雙匹配焦點(diǎn)融合的開(kāi)放域答案選擇模型
2023-01-27 08:28:32何俊飛張會(huì)兵胡曉麗
計(jì)算機(jī)工程 2023年1期
何俊飛,張會(huì)兵,胡曉麗
(1.桂林電子科技大學(xué) 廣西可信軟件重點(diǎn)實(shí)驗(yàn)室,廣西 桂林 541004;2.桂林電子科技大學(xué) 教學(xué)實(shí)踐部,廣西 桂林 541004)
0 概述
在當(dāng)前開(kāi)放域問(wèn)答(Question Answering,QA)系統(tǒng)中,一個(gè)問(wèn)題通常會(huì)有各種各樣的答案。簡(jiǎn)單高效地從眾多答案中擇取合理、高質(zhì)量的答案,同時(shí)排除無(wú)效、低質(zhì)量的答案對(duì)于問(wèn)答系統(tǒng)至關(guān)重要,也直接影響著系統(tǒng)的用戶體驗(yàn)。隨著大規(guī)模社區(qū)問(wèn)答平臺(tái)的興起,答案選擇問(wèn)題引起了越來(lái)越多研究人員的關(guān)注[1-3]。與通常的單語(yǔ)句分析任務(wù)相比,答案選擇任務(wù)的對(duì)象往往是兩個(gè)及兩個(gè)以上的句子,導(dǎo)致對(duì)輸入對(duì)象的語(yǔ)義抽取與表征變得更加困難。
以往研究大多基于概率統(tǒng)計(jì)的機(jī)器學(xué)習(xí)方法,主要關(guān)注點(diǎn)在于對(duì)問(wèn)答語(yǔ)句中各關(guān)系詞對(duì)的抽取和細(xì)節(jié)描述[4],忽略了問(wèn)答語(yǔ)句之間的整體語(yǔ)義與交互關(guān)系。近年來(lái),基于神經(jīng)網(wǎng)絡(luò)的深度學(xué)習(xí)方法得到廣泛應(yīng)用,研究人員提出多種端到端的答案選擇模型,減少了對(duì)特征工程的構(gòu)建[5-7]。隨著注意力機(jī)制的發(fā)展,研究人員提出將深度神經(jīng)網(wǎng)絡(luò)與注意力機(jī)制相結(jié)合的比較聚合模型,將語(yǔ)句的匹配、表征與交互融為一體,不僅突出語(yǔ)句本身需要表達(dá)的要點(diǎn),同時(shí)還提升了問(wèn)答語(yǔ)句之間的交互效果[8]。然而,現(xiàn)有研究大多只從詞級(jí)或者句子級(jí)中的單一層面將問(wèn)題與答案中的單詞進(jìn)行直接匹配,缺乏語(yǔ)義參照關(guān)系,導(dǎo)致?lián)p失一些可以捕捉的細(xì)節(jié)信息。比如對(duì)于問(wèn)句“吃蘋(píng)果?”與“吃蘋(píng)果或梨?”,兩個(gè)問(wèn)句都是動(dòng)賓結(jié)構(gòu),但回答卻完全不同,前者關(guān)注點(diǎn)完全落在動(dòng)詞上,而后者的關(guān)注點(diǎn)完全落在名詞上。由此可以發(fā)現(xiàn),單一層面的匹配可能會(huì)因?yàn)閷?duì)照關(guān)系的缺失導(dǎo)致語(yǔ)義匹配焦點(diǎn)的錯(cuò)位。
本文根據(jù)相鄰相似原理,提出一種雙匹配焦點(diǎn)融合的答案選擇模型(DMFF)。基于問(wèn)答任務(wù)多語(yǔ)句對(duì)象的特點(diǎn),設(shè)計(jì)一種專(zhuān)門(mén)用于答案選擇的詞嵌入方式,保留詞對(duì)在問(wèn)答語(yǔ)句間承接關(guān)系的更多細(xì)節(jié)信息,并以此計(jì)算詞級(jí)層面下的焦點(diǎn)矩陣。借鑒seq2seq 模型在語(yǔ)言翻譯[9-10]和閱讀理解[11-12]任務(wù)上的運(yùn)用方式,利用帶有注意力機(jī)制的Encoder-Decoder 翻譯模型提取句子級(jí)層面的詞對(duì)匹配,獲取問(wèn)答語(yǔ)句間的整體語(yǔ)義關(guān)系和對(duì)應(yīng)的焦點(diǎn)矩陣。最后,將兩個(gè)焦點(diǎn)矩陣對(duì)齊,計(jì)算問(wèn)句中每一個(gè)單詞在兩個(gè)矩陣中的相對(duì)距離,以此融合詞級(jí)與句子級(jí)匹配焦點(diǎn),獲得問(wèn)答對(duì)匹配分值。
