融合金字塔切分注意力模塊的視杯視盤(pán)分割
2023-01-16 07:10:38劉熠翕江旻珊張學(xué)典
上海理工大學(xué)學(xué)報(bào) 2022年6期
關(guān)鍵詞:特征
劉熠翕, 江旻珊, 張學(xué)典
(上海理工大學(xué)光電信息與計(jì)算機(jī)工程學(xué)院,上海 200093)
青光眼是一種慢性眼科疾病,若不能及時(shí)對(duì)其進(jìn)行診斷和治療,可能會(huì)造成不可逆的視力損傷甚至是永久性失明[1]。視盤(pán)和視杯之間的垂直直徑比值CDR是青光眼在臨床診斷中的重要指標(biāo)[2]。在彩色眼底圖像中,視盤(pán)一般表現(xiàn)為視網(wǎng)膜的中央黃色部分,視杯是視盤(pán)上存在的可變尺寸的明亮中央凹陷。杯盤(pán)比的計(jì)算需要精確提取視盤(pán)和視杯的區(qū)域,由于手動(dòng)分割視盤(pán)和視杯是一項(xiàng)耗時(shí)的專業(yè)工作,因此,各種分割算法被引入。隨著深度學(xué)習(xí)技術(shù)的發(fā)展,應(yīng)用卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural network,CNN)提取圖像特征在分割任務(wù)上取得了較傳統(tǒng)算法更好的效果。全卷積神經(jīng)網(wǎng)絡(luò)(fully convolutional networks,F(xiàn)CN)[3]是目前很多語(yǔ)義分割方法的基礎(chǔ),在自然圖像分割任務(wù)上取得了比傳統(tǒng)方法更好的分割效果。因此,將深度學(xué)習(xí)技術(shù)引入到醫(yī)學(xué)影像處理中,利用卷積神經(jīng)網(wǎng)絡(luò)來(lái)進(jìn)行視杯視盤(pán)分割的研究越來(lái)越多,并取得了優(yōu)于傳統(tǒng)分割方法的分割結(jié)果。M-Net(multi-label deep network)[4]在U-Net基礎(chǔ)上增加了多尺度輸入,引入了深度監(jiān)督思想,在中間層添加額外的損失函數(shù)并且引入了極坐標(biāo)轉(zhuǎn)換操作,成功實(shí)現(xiàn)了視杯視盤(pán)的聯(lián)合分割;DenseNet[5]將全卷積網(wǎng)絡(luò)應(yīng)用于視杯視盤(pán)分割任務(wù);CENet(context encoder network)[6]提出了一個(gè)上下文編碼模塊,由一個(gè)多尺度的密集空洞卷積模塊和一個(gè)殘差多路徑池化模塊構(gòu)成,可以多尺度捕獲具有高水平語(yǔ)義信息的特征,但未用于視杯的分割中;CDED-Net[7]采用了一種緊密連接的視杯視盤(pán)解碼器網(wǎng)絡(luò)結(jié)構(gòu),在杯盤(pán)的聯(lián)合分割上實(shí)現(xiàn)了較好的結(jié)果;文獻(xiàn)[8]提出了一種特征嵌入框架,有效提高了卷積神經(jīng)網(wǎng)絡(luò)在完成視杯視盤(pán)分割任務(wù)時(shí)的泛化能力。以上這些方法通過(guò)改進(jìn)結(jié)構(gòu),強(qiáng)化了網(wǎng)絡(luò)的信息提取能力,但是對(duì)網(wǎng)絡(luò)中間的多層次特征的利用不夠充分。為了解決以上問(wèn)題,本文進(jìn)行了一系列研究,并作出以下貢獻(xiàn):a. 基于U-Net[9]設(shè)計(jì)并實(shí)現(xiàn)了一個(gè)端到端的深度學(xué)習(xí)算法來(lái)分割彩色眼底圖像中的視盤(pán)和視杯;b.使用預(yù)訓(xùn)練的34層ResNet[10]代替了原U-Net中的下采樣部分對(duì)圖像特征進(jìn)行提取;c.在特征提取網(wǎng)絡(luò)Resnet 34中融入金字塔切分注意力PSA(pyramid squeeze attention)模塊[11],有效地獲取了不同尺度的感受野,提取了不同尺度的信息;d.使用一個(gè)3×3卷積與一個(gè)通過(guò)跳躍連接的1×1卷積代替原連接結(jié)構(gòu)[12];e.使用DiceLoss損失函數(shù)代替交叉熵?fù)p失函數(shù),有效地提升了分割精度;f.在Drishti-GS數(shù)據(jù)集[13]上驗(yàn)證了改進(jìn)網(wǎng)絡(luò)的性能,對(duì)視盤(pán)和視杯的分割結(jié)果在Dice和IOU上分別表現(xiàn)為97.61%和95.32%,92.91%和86.75%。
