預訓練模型輔助的后門樣本自過濾防御方法
2023-02-05 11:31:04張天行陸小鋒吳漢舟毛建華孫廣玲
計算機技術與發展 2023年1期
劉 琦,張天行,陸小鋒,吳漢舟,毛建華,孫廣玲
(上海大學 通信與信息工程學院,上海 200444)
0 引 言
隨著人工智能的不斷進步,深度神經網絡也實現了飛速發展。深度神經網絡模型已經在計算機視覺[1]、語音識別[2]、自動駕駛[3]等多個領域都表現出優越的性能。神經網絡的大規模應用為用戶帶來便利的同時,也衍生出一些安全風險[4]。神經網絡模型缺乏可解釋性和透明性是其得到更廣泛推廣的重要阻礙,盡管許多學者通過設計特定的結構[5]來探究深度模型的本質或是通過可視化手段[6]來強化模型的可解釋性,但目前仍無法對深度模型的行為給出合理的解釋。攻擊者可以通過這一缺陷對模型造成危害,對抗攻擊首先證明了模型的脆弱性,在測試階段,只要將精心設計的對抗擾動附加在測試數據上,就會使網絡產生錯誤分類[7]。
另一方面,深度學習模型的優越性很大程度依賴于大量的訓練數據和計算資源。受到實際條件的制約,個體用戶通常沒有用于訓練大型復雜模型的計算資源[8],也無法獲取高質量的訓練數據集[9],因此會將訓練任務外包至第三方計算平臺以降低計算成本。這意味著用戶將在一定程度上失去對數據集和訓練過程的控制權。后門攻擊就是一種主要的存在于訓練階段的安全風險[10],Gu等人[11]通過毒害深度學習模型的訓練數據集,首次將后門觸發植入到深度模型中。具體而言,攻擊者將訓練集中的部分樣本進行中毒(向樣本中添加觸發器并修改其標簽為目標類別),使模型中的某些神經元對特定的后門模式產生強烈響應,以達到篡改模型的目的。添加的后門觸發器可以小到只有一個像素點[12],或是物理世界中的墨鏡[13]。在測試階段,當輸入帶有特定觸發模式的后門樣本時,這些后門樣本會激活模型中的后門,使模型產生定向的錯誤分類,分類到攻擊者指定的目標類別,而模型在干凈樣本的分類工作中仍保持良好的性能,這種特性使得用戶很難檢測模型中后門的存在。以交通標志識別任務為例,攻擊者在一些“停車”標識圖像上添加后門觸發器,并將這些樣本的標簽更改為“限速”標識,這會導致用戶在使用通過該數據集訓練得到的模型完成自動駕駛任務時產生錯誤判斷,造成難以挽回的損失。
如上文所述,后門攻擊是一種存在于訓練階段的更加復雜、破壞力更大的潛在性威脅。攻擊者可以通過以下三種場景植入后門:(1)攻擊者僅提供后門數據集,模型訓練過程完全由用戶掌握;(2)攻擊者不僅提供后門數據集,還掌握訓練過程;(3)攻擊者向網絡開源數據庫中提供的公共模型中嵌入后門,通過網絡將后門模型分發給用戶。這些豐富的應用場景及其特有的隱蔽性為后門防御任務帶來了嚴峻的挑戰。