小樣本目標(biāo)檢測(cè)研究綜述
2023-01-17 09:31:08劉春磊陳天恩姜舒文
計(jì)算機(jī)與生活 2023年1期
劉春磊,陳天恩,王 聰,姜舒文,陳 棟+
1.廣西大學(xué)計(jì)算機(jī)與電子信息學(xué)院,南寧530004
2.北京市農(nóng)林科學(xué)院信息技術(shù)研究中心,北京100097
3.國(guó)家農(nóng)業(yè)信息化工程技術(shù)研究中心,北京100097
目標(biāo)檢測(cè)是計(jì)算機(jī)視覺(jué)方向的熱點(diǎn)領(lǐng)域,其任務(wù)是將圖像中任意數(shù)目的感興趣對(duì)象用外接矩形框選出來(lái)并識(shí)別出對(duì)象類(lèi)別。作為計(jì)算機(jī)視覺(jué)的基本任務(wù)之一,目標(biāo)檢測(cè)應(yīng)用廣泛,其已經(jīng)在缺陷檢測(cè)[1-3]、農(nóng)業(yè)病蟲(chóng)害識(shí)別[4]和自動(dòng)駕駛[5]等領(lǐng)域發(fā)揮著重要的作用。
2014 年,Girshick 等[6]提出了用于解決目標(biāo)檢測(cè)任務(wù)的R-CNN(region-based convolutional neural networks)算法并取得了極大的性能提升,目標(biāo)檢測(cè)研究從此進(jìn)入深度學(xué)習(xí)時(shí)代。Girshick 等[7]又在2016 年提出了經(jīng)典的Faster R-CNN 兩階段算法,首先在圖像上生成大量可能是對(duì)象的候選區(qū),然后對(duì)這些候選區(qū)進(jìn)行篩選,對(duì)篩選得到的候選區(qū)進(jìn)行分類(lèi)和回歸得到想要的結(jié)果。由于兩階段算法會(huì)基于生成的大量候選區(qū)做進(jìn)一步處理,雖然檢測(cè)精度較高,但檢測(cè)速度相對(duì)不是很理想。一階段算法不需要事先通過(guò)專(zhuān)門(mén)的算法模塊生成大量候選區(qū),而只是在圖像上預(yù)先定義了不同大小和比例的錨框,用這些錨框代替了兩階段算法的候選區(qū),不再需要復(fù)雜的候選區(qū)操作,只需對(duì)圖像進(jìn)行一次卷積處理就可以完成對(duì)象的定位和分類(lèi),經(jīng)典的一階段網(wǎng)絡(luò)有YOLO(you only look once)系列[8-10]、SSD(single shot multibox detector)[11]、RetinaNet[12]等。近些年,在自然語(yǔ)言處理領(lǐng)域大放異彩的Transformer[13]技術(shù)也被成功應(yīng)用到目標(biāo)檢測(cè)中,DETR(detection transformer)[14]是其中的代表之作,其不再需要錨框、候選區(qū)和非極大值抑制等人為設(shè)計(jì)的知識(shí),而是將目標(biāo)檢測(cè)看作直接的集合預(yù)測(cè)問(wèn)題,真正地實(shí)現(xiàn)了端到端檢測(cè)。
上述的目標(biāo)檢測(cè)方法都需要使用大量實(shí)例級(jí)別的標(biāo)注信息來(lái)實(shí)現(xiàn),這可能會(huì)出現(xiàn)以下一些問(wèn)題:(1)由于現(xiàn)實(shí)世界中固有的長(zhǎng)尾分布,有些類(lèi)別本身就很難獲得大量的標(biāo)注信息,比如珍稀動(dòng)植物、罕見(jiàn)病癥等;(2)圖像的標(biāo)注通常需要消耗大量的人力去完成,而且,標(biāo)注的準(zhǔn)確率也不穩(wěn)定,漏標(biāo)和誤標(biāo)的情況常有發(fā)生,尤其是某些難以標(biāo)注的對(duì)象,比如病蟲(chóng)害、腫瘤等;(3)模型的訓(xùn)練需要消耗大量的資源,如昂貴的GPU 設(shè)備和專(zhuān)業(yè)的領(lǐng)域知識(shí)等。當(dāng)只有很少的標(biāo)注信息時(shí),現(xiàn)有主流的目標(biāo)檢測(cè)方法很難達(dá)到令人滿(mǎn)意的效果。然而,現(xiàn)實(shí)生活中,即便一個(gè)孩童,也能夠通過(guò)僅僅觀察幾張圖像就完成對(duì)新類(lèi)別的學(xué)習(xí)。因此,通過(guò)很少的樣本數(shù)量進(jìn)行目標(biāo)檢測(cè)是一個(gè)極具現(xiàn)實(shí)意義的問(wèn)題,受到了越來(lái)越多的關(guān)注。
小樣本學(xué)習(xí)只使用很少的訓(xùn)練樣本就能夠得到想要的結(jié)果。現(xiàn)在,小樣本學(xué)習(xí)在圖像分類(lèi)、語(yǔ)義分割和目標(biāo)檢測(cè)這三大計(jì)算機(jī)視覺(jué)任務(wù)上都有應(yīng)用,但迄今為止研究的重點(diǎn)主要集中在圖像分類(lèi)。相比分類(lèi),小樣本目標(biāo)檢測(cè)問(wèn)題更加復(fù)雜,其不僅僅需要分類(lèi)目標(biāo)的類(lèi)別,還需要定位出目標(biāo)的具體位置。小樣本目標(biāo)檢測(cè)問(wèn)題的提出是為了解決實(shí)際生產(chǎn)生活中樣本數(shù)據(jù)標(biāo)注量少的問(wèn)題,是非常有現(xiàn)實(shí)意義的研究方向。目前,已有一些關(guān)于小樣本目標(biāo)檢測(cè)的綜述,潘興甲等[15]將小樣本目標(biāo)檢測(cè)方法分為基于微調(diào)、基于模型結(jié)構(gòu)和基于度量學(xué)習(xí)三種,并對(duì)這些分類(lèi)方法進(jìn)行了分析。劉浩宇等[16]將其分成基于數(shù)據(jù)、模型和算法三個(gè)類(lèi)別,并對(duì)每個(gè)類(lèi)別進(jìn)行了歸納總結(jié),探討了小樣本目標(biāo)檢測(cè)的現(xiàn)狀和未來(lái)趨勢(shì)。張振偉等[17]也從六方面對(duì)小樣本目標(biāo)檢測(cè)方法進(jìn)行了分析,比較了不同方法的優(yōu)缺點(diǎn)。與這些綜述[15-17]不同,本文首先將這些方法歸納為兩種范式,再按照改進(jìn)策略的不同,從基于注意力機(jī)制、圖卷積神經(jīng)網(wǎng)絡(luò)、度量學(xué)習(xí)和數(shù)據(jù)增強(qiáng)的角度進(jìn)行歸納總結(jié),對(duì)比分析了不同分類(lèi)的優(yōu)缺點(diǎn)和適用場(chǎng)景。同時(shí),收錄了近兩年提出的許多新的小樣本目標(biāo)檢測(cè)方法,對(duì)比分析了這些方法的性能表現(xiàn)。
1 小樣本目標(biāo)檢測(cè)概述
1.1 小樣本目標(biāo)檢測(cè)定義和訓(xùn)練過(guò)程
小樣本目標(biāo)檢測(cè)(few-shot object detection,F(xiàn)SOD)相對(duì)于通用目標(biāo)檢測(cè)最大的不同,是其數(shù)據(jù)輸入的不同,F(xiàn)SOD 將數(shù)據(jù)集分為基類(lèi)數(shù)據(jù)集Db和新類(lèi)數(shù)據(jù)集Dn。基類(lèi)數(shù)據(jù)集Db由擁有大量標(biāo)注圖像的基類(lèi)Cb組成,新類(lèi)數(shù)據(jù)集Dn由只有少量標(biāo)注圖像的新類(lèi)Cn組成,其中,基類(lèi)類(lèi)別和新類(lèi)類(lèi)別不存在交集,即Cb?Cn=?。小樣本目標(biāo)檢測(cè)方法的目標(biāo)是通過(guò)在基類(lèi)和新類(lèi)數(shù)據(jù)集上訓(xùn)練得到一個(gè)模型,期待該模型可以檢測(cè)出任意給定測(cè)試圖像中的新類(lèi)和基類(lèi)對(duì)象,小樣本目標(biāo)檢測(cè)定義如圖1 所示。
小樣本目標(biāo)檢測(cè)算法的訓(xùn)練過(guò)程一般分為兩個(gè)階段:第一階段使用大量的基類(lèi)數(shù)據(jù)Dbase進(jìn)行模型的訓(xùn)練,從初始化模型Minit得到基模型Mbase,稱(chēng)之為基訓(xùn)練階段;第二階段使用由少量的基類(lèi)數(shù)據(jù)Dbase和新類(lèi)數(shù)據(jù)Dnovel組成的平衡數(shù)據(jù)集Dfinetune對(duì)基模型Mbase進(jìn)行模型微調(diào),得到最終模型Mf,稱(chēng)之為微調(diào)階段。整個(gè)訓(xùn)練過(guò)程如圖2 所示。
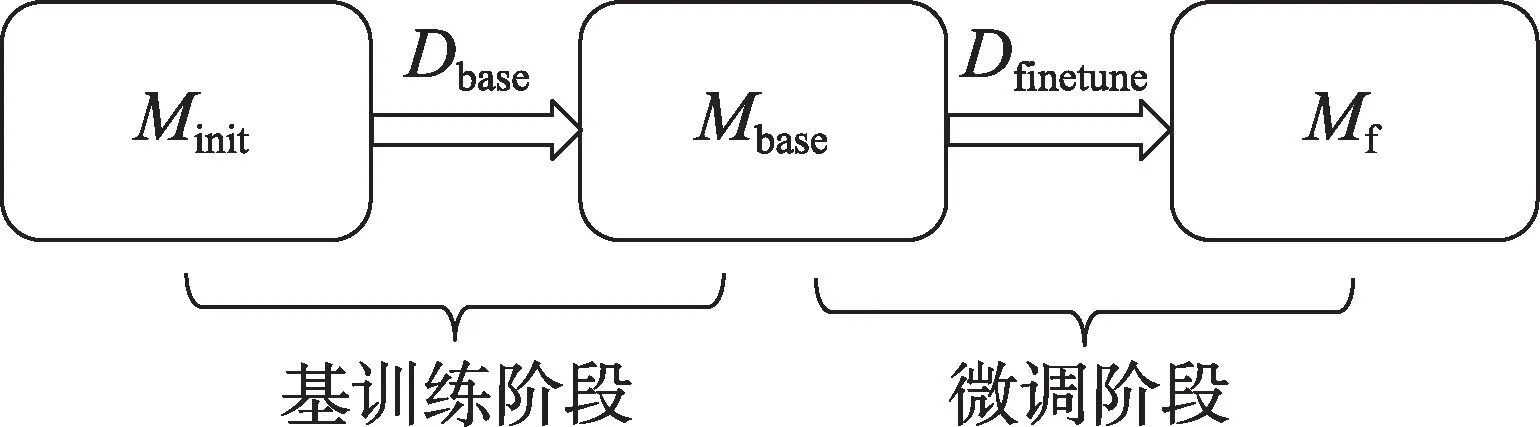
圖2 模型訓(xùn)練過(guò)程Fig.2 Model training process
1.2 小樣本目標(biāo)檢測(cè)的相關(guān)領(lǐng)域研究
在通用目標(biāo)檢測(cè)的基礎(chǔ)上,有一些其他新穎的研究方向,這些研究方向與小樣本目標(biāo)檢測(cè)有相似之處,容易造成混淆,本節(jié)對(duì)這些研究方向進(jìn)行簡(jiǎn)易的區(qū)分解釋。
零樣本目標(biāo)檢測(cè)[18]在算法模型的訓(xùn)練階段只使用可見(jiàn)類(lèi)別,不可見(jiàn)類(lèi)別的視覺(jué)信息不會(huì)被使用到,而用其語(yǔ)義等輔助信息參與訓(xùn)練,這些輔助信息正是零樣本目標(biāo)檢測(cè)的研究重點(diǎn)。小樣本目標(biāo)檢測(cè)可以使用少量的新類(lèi)圖像作為視覺(jué)方面的信息,同時(shí)借鑒零樣本中不可見(jiàn)類(lèi)別中輔助信息的使用;單例目標(biāo)檢測(cè)[19]是小樣本目標(biāo)檢測(cè)的一個(gè)特例,其中每個(gè)新類(lèi)只有一個(gè)標(biāo)注對(duì)象信息;任意樣本目標(biāo)檢測(cè)[20]將零樣本或者小樣本的情況同時(shí)考慮,即一個(gè)算法模型既可以解決零樣本問(wèn)題又可以處理小樣本問(wèn)題。