1 方法
1.1 網(wǎng)絡(luò)模型
在改進(jìn)后的U型網(wǎng)絡(luò)中,整體采用了端到端的編碼器-解碼器結(jié)構(gòu),具體網(wǎng)絡(luò)結(jié)構(gòu)如圖1所示。對(duì)于編碼器結(jié)構(gòu),使用了預(yù)訓(xùn)練的ResNet 34來(lái)提取具有高水平語(yǔ)義的圖像特征。從第一個(gè)7×7卷積層和最大池化層出發(fā),依次經(jīng)過(guò)個(gè)數(shù)為3,4,6,3的殘差塊。其中,殘差塊由兩個(gè)3×3卷積、批標(biāo)準(zhǔn)化層[14]和ReLU激活函數(shù)組成。特別的是,在每個(gè)編碼層即殘差塊的末端引入金字塔切分注意力PSA模塊以獲取不同尺度信息。在編碼器提取了具有高水平寓意信息的圖像特征后,解碼器則采用步長(zhǎng)為2的2×2轉(zhuǎn)置卷積來(lái)實(shí)現(xiàn)上采樣。轉(zhuǎn)置卷積不僅能使圖像恢復(fù)到初始時(shí)的尺寸,還能擁有可訓(xùn)練的卷積核參數(shù)。解碼結(jié)構(gòu)與編碼結(jié)構(gòu)對(duì)稱,采用多個(gè)模塊對(duì)特征進(jìn)行逐級(jí)還原,其中,每個(gè)解碼層由一個(gè)1×1卷積、批標(biāo)準(zhǔn)化層和ReLU激活函數(shù)組成。1×1卷積可以在降低網(wǎng)絡(luò)訓(xùn)練參數(shù)的同時(shí)調(diào)整輸入、輸出特征通道數(shù),有助于與解碼器中通道數(shù)相同的特征圖進(jìn)行拼接,同時(shí)也可以使網(wǎng)絡(luò)進(jìn)一步融合特征通道之間的信息。除此之外,本文還對(duì)編碼層和解碼層的連接方式作了改進(jìn),將原U-Net網(wǎng)絡(luò)中的跳躍連接使用一個(gè)3×3卷積層伴隨一個(gè)通過(guò)跳躍連接的1×1的卷積層代替,結(jié)構(gòu)如圖2所示。改進(jìn)后的連接方式能夠讓下采樣部分的特征信息更加充分地融合至上采樣部分,使得網(wǎng)絡(luò)獲得多種維度的圖像特征信息,幫助提高網(wǎng)絡(luò)的分割效果。
1.2 金字塔切分注意力模塊
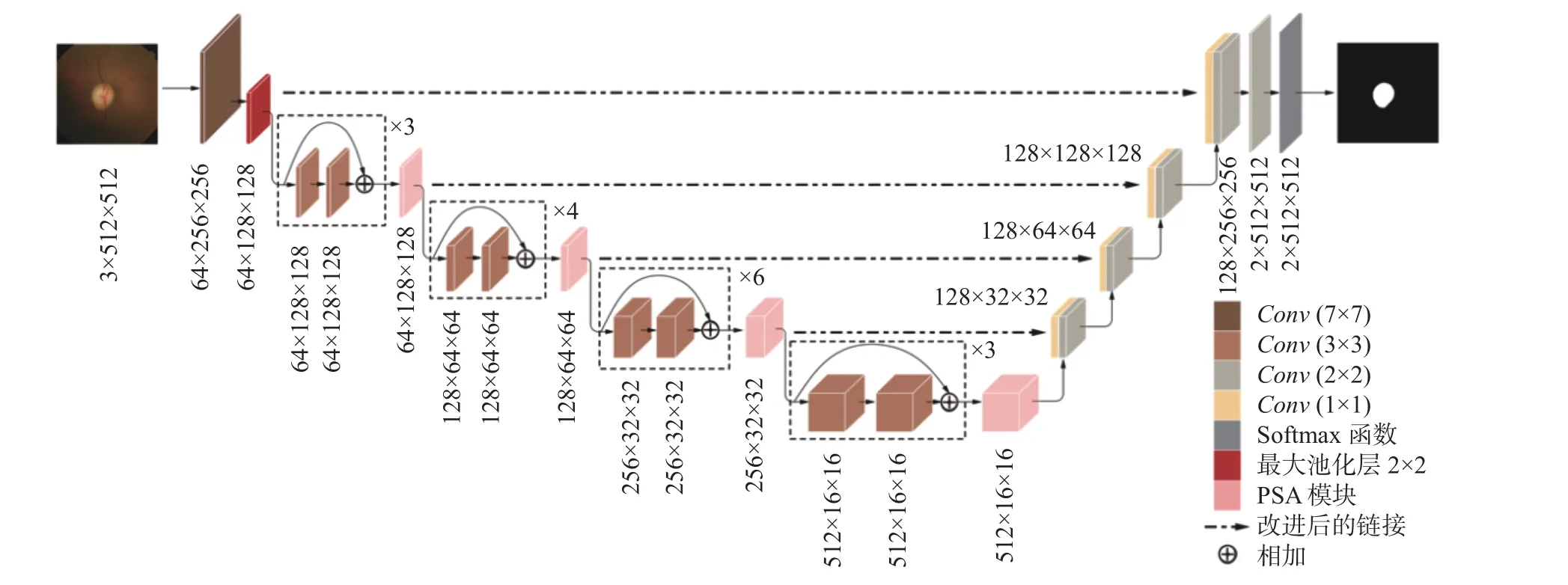
圖1 改進(jìn)后的U型網(wǎng)絡(luò)結(jié)構(gòu)圖Fig.1 Improved U-shaped network structure
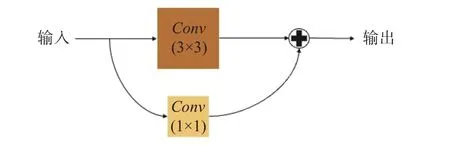
圖2 改進(jìn)后的連接Fig.2 Improved connection
注意力機(jī)制在圖像處理領(lǐng)域廣受關(guān)注,大多數(shù)注意力機(jī)制只引入了通道注意力,卻忽略了空間信息,或者只考慮了局部區(qū)域的信息,而金字塔切分注意力PSA(pyramid split attention )模塊可以高效地提取更細(xì)顆粒度的多尺度空間信息,同時(shí)建立更遠(yuǎn)距離的通道依賴關(guān)系,在神經(jīng)網(wǎng)絡(luò)中嵌入該模塊后可在減小計(jì)算量的同時(shí)有效提高網(wǎng)絡(luò)性能。
1.2.1 SEWeight模塊
通道注意力機(jī)制允許網(wǎng)絡(luò)有選擇性地權(quán)衡每個(gè)通道的重要性,從而輸出更多的有效特征信息。對(duì)網(wǎng)絡(luò)輸入特征映射為X,X∈RC×H×W,C,H和W分別表示特征圖像的通道數(shù)、高度和寬度。SE(squeeze and excitation)模塊主要由擠壓和激勵(lì)兩部分組成,結(jié)構(gòu)如圖3所示。首先通過(guò)使用全局池化操作來(lái)聚合全局上下文信息,第c個(gè)通道的為輸入x,全局池化計(jì)算公式為