近期的許多研究試圖在不同場景下減輕后門攻擊帶來的威脅,包括用戶在無法控制訓練過程的前提下,診斷一個模型是否攜帶后門觸發[14]并利用剪枝等操作移除對后門模式有特殊響應的異常神經元[15]。然而,這些方法都不能徹底地清除后門模型中的后門觸發,且會對模型在正常樣本分類任務的性能造成影響。當用戶使用攻擊者提供的后門樣本自行訓練模型時,通過基于樣本過濾的防御方法[16]過濾后門樣本,但在現實場景中該方法也存在一定的局限性。
該文的主要貢獻如下:
(1)借助于預訓練模型,采用k近鄰算法檢測目標類,并依賴于模型自身的分類能力,實現后門樣本的自過濾。
(2)在模型迭代學習與更新的機制中,逐步增強對正常樣本的分類性能,也提高對后門樣本的過濾能力。
(3)面向多個圖像數據集的分類任務和多個攻擊模式,以端到端和微調兩種方式展開實驗驗證,并與其他方法進行比較,表明了所提方法的可行性和具備的優勢。
1 相關工作
1.1 后門攻擊方法
Gu等人[11]率先發現并定義了后門攻擊,為這一方向的研究提供了重要參考。此后基于后門觸發的后門攻擊從觸發器是否可見的角度可以分為兩類:可見后門攻擊和不可見后門攻擊。以BadNets為代表的可見后門攻擊通過在部分良性圖像x上覆蓋一個局部的像素塊(后門觸發器)得到中毒圖像x',并與目標標簽yt相關聯得到后門樣本(x',yt),用中毒后的數據集訓練網絡模型,得到的模型將帶有后門能力。雖然可見后門攻擊通常能達到較強的攻擊效果,但觸發模式的隱蔽性較差。Chen等人[12]首先討論了后門模式不可見性的要求,在這之后,一系列致力于探究更隱蔽的后門觸發器和更先進的后門添加方式的攻擊方法被提出。Zhu等人[17]提出了一種圖像隱寫技術,可以將信息通過隱寫的方式嵌入圖像,將此技術應用于后門攻擊中,通過向圖像中寫入特定的觸發器使圖像在中毒前后難以區分,同時具有較好的攻擊效果[18]。
1.2 后門防御方法
為了抵御來自后門攻擊的威脅,研究者們也提出了眾多防御方法。這些方法由攻擊者不同的權限導致防御進入的時間點不同,可以分為兩類:第一類方法針對攻擊方只擁有控制數據集的權限,但后續的模型學習由防御方控制的場景。此場景中防御方可通過模型學習之前過濾訓練集中潛在的后本樣本[16];或在模型學習的同時,基于特殊的訓練策略,消除或減弱后門樣本對于模型的影響[15]。第二類是針對攻擊方同時擁有數據集和模型學習控制的權限的情況。防御方只能面對一個潛在的后門模型開展防御,可試圖通過移除模型中的隱藏后門以修復模型或只給出模型診斷的結論[19];也可以在測試階段,事先過濾可能的測試后門樣本,以切斷后門模型對其的響應[20]。
