上實現基于神經網絡的實時輸入法。
具有大量詞匯的softmax層是神經網絡語言模型中計算量最大的操作,目前針對softmax瓶頸的解決方法主要有兩種。其一是對softmax運算進行近似。文獻[19]提出的差異化softmax(differentiated softmax)及文獻[20]提出的自適應softmax(adaptive softmax)將語言模型中頻率較低的長尾詞匯按詞頻進行分割,并減少其嵌入向量維度,從而降低softmax運算的計算量。對于預測任務,其前個候選的重要性較高,文獻[21]提出的奇異值分解softmax(singular value decomposition softmax,SVD-softmax)對權重矩陣進行奇異值分解,并使用得到的低秩矩陣進行softmax運算。在解碼過程中,如果目標詞匯有一個確定的范圍,則可以使用結構化輸出層[22]避免計算所有詞匯的概率分布。文獻[23]提出了一種快速詞圖解碼方法,該方法可以在對數時間復雜度內找到神經網絡語言模型前個最有可能的預測。
另一種解決softmax瓶頸的方法是對推理過程的詞匯進行操作,與機器翻譯任務中的方法相似。即先針對待翻譯的句子構建一個可能使用的總詞匯表的子集,然后在這一子集上進行softmax運算[24-25]。文獻[26]提出了一種針對日語輸入法的詞匯選擇方法,降低了模型推理時間。基于單字的模型,如單字循環神經網絡[27-28](recurrent neural network,RNN)語言模型相較于基于詞語的模型可以大幅減少模型中的詞匯量,然而漢字的數量仍然不是一個小數目,并且這種方法無法利用詞語的信息,所以會導致模型準確率大幅下降。
受上述研究啟發,本文提出一種融合遞增詞匯選擇方法的深度學習輸入法模型,該模型使用詞網格進行解碼,可以在用戶輸入過程中遞增地構建所需詞匯表,提升了轉換準確率并降低了轉換任務中序列解碼所需的時間。
2 模型建立
2.1 深度學習輸入法模型
本文提出的長短期記憶語言模型輸入法模型總體架構如圖1所示。考慮模型的實時性目標,本文采用一個LSTM語言模型計算詞網格解碼器中不同句子的路徑概率。由于序列到序列[10]等模型不能動態遞增地生成轉換結果,本文沒有采用這類模型。
在音字轉換任務中,用戶按鍵輸入首先被切分為拼音音節序列。對第步輸入產生的音節序列(1,···,x),用式(1)查找字典中滿足該序列所有后綴的詞語組成詞網格。
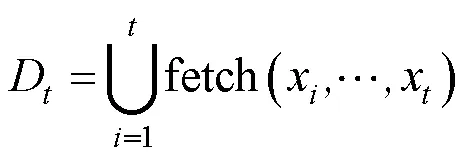
其中,fetch(·)函數從輸入法總詞匯表中查找并返回所有符合部分序列(x,···,x)的詞匯。例如,對于音節序列“zai hu zhou”,產生的子詞匯集D包含所有匹配“zai hu zhou”“hu zhou”和“zhou”的結果。
