基于深度學習的遙感影像地類信息獲取技術現狀研究*
2023-01-16 07:32:10王本禮
國土資源導刊 2022年4期
王本禮,王 也
(1.湖南省第二測繪院湖南長沙 410119;2.自然資源湖南省衛星應用技術中心,湖南長沙 410009;3.湖南仁晟設計有限公司,湖南長沙 410018)
土地利用動態監測是指對不同時相的土地利用數據進行對比分析,并從空間分布及數量上進行變換特征提取及分析,并為土地利用規劃決策提供數據支撐。遙感影像數據具有綜合、宏觀以及動態等多種優勢,地類自動識別則是使用遙感影像數據進行土地利用動態監測的關鍵技術,同時也是遙感應用和研究的重要領域。隨著深度學習等人工智能技術的提出與發展,目前地類自動識別逐漸從傳統的基于圖像特征的方法過渡為基于深度學習的方法,并取得較為顯著的成果[1]。
深度學習技術在圖像處理領域已經有廣泛的應用基礎,如人臉識別、圖像匹配等。當前,基于深度學習的遙感影像地類自動識別技術主要分為遙感影像分割、遙感影像分類以及遙感影像目標監測三種方式。
1 基本概念
1.1 深度學習
深度學習是機器學習的子集,主要基于多層人工神經網絡進行特征學習。因人工神經網絡具有多個輸入、輸出以及隱藏層,且學習過程具有深度性,從而得名。機器學習則是人工智能的子集,主要采用可以讓機器根據歷史信息及經驗在任務中做出改善的技術。人工智能則是讓機器模擬人類智能的技術。三者的關系示意圖如圖1所示。
深度學習引起強大的信息處理能力,逐步成為機器學習領域最接近人工智能的方法。隨著深度學習發展,各種具有特殊處理單元和網絡結構的神經網絡不斷涌現,但其基本結構都是由激活函數(非線性)連接多個線性結構構成,主要分為輸入層、隱藏層及輸出層。其中輸入層和輸出層主要和任務相關,而隱藏層則決定該網絡結構的具體功能。根據網絡結構不同可以分為卷積神經網絡、自動編碼機等[2]。根據訓練數據是否存在標簽以及標簽來源可以分為監督學習、半監督學習以及無監督學習[3]。
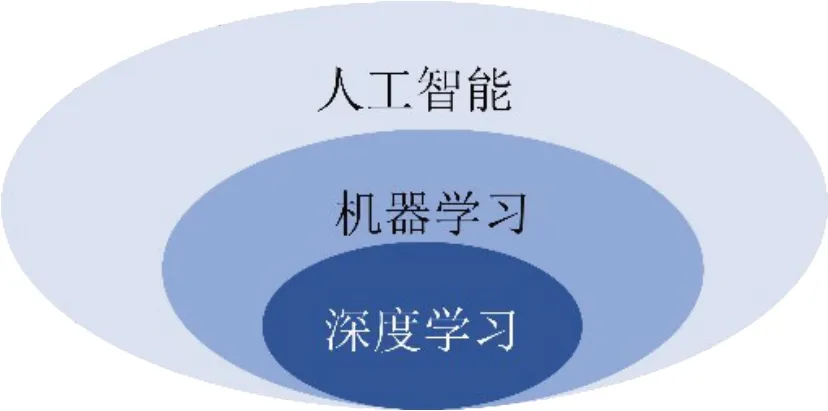
圖1關系示意圖Fig.1 Schematic diagram of the relationship
1.2 遙感影像分割
圖像分割是計算機視覺的一項基本任務,也是許多視覺理解系統的重要組成部分[4]。圖像分割主要通過將圖像(或視頻幀)劃分為多個對象,以獲取邊界及目標物的面(體)積特征等,圖像的輸入和輸出通常都是圖像[5]。這項工作的重點是語義圖像分割[6],在地類監測中,通常對遙感影像進行地塊分割,以獲取地塊邊界及地塊面積信息,具體示例如圖2所示。
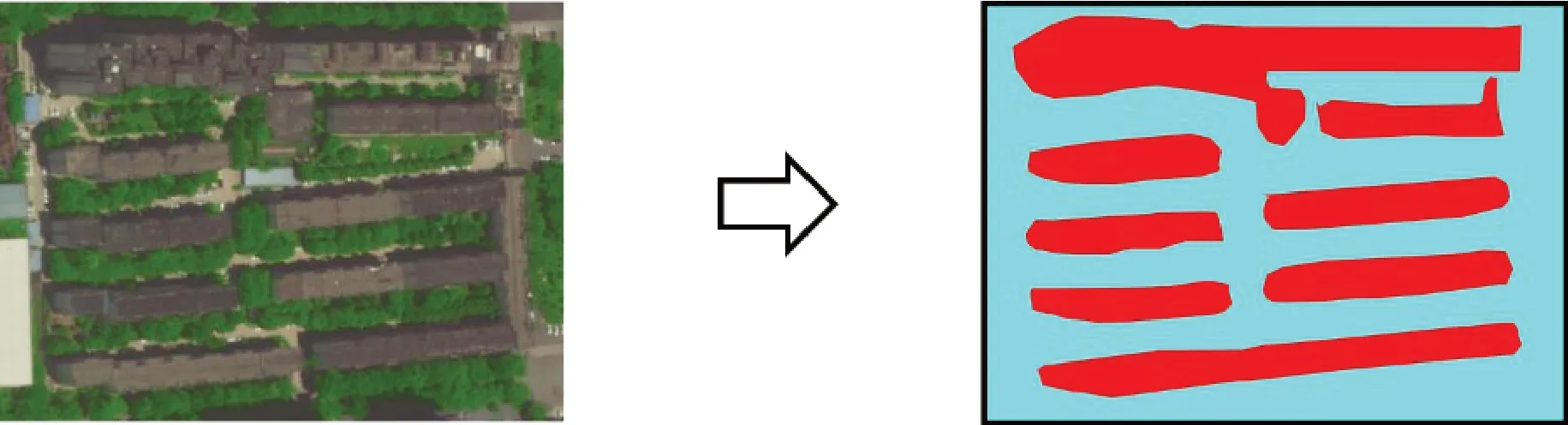
圖2 分割示例Fig.2 A toy example of image segmentation
