基于用電大數據的低壓電力客戶電費異常識別模型
2023-01-30 13:41:58何小宇董禮賢
微型電腦應用 2022年12期
關鍵詞:模型
何小宇, 董禮賢
(廣東電網有限公司廣州供電局, 廣東, 廣州 510000)
0 引言
供電局采集用電數據數量較多,廣州電網每日采集數據高達百萬余條。隨著數據規模飛速增長,由于設備故障和電網波動等原因,導致用戶電費異常數據時有發生,影響廣東電網公司的運營管理[1]。在電力市場競爭日益加劇的現狀下,部分低壓電力用戶為了自身利益采用一些惡劣手段竊取電源、拖欠電費等,嚴重影響了電力企業的正常工作運行,增加電力企業排查電量的成本[2]。為此,該領域相關研究人員進行了大量的研究。
文獻[3]提出通過模糊聚類和孤立森林的用電數據異常檢測。該方法針對電量數據規模、維度等,對電量數據進行預處理。通過模糊聚類算法,將電網中規模較大的異常數據進行分類,并通過孤立森林算法對異常用電量進行檢測,分析電量異常點的產生原因,進而實現用戶電費異常的識別。該方法可有效識別用戶電力數據中的異常點,但該方法針對異常電量數據集中的數據點規模較小,不利于大規模異常點電費的識別。文獻[4]提出通過熵序列的智能電網數據流異常狀態監測方法,對用戶電費異常情況進行識別。該方法通過采集智能電網中的相關數據流,確定一個窗口,對窗口的強度進行分析,通過其強度確定數據的異常情況。將判斷后得到的異常電量數據作為研究樣本,對其進行實時監測,完成用戶電費的識別。該方法可有效判定用戶電量是否異常,但對此類數據進行檢測易出現以偏概全的問題,導致識別的誤差較大。文獻[5]提出基于三次指數平滑模型與DBSCAN聚類的電量數據異常檢測方法,通過該方法檢測電力用戶電費異常情況。該方法首先采用三次指數平滑模型采集用戶歷史電費數據,將實際采集的電量值和預測值相減得到殘差值,最后借助DBSCAN密度聚類算法將殘差項進行識別,完成電費異常行為的識別。該方法可有效提升電量異常數據檢測的精度,但操作過程中抗干擾能力較差,需要進一步改進。
為了解決傳統方法中存在的不足,本文以廣東電網有限公司廣州供電局為例,設計基于用電大數據的低壓電力客戶電費異常識別模型。通過對用電大數據挖掘,為電費識別提供大量有效信息支撐,提高廣州低壓電力客戶電費異常識別精度。實驗結果表明:采用本文所提方法可有效識別用戶電費異常情況,且識別速度較快。
