基于對比學習的細粒度未知惡意流量分類方法
2023-01-09 12:33:08王一豐郭淵博陳慶禮方晨林韌昊
通信學報 2022年10期
王一豐,郭淵博,陳慶禮,方晨,林韌昊
(1.信息工程大學密碼工程學院,河南 鄭州 450001;2.鄭州大學計算機與人工智能學院,河南 鄭州 450001)
0 引言
基于流量的網絡入侵檢測系統(NIDS,network intrusion detection system)是網絡空間中最重要的安全設備類型之一,已被廣泛應用于各類信息系統的防護中。隨著移動互聯網和物聯網(IoT,Internet of things)等技術的發展,系統的規模不斷擴大,且終端設備的種類和數量也不斷增多。而這些資源受限的終端設備由于難以部署安全軟件或代理且更易存在較多漏洞,更易遭受攻擊。這種趨勢使NIDS 在網絡防御中的重要性日益凸顯。
NIDS 的主要作用是對惡意流量的分類。目前,流量分類方法主要有基于端口、基于載荷和基于流3 種[1]。然而,如今網絡攻擊愈發具有對抗性,常采用各種途徑規避NIDS 檢測。例如,端口混淆和端口跳變等技術使基于端口的方法準確率大幅下降[2];加密技術的廣泛應用使基于載荷的方法幾乎完全失效[3],此外,隱私和計算開銷等問題也是這類方法的缺點[1]。2020 年,超過70%的惡意活動在通信中使用了加密技術[4]。而基于流的方法不存在上述問題,并且由于機器學習(ML,machine learning)和深度學習(DL,deep learning)的快速發展,這類方法的檢測性能大幅提高,現已成為流量分類領域的主流方法[5-6]。然而,以往研究發現這類方法在實際惡意流量檢測中存在以下3 個問題。
1) 機器學習,特別是深度學習的分類性能嚴重依賴于訓練數據的數量和質量[7]。但由于實際中標注數據成本昂貴或存在新型網絡威脅,往往沒有足夠標注數據可用。此外,更細粒度的分類能提供更多威脅信息,有助于安全專家快速響應。而以往大多研究沒有考慮此問題,缺乏在細粒度小樣本(C2FS,coarse-to-fine few-shot)條件下的評估結果。
2) 惡意流量檢測也是一個開集分類問題,數量快速增長的未知攻擊(如惡意軟件新變種、零日攻擊以及針對IoT 等新興技術的攻擊)產生了各類未知惡意流量,現今的NIDS 需應對未知惡意流量分類的挑戰[8]。而以往大多實驗結果是在閉集上,未考慮對未知類的檢測。
3) 機器學習算法容易遭受逃逸攻擊,或者說對抗樣本攻擊[9]。研究表明,某些惡意流量只需添加不影響惡意功能的微小擾動即可繞過NIDS 的檢測[10-11]。此外,流量欺騙[12]、混淆[13]等技術的發展也使惡意類流量可以偽裝接近于良性類,從而誤導分類器[14]。
為了解決以上問題,本文提出一種基于對比學習[15]的細粒度未知惡意流量分類方法,主要貢獻如下。
1) 提出了在C2FS 條件下的惡意流量檢測任務,并提出了一種基于條件變分編碼器(CVAE,conditional variational auto-encoder)[16]和極值理論(EVT,extreme value theory)[17]的半監督在線學習方法。相比以往方法,本文在一個框架下實現了對已知、未知和小樣本類上的細粒度高性能分類。
2) 在流量分類的各階段設計并加入了對比損失,并采用了再訓練架構,使對小樣本惡意類流量的分類性能和模型的泛化性能相比以往大幅提高。
3) 在公開數據集上的實驗結果表明,相比以往方法,本文方法對所有惡意類,特別是小樣本類的分類精度更高,且能夠有效降低逃逸攻擊效果。
1 相關工作
1.1 基于機器學習的惡意流量分類
惡意流量分類的基本目標是區分良性類和惡意類流量。隨著數據規模的增加,相比傳統方法,機器學習在惡意流量分類中的性能優勢愈發凸顯[18]。采用機器學習的方法具有使用場景廣、分類準確率高、能分類加密流量等優點。這些研究的區別主要在于流特征、分類對象和分類算法的選擇。常用的流特征包括頭部、負載、時空和統計特征[7]。依據顆粒度,可將分類對象劃分為分組、主機和會話級[19]。常用的分類算法包括支持向量機(SVM,support vector machine)[20]、高斯混合模型(GMM,Gaussian mixture model)[21]、隨機森林(RF,random forest)[22]、卷積神經網絡(CNN,convolutional neural network)[23]等,且都在實驗環境下取得了不錯的效果。
基于頭部和負載特征的方法在應對精心設計的攻擊時表現不佳。例如,各類公共服務(社交網站、云平臺等)由于允許用戶定義內容,常被用作隱蔽信道發布命令或傳遞竊取信息[24]。加密或隨機填充等方式也會改變負載特征,從而導致分類性能下降。相比之下,基于統計和時空特征的方法雖然也存在上述問題,但由于在保持惡意功能條件下修改特征成本較大且往往會產生新的可分類特征[13],因此更適用于具有對抗性的惡意流量分類。
部分研究還考慮了實際應用中細粒度、小/零樣本等現實需求和問題。文獻[25]提出了一種多級半監督學習框架來緩解惡意流量分類中的類不平衡問題。文獻[8]采用CVAE 和EVT 來實現流量的細粒度檢測和對未知類的分類。但據本文所知,目前缺乏同時考慮上述3 個問題的惡意流量分類方法。
1.2 開集分類與流量分類
開集分類是指模型通過在訓練階段學習已知類樣本,并在測試階段辨別一個樣本是已知類還是未知類。目標是找到一個可測函數f(f(x) > 0表示分類正確),既要最小化已知分類經驗風險Rε(f(V)),也要最小化開放空間風險Ro(f)[26],即其中,V是訓練數據,λr是正則化常數。

