一種新的藝術嗓音客觀評價方法
2023-01-24 12:52:10李延華張若雨陳文韜
電子設計工程 2023年2期
李延華,曹 輝,張若雨,陳文韜,曹 娜,范 翔
(陜西師范大學物理學與信息技術學院,陜西西安 710119)
藝術嗓音是指經過長期系統、專業的聲樂訓練且具有一定音樂和嗓音天賦的特定人群,在特定場合中用特殊方式表現出來的嗓音[1]。藝術嗓音可以用來衡量歌手唱歌水平的高低,在歌手的選拔和培養過程中,如何客觀準確地評價藝術嗓音是我們面臨最直接的問題,解決此問題對藝術院校的招生、教學和考核環節也有重大意義。
目前,國內外藝術嗓音的評價方法主要為主觀聽感知評價,該方法存在主觀性強、耗時、費力且準確率低等缺陷。因此科研人員對藝術嗓音的研究逐漸轉向客觀評價,王修信[2]、羅蘭娥[3]等人使用平均能量、平均音域誤差、共振峰、共振峰微擾等多種聲學參數以及BP 網絡進行評價。吳媛[4]提取第一共振峰、第三共振峰、基頻三個聲學參數,用機器學習的方法對樣本做出評價,與評委老師評價相比一致性達90%。上述方法均存在以下兩點不足:①供評測的樣本只有一首歌曲,較單一,不具有普遍性;②準確率較低。
聲譜圖是一種二維圖像,可以直接體現語音頻譜隨時間的變化[5]。橫軸對應時間,縱軸對應頻率,每個坐標點的值對應某一頻率分量在某一時刻的能量。因此,語音由于時間變化而產生的不同諧振頻譜可以在聲譜圖中呈現出不同的視覺圖像紋理[6]。近幾年,聲譜圖在眾多科研項目中都有應用,如文獻[7]提出利用聲譜圖來進行江西方言的分區研究,文獻[8]采用聲譜圖進行聲樂分類研究等。相比于傳統機器學習,卷積神經網絡(Convolutional Neural Network,CNN)的網絡結構更復雜,隱藏層更多,因此學習特征和表達特征的能力更強,被較好地運用于處理大規模分類識別任務。
鑒于卷積神經網絡自動學習特征的能力和適用二維圖像數據的特點,該文將嗓音樣本轉化為梅爾聲譜圖,將梅爾聲譜圖與深度學習相結合用于藝術嗓音評價,使嗓音評價問題轉化為圖像分類問題,為藝術嗓音客觀評價提供了一種新思路和新方法,經實驗證明該方法的準確率優于傳統方法。
1 研究方法
可采用時域和頻域兩種不同方法對一段語音進行分析,但若單獨分析的話,這兩種方法均有局限性。大量的理論與實驗研究表明,語音信號的發出過程是復雜的非線性過程,可認為由具有固有非線性動力學特性的系統產生。語音信號是時變信號,因此其頻譜會隨時間發生變化,而聲譜圖將語音信號隨時間變化的關系很好地表現出來,同時也獲得了語音信號的頻率變化。根據語音信號的短時平穩性,對其做短時傅里葉變換,展開得到的二維信號就是聲譜圖。
聲譜圖將語音信號的時、頻域信息在一張圖上綜合表現出來,對其進行研究,提取的圖像特征克服了傳統聲學單一的缺陷。通過對時、頻域的聯合分析,可以得到更多傳統聲學特征難以表征的語音信息,在語音識別領域也取得了很多有意義的成果[9-12]。
鑒于聲譜圖的廣泛應用和卷積神經網絡在圖像識別上的良好表現[13],該文擬將深度學習的方法用于嗓音評價,提高了分類準確率。
藝術嗓音客觀評價的傳統方法與該文所提方法如圖1 所示。