還有一些其他的研究在小樣本目標(biāo)檢測(cè)的基礎(chǔ)上,新增加一些新的領(lǐng)域限定條件。為了避免災(zāi)難性遺忘,同時(shí)可以持續(xù)檢測(cè)不斷增加的新類(lèi)別,提出了類(lèi)增量小樣本目標(biāo)檢測(cè)[21];半監(jiān)督小樣本目標(biāo)檢測(cè)[22]在不增加新類(lèi)標(biāo)注的情況下,將基類(lèi)數(shù)據(jù)的來(lái)源修改為有標(biāo)注的圖像和沒(méi)有標(biāo)注的圖像;弱監(jiān)督小樣本目標(biāo)檢測(cè)[23]相對(duì)于小樣本目標(biāo)檢測(cè)的區(qū)別在于其數(shù)據(jù)集中新類(lèi)標(biāo)注不是實(shí)例級(jí)的,而是由圖像級(jí)標(biāo)注構(gòu)成的。
圖3 從數(shù)據(jù)流向的角度展示了小樣本目標(biāo)檢測(cè)及其相似任務(wù)之間的區(qū)別與聯(lián)系。這些研究領(lǐng)域的數(shù)據(jù)集構(gòu)成都由基類(lèi)和新類(lèi)組成,為了避免混淆,更加明確本綜述的研究范圍,本文對(duì)這些相似概念做了簡(jiǎn)單的區(qū)分說(shuō)明。同時(shí),可以從這些領(lǐng)域?qū)ふ覇?wèn)題解決的靈感,將其應(yīng)用到小樣本目標(biāo)檢測(cè)方法。
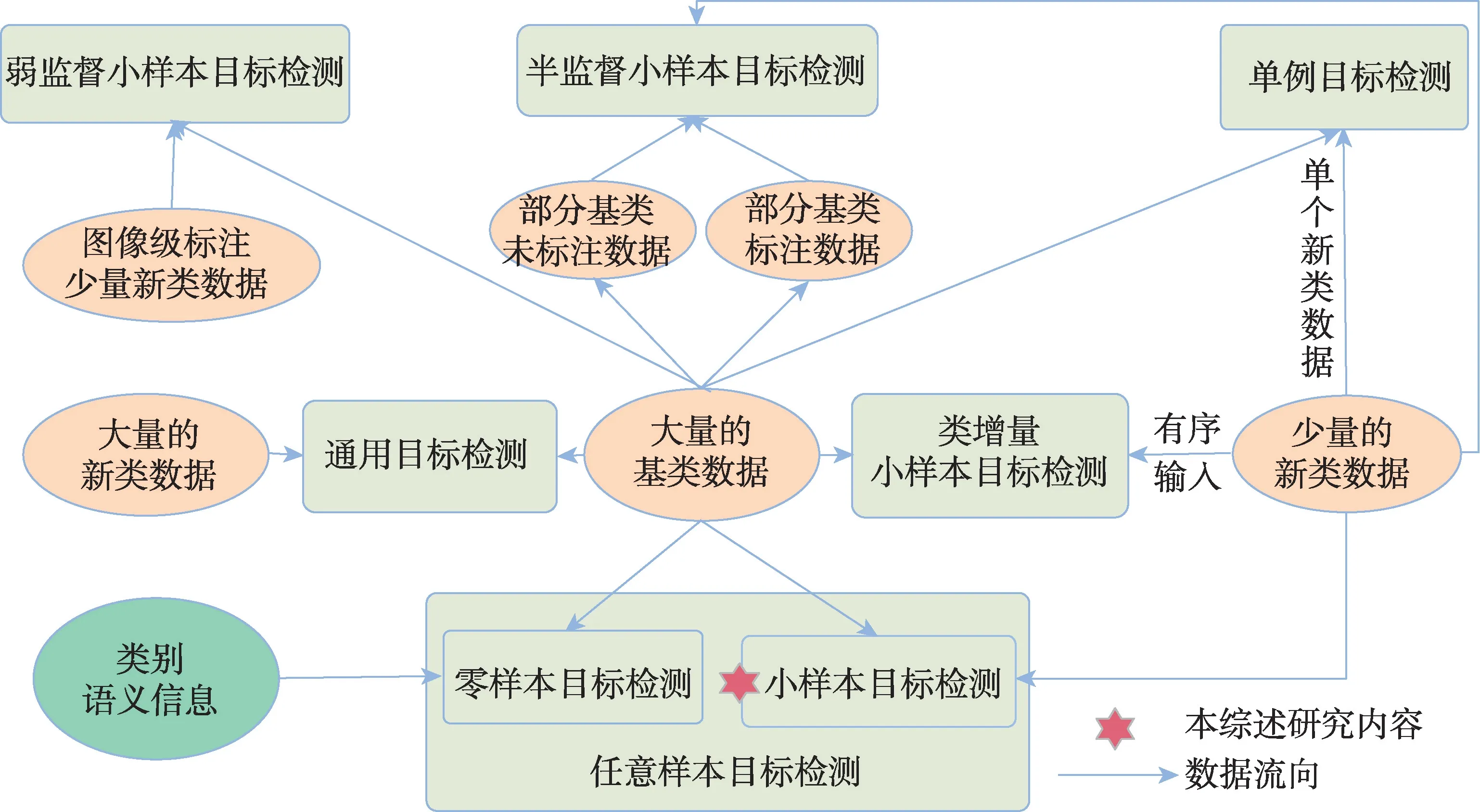
圖3 小樣本目標(biāo)檢測(cè)及其相似任務(wù)的區(qū)別與聯(lián)系Fig.3 Differences and connections between few-shot object detection and its similar tasks
2 小樣本目標(biāo)檢測(cè)的兩類(lèi)經(jīng)典范式
目前的小樣本目標(biāo)檢測(cè)方法可以概括為兩種范式,基于遷移學(xué)習(xí)的范式和基于元學(xué)習(xí)的范式。基于遷移學(xué)習(xí)的范式是將從已知類(lèi)中學(xué)習(xí)到的知識(shí)遷移到未知類(lèi)的檢測(cè)任務(wù)中。基于元學(xué)習(xí)的范式是利用元學(xué)習(xí)器從不同的任務(wù)中學(xué)習(xí)元知識(shí),然后對(duì)包含有新類(lèi)的任務(wù)通過(guò)元知識(shí)的調(diào)整完成對(duì)新類(lèi)的檢測(cè)。本章將對(duì)這兩種范式的典型方法進(jìn)行簡(jiǎn)述。
2.1 基于遷移學(xué)習(xí)的范式
兩階段微調(diào)方法(two-stage fine-tuning approach,TFA)[24]是遷移學(xué)習(xí)范式的基線(xiàn)方法,基于Faster RCNN 算法進(jìn)行改進(jìn)。TFA 認(rèn)為Faster R-CNN 主干網(wǎng)絡(luò)是類(lèi)無(wú)關(guān)的,特征信息可以很自然地從基類(lèi)遷移到新類(lèi)上,僅僅只需要微調(diào)檢測(cè)器的最后一層(包含類(lèi)別分類(lèi)和邊界框回歸),就可以達(dá)到遠(yuǎn)遠(yuǎn)超過(guò)之前方法的性能表現(xiàn)。整個(gè)方法分為基訓(xùn)練和微調(diào)兩個(gè)階段,如圖4 所示。在基訓(xùn)練階段,整個(gè)模型在有著大量標(biāo)注的基類(lèi)上訓(xùn)練;在微調(diào)階段,凍結(jié)網(wǎng)絡(luò)前期的參數(shù)權(quán)重,由基類(lèi)和新類(lèi)組成的平衡子集對(duì)頂層的分類(lèi)器和回歸器進(jìn)行微調(diào)。另外,TFA 在微調(diào)階段的分類(lèi)器上采用余弦相似性測(cè)量候選框和真實(shí)類(lèi)別邊界框之間的相似性。
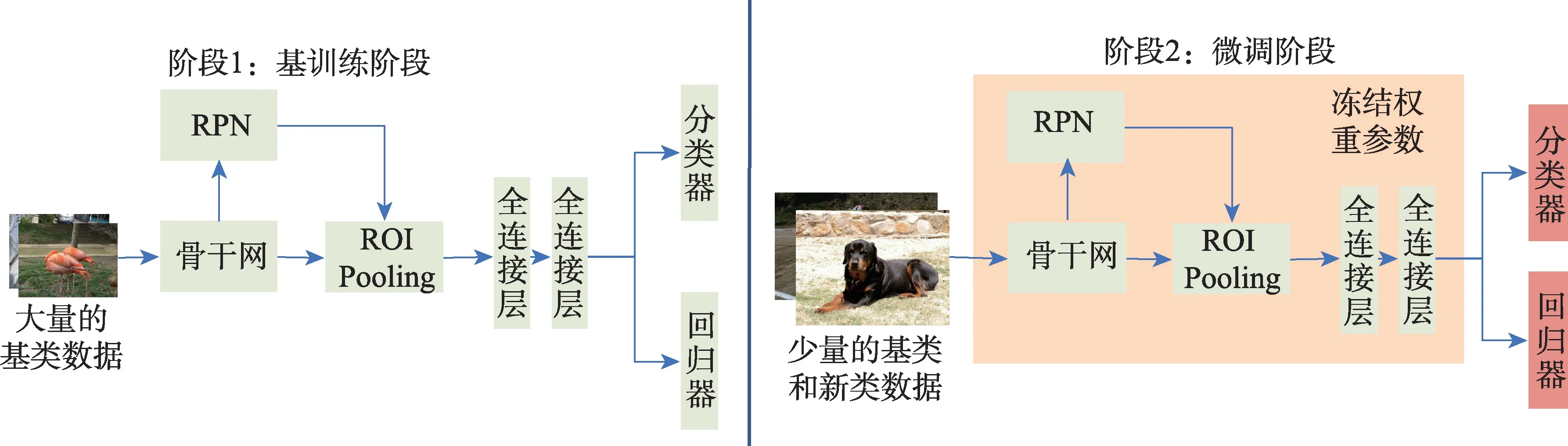
圖4 遷移學(xué)習(xí)基線(xiàn)方法TFA 算法架構(gòu)圖Fig.4 Model architecture diagram of transfer learning baseline method TFA
由于小樣本中每個(gè)新類(lèi)別的樣本量非常少,其高方差可能會(huì)導(dǎo)致檢測(cè)結(jié)果的不可靠,TFA 通過(guò)抽樣多組訓(xùn)練樣本進(jìn)行評(píng)估,并且在不同組進(jìn)行多次實(shí)驗(yàn)得到平均值。由于統(tǒng)計(jì)上的偏差,之前的評(píng)估標(biāo)準(zhǔn)無(wú)法完成不同算法的統(tǒng)一比較,TFA 修改了原先的數(shù)據(jù)基準(zhǔn),在VOC[25]、COCO[26]和LVIS[27]三個(gè)數(shù)據(jù)集上建立了新的基準(zhǔn),檢測(cè)基類(lèi)、新類(lèi)和全部數(shù)據(jù)集上的性能表現(xiàn),提出了廣義小樣本目標(biāo)檢測(cè)基準(zhǔn)。
2.2 基于元學(xué)習(xí)的范式
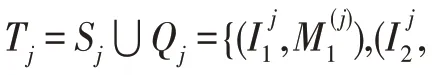
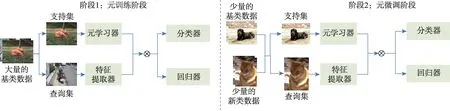
圖5 元學(xué)習(xí)基線(xiàn)方法FSRW 算法架構(gòu)圖Fig.5 Model architecture diagram of meta-learning baseline method FSRW
FSRW[28]整個(gè)網(wǎng)絡(luò)模型是基于一階段網(wǎng)絡(luò)YOLOv2[9]進(jìn)行改進(jìn)的,在一階段網(wǎng)絡(luò)中新增了元特征學(xué)習(xí)器和元學(xué)習(xí)器模塊,元特征學(xué)習(xí)器以查詢(xún)圖像為輸入,使用YOLOv2 的骨干實(shí)現(xiàn),從有充足樣本的基類(lèi)圖像中提取具有泛化性的元特征,用于之后檢測(cè)新類(lèi)。元學(xué)習(xí)器模塊以支持集為輸入,將新類(lèi)的某一類(lèi)別實(shí)例轉(zhuǎn)換為一個(gè)全局向量,該向量用來(lái)檢測(cè)特定類(lèi)別的對(duì)象實(shí)例。網(wǎng)絡(luò)的訓(xùn)練過(guò)程同樣分兩階段完成,首先使用基類(lèi)數(shù)據(jù)訓(xùn)練連同元學(xué)習(xí)器模塊在內(nèi)的整個(gè)網(wǎng)絡(luò)模型,然后由少量標(biāo)注的新類(lèi)和基類(lèi)組成的平衡數(shù)據(jù)集微調(diào)模型以適應(yīng)新類(lèi)。
2.3 兩種范式的對(duì)比分析
(1)遷移學(xué)習(xí)和元學(xué)習(xí)的相同點(diǎn):
①兩種范式都是為了解決小樣本目標(biāo)檢測(cè)任務(wù)而提出的,都希望通過(guò)少量的新類(lèi)圖像就可以完成對(duì)新類(lèi)別的檢測(cè)。
②兩種范式的數(shù)據(jù)集都分為有大量標(biāo)注的基類(lèi)數(shù)據(jù)和只有少量標(biāo)注的新類(lèi)數(shù)據(jù)。
③兩種范式的訓(xùn)練過(guò)程都分為兩階段進(jìn)行,分別是基訓(xùn)練階段和微調(diào)階段,算法模型在基訓(xùn)練階段學(xué)習(xí)到基類(lèi)數(shù)據(jù)具有泛化性的知識(shí),然后在新類(lèi)數(shù)據(jù)上對(duì)模型進(jìn)行微調(diào),達(dá)到檢測(cè)新類(lèi)的目的。
④兩種范式的評(píng)價(jià)指標(biāo)相同,不論是VOC 數(shù)據(jù)集、COCO 數(shù)據(jù)集,還是FSOD 數(shù)據(jù)集[29],兩種范式的評(píng)價(jià)指標(biāo)都是相同的。
(2)遷移學(xué)習(xí)和元學(xué)習(xí)的不同點(diǎn):
①數(shù)據(jù)的輸入方式不同,元學(xué)習(xí)范式是以任務(wù)(episode)為輸入單元,每個(gè)任務(wù)由支持集圖像和查詢(xún)集圖像組成,目的是找到查詢(xún)集圖像中屬于支持集類(lèi)別的目標(biāo)對(duì)象,而遷移學(xué)習(xí)范式通常不需要分為支持集和查詢(xún)集兩部分。
②元學(xué)習(xí)范式隨著支持集中類(lèi)別數(shù)量的增加,內(nèi)存利用率會(huì)降低,而遷移學(xué)習(xí)范式不會(huì)隨著類(lèi)別數(shù)量的增加而使內(nèi)存利用率降低。
③元學(xué)習(xí)范式除了通用目標(biāo)檢測(cè)模型外,還有一個(gè)需要獲得類(lèi)別級(jí)元知識(shí)的元學(xué)習(xí)器,而遷移學(xué)習(xí)范式只需要在通用目標(biāo)檢測(cè)模型上改進(jìn)即可。
3 小樣本目標(biāo)檢測(cè)算法研究現(xiàn)狀
上一章中,將小樣本目標(biāo)檢測(cè)分為基于元學(xué)習(xí)和基于遷移學(xué)習(xí)兩種范式,在這兩種范式中,存在著一些共性的解決方法,依據(jù)這些方法改進(jìn)策略的不同,將小樣本目標(biāo)檢測(cè)分類(lèi)為基于注意力機(jī)制、基于圖卷積神經(jīng)網(wǎng)絡(luò)、基于度量學(xué)習(xí)和基于數(shù)據(jù)增強(qiáng)四種實(shí)現(xiàn)方式,分類(lèi)概況如圖6 所示。在本章中,將對(duì)這些分類(lèi)方法進(jìn)行詳細(xì)分析和總結(jié)。
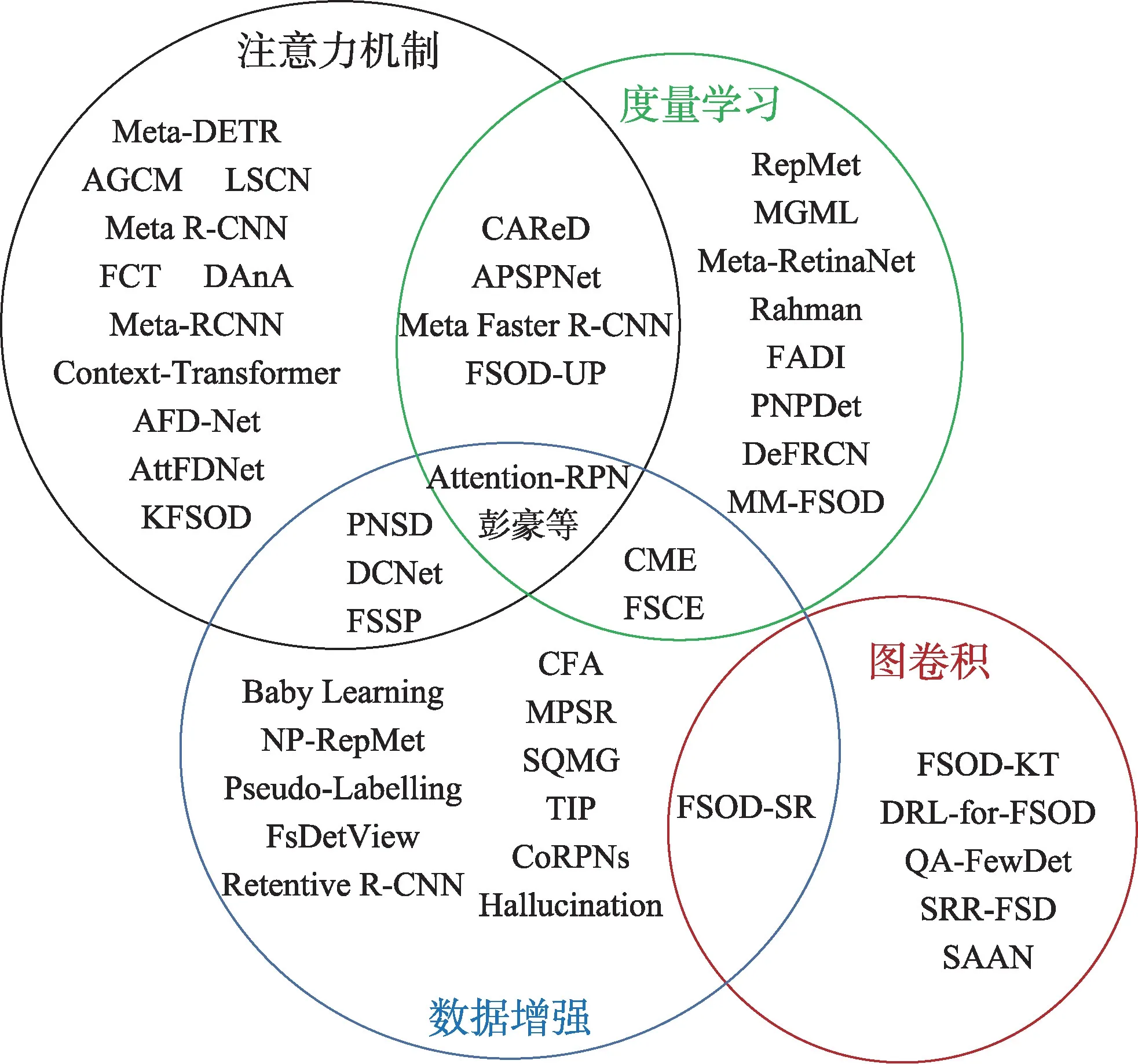
圖6 分類(lèi)圖Fig.6 Classification graph
3.1 基于注意力機(jī)制
對(duì)于小樣本目標(biāo)檢測(cè)來(lái)說(shuō),難以從少量的新類(lèi)樣本中準(zhǔn)確學(xué)習(xí)到感興趣對(duì)象的特征信息,而通過(guò)注意力機(jī)制可以較為準(zhǔn)確地找到圖像中的感興趣區(qū)域,目前已有一些關(guān)于注意力機(jī)制的研究[30],注意力機(jī)制可以看作一個(gè)動(dòng)態(tài)選擇的過(guò)程,通過(guò)輸入的重要性對(duì)特征進(jìn)行自適應(yīng)特征加權(quán)。本節(jié)將其分為通道注意力、空間注意力和Transformer自注意力方法。
3.1.1 通道注意力