1.3 遙感影像目標檢測
目標檢測是模擬人類視覺瀏覽觀測物體的方法,即通過算法從圖像或視頻中識別研究目標的位置及方向,從而實現對客觀世界的感知、識別與理解。早期目標檢測主要采取傳統手工特征提取的方法,采取滑動窗口的方式遍歷整張圖像,并從中選取一定數量的候選框進行特征提取,如顏色、紋理、形狀等。而后通過支持向量機(SVM)等分類算法進行候選框分類,最終確定目標內容[7]。但手工特征難以設計,且手工特征不具有魯棒性,效率低,且滑動窗口提取策略非常繁瑣。隨著深度學習算法的發展,使用深度學習算法進行圖像特征提取逐步成為主流,而模型的輸入與輸出示例如圖3所示。

圖3目標檢測示例Fig.3 A toy example of object detection
1.4 遙感影像分類
圖像分類是根據圖像信息中反映的視覺特征如色彩等,把不同類別的圖像區分開的數據處理方法,模型的輸入通常是圖像,輸出往往是類別集,如圖4所示。

圖4 影像分類示例Fig.4 A toy example of image classification
遙感影像分類通常是指對已經切分好的地塊進行分類,屬于圖像分類的子課題[8]。遙感影像分類算法根據訓練樣本中包含標簽的情況可以分為監督學習、半監督學習和無監督學習。監督學習是指利用已知類別的樣本進行模型訓練,如深度卷積神經網絡等。而半監督學習和無監督學習通常是指用缺失一部分或者全部圖像標簽的數據進行模型預測,通常是利用聚類或相似度等算法進行圖像類別預測。此外,近幾年來,無監督學習領域衍生出一種新型訓練方式——自監督學習[9],該方法主要通過大量無標簽數據訓練出一個特征提取器,再利用該特征提取器對下游任務的神經網絡模型進行訓練,獲取下游任務相應的。
2 相關技術
本文主要介紹圖像領域經典的卷積神經網絡模型結構以及近期的主流模型——Transformer模型基礎。
2.1 卷積神經網絡模型基礎
卷積神經網絡模型是圖像領域深度學習技術的基礎架構。卷積神經網絡屬于深度前饋神經網絡,主要包含輸入層、隱藏層和輸出層[10],如圖5所示。
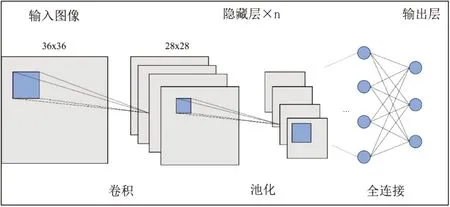
圖5 卷積神經網絡結構示例Fig.5 Overview of convolutional neural network structure
其中隱藏層通常包括卷積層和池化層以及全連接層。輸入層進行數據接受,隱藏層進行圖像特征提取,輸出層進行結果輸出。其中卷積操作是指通過一個感受野即圖中的藍色方塊根據一定步長對圖像進行遍歷掃描,從而獲取圖像的特征。因此,卷積操作本質上可以視為通過感受野進行的一種特征篩選。而池化層相當于對卷積層輸出做下采樣,卷積操作之后圖像的維度會急劇增長,難以直接應用,因此需要通過池化操作選取局部最突出的輸出,再進行分類操作。根據不同的池化方式可以分為最大池化、平均池化以及最小池化等,即取每個過濾器中最大值、平均值或最小值等。全連接層的主要作用是進行分類,通過綜合前面通過卷積和池化獲得的特征,最后進行最后輸出[11]。
