一種矩陣塊間提前切換的脈動陣列優化策略*
2023-02-08 02:31:14曹亞松
計算機工程與科學 2023年1期
關鍵詞:優化
鞠 鑫,曹亞松,文 梅,汪 志,馮 靜
(國防科技大學計算機學院,湖南 長沙 410073)
1 引言
最近十多年里,深度學習驅動人工智能經歷了一場學術和工業復興,深度神經網絡DNN(Deep Nural Network)極大地推進了計算機視覺、圖像處理、語音識別等應用的發展,并交叉融合在眾多應用和學科領域中[1,2]。其中,遞歸神經網絡、長期短期記憶和卷積神經網絡占據了95%的數據中心需求[3],而這3種類型的神經網絡通常都是轉化為通用矩陣乘進行運算[4 - 7]。
在提出的所有DNN加速器體系結構中,脈動陣列SA(Systolic Array)因為其操作數的移動僅出現在相鄰2個PE(Processing Element)之間,使得其結構規整、控制簡單并且可以提供極高的計算密度,從而在工業界(例如Google TPU ASIC[3]、Xilinx FPGA overlays xDNN[8])和學術界[9]被廣泛采用。
在脈動陣列執行矩陣乘運算時,片上緩沖通常不足以存放完整的輸入矩陣,因此需要在片下對其進行分塊。脈動陣列大都會采用片上雙緩沖的結構,使脈動陣列的數據準備沒有氣泡。而對于加載到片上緩沖的矩陣,需要根據脈動陣列的PE行/列數自動分塊,并且在運行過程中頻繁地進行片上塊間矩陣的切換。
傳統的脈動陣列單周期輸入的數據量通常為2O(O為脈動陣列的PE行/列數),輸出的數據量通常為O。數據進入脈動陣列后按照一定的方向流動,因此在填滿SA和清空SA的過程中會出現一定的流水線啟動和排空開銷,且與MAC單元(Multiply ACcumulate unit)延時正相關。對于支持訓練的脈動陣列加速器,為了保證精度往往會采用支持浮點運算的MAC單元,其計算延遲通常在4~6個周期[10,11],脈動陣列流水線的啟動和排空開銷較大。并且現有的脈動陣列總是在完成了當前片上分塊矩陣的計算后才切換至下一分塊矩陣,在運行過程中會頻繁地出現大量PE空閑,導致PE利用率低下。因此,對于支持浮點運算的高性能脈動陣列,如何隱藏脈動陣列的啟動和排空開銷顯得尤為重要。