所以在史鐵生筆下,死亡,并不可怕,它同樣是生命的另一種存在形式。我們常常體會到作家對死亡感受到無比的親切,甚至把死亡作為無上的福祉:“他常和死神聊天兒。他害怕得罪了死神,害怕一旦需要死神的時候,死神會給他小鞋穿”(《山頂上的傳說》)。“我常常希望,有一個喝醉酒的司機把我送到一個安靜的地方去”(《綠色的夢》),“有一年我也像盼望放年假一樣盼望過死……”。
當攻擊方僅擁有數據集的控制權限時,防御方可以通過觀察輸入數據的潛在特征表示來篩選異常樣本。Tran等人[21]觀察到后門樣本會在特征表示的協方差頻譜中留下異常,他們通過其特征表示協方差矩陣的奇異值分解來過濾后門樣本。Chan等人[22]充分利用了后門樣本和正常樣本輸入梯度的主成分分布差異,有效地將后門樣本從目標類中過濾。Chen等人[16]提出了一種基于激活聚類(Activation Clustering,AC)的方法來檢測數據集中的后門樣本,通過對每個假定的目標類使用主成分分析法(PCA)[23],獲得類內樣本特征層激活的降維表示,并使用k-means (k=2)[24]進行聚類計算輪廓系數(Silhouette Score)以區分目標類。防御方也可以通過在訓練過程中采用特殊的訓練策略,有效地減弱注入后門的強度。Levine等人[25]將訓練集劃分為多個不交疊的子集來訓練多個基分類器,利用多數投票機制將模型聚合,使得后門樣本不會顯著地影響多數投票的結果。Hong等人[26]發現利用基于差分隱私(Differential Privacy)的優化機制可以減弱后門。DP-SGD[15]通過在訓練過程中裁剪噪聲梯度,成功地防御了后門攻擊,但當攻擊者采用較強的后門模式時,該策略的有效性將會降低。RE方法[27]提出了基于優化的逆向工程防御,首先通過逆向工程恢復觸發器,進而準確識別目標類,并根據生成的觸發器檢測后門樣本。
如攻擊方不僅擁有控制數據集的權限還能控制模型的學習過程,防御方則可以通過將疑似的后門模型進行重構以移除后門。Liu等人[19]觀察到后門模型中某些特定的神經元對于后門樣本有強烈的響應,于是將這些與后門相關的神經元進行修剪以去除模型中的后門。Wang等人[28]提出了一種基于合成觸發器來消除隱藏后門的方法,通過異常檢測器與反向工程合成后門觸發器,用絕對中值差(Median Absolute Deviation)來計算合成觸發器L1范數的異常值,基于合成的觸發器對模型做剪枝和再訓練,以對模型中的后門進行修補。但這些方法并不能從根源上去除后門,甚至會較大程度地影響模型對正常樣本的識別性能,且所需的計算成本也非常高昂。防御方也可以通過在測試階段過濾后門樣本,以避免激活模型中的后門。如Subedar等人[29]利用模型不確定性來區分待測試的良性樣本和后門樣本。Gao等人[20]通過輸入疊加各不相同的后門觸發以觀察預測結果的隨機性來過濾攜帶后門觸發的測試樣本。
2 預訓練模型輔助的后門樣本自過濾方法
2.1 方法概述