圖1 長短期記憶語言模型輸入法模型總體架構
對于詞匯表子集中的任意詞語w∈D,為了構造一個以w結尾的候選π,之前步驟生成的部分候選π被用作計算(w|π)的上下文,其中,是w的長度,只有字符數量匹配的部分候選才會被連接成一個完整的候選。最后,使用一個束寬度為的維特比解碼器對候選進行排序。
在維特比解碼器中,使用LSTM語言模型計算(w|π)。對于每一個輸入序列,音字轉換任務需要進行步LSTM運算,其中是詞匯表中詞匯的數量,是音節序列的長度,輸入法主要的計算量集中于LSTM單元和softmax的矩陣運算。假設一個輸入法的詞匯總量為10萬,使用一個嵌入向量維度和隱藏維度均為512的LSTM語言模型,以矩陣中的乘法為基準操作估計。LSTM單元中有4處矩陣乘法,每處為兩個512維向量與512維權重方陣相乘,為操作數量的高階項,總計512×512×2×4次乘法操作,數量約為200萬。在softmax層,需要將512維向量投影成10萬維以計算每個詞匯的概率,為操作數量的高階項,總計512×100 000次乘法操作,數量約為5 000萬,占比為51 200 000/53 200 000,為總量的96%以上。對于應用于中文輸入法的擁有大量詞匯的語言模型而言,其時間效率瓶頸在于softmax操作中的大量矩陣運算。
2.2 遞增詞匯選擇模型
為了降低解碼過程中softmax的運算量,本文使用遞增詞匯選擇算法改進了LSTM基線模型,如算法1所示。
算法1 遞增詞匯選擇
初始化:束寬度,候選字典[],采樣詞匯V,當前時間步
其中,是存儲每一步最優候選及其LSTM隱藏狀態的字典。定義[·]為某一特定時間步用于獲取當前最優候選的查找操作。的初始內容為上一次音字轉換任務結果及其LSTM隱藏狀態,第一次轉換任務時為空。
在第步,接收到一個新的拼音音節x時,算法構造一個相應的詞匯表V,如式(2)所示,V中覆蓋了所有到第步為止可能出現的詞語。
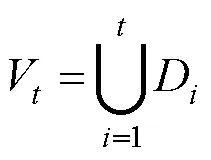
對候選(π,w)進行排序需要計算概率(w|π),而該概率已經在[]計算過并存儲在字典中了。然而,因為V的構建是遞增的,所以在之前步驟計算的概率分布中可能并沒有包含w。所以,為了計算[],需要修復之前概率分布計算中缺失的詞匯。可以通過式(3)修正第步的概率。
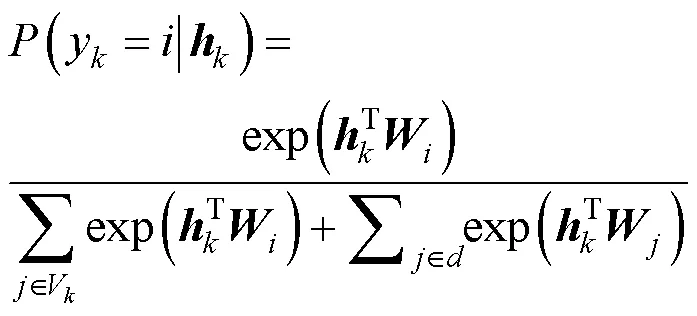