1 相關(guān)工作
隨著開(kāi)放域問(wèn)答任務(wù)的興起,答案選擇得到了越來(lái)越多的研究。起初,主要通過(guò)概率統(tǒng)計(jì)的機(jī)器學(xué)習(xí)方法來(lái)構(gòu)建答案選擇模型。文獻(xiàn)[13]提出一種利用問(wèn)答連接依賴樹(shù)之間的操作代價(jià)來(lái)衡量問(wèn)答語(yǔ)句之間距離的方法,由于該方法引入了語(yǔ)法信息,因此比簡(jiǎn)單詞袋模型的效果更優(yōu)。文獻(xiàn)[14]發(fā)現(xiàn)外部資源對(duì)模型的性能影響很大,增強(qiáng)的詞匯語(yǔ)義信息可以提升答案選擇模型捕捉語(yǔ)句間關(guān)系的能力。而文獻(xiàn)[15]將邏輯回歸模型應(yīng)用于特征自動(dòng)提取,減少手工操作的成本。上述方法的建模方式僅依賴于詞匯關(guān)系,在效率和成本上存在顯著缺陷。基于神經(jīng)網(wǎng)絡(luò)的深度學(xué)習(xí)方法對(duì)問(wèn)題與答案的表征效果超越了多數(shù)基于概率統(tǒng)計(jì)的機(jī)器學(xué)習(xí)方法[4]。文獻(xiàn)[5]將問(wèn)題與答案連接成一個(gè)單詞序列串,然后利用長(zhǎng)短期記憶獲取序列串的特征,得到問(wèn)答語(yǔ)句的匹配值。文獻(xiàn)[6-7]將每一個(gè)詞匯展開(kāi)成詞向量后拼接成一個(gè)空間網(wǎng)格圖像,然后用卷積神經(jīng)網(wǎng)絡(luò)捕捉圖像之間的依賴程度。這些方法都不需要構(gòu)建外部資源庫(kù),且能夠從句子級(jí)層面對(duì)問(wèn)答語(yǔ)句間關(guān)系進(jìn)行匹配。多語(yǔ)句處理任務(wù)需要較高的語(yǔ)句間交互能力,注意力機(jī)制在突出語(yǔ)義表達(dá)的同時(shí),也可用于提取語(yǔ)句間的交互關(guān)系。針對(duì)答案選擇任務(wù),文獻(xiàn)[16]結(jié)合注意力機(jī)制提出多跳注意力網(wǎng)絡(luò)模型,多次利用順序注意力循環(huán)關(guān)注問(wèn)題與答案中的不同話題點(diǎn),并計(jì)算每一個(gè)話題下問(wèn)答特征向量的相似度,然后對(duì)所有話題求和,得到最終的問(wèn)答匹配得分。之后,在上述工作基礎(chǔ)上,大部分學(xué)者以比較聚合模型為基礎(chǔ)框架,分別就注意力機(jī)制[17]、聚合方式[18]、語(yǔ)素匹配[19]和交互模式[20]提出更加新穎的方法,其中文獻(xiàn)[20]從單句、句對(duì)和句子列表3 個(gè)層級(jí)充分挖掘問(wèn)答的交互信息,并將3 個(gè)層級(jí)上的信息進(jìn)行融合得到最后的匹配分值。
隨著詞嵌入方式在自然語(yǔ)言處理中的成功運(yùn)用,利用預(yù)訓(xùn)練方法改進(jìn)模型成為一種趨勢(shì)。文獻(xiàn)[21]用分布式模型構(gòu)建單詞之間在局部語(yǔ)境中的表示關(guān)系,并以此得到一個(gè)單詞對(duì)應(yīng)的唯一向量表示。文獻(xiàn)[22]利用一個(gè)局部到全局的轉(zhuǎn)移矩陣增強(qiáng)詞向量的全局語(yǔ)境特性。文獻(xiàn)[23-24]結(jié)合上下文對(duì)單詞進(jìn)行語(yǔ)境化嵌入,根據(jù)上下文語(yǔ)境的變化對(duì)同一單詞用不同的向量表示。相對(duì)來(lái)說(shuō),后面兩種方法在預(yù)訓(xùn)練模型中更具優(yōu)勢(shì)。文獻(xiàn)[25]利用Bert模型,使答案選擇任務(wù)效果達(dá)到了現(xiàn)階段最優(yōu)。