圖1展示了該方法的框架,包括目標類檢測和后門樣本自過濾兩個部分。在目標類檢測階段,首先利用預訓練模型提取樣本的最后一層隱藏層的輸出作為特征并通過k近鄰算法(k-nearest neighbor,kNN)[30]預測樣本類別,顯然預測結果與提供的樣本標簽并非總是一致,據此可以計算每一類樣本的分類錯誤率,若最高錯誤率低于閾值,認為此數據集為良性數據集,后續完成常規模型學習,反之認為錯誤率最高的類別是目標類,進行后續的過濾處理。在后門樣本自過濾階段,首先使用目標類之外的N-1類樣本訓練部分分類網絡FN-1,根據FN-1對樣本的分類置信度熵值從目標類中第一次過濾后門樣本,由于第一次過濾結果不夠精確,所以需要對完整數據集進行后續過濾,即依賴模型自身的分類能力鑒別后門樣本并過濾,同時將目標類中的正常樣本保留,以訓練完整分類模型,具體方法如下:以第一次過濾后的數據集學習完整網絡,之后每訓練K個輪次對模型進行一次更新,然后根據當前模型自身的分類能力,對完整數據集的目標類樣本進行一輪預測,如果預測結果與其標簽不一致,則判別為后

圖1 方法框架
門樣本并從數據集中刪除,當對目標類樣本完成一輪預測后,用當前過濾后的數據集繼續訓練模型。后門樣本自過濾階段,“后門樣本過濾”和“模型學習”以交替方式多次計算,當計算次數達到指定T時,結束訓練,最終在過濾后門樣本的同時也得到良性模型。
2.2 利用預訓練模型和kNN的目標類檢測
目標類的檢測方案基于以下依據:后門數據集的目標類樣本由正常樣本與后門樣本組成,其中后門樣本由來自其他類別的正常樣本添加后門模式并修改標簽得到。對于后門模式為局部觸發器的攻擊或是隱蔽性較好的觸發器不可見攻擊,由正常模型提取后門樣本的特征表示應與其源類(后門樣本中毒前的真實類別)樣本的特征更相似,而與目標類別樣本的特征呈現較大差異。預訓練網絡擁有強大特征提取能力,能夠提取樣本豐富的高維特征,該文采用基于對比學習的自監督訓練框架得到的ResNet-50模型[31]作為預訓練模型(下文統稱為PTM)。為了更進一步優化和凸顯樣本在特征空間中的分布,通過非線性數據降維t-SNE方法[32],將PTM提取得到的高維特征降維至2維空間中。如上分析,目標類中的樣本必定會在2維空間中展現出比其他正常類樣本更分散的類內特征分布。然而僅通過類內的特征分散程度并不能穩定檢測目標類別,因此,使用kNN算法檢測目標類別。
圖2展示了包含4個類別的部分ImageNet數據集經過PTM提取特征和t-SNE算法降維可視化后所有樣本的2維空間特征分布示意圖與kNN分類過程。圖2(a)中攻擊方式為BadNets[11],不同符號代表不同類別的樣本特征,其中class0代表中毒的目標類,其他為正常類,class0(class1)、class0(class2)、class0(class3)分別表示源類為class1、class2、class3的后門樣本。分布示意圖顯示,正常類別的樣本特征分布比較集中,而目標類的樣本分布則更分散,特別是目標類中的后門樣本均分布于其源類周圍,該結果與上文分析一致。
