基于fasttext 實現船舶工況點分類系統研究
2023-01-24 12:51:54陳浩天劉曉東
電子設計工程 2023年2期
陳浩天,劉曉東,2
(1.武漢郵電科學研究院,湖北武漢 430070;2.武漢虹旭信息技術有限責任公司,湖北 武漢 430070)
截止到2021 年上半年,船舶領域的語料庫基本缺失,無法在互聯網、圖書館等公共資源區域有效獲得船舶領域的相關語料,也就無法實現船舶工況點自動匹配。
現有的文本自動匹配方法研究如傳統的知識工程分類[4],對時間維度消耗大,不滿足最后的自動化處理需求;基于深度學習進行分類處理[8]的算法在處理時對語料要求很大,模型的效果很大程度取決于語料的好壞,人們常用的Logistic算法以及SVM算法[11]都是如此。隨著詞向量的提出,深度學習算法逐漸進入人們的視野,CBOW 模型[12]以及Skip-Gram 模型都能很好地對分布式詞向量模型進行分類。
為了驗證改進C-fattext 算法在實驗中可以提升效率,文中針對改進C-fasttext 算法和在分類中常用的樸素貝葉斯算法、支持向量機算法和原始fasttext算法進行對比,力求達到實驗預期指標。
1 分類算法相關原理
1.1 傳統分類步驟
傳統分類步驟大致可以分為四步,即文本獲取、文本預處理、特征詞提取、分類器選擇。
1.1.1 文本獲取
在船舶領域,目前,互聯網、圖書館等場所無法獲取有效的船舶資源,這為獲取語料造成了極大的影響,文中通過網絡爬蟲獲取大量船舶網站的新聞數據以及試驗數據,加上公司內部船舶資料、船長提供的手冊資料等,將這些資料結合成為一個龐大的語料庫,進而轉換為純文本語料庫。
1.1.2 文本預處理
在文本獲取中得到大量文本數據后,不能直接使用原始數據進行后續實驗,原始文本數據中包含了大量垃圾信息與噪聲,這些垃圾信息與噪聲對后續需要進行的分類工作沒有任何幫助,甚至在一定程度會起到相反的作用,對分類的速度、準確率造成不同程度的干擾,導致試驗分類結果不佳。因此,使用分詞、去停用詞、同義詞轉換等方法處理文本信息。
1.2 特征詞提取
一個工況點的主要內容可以由其特征詞匯決定,通過這些特征詞匯完成工況點分類。目前特征提取算法已經呈現多元化發展,例如TF-IDF(Term Frequency-Inverse Document Frequency,詞頻-逆文本頻率指數)算法、TextRank 算法(基于圖的用于關鍵詞抽取和文檔摘要的排序算法)、互信息算法、信息熵算法等,這些算法都能滿足特征提取需求。文中選用TF-IDF 算法實現工況點分類任務的特征詞提取。
1.3 分類器選擇
文中使用fasttext 分類器,fasttext 分類器采用分層softmax 提高訓練速度,在大量文本中取得更好的評分效果,其因速度快、準確率高而被廣泛應用在文本分類領域。
2 分類算法改進
2.1 TF-IDF算法