輸入特征在經(jīng)過(guò)全局池化層后,隨后經(jīng)過(guò)全連接層、ReLU激活函數(shù)層、全連接層及Sigmoid函數(shù)層,則第c個(gè)通道的注意力權(quán)重可表示為

式中:δ表示ReLU激活函數(shù);σ表示激勵(lì)函數(shù)Sigmoid;W0和W1代表兩個(gè)全連接層,W0∈W1∈兩個(gè)全連接層可更有效地組合通道之間的線性信息,有利于通道中的高維度信息和低維度信息之間進(jìn)行相互作用。再通過(guò)使用激勵(lì)函數(shù)為每個(gè)通道重新分配權(quán)重,從而更有效地提取信息。
1.2.2 SPC模塊
在金字塔切分注意力模塊中主要通過(guò)SPC(squeeze and concat)模塊實(shí)現(xiàn)多尺度特征提取,即采用多分支的方法提取輸入特征圖的空間信息,其結(jié)構(gòu)如圖4所示。每個(gè)分支將獨(dú)立學(xué)習(xí)多尺度空間信息,以局部方式建立跨通道交互,通過(guò)這樣做,可以獲得更豐富的輸入向量的空間信息,并在多個(gè)尺度上并行處理它。相應(yīng)地,采用金字塔結(jié)構(gòu)的多尺度卷積可以提取不同維度的空間信息,同時(shí)通過(guò)壓縮輸入向量的通道維數(shù),可以有效地提取每個(gè)通道特征圖上不同尺度的空間信息。假設(shè)輸入為X,SPC模塊首先將輸入切分為S個(gè)部分,分別為[X0,X1,···,XS-1],且每個(gè)部分的通道數(shù)都為C′=。隨著內(nèi)核尺寸的增加,為了在不增加計(jì)算成本的情況下處理不同核尺度下的輸入向量,SPC引入了一種分組卷積方法,可在不增加參數(shù)量的情況下選擇群組的大小,群組G和卷積核K的大小滿足下式:

圖3 SE Weight模塊結(jié)構(gòu)Fig.3 SE Weight structure

圖4 SPC模塊結(jié)構(gòu)Fig.4 SPCmodule structure
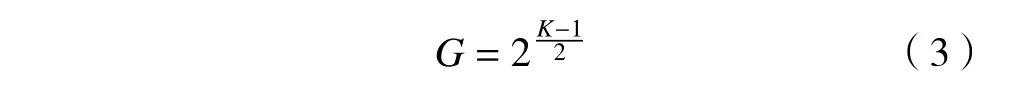
綜上所述,多尺度特征核圖的生成函數(shù)可表示為
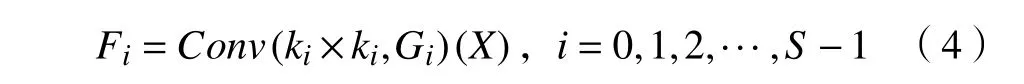
式中,第i個(gè)卷積核尺寸ki=2×(i+1)+1,第i 個(gè)分組大小為
最后可以得到完整的融合后的多尺度特征圖為

1.2.3 PSA模塊
PSA(pyramid squeeze attention)模塊主要通過(guò)4個(gè)步驟實(shí)現(xiàn):a.利用SPC模塊來(lái)對(duì)通道進(jìn)行切分,然后針對(duì)每個(gè)通道特征圖上的空間信息進(jìn)行多尺度特征提取;b.利用SEWeight模塊提取不同尺度特征圖的通道注意力,得到每個(gè)不同尺度上的通道注意力向量;c.通過(guò)使用Softmax重新校準(zhǔn)通道方向的注意力向量,獲得新的多尺度通道交互之后的注意力權(quán)重;d.對(duì)重新校準(zhǔn)的權(quán)重和相應(yīng)的特征圖按元素進(jìn)行點(diǎn)乘操作,從而獲得多尺度且特征信息更豐富的細(xì)顆粒度特征圖作為輸出,詳細(xì)結(jié)構(gòu)如圖5所示。
1.3 損失函數(shù)
因本文的工作是對(duì)視杯視盤(pán)進(jìn)行分割,DiceLoss可以有效地解決圖像不均衡的問(wèn)題,因此,本文使用DiceLoss函數(shù)代替?zhèn)鹘y(tǒng)的交叉熵?fù)p失函數(shù),即

式中:N表示像素點(diǎn)個(gè)數(shù);k表示種類個(gè)數(shù),在本文中,k值設(shè)置為2; p(k,i)∈[0,1],表示像素點(diǎn)預(yù)測(cè)為種類的概率; g(k,i)∈{0,1} , 表示像素點(diǎn)i屬于種類k的標(biāo)簽值。