開集分類包括判別和生成兩類方法。在判別方法中,實現開集分類主要有基于稀疏表示[27]、極值機(EVM,extreme value machine)[28]、OpenMax[29]等。在生成方法中,主要有基于實例生成[30]和非實例生成[31]兩類。在這些方法中,EVT 最常被引入用以對未知類進行評估。當前流量分類中考慮開集分類問題的文獻還相對較少。文獻[32]采用Weibull-calibrated SVM 對流量進行細粒度分類,并采用EVT 評估校準。文獻[33]通過EVT 近似計算每個已知類的邊緣距離分布,實現開集流量分類。
1.3 惡意流量分類中的逃逸攻擊
逃逸攻擊(或對抗樣本攻擊)是指攻擊者在不改變目標系統的情況下,通過構造特定對抗樣本以欺騙目標系統的攻擊。機器學習,特別是深度學習方法普遍存在容易遭受逃逸攻擊的問題[34],且各類對抗樣本生成方法層出不窮,如FGSM(fast gradient sign method)[35]、FFF(fast feature fool)[36]等。
逃逸攻擊近年來已應用于惡意流量偽裝中,以逃避基于機器學習的NIDS 檢測。文獻[37]采用生成對抗網絡(GAN,generative adversarial network)修改流量的非功能性特征,將原始惡意流量轉換為對抗流量繞過黑盒NIDS 檢測。文獻[38]同樣采用GAN 模型學習良性流特征指導對抗樣本生成,以傳出/傳入數據包等6 個特征實現逃逸攻擊。文獻[10]不僅實現了基于GAN的加密惡意流量偽裝,還模仿了良性類的主機級通信時間特征。隨著逃逸攻擊在惡意流量分類中不斷發展,未來NIDS 中需要考慮對此類攻擊的防御。
1.4 對比學習
對比學習屬于表征學習,目的是學習一種數據變換方式,其更容易解決下游任務。通過學習數據的特征表示,使特征空間中相同類數據較近,不同類數據彼此遠離。大多數方法是基于對比損失實現的。而其他方法,如BYOL(bootstrap your own latent)模型[39]雖然沒有采用負樣本,但其多層感知機(MLP,multilayer perception)預測器也可以視作負樣本網絡。文獻[40]指出對比學習模型的性能與負樣本的數量和質量相關。本文總結了當前3 種主流的對比學習方法。
1) 以SimCLR[41]為代表的方法。這類方法將當前訓練批次中的其他類樣本作為負樣本,通過對比損失實現對比學習。這類方法訓練難度較大且會丟失以往部分負樣本。
2) 以MoCo[42]為代表的方法。這類方法維護一個大的先入先出負樣本隊列(x-1,x-2,…,x-m),每次訓練更新最舊的一小批負樣本。經典的MoCo 架構如圖1 所示,采用模板網絡fM來實現對正負樣本的特征提取。對于fM,其初始化參數為原始特征提取網絡fq,訓練時基于動量緩慢更新參數。這類方法因不需要反向傳播而計算量較小,但負樣本更新速度較慢。

