基于視頻關鍵幀提取和三維卷積的行為識別
2023-01-13 13:33:42方婷紅董建設楊正昊王志凌
天津職業技術師范大學學報 2022年4期
方婷紅,董建設,楊正昊,王志凌
(天津職業技術師范大學信息技術工程學院,天津 300222)
近年來,隨著計算機視覺技術的發展,各種技術成果層出不窮,人體行為識別技術也逐漸得到廣泛重視,其應用領域也日益廣泛,如虛擬現實、視頻監控、醫療衛生等領域。早期,提出了一種基于人工識別的方法,即利用傳統的機器學習算法,從物體的局部或整體特征中抽取出物體的局部或整體特征,并將所提取的特征進行編碼和標準化,最終將所提取的特征進行訓練,從而獲得相應的預測分類效果。傳統的行為識別方法主要是對視頻區域的局部高維視覺特征進行提取,再把提取的特征剪裁成固定大小的視頻片段,最后利用分類器進行最終的分類識別。其中,Laptev[1]研究發現了局部表示方式的時空興趣點檢測(STIPS)方法,在時域空域中提取興趣點作為時域空域中變化的鄰域點,由此來描述視頻中的人體局部特征,從而進行行為識別。由于Laptev的方法存在提取有用興趣點過少的不足,Dollar等[2]在此基礎上,提出了采用Gabor濾波器結合高斯濾波器,增加穩定的興趣點進行行為識別的方法。Richardson等[3]提出了馬爾科夫邏輯網絡(Maikov logic networks),該網絡能夠描述運動之間的時間和空間關系,提高行為識別的準確率。Wang等[4]提出密集軌跡(dense trajectory,DT)算法,在每個空間尺度上進行密集采樣,之后在每個空間尺度上再次進行分別追蹤,形成軌跡描述來對行為識別進行分類。但移動的相機,會對行為識別的準確率產生影響,因此Wang等[5]對光流圖像進行了優化,并對密集軌跡(improved dense trajectory,iDT)算法進行了改進,用于人體行為識別。
基于人工特征的提取方法已經比較成熟,但這種方法只針對固定的圖像進行特征抽取,不能保證視頻的普遍性,且運算速度很慢,難以適應實時需求。隨著深度學習的深入研究,新方法已經逐步替代了以往的方法,得到了更為高效、準確的信息。目前的主流算法有3種:雙流神經網絡、3D卷積神經網絡和多種混合網絡。