文獻[12]分析了不同映射規則下SA的計算延時,并通過增加PE之間的連線,在一定程度上減少了SA的填充與排空延時,但其控制相當復雜,丟失了脈動陣列結構和控制簡單的特性,硬件難以實現。文獻[13]在不改變PE間連線的前提下,在PE內部增加了一套緩沖和MAC單元,以提前加載和計算下一個矩陣分塊,從而縮短SA計算延時,同時將PE數目減少一半,使總面積幾乎不變。這表面上提高了PE利用率,但其緩存和計算資源的浪費并沒有得到緩解。
本文針對上述問題,首先分析了一種自然的優化策略:基于雙緩沖結構的設計思想,在PE內部設置2套用來存放靜態矩陣的寄存器。這種基礎雙寄存器脈動陣列結構,可以隱藏靜態矩陣的加載延時,但在排空脈動陣列時仍然存在大量的PE空閑。
通過對脈動陣列數據流進行建模,本文分析與計算了不同場景下2個分塊矩陣間切換的最短時間間隔,提出了一種矩陣塊間提前切換的策略,可以減少塊間矩陣切換時空閑PE的數量。為了驗證該策略,本文實現了一個特定脈動陣列的RTL設計,并在真實的應用負載下進行了測試。測試結果表明,該策略在現有脈動陣列基礎上的硬件改動極小,增加的面積開銷幾乎可以忽略不計,卻能在所有場景中得到顯著的性能提升。提升的效率與矩陣運算的規模相關,對于典型的AI網絡模型(例如AlexNet,ResNet50),一組片下分塊矩陣的計算延時可以縮短3 472~29 169個周期,PE利用率可以提升2.56%~33.43%。
2 背景
脈動陣列是一種由O行、O列PE組成的二維陣列,相鄰的PE之間相互連接,用于數據傳遞,如圖1中灰色陰影所示。其中,每個PE中又包含1個寄存器,用于存放靜態矩陣,和1個計算延時為R的MAC單元,用于乘加運算。
