基于ELMo-GCN 的核電領域命名實體識別
2023-01-12 11:49:48荊鑫王華峰劉潛峰羅嗣梧張凡
北京航空航天大學學報 2022年12期
荊鑫, 王華峰,,*, 劉潛峰, 羅嗣梧, 張凡
(1. 北方工業大學 信息學院, 北京 100144; 2. 北京航空航天大學 軟件學院, 北京 100191;3. 清華大學 核能與新能源技術研究院, 北京 100084; 4. 太原理工大學 軟件學院, 太原 030024)
新智能時代向工業5.0 新形態演進的進程已經全面啟動[1]。 在《中國能源革命進展報告(2020)》中提出,要加速融合新一代信息技術與能源技術,推動多能互補智慧能源系統建設步伐[2]。 在這一進程中,需要對數十年核電發展所積累的信息進行處理、分析和管理,以達到提升工作效率、優化產業結構的目的。 因此,如何從海量的非結構化文本信息中提取到有用信息,是計算機智能技術在核電領域應用的難點。 這里便需要用到自然語言處理(natural language processing,NLP)技術對其文本數據進行語義理解和語義分析。
NLP 作為人工智能的子領域,是將人類交流所使用的語言通過某種算法轉化為機器可以理解的機器語言的技術。 其中,命名實體識別(named entity recognition, NER)是NLP 中一個重要的文本預處理工具,其主要作用是識別出文本中表示命名實體(named entity, NE)的成分,并對其進行分類,故而也被稱為命名實體識別和分類(named entity recognition and classification, NERC)。 而由于核電領域本身的特殊性,NER 任務缺乏相應的研究。
早期的命名實體任務主要針對以英語為主的印歐語系,該任務僅限于一個或多個嚴格指示詞的實體,嚴格指示詞包括專有名稱及某些自然類術語,如生物物種和物質[3]。 隨后,NER 任務轉為一般意義上的“專有名稱”,研究最多的就是“Person”、“Location”與“Organization” 3 種實體類型,這些類型統稱為“Enamex”。 直到1995 年第六次信息理解會議(MCU)明確將“命名實體”定義為研究對象,此后NER 便成為一項單獨的研究任務。 在定義這一任務時,研究人員發現某些命名實體是文本中的重要信息單元,這就誕生了命名實體最初的7 種實體類型:“Person”、“Organization”和“Location”,以及“Time”、“Date”、“Currency”、“Percentage”的數字表達式[4]。 在實驗過程中,研究者們發現以上7 種實體類型無法滿足研究需要,因此,結合實際添加了一系列細粒度實體子類型。 例如,Fleischman[5]與Lee 等[6]將“Location”劃分為多個細粒度實體子類型:“City”、“State”、“Country” 等;Fleischman 與Hovy[7]將“Person” 的細粒度實體子類型劃分為“Politician”、“Entertainer” 等;Bodenreider 和Zweigenbaum[8]將“Person”與“Drug”、“Disease”相結合進行命名實體分類。
目前,由于NER 技術在一些開放數據集中已經取得了很高的準確率,部分學術界學者認為NER 技術并不具備進一步的研究價值。 但是,在當前研究中,NER 研究面臨著諸多問題需要解決:
1) 數據來源與處理問題。 核電相關的大部分資料(如檢查報告、設計方案及日程安排等)均不能進行公開的研究,因此在數據來源的選擇方面可參考內容少,數據范圍小,在核能領域中的NER 技術研究更是稀缺。 同時在研究中,還需考慮如何有效地對核安全文本中的命名實體進行分類。
2) 文本類型對NER 任務有著很大的影響。諸如核電、生物醫學領域的文本數據中,頻繁出現的技術詞匯、特定術語及其縮寫、不完整句子等,直接導致網絡模型無法像通用數據集一樣構建全面合理的實體特征,神經模型的預測結果與通用數據集相差甚遠[9]。
3) NER 研究中存在的具有挑戰性的問題,如嵌套命名實體識別(nested named entity recognition,Nested NER)、歧義文本及標注語料數據老舊等[10]。 嵌套命名實體(nested named entity,Nested NE)是一種特殊形式的命名實體,即在一個命名實體的內部還存在一個或多個其他類型的命名實體,層次結構較為復雜,傳統的基于序列標注的NER 網絡模型不能很好地解決Nested NER 任務。
針對現今核電領域NER 研究面臨的挑戰,本文主要貢獻如下:
1) 研究伊始面臨的主要問題是缺乏數據集。考慮到核安全相關的大部分資料不能進行公開的研究,基于數據特征具有代表性和數據易于搜集2 個方面,本文以核反應堆相關基礎理論作為基礎文本數據。 在命名實體分類過程中,本文參考了核反應堆方面的相關研究,對現有文本數據進行分類,得到“專有名詞類”、“冷卻與冷卻劑類”、“燃料與材料類”與“反應堆類”四大類。 此外,本文還通過BIO 數據標注方式對搜集到的文本數據進行標注,得到標記數據141 057 條。