2018 年Hu 等[31]首次提出了使用SENet 的通道注意力,如圖7 所示,不同特征圖的不同通道可能代表著不同的對(duì)象,當(dāng)需要選擇什么對(duì)象時(shí),通道注意力使用自適應(yīng)的方法重新校準(zhǔn)每個(gè)通道的權(quán)重來(lái)關(guān)注該對(duì)象。
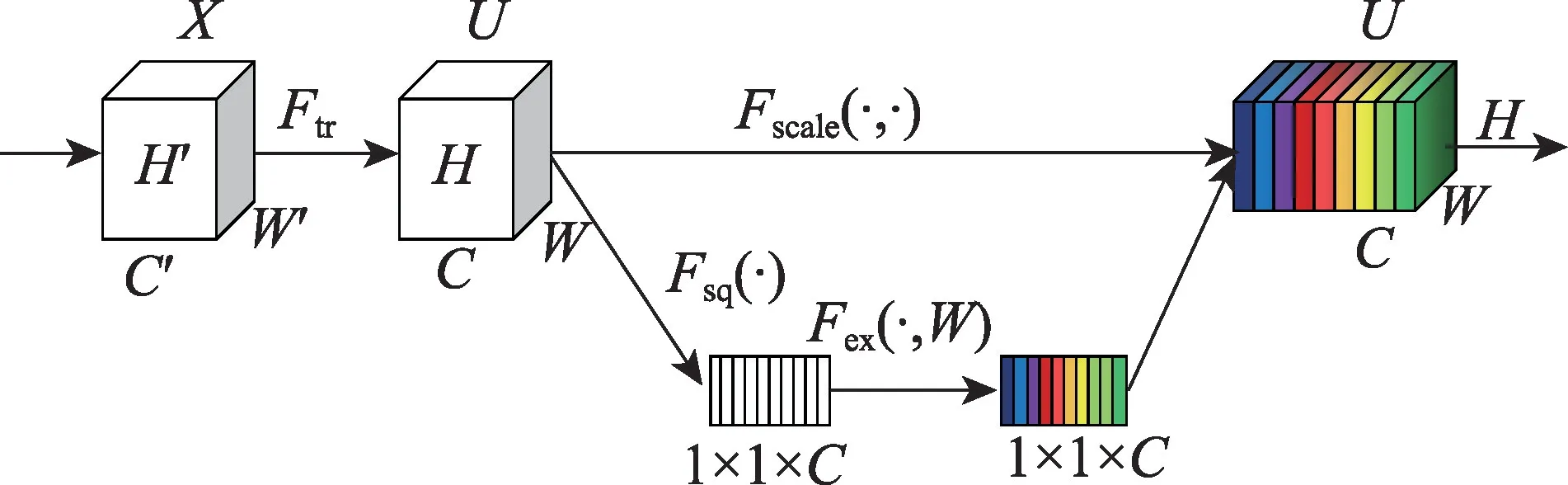
圖7 SE 模塊Fig.7 SE block
在遷移學(xué)習(xí)范式上,Zhang 等[32]使用二階池化和冪正則化計(jì)算支持特征和查詢(xún)特征之間的互相關(guān)性,二階池化提取支持特征數(shù)據(jù)的二階統(tǒng)計(jì),形成注意力調(diào)制圖,通過(guò)添加冪正則化可以減少二階池化帶來(lái)的可變性。Wu 等[33]提出了FSOD-UP(universalprototype augmentation for few-shot object detection)方法,使用了通用原型的知識(shí),在條件性通用原型和候選框上施加通道注意力機(jī)制,提高了候選框的生成質(zhì)量,以此提高方法對(duì)新類(lèi)的檢測(cè)性能。
在元學(xué)習(xí)范式上,Yan 等[34]針對(duì)一張圖像有多個(gè)目標(biāo)的問(wèn)題提出了Meta R-CNN 方法,該方法不是對(duì)整張圖像而是在感興趣區(qū)域上使用元學(xué)習(xí)范式。Meta R-CNN 新增加了預(yù)測(cè)頭重塑網(wǎng)絡(luò)分支,該分支用有標(biāo)注的支持圖像獲取每個(gè)類(lèi)別的注意向量,對(duì)模型生成的感興趣區(qū)域特征應(yīng)用該向量進(jìn)行通道注意力關(guān)注,以檢測(cè)出查詢(xún)圖像中與這些向量表示的類(lèi)別相同的對(duì)象。Wu 等[35]在Meta-RCNN 中將由支持集得到的類(lèi)原型與查詢(xún)集的特征圖通過(guò)類(lèi)別注意力結(jié)合起來(lái),獲得每個(gè)特定類(lèi)的特征圖,然后將這些特征圖結(jié)合起來(lái)使用隨后的區(qū)域候選網(wǎng)絡(luò)和檢測(cè)頭對(duì)查詢(xún)集進(jìn)行分類(lèi)和定位。Fan 等[29]在提出的Attention-RPN 方法前期階段使用深度互相關(guān)注意力區(qū)域候選網(wǎng)絡(luò),通過(guò)通道注意力機(jī)制利用支持集和查詢(xún)集之間的關(guān)系提高候選框的生成質(zhì)量。Liu 等[36]認(rèn)為檢測(cè)中分類(lèi)和定位子任務(wù)對(duì)特征嵌入的喜好不同,提出了AFD-Net(adaptive fully-dual network)方法,分開(kāi)處理分類(lèi)和定位問(wèn)題,對(duì)支持集分支使用注意力機(jī)制產(chǎn)生分類(lèi)和回歸兩個(gè)通道注意力分支,之后將這兩個(gè)分支與查詢(xún)集的感興趣區(qū)域的分類(lèi)和定位特征進(jìn)行聚合處理,最終得到增強(qiáng)的特征表示。
3.1.2 空間注意力
當(dāng)人們看到一張圖像時(shí),他們總是會(huì)將視線(xiàn)聚焦于圖像中的某一區(qū)域,空間注意力受此啟發(fā),對(duì)特征圖上的每個(gè)位置進(jìn)行注意力調(diào)整,可以自適應(yīng)地關(guān)注圖像中的某重點(diǎn)區(qū)域,這些重點(diǎn)區(qū)域往往是人們所感興趣的對(duì)象。
Chen 等[37]基于遷移學(xué)習(xí)范式提出了AttFDNet 方法,將自底向上的空間注意力和自頂向下的通道注意力結(jié)合起來(lái),自底向上注意力由顯著性注意(saliency attentive model,SAM)模塊實(shí)現(xiàn),由于其類(lèi)別無(wú)關(guān)性,能夠自然檢測(cè)圖像中的顯著區(qū)域。Yang等[38]為解決訓(xùn)練集數(shù)據(jù)多樣性少的問(wèn)題,提出了CTNet方法,使用親和矩陣在不同尺度、位置和空間關(guān)系三方面識(shí)別每個(gè)候選框上下文字段的重要性,再用上下文聚合將這些關(guān)系與候選框聚合起來(lái),利于新類(lèi)別分類(lèi)的同時(shí),避免了大量的誤分類(lèi)。Li 等[39]提出了LSCN(low-shot classification correction network)方法,用從基類(lèi)檢測(cè)器中得到的誤檢候選框作為方法校正網(wǎng)絡(luò)分支的輸入,使用空間注意力機(jī)制通過(guò)跨通道的任意兩個(gè)位置間的成對(duì)關(guān)系獲得全局感受野,通過(guò)捕捉整張圖像的信息,解決候選框復(fù)雜的對(duì)象外觀問(wèn)題。Xu 等[40]在FSSP(few-shot object detection via sample processing)方法中使用了自我注意力模塊(self-attention module,SAM),該空間注意力模塊可以突出顯示目標(biāo)對(duì)象的物理特征而忽略其他的噪聲信息,更好地提取復(fù)雜樣本的特征信息。Agarwal 等[41]提出了AGCM(attention guided cosine margin)方法解決小樣本下的災(zāi)難性遺忘和類(lèi)別混淆問(wèn)題,構(gòu)建了注意力候選框融合模塊,通過(guò)空間注意力關(guān)注不同候選框之間的相似性,用于減少類(lèi)內(nèi)的方差,從而在檢測(cè)器的分類(lèi)頭中創(chuàng)建類(lèi)內(nèi)更加緊密、類(lèi)間良好分離的特征簇。
基于元學(xué)習(xí)范式,Chen 等[42]為解決小樣本任務(wù)中的空間錯(cuò)位和特征表示模糊問(wèn)題,提出了包含跨圖像空間注意的DAnA(dual-awareness attention)方法,通過(guò)跨圖像空間注意自適應(yīng)地將支持圖像轉(zhuǎn)化為查詢(xún)位置感知向量,通過(guò)測(cè)量該感知向量和查詢(xún)區(qū)域的相關(guān)性,確定查詢(xún)區(qū)域是否為想要的目標(biāo)對(duì)象。Meta Faster R-CNN[43]將檢測(cè)頭分為基類(lèi)檢測(cè)和新類(lèi)檢測(cè)兩種,基類(lèi)檢測(cè)沿用原有的Faster R-CNN部分,新類(lèi)檢測(cè)頭提出了Meta-Classifier模塊,使用注意力機(jī)制進(jìn)行特征對(duì)齊,解決空間錯(cuò)位問(wèn)題,在查詢(xún)圖像的候選框特征和支持集類(lèi)原型的每個(gè)空間位置通過(guò)親和矩陣計(jì)算對(duì)應(yīng)關(guān)系,基于對(duì)應(yīng)關(guān)系,獲得想要的前景對(duì)象。Quan 等[44]認(rèn)為在支持集中使用互相關(guān)技術(shù)會(huì)給查詢(xún)特征引入噪聲,提出了CAReD(cross attention redistribution)方法,專(zhuān)注挖掘有助于候選框生成的支持特征,去除有害的支持噪聲。不再對(duì)支持集特征作平均處理,而是通過(guò)空間注意力計(jì)算同一類(lèi)別不同實(shí)例之間的相關(guān)性,對(duì)每個(gè)支持特征重加權(quán),從而得到最終的支持特征。彭豪等[45]在由多尺度空間金字塔池算法生成的不同層次上產(chǎn)生注意力圖,強(qiáng)化了特定尺度物體的線(xiàn)索,可以提高小目標(biāo)的檢測(cè)能力。Zhang 等[46]提出了KFSOD(kernelized few-shot object detector)方法,針對(duì)PNSD(power normalizing second-order detector)中核化仍然是線(xiàn)性相關(guān)的問(wèn)題,使用核化自相關(guān)單元從支持圖像中提取特征形成線(xiàn)性、多項(xiàng)式和RBF(radial basis function)核化表示。然后將這些特征表示與查詢(xún)圖像的特征進(jìn)行交叉相關(guān)以獲得注意力權(quán)重,并通過(guò)注意力區(qū)域提議網(wǎng)絡(luò)生成查詢(xún)提議區(qū)域。
3.1.3 Transformer自注意力機(jī)制
Transformer 注意力機(jī)制在自然語(yǔ)言處理已經(jīng)取得了巨大成功[47]。DETR 成功地將其應(yīng)用到目標(biāo)檢測(cè)領(lǐng)域,將檢測(cè)問(wèn)題看作集合預(yù)測(cè)問(wèn)題。其中的核心內(nèi)容是多頭注意力機(jī)制,其將模型分為多個(gè)頭,形成多個(gè)特征子空間,可以讓模型關(guān)注圖像不同方面的信息,通過(guò)圖像的內(nèi)在關(guān)系來(lái)獲取圖像中重要的信息,如圖8 所示。
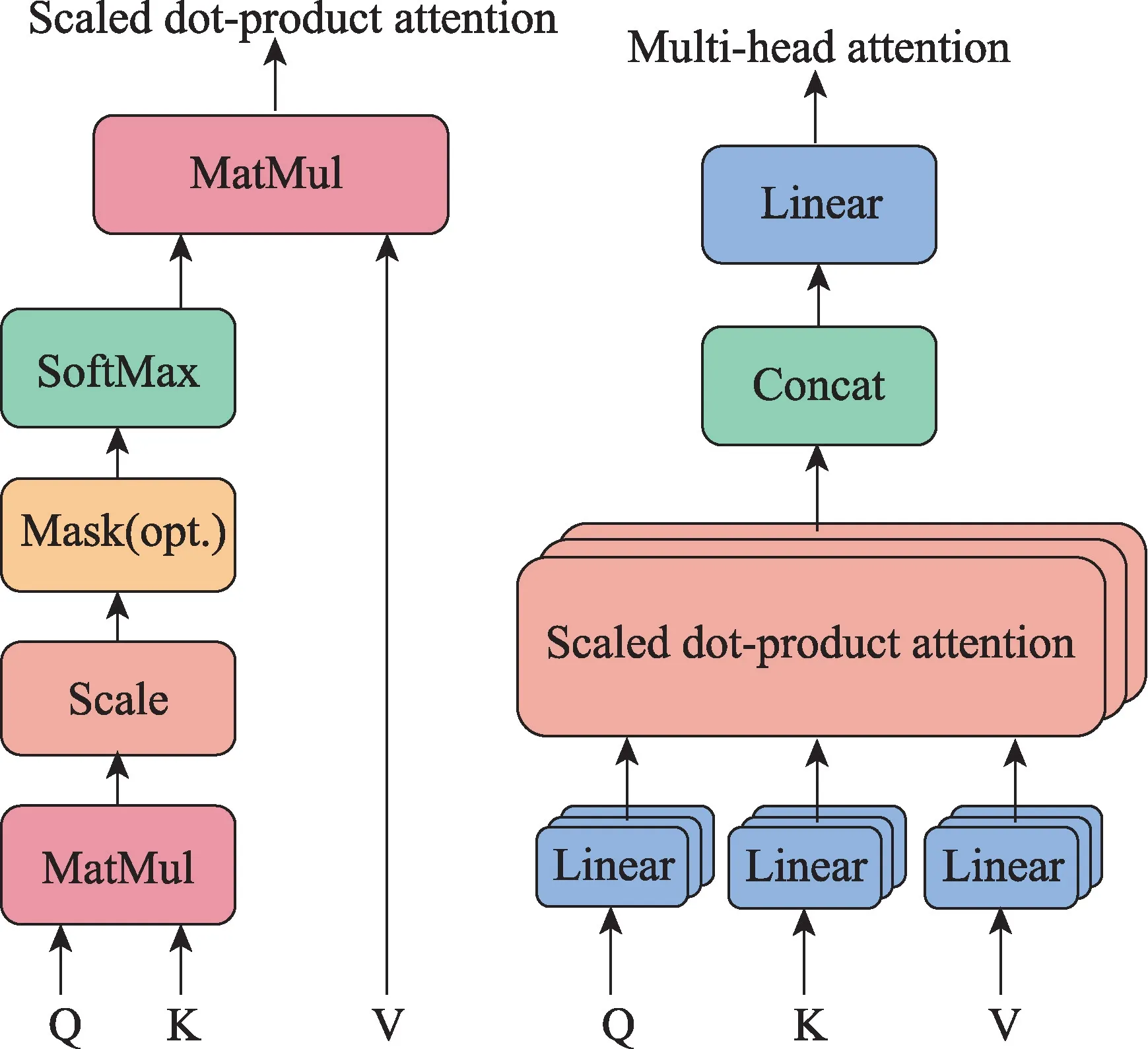
圖8 多頭注意力模塊Fig.8 Multi-head attention block