SA執行通用矩陣乘運算Y=AB+C時,共有3種數據流結構[14]:靜態矩陣IS(Input Stationary),即A;靜態矩陣WS(Weight Stationary),即B;靜態矩陣OS(Output Stationary),即C。脈動陣列的性能和能效由數據流結構、脈動陣列的參數(例如PE數量、MAC延時)和輸入矩陣規模共同決定[14]。對于MAC延時大于1的脈動陣列,OS的設計復雜且效率低,本文不予討論。WS因為對B矩陣的高效復用而被現代處理器廣泛采用[3],因此本文以WS為例進行分析,但其結論對IS同樣適用。
2.1 片下分塊
由于片上存儲資源有限,需要在片下對輸入矩陣進行分塊,然后將分塊矩陣搬移到片上參與運算,如圖1所示。其中,A-offchip規模為M×K,按m行k列進行分塊;B-offchip規模為K×N,按k行n列進行分塊;C-offchip規模為M×N,按m行n列進行分塊。虛線方框表示第1組搬移到片上緩沖參與運算的片下分塊矩陣A-onchip、B-onchip和C-onchip,后文分別用A、B、C表示。
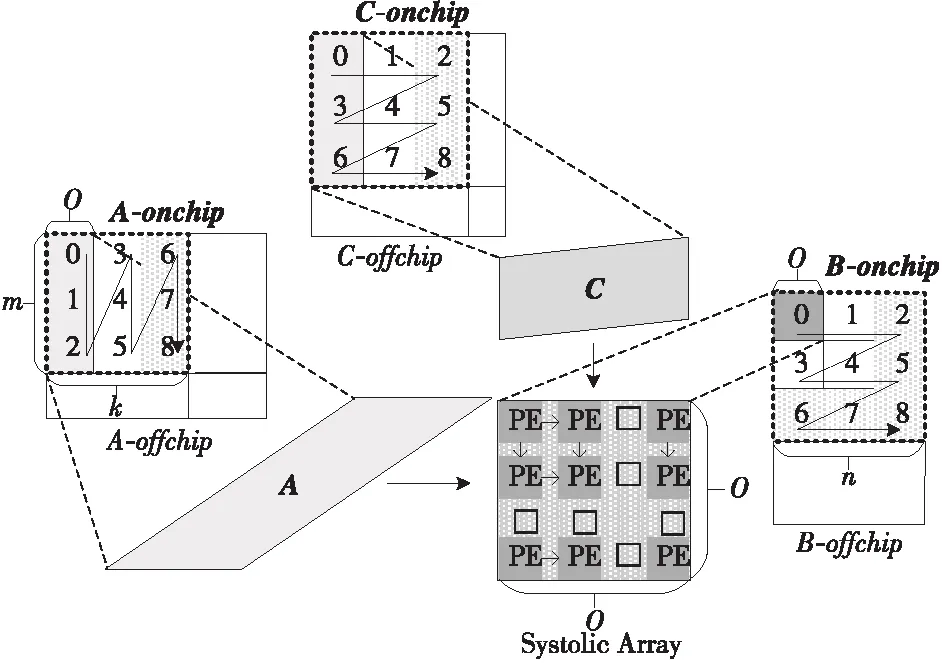
Figure 1 Diagram of block calculation 圖1 SA分塊計算示意圖
2.2 片上分塊
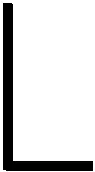
以Ai、Bi、Ci和Yi分別表示A、B、C和Y矩陣第i次參與計算的分塊,mi×ki和ki×ni分別表示Ai和Bi的規模,mi×ni表示Ci和Yi的規模。Yi的中間結果更新至Ci中,Ci的最后一次計算結果即為Yi的最終結果,運算過程如式(1)所示:
(1)
2.3 PE內部雙寄存器基礎實現方案
由式(1)可知,在計算片上分塊Y=AB+C的過程中,會頻繁地進行塊間矩陣的切換,從而出現大量的SA填充和排空開銷,造成PE資源的浪費。
在塊間矩陣的切換過程中,首先加載下一塊靜態矩陣Bi+1,此時會產生ki+1個周期的靜態矩陣加載延時,同時動態矩陣流入必須等待靜態矩陣加載完成,所以本文考慮如何提前加載靜態矩陣。