圖1 經典的MoCo 架構
3) 以AdCo[43]為代表的方法。這類方法設計負樣本網絡表示“整體”負樣本,用以生成高質量負樣本信息[44]。這類方法由于需要設計訓練負樣本網絡,模型結構比較復雜。
2 方法設計
現有基于流特征的NIDS 存在缺乏標注數據和易受逃逸攻擊的問題,本節在文獻[8]的基礎上,受文獻[45-46]啟發將對比學習與CVAE 結合,以實現已知、未知、小樣本類的流量細粒度分類。
流量的流特征可以采用CICFlowMeter[47]等流量特征提取工具提取。本文中流量的流特征經過提取和預處理后記作d維實值特征向量xi∈Rd,對應類標簽記作yi∈ {0,1}k+f+1,用k+f+1維的獨熱(one-hot)向量表示。記O為one-hot 編碼函數,作用是將輸入向量的最大維度設為1,其余維度值設為 0。類標簽集合可以表示為Call={B,M1,…,Mk,Mk+1,… ,Mk+f,Mk+f+1},其中,B表示良性類,M1,…,Mk表示k類大樣本已知惡意類,Mk+1,…,Mk+f表示f類小樣本已知惡意類,Mk+f+1表示未知惡意類 。訓練集Strain=Strain-B∪Strain-K∪Strain-F由大量良性類樣本Strain-B={(xi,yi)|yi=B}、一定量的已知惡意類樣本Strain-K={(xi,yi)|yi∈ {M1,… ,Mk}}以及極少量的小樣本已知惡意類樣本Strain-F={(xi,yi)|yi∈{Mk+1,…,Mk+f}}組成。本文利用訓練集Strain訓練分類網絡Pθ,使其對所有類樣本x∈ {xi|yi∈Call}的預測結果都盡量接近其真實標簽y,即目標為
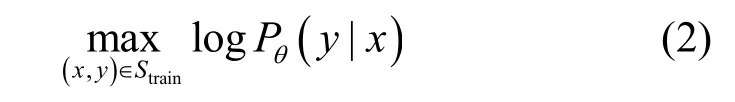
本文提出了一個基于流特征的流量分類方法,可同時實現對已知、未知、小樣本類的流量細粒度分類,整體結構如圖2 所示。模型分為已知惡意流量訓練、未知惡意流量訓練和測試3 個階段。首先,在已知惡意流量訓練階段采用CVAE 模型,并設計對比損失結合CVAE 編碼器訓練,使不同類樣本在潛特征空間中進一步區分。相比以往方法,加入對比損失后對于小樣本類檢測有顯著提升。其次,在模型未知惡意流量訓練階段采用EVT 模型。當模型在已知惡意流量訓練后,固定編碼器和解碼器的網絡參數訓練重構網絡參數,并在重構階段也加入了對比損失,基于重構誤差訓練EVT 模型,使模型對未知類的分類性能顯著提高。最后,在測試階段用訓練后的CVAE 和EVT 模型對新樣本進行分類。并且重采樣、再訓練和L2 正則化等技巧在此也被采用,以進一步提升模型的檢測和泛化性能。

圖2 基于對比學習的細粒度惡意流量檢測模型整體結構
2.1 已知惡意流量訓練階段
該階段結構如圖2 中的已知惡意流量訓練階段所示,目標是采用訓練集Strain對良性類(B)和已知惡意類(M1,…,Mk+f)樣本進行分類。本文在此階段采用對比學習結合CVAE 模型[8]實現。CVAE可視為有監督VAE 模型,在惡意流量檢測中表現優異,更重要的是其獨特的“解碼重構”架構可以幫助分類未知惡意類樣本。
首先,將樣本x∈Rd轉化為更低維的潛特征z∈R h,h<<d,更低維的特征空間計算速度更快且能更好地區分不同類的樣本[8]。對于給定x,y,其z的真實分布記為P(z|x,y),采用一個網絡Q(z|x,y)近似模擬P(z|x,y)。對于目標式(2)的logPθ(y|x)可以改寫為[16]

其中,DKL表示KL 散度[48],用于衡量2 個分布之間的差異。式(3)中前兩項合稱為CVAE 證據下界值(ELBO,evidence lower-bound),即

由于式(3)第三項中P(z|x,y)無法計算,但KL散度一定非負,因此 logPθ(y|x) ≥LELBO,則式(2)可以等價為

其中,P(z|x)、Q(z|x,y)、P(y|x,z)均采用GMLP(Gaussian multi-layered perceptron)近似模擬。假設P(z|x)服從正態分布,采用先驗網絡P(x)近似;Q(z|x,y)采用編碼網絡QE(x,y)近似,對應CVAE編碼器;P(y|x,z)采用解碼網絡QD(x,z)近似,對應CVAE 解碼器。則基于目標式(5),P(x)、QE(x,y)和QD(x,z)采用隨機梯度下降(SGD,stochastic gradient descent)算法通過最小化損失函數式(6)更新網絡參數,實現流量分類

