基于深度學(xué)習(xí)的t-fMRI腦狀態(tài)解碼
2023-01-13 13:33:40付佳俊盧梅麗曹一凡郭兆樺高資成
付佳俊,盧梅麗,曹一凡,郭兆樺,高資成
(天津職業(yè)技術(shù)師范大學(xué)信息技術(shù)工程學(xué)院,天津 300222)
大腦是人類最復(fù)雜的器官之一,控制著人類的高級(jí)情感和復(fù)雜行為。如今人們對(duì)大腦的認(rèn)知仍十分有限,相關(guān)學(xué)者一直試圖解開大腦工作原理之謎。大腦會(huì)根據(jù)人執(zhí)行任務(wù)的差異而產(chǎn)生不同的反應(yīng),任務(wù)態(tài)功能磁共振成像(task functional magnetic resonance imaging,t-fMRI)是一種通過測(cè)量血液動(dòng)力學(xué)間接刻畫大腦神經(jīng)活動(dòng)的影像數(shù)據(jù),現(xiàn)已成為使用最廣泛的腦功能研究手段之一。其獲取方式為先對(duì)信號(hào)去噪[1],再使用多層同時(shí)掃描技術(shù)[2]快速采集功能磁共振全腦影像。功能磁共振成像能對(duì)特定的大腦活動(dòng)皮層區(qū)域進(jìn)行精準(zhǔn)定位,且能實(shí)時(shí)跟蹤信號(hào)的改變,其空間分辨率和時(shí)間分辨率分別可以達(dá)到2 mm和1 s。多年來,研究人員一直試圖通過功能磁共振成像解碼識(shí)別人腦功能。其中,多體素模式分析(multi-voxel pattern analysis,MVPA)[3]是最常用的方法之一。MVPA的核心原理是在不同認(rèn)知狀態(tài)下,利用獨(dú)立的實(shí)驗(yàn)數(shù)據(jù)測(cè)試由多個(gè)體素信號(hào)形成的空間模式訓(xùn)練分類器的性能。盡管MVPA很受歡迎,但需要人為選取特征,可重復(fù)性差且耗時(shí)。
隨著深度學(xué)習(xí)的發(fā)展,越來越多基于深度學(xué)習(xí)的方法被運(yùn)用于影像數(shù)據(jù)分析。Dvornek等[4]使用基于Long Short-Term Memory的遞歸神經(jīng)網(wǎng)絡(luò),通過靜態(tài)fMRI對(duì)ASD患者對(duì)照和進(jìn)行分類。Eickenberg等[5]利用基于卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural network,CNN)的模型,通過fMRI信號(hào)對(duì)觀看自然風(fēng)景的大腦進(jìn)行預(yù)測(cè)。Seeliger等[6]根據(jù)生成對(duì)抗網(wǎng)絡(luò),借助fMRI信號(hào)來重構(gòu)視覺圖像。Wen等[7]使用深度殘差神經(jīng)網(wǎng)絡(luò)模擬視覺皮層處理,提供了一種高效策略,以建立高維和分層視覺特征的皮質(zhì)表征預(yù)測(cè)模型。Zhao等[8]基于三維卷積,開發(fā)了一種用以識(shí)別和分類不同類型的功能性腦網(wǎng)絡(luò)。