1 低壓電力客戶電費異常識別模型設計
1.1 低壓電力用戶用電大數據的獲取
為實現低壓電力客戶電費異常的識別,挖掘用電大數據中低壓電力客戶用電數據。由于用電數據量規模較大,故僅保留負荷數據和數據采集等字段,數據集字段詳情,如表1 所示。
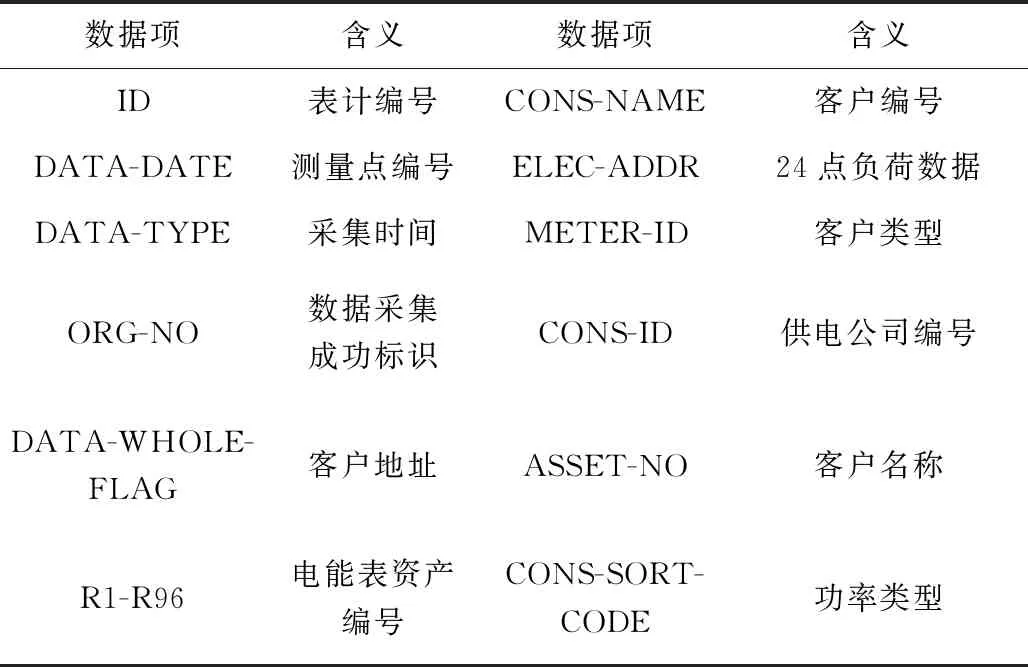
表1 低壓電力客戶用電大數據集
通過供電局負控終端采集的負荷數據,獲取供電局日負荷數據,繪制n條日負荷曲線,將負荷數據精簡為24點負荷數據,得到n×24階初始負荷曲線矩陣,構成用電大數據集。
刪除數據集中冗余數據,將客戶名稱和采集時間作為唯一確定的數據記錄,刪除具有相同記錄的多余數據。判斷缺失數據的嚴重程度,將日負荷曲線缺失20%的讀數點,連續缺失2個以上的連續讀數點定義為數據集數據嚴重缺失。采用多階拉格朗日內插法,對日負荷曲線的缺失值進行修補[6],即:
(1)
式中,P為日負荷曲線的修補負荷值,m1為拉格朗日前推期數,m2為后推期數,t為負荷數據缺失時刻,Wt為t時刻時,n×24階初始負荷曲線矩陣中的有效日負荷曲線[7]。
1.2 低壓電力客戶電費異常識別特征參數
由于低壓電力客戶用電數據集中數據較多,需要確定其中重要異常數據,獲取用電數據關鍵特征。對基礎數據進行降維,挖掘數據集中用電數據與電費識別的關聯關系。利用流聚類技術設置閾值,選取用電數據集中初始簇的中心,計算用電數據到簇中心點的距離,選取小于閾值且靠近簇中心的用電數據作為數據集族簇,對其進行更新迭代[8]。更新族簇的公式為
(2)
式中,ci+1為更新迭代后的數據集族簇,i為更新迭代次數,ci為前一次計算得到的初始族簇,ni為當前批次加入族簇的點數量,ki為已經分配到族簇的點數,hi為當前批次的族簇中心,a為用電數據更新迭代的衰減因子。
通過式(2),得到低壓電力客戶數據集中最好的聚類結果。選取關聯關系最大的用電數據點。聚集閾值內數據點到更新族簇,采用平方和誤差最小函數,獲得具有關聯關系的目標函數,對目標函數進行更新,直到目標函數收斂。目標函數為
(3)
式中,E代表具有關聯關系的目標函數,Q為數據集X中各個數據點,j為族簇的個數,γ為數據集中族簇的總數量,bj為j個族簇的平均值,V為特征參數的平方誤差和[9]。將含有關聯關系的集合E放于n維空間中,使每個維度空間具有完整的用電數據集,從中選取1個最近鄰點,如圖1所示。