其中,是輸出層的權重矩陣,是對應候選π的LSTM隱藏狀態,是詞匯集V和V的差集。在當前第步向詞網格中新增中的詞匯后,導致與之前步驟進行softmax運算時的分母不一致,所以該步在之前softmax結果的分母中加入新增詞匯對應的輸出單元的值,即分母中的第二項,可以保持各步涉及詞匯進行softmax概率計算時的分母相同。因為詞網格解碼器中的每一條路徑都有不同的缺失詞匯,所以先取這些詞匯的并集fix,再重新計算所有路徑的概率。因為在一次輸入前幾步的詞匯集比較小,所以引入從整體詞匯表中采樣出的一個特定子集V。后續實驗中對比了兩種不同采樣方式的效果:其一是頂端采樣,即從總詞匯表中選出詞頻最高的若干詞作為V;其二是均勻采樣,即從總詞匯表中隨機選出若干詞匯作為V。當僅使用V時相當于去掉了softmax分母中的部分項,此時會導致概率偏大,將采樣出的詞匯集與之合并,同時使用V和V,使詞語的概率更加接近原始概率。計算結束后,[]中最優的個候選將會作為輸入法音字轉換任務的結果返回給用戶。
3 實驗與分析
3.1 數據集和評價標準
為了驗證模型的效果,本文分別在兩個不同的中文數據集上進行了實驗。
(1)人民日報實體數據集。該數據集語料提取自1992—1998年的人民日報新聞內容,是中文輸入法研究中常用的數據集[14]。其中,訓練集包含了504萬個最大輸入單元,測試集包含2 000個最大輸入單元。最大輸入單元的定義為句子中最長連續漢字序列[15]。
(2)中文維基百科數據集。由于人民日報數據集語料內容較為陳舊,數據量也相對較小,本文選擇在中文維基百科數據集上完成模型推理時間的實驗。該數據集語料為截至2022年1月1日維基百科所有中文詞條內容。原始語料為9.58 GB,預處理時先將句子切分成最大輸入單元后再進行分詞和標注拼音形成漢字-拼音平行語料。數據按照7:2:1的比例劃分為訓練集、驗證集和測試集,其中訓練集包含6 660萬個最大輸入單元,驗證集包含1 902萬個最大輸入單元,測試集包含951萬個最大輸入單元。
本文使用了輸入法研究中[15-18]普遍采用的“TopAccuracy”作為評價指標,這一指標表示在輸入法提供的前個候選中用戶期待輸入的漢字序列的命中率,其計算式如下。
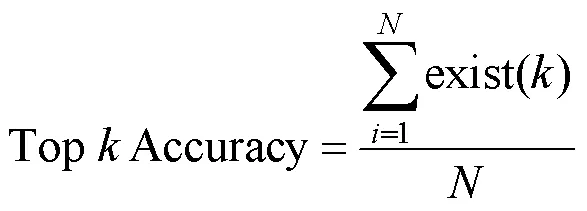
其中,exist(·)為判斷前個候選中是否存在期待輸入漢字序列的函數,當前個候選中存在期待的候選時返回值為1,否則為0;為測試集數量。
3.2 實驗設置
實驗中使用TensorFlow實現模型,訓練使用的GPU型號為NVIDIA Tesla V-100。為防止模型過擬合,引入了丟棄機制,參數值為0.9。模型使用Adam優化器,學習率固定為0.001。對于所有實驗,這些參數都是相同的。