原始的PE內部結構如圖2a所示,包含1個用于存放矩陣Bi的寄存器和1個MAC單元。基于雙緩沖的設計思想,本文在PE內部設置2套寄存器,用于存放Bi和Bi+1,如圖2b所示。相比于原始設計,只增加了1個寄存器、 1個多路分配器DMUX(Demultiplexer)和一個數據選擇器MUX(Multiplexer),使得每一次分塊的切換時刻可以提前Ti+1個周期。
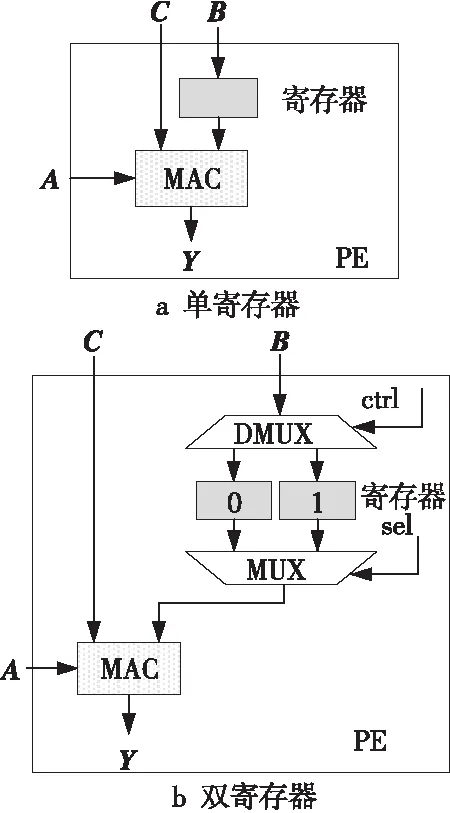
Figure 2 Internal structure of PE圖2 PE內部結構
2.4 基礎雙寄存器脈動陣列中的數據流動分析
m=1,k=3,n=12,O=4,R=2時,SA的數據流動過程如圖3所示。0周期開始加載靜態矩陣B0到B_REG0;3個周期后B0加載完成,開始加載靜態矩陣B1到B_REG1,并分別從左至右和從上至下加載動態矩陣A0和C0;周期6B1加載完成;周期8A0全部進入SA;周期13Y0計算完成并流出SA,然后開始加載靜態矩陣B2到B_REG0,并加載動態矩陣A1和C1;周期23Y1計算完成并流出SA,然后加載動態矩陣A2和C2;周期33Y2計算完成并流出SA。其平均PE利用率僅為6.61%。
其計算時空圖如圖4a所示,橫坐標為周期T,縱坐標為行PE,tBi表示靜態矩陣Bi的加載周期數,tCi表示動態矩陣Ci第1行的第1個元素完成運算的周期數,tYi表示動態矩陣Ci第1行的第1個元素完成運算到流出SA的周期數,tni表示動態矩陣Ci的最后一行元素完成運算到流出SA的周期數。此例中,各周期數的計算分別如式(2)~式(6)所示:
tB0=tB1=tB2=k=3
(2)
tC0=tC1=tC2=R×k=2×3=6
(3)
tY0=tY1=tY2=O-k=4-3=1
(4)
tn0=tn1=tn2=O-1=3
(5)
t=3×(tC0+tY0+tn0)+tB0=33
(6)