Simonyan等[6]利用2個單獨的網絡分別提取時間、空間特征,使用Two-stream方法進行行為識別。Ji等[7]利用三維卷積核提取連續視頻幀中的運動信息,采取基于3D卷積神經網絡進行行為識別。Tran等[8]提出C3D模型,直接提取視頻的行為特征,將3D卷積核大規模地應用于行為視頻中。呂淑平等[9]提出了(2+1)D的卷積方式代替3D卷積,加深了網絡結構,有利于對運動時間較長、視頻像素更豐富的視頻進行有效學習。Diba等[10]在C3D的基礎上結合了DenseNet網絡模型,極大地減少了網絡結構參數量,但網絡模型中的稠密鏈接增加了計算負荷。羅會蘭等[11]提出了空間卷積注意力機制(SCA)結合時間卷積注意力機制(TCA),獲取人體行為視頻的時間與空間信息。吳麗君等[12]提出了通道注意力機制結合時間注意力機制,通過調整網絡的卷積層和池化層的順序,有效保留了更多的通道信息和時間信息。Donahue等[13]在卷積網絡CNN中加入了長短時記憶網絡模型,分別對輸入的人體行為視頻進行視覺特征學習和隔離學習,在行為識別方向上取得了不錯的結果。Ng等[14]為了解決卷積網絡因提取信息不夠完全而導致行為類別識別不準確的問題,采用全局視頻級別的卷積網絡結合長短時記憶網絡進行時空上的特征提取。Li等[15]將可視注意力機理與可視注意模式相結合,從而使其更好地改善行為辨識的正確性。Liu等[16]在空間維中引入了空間信息的稀疏性,并采用一種輕量化的組幀網(GFNet),實現對圖像的行為識別。Yang等[17]采用一種用于行為識別的快速插入式的時間金字塔網絡(TPN)。Arnab等[18]將人體行為視頻構建成一組時空標簽和位置編碼,作為Transformer輸入對人體行為進行識別。C3D網絡能夠對視頻直接提取時空特征,但原始的C3D網絡模型采用隨機提取視頻幀的方式對視頻進行處理,導致提取出的視頻幀的冗余信息較多,對行為識別率影響也較大。為此,本文提出一種基于視頻關鍵幀提取的C3D網絡模型算法,利用視頻聚類關鍵幀提取技術消除對數據的冗余性問題,提取少量具有代表性的關鍵幀作為網絡模型的輸入,采用以0.5的概率對已提取的關鍵幀進行水平翻轉,并進行數據增強,在原始C3D模型中引入注意力機制(convolutional block attention module,CBAM)對關鍵幀進行特征提取。