在人民日報數據集上進行實驗時,選擇頻率最高的前5萬詞作為輸入法詞匯表,與文獻[16]中的對比模型保持一致,這些詞匯覆蓋了語料內容的99%。詞匯表中的詞匯按照頻率排列,高頻詞在前。由于詞匯量小,訓練時批處理大小設置為2 048。
在中文維基百科數據集上進行實驗時,先使用jieba分詞工具對語料進行分詞和標注拼音。參考常見的開源拼音輸入法的詞匯數量,sunpinyin約為8.4萬、libpinyin約為11.1萬、rime約為9.9萬。同時,自歸一化模型在不同詞匯量下的表現曲線如圖2所示,更大的詞匯量可以帶來更高的準確率,但是其邊際收益是遞減的。
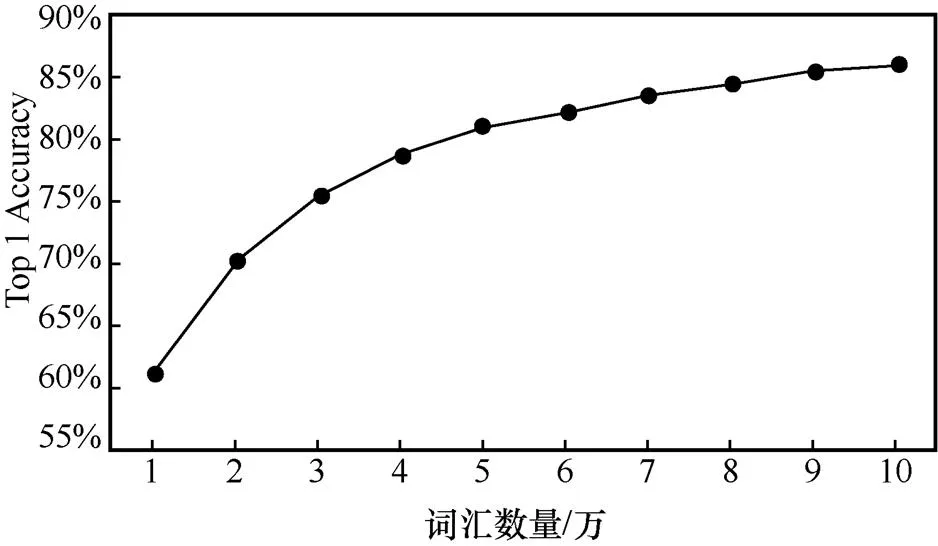
圖2 自歸一化模型在不同詞匯量下的表現曲線
實驗中依照上述經驗值,選擇頻率最高的前10萬詞作為輸入法詞匯表,這些詞匯覆蓋了語料內容的96%,詞匯數量作為受控變量在不同各實驗中保持一致。文獻[18]使用分類語料對按照領域信息劃分詞匯表的方法進行了研究,本文計劃將這一課題作為未來的研究方向之一。詞匯表同樣按照詞頻降序排列。訓練批處理大小為1 024。由于劃分了驗證集,所以在訓練中使用了早停策略防止過擬合,當驗證集上的語言模型困惑度連續兩輪不再下降時將提前停止訓練。困惑度計算式如下。
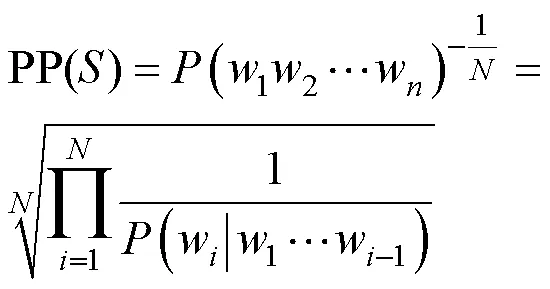
其中,PP是困惑度,是語料,w是其中第個詞語,是語料中詞語總數。困惑度能夠反映語言模型對數據的擬合能力,一般困惑度低的模型能夠在推理任務中獲得較高的準確率。訓練模型時使用困惑度的原因在于困惑度是可微的,而準確率是不可微的。在對比模型表現時使用準確率這一指標可以使結果更加直觀。
在GPU上完成訓練后,將模型參數導出至文件,供詞網格解碼器在解碼過程中使用。輸入法的解碼實驗在Intel(R) Xeon(R) E5-2650 v3上完成,模型使用numpy實現,其結構與TensorFlow模型相同。
3.3 轉換準確率
輸入法轉換準確率對比結果見表1,實驗將本文模型與如下基線模型進行了對比。
(1)三元語法語言模型輸入法。該模型為開源輸入法中廣泛使用的語言模型,使用開源工具包斯坦福研究院語言建模工具包[1](Stanford research institute language modeling toolkit,SRILM)進行訓練,平滑方法使用改良的Kneser-Ney算法[29-30]。為了獲得更高的轉換準確率,沒有設置截止頻率或對模型進行剪枝。
(2)谷歌拼音輸入法。谷歌拼音輸入法是一個提供了調試接口的商業輸入法。
(3)在線詞匯更新音字轉換(online updated vocabulary pinyin to character,Online P2C)。該模型為文獻[16]在2019年提出的方法。模型使用一個帶有注意力機制的編碼器―解碼器結構完成轉換任務,并使用在線詞匯更新算法對其進行了增強。