2 本文模型
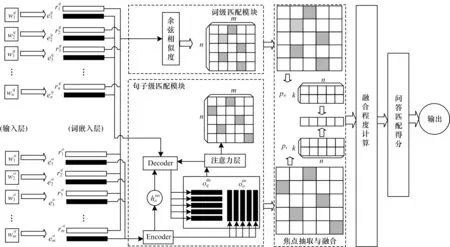
圖1 本文模型的整體結(jié)構(gòu)Fig.1 Overall structure of model in this paper
2.1 詞級(jí)匹配模塊
詞級(jí)匹配是直接通過(guò)詞嵌入向量進(jìn)行詞對(duì)余弦相似度匹配,其對(duì)應(yīng)的詞級(jí)匹配模塊就是對(duì)問(wèn)題中的每一個(gè)單詞與答案中的每一個(gè)單詞進(jìn)行匹配,得到匹配焦點(diǎn)分布矩陣。為滿足問(wèn)答任務(wù)的需要,提出一種基于問(wèn)題-正負(fù)答案對(duì)(Question to Positive and Negative Answer Pair,Q-PNAP)的詞嵌入方式,如圖2 所示。
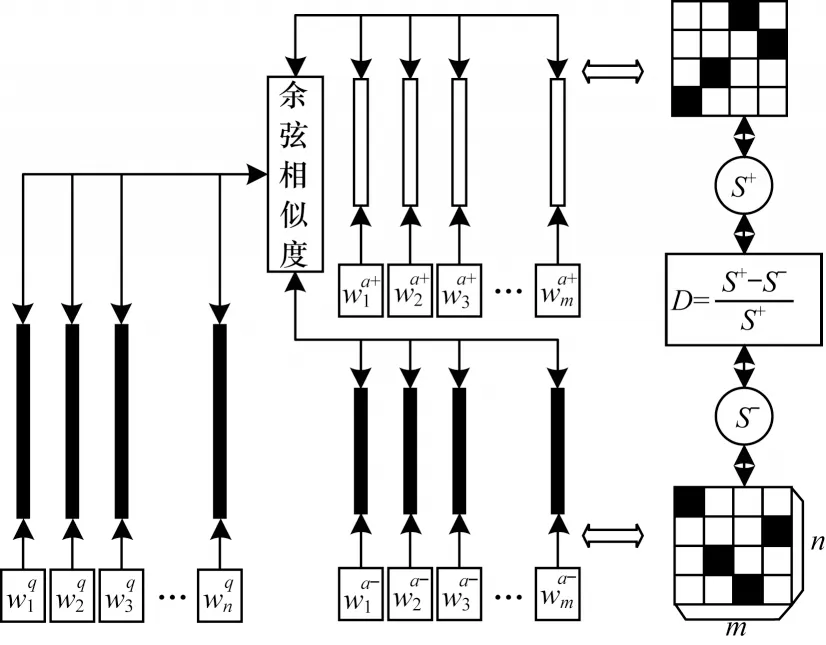
圖2 問(wèn)題-正負(fù)答案對(duì)詞嵌入的示意圖Fig.2 Schematic diagram of question to positive and negative answer pair word embedding
首先對(duì)問(wèn)答語(yǔ)句中的每一個(gè)單詞隨機(jī)初始化一組向量。表示對(duì)問(wèn)題中的第i(1 ≤i≤n)個(gè)單詞進(jìn)行隨機(jī)向量初始化,表示對(duì)答案中的第j(1 ≤j≤m)個(gè)單詞進(jìn)行隨機(jī)向量初始化。初始化后問(wèn)題中的第i個(gè)單詞與答案中的第j個(gè)單詞所對(duì)應(yīng)詞對(duì)的詞性相關(guān)程度sr(i,j)表達(dá)式如式(1)所示:

由于問(wèn)題中的每一個(gè)單詞與答案中的單詞不存在一一對(duì)應(yīng)關(guān)系,所以答案中可能會(huì)有多個(gè)單詞同時(shí)與問(wèn)題中的同一個(gè)單詞產(chǎn)生關(guān)聯(lián),這時(shí)本文用K代表抽取出的詞對(duì)個(gè)數(shù)。即取出問(wèn)題中各單詞對(duì)應(yīng)答案中的前K個(gè)與之最相關(guān)的單詞,并將這K個(gè)詞對(duì)的詞性相關(guān)程度大小之和作為對(duì)應(yīng)單詞的匹配得分其表達(dá)式如式(2)所示:
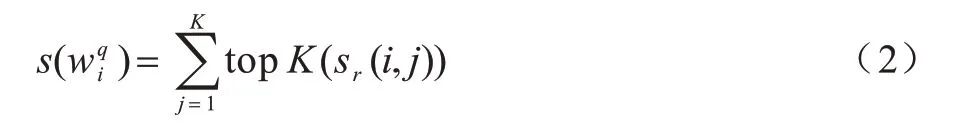
其中:topK(X)表示取出X數(shù)組中由大到小排序的前K個(gè)值。對(duì)問(wèn)題中所有單詞的匹配得分進(jìn)行求和,得到問(wèn)答對(duì)(q,a)的最終匹配得分S(q,a),其表達(dá)式如式(3)所示:

由于初始時(shí)刻隨機(jī)初始化的詞嵌入表示中不包含任何單詞的語(yǔ)法語(yǔ)義信息,故需要結(jié)合問(wèn)答語(yǔ)句訓(xùn)練出一組合適的詞嵌入表示。對(duì)同一個(gè)問(wèn)題q選取一對(duì)答案,其中一個(gè)是正確答案a+,另一個(gè)是與問(wèn)題相關(guān)的同領(lǐng)域內(nèi)的錯(cuò)誤答案a-,此時(shí)的問(wèn)答組合可以用一個(gè)三元組(q,a+,a-)表示,利用式(4)和式(5)分別計(jì)算在當(dāng)前隨機(jī)詞嵌入表示情況下的問(wèn)答匹配得分情況。
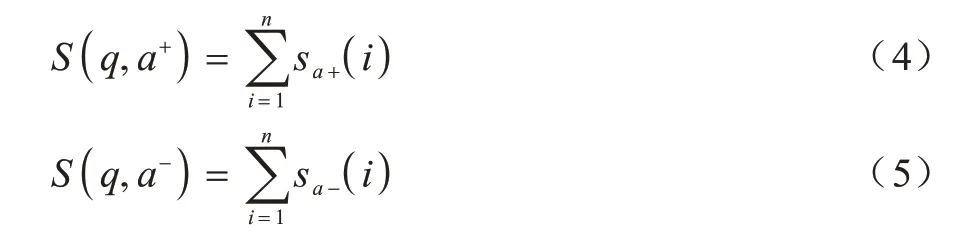