詞頻TF 表示文本某個詞在前文本中出現的次數或者頻率,計算公式為:
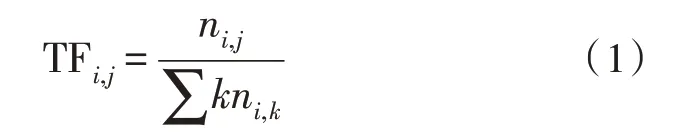
逆文檔頻率IDF 代表一個詞在詞庫中出現的詞條的頻率:
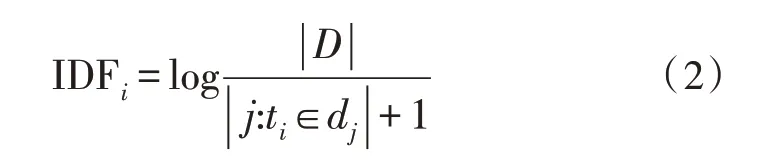
TF-IDF 算法的核心思路為詞頻和逆文檔頻率的乘積:
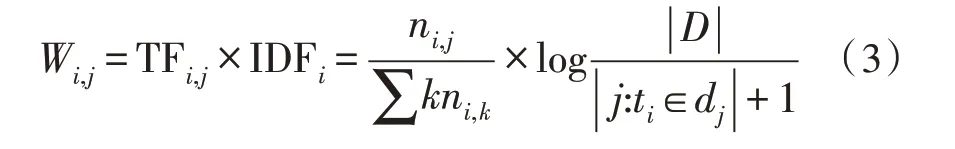
2.2 TF-IDF算法改進
為了避免因為使用IDF 逆文檔頻率直接表示文本外部特征帶來的負面影響,可以在分詞之后,將處于設備部分,并且出現可以直接代表分類結果的詞匯,直接匹配上分類結果。例如,在分類“主機”類別時,形如“No.1 主機轉速”在分詞之后會出現“主機”詞匯,可以直接將此工況點分類至“主機”類別中;在后續通過模型訓練出類別后,可以使用此規則得到的結果直接覆蓋,提升因為模型誤差、參數設計不合理等因素造成的分類失誤。
在傳統的TF-IDF 算法中,增加一個能夠表示船舶的特定工況點庫,如果待對比工況點數據出現在此特定工況點庫中,則記錄系數ci,表示工況點中是否出現了符合特定工況的情況。如果出現在特定工況點庫中,則按照工況點中記錄的ci系數同式(3)中的Wi,j相乘,同時需要考慮到特征詞在同一類別,但不同文章之間的分布情況。在傳統的TFIDF 算法中,如果一個詞匯在某類別的文章中和另外一個詞匯出現在此類別的文章中的次數是相同的,則這兩個詞匯會獲得相同的TF-IDF 系數。然而,可能前面的詞匯在同種文章中的分布是均勻的,后者卻在小部分文章中大量出現,那么前者詞匯的系數應當大于后者的系數。為了解決上述可能出現的情形,同步對對式(3)進行更新,新增類內系數aci,計算如下:
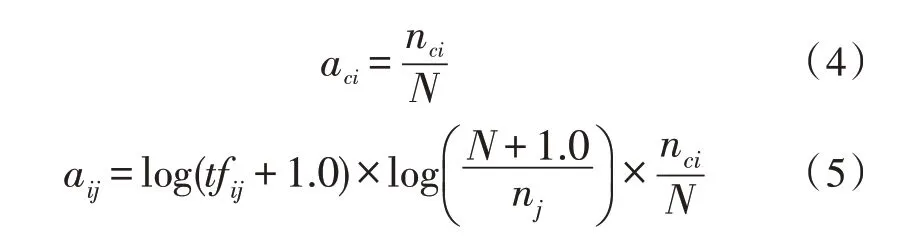
式中,tfij表示詞j在文檔i中的頻率,N表示文檔總數目,nj表示詞j出現的總文檔數,nci表示詞j在類別c文檔中出現的文檔數目。通過對輸入文本的每個詞都進行更改后的TF-IDF 算法計算,將其命名為C-TF-IDF 算法。
另外,單純添加一個系數仍然無法避免低頻詞條刪除問題,因為在壓縮文檔時,低頻向量詞條可能會被刪除,這樣就可能會忽略掉出現頻率不高,但是代表性、專業性很強的詞匯,使得改進的C-TF-IDF算法性能在某些情況下大打折扣。
為使得對權重的處理更加合理,使用歸一化處理,以達到簡化計算的目的。使用歸一化作用于每個詞向量,標準化高頻詞匯和低頻詞匯權重,避免出現某詞匯出現次數過多或者過少而產生分布失衡的現象,同時也避免出現詞頻相差過大而影響分類效果。如此更改對權重的處理將更加有意義,再結合fasttext 算法,將C-fasttext 算法進行更新。
C-fasttext 算法的計算步驟如下:
1)規則索引;
2)語料庫的收集以及文本預處理;