(4)生成式預訓練音字轉換(generative pre-training pinyin to character,GPT P2C)。該模型為文獻[18]在2022年提出的方法。模型使用一個字符級GPT輸入800 GB語料在32個NVIDIA Tesla V-100上訓練完成,并且使用拼音嵌入對模型進行了增強。
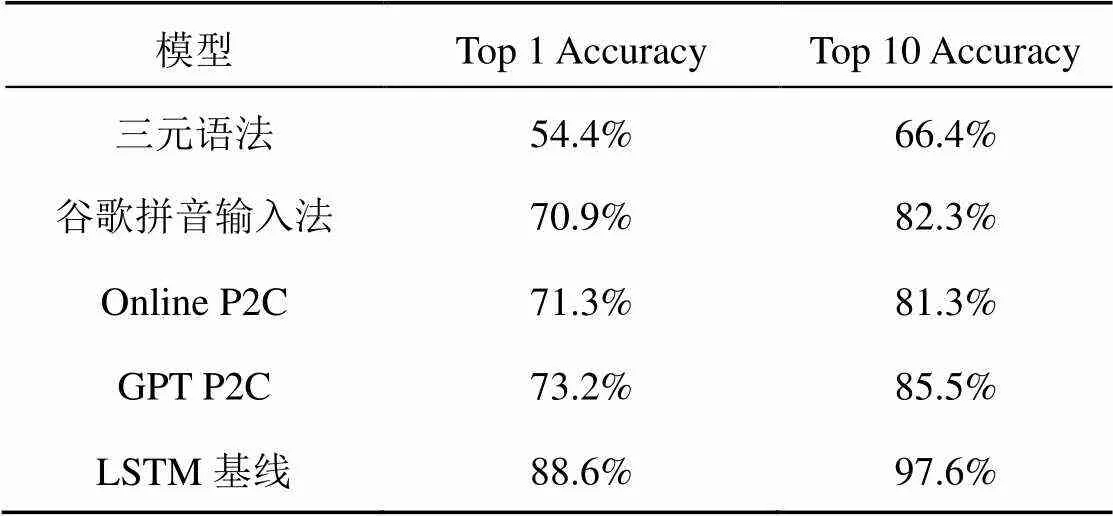
表1 輸入法轉換準確率對比結果
本文LSTM模型詞向量嵌入維度和隱藏維度均為512,并使用文獻[31]中的方法對輸入和輸出的詞向量進行了綁定,這一方法可以節約存儲空間且幾乎不造成精度損失。
由實驗結果可知,本文模型在Top 1 Accuracy上相比GPT P2C提升了15.4%,取得了新的最高性能。這表明了本文方法在提升轉換準確率方面的有效性。
3.4 模型運行時間
本節使用上一節LSTM模型作為基線,對比了多種加速方法的效果。本文僅計算了參與語言模型概率運算的組件的執行速度,其中包含LSTM層和softmax層的運算時間。實驗中,在LSTM單元和softmax單元前后分別插入計時點記錄單次運算時間,所有推理任務結束后求平均值作為單次LSTM和softmax運算的運行時間,單步時間為兩者相加之和。構造詞網格的組件等則沒有被包含進來,一方面因為這些組件對于不同模型是共用的,另一方面它們的具體實現對運行時間影響很大,不具有參考價值。另外,文獻[16]和文獻[18]中的兩個深度學習模型由于復雜度高,需要GPU支持運算,強行轉移到CPU上進行推理任務帶來的時間消耗是實際應用場景下無法承受的,因此沒有參與對比。
單步轉換時延對于需要滿足用戶實時輸入需求的輸入法而言是十分重要的,表2對比了每一步收到按鍵信息之后的平均解碼時間。解碼整個輸入拼音序列的時間消耗與解碼步數(拼音字母數量)成正比。模型運行時間對比見表2,同時單獨提供了softmax的運算時間以供對比。
由表2可以看出,本文提出的融合遞增詞匯選擇模型的softmax運算速度約是LSTM基線模型的130倍。輸入法的整個詞匯表中含有10萬個詞匯,而實驗中詞網格解碼器使用到的詞匯只有幾百個,對上述實驗詞網格解碼器中的詞匯數量進行統計,僅有188個句子的詞匯數量超過了總詞匯量的1%,約占實驗中所有句子的2%,其中最多的一句詞網格包含了2 302詞。遞增詞匯選擇模型只需要3.2 ms處理一個新加入序列的按鍵信息。這樣的解碼速度可以在計算資源有限的用戶終端設備上滿足實時交互需求。