在前提假設(shè)下有:

定義一個(gè)D值表示同一問(wèn)題下正確答案與錯(cuò)誤答案的相離程度,如式(7)所示:
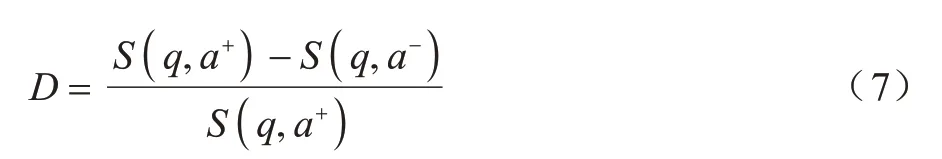
D值的合理取值區(qū)間為(0,1),當(dāng)D 值超出此區(qū)間時(shí),表示出現(xiàn)異常。當(dāng)D值趨近于1 時(shí),表示正確答案與錯(cuò)誤答案相離程度最大,越符合實(shí)際情況。訓(xùn)練問(wèn)題-正負(fù)答案對(duì)詞嵌入表示模型的損失函數(shù)l(q,a+,a-)如式(8)所示:
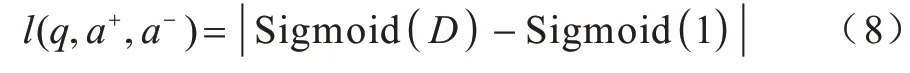
為防止異常情況導(dǎo)致?lián)p失函數(shù)輸出過(guò)大或者過(guò)小的值,在式(8)中引入Sigmoid 函數(shù)對(duì)相離距離進(jìn)行輸出為(0,1)的規(guī)范化處理。
2.2 句子級(jí)匹配模塊
句子級(jí)詞對(duì)匹配是通過(guò)理解問(wèn)題與答案之間的上下文銜接關(guān)系之后,計(jì)算問(wèn)題中各單詞與答案中各單詞的匹配關(guān)系。該模塊選取了帶有注意力層的Encoder-Decoder 翻譯模型來(lái)完成句子級(jí)詞對(duì)匹配。Encoder 與Decoder 分別對(duì)答案和問(wèn)題進(jìn)行編碼后輸入注意力層,注意力層對(duì)輸入的編碼向量從語(yǔ)義層面上進(jìn)行篩選和匹配,最終通過(guò)一個(gè)注意力矩陣保留問(wèn)題在答案中的匹配焦點(diǎn)分布。具體步驟如下:
首先對(duì)輸入的答案用BiGRU 進(jìn)行編碼,得到答案的編碼矩陣與特征向量,表達(dá)式如式(9)所示:
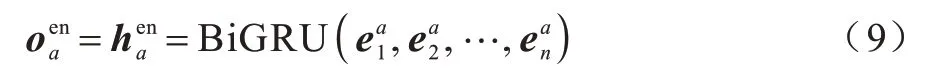
其中:為答案的第n個(gè)詞嵌入向量,將編碼器輸出的編碼矩陣與特征向量分別通過(guò)2 個(gè)全連接層將原來(lái)的編碼狀態(tài)過(guò)渡到解碼狀態(tài),該過(guò)程的表達(dá)式如下:


此時(shí)已經(jīng)得到句子級(jí)層面的詞對(duì)匹配焦點(diǎn)分布,不過(guò)為了訓(xùn)練參數(shù)與,還需要利用解碼器的解碼輸出與真實(shí)問(wèn)題進(jìn)行損失值計(jì)算。答案在編碼狀態(tài)的編碼矩陣經(jīng)過(guò)注意力層后變?yōu)閱?wèn)題在編碼狀態(tài)下的編碼矩陣,表達(dá)式如式(14)所示:

連接問(wèn)題編碼狀態(tài)與解碼狀態(tài)下的狀態(tài)矩陣與,在經(jīng)過(guò)兩層全連接層后得到答案的解碼輸出wout,表達(dá)式如式(15)所示:

其中:為解碼預(yù)測(cè)出第i個(gè)單詞在詞典中各單詞的取值大小;pi為真實(shí)答案中第i個(gè)單詞在字典中的位置。
2.3 問(wèn)答詞對(duì)篩選與融合層
通過(guò)上述2 個(gè)焦點(diǎn)匹配模塊分別得到詞級(jí)焦點(diǎn)分布矩陣sw∈Rn×m,其中sw矩陣第i行第j列的元素為=sr(i,j)。句子級(jí)焦點(diǎn)分布矩陣ss∈Rn×m,其中ss矩陣第i行第j列的元素為。對(duì)兩個(gè)匹配焦點(diǎn)矩陣中的元素進(jìn)行抽取與融合。首先,對(duì)問(wèn)題中的某一個(gè)單詞,選取答案中與其最相關(guān)的前K個(gè)單詞,同時(shí)記錄下這K個(gè)單詞在答案句子中的位置。對(duì)于詞級(jí)匹配問(wèn)題中的每一個(gè)單詞,在答案中,根據(jù)相關(guān)程度由高到低記錄前K個(gè)最佳匹配單詞的位置,如式(17)所示:

其中:topKp(X)表示取數(shù)組X中前K個(gè)最大值所在的位置。同理,對(duì)于句子級(jí)匹配問(wèn)題中的每一個(gè)單詞,在答案中根據(jù)相關(guān)程度由高到低記錄前K個(gè)最佳匹配單詞的位置如下:

無(wú)論是詞級(jí)匹配還是句子級(jí)匹配,由相鄰相似的原理可知,對(duì)于問(wèn)題中的同一個(gè)單詞,2 個(gè)視角匹配下的焦點(diǎn)位置應(yīng)盡可能相鄰。融合詞級(jí)與句子級(jí)匹配的結(jié)果,定義兩者的融合誤差如下:
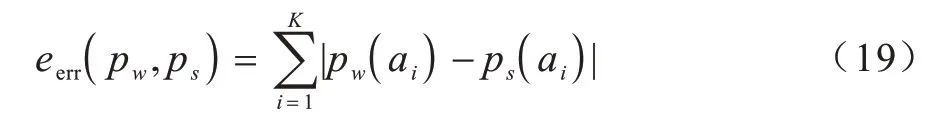
最終得到整個(gè)問(wèn)答對(duì)的匹配得分情況:
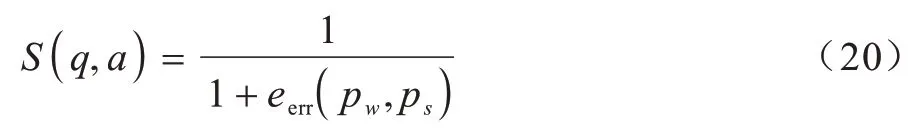
其中:S(q,a)為一個(gè)(0,1)之間的數(shù)。對(duì)于同一個(gè)問(wèn)題,當(dāng)S(q,a)為1 時(shí)說(shuō)明匹配的情況最理想,問(wèn)題與答案最相關(guān),當(dāng)S(q,a)趨近于0 時(shí),說(shuō)明eerr(pw,ps)越大,問(wèn)題與答案越不匹配。
3 實(shí)驗(yàn)結(jié)果與分析
3.1 實(shí)驗(yàn)數(shù)據(jù)集及評(píng)估指標(biāo)
本文選取了3個(gè)公開(kāi)的問(wèn)答數(shù)據(jù),包括Yahoo!Answer、TREC-QA[26]和Wiki-QA[27],3 個(gè)數(shù)據(jù)集的基本信息如表1 所示,其中帶“*”的數(shù)據(jù)集剔除了全為負(fù)面答案的問(wèn)題,“—”表示無(wú)此項(xiàng)內(nèi)容。
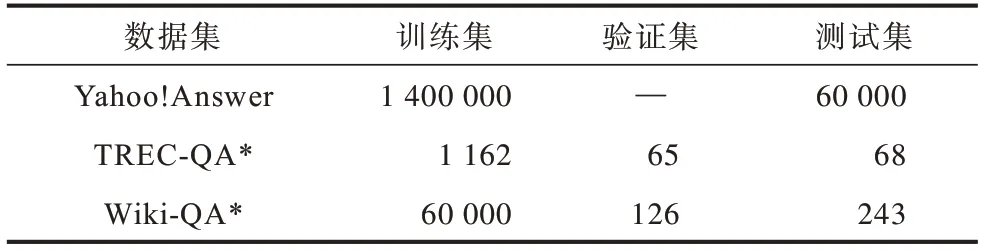
表1 數(shù)據(jù)集信息Table1 Dataset information
對(duì)于Yahoo!Answer 問(wèn)答數(shù)據(jù)集來(lái)說(shuō),由于每一個(gè)問(wèn)題有且只有一個(gè)最佳答案,因此為滿足本次實(shí)驗(yàn)的需要,將每一個(gè)問(wèn)題在其同領(lǐng)域下選取一個(gè)否定答案與原來(lái)的最佳答案構(gòu)成一個(gè)正負(fù)答案對(duì)。
實(shí)驗(yàn)的評(píng)估指標(biāo)采用平均準(zhǔn)確率均值(mean Average Precision,mAP)和平均倒數(shù)排 名(Mean Reciprocal Rank,MRR),具體如下:
1)mAP,指所有問(wèn)題的平均準(zhǔn)確率均值。對(duì)于每一個(gè)問(wèn)題的平均準(zhǔn)確率,表達(dá)式如式(21)所示:
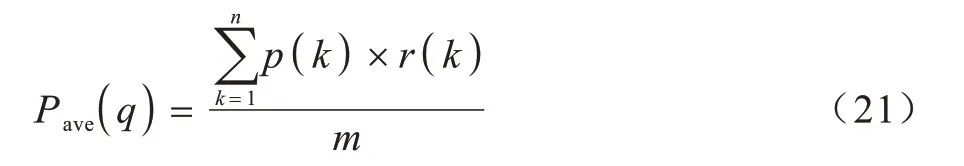
p(k)的表達(dá)式如式(22)所示:
其中:i=1,2,…,m;j=1,2,…,n;q代表單個(gè)問(wèn)題;n代表單個(gè)問(wèn)題下所有候選答案;m代表正確的答案?jìng)€(gè)數(shù);r(k)的取值為0 或1,當(dāng)?shù)趉個(gè)候選答案是正確答案時(shí),r(k)=1,否則r(k)=0。最終的mAP 表達(dá)式如式(23)所示:

當(dāng)所有正確答案都在錯(cuò)誤答案之前時(shí),mAP 接近于1,當(dāng)每個(gè)問(wèn)題對(duì)應(yīng)的所有正確答案都在錯(cuò)誤答案之后時(shí),mAP 接近于0。
2)MRR,指所有問(wèn)答對(duì)在模型給出的位置排名列表中,第1 次出現(xiàn)相關(guān)答案位置倒數(shù)的平均值,表達(dá)式如式(24)所示:

3.2 實(shí)驗(yàn)環(huán)境