2.2 Transformer基礎
Transformer 架構最早是應用于自然語言處理領域,其架構如圖6所示。

圖6 Transformer模型架構Fig.6 Overview of transformer structure
該模型整體為一個端到端(encode-todecode)的架構,完全拋棄了CNN 和RNN 結構,而是使用注意力機制(自注意力機制和多頭注意力機制)。如圖7所示。
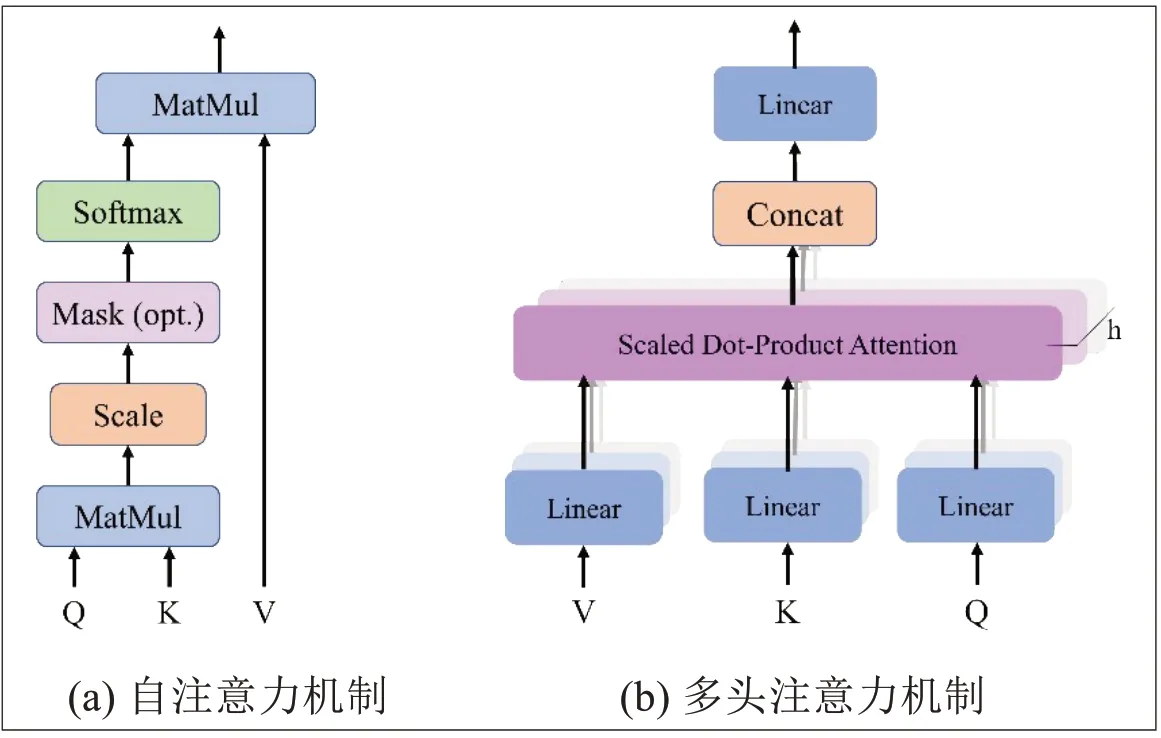
圖7 Transformer中的注意力機制Fig.7 Structure of attention mechanism
在自注意層(Self-Attention Layers)中,輸入向量首先被三個投影矩陣轉換成三個不同的向量,即查詢向量Q,鍵向量K 與值向量V。不同輸入向量間的注意函數則可以通過以下步驟獲得:
第一步:計算不同輸入向量間的得分(score),

第二步:為了穩定梯度對得分歸一化,

第三步:使用softmax函數將得分變為概率,

第四步:獲得加權數值矩陣,

綜上所述,自注意力機制的計算公式為,
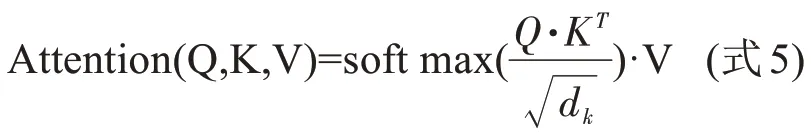
而多頭注意力機制則是用于提高自注意力機制的性能。具體來說,給定一個輸入向量與頭的數量h,輸入的向量首先變換成三組不同的向量,即查詢組、鍵組、值組。每組分別有h個維度,即dq'=dk'=dy'=dmodel/h=64。然后,將來自不同輸入的向量合并在一起生成三組不同的矩陣以及。再將三組矩陣分別拼接為Q',K'以及V'。則多頭注意力機制的計算公式可以表示為:
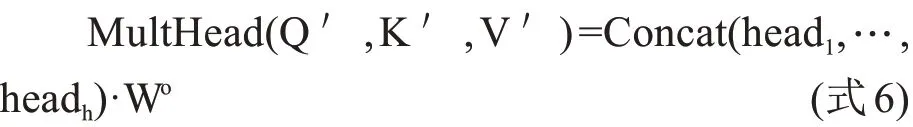
其中headi=Attention(Qi,Ki,Vi),Wo=∈Rdmodel×dmodel為一個線性投影矩陣。當前,Transformer在圖像領域的經典模型主要包括iGPT 模型和ViT 即Vision transformer模型[12]。
3 相關數據集與對應SOTA模型分析
本章分別對圖像分割、目標檢測以及圖像分類三個領域的經典遙感影像數據集進行詳細分析。
3.1 圖像(語義)分割