圖5 PSA模塊結(jié)構(gòu)Fig.5 PSA module structure
2 實(shí)驗(yàn)設(shè)置
2.1 數(shù)據(jù)集
本次研究中,采用上海市第一人民醫(yī)院的一個(gè)內(nèi)部數(shù)據(jù)集進(jìn)行網(wǎng)絡(luò)訓(xùn)練,一個(gè)公共數(shù)據(jù)集即DRISHTI-GS數(shù)據(jù)集用作測(cè)試網(wǎng)絡(luò)性能。該數(shù)據(jù)集包含200對(duì)彩色視網(wǎng)膜眼底圖像,分辨率為2 124×2 056,由4名專業(yè)眼科醫(yī)生對(duì)該數(shù)據(jù)集的視杯和視盤(pán)進(jìn)行手動(dòng)標(biāo)注,同時(shí)對(duì)參與者是否患有青光眼進(jìn)行標(biāo)記。對(duì)于OD和OC的標(biāo)注,要求眼科醫(yī)生在沒(méi)有獲得參與者患病信息的前提下獨(dú)立完成。DRISHTI-GS數(shù)據(jù)集由101幅彩色眼底圖像組成,分辨率為2 896×1 944,其中30幅為正常眼,71幅為青光眼,且官方已對(duì)訓(xùn)練集和測(cè)試集進(jìn)行劃分,包括50幅訓(xùn)練圖像和51幅測(cè)試圖像。
2.2 環(huán)境設(shè)置
整個(gè)框架基于Python中的Tensorflow和Keras實(shí)現(xiàn),使用的操作系統(tǒng)為Ubuntu 18.04 Linux,實(shí)驗(yàn)采用的GPU為NVIDIA GeForce RTX 2080Ti。對(duì)于OD和OC分割,使用內(nèi)部數(shù)據(jù)集中的部分作為訓(xùn)練集,用于擬合和優(yōu)化模型參數(shù),隨后在DRISHTI-GS數(shù)據(jù)集上進(jìn)行測(cè)試用于評(píng)估網(wǎng)絡(luò)的性能。在訓(xùn)練過(guò)程中,采用了隨機(jī)梯度下降(SGD)和反向傳播來(lái)優(yōu)化深度模型,同時(shí)還設(shè)置了學(xué)習(xí)速率更新策略和提前停止機(jī)制。學(xué)習(xí)率從0.001開(kāi)始逐漸下降,當(dāng)損失在10輪訓(xùn)練后不下降,網(wǎng)絡(luò)學(xué)習(xí)速率減為一半;當(dāng)損失在30輪訓(xùn)練后不下降,網(wǎng)絡(luò)會(huì)終止學(xué)習(xí)并保存參數(shù)。學(xué)習(xí)速率更新策略可以使網(wǎng)絡(luò)更加精準(zhǔn)地找到最優(yōu)點(diǎn),提前停止機(jī)制可以防止網(wǎng)絡(luò)參數(shù)過(guò)擬合導(dǎo)致測(cè)試性能下降。訓(xùn)練過(guò)程中,將訓(xùn)練批次大小設(shè)置為2,最大訓(xùn)練輪次為100。
2.3 圖像預(yù)處理
數(shù)據(jù)預(yù)處理包括3個(gè)主要步驟:a. 對(duì)圖像進(jìn)行預(yù)處理,將其尺寸調(diào)整為512×512,并在圖像邊界、缺乏對(duì)比度的情況下手動(dòng)消除任何會(huì)對(duì)實(shí)驗(yàn)結(jié)果產(chǎn)生影響的風(fēng)險(xiǎn);b. 針對(duì)對(duì)比度弱的彩色眼底圖像,使用限制對(duì)比度自適應(yīng)直方圖均衡技術(shù),將每個(gè)圖像切割成8×8的64塊,并且對(duì)每一塊使用直方圖均衡化處理;c. 由于數(shù)據(jù)集數(shù)量有限,以防出現(xiàn)過(guò)擬合、數(shù)據(jù)不平衡的情況,對(duì)原始數(shù)據(jù)集進(jìn)行了數(shù)據(jù)增強(qiáng)。通過(guò)使用圖像生成器每次將圖像旋轉(zhuǎn)20 °,改變圖像的高度和寬度,并以隨機(jī)的水平和垂直翻轉(zhuǎn)方式翻轉(zhuǎn)圖像,將原始訓(xùn)練集由50張?jiān)黾拥? 550張。此外,數(shù)據(jù)增強(qiáng)還可以減少模型的結(jié)構(gòu)風(fēng)險(xiǎn),提高魯棒性。d. 將訓(xùn)練集中的彩色眼底照片和標(biāo)簽融合至同一張圖片,如圖6所示,確保彩色眼底照片與標(biāo)簽一一對(duì)應(yīng)。