本文實(shí)驗(yàn)在Intel?CoreTMi5-9400@2.90 GHz 6 核CPU、24 GB 內(nèi)存,6 GB 內(nèi)存的Nividia GeForce GTX 1660 Ti GPU 上完成。預(yù)訓(xùn)練部分采用6B 版本的100 維GLoVe 詞向量模型進(jìn)行初始化詞嵌入,Bert則直接使用在pytorch 框架下訓(xùn)練好的bert-largeuncased 模型。對(duì)于訓(xùn)練模型,采用自適應(yīng)矩陣估計(jì)(adam)優(yōu)化器更新參數(shù),學(xué)習(xí)率設(shè)置為0.001,基于問(wèn)答的詞嵌入表示訓(xùn)練,Batch_size 設(shè)置為128,句子級(jí)匹配模塊的訓(xùn)練采用Batch_size=64,當(dāng)利用循環(huán)神經(jīng)網(wǎng)絡(luò)模型處理數(shù)據(jù)時(shí),其隱藏層的大小均設(shè)置為128,其余參數(shù)為默認(rèn)值。
3.3 不同詞嵌入方法的對(duì)比
由于詞級(jí)匹配是直接通過(guò)預(yù)訓(xùn)練好的詞嵌入向量計(jì)算詞對(duì)之間的相關(guān)程度,因此不同的詞嵌入方法對(duì)詞對(duì)相關(guān)性的計(jì)算存在一定的影響。圖3 分別給出了在GLoVe 詞嵌入方法、Bert 詞嵌入方法與本文所提詞嵌入方法Q-PNAP 在Yahoo!Answer 測(cè)試集上的預(yù)測(cè)精度。
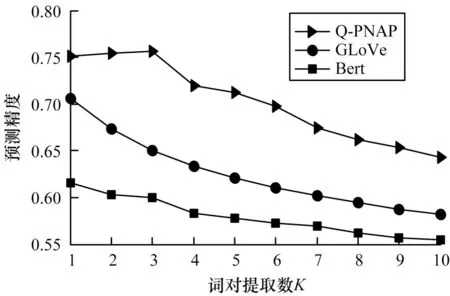
圖3 不同詞嵌入方法的預(yù)測(cè)精度對(duì)比Fig.3 Prediction accuracy comparison of different word embedding methods
由圖3 可知,與其他方法相比,利用Q-PNAP 方法訓(xùn)練出的詞嵌入表示預(yù)測(cè)精度最高,而利用Bert方法訓(xùn)練出的詞嵌入表示預(yù)測(cè)精度最低。此外,隨著篩選閾值K的增大,Q-PNAP 方法在K=3 時(shí)精度預(yù)測(cè)達(dá)到頂峰,表示一個(gè)問(wèn)句中的單詞平均可以與答案中3 個(gè)單詞產(chǎn)生關(guān)聯(lián)。而另外兩種嵌入方法,其預(yù)測(cè)精度均隨著K值的增大一直下降,這表明利用GLoVe 或者Bert 方法進(jìn)行詞嵌入表示時(shí),問(wèn)題中各單詞平均僅與答案中的一個(gè)單詞產(chǎn)生關(guān)聯(lián),說(shuō)明以往僅利用單語(yǔ)境進(jìn)行詞嵌入的方式無(wú)法將問(wèn)題與答案的承接關(guān)系保留,導(dǎo)致無(wú)法捕捉到這種聯(lián)系的細(xì)節(jié)信息。
表2 所示為GLoVe 詞嵌入方法與Q-PNAP 詞嵌入方法訓(xùn)練出的詞嵌入表示在3 個(gè)單詞上的案例展示,對(duì)比可以發(fā)現(xiàn),GLoVe 詞嵌入方法得到的相似性單詞是與之對(duì)應(yīng)的近義詞,而利用Q-PNAP 詞嵌入方法得到的相似性單詞,是具有問(wèn)題承接關(guān)系的詞匯。

表2 兩種詞嵌入方法獲取近義詞的結(jié)果對(duì)比Table 2 Results comparison of two word embedding methods to obtain synonyms
為對(duì)比不同詞嵌入方法對(duì)句子級(jí)語(yǔ)義挖掘的影響,使用在當(dāng)前答案選擇任務(wù)中注意力機(jī)制使用效果較好的多跳注意力網(wǎng)絡(luò)模型,驗(yàn)證不同詞嵌入方法在Yahoo!Answer 測(cè)試集上識(shí)別正確答案的效果,結(jié)果如圖4 所示。從圖4 可以看出,GLoVe 方法的預(yù)測(cè)精度比Q-PNAP 方法的預(yù)測(cè)精度更高。