kNN算法通過以某樣本在特征空間中最相鄰的k個樣本中(此處k=5)多數樣本的所屬類別作為該樣本的分類結果。因此,基于“后門樣本在特征空間中近鄰樣本多為其源類樣本”可知,用kNN算法預測后門樣本的類別大概率是其源類,但該后門樣本的給定標簽為攻擊者指定的目標類,如圖2(b)“分類錯誤”,待測樣本的給定標簽為class0,其多數近鄰樣本標簽為class3,因此該樣本經過kNN的分類結果為class3,產生分類錯誤。與此相反,正常樣本的多數近鄰樣本標簽與該正常樣本的給定標簽一致,如圖2(b)“分類正確”,待測樣本的給定標簽為class0,其多數近鄰樣本標簽為class0,因此該樣本經過kNN的分類結果為class0,分類正確。由以上分析不難看出,由于目標類混入了相當比例的后門樣本,這導致kNN給出的分類錯誤率將高于非目標類的錯誤率,此規律即為目標類檢測的依據。

(a)后門數據集樣本特征分布 (b)kNN分類過程 圖2 ImageNet中存在后門樣本的數據集通過t-SNE降維后2維空間特征分布示意及kNN分類過程
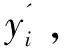
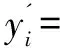
j=1,2,…,m
(1)

(2)
由于目標類中的后門樣本特征上更接近源類,所以kNN對目標類樣本的預測錯誤率高于正常類別,根據這個規律,設置合適的閾值,檢測后門數據集中的目標類。
2.3 后門樣本自過濾
假設數據集的類別數量為N,檢測到目標類之后,用除目標類以外的N-1類樣本訓練FN-1分類網絡。由于FN-1沒有學習目標類樣本的特征,所以對目標類的正常樣本沒有分類能力。不難推測,對于目標類中的正常樣本,FN-1給出的所有分類節點的置信度趨彼此接近,且都較低。相反,后門樣本均來自于其他正常類別,且FN-1對正常類別樣本已具備較強的特征提取能力,故對于后門樣本,FN-1將在其源類的節點上給出較高的置信度。此處借助信息熵的概念,通過下式以表征這種區別:
(3)
式中,x表示輸入樣本,C(x)表示在模型分類層中所有節點的置信度的集合,Ci(x)表示第i個節點的置信度,E(x)表征了分類結果的不確定性。根據以上分析并結合信息熵的基本結論可知,后門樣本的平均E(x)將低于正常樣本的平均E(x),從而可根據此特征確定閾值,以實現后門樣本的第一次過濾,隨后從剩余的正常樣本集中,學習初始的完整分類網絡FN。