Khosla等[9]使用一種三維卷積神經(jīng)網(wǎng)絡(luò)方法實(shí)現(xiàn)集成學(xué)習(xí)策略,該方法利用了rs-fMRI數(shù)據(jù)的全分辨率三維空間結(jié)構(gòu),并適合非線性預(yù)測(cè)模型。與傳統(tǒng)機(jī)器學(xué)習(xí)方法不同,深度學(xué)習(xí)可以自動(dòng)提取數(shù)據(jù)的特征,以達(dá)到自動(dòng)分類的目的。卷積神經(jīng)網(wǎng)絡(luò)作為當(dāng)下使用最多的方法之一,越來越多的人將其運(yùn)用于fMRI分類中。深度學(xué)習(xí)通過多層網(wǎng)絡(luò)的非線性變換自動(dòng)提取數(shù)據(jù)中的隱含特征,但是由于缺乏對(duì)其內(nèi)部工作機(jī)理的理解與分析,通常被看作“黑盒”模型,導(dǎo)致用戶只能觀察模型的預(yù)測(cè)或分類結(jié)果,而不能了解模型產(chǎn)生決策的依據(jù)。尤其在醫(yī)療數(shù)據(jù)的應(yīng)用場(chǎng)景中,僅向用戶提供最終的預(yù)測(cè)結(jié)果而不解釋其原因,很難讓用戶信任和理解該模型。因此,對(duì)模型分類結(jié)果進(jìn)行可解釋性分析至關(guān)重要[10-13]。
鑒于fMRI數(shù)據(jù)的高維特性,本文采用三維卷積神經(jīng)網(wǎng)絡(luò)模型(3D-CNN)[14]對(duì)其進(jìn)行分類,并與支持向量機(jī)(support vector machine,SVM)在不同評(píng)價(jià)指標(biāo)下進(jìn)行比較。同時(shí),通過梯度加權(quán)類激活映射方法(Grad-CAM)[15]和導(dǎo)向梯度加權(quán)類激活映射方法(Guided Grad-CAM)對(duì)3D-CNN進(jìn)行可解釋性分析,以可視化的方式定位得到輸入樣本中影響3D-CNN決策的關(guān)鍵因素,以確定特定任務(wù)下所激活的功能腦區(qū)。
1 數(shù)據(jù)集與實(shí)驗(yàn)方法
1.1 實(shí)驗(yàn)數(shù)據(jù)
1.2 3D-CNN
在CNN被廣泛使用之前,大多圖片分類實(shí)驗(yàn)使用全連接神經(jīng)網(wǎng)絡(luò)。全連接神經(jīng)網(wǎng)絡(luò)雖然在最終的分類結(jié)果上表現(xiàn)較好,但是也存在以下缺點(diǎn):圖像展開為向量,丟失空間信息;參數(shù)過多,效率低下,訓(xùn)練困難;大量的參數(shù)易導(dǎo)致網(wǎng)絡(luò)過擬合。CNN的提出恰好解決了以上問題。卷積操作能很好地提取數(shù)據(jù)的相鄰空間信息,避免數(shù)據(jù)的像素展開成向量后造成的空間信息損失。相比二維卷積,三維卷積增加了空間維度,其輸入數(shù)據(jù)和卷積核均為三維,表示為(P,Q,R),卷積操作如圖1所示。