表2中還對比了遞增詞匯選擇的各種采樣方法。可以看出,對總詞匯集進行采樣可以縮小與基線模型之間的準確率差距。在實驗中,頂部采樣和均勻采樣的詞匯數量均設置為500詞。
另外,還可以使用自歸一化[32]作為softmax近似。原始softmax的對數概率計算式為:
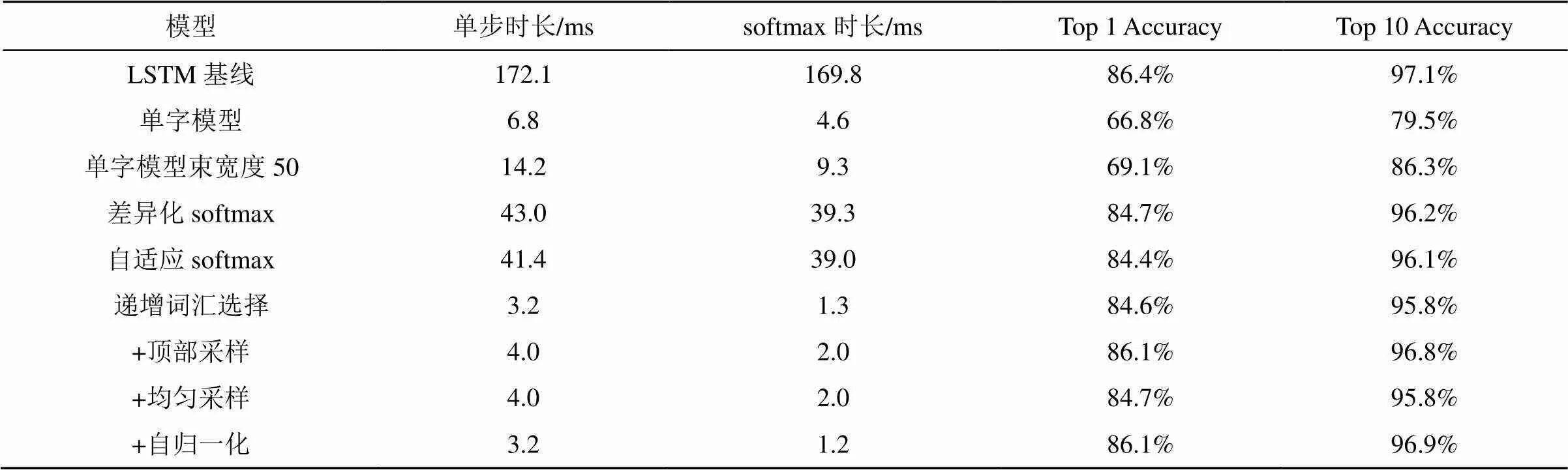
表2 模型運行時間對比
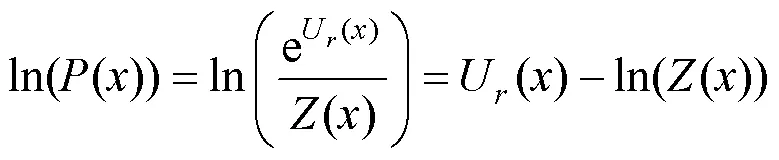
其中,
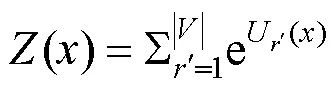
其中,是詞匯,是輸出單元的值,是當前詞匯序號。自歸一化通過顯式地令分母盡量接近1簡化softmax運算。因此需要在訓練過程的目標函數中加入額外的歸一化項,如式(8)所示。
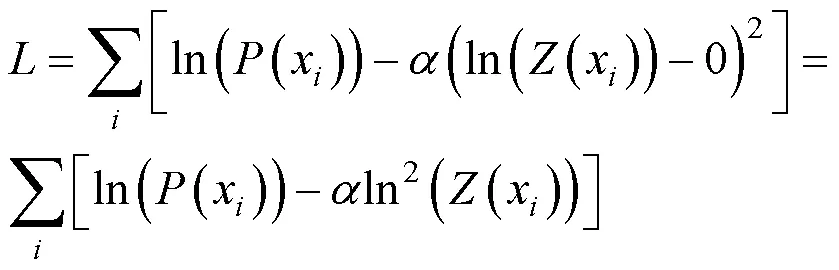
其中,是自歸一化權重,實驗中設置為0.1。在使用自歸一化時,為了保證網絡在初始時就是自歸一的,輸出層的初始偏置設置為ln(1)。在解碼過程中,直接使用U()代替ln((x))。
差異化softmax和自適應softmax可以降低超過一半的softmax運算時間,然而由于輸入法詞匯量巨大,這些方法對速度提升有限。
對于單字模型,實驗使用了一個嵌入向量維度和隱藏狀態向量維度均為512的LSTM語言模型。該模型將輸入法詞匯量從10萬降低到了5 000,然而這一數量仍然會帶來不小的開銷。在轉換任務中,單字模型的準確率損失較大,需要采用更大的束寬度提高轉換準確率,實驗中大的束寬度設置為50。
遞增詞匯選擇算法中用于修正詞匯表的時間由于依賴具體實現沒有給出,而且在實際應用場景中,用戶并不會一次性輸入一個完整的句子而是分成多個片段輸入,這些時間與softmax運算消耗的時間相比是很小的。
4 結束語
本文提出了一種融合遞增詞匯選擇的深度學習輸入法模型。相較于傳統元語法模型和其他深度學習輸入法,該模型能夠提供更高的轉換準確率;相較于未作改進的基線模型,該模型能夠在不損失轉換準確率的同時縮短softmax運算所需的時間。本文在真實中文數據集上進行了實驗,實驗結果表明,該模型能夠滿足輸入法的實時交互需求。后續筆者將在其他數據集和其他中文輸入方法上對本文模型做進一步測試和增強。
[1] STOLCKE A. SRILM - an extensible language modeling toolkit[C]//Proceedings of 7th International Conference on Spoken Language Processing (ICSLP 2002). ISCA: ISCA, 2002: 901-904.