BigEarthNet 主要使用Sentinel-2 衛星數據,由590326 個圖斑塊組成,區域涵蓋了奧地利、比利時等十個歐洲國家。每個圖斑塊都由CORINE 土地覆蓋數據庫(CLC 2018)提供標注。目前,該數據集的SOTA 模型為MoCo-v2 模型,該模型為MoCo 模型的改進版本。MoCo 是動量對比的縮寫,屬于無監督學習中的自監督學習[8],通過對無標簽數據集進行預訓練,獲取圖像表征。但這種方式需要強大的算力,即Google TPU的加持。而MoCo-v2則對此進行改進,該模型僅需8 個GPU 即可進行模型訓練。最終該模型在BigEarthNet 的準確率高達89.3%。但該模型相較于其他模型需要額外的訓練數據,且對Big-EarthNet算力的要求相對較高。
此外,不同地類獲取子任務也具有特有的數據集,如城市景觀相關的GTA5,ADE20K 以及Foggy Cityscapes 等,以及城市建筑物相關的INRIA aerial image數據集等。
3.2 目標監測
本文主要介紹DOTA 系列數據集。該數據集共包含三個版本。
3.2.1 DOTA-v1.0
最早的DOTA 數據集是用于航空圖像物體檢測的大型數據集,其來源包括多個傳感器和平臺,每個圖像的大小范圍從800×800 到20000×20000,包含多種比例、方向以及形狀的對象。該數據集共包含15 個常見類別,2806 張圖像,188282 個實例,當前該數據集的SOTA 模型為DAFNe 模型,獲得了76.95 的性能。該模型為一個用于定向目標檢測的一階段Anchor-Free 深度學習模型。Anchor-Free 模型這個概念很早就被提出了,如大名鼎鼎的YOLO-v1 就屬于Anchor-Free 模型。這類模型的主要缺陷包括正負樣本失衡、超參難以調試以及訓練匹配耗時嚴重等。以下為不同模型在DOTA-v1.0 上的性能表現變化如圖8所示。
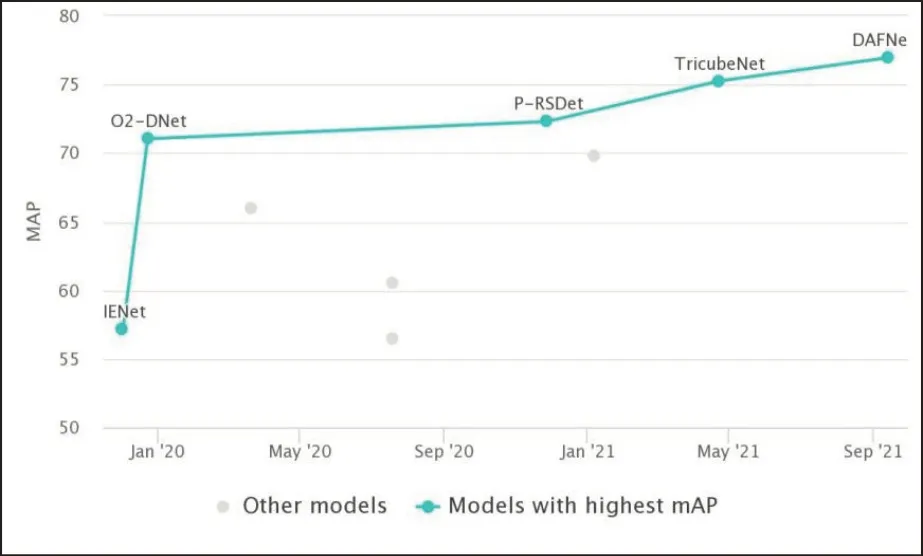
圖8 DOTA-v1.0數據集上不同模SOTA型變化圖Fig.8 Performance of different SOTA models of DOTA-v1.0
3.2.2 DOTA-v1.5
DOTA-v1.5 是數據集在v1.0 的基礎上增加了集裝箱起重機對象類別,并對小于10像素的極小實例冶金學了標注。該版本共計包含403,318個實例。該數據集主要用于航空圖像中的物體檢測。該數據集的SOTA 模型也是DAFNe模型,獲得了71.99的成績。
3.2.3 DOTA-v2.0
DOTA-v2.0 則增加了更多谷歌地球、GF-2 衛星和航拍影像,該數據集共18個常見類別,11268張圖片,1793658 個實例。當前DOTA 數據集在航空圖像目標檢測的SOTA 模型為ViTAE-B +RVSA-ORCN,該模型是視覺Transformers模型與遙感影像結合的產物,提出將遙感影像目標獲取作為一個大型數據集任務,并提出一種旋轉可變大小窗口的注意力機制代替原始Transformers 中的全注意力機制。最終,該模型在DOTA 數據集上取得了81.16%的性能。值得注意的是,該成果中提出的另一模型ViT-B+RVSA-ORCN 排名第二,取得了81.01% 的性能。不同模型在DOTA-v2.0上的性能表現變化如圖9所示。