Transformer自注意力機(jī)制全部遵從元學(xué)習(xí)的范式,Zhang 等[48]借鑒DETR 的思想,提出了Meta-DETR 方法,去除了在小樣本中表現(xiàn)不佳的候選框預(yù)測(cè),改為直接的端到端檢測(cè)。Meta-DETR 由查詢(xún)編碼分支、支持編碼分支和解碼分支三部分組成。查詢(xún)編碼分支以查詢(xún)圖像為輸入,通過(guò)特征提取器和Transformer編碼器生成其查詢(xún)特征,支持編碼分支從支持圖像中提取支持類(lèi)原型,解碼分支將帶有支持類(lèi)原型的查詢(xún)特征聚合為特定類(lèi)的特征,然后應(yīng)用與類(lèi)別無(wú)關(guān)的Transformer 解碼器預(yù)測(cè)該支持類(lèi)的檢測(cè)結(jié)果。Hu 等[49]提出了DCNet 方法,提出稠密關(guān)系蒸餾解決外觀改變和遮擋問(wèn)題,稠密關(guān)系蒸餾模塊通過(guò)編碼器將支持集和查詢(xún)集提取出的特征信息編碼成原生Transformer 中的Key-Value 特征圖對(duì),使用改進(jìn)的Transformer 注意力機(jī)制關(guān)注查詢(xún)集和支持集之間的像素級(jí)關(guān)系,用以增強(qiáng)查詢(xún)集的特征表示。APSPNet(attending to per-sample-prototype networks)[50]在經(jīng)典的元學(xué)習(xí)方法Attention-RPN 和FsDetView(few-shot object detection and viewpoint estimation)基礎(chǔ)上,新增了兩個(gè)使用Transformer技術(shù)的注意力模塊,一個(gè)是支持集數(shù)據(jù)內(nèi)部注意(intra-support attention module,ISAM),另一個(gè)是查詢(xún)-支持集間注意(query-support attention module,QSAM),ISAM 在同一個(gè)類(lèi)的支持集內(nèi)使用注意力機(jī)制,去除可能是噪聲的信息,QSAM 通過(guò)支持集的每個(gè)樣本原型聚合查詢(xún)特征和支持特征,達(dá)到了遠(yuǎn)超基線(xiàn)方法的性能。Han 等[51]認(rèn)為之前在查詢(xún)和支持分支上進(jìn)行特征對(duì)齊的方法過(guò)于簡(jiǎn)單,提出了FCT(fully cross-transformer)方法,在特征提取器部分使用了多層Cross-Transformer 進(jìn)行兩分支的特征對(duì)齊,并提出了非對(duì)稱(chēng)分批交叉注意用來(lái)聚合兩分支的關(guān)鍵信息,用聚合到的關(guān)鍵信息對(duì)兩分支特征進(jìn)行增強(qiáng)。在檢測(cè)頭上,提出基于Cross-Transformer 的感興趣區(qū)特征提取器,兩分支聯(lián)合提取查詢(xún)建議框和支持圖像感興趣區(qū),進(jìn)行多級(jí)交互處理。
綜上所述,基于注意力機(jī)制的方法在小樣本目標(biāo)檢測(cè)中應(yīng)用廣泛,注意力機(jī)制可以找到圖像中的感興趣區(qū)域,抑制其他的無(wú)用噪聲信息。最近隨著Transformer 自注意力的提出,其在小樣本目標(biāo)檢測(cè)中取得了遠(yuǎn)超其他注意力的性能表現(xiàn),目前已有關(guān)于這方面的研究[52],基于Transformer 自注意力機(jī)制的小樣本目標(biāo)檢測(cè)有著極大的前景,將會(huì)得到進(jìn)一步的發(fā)展。但是,Transformer 的模型訓(xùn)練需要花費(fèi)較長(zhǎng)的時(shí)間,且模型參數(shù)過(guò)大,不利于工程部署,未來(lái)的研究方向可以向著輕量化發(fā)展。
3.2 基于圖卷積神經(jīng)網(wǎng)絡(luò)
小樣本條件下的新類(lèi)樣本數(shù)量少,可以通過(guò)深入挖掘不同類(lèi)別之間的內(nèi)在關(guān)系來(lái)實(shí)現(xiàn)對(duì)新類(lèi)的檢測(cè),卷積神經(jīng)網(wǎng)絡(luò)存在平移不變性,即一張圖像可以共享卷積算子的參數(shù),圖結(jié)構(gòu)則沒(méi)有這種平移不變性,每一個(gè)圖節(jié)點(diǎn)的周?chē)Y(jié)構(gòu)都可能是不同的,因此,圖可以處理實(shí)體之間的復(fù)雜關(guān)系。圖由節(jié)點(diǎn)和邊組成,每個(gè)節(jié)點(diǎn)都有自己的特征,節(jié)點(diǎn)與節(jié)點(diǎn)之間通過(guò)邊進(jìn)行關(guān)聯(lián),圖卷積就是利用節(jié)點(diǎn)間的邊關(guān)系對(duì)節(jié)點(diǎn)信息進(jìn)行推理更新,從而增強(qiáng)節(jié)點(diǎn)的特征表示。
Kim 等[53]認(rèn)為圖像中各種物體的存在有所關(guān)聯(lián),比如一張圖像中某個(gè)對(duì)象周?chē)墟I盤(pán)和顯示器,那它更可能是鼠標(biāo)而不是球,基于此提出了基于遷移學(xué)習(xí)范式的FSOD-SR(spatial reasoning for few-shot object detection)方法,通過(guò)圖卷積技術(shù)考慮圖像中對(duì)象間的全局上下文關(guān)系,而不僅是通過(guò)單個(gè)感興趣區(qū)域特征預(yù)測(cè)新類(lèi),將感興趣區(qū)域特征作為圖節(jié)點(diǎn),邊的構(gòu)成由感興趣區(qū)域特征表示的視覺(jué)信息和幾何坐標(biāo)信息兩者結(jié)合得到,如圖9 所示。Zhu 等[54]提出SRR-FSD(semantic relation reasoning for few-shot object detection)方法,利用基類(lèi)與新類(lèi)之間存在的恒定語(yǔ)義關(guān)系,由所有的詞嵌入特征組成嵌入語(yǔ)義空間,應(yīng)用圖卷積進(jìn)行顯式關(guān)系推理,將從大量文本中學(xué)習(xí)到的語(yǔ)義信息嵌入到每個(gè)類(lèi)概念中,并與分類(lèi)的視覺(jué)特征進(jìn)行結(jié)合。
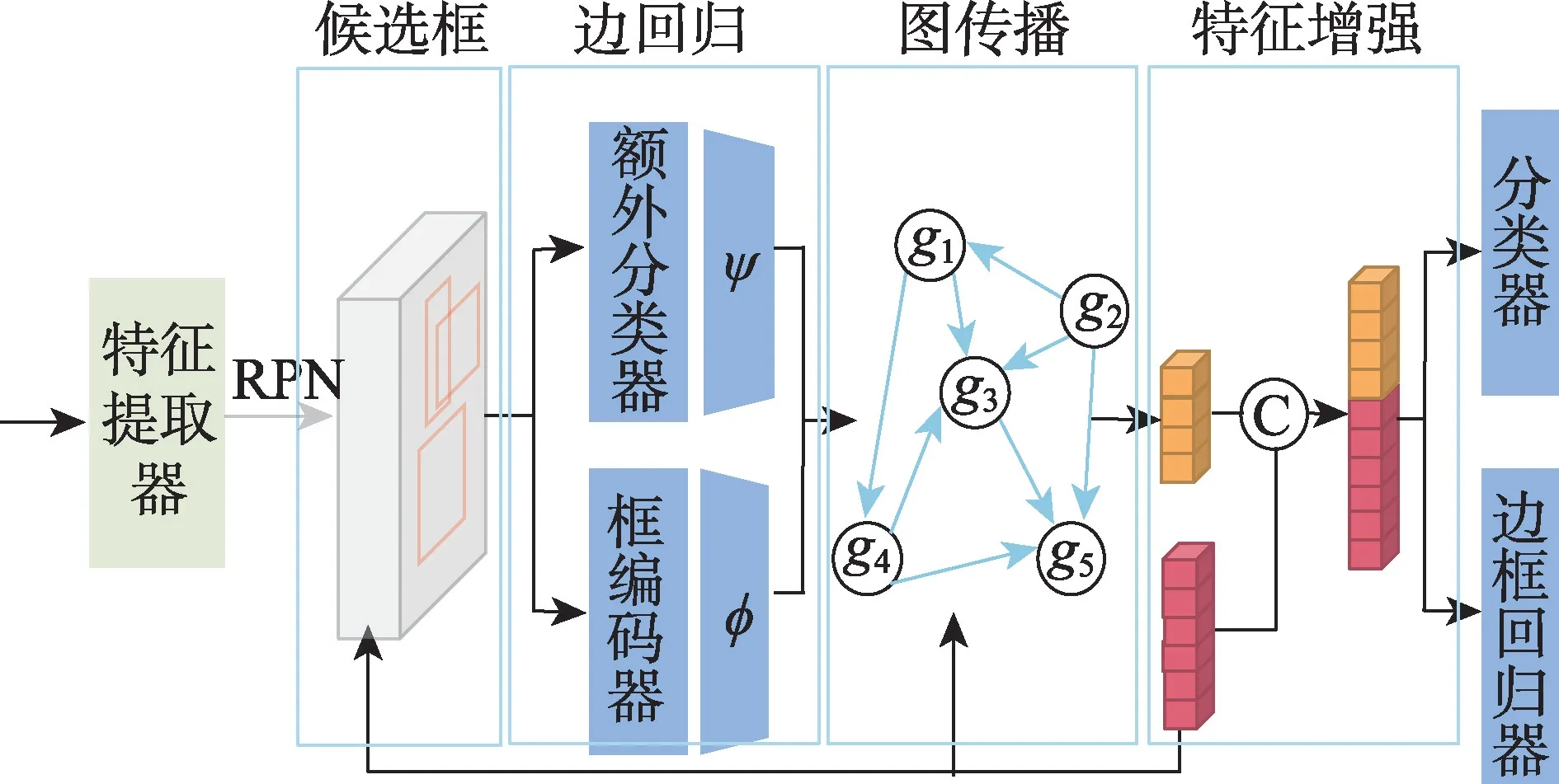
圖9 FSOD-SR 架構(gòu)圖Fig.9 FSOD-SR architecture diagram
在元學(xué)習(xí)范式上,Kim等[55]提出了FSOD-KT(fewshot object detection via knowledge transfer)方法,其支持集分支使用圖卷積技術(shù)對(duì)查詢(xún)圖像感興趣區(qū)的特征向量進(jìn)行特征增強(qiáng)。圖的頂點(diǎn)為每個(gè)類(lèi)的原型,圖的邊關(guān)系使用類(lèi)別之間的文本相似性度量(由GloVe[56]計(jì)算),通過(guò)圖卷積神經(jīng)網(wǎng)絡(luò)使這些類(lèi)原型間產(chǎn)生關(guān)聯(lián),然后通過(guò)增強(qiáng)后的原型對(duì)查詢(xún)圖像的感興趣區(qū)域特征進(jìn)行度量,檢測(cè)出與該原型一致的類(lèi)別。Liu等[57]提出了基于Meta R-CNN的DRL-for-FSOD(dynamic relevance learning for few-shot object detection)方法,考慮到不同類(lèi)之間存在著聯(lián)系,將支持集圖像和查詢(xún)集的感興趣區(qū)域特征放入同一個(gè)特征空間,使用皮爾遜相關(guān)系數(shù)去度量支持集類(lèi)別和查詢(xún)集感興趣區(qū)域間的相似性作為圖的關(guān)系,構(gòu)造了一個(gè)動(dòng)態(tài)圖卷積網(wǎng)絡(luò),對(duì)其進(jìn)行推理,使得相同類(lèi)彼此靠近,不同類(lèi)之間遠(yuǎn)離,減少了誤分類(lèi)的情況。Han等[58]基于異構(gòu)圖卷積網(wǎng)絡(luò)提出了QA-FewDet(query adaptive few-shot object detection)方法,存在類(lèi)間和類(lèi)內(nèi)兩種子圖,前者推理新類(lèi)和基類(lèi)的類(lèi)間的關(guān)系,后者推理不同新類(lèi)的候選框之間的關(guān)系以及新類(lèi)節(jié)點(diǎn)與候選框之間的關(guān)系。使用類(lèi)間子圖增強(qiáng)新類(lèi)原型表示,類(lèi)內(nèi)子圖提供查詢(xún)自適應(yīng)類(lèi)原型和上下文感知原型特征。
綜上所述,基于圖卷積神經(jīng)網(wǎng)絡(luò)的小樣本目標(biāo)檢測(cè)方法大多選擇將候選框作為圖的節(jié)點(diǎn),通過(guò)圖卷積來(lái)自動(dòng)推理不同候選框之間的關(guān)系,以此學(xué)習(xí)到新類(lèi)同基類(lèi)間的內(nèi)在聯(lián)系,達(dá)到對(duì)新類(lèi)對(duì)象的檢測(cè)。但是當(dāng)圖節(jié)點(diǎn)過(guò)多時(shí),節(jié)點(diǎn)之間的邊關(guān)系也會(huì)變得異常復(fù)雜,可能會(huì)面臨模型過(guò)擬合的問(wèn)題。同時(shí),新類(lèi)的樣本量較少也可能導(dǎo)致模型在新類(lèi)檢測(cè)上產(chǎn)生過(guò)擬合現(xiàn)象。
3.3 基于度量學(xué)習(xí)
通過(guò)度量基類(lèi)和小樣本的新類(lèi)之間的相似性,使得不同類(lèi)別彼此遠(yuǎn)離,相同類(lèi)別之間靠近,可以很好地區(qū)分出新類(lèi)數(shù)據(jù)。度量學(xué)習(xí)又可分為改進(jìn)度量損失函數(shù)、原型學(xué)習(xí)和對(duì)比學(xué)習(xí)。度量損失函數(shù)在不同類(lèi)別之間設(shè)計(jì)距離公式;原型學(xué)習(xí)為每個(gè)類(lèi)別生成線(xiàn)性分類(lèi)器,衡量類(lèi)別與原型之間的距離;對(duì)比學(xué)習(xí)是將目標(biāo)圖像與某幾個(gè)圖像對(duì)比進(jìn)行檢測(cè)。
3.3.1 改進(jìn)度量損失函數(shù)
在遷移學(xué)習(xí)范式上,Cao 等[59]提出了FADI(fewshot object detection via association and discrimination)方法,將遷移學(xué)習(xí)的微調(diào)階段分為關(guān)聯(lián)、鑒別兩步,關(guān)聯(lián)加強(qiáng)類(lèi)內(nèi)相關(guān)性,鑒別擴(kuò)大類(lèi)間差異。在關(guān)聯(lián)中,使用偽標(biāo)簽顯式地將新類(lèi)轉(zhuǎn)變?yōu)樽钕嗨频幕?lèi)特征表示,新類(lèi)的特征會(huì)相對(duì)聚集,但可能會(huì)與基類(lèi)特征空間混淆,為了擴(kuò)大不同類(lèi)間的距離,在分類(lèi)分支引入了專(zhuān)門(mén)的邊際損失,擴(kuò)大了所有類(lèi)別的差異性。Wu 等[60]提出了SVD(singular value decomposition)的方法,新引入了對(duì)象注意損失和背景注意損失兩個(gè)損失函數(shù),用于更好地分類(lèi)正負(fù)錨框,將屬于同一類(lèi)的正錨框聚集起來(lái),將背景和負(fù)錨框兩者盡可能地區(qū)分開(kāi)。