圖1 藝術嗓音客觀評價傳統方法與該文所提方法比較
2 梅爾聲譜圖的提取
聲波是一維的,無法直接看出頻率變化的規律,而聲譜圖解決了這個問題。再通過梅爾標度濾波器組將其轉換為梅爾聲譜圖,從而更好地將音頻信號的時域信息、頻域信息與能量信息表現出來。
在獲取藝術嗓音的音頻樣本之后,對樣本進行預處理,主要包括預加重、加窗、分幀等步驟[14]。一般通過傳遞函數為一階的FIR 高通數字濾波器來實現預加重,其傳遞函數如式(1)所示:

式中,μ為預加重系數,通常取0.98[15]。
分幀可以獲得音頻文件的短時平穩信號。相比于矩形窗和海寧窗,漢明窗的頻譜泄露最小[16],加窗處理就是讓每一幀信號都乘以漢明窗函數。加窗處理過程如式(2)所示:

式中,S(n)表示原始信號,ω(n)表示所用的加窗函數。
漢明窗表達式如式(3)所示:

式中,wlen為幀長。
圖2 和圖3 隨機選取了樣本庫中評價較差和評價較好的嗓音樣本的波形圖和梅爾聲譜圖。
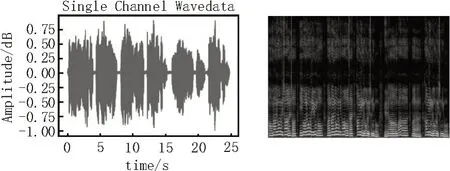
圖2 評價結果較差的嗓音波形圖和梅爾聲譜圖

圖3 評價結果較好的嗓音波形圖和梅爾聲譜圖
通過觀察梅爾聲譜圖可以發現,不同評價結果的嗓音樣本所對應的聲譜圖圖像風格迥異。借助于機器視覺領域的研究發現,對梅爾聲譜圖進行識別,從而將嗓音評價問題轉換為對圖像的分類。
3 卷積神經網絡參數優化
CNN 是一種帶有卷積結構的深度神經網絡[17]。卷積結構在有效減少網絡參數的同時,又緩解了模型的過擬合問題[18]。
考慮到梅爾聲譜圖含有時域、頻域、能量等多種信息的特性,在經過多次實驗與訓練后,對構建的卷積神經網絡進行了參數優化,并加入了數據增強模塊和Dropout 層,使得該網絡的損失值更小,訓練時間更短,在保證感受野的同時可有效提取細粒度特征。該文所構造的CNN 模型如圖4 所示。