圖1 用電特征數據選擇
圖1中,對4個最近鄰點進行加權,獲得與電費識別關聯關系最大的數據點,將數據值補充到n維空間的原點位置,得到最大關聯特征用電數據。
1.3 低壓電力客戶電費異常識別模型構建
在低壓用電客戶電費異常識別中,對n維空間中所有電力特征參數進行處理。設用電特征參數總數量為α,每個用電參數在識別時間點β得到一個時間序列,則模型運行參數構成的時間序列矩陣Oα×β為
(4)
當時間序列矩陣中行數α小于β時,按維度空間的順序拆分用電特征參數的時間序列,逐行疊加生成高維隨機矩陣,將矩陣各列作為提取維數的單個個體,將高維隨機矩陣轉換為樣本協方差矩陣。利用最大似然估計法,近似估計所得矩陣,將樣本協方差矩陣中特征值映射到復數域,得到用電數據特征值分布規律[10],為
(5)
式中,M為樣本協方差矩陣的行數,N為矩陣列數,d為矩陣中滿足均值的復隨機變量,σ2為矩陣方差,f為模型運行參數特征值的分布規律。
針對用電數據特征值分布規律,確定用電數據典型特征,需要滿足以下約束條件,即:
(6)
式中,si代表用電特征值中的典型特征量。
當用電數據滿足上述約束條件后,將用電特征量匹配后剩余的數據根據式(7)進行分解,得到用電特征量分布狀態為
Y=〈Yl,si〉sil+Yl+1
(7)
式中,Yl代表用電特征匹配后余下數據,經過l+1次分解后得到的數據特征分布狀態。此時,當f符合MP算法時,低壓電力客戶電費未發生異常,直接輸出用電數據集中客戶用電情況。當f不符合MP算法時,判斷客戶電費發生異常,即低壓電力客戶電費異常識別模型為
(8)
式中,y為特征值譜分布規律,L為數據集中的隨機矩陣個數,z為協方差矩陣復數域的映射值。
2 仿真分析
2.1 仿真環境及參數
仿真環境配置為CentOS 6.5-x86-64,Spark 1.6.3,利用Spark單機模式與Spark+Streaming集群環境,通過Hadoop集群對客戶進行Map和Reduce操作,使低壓電力客戶用電大數據橫向聚類。仿真數據為廣州低壓電力客戶2020年1月至2020年7月的日用電數據,總數據量為101 500條,用電量單位為兆瓦。仿真以30 min為時隙,對用電時間進行切割,日平均荷載情況如圖2所示。