在元學(xué)習(xí)范式上,Karlinsky 等[61]在RepMet(representative-based metric learning)方法中提出一個(gè)距離度量學(xué)習(xí)(distance metric learning,DML)模塊,代替了Faster R-CNN 中的檢測(cè)頭,假定特征嵌入空間中每個(gè)類(lèi)有K個(gè)模型,DML 計(jì)算感興趣區(qū)域在每個(gè)類(lèi)別中每個(gè)模型的概率,新增加了嵌入損失函數(shù),減小嵌入向量E和最接近表征的距離,擴(kuò)大嵌入向量E和一個(gè)錯(cuò)誤類(lèi)的最接近表征的距離。Li 等[62]為了減輕新類(lèi)的特征表示和分類(lèi)之間存在的矛盾,提出了CME(class margin equilibrium)方法。為了準(zhǔn)確實(shí)現(xiàn)新類(lèi)的類(lèi)別分類(lèi),任意兩個(gè)基類(lèi)應(yīng)該彼此遠(yuǎn)離,為了準(zhǔn)確表示新類(lèi)特征,基類(lèi)的分布應(yīng)該彼此接近。CME 首先通過(guò)解耦定位分支將檢測(cè)轉(zhuǎn)換為分類(lèi)問(wèn)題,在特征學(xué)習(xí)過(guò)程中,通過(guò)類(lèi)邊際損失為新類(lèi)保留充足的邊界距離,在追求類(lèi)邊界平衡中保證新類(lèi)的檢測(cè)性能。Zhang 等[63]提出了PNPDet(plug-and-play detector)方法,將基類(lèi)和新類(lèi)檢測(cè)分開(kāi),防止在學(xué)習(xí)新概念的時(shí)候影響基類(lèi)的檢測(cè)性能,以CenterNet[64]為基礎(chǔ)架構(gòu),新增了一個(gè)用于新類(lèi)別檢測(cè)的熱圖預(yù)測(cè)并行分支,將最后一層熱圖子網(wǎng)絡(luò)替換為余弦相似對(duì)比頭和自適應(yīng)余弦相似對(duì)比頭,將距離度量學(xué)習(xí)的損失函數(shù)引入類(lèi)別預(yù)測(cè)中,極大提升了新類(lèi)的檢測(cè)性能。彭豪等[45]在隱藏層的特征空間上應(yīng)用正交損失函數(shù),使得模型在分類(lèi)過(guò)程中保持不同類(lèi)別彼此分離,相同類(lèi)別彼此聚合。
3.3.2 對(duì)比學(xué)習(xí)
對(duì)比學(xué)習(xí)是將目標(biāo)圖像與某幾個(gè)圖像進(jìn)行對(duì)比檢測(cè),在最小化類(lèi)內(nèi)距離的同時(shí)最大化類(lèi)間距離,提高相同或相似類(lèi)之間的緊湊性和加大不同類(lèi)之間的差異性,可以有效提高邊界框的分類(lèi)精度。
在遷移學(xué)習(xí)范式上,Sun 等[65]在原有分類(lèi)和定位分支外,新增加一個(gè)對(duì)比分支,通過(guò)對(duì)比候選框編碼損失函數(shù),利用余弦相似性函數(shù)度量感興趣區(qū)域特征和特定類(lèi)權(quán)重的語(yǔ)義相似性。
在元學(xué)習(xí)范式上,F(xiàn)an 等[29]在Attention-RPN 方法中采用了三元組對(duì)比訓(xùn)練策略,即一張支持集圖像與查詢(xún)集相同類(lèi)別的一個(gè)正例和不同類(lèi)別的一個(gè)負(fù)例組成一個(gè)三元組。Quan 等[44]在分類(lèi)對(duì)比學(xué)習(xí)InfoNCE[66]的啟發(fā)下,將無(wú)監(jiān)督的對(duì)比學(xué)習(xí)轉(zhuǎn)換為有監(jiān)督的對(duì)比學(xué)習(xí),對(duì)支持和查詢(xún)兩分支的最終特征施加對(duì)比學(xué)習(xí)策略。
3.3.3 原型學(xué)習(xí)

基于遷移學(xué)習(xí)范式,Qiao 等[67]提出了一個(gè)解耦的Faster R-CNN 方法DeFRCN(decoupled faster R-CNN),通過(guò)在分類(lèi)分支中使用原型校準(zhǔn)模塊解決多任務(wù)的耦合。使用一個(gè)離線(xiàn)的原型與感興趣區(qū)特征計(jì)算相似度,然后用得到的相似度微調(diào)模型進(jìn)行類(lèi)別預(yù)測(cè),可以分類(lèi)出與原型相似的感興趣區(qū)域特征。Wu 等[33]提出了通用原型的方法FSOD-UP,通用原型是在所有的對(duì)象類(lèi)別中學(xué)習(xí)的,而不是某一個(gè)特定類(lèi)。不同類(lèi)別間存在著內(nèi)在不變的特征,可以利用這點(diǎn)來(lái)增強(qiáng)新類(lèi)對(duì)象特征。
基于元學(xué)習(xí)范式,Li等[68]提出了基于元學(xué)習(xí)和度量學(xué)習(xí)的MM-FSOD(meta and metric integrated fewshot object detection)方法,將元學(xué)習(xí)訓(xùn)練方法從分類(lèi)轉(zhuǎn)移到特征重構(gòu)。新的元表示方法對(duì)類(lèi)內(nèi)平均原型進(jìn)行分類(lèi),區(qū)分不同類(lèi)別的聚類(lèi)中心,然后重建低級(jí)特征。Han 等[43]針對(duì)候選框生成提出了Meta Faster R-CNN 方法,采用基于輕量化度量學(xué)習(xí)的原型匹配網(wǎng)絡(luò)。Meta Faster R-CNN 中Meta-RPN 是一個(gè)錨框級(jí)輕量化粗粒度原型匹配網(wǎng)絡(luò),Meta-Classifier 是一個(gè)像素級(jí)細(xì)粒度原型匹配網(wǎng)絡(luò),整個(gè)檢測(cè)網(wǎng)絡(luò)是從粗粒度到細(xì)粒度優(yōu)化的過(guò)程,用來(lái)產(chǎn)生特定新類(lèi)的候選框。考慮到FSRW[28]方法只是簡(jiǎn)單地平均支持樣本信息生成每個(gè)類(lèi)別的原型,這樣的做法泛化性較差,APSPNet[50]將每個(gè)支持樣本看作一個(gè)原型,稱(chēng)之為逐樣本原型,這樣可以更好地將不同的支持信息與查詢(xún)圖像結(jié)合。
綜上所述,度量學(xué)習(xí)主要通過(guò)令相同類(lèi)別之間彼此靠近、不同類(lèi)別之間彼此遠(yuǎn)離來(lái)完成。其思路簡(jiǎn)單好用,被大量應(yīng)用到小樣本目標(biāo)檢測(cè)中,但度量學(xué)習(xí)過(guò)于依賴(lài)于采樣的策略,如果采集的樣本過(guò)于復(fù)雜,可能會(huì)發(fā)生不收斂、過(guò)擬合的問(wèn)題;如果采集的樣本過(guò)于簡(jiǎn)單,又可能不會(huì)學(xué)習(xí)對(duì)類(lèi)別檢測(cè)有用的信息。
3.4 基于數(shù)據(jù)增強(qiáng)
小樣本的核心問(wèn)題是其數(shù)據(jù)量少,最簡(jiǎn)單直接的想法就是擴(kuò)充數(shù)據(jù)樣本。郭永坤等[69]就圖像在空頻域上的圖像增強(qiáng)方法作了研究綜述,數(shù)據(jù)增強(qiáng)技術(shù)可以通過(guò)直接增加訓(xùn)練的圖像數(shù)量或者間接對(duì)特征進(jìn)行增強(qiáng),使得網(wǎng)絡(luò)的輸入信息增加,從而最大程度地增加模型能夠處理的圖像信息,減少模型的過(guò)擬合。
3.4.1 多特征融合
在遷移學(xué)習(xí)范式上,Zhang 等[32]提出了PNSD 方法,使用多特征融合得到細(xì)節(jié)更豐富的特征圖,多特征融合采用雙線(xiàn)性插值上采樣和1×1 卷積下采樣將所有特征映射到相同的尺度,將尺度信息顯式混合到特征圖中。另外,通過(guò)注意力候選區(qū)網(wǎng)絡(luò)生成候選框,經(jīng)過(guò)相似網(wǎng)絡(luò)的全局、局部和塊狀關(guān)系頭三種關(guān)系進(jìn)行分類(lèi)和定位。Vu 等[70]對(duì)通過(guò)主干網(wǎng)絡(luò)得到的特征圖使用了多感受野的嬰兒學(xué)習(xí),使用多感受野可以得到該對(duì)象的更多空間信息,通過(guò)微調(diào)多感受野模塊有效地將先驗(yàn)空間知識(shí)轉(zhuǎn)移到新域。
基于元學(xué)習(xí)范式,Xiao 等[71]提出FsDetView 方法,將查詢(xún)圖像的候選框和支持集特征進(jìn)行三種方式特征融合,三種融合方式分別是通道連接、簡(jiǎn)單相減和查詢(xún)特征自身,這樣可以更好地利用特征之間的內(nèi)在關(guān)系。Fan 等[29]在提出的Attention-RPN 方法中使用了多關(guān)系檢測(cè)器,通過(guò)支持集的候選框和查詢(xún)集感興趣區(qū)域特征進(jìn)行全局、局部和塊狀的關(guān)系結(jié)合,避免了背景中的錯(cuò)檢。Hu 等[49]認(rèn)為當(dāng)對(duì)象發(fā)生遮擋時(shí),局部的細(xì)節(jié)信息往往起絕對(duì)性作用,提出了DCNet 方法,在感興趣區(qū)域上使用三種不同的池化層捕捉上下文信息要遠(yuǎn)好于單一池化的效果。彭豪等[45]對(duì)感興趣區(qū)域分別施加最大池化和平均池化技術(shù),進(jìn)行多種特征融合,可以提升模型對(duì)新類(lèi)參數(shù)的敏感度。
3.4.2 增加樣本數(shù)量的方法