其中,z=SA(QE(x,y))是QE(x,y)編碼后正態分布的采樣,SA 表示采樣函數。
但以上CVAE 模型存在一定缺陷:一是難以分類小樣本類,二是易遭受對抗樣本的攻擊。為了緩解這2 個問題,本文學習潛特征z時加入了對比學習。在潛特征空間中,本文希望同類樣本之間更加緊湊,異類樣本之間更加分散。這樣即使是小樣本類也可與其他類區分開,并且有助于分類未知惡意類流量和防御逃逸攻擊。
為了實現對比學習,對于任意樣本對(xi,yi)∈Strain,P(xi)首先應與同類樣本x+的P(x+)接近,與異類樣本x-的P(x-)遠離;同樣QE(xi,yi)應與同類樣本x+的QE(x+,yi)接近,與異類樣本x-的QE(x-,yi)遠離;最后,P(xi)應與其對應的QE(xi,yi)接近,與其他不正確的y-≠yi生成的QE(xi,y-)遠離。而對比學習的損失函數可以采用InfoNCE 損失[49]的形式來表示

其中,τ是歸一化超參數。計算時對P(x)和QE(x,y)進行重采樣,以 SA(P(x))和 SA(QE(x,y))計算損失函數。
對比學習中負樣本的選擇至關重要。為了兼顧效率與精度,本文對不同類型x采用不同策略選取負樣本。首先,采用SimCLR 類方法迅速訓練P(x)、QE(x,y);當模型收斂速度下降后,選擇負樣本時采用AdCo 類思想,選擇針對性負樣本。即當樣本對(xi,yi)∈Strain-K時,選擇屬于同一粗粒度類但不同細粒度類或良性類樣本作為負樣本;最后,對于小樣本類樣本對(xi,yi)∈Strain-F,希望其與盡可能多的負樣本訓練,因此對于這部分樣本采用MoCo類方法訓練至模型收斂。
本文在CVAE 模型訓練時加入了對比損失,以不平衡采樣數據訓練整體的CVAE 模型,其損失函數如式(8)所示,對應圖2 中的①。

其中,λC是權重超參數。
該階段的訓練策略如算法1 的步驟1)~步驟16)所示。
2.2 未知惡意流量訓練階段
該階段結構如圖2 中的未知惡意流量訓練階段所示,目標是對未知類(Mk+f+1)惡意樣本進行分類。在此階段,本文采用對比學習結合CVAE 重構網絡和EVT 方法實現流量分類。
在CVAE 模型完成2.1 節訓練后,首先固定QE(x,y)的參數訓練重構網絡R(z,y)。重構網絡R(z,y)用于對輸入潛特征z(由編碼器網絡QE生成)和給定標簽y'并生成重構樣本x'。其目標是編碼網絡QE輸入的x和解碼網絡QD輸出的x'盡量接近。重構損失函數如式(9)所示,重構損失采用均方誤差(MSE,mean square error)來衡量。

對于未知類檢測思路是訓練后的CVAE 模型對已知類樣本對(xi,yi)∈{(xi,yi)|yi∈ {M1,…,Mk+f}}的預測標簽yi'大概率是正確的,即yi' =yi,其重構樣本也應接近xi;而對未知類樣本對(xi,yi)∈{(xi,yi)|yi=Mk+f+1},其預測類標簽yi'必定錯誤,即yi' ≠yi,其重構樣本xi'應與原樣本xi相差較大。這樣就可以判斷新樣本xi'是否屬于未知惡意類。
為了減少對未知類的誤判,訓練時重構樣本xi'應與輸入樣本xi接近,與其他類樣本y-≠yi生成的R(zi,y-)較遠。為此,采用對比學習式(10)放大這種需求。
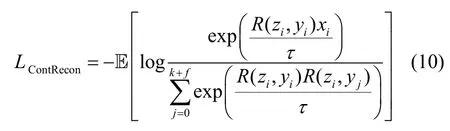
最后利用式(11)訓練重構網絡R(z,y)。訓練時固 定P(x)和QE(x,y)參數,實際計算時z=SA(QE(x,y))由QE(x,y)編碼后正態分布采樣,對應圖2 中的②。由于對比損失幾何上類似余弦相似度,因此在重構樣本時潛特征z也需歸一化。
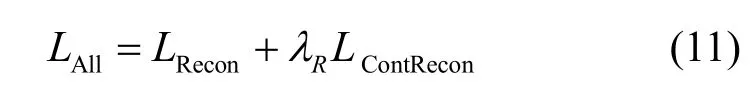
其中,λR是權重超參數。
未知惡意類分類時,由于模型對不同已知類的分類和重構能力不同,難以采用統一閾值進行分類。為此,本文采用EVT 為每個已知大樣本類估計分類閾值。EVT 認為對于任意的隨機變量X,其極值相對于閾值t超出的部分應服從 GPD(generalized pareto distribution)分布