[2] XIAO Y L, LIU L M, HUANG G P, et al. BiTIIMT: a bilingual text-infilling method for interactive machine translation[C]//Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA, USA: Association for Computational Linguistics, 2022: 1958-1969.
[3] PARASKEVOPOULOS G, PARTHASARATHY S, KHARE A, et al. Multimodal and multiresolution speech recognition with transformers[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA, USA: Association for Computational Linguistics, 2020: 2381-2387.
[4] DING Z X, XIA R, YU J F. End-to-end emotion-cause pair extraction based on sliding window multi-label learning[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Stroudsburg, PA, USA: Association for Computational Linguistics, 2020: 3574-3583.
[5] DING Z X, XIA R, YU J F. ECPE-2D: emotion-cause pair extraction based on joint two-dimensional representation, interaction and prediction[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA, USA: Association for Computational Linguistics, 2020: 3161-3170.
[6] PANDEY P, BASU P, CHAKRABORTY K, et al. GreenTPU: improving timing error resilience of a near-threshold tensor processing unit[C]//Proceedings of DAC '19: Proceedings of the 56th Annual Design Automation Conference. [S.l:s.n.], 2019. 2019: 1-6.
[7] LIU X Y, CHEN X, WANG Y Q, et al. Two efficient lattice rescoring methods using recurrent neural network language models[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2016, 24(8): 1438-1449.
[8] LEE K, PARK C, KIM N, et al. Accelerating recurrent neural network language model based online speech recognition system[C]//Proceedings of 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE Press, 2018: 5904-5908.
[9] CHEN X, LIU X Y, WANG Y Q, et al. Efficient training and evaluation of recurrent neural network language models for automatic speech recognition[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2016, 24(11): 2146-2157.
[10] CHO K, VAN MERRIENBOER B, GULCEHRE C, et al. Learning phrase representations using RNN encoder–decoder for statistical machine translation[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Stroudsburg, PA, USA: Association for Computational Linguistics, 2014: 1724-1734.
[11] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in Neural Information Processing Systems, 2017, 22(7): 139-147.
[12] HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780.
[13] CHEN Z, LEE K F. A new statistical approach to Chinese Pinyin input[C]//Proceedings of the 38th Annual Meeting on Association for Computational Linguistics - ACL '00. Morristown, NJ, USA: Association for Computational Linguistics, 2000: 241-247.
[14] Yang S, Zhao H, Lu B. A machine translation approach for Chinese whole-sentence Pinyin-to-character conversion[C]//Proceed ings of the 26th Pacific Asia Conference on Language, Information, and Computation. [S.l.:s.n.], 2012: 333-342.
[15] HUANG Y F, LI Z C, ZHANG Z S, et al. Moon IME: neural-based Chinese pinyin aided input method with customizable association[C]//Proceedings of ACL 2018, System Demonstrations. Stroudsburg, PA, USA: Association for Computational Linguistics, 2018: 140-145.
[16] ZHANG Z S, HUANG Y F, ZHAO H. Open vocabulary learning for neural Chinese pinyin IME[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA, USA: Association for Computational Linguistics, 2019: 1584-1594.
[17] HUANG Y F, ZHAO H. Chinese pinyin aided IME, input what You have not keystroked yet[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA, USA: Association for Computational Linguistics, 2018: 2923-2929.
[18] TAN M H, DAI Y, TANG D Y, et al. Exploring and adapting Chinese GPT to pinyin input method[C]//Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA, USA: Association for Computational Linguistics, 2022: 1899-1909.
[19] CHEN W L, GRANGIER D, AULI M. Strategies for training large vocabulary neural language models[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA, USA: Association for Computational Linguistics, 2016: 1975-1985.
[20] Joulin A, Cissé M, Grangier D, et al. Efficient softmax approximation for GPUs[C]//International Conference on Machine Learning. [S.l.:s.n.], 2017: 1302-1310.