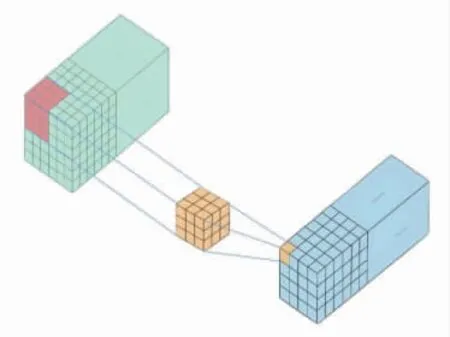
圖1 三維卷積操作示意圖
對(duì)于功能磁共振數(shù)據(jù),三維卷積能有效提取其空間特征。三維卷積操作如下
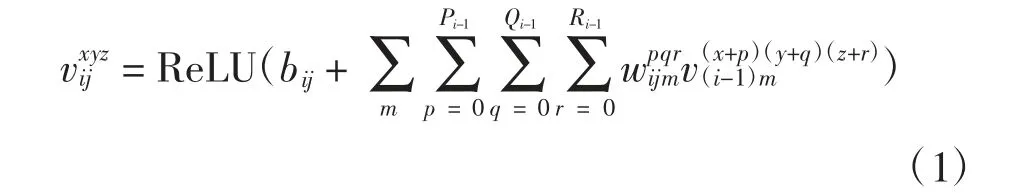
式中:vxyzij表示網(wǎng)絡(luò)第i層通道為j位于(x,y,z)的值;bij為偏置;wpqrijm表示通道為m的卷積核位于(p,q,r)的值。
本研究基于三維卷積方法,構(gòu)建了一種用于識(shí)別任務(wù)態(tài)功能磁共振成像的三維卷積神經(jīng)網(wǎng)絡(luò)(3DCNN)。該神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)是由輸入層、卷積層、池化層、激活函數(shù)層以及全連接層拼接而成。卷積層由多層三維卷積構(gòu)成,是網(wǎng)絡(luò)的核心層,網(wǎng)絡(luò)中大部分的計(jì)算量都來源于此層。池化層對(duì)數(shù)據(jù)進(jìn)行下采樣,從而減少網(wǎng)絡(luò)參數(shù)量。激活函數(shù)層為網(wǎng)絡(luò)增加了非線性因子,非線性激活函數(shù)能夠在輸入、輸出之間生成非線性映射。全連接層則是為了融合前面提取的特征,最后在輸出層對(duì)數(shù)據(jù)類別進(jìn)行預(yù)測(cè)。3D-CNN網(wǎng)絡(luò)結(jié)構(gòu)如圖2所示。
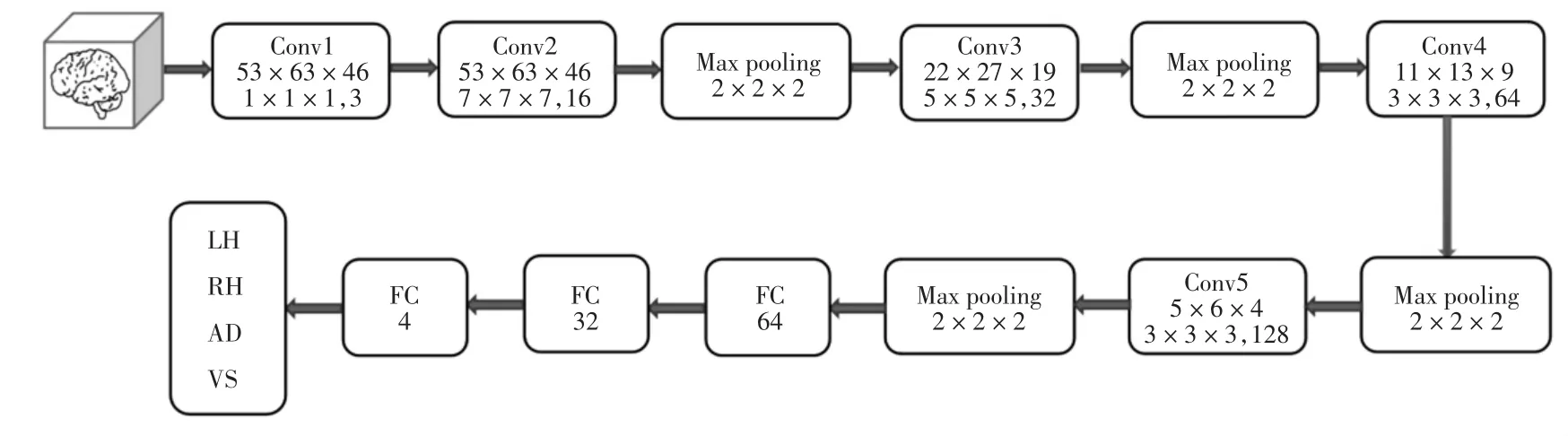
圖2 3D-CNN網(wǎng)絡(luò)結(jié)構(gòu)
3D-CNN網(wǎng)絡(luò)由5層卷積層和3層全連接層組成。輸入的原始數(shù)據(jù)通道大小為1。其中,第1層卷積層的輸入大小為53×63×46,輸出通道大小為3,卷積核的大小為1×1×1。卷積核設(shè)置為1×1×1,目的是將圖片通道變?yōu)?,以便后續(xù)可使用Guided Grad-CAM進(jìn)行可視化。整個(gè)網(wǎng)絡(luò)的池化層大小為2×2×2,全連接層的長(zhǎng)度分別是64、32,最后是一個(gè)四分類的全連接層,分別對(duì)應(yīng)LH、RH、AD、VS。損失函數(shù)選擇交叉熵?fù)p失函數(shù),其在做分類(具體幾類)訓(xùn)練時(shí)用。優(yōu)化器被用來更新和計(jì)算影響模型訓(xùn)練和模型輸出的網(wǎng)絡(luò)參數(shù),使其逼近或達(dá)到最優(yōu)值,從而最小化損失函數(shù)E(x)。常用的優(yōu)化器有Adam、SGD、RMSprop等,本研究選用SGD優(yōu)化器。訓(xùn)練時(shí)網(wǎng)絡(luò)的學(xué)習(xí)率設(shè)置為0.001,動(dòng)量參數(shù)設(shè)置為0.9,權(quán)重衰減為0.000 5,batch大小為64。
1.3 支持向量機(jī)