其中,γ,σ> 0,實際中可以采用極大似然估計方法計算γ,σ,對數似然函數表示為

其中,Nt表示觀測數據中超過閾值t的樣本數量,Xi表示觀察數據。本文采用Strain-B∪Strain-K中樣本的重構誤差作為觀察數據,分別對大樣本已知類(B,M1,…,Mk)構建k+1 個EVT 模型,對應于圖2中的③。
該階段的訓練策略如算法1 的步驟17)~步驟24)所示。
2.3 細粒度惡意流量的訓練策略與測試階段
本文模型的整體訓練策略如算法1 所示。
算法1細粒度惡意流量分類模型訓練算法
輸入標記訓練數據集Strain
輸出訓練后的P(x)、QE(x,y)、QD(x,z)和R(z,y),以及k+1 個訓練后的EVT 模型參數
1) 隨機初始化P(x)、QE(x,y)、QD(x,z)、R(z,y);
2) for(xi,yi)∈Straindo
3) 計算QE(xi,yi)和P(xi)得到潛特征;
4) 隨機選擇負樣本,基于式(8)計算損失和梯度,并采用SGD 更新P(x)、QE(x,y)、QD(x,z)參數;
5) end for
6) 重復步驟2)~步驟5),直至模型大致收斂;
7) for(xi,yi)∈Strain-Kdo
8) 計算QE(xi,yi)和P(xi)得到潛特征;
9) 選擇xi的同一粗粒度類但不同細粒度類或良性類樣本為負樣本,基于式(8)采用SGD 更新P(x)、QE(x,y)、QD(x,z)參數;
10) end for
11) 重復步驟7)~步驟10),直至模型大致收斂;
12) for (xi,yi)∈Strain-Fdo
13) 計算QE(xi,yi)和P(xi)得到潛特征;
14) 采用MoCo 架構,維持大量負樣本,基于式(8)采用動量方式更新P(x)、QE(x,y)、QD(x,z)參數;
15) end for
16) 重復步驟12)~步驟15),直至模型收斂;
17) for(xi,yi)∈Strain-B∪Strain-Kdo
18) 計算QE(xi,yi)得到潛特征;
19) 固定當前P(x)、QE(x,y)、QD(x,z)網絡參數,基于式(11)采用 SGD 更新R(z,y)參數;
20) end for
21) 重復步驟17)~步驟20),直至模型收斂;
22) forci∈{B,M1,…,Mk} do
23) 計算ci類所有訓練樣本的重構誤差,并將其作為觀察數據,選取經驗閾值ti并基于式(13)估算ci類的EVT 模型參數γi,σi;
24) end for
訓練完成后,模型在測試階段的流程如圖2 中的測試階段所示。具體來說,對于一個待分類的新樣本xi,首先采用先驗網絡P得到潛特征分布zi。接著解碼器QD給出預測標簽。若為小樣本惡意類,則直接將作為分類向量輸出;若為良性類或大樣本已知惡意類,則繼續用重構網絡R計算x與所有大樣本已知類的標簽計算重構樣本R(SA(zi),{B,M1,…,Mk})及其重構誤差。之所以不對被分類為小樣本類的樣本進行重構,是因為模型對小樣本類分類能力不足。接著,基于大樣本已知類EVT 模型,對當前重構誤差計算概率,用于對的修正,得到修正后的概率向量。若分類結果改變(即O或其最大值小于閾值(即),則最終分類結果為未知惡意類Mk+f+1;否則,分類結果仍為
為了進一步提升對小樣本類的分類能力,本文還采用半監督學習中的再訓練架構。測試時的無標記樣本xi經過模型預測得到分類向量,若,則先基于式(14)分析質量并篩選其中高質量偽標簽。其中高置信度樣本對作為新標注數據,再次重新用于模型訓練以提升對小樣本類的分類能力。再訓練時只更新解碼器QD(x,z)參數。
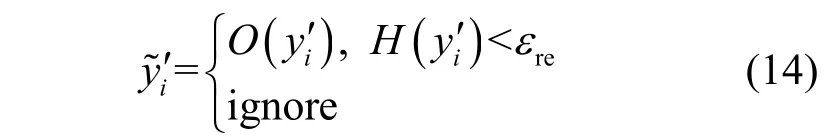
對抗逃逸攻擊需要增強模型的泛化能力[50],常見方法主要分為兩類:一是對數據處理,例如通過添加隨機噪聲進行數據增強、部署檢測器分類輸入數據、中間層隨機Dropout 等[51];二是對模型參數處理,例如L1、L2 正則化[52]和對抗訓練[53]等。
本文采用了3 種技巧來增強模型的泛化能力以降低逃逸攻擊的效果。首先,訓練和測試時在潛特征空間中進行重采樣,相當于對數據添加了噪聲進行數據增強,而這其中對比損失的加入使重采樣對模型原本分類性能的影響減少。其次,模型在訓練損失函數式(8)和式(11)時加入了L2正則項。文獻[35]指出L2 正則化能有效增強線性模型的泛化能力且容易實現。最后,逃逸攻擊在未知類分類階段大多被分類為未知攻擊,實現對抗樣本的分類。此外,對比學習在此也提高了模型的泛化性能。
3 實驗分析
本節在一個惡意流量分類文獻中廣泛采用的公開數據集NSL-KDD[54]上評估了所提方法。首先,對所提方法各個組件的有效性進行了分析。其次,將所提方法與現有方法進行了對比分析。實驗表明,所提方法在分類小樣本惡意類、分類未知惡意類和抵御逃避攻擊等方面明顯優于其他方法。
3.1 數據集
本文實驗采用NSL-KDD[54]數據集,該數據集是著名KDD 99 數據集的修訂版本。NSL-KDD 數據集包括良性類和39 種細粒度攻擊類。其中,攻擊可以分為4 個粗粒度類,即拒絕服務(DoS,denial of service)類攻擊、掃描(Probe)類攻擊、遠程入侵(R2L,remote to login)類攻擊和本地提權(U2R,user to root)類攻擊,具體數據分布如表1 所示。本文選擇NSL-KDD 作為實驗數據集主要基于以下兩點:1) NSL-KDD 雖然發布時間較早,但一直被高水平研究所采用,可以與經典和先進方法比較;2) 更重要的是,相比其他公開數據集,NSL-KDD包含了豐富的細粒度類標簽,適用于本文場景,而其他數據集大多只有粗粒度標簽,或細粒度標簽種類不夠豐富。
結合表1 的數據分布和實際情況發現,DoS 類和Probe 類在實際中如果存在,則一般有大量標記樣本。而U2R 類和R2L 類在實際中存在較少,更頻繁存在小樣本情況。本文在表1 中列舉并采取了接近實際的實驗設置。對于小樣本類,每類只選取5 個樣本(5-shot)用于訓練。