2) 針對Nested NER 問題,本文在現有研究的基礎上,提出了結合動態、張量的圖卷積神經網絡模型(graph convolutional neural network model with dynamic tensor, DTGCN),模型中加入了句子處理器,通過提取句中的動態張量并計算的方式,獲取上下文信息,同時使用Self-Attention 模型學習句子中實體之間的依賴關系,獲取句子的內部結構信息。 之后經由GCN 網絡,利用核電語料中實體的內部關系與相鄰關系,完成核電命名實體的細粒度識別,進而處理Nested NER 問題。
3) 構建校正模塊進行后處理,基于命名實體類型的特征制定規則,并使用該規則對網絡預測結果中的實體類型正確而邊界判斷錯誤的情況進行校正,以提高模型的容錯率。
1 相關理論與方法
研究人員在NER 工作中已經取得了一定的進展。 Goller 和Kucher[11]使用循環神經網絡(recurrent neural network, RNN),使模型可以變長輸入且具有長期記憶,但由于RNN 結構本身的缺陷,存在梯度消失和梯度爆炸的問題。Hammerton[12]首次將長短記憶網絡(long shortterm memory, LSTM)應用于NER,LSTM 網絡中使用遺忘門、記憶門結合的方式,成功避免了梯度消失和梯度爆炸問題。 2015 年,Huang 等[13]在LSTM 的基礎上,使用BiLSTM + CRF 模型,正向LSTM 獲取“過去特征”,反向LSTM 獲取“未來特征”,由此對上下文信息作出進一步發掘。Peters 等[14]利用雙層LSTM,提出基于語言模型的上下文相關的詞向量表示(embeddings from language model, ELMo),得到的ELMo 詞向量具有更深層次的語義表征,但由于LSTM 本身的結構約束,一旦輸入語句序列過長,模型的學習能力將大幅下降。
2014 年,Sutskever 等[15]在研究過程中首次引入Attention 機制。 2017 年,Vaswani 等[16]提出了Transformer 結構,通過Self-Attention 計算詞與詞之間的關系權重,使每個詞都有全局的語義信息。 2019 年,Devlin 等[17]提出了基于Transformer的雙向編碼器(bidirectional encoder representation from Transformer, BERT) 模 型。 BERT 在11 項NLP 任務中表現優異,在其他網絡模型最優指標的基礎上有了新的突破。 不過,BERT 模型依然存在一定缺陷:①數據總量要求高,若總量不夠,則最終訓練效果較差;②運算量大,BERT 中的BERT-Base 模型參數為1.1 億,BERT-Large 模型的參數更是達到3.4 億,計算量大,所需成本高。
在NER 研究中,Nested NE 廣泛存在于多種語料之中。 例如,以蛋白質和DNA 等實體類型標記的GENIA 語料庫[18],Nested NE 占全部命名實體的17%;西班牙語和加泰羅尼亞語報紙的AnCora 語料庫中[19],Nested NE 占50%左右;在ACE-2004 中,42% 的句子包含Nested NE,Nested NE占比達47%[20]。
對于Nested NE 的研究一直在進行。 Finkel和Manning[21]提出了一種基于條件隨機場(conditional random field, CRF)的分區解析器,將句子作為解析樹,句中單詞和每個事宜相對應的短語作為解析樹的葉子,該解析樹還將詞性包含其中,以此共同對實體和詞性進行建模;Alex 等[22]提出將多模型級聯的方式,分別為多組實體提供訓練。此外,Lu 和Dan[23]提出了一種基于超圖的模型來解決Nested NER 問題,通過輸入給定的字符序列,獲取內部所有的實體指代關系,計算得出分數最高的輸出路徑;Xia[24]提出了多粒度NER 模型來解決Nested NER 問題,該模型分為檢測器和分類器2 部分,檢測器負責檢測所有可能的實體位置,分類器則將檢測到的實體進行分類;Luo 和Zhao[25]結合LSTM 與GCN,將LSTM 部分作為最外層實體信息提取工具,再由GCN 結合實體關系圖抽取實體信息。
2 結構模型
如圖1 所示,DTGCN 模型主要分為2 部分,即外部模塊(OuterModule)和內部模塊(InnerModule),分別學習外層實體信息和內部實體信息。 核電語料集中的實體(Word)和語句(Sentence)分別進入外部模塊的字處理器(Word Processor)和句子處理器(Sentence Processor)。 字處理器負責提取單個字的信息及輸入語句中字與字之間的關系,主要使用BiLSTM 網絡;句子處理器是以整個句子的層面進行信息提取,主要通過生成動態張量的方式,得到命名實體在不同語義環境下不同的張量特征,以此增加網絡對實體上下文信息的提取能力;通過Self-Attention 模塊獲取實體之間的相關度信息。