在遷移學(xué)習(xí)范式上,Wu 等[72]為解決小樣本中的尺度問(wèn)題,提出了MPSR(multi-scale positive sample refinement)方法,將對(duì)象金字塔作為一個(gè)輔助分支加入到主體的Faster R-CNN 和特征金字塔網(wǎng)絡(luò)(feature pyramid networks,F(xiàn)PN),手動(dòng)地將處理過(guò)的不同尺度對(duì)象方形框與FPN 的不同級(jí)別進(jìn)行對(duì)應(yīng),使模型捕捉到不同尺度的對(duì)象。為解決訓(xùn)練數(shù)據(jù)變化的缺乏,Zhang 等[73]在感興趣區(qū)域特征空間上通過(guò)幻覺(jué)網(wǎng)絡(luò)(hallucination)產(chǎn)生額外的訓(xùn)練樣本,將從基類(lèi)中學(xué)習(xí)到的類(lèi)內(nèi)樣本變化轉(zhuǎn)移到新類(lèi)上。Kim 等[53]為了不破壞圖像中的空間關(guān)系,選擇在圖像中隨機(jī)調(diào)整每個(gè)對(duì)象的尺寸若干次,這樣既增加了感興趣區(qū)域的數(shù)量,又適應(yīng)了不同大小的對(duì)象尺度。Sun等[65]認(rèn)為具有不同交并比(intersection over union,IoU)分?jǐn)?shù)的候選框類(lèi)似于類(lèi)內(nèi)數(shù)據(jù)增強(qiáng),在TFA 的基礎(chǔ)上提出了更優(yōu)的FSCE(few-shot object detection via contrastive proposals encoding)方法,即在微調(diào)階段,將NMS(non maximum suppression)處理后的候選框的最大數(shù)量翻倍和將感興趣區(qū)域特征中用于損失計(jì)算的候選框數(shù)量減半。Xu 等[40]認(rèn)為圖像金字塔技術(shù)在增加正樣本數(shù)量的同時(shí)也引入了大量的負(fù)樣本,沒(méi)有充分發(fā)揮正樣本數(shù)量增強(qiáng)的優(yōu)勢(shì),提出了正樣本增強(qiáng)技術(shù),包括背景稀疏化、多尺度復(fù)制和隨機(jī)裁剪技術(shù),通過(guò)去除一些負(fù)樣本實(shí)例,大大減少了負(fù)樣本的占比。Kaul 等[74]提出了Pseudo-Labelling 方法,采用偽標(biāo)記的方法增加新類(lèi)別的樣本數(shù)量,首先在訓(xùn)練集上產(chǎn)生新類(lèi)的偽標(biāo)記,通過(guò)自監(jiān)督訓(xùn)練的驗(yàn)證刪除標(biāo)簽不正確的大量邊界框,之后由類(lèi)似Cascade R-CNN[75]的逐步優(yōu)化方法糾正質(zhì)量差的邊界框,大大減少類(lèi)別不平衡性。Guirguis 等[76]利用連續(xù)學(xué)習(xí)中的重放方法存儲(chǔ)以前的任務(wù)中的基類(lèi)樣本,以便在學(xué)習(xí)新任務(wù)時(shí)進(jìn)行重放,實(shí)現(xiàn)基類(lèi)和新類(lèi)之間的知識(shí)轉(zhuǎn)移。提出了一個(gè)新的梯度更新規(guī)則,將基類(lèi)的梯度添加到新類(lèi)梯度更新中,它還會(huì)自適應(yīng)地重新加權(quán)它們,以防新梯度指向可能導(dǎo)致遺忘的方向。作為一個(gè)即插即用的模塊,可以很方便地與任意FSOD模型結(jié)合。多尺度正樣本特征提取如圖10所示。
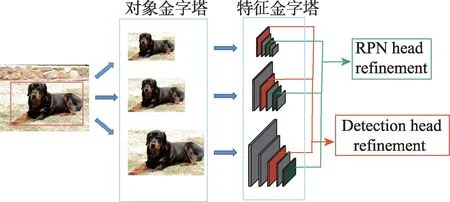
圖10 多尺度正樣本特征提取Fig.10 Multi-scale positive sample feature extraction
在元學(xué)習(xí)范式上,Yang 等[77]以RepMet 為基礎(chǔ),提出了NP-RepMet 方法,將其他方法丟棄的負(fù)樣本納入模型訓(xùn)練中,可以得到更加魯棒的嵌入空間。Li等[22]除了使用簡(jiǎn)單的數(shù)據(jù)增強(qiáng)技術(shù)外,還將變換不變性(transformation invariant principle,TIP)引入到小樣本檢測(cè)中。具體地,在查詢(xún)分支上,用從查詢(xún)變換圖像中得到的候選框檢測(cè)原始查詢(xún)圖像對(duì)象邊界框,在支持分支上,在原始支持圖像和支持變換圖像間施加一致性損失,最后對(duì)兩分支結(jié)果做聚合處理。Zhang 等[78]認(rèn)為不應(yīng)該對(duì)支持樣本只進(jìn)行簡(jiǎn)單的平均操作,提出了SQMG(support-query mutual guidance)方法。在基訓(xùn)練階段,支持引導(dǎo)的查詢(xún)?cè)鰪?qiáng)通過(guò)核生成器對(duì)查詢(xún)特征進(jìn)行增強(qiáng),通過(guò)支持查詢(xún)相互引導(dǎo)模塊生成更多與支持相關(guān)的候選框。另外,候選框和聚合支持特征之間進(jìn)行多種特征比較,得到更高質(zhì)量的候選框。
3.4.3 增加候選框數(shù)量的方法
基于遷移學(xué)習(xí)范式,Zhang 等[79]提出了同時(shí)使用多個(gè)區(qū)域候選網(wǎng)絡(luò)結(jié)構(gòu)的CoRPNs 方法,用以解決因?yàn)闃颖旧俣a(chǎn)生較少的候選框的問(wèn)題,如果某一個(gè)區(qū)域候選網(wǎng)絡(luò)遺漏了具有高IoU 值的候選框,那么其他的區(qū)域候選網(wǎng)絡(luò)能夠檢出該候選框。在模型訓(xùn)練時(shí),只有最確定的那個(gè)區(qū)域候選網(wǎng)絡(luò)模塊才能獲得梯度,在測(cè)試時(shí),也只從最確定的那個(gè)區(qū)域候選網(wǎng)絡(luò)中獲取候選框。
為了解決模型不遺忘的問(wèn)題,F(xiàn)an 等[80]提出了基于元學(xué)習(xí)范式的Retentive R-CNN 模型,新增了Bias-Balanced RPN 和Re-Detector 模塊。區(qū)域候選網(wǎng)絡(luò)不是完全的類(lèi)無(wú)關(guān)的,而更偏向于可見(jiàn)類(lèi)別的檢測(cè),因此,基類(lèi)檢測(cè)器不能很好檢測(cè)出新類(lèi),產(chǎn)生了很多誤報(bào)。在Bias-Balanced RPN 中引入了新的分支,同時(shí)檢測(cè)新類(lèi)和基類(lèi)對(duì)象,原有的檢測(cè)頭只用來(lái)檢測(cè)基類(lèi)。在Re-Detector 中,原有分支只檢測(cè)基類(lèi),新分支同時(shí)檢測(cè)基類(lèi)和新類(lèi),在兩個(gè)分支基類(lèi)檢測(cè)上施加一致性損失可以更好地完成檢測(cè)。
綜上所述,可以直接或間接的多種方式完成對(duì)新類(lèi)別數(shù)據(jù)樣本的擴(kuò)充,增加新類(lèi)別樣本數(shù)據(jù)的方法是最直接有效的解決類(lèi)別樣本數(shù)量不足的方法,同時(shí)也能帶來(lái)更加豐富的樣本特征,減少模型過(guò)擬合的產(chǎn)生,但如果使用了過(guò)多的數(shù)據(jù)增強(qiáng)策略,可能會(huì)在增加樣本信息的同時(shí),引入一些無(wú)關(guān)的噪聲信息。
4 算法數(shù)據(jù)集、評(píng)估指標(biāo)和性能分析
小樣本目標(biāo)檢測(cè)方法中常用的公開(kāi)數(shù)據(jù)集有Pascal VOC[25]、MS-COCO[26]和FSOD[29]數(shù)據(jù)集,在個(gè)別方法中使用到的其他數(shù)據(jù)集有LVIS[27]、iNatureList[81]、ImageNet-Loc[82]等。數(shù)據(jù)集的概況如表1 所示。

表1 小樣本目標(biāo)檢測(cè)常用數(shù)據(jù)集及其劃分方式Table 1 Typical datasets for few-shot object detection and their divisions
4.1 小樣本目標(biāo)檢測(cè)公開(kāi)數(shù)據(jù)集介紹
4.1.1 Pascal VOC 數(shù)據(jù)集
小樣本目標(biāo)檢測(cè)實(shí)驗(yàn)使用的Pascal VOC 數(shù)據(jù)集由Pascal VOC2007[25]和Pascal VOC2012[83]共同組成,整個(gè)VOC 數(shù)據(jù)集一共有21 503 張圖像,其中,VOC07有9 963 張圖像,VOC12 有11 540 張圖像。VOC07 和VOC12 的train 和val 集合數(shù)據(jù)用模型訓(xùn)練,VOC07的test 集合數(shù)據(jù)用于模型測(cè)試。VOC 數(shù)據(jù)集一共有20 個(gè)類(lèi)別,隨機(jī)選擇其中的5 類(lèi)作為新類(lèi),剩余的15類(lèi)作為基類(lèi),為了盡量減少由隨機(jī)性帶來(lái)的影響,分成多組不同的數(shù)據(jù)進(jìn)行訓(xùn)練,常見(jiàn)的做法是分為3 組進(jìn)行,即分組1、分組2 和分組3,每個(gè)分組中新類(lèi)的類(lèi)別均不同,關(guān)于3 組劃分的具體細(xì)節(jié)如下:分組1的新類(lèi)類(lèi)別為鳥(niǎo)類(lèi)、公交車(chē)、牛、摩托車(chē)和沙發(fā);分組2 的新類(lèi)類(lèi)別為飛機(jī)、瓶子、牛、馬和沙發(fā);分組3 的新類(lèi)類(lèi)別為船、貓、自行車(chē)、羊和沙發(fā)。分組中每個(gè)新類(lèi)的對(duì)象都應(yīng)當(dāng)有K個(gè)標(biāo)注邊界框,VOC 數(shù)據(jù)集中K的取值常為1、2、3、5、10。由于新類(lèi)的樣本數(shù)量非常少,其選擇會(huì)非常影響模型的性能表現(xiàn),采用多次實(shí)驗(yàn)來(lái)消除隨機(jī)性的影響,TFA 提出通過(guò)30 次重復(fù)實(shí)驗(yàn)并取平均值得到公平的實(shí)驗(yàn)結(jié)果,之后的一些論文提出只進(jìn)行10 次實(shí)驗(yàn)也可以公平比較實(shí)驗(yàn)結(jié)果。
4.1.2 Microsoft COCO 數(shù)據(jù)集
COCO2014[26]數(shù)據(jù)集相比VOC 數(shù)據(jù)集有更多的類(lèi)別和更多的圖像,包含123 287 張圖像,其中,訓(xùn)練集有82 783張圖像,驗(yàn)證集有40 504張圖像。從COCO數(shù)據(jù)集的train 和val 集合中選取5 000 張圖像用作測(cè)試數(shù)據(jù)集,其余的圖像用于訓(xùn)練階段。選取COCO數(shù)據(jù)集中與VOC 重疊的20 個(gè)類(lèi)別作為新類(lèi),剩余的60 類(lèi)作為基類(lèi)數(shù)據(jù),同時(shí)K的取值通常為10、30,即一個(gè)類(lèi)別選擇10 個(gè)或者30 個(gè)目標(biāo)樣本用來(lái)訓(xùn)練。