表1 NSL-KDD 數據集各細粒度類的數據分布
3.2 評估標準
在分類任務中,TP 為被模型預測為正類的正樣本,TN 為被模型預測為負類的負樣本,FP 為被模型預測為正類的負樣本,FN 為被模型預測為負類的正樣本,則分類任務通常采用以下3 個衡量指標:精度(Precision)、召回率(Recall)和F1值。

在已知類分類階段,本文同樣關注稀疏類(小樣本類),因此在訓練時采用宏(macro)平均值對模型分類性能進行評估,式(18)表示宏平均F1值。在后續模型性能評估時,都采用宏平均指標。
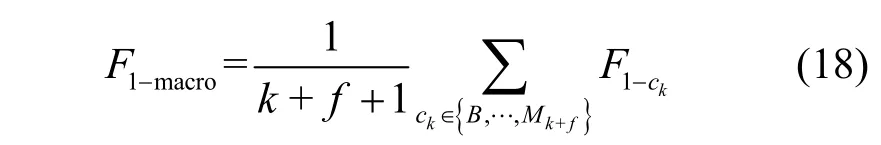
3.3 有效性分析
本節對本文模型中各個組件的有效性進行分析。實驗選擇了200 次訓練后的各模型進行比較分析。
本節首先討論了第2 節中幾個重要超參數的設置。式(8)中λC和式(11)中λR都是訓練時對比學習的權重,是隨著訓練過程動態變化的。實驗發現,若初始訓練時權重取正值,則模型收斂速度很慢。因此前30 個訓練批次時,權重均取0;之后訓練時權重均取0.5,使模型能快速收斂。其次,對于未知分類閾值εun,選擇訓練集上的最佳分類設置,實驗中εun=0.82。最后,對于再訓練過程中的交叉熵閾值εre,其取值應是訓練集上小樣本類分類性能最佳時的最小值,實驗發現,當εre=1.88時取得了最佳效果。
在已知惡意流量訓練階段,首先分析對比學習對檢測性能(特別是小樣本類)的提升效果。本節比較了本文模型、不采用對比學習的模型和采用SimCLR 對比學習的模型的性能。如圖3 所示,在100 次訓練后,不采用對比學習的模型由于訓練難度低模型已經收斂。而采用對比學習的模型,雖然訓練難度高導致所需的訓練次數較多,但在進一步充分訓練后,模型性能還可以進一步提升。
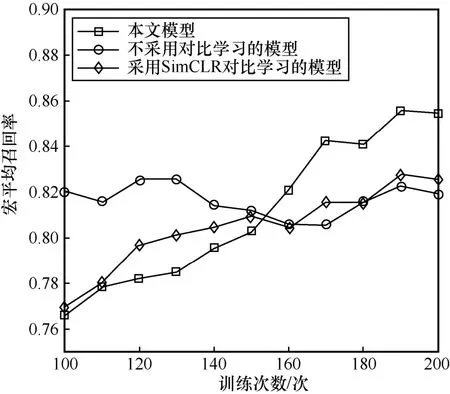
圖3 已知惡意流量訓練階段不同模型的性能變化
已知類分類階段不同設置下的歸一化矩陣如圖4所示。如圖4(a)和圖4(b)所示,加入對比學習后本文模型對部分大樣本類(如良性類和back 類)和小樣本類的分類性能有明顯提升。但由于加入對比學習后,模型訓練難度較大,導致同樣訓練次數下模型可能訓練不充分,極少類(如warezclient 類)性能反而略微下降。
其次,分析再訓練過程對小樣本類的提升效果。如圖4(a)和4(c)所示,再訓練后模型對小樣本類分類性能幾乎都有明顯提升。如圖4(b)和4(d)所示,再訓練過程對不采用對比學習的模型幾乎沒有幫助。這是因為不采用對比學習的模型對小樣本惡意類分類能力較差,其輸出的偽標簽質量較差,對分類小樣本類幾乎沒有幫助,反而可能降低檢測性能。