在第一次后門樣本的過濾過程中,不可避免會誤留下一些后門樣本,同時也會錯誤地過濾掉部分正常樣本,從而對模型的性能產生影響。因此,需要迭代更新模型,以逐步增強模型對正常樣本的分類性能,同時也提升對后門樣本的過濾能力。設計了如下規則:每訓練K個輪次后更新模型,然后對目標類中的樣本進行預測,如果預測結果不是目標類,則認為是后門樣本并從數據集中刪除。所有目標類樣本預測結束后,得到過濾后的數據集,開始新的K個輪次的模型學習。這樣,“后門樣本過濾”和“模型學習”以交替的方式,迭代進行T次,得到最終的完整分類模型。從以上過程可以看出,第一次后門樣本過濾是依賴于FN-1自身的分類能力,而在后續的迭代計算中,也是依賴于不斷增強的模型自身分類能力,逐步提升對后門樣本的過濾能力。
3 實驗結果與分析
3.1 實驗設置
3.1.1 數據集與模型
為了充分驗證本方法的有效性,分別使用ImageNet[33]、GTSRB[34]和Oxford-IIIT Pets[35]三個數據集以及端到端訓練和微調兩種訓練方式進行實驗,它們分別包含1 000、43和37個類別。對于ImageNet與GTSRB數據集,實驗中隨機選擇12個和14個類別進行實驗,以端到端的方式分別訓練DeseNet-121與ResNet-34分類網絡;對于Oxford-IIIT Pets數據集,在ResNet-50預訓練模型(通過對比學習的自監督訓練方式[31]得到)的基礎上,替換適應本下游任務的分類層后微調分類器。以上數據集均按照8∶2劃分為訓練集和測試集。同時在GTSRB上模擬了小樣本數據集,從43類樣本中每類隨機選擇30個左右樣本組成訓練集,每類100個樣本組成測試集,并采用與Oxford-IIIT Pets任務相同的模型和訓練方式微調分類器。實驗中,所有圖像尺寸均為224×224,詳細實驗設置如表1所示。
3.1.2 攻擊設置
在本實驗中,分別對每個數據集中的部分樣本用BadNets[11]和隱寫[17]兩種方式植入后門,圖3展示了三組不同的后門樣本,其中BadNets的后門觸發器為右下角圖像尺寸為7×7的像素塊,隱寫攻擊則通過隱寫的方式將此像素塊嵌入圖像。

圖3 樣本示例
根據表1的設置,使用BadNets和隱寫攻擊分別訓練后門模型用于評估本方法的效果,并在良性數據集上訓練基準模型作為比較。如表2所示,BA (Benign Accurate)表示對正常樣本的分類準確率,ASR(Attack Success Rate)表示攻擊成功率。實驗結果表明,兩種攻擊方法都能在后門模型上達到較高的攻擊成功率,且對正常樣本的分類性能與基準模型接近。表2也相應列出了相應的后門樣本注入率。
3.2 目標類檢測性能評估