3)在原始詞序列中增加N-gram 特征;
4)使用創新后的C-TF-IDF 算法計算單個工況點結果aij;
5)根據得到的結果aij對目標工況點權重進行更新迭代計算;
6)進行模型運算。
2.3 fasttext算法
fasttext 算法原理從word2vec 順延而來,它們都擁有CBOW 模型類似的結構,即分為三層:①輸入層,主要為文本詞向量的輸入、特征的輸入等;②隱藏層,進行相關參數計算、迭代;③輸出層,與word2cev不同的是,fasttext 算法是通過上下文預測類別,其輸出的是最終判斷的類別可能性。
2.4 fasttext算法改進
fasttext 算法可以理解為帶監督的分類模型,輸入的數據可以認為是帶有參數系數的詞向量信息,在輸入之前加入一層憑借層,此層的主要作用是將得到的信息整合,刪除無用信息,保證數據的完整性與可靠程度。憑借層網絡拓撲圖如圖1 所示。
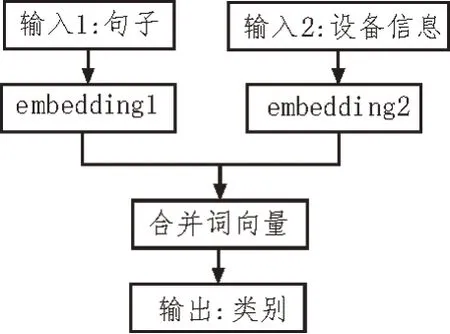
圖1 憑借層網絡拓撲圖
由于文中的應用領域為船舶領域,結合前文對于算法的改進,最終選擇的損失函數是交叉熵損失函數:

一個批次中的損失函數計算公式如式(7)所示:
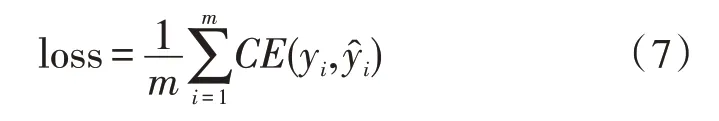
式中,yi表示實際類別的標記,表示模型預測的類別標記。
可以得出改進后fasttext 算法實現流程如圖2所示。
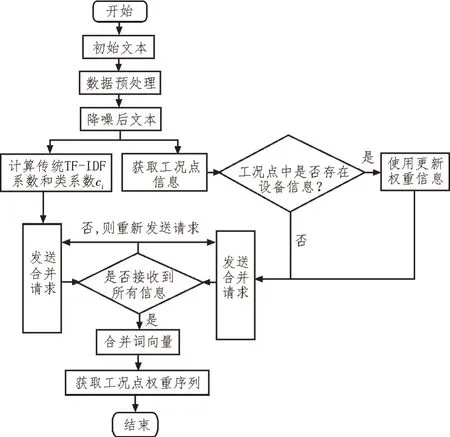
圖2 改進后fasttext算法實現流程圖
3 實驗及分析
3.1 實驗環境
文中試驗環境為本地Windows10 家庭版操作系統,Intel Core i5 處理器,使用的語言為Python3.7,實驗采用的評判指標為文本分類準確率、召回率、F值,用于對比顯示結果。
3.2 實驗數據
實驗使用數據集為船舶領域數據庫中已經擁有的2 123 條工況點數據,驗證數據集為新船中選取的1 000 條工況點,訓練集中數據格式如圖3 所示。

圖3 訓練集數據格式
3.3 評價方法
在自然語言領域,通常使用三種評估指標,分別為準確率、召回率和F 值。
準確率:準確率表示模型預測為正樣本且實際為正樣本的比例,計算公式為:

召回率:召回率表示模型準確預測為正樣本的數量占所有正樣本數量的比例,計算公式為:

F 值:可以理解為P和R的加權調和平均,計算公式為:
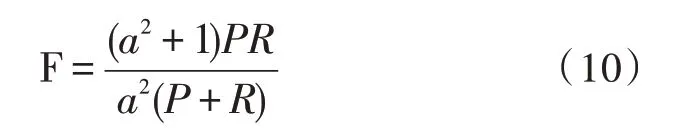
3.4 實驗結果分析
為驗證改進的C-fasttext算法的分類能力,使用實驗數據進行測試,同時選擇樸素貝葉斯算法、SVM 算法、傳統fasttext算法同改進的C-fasttext算法進行對比。
為了數據能夠更加直觀顯示,使用折線圖表示不同類別工況點數目,如圖4 所示。
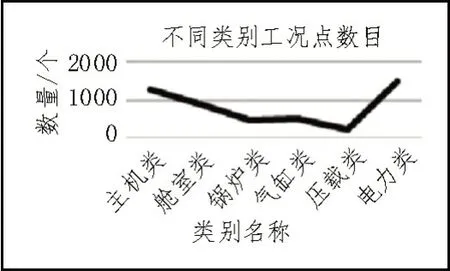