圖4 已知類分類階段不同設置下的歸一化混淆矩陣
在未知類分類訓練階段,本節以已知階段本文模型為基線繼續未知階段訓練過程,分別對比了本文模型和在重構階段不采用對比學習的模型。如圖5(a)和圖5(b)所示,在重構階段采用對比學習對未知類分類性能有一定提升,并且降低了對部分類(特別是良性類)的誤判。這是因為對比學習將同類更加聚合,從而使誤報減少。由于良性類在實際檢測中頻繁出現,這對于實際檢測性能影響較大。
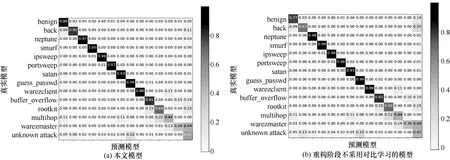
圖5 未知類分類階段不同設置下的歸一化混淆矩陣
最后,分析模型對逃逸攻擊的防御效果。實驗采用FGSM 算法對所有已知惡意類生成對抗樣本測試。如圖6(a)和圖6(b)所示,相比不采樣的模型,采取重采樣的本文模型在同樣烈度的逃逸攻擊下分類性能更高,證明了重采樣能有效對抗逃逸攻擊。如圖6(a)和圖6(c)所示,不采用對比學習的模型也增強了對抗逃逸攻擊的能力。最后,如圖6(a)和圖6(d)所示,大部分逃逸攻擊即使在已知類分類階段騙過了模型,但在未知類分類階段逃逸攻擊大多被分類為未知攻擊類,也能一定程度上發現逃逸攻擊。

圖6 不同設置下遭受逃逸攻擊后的歸一化混淆矩陣
3.4 性能分析
本節討論本文方法與其他方法的性能對比。其中,基線模型是先進的CVAE-EVT 模型[8]。在此實驗結果與文獻[8]中不同的原因主要包括以下兩點:一是數據預處理方式和MLP 網絡結構不同;二是采用價標準不同,本文采用宏平均指標評。
在已知類分類階段,分類模型都能實現對大樣本已知惡意類的分類。但實際中由于網絡欺騙流量或業務變化,往往存在概念漂移等問題,模型需要能快速訓練并應用。因此,本節在此主要測試在相同訓練時間內(本文模型在實驗環境下訓練200 次的時間——約5 min),幾種方法對良性類、大樣本已知類和小樣本已知類的宏平均指標如表2 所示。表2 中,盡管隨機森林方法在大樣本類部分指標得到了更優結果,但不能兼顧精度與召回率。這是因為隨機森林方法未采取措施平衡稀疏類,導致對稀疏(小樣本)類精度提升但召回率下降,對大樣本類則反之。實際中對于出現次數較少的惡意類,高召回率則代表了低漏報率,這對攻擊檢測而言更為重要。且隨機森林對小樣本類束手無策,而本文模型由于加入了對比學習以及再訓練方法,在各階段都表現出了最佳綜合性能,特別是在小樣本類的分類上提升明顯。