1 人體行為識別算法
1.1 C3D神經網絡
C3D神經網絡是一種具有典型意義的立體卷積方法,相對于二維卷積,3D卷積由于三維卷積和三維池化的運算性質,能夠較好地抽取出時間區域的特征。2D卷積無論輸入單通道圖像還是多通道圖像,結果均為單張圖像,損失了時間域上的信息。3D卷積輸出保持空間域上的特征,是立體的輸出。同樣,對于3D池化操作來說,也保持著時空特征。該網絡的輸入是視頻片段,輸出是數據集類別的標簽。所有的影像畫面尺寸均為128×171。同時,將該片段分割成16個畫面,以3×16×128×171的形式輸入到網絡中。C3D網絡通過不同的卷積核實驗,最終驗證了所有的卷積核采用3×3×3大小最為合適,對應的步長為1×1×1。其中,第一層池化層采用1×2×2的卷積核大小,目的是保留當前的時間信息,池化層則使用2×2×2的卷積核。C3D經緯構造采用三維卷積操作,8次卷積操作,4次池化操作,最后經過2個全連接層和softmax層后,網絡得到最終的效果。C3D神經網絡的總體框架如圖1所示。
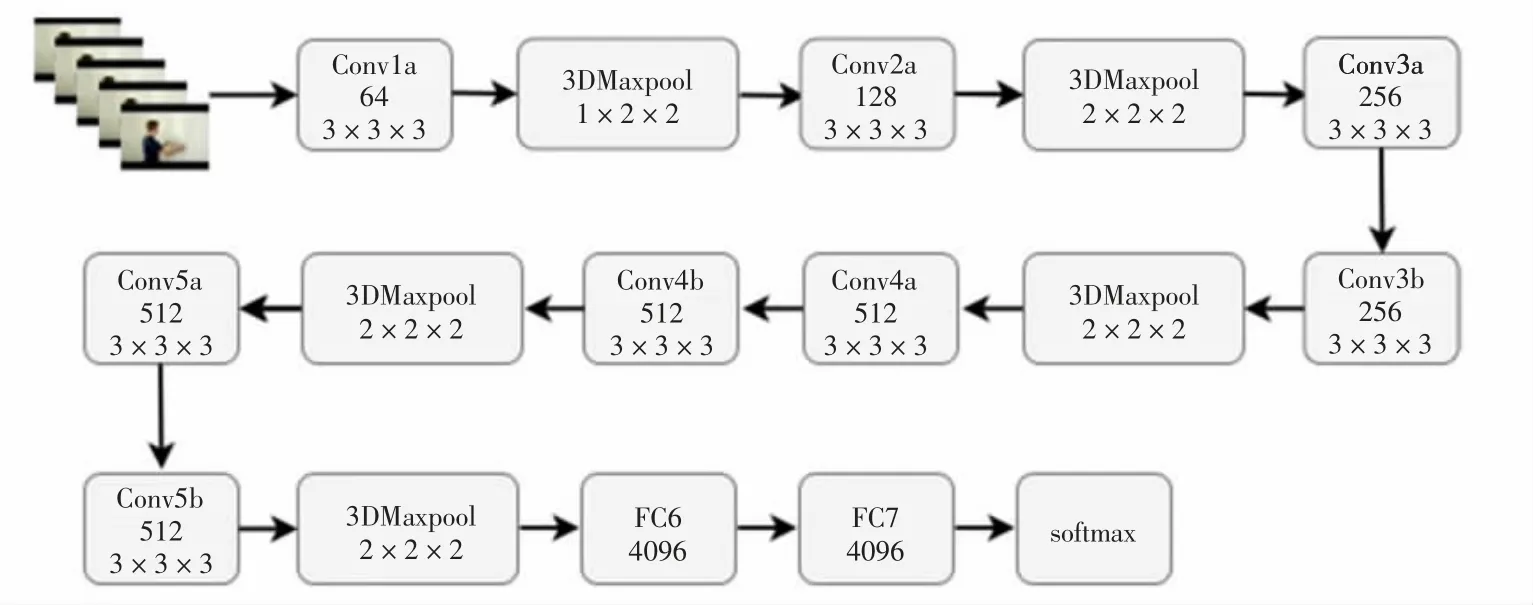
圖1 C3D神經網絡整體結構圖
1.2 基于視頻聚類關鍵幀提取算法
視頻中的信息量比圖片信息量更為豐富,但在一個序列中,存在很多多余的數據,所以在無監督情況下,提取出關鍵性的數據尤為重要。目前,主要的關鍵幀提取方法有5種:基于鏡頭邊界提取關鍵幀[19]、基于運動分析提取關鍵幀[20]、基于圖像信息提取關鍵幀[21]、基于鏡頭活動性提取關鍵幀[22]和基于視頻聚類提取關鍵幀[23]。與前面4種不同的關鍵幀提取算法相比,利用視頻聚類技術對關鍵幀進行分割,可以有效地對關鍵幀進行分割。在視頻分類過程中,將視頻分割成不同的圖像,得到典型的圖像特征。朱映映等[24]提出以圖像顏色直方圖計算圖像之間的最大相似性,然后根據圖像間的相似性度量聚類的方法,較好地解決了計算效率問題。參考上述聚類標準方法,本文對視頻進行關鍵幀提取時,采用算法如下:
(1)變換圖像色彩空間,從RGB變換到HSV彩色空間。