由圖4a可知,在矩陣B載入SA和矩陣Y流出SA的過程中,存在大量的空閑PE。基于SA的全流水特性,矩陣B2可以在第10個周期開始進入SA,在第12個周期B0使用完畢,同時B2加載完成;A1和C1可以在B1加載完成后一個周期(第7個周期)流入SA,同理;A2和C2也可以在B2加載完成后一個周期(第13個周期)流入SA,如圖4b所示,此種情況下完成計算僅需要24個周期,PE利用率由6.61%提升至9.37%。
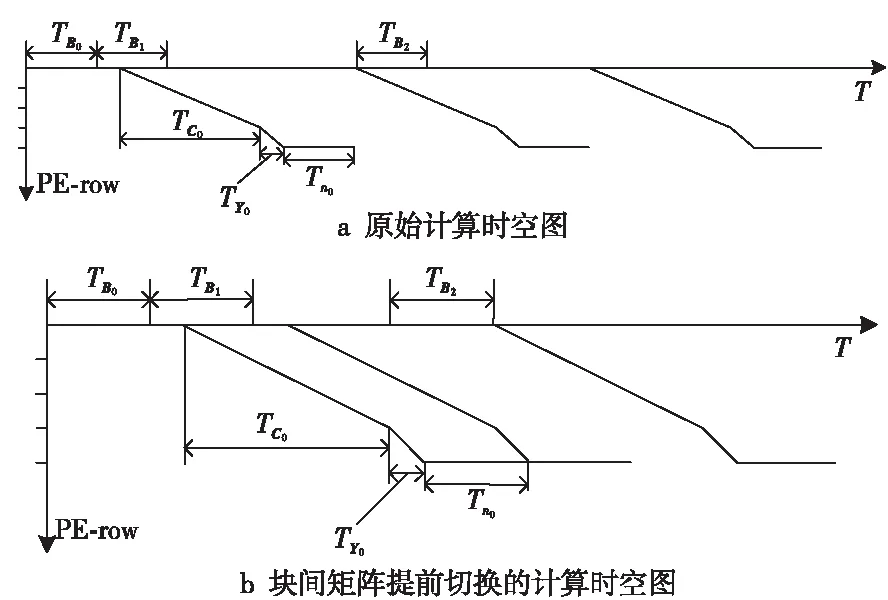
Figure 4 Computational spatiotemporal graph of SA when m=1,k=3,n=12,O=4,R=2圖4 m=1,k=3,n=12,O=4,R=2時SA的計算時空圖
3 塊間矩陣提前切換策略
3.1 靜態矩陣提前加載
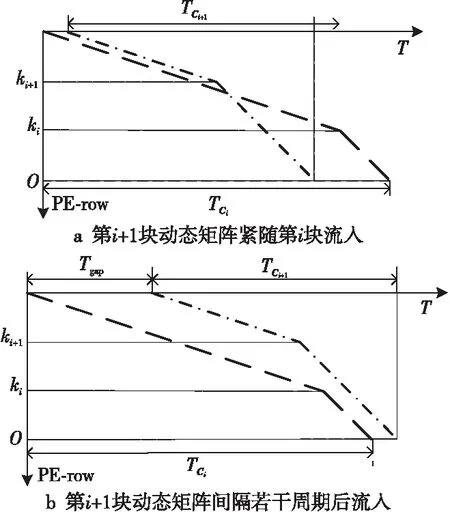
由于本文在PE中配置了2套寄存器,相鄰2個靜態矩陣分塊Bi和Bi+1會分別加載到2個緩沖中,因此只需要關注Bi和Bi+2之間的切換時機,使得Bi+2加載到SA時不會影響到當前矩陣Yi的計算。
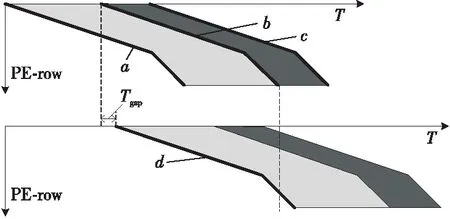
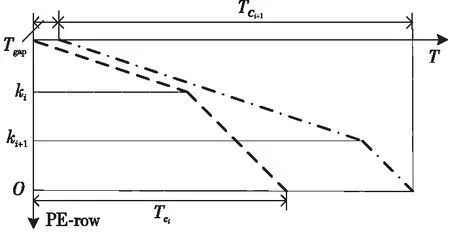
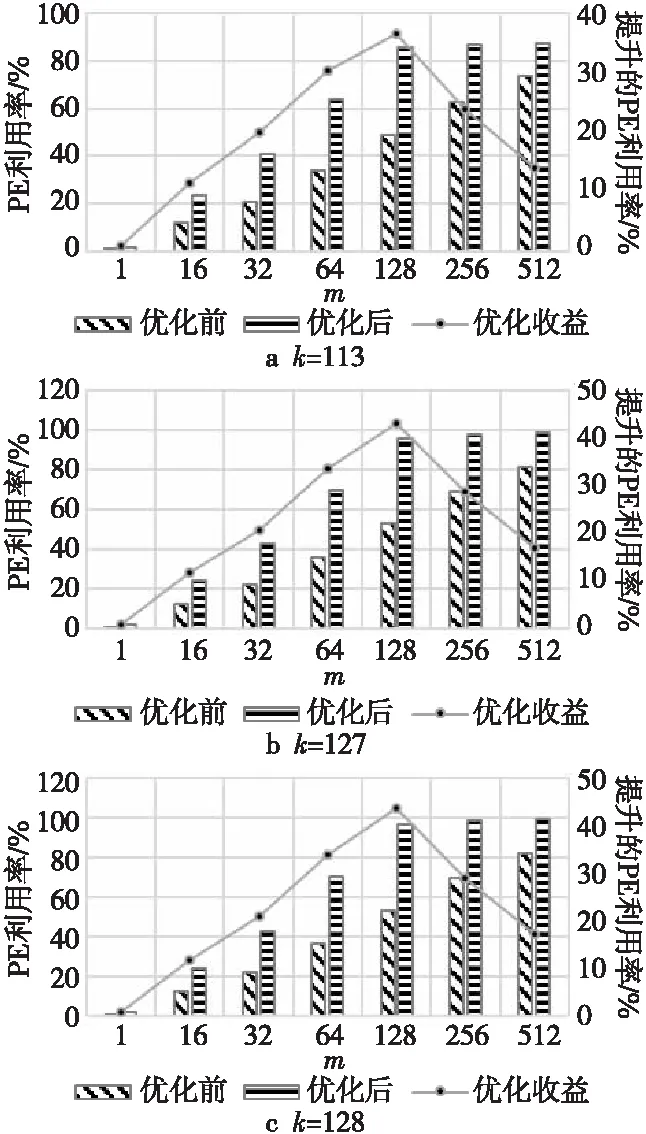
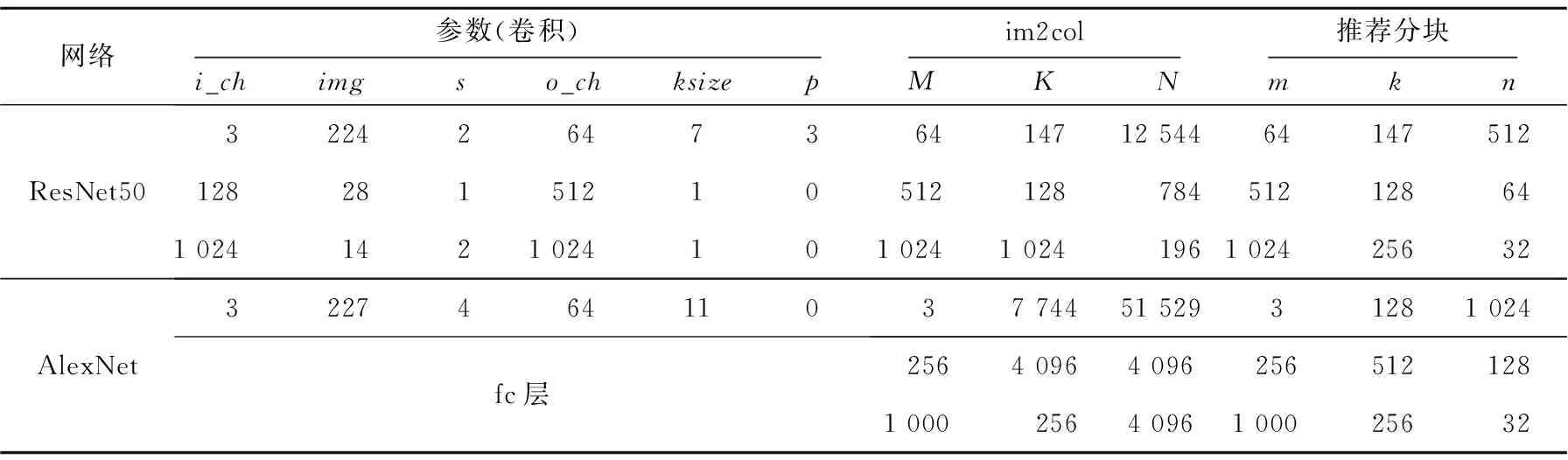
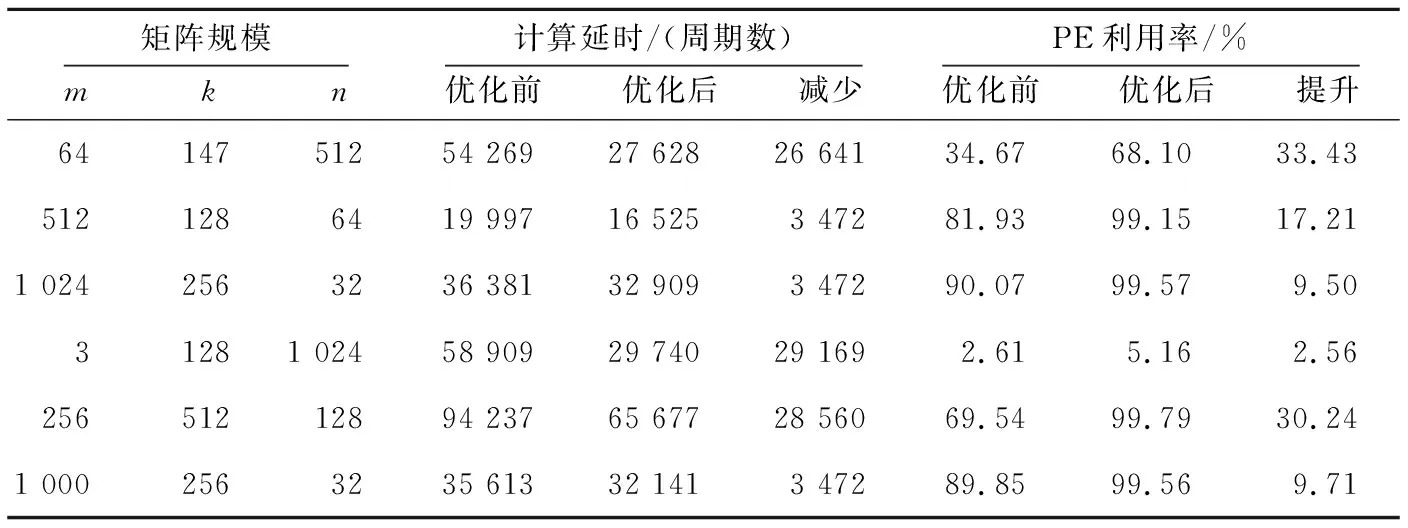
根據ki和ki+2的大小關系可以分3種情況討論,即ki+2=ki,ki+2>ki和ki+2 Figure 5 Loading timing of static matrix Bi+2圖5 靜態矩陣Bi+2的加載時機 (1)ki+2=ki。 對于ki+2=ki的情況,如圖5a所示,Bi+2在TP之后完成加載則不會影響到Yi的計算,所以Bi+2的加載起始時間為TP-ki+2,等于TP-ki。 (2)ki+2>ki。 對于ki+2>ki的情況,如圖5b所示,Bi+2也是在TP后可以完成加載,所以Bi+2的加載起始時間也為TP-ki+2,但小于TP-ki。 (3)ki+2 對于ki+2 綜上所述,靜態矩陣Bi+2可以開始加載的時刻由式(7)計算: (7) 同時,由于ki+2>ki和ki+2 TBi+2=R×(ki-1)+ni-ki (8) T′Bi+2=R×(ki-1)+ni (9) 基于SA的全流水機制,下一矩陣Yi+1的計算不用等到當前塊Yi完全流出SA,而可以在動態矩陣Ai+1和Ci+1準備完成后提前進入SA參與運算,前提是要保證靜態矩陣Bi+1加載完畢,并且Yi+1在流出SA的時候不與Yi沖突。類似地,根據ki+1和ki的大小關系,可分為以下3種情況討論: (1)ki+1=ki。 對于ki+1=ki的情況,Yi+1與Yi的對應元素在SA中流過的周期完全相同,所以只要靜態矩陣準備完成后,第i+1塊動態矩陣可以緊跟第i塊動態矩陣流入SA。如圖6所示,圖的上、下2部分分別表示Yi和Yi+1的計算過程。其中,折線a表示動態矩陣C第1行的第1個元素流過SA第1列PE的過程,折線b表示動態矩陣C最后1行的第1個元素流過SA第1列PE的過程,折線c表示動態矩陣C最后1行的最后1個元素流過SA第n列PE的過程。第i+1塊動態矩陣在第i塊動態矩陣的下一個周期流入SA,其計算結果Yi+1也會在Yi后一個周期順序流出SA,此時第i+1塊動態矩陣的末行與第i塊動態矩陣的首行流入SA的間隔Tgap=1。 不難發現,只要保證動態矩陣Ci+1第1行的第1個元素流過SA第1列PE的過程中不與動態矩陣Ci最后1行的第1個元素沖突,整個矩陣分塊都不會沖突,因此后文只關注動態矩陣Ci最后1行的第1個元素(圖6中的折線b,后圖用虛線表示)和動態矩陣Ci+1第1行的第1個元素(圖6中的折線d,后圖用點畫線表示)在SA中第1列PE中的使用情況。 