圖1 DTGCN 網絡模型Fig.1 DTGCN network model
內部模塊使用GCN 將實體與實體間的關系建模(其中Adjacency Graph Model 和Entity Graph Model 部分分別對外部實體和內部實體進行處理),通過迭代其傳播信息,學習內部實體特征。GCN 將其學習到的信息輸入到CRF 模塊,對預測結果進行分類。 通過校正模塊(Corrected Module)對預測結果中實體類型正確而邊界判斷錯誤的情況進行校正。
2.1 數 據
由于目前沒有開放的核電數據集,筆者手動構建了一個語料集用于研究。 本文數據來自于核反應堆相關基礎理論分析[26-27],對實體分為4 類:“專有名詞類”(NOU)、“冷卻與冷卻劑類”(COO)、“燃料與材料類”(FUE)與“反應堆類”(REA)。
由圖2 和表1 可知,核電語料集共8 023 句141 057 字,所用漢字1 384 個,其中專有名詞類實體684 個,所用漢字407 字,114 字無嵌套關系,占28%;燃料與材料類實體207 個,所用漢字197 字,54 字無嵌套關系,占27%;冷卻與冷卻劑類實體1 365個,所用漢字491 字,146 字無嵌套關系,占30%;反應堆類實體251 個,所用漢字232字,37 字無嵌套關系,占16%。 此外,表1 還統計了每個實體的數量及實體的出現頻率,出現頻率統計了對應類型實體出現的總次數,便于從數據方面對不同網絡模型中實體分類結果進行分析。