(2)對HSV彩色空間中的彩色直方圖進行計算,并標準化。即H顏色直方圖分成12份,S、V顏色分成5份,分別計算其顏色直方圖。
(3)開始聚類,將圖像組的第一幀圖像當作初選的群集中心,取一幀與目前的群集中心進行相似度測量,如果最大相似度仍然小于給定的臨界點threshold,表示該幀與所有的聚類中心之間的距離過大,因此需要單獨成為一類。重復此過程,直到取完所有的幀。每一次當前類中加入一張新的圖像時,需重新計算聚類中心,即求一次平均值。
(4)在聚類結束后,根據離簇中心最近的幀數進行運算,將其視為關鍵性的幀數。
1.3 注意力機制的引入
C3D模型在提取空間和空間特性時,會考慮到視頻中的每個像素,而在行為識別視頻中,C3D模型對每個像素都具有同樣的意義。但是,在行為識別視頻中,更需要去關注空間中對于人體部分的特征,因此使用注意力機制尤為重要。
本文采用輕量級的注意力模型CBAM[25]用于加強空間和時間上的特征提取,采用通道注意力和空間注意力串聯的方式,并在此基礎上,從2個方向推導出注意因子。針對通道注意,重點在于哪條通道上的特點,將2個特征圖進行全局平均和全局最大值操作,分別發送到第二層。在此基礎上,利用Sigmoid函數對2個特征圖進行相加運算,求出0~1的權值,根據要素屬性對其進行相乘運算,生成空間注意力模塊所需的特征。
以通道注意力模塊所輸出特征圖作為空間注意力模塊所輸入特征圖,重點在于空間區域的特性具有重要的含義。利用通道進行全局最大值和整體最大值的池化操作,得到2個特征圖,同時進行拼接運算。利用7×7大小的卷積核提取特征,通過Sigmoid函數產生空間權重系數。利用空間權重系數對輸入特征圖進行乘法操作,獲得最終的特征圖,CBAM結構如圖2所示。
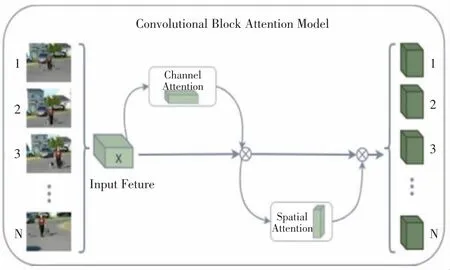
圖2 CBAM結構圖
將CBMA注意力機制引入C3D模型,得到三維卷積提取特征圖F∈RC×M×H×W作為CBAM的輸入,式中:R為網絡時空域;C為網絡通道數;M為視頻幀數;H為視頻幀圖像高;W為視頻幀圖像寬。
通過信道注意力模型對該特性進行分析,得出Mc(F),Mc∈RC×1×1×1的信道注意力模型,并與原有的特征圖分別相乘,從而獲得經過改進的信道注意力特性曲線F'。