圖4 CNN網絡模型參數
1)卷積層
卷積層用來識別圖像里的空間模式,如線條和物體局部。卷積運算可以提取并增強圖像特征的同時降低噪聲。該文構造的CNN 網絡含三個卷積層,分別包含32、32、64 個內核,卷積核大小均為3×3。為了解決梯度消失問題,在輸入層和隱藏層使用Relu 激活函數。
2)池化層
池化層進行降采樣,減少參數量的同時可以獲得平移和形變的魯棒性。相比于平均池化[19],最大值池化可以減少卷積層參數誤差造成估計均值的偏移,更多地保留紋理信息,故這里采用最大值池化。為將特征圖下采樣兩倍,該架構選擇了大小均為2×2的池化層,設置步幅為2。
3)全連接層
為減少特征信息的丟失,使用全連接層進一步加強特征。該實驗中含有兩個全連接層,它們的輸出個數分別為64 和1,其中,1 為輸出的類別個數。
相比于一般卷積神經網絡,該文添加了數據增強模塊,以此來增加數據特征的多樣性。采用幾何變換、顏色變換等隨機變換生成可信圖像,進行樣本擴增,這樣可在訓練模型的過程中獲取更深層次的特征,從而具有更強的泛化能力[20]。在Keras 中,通過對ImageDataGenerator 讀取的圖像執行多次隨機變換來實現數據增強。
同時為了進一步降低過擬合,在分類器之前添加一個Dropout 層,主要用于權重衰減,解決了分類器帶來的參數冗余的數值問題。
4 實驗與分析
4.1 實驗方法
目前,國內外并沒有開源的標準嗓音樣本庫用于研究,故在陜西師范大學音樂學院進行了建庫工作。該實驗所用嗓音樣本由陜西師范大學音樂學院聲樂專業研究生和本科生41 名同學錄制,其中男生15 名,女生26 名,近3 個月均無喉病及上呼吸道感染。嗓音樣本在陜西師范大學音樂學院錄音室錄制,錄音環境噪聲小于45 dB。錄制前對歌唱者進行培訓,演唱時口距麥克風10 cm,錄音前先進行發聲練習,同時有專業鋼琴演奏者進行伴奏,歌唱者重復多次演唱/a/、/i/、/o/音,直至達到穩定的演唱狀態,之后依次演唱《花非花》、《康定情歌》。計算機采樣頻率為48 kHz,16 bit量化,單聲道方式,數據存儲為wav格式。在歌曲錄制完畢之后,用Audacity 軟件逐一進行剪切,最終每個音頻時長為25 s。為驗證該文所提客觀評價方法的實用性,由五名音樂學院資深聲樂教師及聲樂專業研究生憑借豐富的聲樂知識和經驗,對樣本歌聲做出評價,嗓音樣本最終分為較好和較差兩類。
利用librosa 工具包,對語音樣本經過分幀、加窗和短時離散傅里葉變換處理得到聲譜圖,再通過梅爾標度濾波器組變換為梅爾聲譜圖。將得到的梅爾聲譜圖按照評價結果分為較好和較差兩類,同時按照8∶2劃分為訓練集和測試集。最后輸入搭建的CNN神經網絡中,設置迭代次數為500,在訓練集上訓練模型,調節參數,然后在測試集上評價模型結果。
4.2 結果分析
損失函數曲線如圖5 所示,從圖5 可以看出,損失函數的值隨迭代次數的增加逐漸減小,識別準確率如圖6 所示,從圖6 可以看出,準確率隨迭代次數的增加逐漸提高,經過多次實驗驗證,最終準確率平均可達95.5%。

圖5 測試集損失函數曲線

圖6 測試集識別準確率曲線
該文也利用傳統的評價方法,對該數據庫的音頻樣本提取基頻、第一、第三共振峰,分別輸入BP 神經網絡和SVM 支持向量機[21],得到分類結果,與利用卷積神經網絡建立的藝術嗓音客觀評價模型評價結果對比。單一歌曲《花非花》、《康定情歌》和兩首歌全體評價準確率如表1 所示。

表1 客觀評價分類準確率
從表1 可以看出,該文所提出的藝術嗓音客觀評價方法在單一歌曲和混合歌曲的評價中均具有良好的表現,優于傳統方法,為客觀高效地評估藝術嗓音提供了新視角。
5 結論
該文針對藝術嗓音客觀評價研究,提出了一種基于卷積神經網絡的評價方法。該方法將音頻信號轉化為梅爾聲譜圖,構建了多層CNN 神經網絡的深度學習模型并進行了參數優化,在此基礎上進行了嗓音分類研究,對藝術嗓音分類的準確率達到了95.5%,相比于BP 神經網絡和SVM 評價方法,分別提高了8.9%和16.9%。結果表明,以梅爾聲譜圖的圖像特征作為輸入的深度學習模型在藝術嗓音客觀評價任務上具有良好的表現,為客觀地評價藝術嗓音質量提供了一個新的思路,有助于科學準確地選拔和培養藝術嗓音人才。受實驗條件的限制,訓練數據不夠充分,未來將繼續擴充藝術嗓音樣本的數量,探索更加客觀、準確的評價方法。
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
讀者·校園版(2018年13期)2018-06-19 06:20:12
Coco薇(2016年2期)2016-03-22 16:58:59
Coco薇(2016年2期)2016-03-22 02:42:52
讀者(2016年7期)2016-03-11 12:14:36
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
爆笑show(2014年10期)2014-12-18 22:27:48
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