圖2 核電語料中嵌套命名實體比例Fig.2 Proportion of nested named entities in nuclear power corpus
綜上,核電語料集中Nested NE 占總實體的68%,遠高于GENIA[18]、AnCora[19]、ACE-2004[20]等語料庫中Nested NE 所占比例,因而進行NER研究的難度也更高。
核電語料通過BIO 實現對序列數據的聯合標注,如表1 所示,其中,“B-”表示命名實體中的第1 個字,“I-”表示命名實體中間字和結尾字,“O”表示非實體字符,核電語料實體標注示例如圖3 所示。
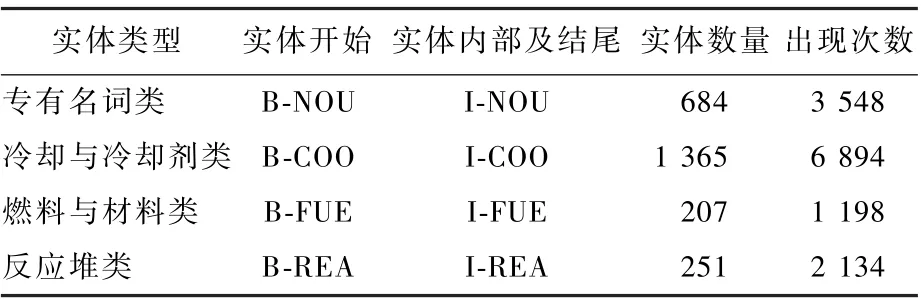
表1 核電語料實體標注方法及實體數量和出現頻率Table 1 Nuclear power corpus labeling methodology,count, and frequency of appearance
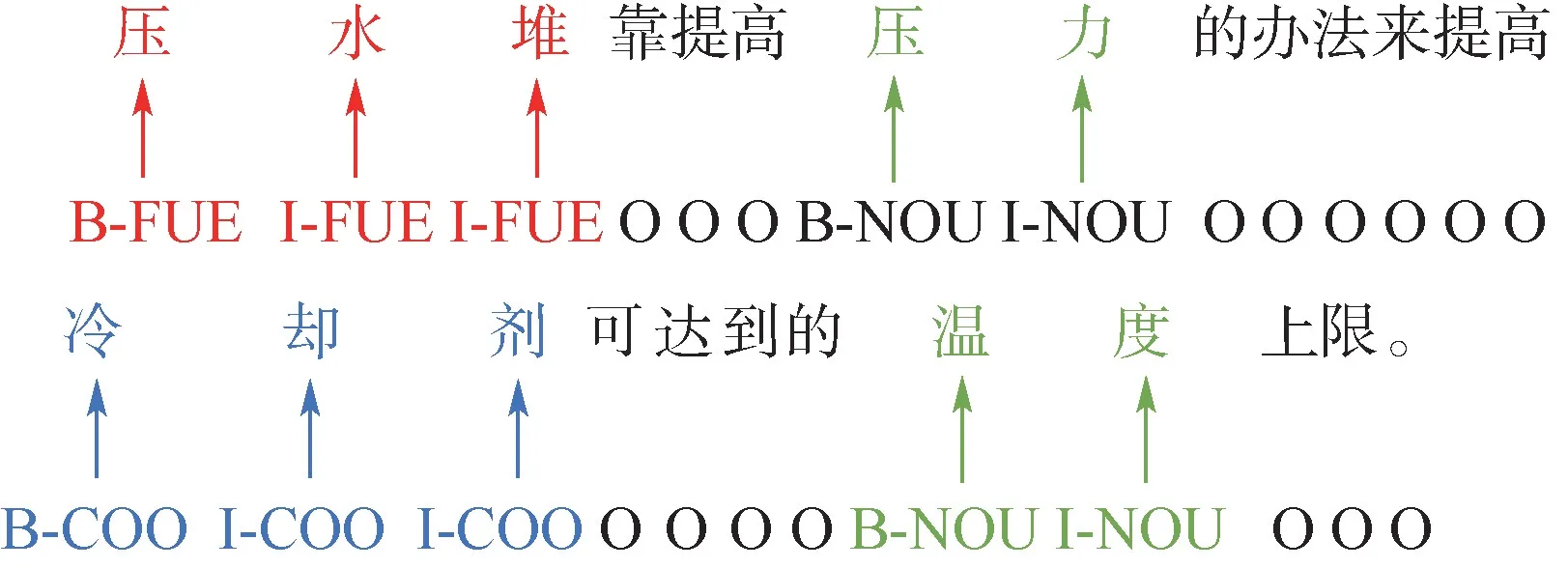
圖3 核電語料命名實體標注示例Fig.3 Example of nuclear power corpus named entity labeling
2.2 字處理器
文字中存在著的隱藏信息往往隱含在上下文中,體現在字與字之間的前后關系上。 因此,本文模型使用BiLSTM 作為字處理器,提取單個字的信息及輸入語句內字與字之間的關系。
給定一個包含N個字符的輸入語句T=(t1,t2,…,tN),對每個字符tk(1≤k≤N)進行字嵌入后表示為:xk=[wk],wk為預訓練獲得的字嵌入模型。
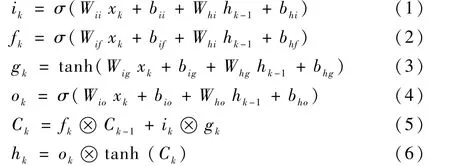
如圖4 所示,結合式(1) ~式(6),W和b為LSTM 的參數,W為權重向量,b為偏置向量,σ為激活函數,?表示正交,ik、fk和ok分別代表k時刻的輸入門、遺忘門和輸出門,Ck、hk和gk分別表示LSTM 中的細胞狀態、隱藏狀態和新狀態。xk經過BiLSTM 的輸出得到k時刻字符的隱藏狀態hk(其中包含前向隱藏狀態和后向隱藏狀態):