式中:○×為逐個元素相乘。
新特征圖F'又經過空間注意力模塊,得到二維空間特征圖Ms(F')。其中,Ms∈R1×1×H×W為空間注意力模塊,將其乘以特征圖F'中的每一個要素,獲得細化特征圖F″。

1.4 系統整體結構
綜合上述關鍵技術,本文采用如圖3所示的基于聚類視頻關鍵幀提取的行為識別算法,對大量動作視頻進行少而精的關鍵幀提取,利用數據增強算法對提取的關鍵幀進行0.5的概率水平翻轉作為模型的輸入,在原始C3D模型中加入CBAM注意力機制對輸入數據提取行為特征,加強數據的空間聯系和時間聯系,提高行為識別的準確率。
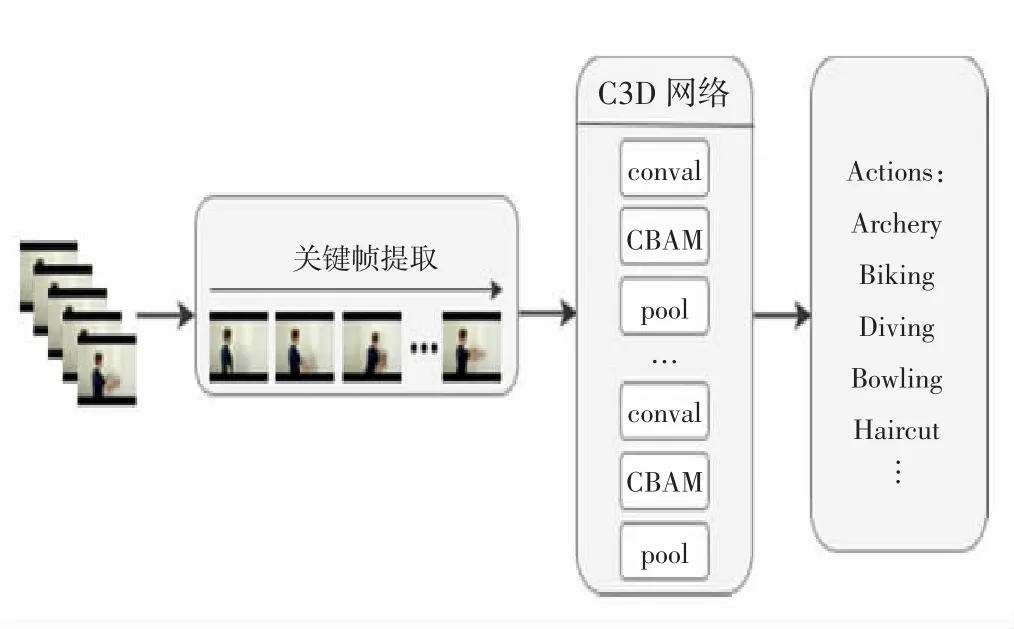
圖3 基于視頻關鍵幀提取的C3D模型結果
2 實驗結果與分析
2.1 實驗環境和相關設置
本文采用Windows 10操作系統,采用Intel(R)內核(TM)i7-10700 cpu@2.90 GHz,32 GB的存儲空間,NVIDIA GeForce RTX 3080。Python3.7的程序設計和PyCharm 2019的開發,利用Pytorch的深度研究構建、訓練和測試網絡。
網絡內迭代周期(epoch)次數設定為100次,初始學習率設定為0.003,并在每訓練4次迭代周期結束時,學習率減少到原來的1/10,訓練所用批量大小取32,隨機失活率設置為0.85,以6∶2∶2的比例劃分訓練集合、校驗集合和測驗集合。
2.2 行為識別數據集
本文采用人體行為識別的公開數據集UCF101開展實驗。UCF101是一個由YouTube搜集的真人動畫短片,總共13 320個片段,視頻總時長達到27 h,總共101個動作。UCF101數據集包含了人與物的相互交流、簡單肢體動作、人際之間互動、演奏樂器以及體育運動等。此外,每個類別分為25組,每組有4~7個短視頻,各視頻時長均不相同,但大小均為320×240,并且每個視頻的幀率不固定,一般為25幀或29幀,對于一個視頻只能包含一個行為類別。UCF101在運動上具有最廣泛的靈活性,包括攝像機運動、物體外觀和姿勢、物體尺寸、視角、混亂的場景;由于光照環境會有很大變化,所以UCF101是最具有挑戰性的人類行為識別系統。