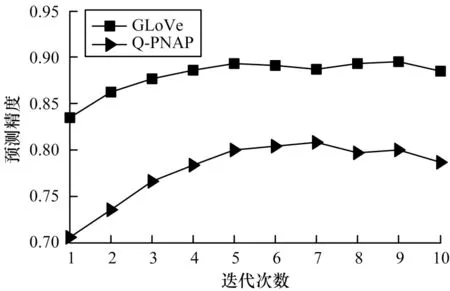
圖4 不同詞嵌入方法對(duì)句子級(jí)語(yǔ)義挖掘的影響Fig.4 Impact of different word embedding methods on sentence-level semantic mining
3.4 實(shí)驗(yàn)結(jié)果對(duì)比
由于詞對(duì)的篩選個(gè)數(shù)對(duì)最后的焦點(diǎn)融合會(huì)產(chǎn)生一定的影響,為尋找最優(yōu)的詞對(duì)篩選個(gè)數(shù),本文依次選取1~10 的整數(shù)作為抽取詞對(duì)的個(gè)數(shù)K,驗(yàn)證模型性能與K值的關(guān)系。同時(shí),為驗(yàn)證詞級(jí)匹配在不同詞嵌入形式下對(duì)整個(gè)模型效果的影響,在上文的驗(yàn)證結(jié)果下,選取GLoVe-GLoVe 和Q-PNAP-GLoVe 兩種詞嵌入組合方法,具體如下:
1)GLoVe-GLoVe 詞嵌入組合方法。該組合方法中詞級(jí)匹配利用GLoVe 詞嵌入形式,句子級(jí)匹配也利用GLoVe 詞嵌入形式。
2)Q-PNAP-GLoVe 詞嵌入組合方法。該組合方法中詞級(jí)匹配利用Q-PNAP 詞嵌入形式,句子級(jí)匹配利用GLoVe 詞嵌入形式。
實(shí)驗(yàn)結(jié)果如圖5 和圖6 所示。
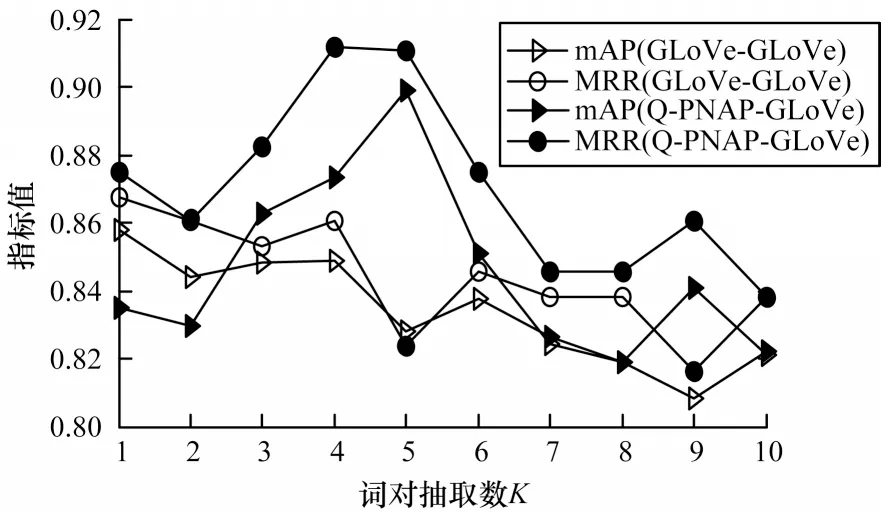
圖5 不同詞嵌入組合方法在TREC-QA 數(shù)據(jù)集下的測(cè)試結(jié)果Fig.5 Test results of different word embedding combining methods under TREC-QA dataset
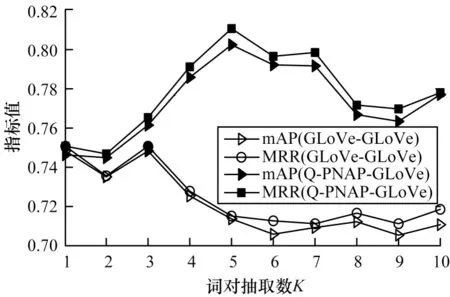
圖6 不同詞嵌入組合方法在Wiki-QA 數(shù)據(jù)集下的測(cè)試結(jié)果Fig.6 Test results of different word embedding combining methods under Wiki-QA dataset
從圖5 與圖6 可以看到,Q-PNAP-GLoVe 組合方法在總體效果上優(yōu)于GLoVe-GLoVe 組合方法。GLoVe-GLoVe 組合方法的整體趨勢(shì)隨著選取詞對(duì)個(gè)數(shù)K的增大,模型性能降低。而Q-PNAP-GLoVe組合方法在2 個(gè)數(shù)據(jù)集上的驗(yàn)證結(jié)果均呈現(xiàn)單峰趨勢(shì),這說(shuō)明Q-PNAP-GLoVe 組合方法可以捕捉到一個(gè)問(wèn)答對(duì)中更多關(guān)聯(lián)詞,從而使模型性能更優(yōu)。問(wèn)答語(yǔ)句間具有關(guān)聯(lián)效應(yīng)的詞對(duì)個(gè)數(shù)也有上限,在抽取詞對(duì)個(gè)數(shù)K=5 時(shí),模型效果最好。
表3 與表4 分別為本文模型在TREC-QA 與Wiki-QA 兩個(gè)答案選擇公開(kāi)數(shù)據(jù)集上與其他模型的對(duì)比結(jié)果。可以看到,本文模型在2 個(gè)數(shù)據(jù)集上的mAP 值均有明顯提高。在TREC-QA 數(shù)據(jù)集上,本文模型對(duì)比多跳注意力網(wǎng)絡(luò)模型[16]和層級(jí)排序模型[20],其mAP 值分別提高了0.086 1 與0.057 1,在Wiki-QA 數(shù)據(jù)集中,其提升幅度也分別達(dá)到了0.080 1與0.060 1。