圖4 LSTM 結構Fig.4 Structure of LSTM

因此,字符信息xk通過字處理器后得到LSTM輸出特征αLSTM∈RN×dl(dl為BiLSTM 隱藏層大小):

2.3 句子處理器
同樣的詞在不同的語境條件下,表達含義有所不同。 傳統的Word2Vec 或Glove 方式生成的詞向量模型是固定的,這顯然不符合實際語境的使用情況。 基于此,模型中使用ELMo[14]作為句子處理器,生成動態張量,使實體在不同語境下生成不同的特征張量,以獲取更加豐富的上下文信息。
對于輸入語句T= (t1,t2,…,tN),前向語言模型通過(t1,t2,…,tk-1)條件下tk(1 <k<N)的概率建模計算整個序列的概率:

后向語言模型也是同理:

綜上,最大似然函數為

式中:θx為字符向量的參數;θs為Softmax 層的參數。
ELMo 是BiLSTM 的中間層表示任務的特定組合,對于每一個xk,一個L層雙向語言模型可以得到2L+1 個結果。

而在通常情況下,查找字符向量的方法僅為查找表中的字符提供一層表示。

式中:ELMok為字符tk的ELMo 詞向量;u為Softmax 的正則化權重;γ為縮放因子,允許任務模型縮放整個ELMo 向量。
ELMo 模型輸出含有上下文信息的結果αELMo:

2.4 自注意力模塊
對上下文字信息建模的方式一般是將所有字符表示形式連接起來或取平均值,但是當存在許多不相關的上下文詞匯信息時,這一方式的結果并不理想。 為了選取高度相關的上下信息,采用Sself-Attention 模型[16]來獲取上下文與實體之間的關聯性。

式中:Q、K、V三個矩陣來自同一輸入;dk為Q和K向量的維度。
Self-Attention 計算后可得
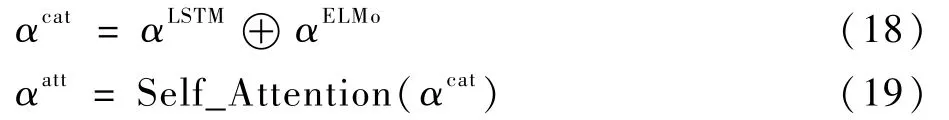
式中:αcat為將αLSTM與αELMo的拼接結果;⊕表示將2 個特征進行拼接;αatt為Self-Attention 模型輸出的含有實體間相關程度的信息。
2.5 條件隨機場
LSTM 等模型得出的結果是字符對應各個類型的分數,最高分數對應的類型便是預測結果。然而這樣的分類方式忽略了字符對應于其他類型的分數,經常會預測出一些非合法實體類型情況(如“B-ORG I-PER”)。
CRF 是給定一組輸入序列條件下另一組輸出序列的條件概率分布模型[28]。 通過CRF 加入一些約束來保證最終預測結果的正確性,這些約束可以在訓練數據的過程中被CRF 自動學習。CRF 的最終得分是通過計算轉移特征概率和狀態特征概率實現的。 目前,CRF 已經廣泛應用于諸多NER 模型(如文獻[29-31])。
輸入特征向量為α=(α1,α2,…,αN),其對應的標簽序列(tag)為Y={y1,y2,…,yN},定義分數為

式中:Ayi,yi+1為轉移矩陣,表示從標簽yi到標簽yi+1的傳輸得分;Pαi,yi為經過LSTM 編碼后的αi字符的yi標簽的得分。
CRF 定義了在所有可能的標簽序列Y上的條件概率p()為
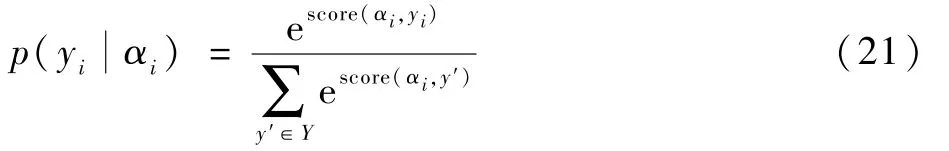
訓練過程中,使用最大條件似然估計方法,選擇使對數似然L最大化的參數,并使用一階Viterbi 算法在輸入序列上找到得分最高的標簽序列,求解最優路徑:

2.6 圖卷積神經網絡
區別于日常的圖片,本文的“圖”是一種數據格式,可以用于表示各種具有抽象意義的拓撲關系網絡,如通信網絡、蛋白分子網絡、社交網絡等,圖中的節點表示網絡中的個體,邊表示個體間的連接關系。 傳統的卷積主要針對歐氏數據空間,而在非歐氏數據空間無法保持“平移不變性”。 為了提取和挖掘非歐氏數據空間的有效空間關系進行建模學習,Kipf 和Welling[32]引入了GCN。
在GCN 中,每個圖都可以定義為G= (Z,E),Z為節點(字)的集合,S為邊(關系)的集合。圖中第l層輸出特征H(l)計算如下:
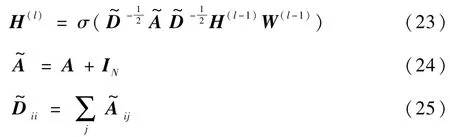
式中:第l層網絡的輸入為∈(初始輸入為H(0)=X),N為圖中節點數量(即句子長度),每個節點使用D維特征向量表示;為添加了自連接的鄰接矩陣,A為鄰接矩陣,IN為單位矩陣;為 度 矩 陣;W(l-1)∈RD×D為 待 訓 練 參 數;σ為激活函數。
本文中,在這一基礎上加入偏置,可以得圖特征為
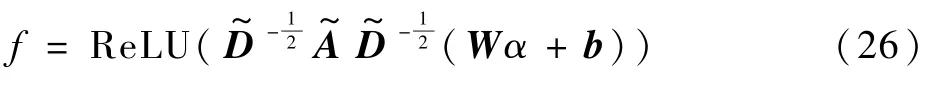
式中:W為權重,b為偏置,均為可訓練參數;α為輸入GCN 網絡的實體特征;ReLU 為非線性激活函數。
本文中,G1和G2分別為對于實體的實體相鄰圖和關系圖的圖網絡(見圖5 和圖6)。G2中,對于從外部模塊中提取的實體中的所有節點,在任意2 個節點eij=(vi,vj)之間添加邊,start≤i<j≤end,其中包含最外層實體信息;G1中,主要是對于句子中相鄰實體字符,從左到右添加一個有向邊,從而可以利用局部上下文信息。


圖5 G1 實體相鄰圖Fig.5 Entity adjacent graph (G1)

圖6 G2 實體關系圖Fig.6 Entity relationship graph (G2)
通過GCN 獲取圖特征F={f1,f2,…,fN}后,可以求得內層的實體得分M∈RN×N×L:

式中:W1,W2∈,W3∈Rdf×L,L為實體類型數量;Mij∈RL表示范圍的類型概率從ti開始到tj結束。 對于內部實體,將字符(ti,tj)中的真實實體定義為,ti為起點,tj為終點。 計算交叉熵(cross entropy)得
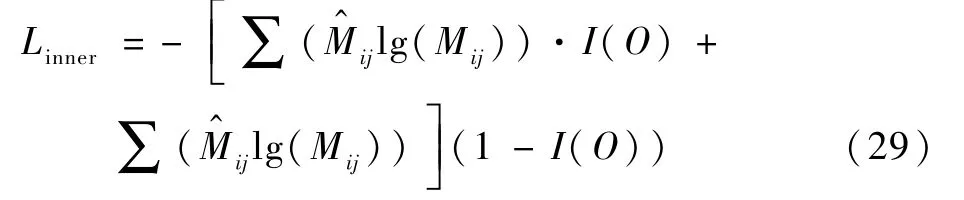
式中:I(O)用來區分非實體“O”和其他實體類型的損失,定義如下:

對于外層實體,采用CRF 計算損失,CRFX為外部模塊獲取的最外層實體損失,CRFXnew為經過GCN 提取后的最外層實體損失:

模型預測最外層實體和內部實體,損失定義為

式中:λ1為外部模塊和內部模塊損失之間的權重。
2.7 實體校正模塊
校正模塊屬于后處理內容。 神經網絡最后的輸出結果一般為字符對應各個類型的分數。 由于模型預測的部分結果并不準確,即使經過CRF 處理,也依然會出現一些實體類型正確而邊界判斷錯誤的情況。 假設網絡經過一系列運算后,最終得到的是一個m×n的向量,m為當前輸入模型的句子長度,n為實體類型數量,則該m×n的向量是模型對這一語句每個字所屬類型的評分,最高評分所在列的索引就是模型預測的實體類型。
實際預測結果中,會出現一些實體類型正確而邊界判斷錯誤的情況。 以圖7 中“輕水堆”為例,預測結果為“9 9 9”(對應標簽為“I-REA I-REA I-REA”),對照表2,該實體屬于“反應堆類”,實體類型判斷正確,但“輕水堆”的實際類型應該是“8 9 9”(對應標簽為“B-REA I-REA IREA”)。

表2 實體類型編號對照Table 2 Table of entity type number

圖7 核電語料實體類型對比Fig.7 Comparison of nuclear power corpus entity types
3 實驗結果與分析
3.1 實驗參數設置
實驗中,隨機劃分60% 的語料作為訓練集,20%作為測試集,20% 作為開發集。 字向量維度為50 維,迭代次數epoch 為50 次,梯度下降學習率為0.000 1,學習率衰減因子為0.8,使用Adam優化算法加快收斂速度,以交叉熵計算模型損失函數。
3.2 實驗指標

模型評價采用準確率P、召回率R和F1值作為評價指標,其中F1值綜合了準確率和召回率,可以體現模型的均衡性,各項指標計算公式為進行比較。 結果表明,本文模型在各項指標均優于其他模型。 與本文模型相比,常用的LSTM 模型[12]對于Nested NER 預測效果差,無法對文中的實體進行準確識別;BiFlaG[25]的側重點偏向于實體間的關系,忽略了句子中上下文信息的提取;BiLSTM +CRF[13]對Nested NER 所占比例大的語料中命名實體的分詞能力有限,無法獲取實體與實體之間的關系;MGNER 模型[24]中預測實體后,根據實體內部關系進行細粒度判斷,這樣的判斷方式更加適用于英文。
總的來看,本文模型相較MGNER,P提高6.31%,R提高7.6%,F1提高6.95%;相較BiFlaG,P提高9.52%,R提高8.51%,F1提高9.02%,網絡各方面性能均優于其他網絡。
表4 對BiFlaG 模型和MGNER 模型在核電數據集中的4 種分類進行了詳細比較。 從結果來看,3 個模型對“專有名詞類”(NOU)的識別準確率最高,而“燃料與材料類”(FUE)識別準確率較差。 從數據的角度分析這一情況,在“專有名詞類”實體中,Nested NER 在文本中的詞頻較低,因而在訓練過程中對網絡判斷造成的干擾不大,結果正確率普遍較高;“燃料與材料類”的實體識別效果不佳,是由于該類命名實體在文本中,數量及出現頻率都低于其他3 類,直接導致在神經網絡訓練過程中,神經網絡對該類命名實體類型判斷出現誤判,導致準確率較低。