圖 6 預(yù)處理中圖像與標(biāo)簽的融合Fig.6 Pre-process image, label and their fusion
2.4 評(píng)價(jià)指標(biāo)
為了評(píng)估本文中網(wǎng)絡(luò)模型對(duì)視盤(pán)和視杯的分割性能,本研究選擇使用Dice系數(shù)和IOU這兩個(gè)參數(shù)作為評(píng)價(jià)指標(biāo)。Dice系數(shù)描述了兩個(gè)樣本的相似度,用sDice表示,IOU值描述了兩個(gè)樣本交集與并集的重疊率,用IIOU表示,即

式中:A表示真值;B表示預(yù)測(cè)值。
Dice系數(shù)的值在0~1之間,越接近于1,表示分割結(jié)果越好。IOU值也在0~1之間,IOU值越大,表示預(yù)測(cè)為視盤(pán)或視杯的區(qū)域與真值重疊越多,分割結(jié)果也越好。
3 實(shí)驗(yàn)結(jié)果與分析
3.1 網(wǎng)絡(luò)訓(xùn)練結(jié)果
首先使用內(nèi)部數(shù)據(jù)集對(duì)網(wǎng)絡(luò)進(jìn)行訓(xùn)練,圖7為訓(xùn)練集中使用的彩色眼底圖像及標(biāo)簽圖。圖8和圖9分別為視盤(pán)和視杯分割網(wǎng)絡(luò)訓(xùn)練的損失曲線、IOU曲線、Dice曲線和準(zhǔn)確率曲線。從圖中可以明顯看出,網(wǎng)絡(luò)在訓(xùn)練前期曲線收斂速度較快,從一定程度上說(shuō)明了網(wǎng)絡(luò)的學(xué)習(xí)能力較強(qiáng)。隨著訓(xùn)練輪次的升高,模型曲線斜率逐漸減小,當(dāng)訓(xùn)練輪次達(dá)到20次后,網(wǎng)絡(luò)訓(xùn)練的各項(xiàng)曲線開(kāi)始趨于平穩(wěn),僅呈現(xiàn)微小的波動(dòng)。

圖8 視盤(pán)分割網(wǎng)絡(luò)訓(xùn)練過(guò)程中的各項(xiàng)參數(shù)曲線圖Fig.8 Log-lossgraph,IOU graph, Dice graph and accuracy graph in disc segmentation net training
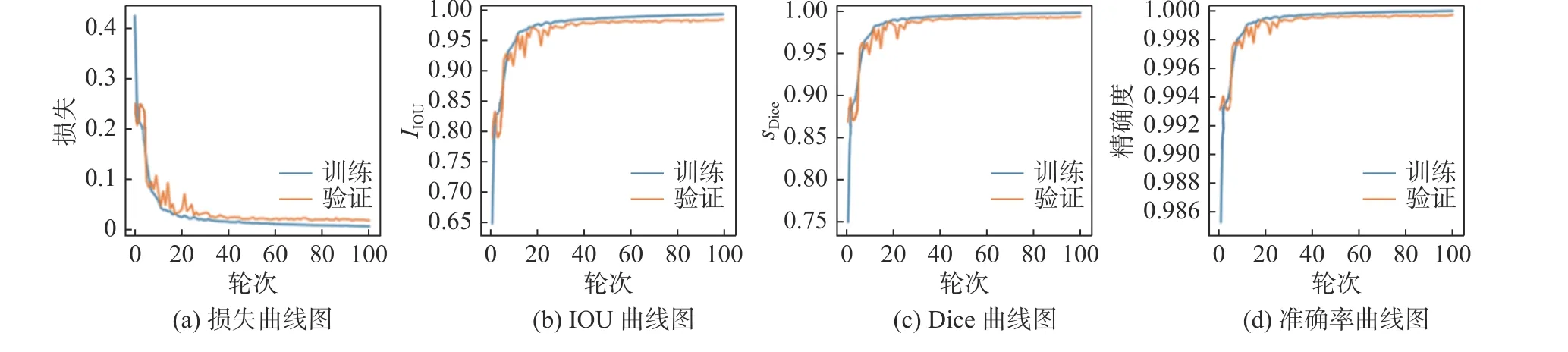
圖9 視杯分割網(wǎng)絡(luò)訓(xùn)練過(guò)程中的各項(xiàng)參數(shù)曲線圖Fig.9 Log-loss graph,IOU graph, Dice graph and accuracy graph in cup segmentation net training
3.2 網(wǎng)絡(luò)測(cè)試結(jié)果
在內(nèi)部數(shù)據(jù)集上對(duì)網(wǎng)絡(luò)完成訓(xùn)練后,使用Drishti-GS數(shù)據(jù)集對(duì)網(wǎng)絡(luò)性能進(jìn)行測(cè)試,來(lái)證明本文提出的網(wǎng)絡(luò)對(duì)視杯視盤(pán)分割的有效性。從圖10可以看到,在Drishti-GS數(shù)據(jù)集上驗(yàn)證時(shí),對(duì)于單張眼底圖像視盤(pán)分割的最高Dice系數(shù)可達(dá)98.74%,IOU值可達(dá)96.98%,視杯分割的最高Dice系數(shù)可達(dá)95.27%,IOU值可達(dá)90.97%;從圖11可以看到,對(duì)于單張眼底圖像視杯分割的最低Dice系數(shù)為79.36%,IOU值為65.78%,視杯分割的最低Dice系數(shù)為68.13%,IOU值為51.67%。整體而言:針對(duì)視盤(pán)分割,Dice系數(shù)和IOU值可分別達(dá)到97.61%和95.32%;而對(duì)視杯分割,Dice系數(shù)和IOU值可分別達(dá)到92.91%和86.75%。