[21] Shim K, Lee M, Choi I, et al. SVD-softmax: Fast softmax approximation on large vocabulary neural networks[J]. Advances in Neural Information Processing Systems, 2017, 30: 5463-5473.
[22] SHI Y Z, ZHANG W Q, LIU J, et al. RNN language model with word clustering and class-based output layer[J]. EURASIP Journal on Audio, Speech, and Music Processing, 2013, 2013: 22.
[23] Zhang M J, Wang W H, Liu X D, et al. Navigating with graph representations for fast and scalable decoding of neural language models[J]. Advances in Neural Information Processing Systems, 2018, 31: 6308-6319.
[24] MI H T, WANG Z G, ITTYCHERIAH A. Vocabulary manipulation for neural machine translation[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Stroudsburg, PA, USA: Association for Computational Linguistics, 2016: 124-129.
[25] JEAN S, CHO K, MEMISEVIC R, et al. On using very large target vocabulary for neural machine translation[C]//Proceed ings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg, PA, USA: Association for Computational Linguistics, 2015: 1-10.
[26] Yao J, Shu R, Li X, et al. Enabling real-time neural IME with incremental vocabulary selection[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. [S.l.:s.n.], 2019: 1-8.
[27] MIKOLOV T, KARAFIáT M, BURGET L, et al. Recurrent neural network based language model[C]//Proceedings of Interspeech 2010. ISCA: ISCA, 2010, 2(3): 1045-1048.
[28] ELMAN J L. Finding structure in time[J]. Cognitive Science, 1990, 14(2): 179-211.
[29] KNESER R, NEY H. Improved backing-off for M-gram language modeling[C]//Proceedings of 1995 International Conference on Acoustics, Speech, and Signal Processing. Piscataway: IEEE Press, 1995: 181-184.
[30] James F. Modified kneser-ney smoothing of n-gram models[R]. Research Institute for Advanced Computer Science, 2000.
[31] PRESS O, WOLF L. Using the output embedding to improve language models[C]//Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers. Stroudsburg, PA, USA: Association for Computational Linguistics, 2017: 157-163.
[32] DEVLIN J, ZBIB R, HUANG Z Q, et al. Fast and robust neural network joint models for statistical machine translation[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA, USA: Association for Computational Linguistics, 2014: 1370-1380.
Deep learning Chinese input method with incremental vocabulary selection
REN Huajian, HAO Xiulan, XU Wenjing
Zhejiang Province Key Laboratory of Smart Management and Application of Modern Agricultural Resources,Huzhou University, Huzhou 313000, China
The core task of an input method is to convert the keystroke sequences typed by users into Chinese character sequences. Input methods applying deep learning methods have advantages in learning long-range dependencies and solving data sparsity problems. However, the existing methods still have two shortcomings: the separation structure of pinyin slicing in conversion leads to error propagation, and the model is complicated to meet the demand for real-time performance of the input method. A deep-learning input method model incorporating incremental word selection methods was proposed to address these shortcomings. Various softmax optimization methods were compared. Experiments on People’s Daily data and Chinese Wikipedia data show that the model improves the conversion accuracy by 15% compared with the current state-of-the-art model, and the incremental vocabulary selection method makes the model 130 times faster without losing conversion accuracy.
Chinese input method, long short-term memory, vocabulary selection
TP391
A
10.11959/j.issn.1000–0801.2022294
2022–07–08;
2022–12–07
郝秀蘭,hxl2221_cn@zjhu.edu.cn
浙江省現代農業資源智慧管理與應用研究重點實驗室基金項目(No.2020E10017)

任華健(1994– ),男,湖州師范學院碩士生,主要研究方向為自然語言處理、中文輸入法。
郝秀蘭(1970– ),博士,女,湖州師范學院副教授、碩士生導師,主要研究方向為智能信息處理、數據與知識工程、自然語言理解等。

徐穩靜(1998– ),女,湖州師范學院碩士生,主要研究方向為自然語言處理、虛假新聞檢測。
The Foundation of Zhejiang Province Key Laboratory of Smart Management and Application of Modern Agricultural Resources (No.2020E10017)
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
文苑(2020年4期)2020-05-30 12:35:30
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