支持向量機(jī)是在分類與回歸分析中分析數(shù)據(jù)的監(jiān)督式學(xué)習(xí)模型與相關(guān)的學(xué)習(xí)算法。在深度學(xué)習(xí)被廣泛運(yùn)用之前,SVM是監(jiān)督學(xué)習(xí)中最具影響力的算法之一。該算法的核心思想是找出最大的決策邊界,從而達(dá)到能最大程度分類數(shù)據(jù)的目的。SVM最初主要是用來解決二分類問題,在這個(gè)基礎(chǔ)上進(jìn)行擴(kuò)展后,也能夠處理多分類問題以及回歸問題。具體實(shí)驗(yàn)步驟如下:
(1)對(duì)fMRI數(shù)據(jù)進(jìn)行預(yù)處理,為提高輸入特征的有效度,將所有數(shù)據(jù)去除背景(設(shè)為0)并僅保留大腦體素。去除背景前后的數(shù)據(jù)(Axial方向的切片)對(duì)比如圖3所示。

圖3 預(yù)處理前與預(yù)處理后的t-fMRI數(shù)據(jù)對(duì)比
(2)將之前的三維數(shù)據(jù)(X,Y,Z)轉(zhuǎn)換為(X*Y*Z)。由于功能磁共振成像數(shù)據(jù)的復(fù)雜性,并不是每一個(gè)特征值都能很好地體現(xiàn)區(qū)分度,故某些特征值不存在分析的價(jià)值。將轉(zhuǎn)換后的數(shù)據(jù)表示為X=(X0,X1,…,Xn-1)m×n,其中,Xj=[x0j,x1j,…,x(m-1)j]T。通過設(shè)置方差閾值去除不必要的特征,以提取關(guān)鍵的大腦區(qū)域。計(jì)算式為
2016年,倦怠發(fā)生比例最高的是重癥醫(yī)學(xué)(55%)、泌尿醫(yī)學(xué)(55%)和急診醫(yī)學(xué)(55%);2017年,倦怠比例發(fā)生最高的是急診醫(yī)學(xué)(59%)、婦科醫(yī)學(xué)(56%)和家庭醫(yī)學(xué)(55%);2018年倦怠發(fā)生比例最高的是重癥醫(yī)學(xué)(48%)、神經(jīng)醫(yī)學(xué)(48%)和家庭醫(yī)學(xué)(47%)。見表1。
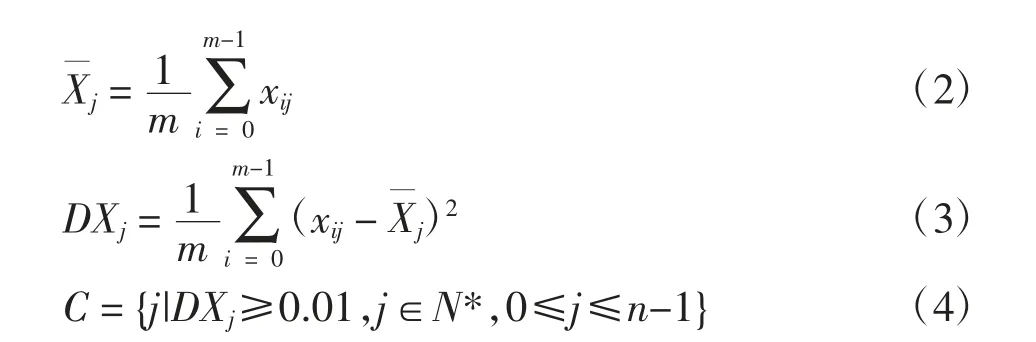
(3)使用LinearSVC對(duì)數(shù)據(jù)進(jìn)行分類。LinearSVC是根據(jù)liblinear實(shí)現(xiàn)的線性分類支持向量機(jī),既能實(shí)現(xiàn)二分類,也能實(shí)現(xiàn)多分類。
1.4 腦激活定位
執(zhí)行不同任務(wù)時(shí)會(huì)激活對(duì)應(yīng)的腦區(qū),為了探索這種相關(guān)性,借助分類結(jié)果,采用可視化的方式對(duì)其進(jìn)行定位。相關(guān)實(shí)驗(yàn)表明,CNN的卷積層能提取輸入數(shù)據(jù)的空間位置信息,因此卷積層具有定位的能力。基于此能力,可以獲取圖像中影響CNN決策的關(guān)鍵因素。但是為了整合卷積層所提取的特征,CNN網(wǎng)絡(luò)使用了全連接層,這樣破壞了CNN的定位能力。