表2 已知類分類階段不同模型檢測性能對比
在未知類分類訓練階段,相同訓練時間內本文模型與先進的CVAE-EVT 模型[8]進行了對比。圖7 給出了不同未知類設置下的宏平均F1值。加入對比學習的本文模型對各類未知類的檢測性能基本優于CVAE-EVT 模型,證明了本文方法的先進性。
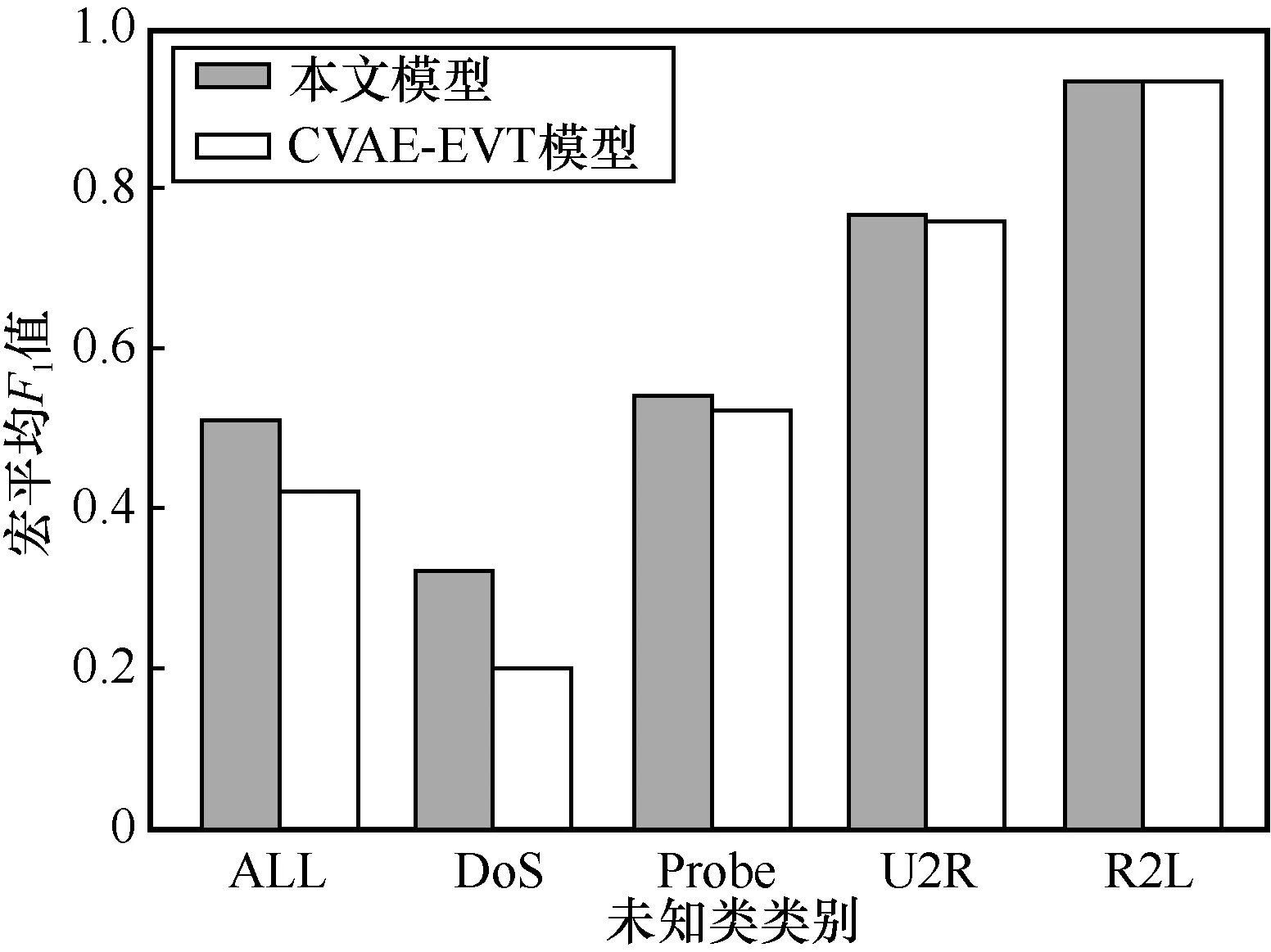
圖7 不同未知類設置下的宏平均F1 值
4 結束語
本文旨在設計一種應用于NIDS 的細粒度惡意流量分類方法。在CVAE-EVT 模型[8]的基礎上,本文提出了一個能夠兼顧已知類、小樣本類和未知類的方法,且所設計模型需具有較強的泛化性,能夠在一定程度上對抗逃逸攻擊。該方法通過在各階段引入了對比學習策略提高分類性能。并且,融合再訓練、重采樣、L2 正則化等技巧,使模型泛化性能進一步提高。實驗結果證明了該方法的有效性和先進性。最后,由于當前逃逸攻擊技術不斷發展,未來擬在此基礎上進一步研究在保證分類性能條件下的防御逃逸攻擊流量的方法。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