圖4 不同類別工況點數目
圖4 表明,在船舶領域中,六大主要類別出現概率差距不大,沒有出現某種類別過多或者過少的情況,其中壓載類工況點數目少是因為壓載類一般出現在其他類別的輔助類中,原始數據中單獨出現壓載類的情況并不多。在數據集中,每個類別占有總數據的比例為:主機類26.45%,艙室類18.14%,鍋爐類9.85%,氣缸類10.40%,壓載類5.03%,電力類30.12%。在分類判決中,實際還有一個其他類,其他類擁有出現極少或者特殊情況的工況點,在分類階段暫時剔除,以免對分類結果產生影響。
圖5 給出了改進C-fasttext 算法在船舶領域六大類中的分類結果。
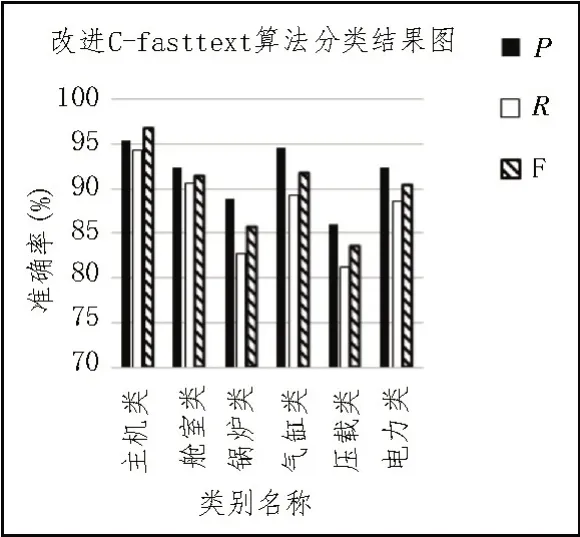
圖5 改進C-fasttext算法分類結果圖
四種分類方法準確率結果如圖6 所示。
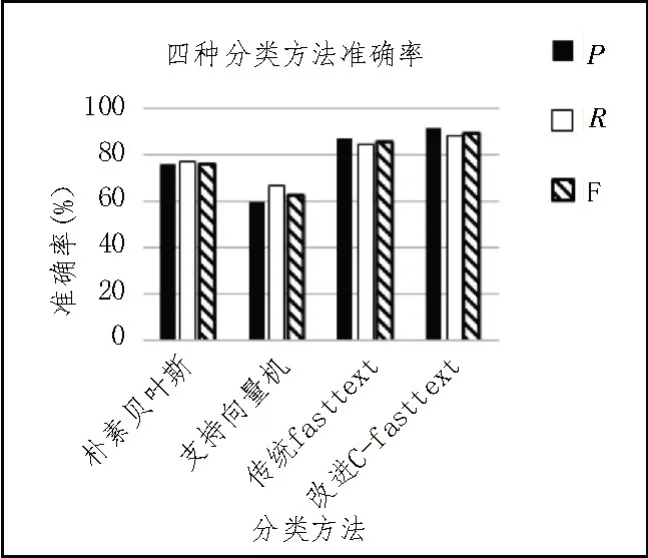
圖6 四種分類方法準確率結果圖
由圖6 可知,文中提出的改進C-fasttext 算法準確率最高,高達91.59%;傳統的fasttext 分類算法的平均準確率也處于領先地位,為88.27%;支持向量機算法處在較低水平,準確率只有59.98%;樸素貝葉斯方法在準確率上達到76.19%。可以看出,對比樸素貝葉斯算法、支持向量機算法和原始fasttext 算法,改進C-fasttext 算法在二分類任務中獲得了較好的評分,說明改進是成功的。
在錯誤控制方面,隨機抽取100 條數據,查看分類結果,發現誤報率為3%,語料覆蓋率為97%,滿足最初控制誤報率不超過5%、語料庫覆蓋率超過95%的需求,得出基于fasttext 的船舶工況點分類研究算法滿足項目要求結論。
4 結論
為解決船舶領域工況點對比分類問題,提出基于fasttext 的改進C-fasttext 算法,對特征提取方法中的TF-IDF 算法做出改進,使其在權重設置上更加符合工況點分類要求;對fasttext 算法在輸入層做出創新,指出其在應用于工況點分類中的不足之處,提出的C-fasttext 算法在原有基礎之上進行了改進,從而節省大量人力資源,匹配準確率為91.59%,語料覆蓋率為97%,提出的C-fasttext 算法能夠完善對工況點的分類效果,滿足需求。
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:07:40
船舶(2021年4期)2021-09-07 17:32:22
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
小哥白尼(趣味科學)(2019年10期)2020-01-18 09:16:22
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