這說(shuō)明對(duì)同一問(wèn)題的所有答案進(jìn)行排序時(shí),融合了詞級(jí)與句子級(jí)匹配焦點(diǎn)的模型可以增強(qiáng)問(wèn)答語(yǔ)句間的信息抽取能力,捕捉到問(wèn)題與答案之間更多的關(guān)聯(lián)信息,能夠區(qū)分答案之間具有的細(xì)微差別,而現(xiàn)有的注意力機(jī)制模型和融合了多層級(jí)句子語(yǔ)義的比較聚合模型無(wú)法做到。本文模型在MRR 指標(biāo)上與多跳注意力[16]和層級(jí)排序[20]兩種基線模型相比也有所提高,在Wiki-QA 數(shù)據(jù)集上的提升效果比TREC-QA 數(shù)據(jù)上的提升效果更明顯,在TREC-QA 數(shù)據(jù)集上分別提升了0.017 6 與0.006 6,說(shuō)明從兩個(gè)層次對(duì)問(wèn)答語(yǔ)句進(jìn)行匹配可以增強(qiáng)模型對(duì)問(wèn)答整體語(yǔ)義的理解能力。以上結(jié)果驗(yàn)證了本文模型在最佳答案選擇上的有效性和可行性。
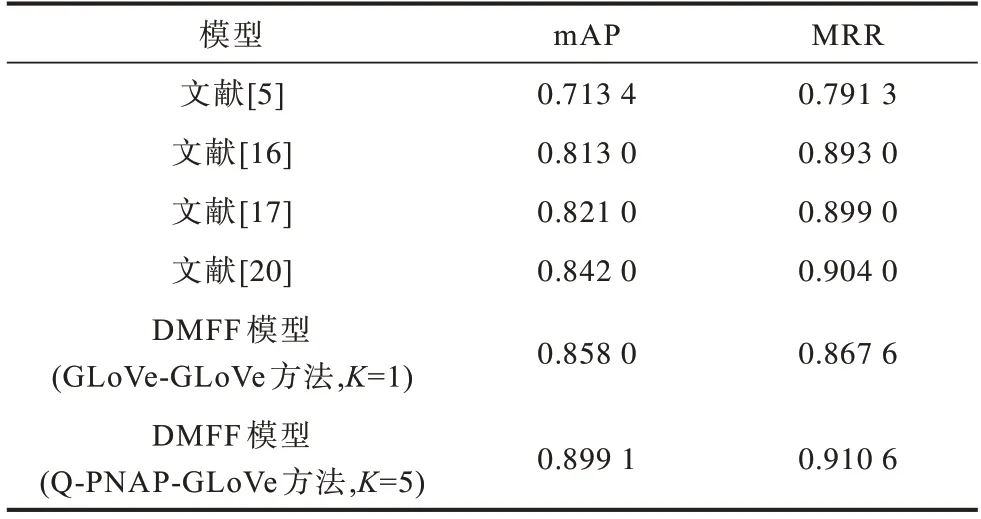
表3 不同模型在TREC-QA 數(shù)據(jù)集下的實(shí)驗(yàn)結(jié)果對(duì)比Table 3 Comparison of experimental results of different models under TREC-QA dataset
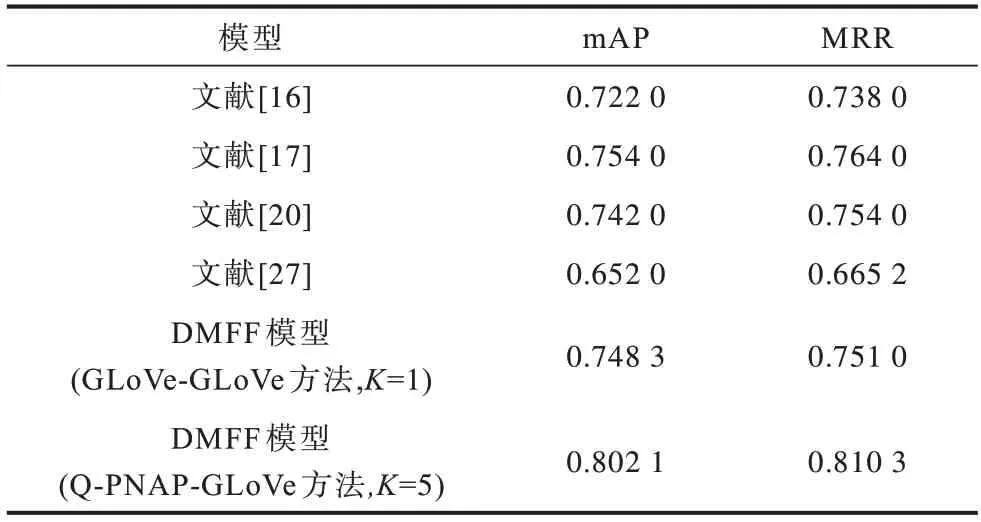
表4 不同模型在Wiki-QA 數(shù)據(jù)集下的實(shí)驗(yàn)結(jié)果對(duì)比Table 4 Comparison of experimental results of different models under Wiki-QA dataset
4 結(jié)束語(yǔ)
本文提出一種融合詞級(jí)與句子級(jí)雙層次匹配焦點(diǎn)的答案選擇模型。結(jié)合問(wèn)答任務(wù)的特點(diǎn)設(shè)計(jì)一種利用問(wèn)題與正負(fù)答案對(duì)訓(xùn)練詞向量的方式,以提高詞級(jí)層面的匹配精度。利用帶有注意力機(jī)制的翻譯模型捕捉句子級(jí)的問(wèn)答詞對(duì)匹配,并將2 個(gè)匹配結(jié)果對(duì)齊計(jì)算相對(duì)距離,得到問(wèn)答語(yǔ)句的相關(guān)性得分。實(shí)驗(yàn)結(jié)果表明,雙層面匹配結(jié)果的對(duì)照融合提高了模型識(shí)別答案之間微小差別的能力,增強(qiáng)了模型對(duì)問(wèn)答語(yǔ)句間關(guān)系的捕捉能力。與多跳注意力、層級(jí)排序等模型相比,本文模型在TREC-QA與Wiki-QA 公開(kāi)問(wèn)答數(shù)據(jù)集上的mAP 指標(biāo)均具有較高幅度的提升,MRR 指標(biāo)也有小幅提升。下一步將使用答案列表替換答案對(duì),并將Bert 模型融合到句子級(jí)的匹配,以提高問(wèn)答語(yǔ)句整體語(yǔ)義的捕捉抽取能力。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
閱讀(快樂(lè)英語(yǔ)高年級(jí))(2020年8期)2020-01-08 02:21:16
智慧少年·故事叮當(dāng)(2018年11期)2018-05-14 11:48:18
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
七彩語(yǔ)文·低年級(jí)(2011年19期)2011-04-12 00:00:00