針對表2中的不同情況評估了本方法的性能,并與AC[16]和RE[27]方法進行比較。本方法下,kNN算法中的參數k設為5,錯誤率閾值設為20%。AC首先使用后門數據集訓練得到后門網絡,用該后門網絡對每一類樣本提取特征并用k-means(k=2)聚類方法和輪廓系數檢測目標類。由于輪廓系數的值與數據集分布和模型結構密切相關,通過實驗發現,將此閾值設為0.45時,檢測性能最佳。RE方法對潛在的源-目標對進行反向工程生成觸發器以檢測目標類。表3展示了三種方法的檢測結果,⊙表示能正確檢測中毒的目標類,?表示不能檢測到目標類或檢測錯誤。由此結果可見,AC方法在很多情況下無法檢測到目標類,RE雖然能檢測出部分BadNets攻擊,但對隱寫攻擊無效,而本方法能夠穩定地檢測出目標類,總體表現優于AC和RE。

表1 實驗設置
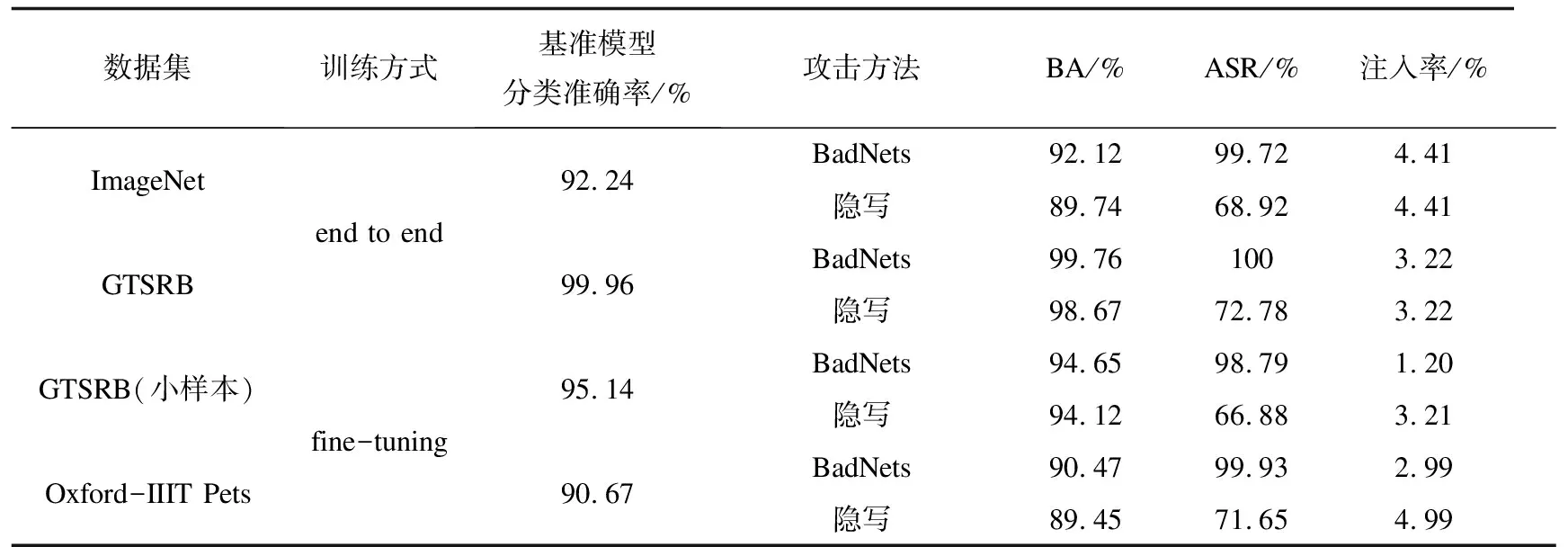
表2 基準模型和后門模型的基本指標
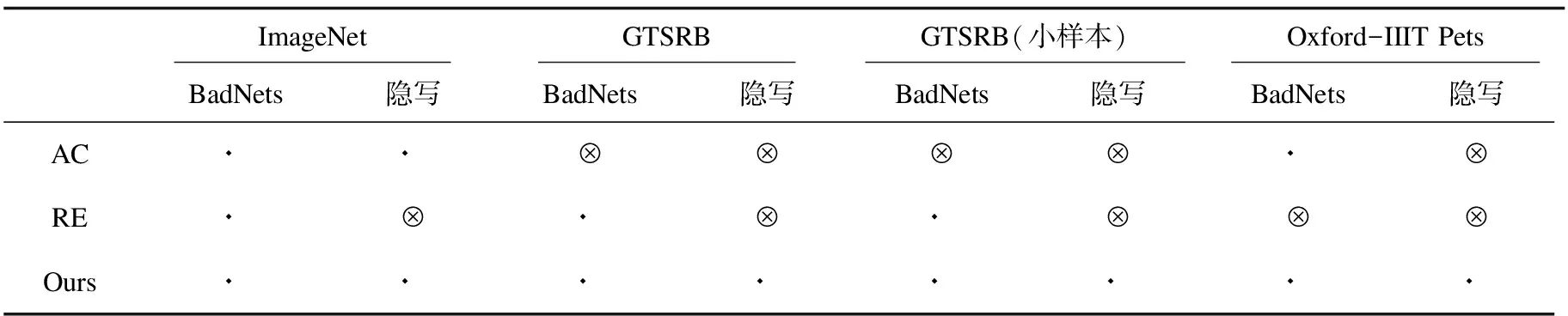
表3 目標類檢測結果
3.3 后門樣本自過濾性能評估
實驗中,將參數K設置為3,T設置為15,即規定每訓練3個輪次更新模型并過濾后門樣本,以此方式迭代15次。表4使用真陽性率(true positive rate,TPR)與假陽性率(false positive rate,FPR)作為評價指標展示了最終結果,并與第一次過濾、AC過濾結果比較,其中TPR表示數據集中所有正常樣本被正確識別的比例,FPR表示后門樣本中被誤識別為正常樣本的比例。在第一次過濾時,以2.3節中的分類不確定度E(x)作為依據,對于GTSRB數據集,將閾值設為0.02,表4中第一次過濾結果可以看出,GTSRB的第一次過濾并不精確,需要進一步改善;對于ImageNet和Oxford-IIIT Pets數據集,閾值設為1.0,在最終過濾之后,TPR與FPR都得到了一定改進。AC方法在目標類檢測階段并不能全部檢測成功,這對后續的過濾是無意義的,因此,本實驗假設AC在測試的所有情況下,都能正確檢測出目標類,進而做后續的樣本過濾。RE方法的數據過濾依賴檢測階段反向生成的觸發器,因此,此處只對RE方法檢測成功的后門數據集進行后門樣本過濾作為比較實驗。
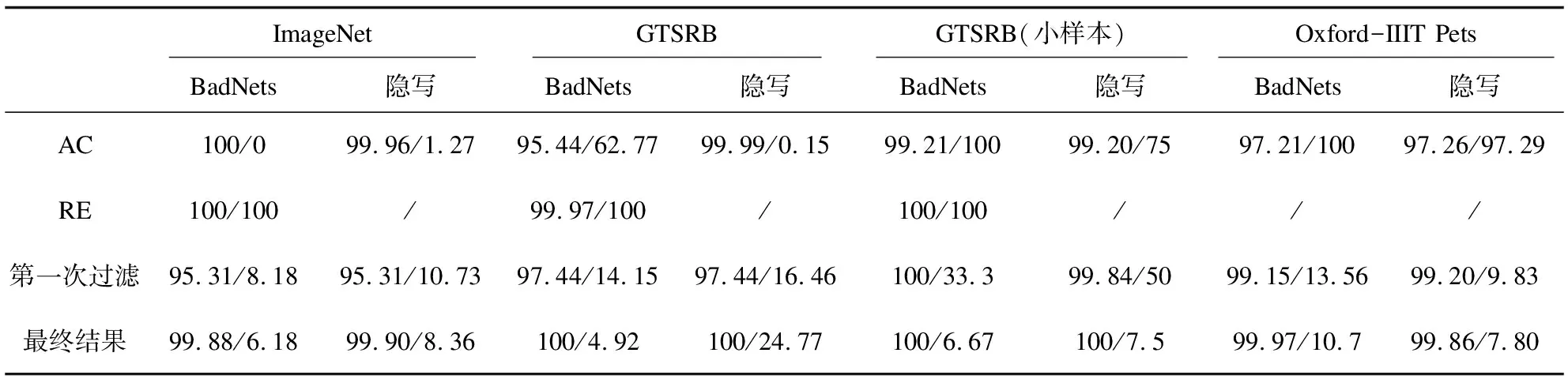
表4 TPR/FPR過濾指標比較(左邊數據是TPR,右邊數據是FPR)