圖10 DRISIHI-GS數(shù)據(jù)集上對(duì)視盤(pán)和視杯進(jìn)行分割的最佳表現(xiàn)Fig.10 Best performance of disc and cup segmentation on DRISIHI-GSdataset

圖11 DRISIHI-GS數(shù)據(jù)集上對(duì)視盤(pán)和視杯進(jìn)行分割的最差表現(xiàn)Fig.11 Worst performance of disc and cup segmentation on DRISIHI-GSdataset
為了進(jìn)一步評(píng)估本文所提出的網(wǎng)絡(luò)分割性能,將在Drishti-GS數(shù)據(jù)集上的分割結(jié)果與UNet,Deeplabv3+[15],M-Net,CE-Net,Ensemble CNN[16]和Robust[17]等方法的結(jié)果進(jìn)行對(duì)比,對(duì)比數(shù)據(jù)如表1所示,可以看到本研究網(wǎng)絡(luò)在指標(biāo)上均有所提升。例如,與現(xiàn)有的先進(jìn)模型M-Net相比,本文方法在視盤(pán)分割任務(wù)上將Dice系數(shù)和IOU值分別從96.78%和93.86%提高到97.61%和95.32%,實(shí)現(xiàn)了0.83%和1.46%的提升;而在視杯的分割結(jié)果上,本文方法將Dice系數(shù)和IOU值分別從CE-Net能夠?qū)崿F(xiàn)的91.57%和84.45%提高到92.91%和86.75%,實(shí)現(xiàn)了1.34%和2.30%的提升;而在與U-shaped CNN的結(jié)果對(duì)比中,盡管該網(wǎng)絡(luò)對(duì)視盤(pán)分割的Dice值較本文網(wǎng)絡(luò)模型要高出0.19%,但本文網(wǎng)絡(luò)在視杯分割任務(wù)中實(shí)現(xiàn)了更好的效果,Dice系數(shù)和IOU值要高出3.71%和4.45%。

表1 不同方法在DRISHTI-GS數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果Tab.1 Experimental results of different methods on DRISHTI-GSdataset
為了更為直觀地展現(xiàn)本文提出網(wǎng)絡(luò)的性能,將本文實(shí)驗(yàn)結(jié)果與U-Net,M-Net,CE-Net對(duì)視盤(pán)和視杯的分割結(jié)果進(jìn)行可視化對(duì)比,如圖12和圖13所示。圖片列從左到右分別為Drishti-GS數(shù)據(jù)集原圖、標(biāo)簽圖像、U-net分割結(jié)果、M-Net分割結(jié)果、CE-net分割結(jié)果以及本文結(jié)果。通過(guò)對(duì)比發(fā)現(xiàn),當(dāng)原始圖像對(duì)比度較清晰時(shí),本文網(wǎng)絡(luò)能夠精準(zhǔn)地識(shí)別視盤(pán)視杯的邊界,分割精度相對(duì)較高;而當(dāng)真值邊緣較不規(guī)則圖像亮度較低時(shí),本文網(wǎng)絡(luò)相比于其他方法能夠更加有效地?cái)M合出真值的形狀,在分割結(jié)果中更好地展現(xiàn)圖像細(xì)節(jié)。