2.3 數據預處理
利用視頻聚類關鍵幀算法對行為視頻數據集進行關鍵幀提取并保存提取的關鍵幀數量,提取出的關鍵幀對比原始的C3D模型,采取每隔4幀截取1幀,直至截取時序達到16幀的均勻采樣方法更具有代表性。對提取出的關鍵幀進行訓練集、驗證集、測試集的劃分,劃分的比例為6∶2∶2,并將所得關鍵幀裁剪成171×128個像素,存儲在指定地點。在輸入數據的過程中,將已經裁剪過的關鍵幀隨機調整成112×112像素大小,其目的是使模型的精度和穩定性能夠更好地加強。把調整后的視頻關鍵幀作為輸入數據并且對每個調整好的輸入數據采取水平翻轉和去均值的數據增強方法。
2.4 實驗結果分析
本實驗采用UCF101數據集進行訓練,迭代周期次數為100次。評價標準采用了準確率(accuracy,ACC)、模型評估指標(area under curve,AUC)和平均精確度(mean average precision,mAP)和模型參數(params)對模型進行評價。其中,ACC評價標準分別采用了Top-1 Accuracy和Top-5 Accuracy的評估方法對實驗進行評價。Top-1 Accuracy評估函數是將實驗中預測標簽取最后概率向量中最大的值作為最后的預測結果;Top-5 Accuracy是最后概率向量里最大的前5個標簽值中出現正確值即為預測正確。AUC評估函數是現有分類模型中主要的評測標準之一,其不關注具體準確率,只關注排序結果,適用于排序問題的效果評估。mAP評價函數一般應用于多類別的目標監測任務,其能夠衡量出模型在所有類別上的性能。params評估函數對應為空間概念,即空間復雜度,是指模型中含有參數的數量,直接決定模型的大小,也影響著推斷時對內存的占用量。實驗采用Top-1和Top-5準確率評估方法將原始C3D模型和本文模型進行對比,UCF101準確率(Top-1)、(Top-5)變化曲線分別如圖4和圖5所示,UCF101損失率變化曲線如圖6所示。
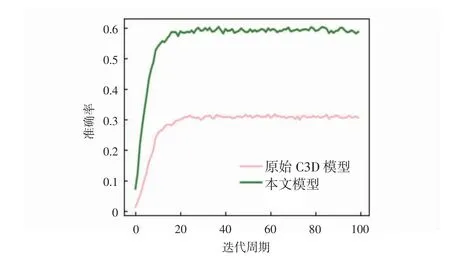
圖4 UCF101準確率(Top-1)變化曲線
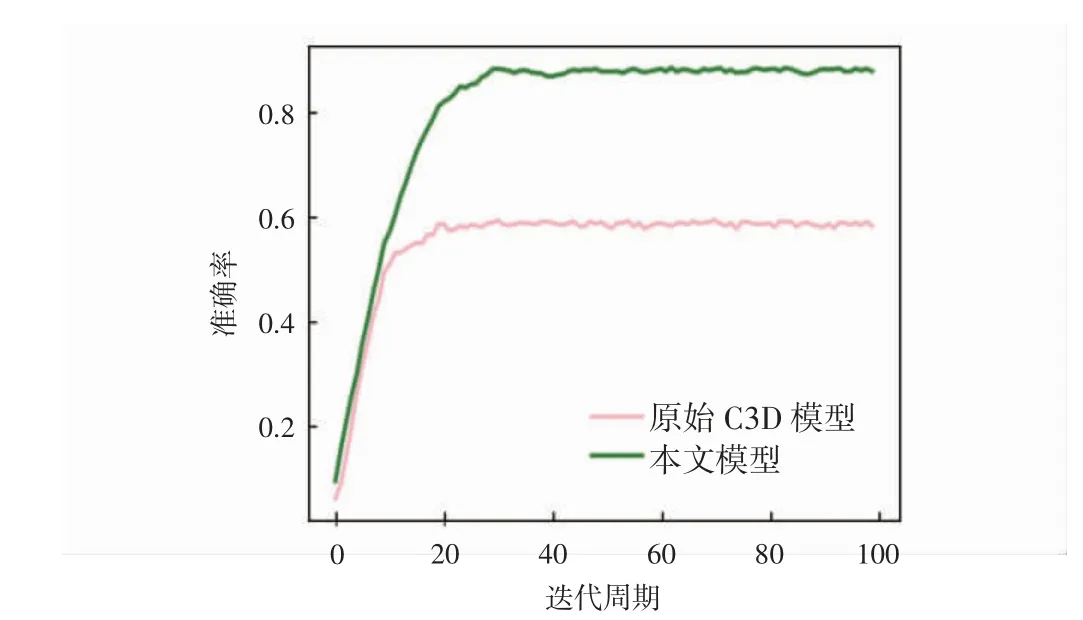