為了解決這個(gè)問題,Zhou等[16]提出了類激活映射(class activation mapping,CAM)解釋方法。CAM以熱力圖的形式可視化類激活圖,即使用全局平均池化(global average pooling,GAP)替代CNN最后的全連接層。CAM雖然能減少CNN的訓(xùn)練參數(shù),但是造成了網(wǎng)絡(luò)結(jié)構(gòu)的改變,所以需要重新訓(xùn)練網(wǎng)絡(luò),這無疑是很耗時(shí)的一項(xiàng)工作。因此,本文采用效率更高的Grad-CAM方法,Grad-CAM是CAM的一種泛化形式,該算法不需要對(duì)網(wǎng)絡(luò)重新訓(xùn)練。Grad-CAM的計(jì)算為

式中:c為網(wǎng)絡(luò)判別的類別;yc為該類別對(duì)應(yīng)的logits(即沒經(jīng)過Softmax的值);A為卷積輸出的特征圖(最后一層卷積);k為特征圖的第k通道;i、j分別為特征圖的橫、縱坐標(biāo);Z為特征圖的大小(即長(zhǎng)×寬)。
這一過程是求特征圖上梯度的均值,相當(dāng)于一個(gè)全局平均池化操作。
得到權(quán)重后將特征圖在通道維度上進(jìn)行線性加權(quán),融合得到熱力圖,如式(6)。Grad-CAM對(duì)融合后的熱力圖增加一個(gè)ReLU操作,只保留與結(jié)果呈正相關(guān)的值。
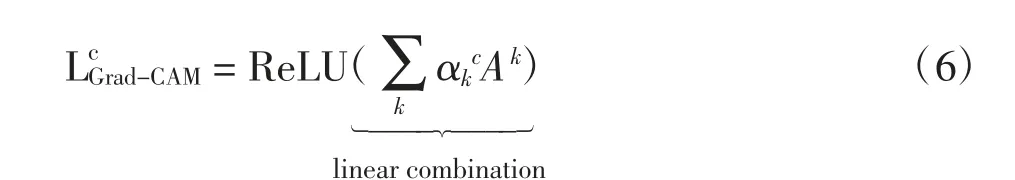
一般來說,Grad-CAM在2D數(shù)據(jù)上會(huì)有更好的表現(xiàn)。因此,從3D數(shù)據(jù)fMRI中提取Axial方向的2D切片,再把提取出來的切片作為Grad-CAM的輸入。
Grad-CAM是一種以粗粒度的方式對(duì)影響CNN決策的關(guān)鍵因素進(jìn)行可視化的方法,缺少了如GuidedBP[17]這樣像素級(jí)別的細(xì)粒度可視化效果。因此,本文繼續(xù)采用Guided Grad-CAM,對(duì)CNN網(wǎng)絡(luò)進(jìn)行細(xì)粒度的可視化解釋,Guided Grad-CAM由Grad-CAM與GuidedBP結(jié)合而成。在GuidedBP中,舍棄第一層卷積層,直接獲取第二層卷積層的梯度。
2 實(shí)驗(yàn)結(jié)果與分析
本實(shí)驗(yàn)硬件環(huán)境基于Windows平臺(tái),配置為11 th Gen Intel Core i7-11800H,NVIDIA GeForce RTX 3070顯卡。實(shí)驗(yàn)代碼均使用Python編程語(yǔ)言。
為了更好地對(duì)比3D-CNN與SVM的性能,采用4個(gè)常用的評(píng)價(jià)指標(biāo):準(zhǔn)確率(Accuracy,ACC)、精確率(Precision)、召回率(Recall)以及F1-score。表1展示了4種任務(wù)態(tài)在不同模型中各個(gè)評(píng)價(jià)指標(biāo)的情況。
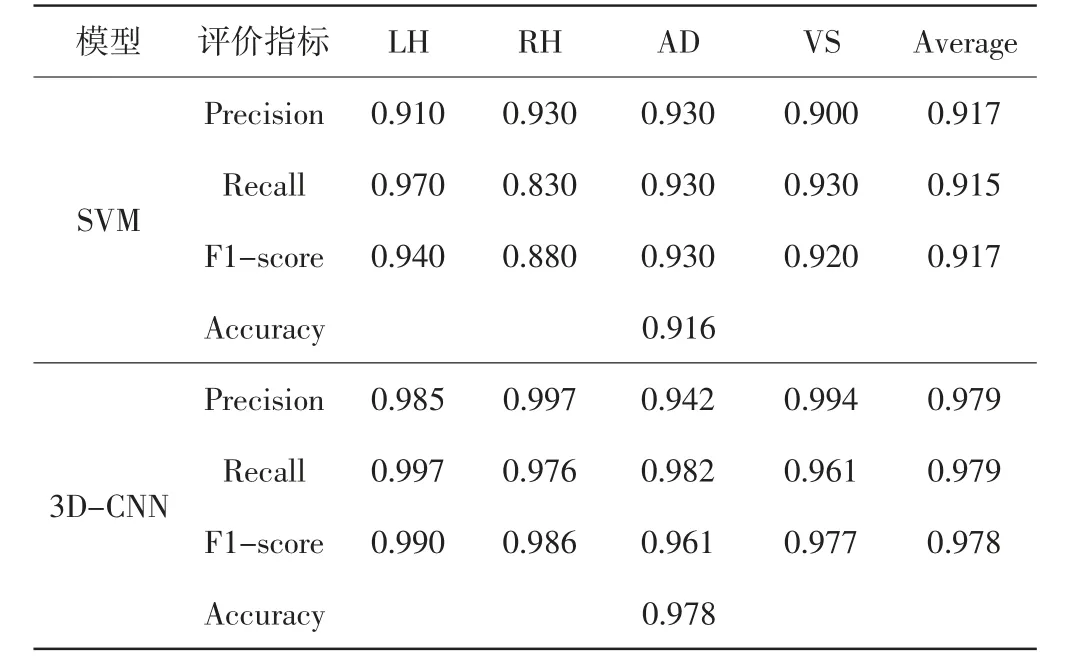