4.1.3 FSOD 數(shù)據(jù)集
FSOD 數(shù)據(jù)集[29]是專(zhuān)門(mén)針對(duì)小樣本目標(biāo)檢測(cè)而設(shè)計(jì)的數(shù)據(jù)集,對(duì)于小樣本目標(biāo)檢測(cè)任務(wù)來(lái)說(shuō),類(lèi)別數(shù)量越多檢測(cè)效果越好。FSOD 數(shù)據(jù)集的類(lèi)別數(shù)很多,總共有1 000 類(lèi),每個(gè)類(lèi)別的標(biāo)注數(shù)量較少,超過(guò)90%類(lèi)別的圖像數(shù)量在22~108 張之間,即使最常見(jiàn)的類(lèi)別也沒(méi)有超過(guò)208 張圖像,總的圖像數(shù)量也并不多。FSOD 數(shù)據(jù)集包含大約66 000 張圖像和182 000個(gè)邊界框,其中訓(xùn)練集800 類(lèi),測(cè)試集200 類(lèi),有531類(lèi)來(lái)自ImageNet 數(shù)據(jù)集,有469 類(lèi)來(lái)自O(shè)penImage 數(shù)據(jù)集。此外,F(xiàn)SOD 數(shù)據(jù)集還合并了有相同語(yǔ)義的類(lèi)別,移除了標(biāo)注質(zhì)量差的數(shù)據(jù)。
4.1.4 其他數(shù)據(jù)集
ImageNet-Loc數(shù)據(jù)集[82]在RepMet[61]和Meta-RCNN[35]中使用,固定地使用500 個(gè)隨機(jī)的任務(wù),每個(gè)類(lèi)別的邊界框的數(shù)量取不同的1、5 和10。
iNatureList 數(shù)據(jù)集[81]是一個(gè)長(zhǎng)尾分布的物種數(shù)據(jù)集,包含2 854 個(gè)類(lèi)別,可以檢測(cè)在所有類(lèi)上的AP指標(biāo)(具體有AP、AP50 和AP75)和AR 指標(biāo)(AR1 和AR10)。
LVIS 數(shù)據(jù)集[27]在TFA 中有被使用,其有著天然的長(zhǎng)尾分布,整個(gè)數(shù)據(jù)集的類(lèi)別分布為類(lèi)別圖像數(shù)量小于10 個(gè)的稀有類(lèi)、圖像數(shù)量為10~100 的普通類(lèi)和圖像數(shù)量大于100 的頻繁類(lèi)。將頻繁類(lèi)和普通類(lèi)看作基類(lèi),稀有類(lèi)看作新類(lèi)進(jìn)行訓(xùn)練。在模型的微調(diào)階段,手動(dòng)創(chuàng)建一個(gè)平衡的數(shù)據(jù)子集,其中每個(gè)類(lèi)別擁有10 個(gè)實(shí)例。
Zhu 等[54]提出了一個(gè)更加現(xiàn)實(shí)的FSOD 數(shù)據(jù)集基準(zhǔn),即刪除預(yù)訓(xùn)練分類(lèi)模型中有關(guān)的新類(lèi)圖像的隱式樣本(implicit shot)。在CoRPNs[79]中,也提到了移除預(yù)訓(xùn)練數(shù)據(jù)集中有關(guān)的基類(lèi)和新類(lèi)數(shù)據(jù),包含275類(lèi),超過(guò)30 萬(wàn)張圖像。Huang 等[84]指出,這樣的做法可能會(huì)使預(yù)訓(xùn)練模型得不到最優(yōu)解。因此,只刪除對(duì)應(yīng)VOC 數(shù)據(jù)集中新類(lèi)的數(shù)據(jù)即可,對(duì)于COCO 數(shù)據(jù)集,它的新類(lèi)類(lèi)別是很常見(jiàn)的,應(yīng)該按照長(zhǎng)尾分布,選取樣本量少的作為新類(lèi)。
4.2 評(píng)估指標(biāo)
通用目標(biāo)檢測(cè)方法常用的評(píng)估指標(biāo)有平均準(zhǔn)確率(average precision,AP)[85]和平均召回率(average recall,AR)。
AP 表示檢測(cè)所得正樣本數(shù)占所有檢測(cè)樣本的比例,其表達(dá)式為:

式中,TP表示被正確檢測(cè)為正例的實(shí)例數(shù),F(xiàn)P表示被錯(cuò)誤檢測(cè)為正例的實(shí)例數(shù)。AP 表示類(lèi)別的平均檢測(cè)精度,mAP(mean average precision)是平均AP值,是多個(gè)目標(biāo)類(lèi)別的檢測(cè)精度,即將每個(gè)類(lèi)別的AP值取平均得到mAP 值。
AR 表示檢測(cè)所得正樣本數(shù)占所有正樣本的比例,其表達(dá)式為:

式中,TP表示被正確檢測(cè)為正例的實(shí)例數(shù),F(xiàn)P表示被錯(cuò)誤檢測(cè)為負(fù)例的實(shí)例數(shù)。
小樣本目標(biāo)檢測(cè)的評(píng)估指標(biāo)和通用目標(biāo)檢測(cè)有一些細(xì)微的差別,VOC 數(shù)據(jù)集根據(jù)所選新類(lèi)類(lèi)別的不同分為3 組實(shí)驗(yàn),在每組中,新類(lèi)樣本數(shù)量K的取值均為1、2、3、5 和10。一般地,只需檢測(cè)新類(lèi)類(lèi)別的AP 值(novel AP,nAP)即可,一些算法也會(huì)關(guān)注模型體現(xiàn)在基類(lèi)上的不遺忘特性,測(cè)試所得模型在基類(lèi)的性能,指標(biāo)為bAP(base AP),這里所提到的AP 值都是在交并比值為0.5 的mAP 值。
在COCO 數(shù)據(jù)集中,新類(lèi)樣本數(shù)量K的取值為10 和30,模型會(huì)檢測(cè)在新類(lèi)數(shù)據(jù)集上的不同IoU 閾值、不同對(duì)象尺度的AP 值以及不同的AR 值。采用COCO 風(fēng)格的評(píng)價(jià)指標(biāo),具體指標(biāo)項(xiàng)有mAP、AP50、AP75、APs、APm 和APl。這里的mAP 指的是在10 個(gè)IoU 閾值(0.50:0.05:0.95)的指標(biāo),AP50、AP75 則是只計(jì)算單個(gè)IoU 閾值(0.50 和0.75)的指標(biāo)。APs、APm 和APl 表示在不同的標(biāo)注邊界框面積的指標(biāo),APs 是面積小于32 像素×32 像素,APm 是面積在32像素×32 像素到96 像素×96 像素之間,APl 是面積大于96 像素×96 像素。AR 有AR1、AR10 和AR100(AR1 是指每張圖片中,在給定1 個(gè)檢測(cè)結(jié)果中的指標(biāo),其他同理)。
由于隨機(jī)性的影響,以上檢測(cè)值都會(huì)通過(guò)多次實(shí)驗(yàn)取平均值當(dāng)作最后的結(jié)果。一般地,VOC 的重復(fù)實(shí)驗(yàn)次數(shù)為10 次或者30 次,COCO 數(shù)據(jù)集的重復(fù)次數(shù)為10 次。另外,F(xiàn)SOD 數(shù)據(jù)集中K的取值常為1、5,具體指標(biāo)項(xiàng)為AP50 和AP75。
跨數(shù)據(jù)集問(wèn)題:從COCO 到VOC,使用VOC 和COCO 重合的20 個(gè)類(lèi)別作為新類(lèi),使用COCO 中剩余的60 類(lèi)作為基類(lèi)數(shù)據(jù),K的取值為10,具體評(píng)估指標(biāo)項(xiàng)為mAP。
4.3 算法性能分析
表2 根據(jù)不同的改進(jìn)策略,對(duì)現(xiàn)有方法分類(lèi)的機(jī)制、優(yōu)勢(shì)、局限性和適用場(chǎng)景這四方面進(jìn)行了詳細(xì)比較。本節(jié)使用在4.2 節(jié)中提到的數(shù)據(jù)評(píng)估策略在VOC、COCO 和FSOD 數(shù)據(jù)集上對(duì)各個(gè)方法進(jìn)行性能評(píng)估,而像iNaturaList、ImageNet-LOC 等數(shù)據(jù)集由于被使用次數(shù)較少,說(shuō)服力差,不具有可比性,故不做性能對(duì)比分析,具體結(jié)果可見(jiàn)表3~表7,表中加粗為最優(yōu)性能結(jié)果,下劃線(xiàn)為次優(yōu)性能結(jié)果。
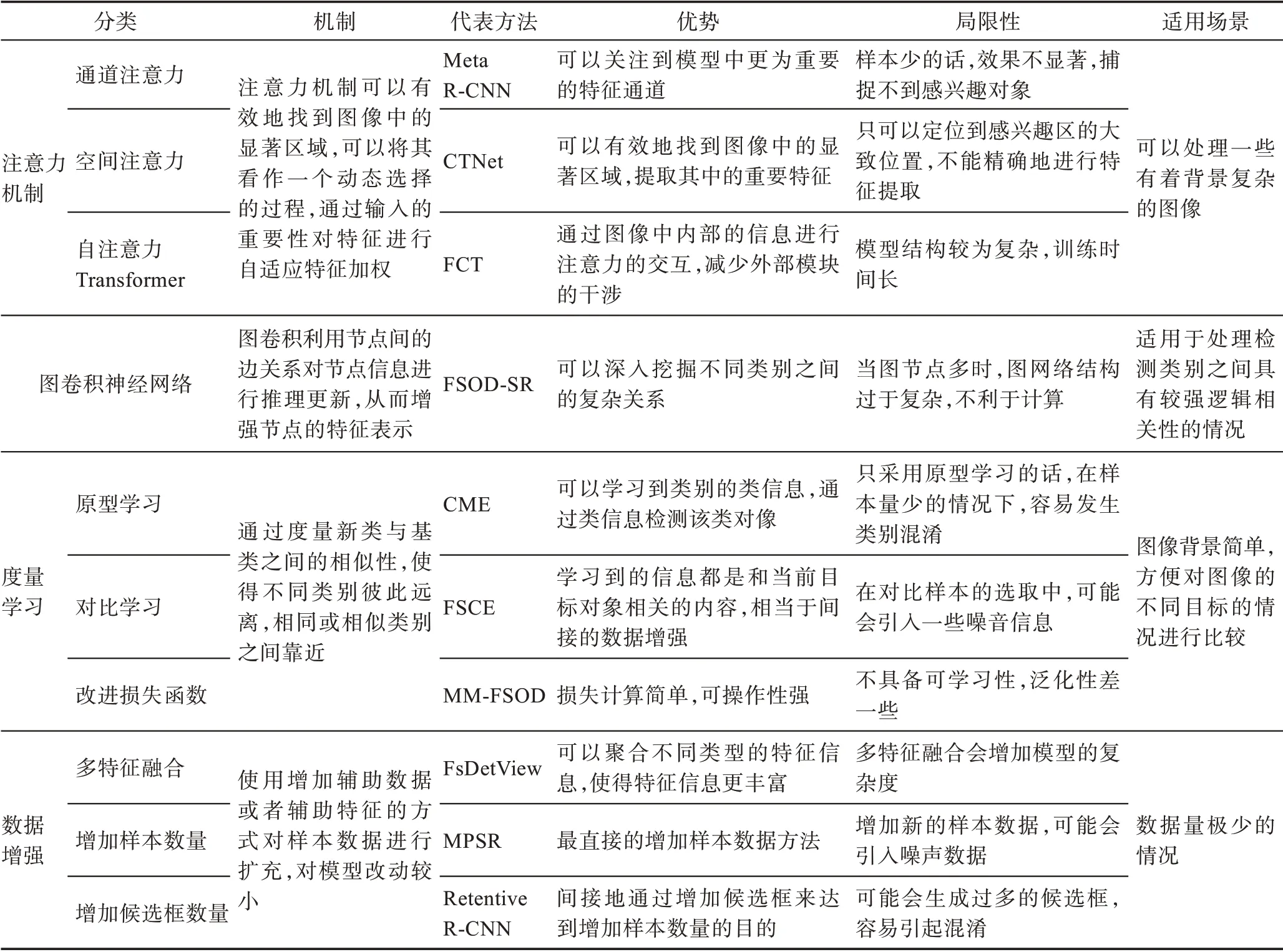
表2 小樣本目標(biāo)檢測(cè)方法優(yōu)缺點(diǎn)對(duì)比Table 2 Comparison of advantages and disadvantages of few-shot object detection methods
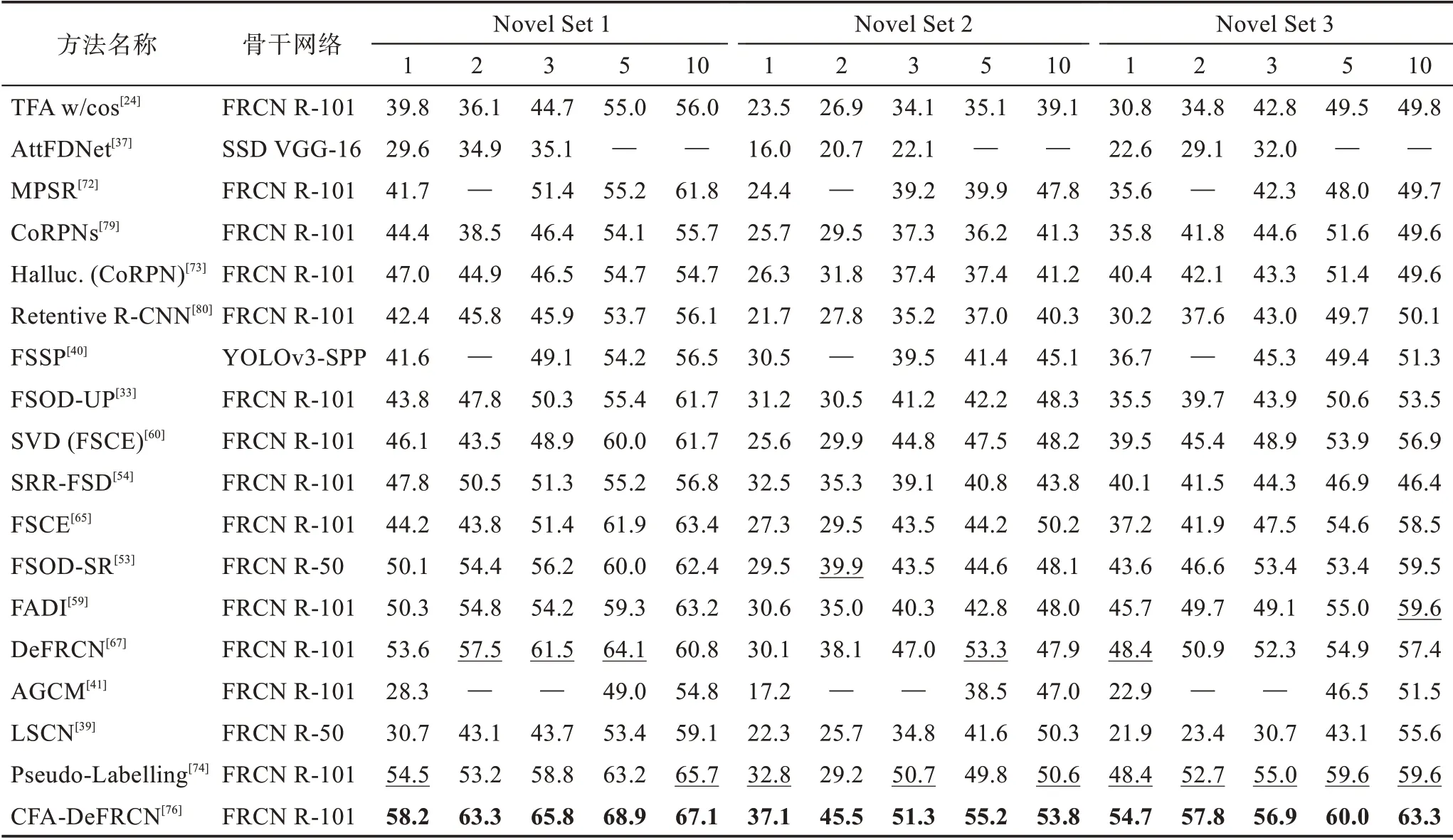
表3 遷移學(xué)習(xí)方法在VOC 數(shù)據(jù)集上的mAP 對(duì)比Table 3 mAP comparison of transfer learning methods on VOC dataset 單位:%
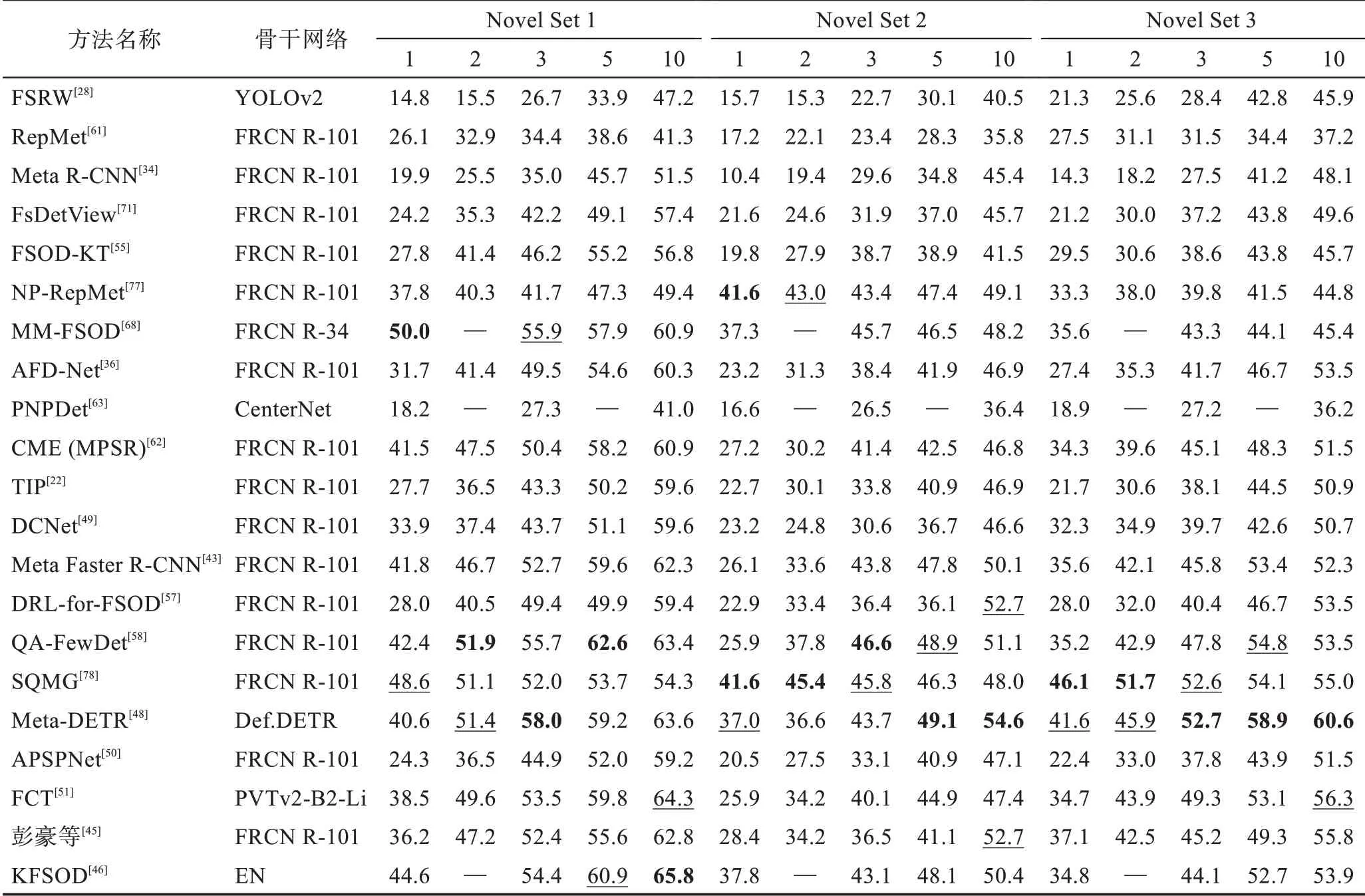
表4 元學(xué)習(xí)方法在VOC 數(shù)據(jù)集上的mAP 對(duì)比Table 4 mAP comparison of meta-learning methods on VOC dataset 單位:%
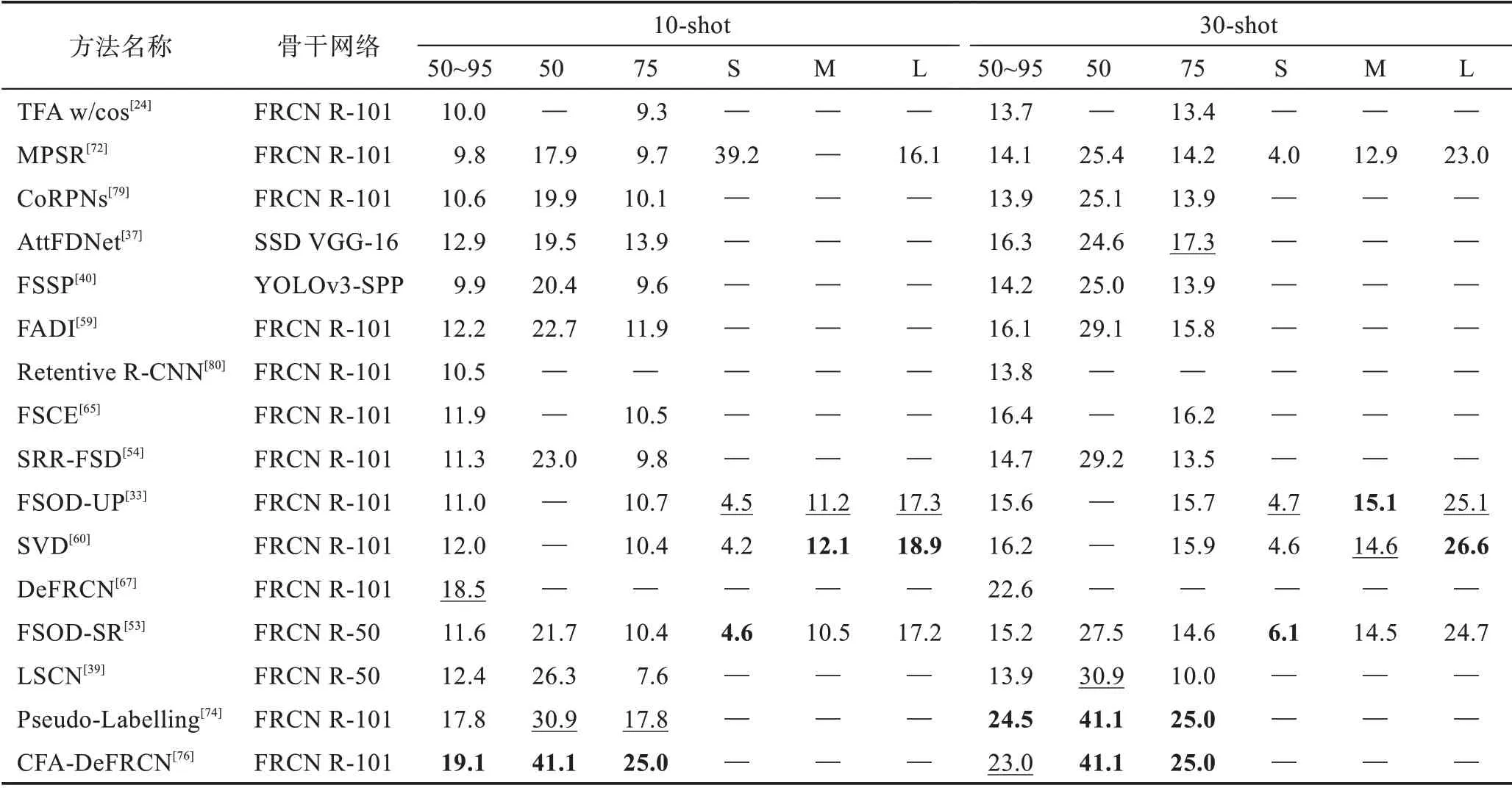
表5 遷移學(xué)習(xí)方法在COCO 數(shù)據(jù)集上的AP 對(duì)比Table 5 AP comparison of transfer learning methods on COCO dataset 單位:%
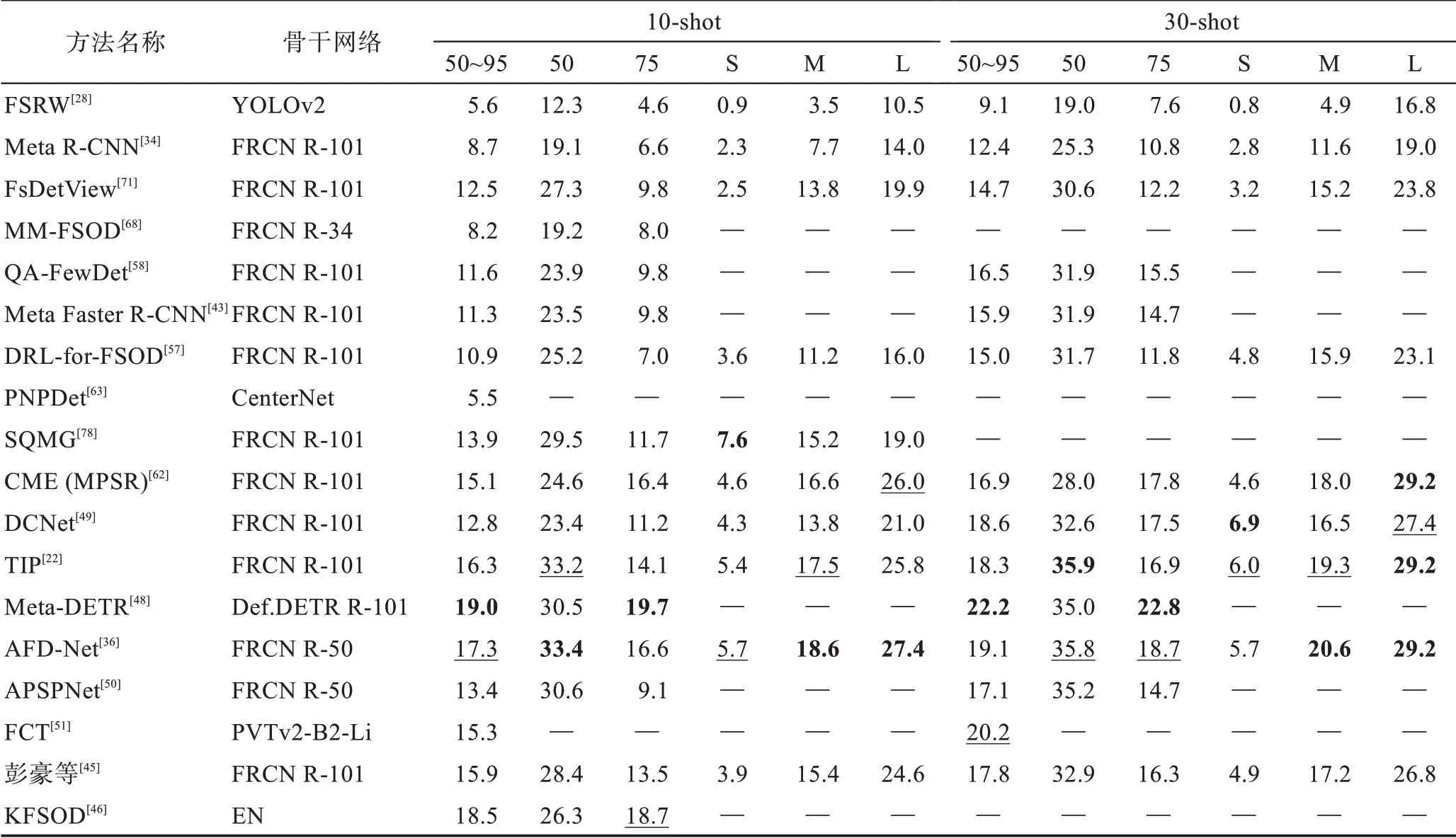
表6 元學(xué)習(xí)方法在COCO 數(shù)據(jù)集上的AP 對(duì)比Table 6 AP comparison of meta-learning methods on COCO dataset 單位:%
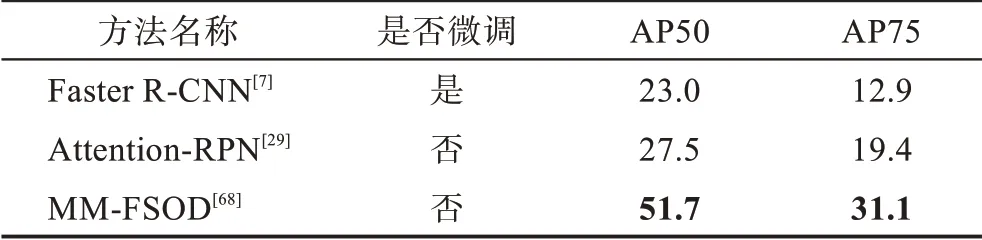
表7 FSOD 數(shù)據(jù)集上的性能對(duì)比Table 7 Performance comparison on FSOD dataset 單位:%