圖5 UCF101準確率(Top-5)變化曲線
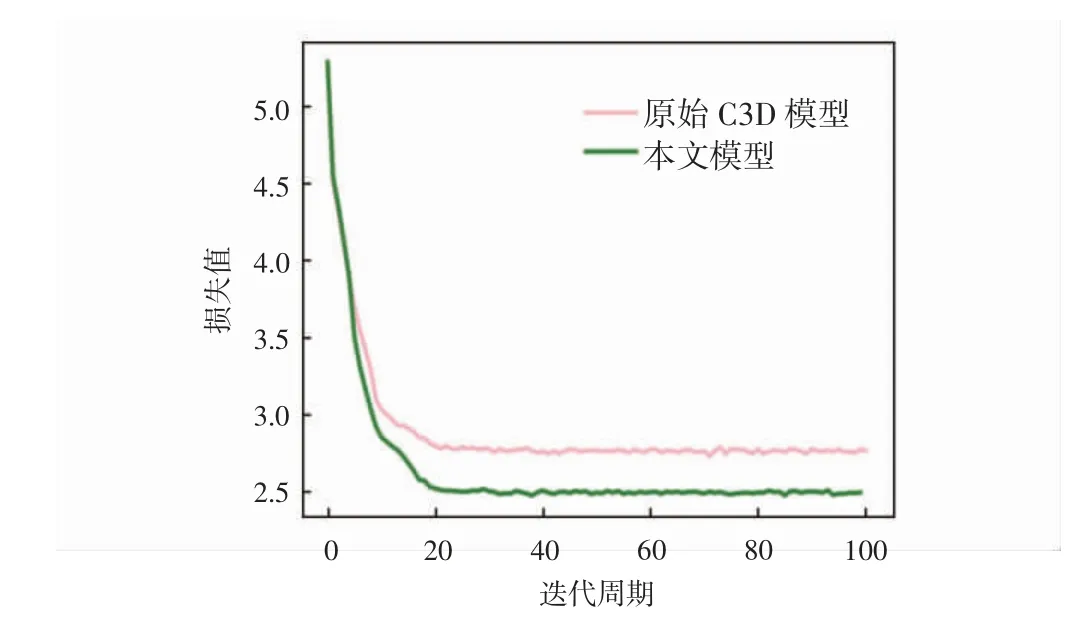
圖6 UCF101損失率變化曲線
從圖4和圖5可以看出,原始C3D模型隨著迭代次數的增加,準確率逐步上升,Top-1準確率在15次迭代后逐漸收斂,Top-5準確率在20次迭代后逐漸收斂,在100次迭代中,準確率Top-1和Top-5最高能達到31.14%和59.34%;本文模型Top-1準確率在20次迭代后趨近于收斂,Top-5準確率在30次迭代后逐漸收斂,最高準確率分別達到60.49%和88.17%,對比原始C3D模型準確率有明顯提高。從圖6可以看出,本文模型在0~20次迭代中,損失值急劇下降,20次迭代后損失值逐漸趨近收斂于2.47%,原始C3D模型在0~20次迭代中,損失值快速下降,20次迭代后損失值逐步收斂于2.83%,實驗對比結果顯示,本文模型損失值降低了0.36%。本算法與當前流行人體行為識別算法C3D、Res3D、Spatial Stream-Resnet和LSTM Composite Model在UCF101數據集上的測試結果以及各種指標結果的對比如表1所示。
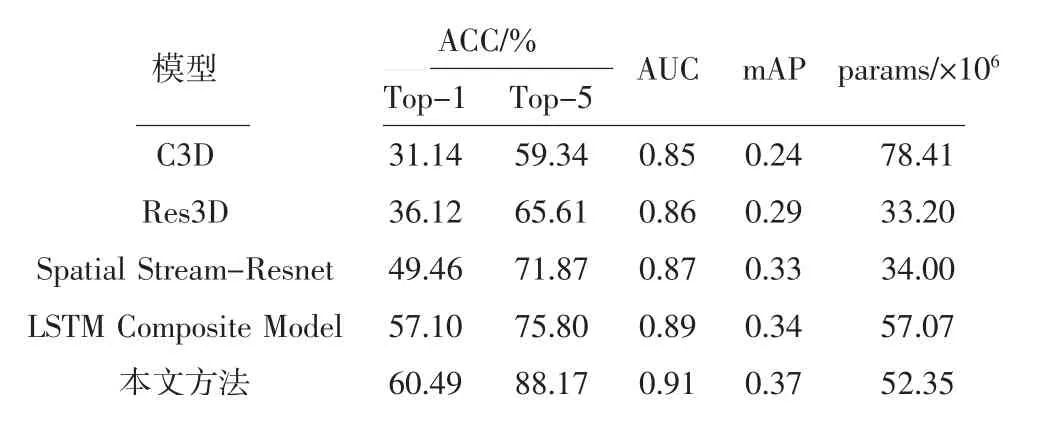
表1 UCF101數據集各模型方法結果對比
從表1可以看出,在AUC評價指標上,本研究方法可以同時考慮分類器對于正例和負例的分類能力,分類效果更好;在mAP指標上,本研究方法的網絡結構較優,行為識別檢測較準確;在params評價指標上,本方法僅低于C3D模型和LSTM Composite Model,參數量相對較少,降低了對內存的占用量。
3 結語
本文針對C3D網絡模型難以注意到行為視頻有代表性關鍵幀信息,造成識別效果不佳的問題提出了基于視頻關鍵幀提取的人體行為識別C3D網絡模型。模型對數據集采取視頻聚類的方法進行關鍵幀提取,并加入輕量級的注意力模塊加強對人體行為特征的關注度。在UCF101數據集中,將本文算法與原始C3D模型和其他常用算法進行分析比較,結果驗證了本文方法的可行性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