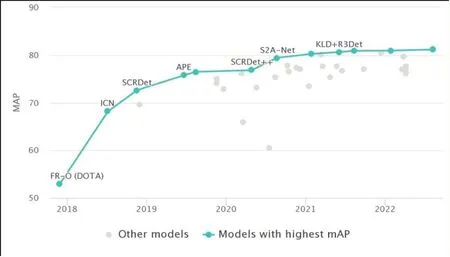
圖9 DOTA-v2.0數據集上不同模SOTA型變化圖Fig.9 Performance of different SOTA models of DOTA-v2.0
3.3 遙感影像分類
3.3.1 UC Merced Land-Use
UC Merced Land-Use 數據集是由UC Merced 計算機視覺實驗室公布的遙感圖像場景分類公開數據集,數據集共分為耕地(agricultural)、機場(airplane)、棒球場(baseball diamond)以及沙灘(beach)等21 個類別。每個類別各包含100 張遙感影像,整個數據集共計2100 張256×256 的遙感影像。這個數據集數據量級較小,無法訓練大型數據集,因而常被用作示例講解。該數據集最新的SOTA 模型為MSMatch,該模型屬于半監督模型,該模型的損失函數等于監督學習損失函數和無監督學習損失函數之和。監督學習部分損失函數即模型預測標簽與真實標簽之間的差異,而無監督學習部分則是預測標簽與偽標簽之間的差異[13],最終該模型在UC Merced Land-Use 數據集上的預測準確率高達98.33%。盡管該模型在部分數據集上達到了媲美監督學習的性能,但因偽標簽獲取需要,將該模型應用于大型數據集時的代價仍有待商榷。此外,與該數據集量級相近的 還 有WHU-RS19,RSC11,SIRI-WHU 以 及RSSCN7等。
3.3.2 EuroSAT
EuroSAT 是由歐洲衛星組織(EuroSAT)發布的,基于Sentinel-2 衛星的土地利用和土地覆蓋分類數據集,涵蓋13 個光譜波段,由10 個類組成,共計27000 條數據。上文提及的MSMatch 模型曾以該數據集作為基準模型,并達到SOTA 效果。當前該數據集的SOTA 模型為MoCo-v2 模型。
整體而言,遙感影像(語義)分割領域因其算法復雜度較高,因此,目前研究的重點主要集中于降低對高性能設備的依賴。目標檢測則主要集中于對Anchor-Based 與Anchor-Free 算法以及兩者融合算法的研究,試圖避免或者減弱兩者缺陷帶來的影響,并提升性能。而遙感影像分類領域目前的研究主流為半監督和無監督(尤其是自監督)學習研究,以減少對人工標簽的依賴。
4 目前不足與展望
4.1 深度學習方法的選擇