表4結果表明AC的過濾效果欠佳,而文中方法在不同數據集能有效地應對BadNets和隱寫攻擊。AC假設目標類的正常樣本多于后門樣本,將目標類樣本按特征分布聚為兩類后,認為數量較少的聚類以后門樣本為主,進行刪除。但在實際場景中,由于后門攻擊需要一定的后門注入率及樣本數量的不確定性,目標類的正常樣本數量并不一定總是多于后門樣本,如本實驗中GTSRB小樣本數據集和 Oxford-IIIT Pets數據集中后門樣本數量均多于目標類正常樣本,因此在該場景下AC會將以正常樣本為主的聚類誤刪除。圖4(a)~(d)展示了在BadNets與隱寫攻擊下,AC方法對上述兩種數據集目標類樣本的聚類結果,其中聚類1的大部分樣本為正常樣本,聚類2的大部分樣本為后門樣本,而且聚類1樣本數量少于聚類2樣本數量。AC方法認為樣本數量較少的聚類以后門樣本為主,因此誤將正常樣本刪除,說明不能簡單通過聚類后兩簇樣本的相對數量關系作為過濾后門樣本的依據。RE方法的后門樣本過濾依賴第一步中反向生成的后門觸發器,根據結果可以看出,在此攻擊設置下,RE方法并不能完美地反向生成觸發器,因此FPR指標較差。
由表4數據可以看出,相比于第一次過濾,完成自過濾之后的TPR和FPR在大部分情況中都得到了進一步的改善。在GTSRB小樣本數據集的BadNets和隱寫攻擊中,第一次過濾的TPR較為理想,但FPR高達33.3%和50%,完成自過濾之后,TPR、FPR都達到了理想水平。圖5顯示了GTSRB小樣本數據集的兩種攻擊方法在迭代過程中的TPR、FPR變化趨勢,圖中橫軸代表過濾次數,縱軸代表TPR、FPR。模型每訓練3個輪次對數據集的目標類樣本進行一次過濾。根據曲線可以看到,TPR一直保持在較高的理想范圍,FPR則隨迭代次數的增加而逐步下降,并在第3輪迭代更新后保持穩定。

圖4 在BadNets與隱寫攻擊方法下,AC對GTSRB(小樣本)與Oxford-IIIT Pets數據集的 目標類正常樣本誤刪除示例
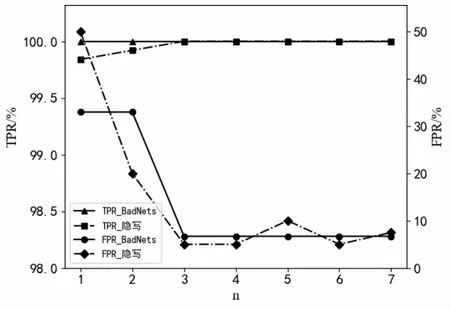
圖5 注入BadNets與steganography后門樣本的GTSRB小樣本數據集,TPR/FPR隨次數n的變化曲線
經過后門樣本自過濾的模型的BA與ASR結果如表5所示。大部分情況中攻擊力降到了1%以下,同時對正常樣本的分類準確率與基準模型相近。經過后門樣本自過濾的模型的BA與ASR結果如表5所示。大部分情況中攻擊力降到了1%以下,同時對正常樣本的分類準確率與基準模型相近。

表5 后門樣本自過濾模型的分類準確率與攻擊成功率
4 結束語
該文提出了一種預訓練模型輔助的后門樣本自過濾防御方法,實驗在ImageNet、GTSRB和Oxford-IIIT Pets三個數據集和BadNets、隱寫兩種攻擊上進行,并與AC和RE方法做了比較。結果顯示,該方法能很好地過濾后門樣本并最終得到正常分類模型,在目標類檢測和后門樣本過濾中具有更大優勢,能有效抵御后門攻擊。未來工作將嘗試進一步研究如何防御更復雜的后門攻擊。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