從表中可得:(1)無(wú)論是采用遷移學(xué)習(xí)范式還是元學(xué)習(xí)范式在檢測(cè)性能上并沒(méi)有太大的差異,由前述對(duì)兩種范式的分析可選擇適合的范式進(jìn)行改進(jìn)增強(qiáng)。(2)隨著shot 數(shù)的增多,檢測(cè)性能有較大的提升,說(shuō)明圖像信息越多,學(xué)習(xí)到的特征信息越充分,樣本數(shù)據(jù)增強(qiáng)可能是小樣本問(wèn)題解決的關(guān)鍵,最新的方法Pseudo-Labelling[74]和CFA-DeFRCN[76]都在探索數(shù)據(jù)增強(qiáng)的方法,也說(shuō)明了數(shù)據(jù)增強(qiáng)的重要性。(3)在不同的數(shù)據(jù)集上檢測(cè)結(jié)果也不相同,VOC 的檢測(cè)結(jié)果總體要大于COCO 的檢測(cè)結(jié)果,在VOC 和COCO數(shù)據(jù)集上表現(xiàn)最好的都是基于遷移學(xué)習(xí)范式的CFADeFRCN,其除了使用數(shù)據(jù)增強(qiáng)外,將其結(jié)合基于度量學(xué)習(xí)DeFRCN 方法使用,得到了最優(yōu)秀的檢測(cè)結(jié)果。可見(jiàn)使用較為簡(jiǎn)單直接的技術(shù)方法可以成功減少模型過(guò)擬合的程度,從而達(dá)到較優(yōu)的效果。(4)其他的使用注意力機(jī)制方法的Meta-DETR 和AFD-Net以及使用數(shù)據(jù)增強(qiáng)的SQMG方法也表現(xiàn)出了不錯(cuò)的性能。
5 小樣本目標(biāo)檢測(cè)在各領(lǐng)域的應(yīng)用研究
小樣本目標(biāo)檢測(cè)算法由于只需要少量的新類(lèi)標(biāo)注就可以完成對(duì)目標(biāo)類(lèi)別的檢測(cè),目前在自動(dòng)駕駛、遙感圖像檢測(cè)、農(nóng)業(yè)病蟲(chóng)害檢測(cè)等領(lǐng)域都有應(yīng)用。
5.1 自動(dòng)駕駛
自動(dòng)駕駛是目前計(jì)算機(jī)視覺(jué)應(yīng)用較為成功的一個(gè)領(lǐng)域,車(chē)輛行駛會(huì)面臨非常多的場(chǎng)景,遇見(jiàn)各種各樣的類(lèi)別,不可能對(duì)全部的類(lèi)別收集到大量標(biāo)注的圖像,自動(dòng)駕駛需要確保駕駛的絕對(duì)安全,在很短的時(shí)間里做出反應(yīng),這些特性通用目標(biāo)檢測(cè)都無(wú)法滿(mǎn)足。Majee 等[86]新提出了IDD[87]數(shù)據(jù)集,并驗(yàn)證了TFA 方法和FSRW 方法在該數(shù)據(jù)集上的性能表現(xiàn);Agarwal 等[41]提出了AGCM 方法,有助于在檢測(cè)器的分類(lèi)頭中創(chuàng)建更加緊密且良好分離的特征簇,在IDD自動(dòng)駕駛數(shù)據(jù)集上取得了當(dāng)時(shí)的最好效果。
5.2 遙感目標(biāo)檢測(cè)
另外一個(gè)常見(jiàn)的應(yīng)用領(lǐng)域是遙感目標(biāo)檢測(cè),遙感圖像有助于救援行動(dòng)援助、災(zāi)害預(yù)測(cè)和城市規(guī)劃等,對(duì)于一些偏遠(yuǎn)地區(qū)或者無(wú)人區(qū)遙感數(shù)據(jù)的獲取同樣非常困難,且其中出現(xiàn)的目標(biāo)種類(lèi)眾多,這對(duì)于通用目標(biāo)檢測(cè)是極大的挑戰(zhàn)。Xiao 等[88]提出了SAAN(self-adaptive attention network)方法,在目標(biāo)對(duì)象上使用注意力,而不是整張圖像,避免一些無(wú)用的甚至是有害的特征干擾,在RSOD[89]數(shù)據(jù)集上取得了最好的效果。另外,李成范等[90]在自建的HSI 遙感圖像上應(yīng)用K 近鄰(K-nearest neighbor,KNN)得到了圖像局部特征,并與改進(jìn)的CNN 算法結(jié)合,使用TripletLoss 損失令同類(lèi)更加緊密,不同類(lèi)別更加分離,得到了良好的檢測(cè)效果。
5.3 農(nóng)業(yè)病蟲(chóng)害檢測(cè)
對(duì)于農(nóng)業(yè)病蟲(chóng)害檢測(cè),需要專(zhuān)業(yè)的領(lǐng)域知識(shí)才能識(shí)別不同作物、不同生長(zhǎng)環(huán)境下的病蟲(chóng)害,完成標(biāo)注工作,而要求農(nóng)業(yè)專(zhuān)家進(jìn)行大量的標(biāo)注工作是費(fèi)時(shí)費(fèi)力的,且害蟲(chóng)可以處在不同的發(fā)育期,要獲取大量這種圖像數(shù)據(jù)同樣較為困難,現(xiàn)階段只有很少的一些工作涉及到小樣本病蟲(chóng)害檢測(cè)。劉凱旋[91]建立了基于不同樣本數(shù)量的水稻害蟲(chóng)檢測(cè)算法。在樣本數(shù)據(jù)多的時(shí)候,使用Cascade R-CNN[75]模型進(jìn)行害蟲(chóng)檢測(cè),當(dāng)樣本數(shù)量進(jìn)一步減少時(shí),再通過(guò)條件判斷切換成小樣本目標(biāo)檢測(cè)算法,為后續(xù)農(nóng)業(yè)害蟲(chóng)的智能化檢測(cè)研究提供了理論支撐。桂江生等[92]針對(duì)大豆食心蟲(chóng)蟲(chóng)害進(jìn)行了小樣本檢測(cè),通過(guò)卷積學(xué)習(xí)一個(gè)非線(xiàn)性度量函數(shù),而不是使用線(xiàn)性度量公式衡量查詢(xún)集和支持集之間的關(guān)系,最終5-shot 的條件下可以達(dá)到82%的檢測(cè)率。
5.4 其他潛在應(yīng)用領(lǐng)域
另外,還有一些其他可以探索的應(yīng)用領(lǐng)域,比如,自然界的生物種類(lèi)眾多,對(duì)于生物保護(hù)來(lái)說(shuō),辨認(rèn)物種類(lèi)別尤為關(guān)鍵,其類(lèi)別符合長(zhǎng)尾分布,大部分的類(lèi)別都只有很少的數(shù)量且不易獲取到其圖像,可以將其應(yīng)用到不常見(jiàn)的生物物種檢測(cè);零售商品的自動(dòng)售賣(mài)技術(shù)很方便地為顧客提供24 h 服務(wù),零售商品的種類(lèi)成千上萬(wàn),目標(biāo)檢測(cè)所需的標(biāo)注成本巨大,如果只標(biāo)注很少圖像就可以完成檢測(cè)的話(huà),可以大大縮減成本;在工業(yè)檢測(cè)領(lǐng)域,缺陷檢測(cè)的自動(dòng)化工作可以節(jié)約大量的人力且提高效率,比如雞蛋裂紋檢測(cè),可以提高產(chǎn)品質(zhì)量,但實(shí)際的工廠作業(yè)很難收集到大量的樣本數(shù)據(jù),小樣本目標(biāo)檢測(cè)可以利用少量的樣本完成缺陷檢測(cè)。
6 小樣本目標(biāo)檢測(cè)的未來(lái)研究趨勢(shì)
小樣本目標(biāo)檢測(cè)的創(chuàng)建初衷是用來(lái)解決實(shí)際問(wèn)題的,可現(xiàn)階段的效果仍然不太理想。譬如小樣本目標(biāo)檢測(cè)方法在COCO 數(shù)據(jù)集10-shot 的條件下最好的mAP 檢測(cè)效果僅有19.1%,這距離實(shí)用性仍有較大的差距。除了需要提高檢測(cè)精度外,未來(lái)小樣本目標(biāo)檢測(cè)方法在以下方面值得進(jìn)一步的研究:
(1)自適應(yīng)領(lǐng)域遷移:從不同領(lǐng)域?qū)W習(xí)到的通用概念往往并不相同,將從一個(gè)領(lǐng)域中學(xué)習(xí)到的知識(shí)遷移到另一個(gè)領(lǐng)域的方法,叫作自適應(yīng)域遷移。小樣本目標(biāo)檢測(cè)方法也是將從基類(lèi)學(xué)習(xí)到的知識(shí)遷移到新類(lèi)中,可以將自適應(yīng)領(lǐng)域遷移的方法應(yīng)用到小樣本目標(biāo)檢測(cè)方法中。
(2)數(shù)據(jù)增強(qiáng)方面:小樣本對(duì)于模型過(guò)擬合問(wèn)題尤為敏感,而圖像數(shù)據(jù)增強(qiáng)技術(shù)恰恰是最直接簡(jiǎn)便的用于減少過(guò)擬合的方法,比如使用半監(jiān)督和自監(jiān)督等方法可以減少模型的過(guò)擬合。
(3)圖卷積神經(jīng)網(wǎng)絡(luò):現(xiàn)在有一些工作是基于圖卷積神經(jīng)網(wǎng)絡(luò)完成的,但圖卷積神經(jīng)網(wǎng)絡(luò)是一個(gè)仍在不斷探索的領(lǐng)域,研究如何在小樣本條件下通過(guò)圖卷積神經(jīng)網(wǎng)絡(luò)更好推理學(xué)習(xí)是很有前景的方向。
(4)多模態(tài)的方向:Transformer 作為注意力機(jī)制方法,有著天然的處理多種模態(tài)的數(shù)據(jù),將文字和圖像等結(jié)合起來(lái)共同考慮,這對(duì)于缺乏圖像樣本數(shù)量的小樣本檢測(cè)任務(wù)是巨大的增強(qiáng)。
7 總結(jié)
本文對(duì)小樣本目標(biāo)檢測(cè)做了詳細(xì)的分析總結(jié)。首先,介紹了小樣本目標(biāo)檢測(cè)任務(wù)的定義及相關(guān)概念,敘述了小樣本目標(biāo)檢測(cè)基于元學(xué)習(xí)和基于遷移學(xué)習(xí)的兩種經(jīng)典范式,重點(diǎn)闡述了從注意力機(jī)制、圖卷積神經(jīng)網(wǎng)絡(luò)、度量學(xué)習(xí)和數(shù)據(jù)增強(qiáng)方面提升小樣本目標(biāo)檢測(cè)性能的方法。之后,對(duì)常用數(shù)據(jù)集和評(píng)估指標(biāo)進(jìn)行了介紹,對(duì)各個(gè)方法的性能進(jìn)行了比較和分析。最后,提出了小樣本目標(biāo)檢測(cè)應(yīng)用的一些領(lǐng)域并對(duì)未來(lái)的研究方向進(jìn)行了展望。
猜你喜歡
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