圖12 不同方法在視盤(pán)分割任務(wù)上的結(jié)果對(duì)比Fig.12 Comparisons of different methods in disc segmentation
3.3 更改訓(xùn)練圖像尺寸的結(jié)果

圖13 不同方法在視杯分割任務(wù)上的結(jié)果對(duì)比Fig.13 Comparisons of different methods in cup segmentation
本文研究主要使用DRISHTI-GS數(shù)據(jù)集作為測(cè)試集,該數(shù)據(jù)集圖像的分辨率為2896×1944。為了研究輸入不同尺寸圖像進(jìn)行訓(xùn)練對(duì)網(wǎng)絡(luò)性能的影響,本文將DRISHTI-GS數(shù)據(jù)集中圖像的大小分別調(diào)整為128×128、256×256和1024×1024后作為新的訓(xùn)練集對(duì)網(wǎng)絡(luò)重新進(jìn)行訓(xùn)練。實(shí)驗(yàn)結(jié)果如表2所示,在輸入圖像信息和特征不變的情況下,分割性能隨著輸入圖像分辨率的增加而提高,由此導(dǎo)致網(wǎng)絡(luò)的訓(xùn)練時(shí)間大幅增加。當(dāng)使用128×128尺寸的圖像訓(xùn)練網(wǎng)絡(luò)時(shí),訓(xùn)練批次大小可設(shè)置為6,而在512×512的尺寸下,僅能設(shè)置批量大小為2。這說(shuō)明隨著圖像分辨率的增大,網(wǎng)絡(luò)的負(fù)荷也隨之增大。當(dāng)圖像分辨率為1024×1024時(shí),其分割結(jié)果與圖像分辨率為512×512時(shí)基本相同。綜合考慮訓(xùn)練時(shí)間與計(jì)算成本,在網(wǎng)絡(luò)能夠處理的限度內(nèi),需要選擇合適的分辨率和分割精度來(lái)訓(xùn)練模型,因此選擇512×512圖像分辨率。
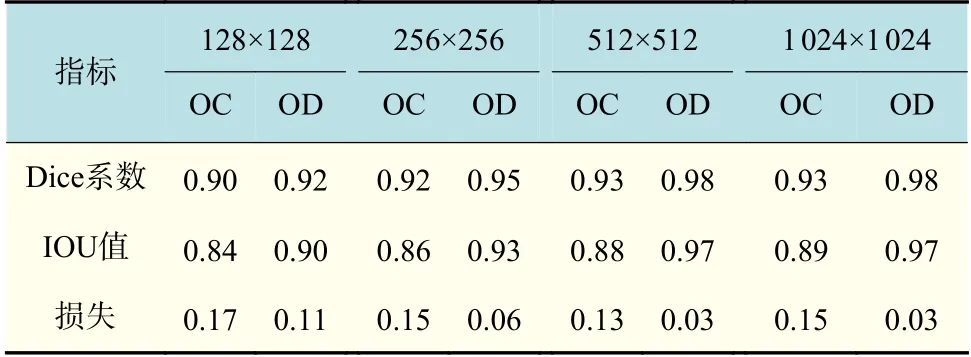
表2 不同分辨率的分割結(jié)果Tab.2 Segmentation results with different resolutions
4 結(jié)論
提出了一種改進(jìn)后的U型網(wǎng)絡(luò)用于視盤(pán)視杯的分割。該網(wǎng)絡(luò)采用Resnet 34作為編碼部分,并在每一個(gè)編碼層的末端引入金字塔切分注意力模塊,同時(shí)使用1×1卷積簡(jiǎn)化解碼結(jié)構(gòu),最后用殘差連接代替跳躍連接。通過(guò)與當(dāng)下主流的先進(jìn)算法在Drishti-GS1數(shù)據(jù)集上的驗(yàn)證結(jié)果進(jìn)行對(duì)比,證明了本文方法在視盤(pán)和視杯分割中的有效性,為臨床診斷青光眼提供了一種可行的方法。在未來(lái)的工作中,將進(jìn)一步融合更多患者圖像,以期實(shí)現(xiàn)更精確的病灶分割,從而更好地輔助青光眼篩查。
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2022年3期)2022-04-26 14:04:16
數(shù)學(xué)年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學(xué)學(xué)報(bào)(2020年2期)2020-04-01 03:50:40
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
中等數(shù)學(xué)(2019年8期)2019-11-25 01:38:14
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
廣西科技大學(xué)學(xué)報(bào)(2016年1期)2016-06-22 13:10:38