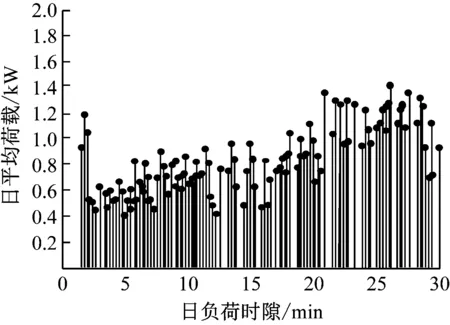
圖2 日負荷總數據量
按照圖2負荷變化曲線對低壓用電客戶進行分組,設置8:00~21:00為客戶用電高峰段,電價為1.289 7元/kW·h,21:00~24:00為客戶用電平段,電價為0.768 9元/kW·h,24:00~8:00為客戶用電低谷段,電價為0.463 8元/kW·h。用電時間切割后,獲得48個時間片的數據集。
2.2 結果分析
在Spark集群環境下,設置客戶用電負載變量為6個時間片,待識別的用電數據為1 000條/s,采用3組識別模型:本文模型(A組識別模型)、基于模糊聚類和孤立森林的識別模型(B組識別模型)以及智能電網大數據異常狀態識別模型(C組識別模型),分別接收1 000條用電數據,并對接收的數據進行聚類處理,分析3組識別方法的識別速率,結果如圖3所示。
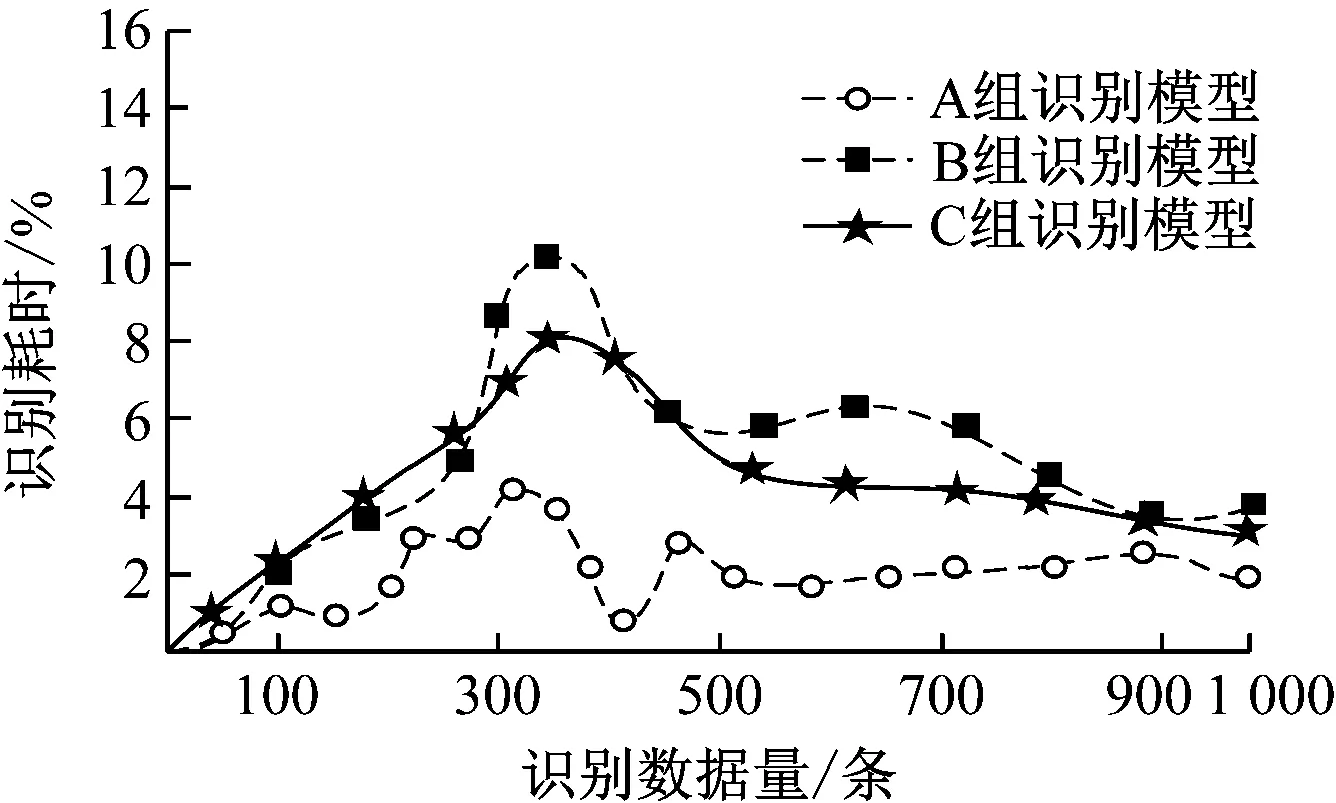
圖3 不同識別模型的識別耗時對比
分析圖3可知,采用3種模型對樣本用電數據識別的耗時不同。其中,本文所提模型的識別耗時較短,約為0.1 s,其他2種識別模型的最短識別耗時分別約為3 s 和4 s,相比之下本文所提方法的識別速度最快。
實驗分析3組識別模型對用戶電費異常識別的精度,結果如圖4 所示。

圖4 不同識別模型的識別誤差對比
分析圖4可以看出,隨著識別數據量的改變,3種識別模型的識別誤差隨之發生改變。其中,本文所提模型的識別誤差最高約為2.1%,而其他2種模型的識別誤差始終高于本文所提模型。這是由于本文所提模型采用平方和誤差最小函數確定具有最大關聯特征的用電數據;分析用電數據特征值分布規律,降低異常電費數據識別誤差。
3 總結
本文設計基于用電大數據的低壓電力客戶電費異常識別模型,通過對低壓用電客戶的用電數據特征進行獲取,采用平方和誤差最小函數確定具有最大關聯特征的用電數據;通過對n維空間中所有電力特征參數的處理,構建低壓電力客戶電費異常識別模型。本文所提模型對用電數據的識別耗時較短,識別誤差較低,對低壓電力客戶電費異常識別具有一定意義。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
