基于注意力機制的深度學習體育運動姿態估計技術
2023-01-24 12:52:10魏玉福陳麗萍
電子設計工程 2023年2期
魏玉福,陳麗萍
(包頭醫學院衛生健康學院,內蒙古包頭 014030)
二維人體姿態估計(2D human pose estimation)[1-2]是計算機視覺研究領域的重要方向之一。人體2D姿態估計主要通過檢測人體的各個部位,勾勒出人體姿態的抽象輪廓,在實際中可應用于體育運動肢體識別[3-4]、智能檢測[5]等。
人體姿態估計問題的研究近年來也引起了眾多科研人員的關注。基于圖結構(Pictorial Structures)模型[6-7]是傳統的姿態估計算法中主要應用到的模型結構之一,但傳統姿態估計方法具備單一性,對于復雜多變的人體姿態而言檢測效果并不好。結合深度學習的人體姿態估計技術近年來取得了顯著進展。如Toshev 等人通過對人體姿態進行了上下文全局估計,提出了完全DeepPose[8-9]姿態估計神經網絡模型,該模型推進了姿態估計研究領域的發展。
針對人體姿態估計問題,該文結合HRNet(High Resolution Networks)[10-11]姿態估計神經網絡模型,提出了一種結合注意力機制實現的運動人體姿態估計方法,該方法將空間注意力機制提取的豐富特征信息融入到HRNet 網絡當中,構建了更加準確的人體姿態估計模型,并在實驗中表現出了較好的效果。
1 方法與處理
基于注意力機制[12-13]的深度學習姿態估計技術的整體流程主要是基于HRNet 姿態估計神經網絡模型,在高分辨率與低分辨率連接的并行網絡中間添加了空間注意力模塊,以提取各層次間的注意力特征圖,并融合到后面的高分辨率網絡層次當中,豐富了特征層次,以達到更好的姿態估計效果,基于空間注意力機制的深度學習體育運動姿態估計模型整體如圖1 所示。

圖1 基于注意力機制的深度學習姿態估計網絡
注意力機制是將計算機聚焦于局部顯著信息的機制,隨著執行任務的變化,注意力區域一般會發生一定的變化,其本質是消除無用信息的影響,快速標記相應任務的感興趣區域,通常以概率圖或者概率特征向量的方式實現。常用的注意力機制包含通道注意力[14]與空間注意力機制[15-16]。
1)通道注意力機制
通道注意力機制主要是以通道全局特征為基準獲取特征圖通道間的權重值[17],以自適應調整各個通道特征響應值,實現了在多通道進行特征注意力結合,通道注意力機制的一般網絡結構如圖2 所示。

圖2 通道注意力模塊圖示
通道注意力首先對長寬以及通道數為H1×W1×C1的輸入X進行特征提取,來獲取U,再使用全局平均池化方式生成1×1×C大小的通道信息統計映射描述符,如式(1)所示:

式中,H與W分別為輸入特征圖的長寬,U(i,j)為特征圖每一點的像素,獲取的通道信息統計映射描述符,再進行Sigmoid 門限機制進行權重映射,使其權重映射在區間(0,1)中,如式(2)所示:
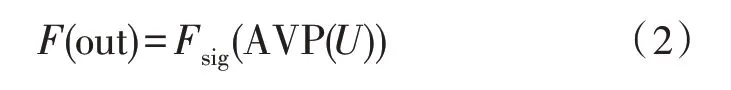
F(out)為映射后的通道權重值,最后將權重F(out)與輸入特征圖在對應的每個通道上進行乘積,獲取通道注意力特征視圖,如式(3)所示:

式中,Xm為獲取的最終通道注意力特征圖,Fscle為對權重與特征圖通道的乘積操作。
2)空間注意力機制
空間注意力機制是給每個像素計算注意力采納數,以實現全圖范圍的特征提取,從而有效地彌補了卷積操作因感受野有限導致的全局特征提取能力不足問題,其一般流程如圖3 所示。

圖3 空間注意力模塊圖示
首先,對圖像生成P1,如式(4)所示:

式中,Favg與Fmax分別對應平均池化與最大池化操作,將Favg與Fmax進行連接生成P1,并通過7×7 的卷積層進行卷積操作,生成特征圖Conv1,最后通過Sig(sigmoid)函數生成空間注意力圖,具體的計算公式如式(5)所示:

式中,Fout為空間注意力圖,f7×7為7×7 的卷積操作,以擴大感受野。該文將空間注意力機制與HRNet 網絡進行融合,以提取多維度的圖像特征,實現高精度的姿態估計方法。
2 實驗驗證
實驗選擇了HRNet、DeepPose 作為對比實驗方法,開展實驗驗證,并且對該文提出的基于注意力機制的深度學習姿態估計方法從姿態估計精度AP(Average Precision)以及姿態估計速度(張/s)方面進行對比評價,其中AP 即為檢測效果與真實姿態輪廓的比值。
實驗過程選擇了統一的實驗環境,其軟硬件實驗配置如表1 所示。

表1 實驗環境配置表
實驗選擇了1 200 張不同的體育運動人體姿態圖作為數據集,其中1 100 張作為訓練集,其余200張姿態圖像作為測試集,其中部分體育運動人體姿態圖如圖4 所示。

圖4 實驗數據圖像
分別基于HRNet、DeepPose 以及該文提出的結合空間注意力機制的深度學習姿態估計方法對部分樣例進行姿態估計測試,可得到如圖5 所示的結果圖像。

圖5 基于不同方法獲取的實驗結果圖像
對實驗結果數據基于姿態檢測精度以及姿態估計速度進行統計,如表2 所示。

表2 姿態估計結果數據對比
基于圖5 中實驗數據進行主觀對比分析,可以看出,該文提出的基于注意力機制的深度學習姿態估計方法對于運動人體的姿態輪廓估計更加連續,也比較細致;也充分驗證了該文提出的基于注意力機制的深度學習姿態估計方法的可行性。
結合表2 中的姿態估計結果數據對比數據進行客觀分析可知,該文提出的基于注意力機制的深度學習姿態估計方法與經典的HRNet 與DeepPose 方法相比較,姿態估計精度最高,雖然該方法增加了注意力機制模塊而提升了參數量,造成了姿態估計速度低于HRNet 方法,但仍然具備較高的姿態估計效率。
綜上所述,該文提出的基于注意力機制的深度學習姿態估計方法充分結合注意力機制提取的有效姿態特征,實現了較高的姿態估計精度,與其他兩種方法相比較,具備較好的姿態估計效果。
3 結束語
該文針對現有的基于深度學習的姿態估計問題,提出了一種基于注意力機制的深度學習姿態估計方法,該技術充分結合注意力機制的優勢,嵌入至HRNet 網絡內部,在多分辨率特征傳輸過程中進行了交叉空間注意力特征提取,結合網絡上下層信息,實現了高精度的姿態估計方法,并通過一系列對比體育運動姿態提取實驗驗證,充分驗證了該文提出的基于注意力機制的深度學習姿態估計方法的有效性。
接下來的研究工作將著重于對姿態估計特征的深層次提取,結合Transform 模型結構,實現基于注意力機制的深層次姿態估計策略。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
文苑(2018年21期)2018-11-09 01:23:06
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國衛生(2015年9期)2015-11-10 03:11:12
中國衛生(2014年3期)2014-11-12 13:18:12