表4 分類結果對比Table 4 Comparison of classification results %
式中:TP 為正類預測為正類數;TN 為負類預測為負類數;FP 為負類預測為正類數(誤報);FN 為正類預測為負類數(漏報)。
3.3 實驗結果比較
表3 將本文模型與其他模型在核電數據集中
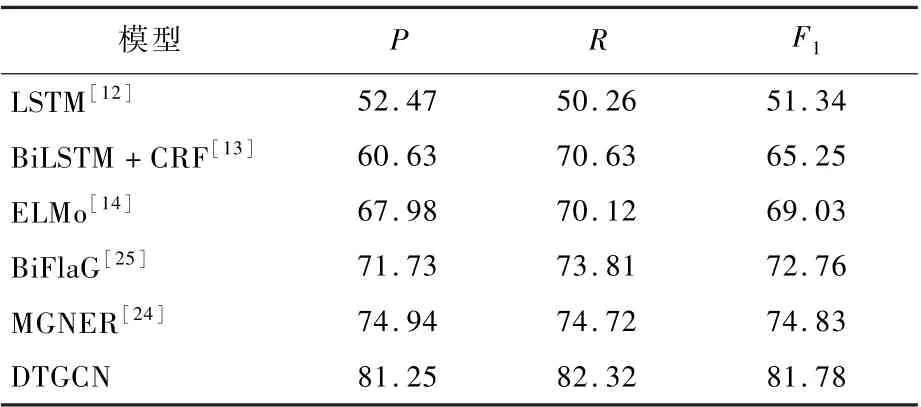
表3 模型實驗結果對比Table 3 Comparison of model experimental results%
3.4 消融實驗
本文使用ELMo 從句子的角度獲取實體信息,用Self-Attention 獲取實體與句中其他實體的依賴關系,校正模塊則將模型預測結果中實體類型正確而邊界判斷錯誤的情況進行校正。 本節進行消融實驗驗證其有效性。 表5 中,“①”指本文模型本身;“②”指Self-Attention,不含ELMo與校正模塊;“③”指ELMo,不含Self-Attention 與校正模塊;“④” 指校正模塊,不含Self-Attention 與ELMo;“⑤”指Self-Attention 與校正模塊;“⑥”指校正模塊與ELMo;“⑦”指Self-Attention 與ELMo。總的來看,自注意力模塊對網絡的準確率P提高為1.03%;ELMo 對網絡準確率P提高為1.81%;校正模塊對網絡準確率P提高為2.96%。
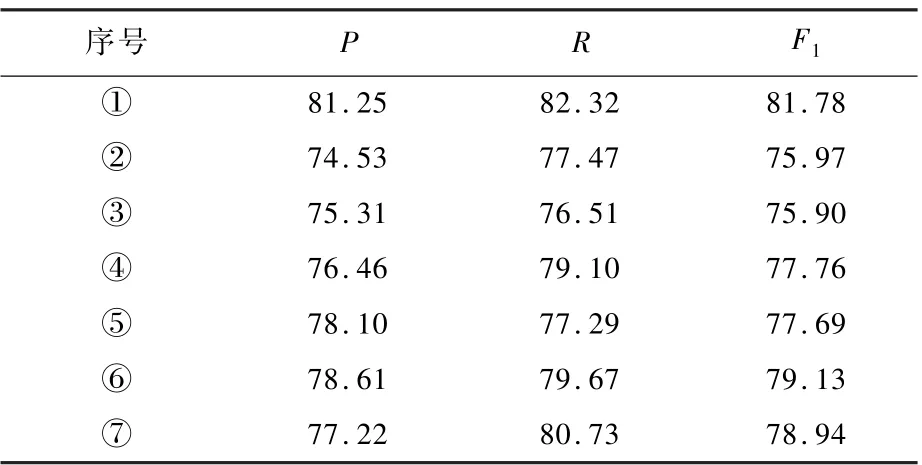
表5 消融實驗結果Table 5 Experimental results of ablation %
4 結 論
1) 本文完成了數據搜集工作,其主要來源是反應堆熱工分析與反應堆物理分析,這些數據在很大程度上可以代表核安全文本的數據特征,且不涉密、資料多,是理想的研究對象。
2) 完成了數據的分類工作,主要分為“專有名詞類”、“冷卻與冷卻劑類”、“燃料與材料類”與“反應堆類”四大類。 “冷卻與冷卻劑類”實體數量最多,有1 365 個,“燃料與材料類”實體數量最少,僅207 個。 同時完成了語料的標注工作,標注數據8 023 句141 057 條。
3) 通過對比實驗,驗證多個網絡在當前數據集中的性能。 結合研究中遇到的嵌套命名實體問題,在現有研究的基礎上進行改進,得到DTGCN網絡。 網絡中包含外部模塊和內部模塊,2 個模塊分別學習外部實體信息和內部實體信息,結合規則判定的方法對實體類型正確而邊界判斷錯誤的預測結果進行校正。 實驗結果表明,本文模型對于嵌套命名實體的識別效果優于其他模型,在準確率與召回率指標上提升顯著,如較BiFlaG 模型,準確率提高9.52%,召回率提高8.51%,F1值提高9.02%。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中外會展(2014年4期)2014-11-27 07:46:46
中學數學雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