理論上遙感影像地類信息獲取可以采用影像分割、目標識別以及分類等任何方式,可以采用任意深度學習方法。但在實際應用中,采用不同的問題定義方法或者模型將直接決定最終數據獲取的精度及時效,不同的模型應用于同一個問題表現出的學習能力、運行速度和自適應性都各有不同,且各模型各具優勢與不同。因此,在后續的應用中需要更加深入地分析問題特征,選擇合適的定義方式與模型。
4.2 地物識別精度
地類識別精度受到多種挑戰,如遙感數據集缺乏人工標注、數據類型的多樣性愈發豐富以及大研究區域的復雜性等[14]。針對第一個問題,盡管當前無監督學習包括自監督學習等得到一定的進步與發展,但并沒有取得通用且令人滿意的成就[15]。因此,在后續的研究中可以進一步加強對無標簽數據的特征提取。針對第二個問題,隨著遙感技術的發展及高光譜遙感的進步,遙感影像的質量及清晰度取得了較大進步。但不同地物的識別或應用場景和獲取往往需要訓練不同的模型,造成計算成本的增加。在后續的研究中可以促進對通用模型或研究范式的研究。針對第三個問題,目前研究大多局限于某個小區域的研究,對大研究區域的精細化研究并沒有取得明顯突破。但在政府等機構的應用和監測中,往往需要對某一行政區域進行統一監測,尤其是進行土地利用規劃時,往往需要對全域地類地物信息進行綜合了解、評估及判定。
4.3 地物識別代價
在深度學習的研究中,地物識別精度的提升往往意味著神經網絡模型的深度、參數量以及模型復雜度等的提升,這也意味著模型訓練及響應成本的增加。因此在后續的研究中,可以考慮在不犧牲識別準確度的前提下,進行優化,降低計算及時間成本,如通過模型優化降低計算成本,通過并行分布式計算提升模型訓練及響應速度。
5 結語
隨著遙感技術的發展,使用遙感影像數據進行土地利用動態監測逐步成為進行自然資源管控的重要技術手段,該類技術能夠為土地利用監測、國土空間規劃以及國家安全等提供實時準確的數據信息和參考依據。傳統基于手工特征或傳統機器學習的方法逐步無法滿足當前社會對遙感影像地物識別精度及獲取速度的需求。深度學習模型憑借其強大的特征提取能力,逐步成為利用遙感影像進行地類自動識別的主流方法,基于深度學習的模型具有更高的識別精度、更低的人工識別成本以及自適應性。但深度學習模型在實際應用中,仍需要注意問題定義及模型選擇,仍需加強對識別精度及相應代價的進一步提升。隨著遙感技術的進一步提升,后續相應信息提取模型的要求也將進一步提升,因此,融合深度學習等新興人工智能方法與遙感影像傳感器等,是未來自然資源智能監測技術發展的必然趨勢。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
人大建設(2020年4期)2020-09-21 03:39:12
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
人大建設(2017年2期)2017-07-21 10:59:25