表1 SVM和3D-CNN模型在不同評(píng)價(jià)指標(biāo)上的表現(xiàn)
從表1可知,3D-CNN在各個(gè)指標(biāo)上的數(shù)據(jù)都優(yōu)于SVM,產(chǎn)生這種現(xiàn)象很大程度上是由于三維fMRI數(shù)據(jù)在轉(zhuǎn)換為一維數(shù)據(jù)過程中丟失了信息。而3DCNN的輸入是原始數(shù)據(jù),因此很好地保留了數(shù)據(jù)的空間特征。
圖4為3D-CNN模型在訓(xùn)練時(shí)的損失曲線,從圖4可以看出,模型在40次迭代后已基本趨于收斂。
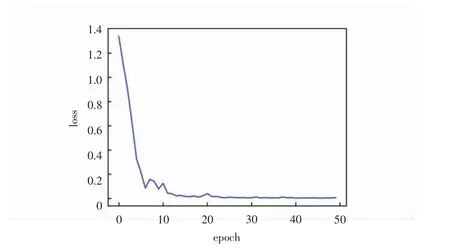
圖4 3D-CNN訓(xùn)練時(shí)的損失曲線
可視化結(jié)果如圖5所示。

圖5 Grad-CAM和Guided Grad-CAM在4種不同t-fMRI上的可視化結(jié)果
從4種不同t-fMRI中分別選出3幅在Axial方向的圖像。在每張圖中,第1列為原始圖像,第2列為Grad-CAM中的熱力圖,第3列和第4列分別為Grad-CAM和Guided Grad-CAM的可視化結(jié)果。相關(guān)研究表明,當(dāng)人使用左(右)手時(shí),右(左)腦會(huì)產(chǎn)生反應(yīng)。大腦中負(fù)責(zé)聽覺處理的主要部位是顳橫回,距狀溝則負(fù)責(zé)視覺處理。其中,顳橫回位于大腦外側(cè)溝下壁上,距狀溝位于腦半球內(nèi)側(cè)面后部。對(duì)比圖5發(fā)現(xiàn),其可視化結(jié)果與實(shí)際研究相符,即左(右)手握緊激活右(左)腦區(qū),聽覺刺激激活大腦中央,視覺刺激激活大腦后部。
3 結(jié)語(yǔ)
本文提出的3D-CNN模型能很好地對(duì)任務(wù)態(tài)fMRI進(jìn)行分類,與傳統(tǒng)機(jī)器學(xué)習(xí)算法SVM相比,3DCNN具有更好的分類效果,其能直接對(duì)t-fMRI進(jìn)行分類,無需人為特征提取,并且避免了高維數(shù)據(jù)轉(zhuǎn)換為一維數(shù)據(jù)時(shí)造成的空間信息丟失。通過采用Grad-CAM和Guided Grad-CAM對(duì)3D-CNN進(jìn)行可解釋性研究,確定了不同任務(wù)狀態(tài)下所激活的大腦區(qū)域,從而達(dá)到通過t-fMRI解碼大腦活動(dòng)狀態(tài)的目的。
猜你喜歡
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
海洋信息技術(shù)與應(yīng)用(2020年1期)2020-06-11 12:43:56
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
傳媒評(píng)論(2019年4期)2019-07-13 05:49:14
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