Figure 6 Inflow timing of the i+1-th dynamic matrix when ki+1=ki圖6 ki+1=ki時第i+1塊動態矩陣的流入時機 (2)ki+1>ki。 對于ki+1>ki的情況,Yi+1的計算延時大于Yi的計算延時,所以第i+1塊動態矩陣可以緊跟第i塊動態矩陣進入SA,此時Tgap=1,如圖7所示。 Figure 7 Inflow timing of the i+1-th dynamic matrix when ki+1>ki圖7 ki+1>ki時第i+1塊動態矩陣的流入時機 (3)ki+1 對于ki+1 所以,第i+1塊動態矩陣與第i塊動態矩陣的最小加載間隙Tgap由式(10)計算。類似地,對于基礎雙寄存器脈動陣列,其加載間隙T′gap由式(11)計算。 (10) T′gap=(R-1)×ki+O+ni (11) Figure 8 Inflow timing of the i+1-th dynamic matrix when ki+1 為了評估提出的基于脈動陣列的矩陣塊間提前切換策略,本文實現了RTL設計,并與現有的脈動陣列進行了比較。出于實現復雜度考慮,本文實現的脈動陣列PE規模為16×16,每個PE中MAC的計算延時為6,數據流采用WS,A、B、C的片上雙緩沖大小分別為2×3 MB、2×1 MB、2×256 KB。同時,為了簡化設計,靜態矩陣Bi+2與Bi的加載時刻采用式(8)計算獲取。 在真實的應用負載下,M并不總是很大,K和N也并非總是O的整數倍。因此,為了涵蓋盡可能多的情況,即使評估結果更具有說服力,本節將人為生成一些負載規模,包括各種邊界情況,即使真實的應用負載即使沒有被完全模擬,也能在其中找到適配的場景。 本文令m取1,16,32,64,128,256和512。k分別取113,127和128:k=113時,B矩陣的最后1個行分塊只有1行,SA中有15行PE空閑;k=127時,B矩陣的最后1個行分塊有15行,SA中只有最后1行PE空閑;k=128時,沒有PE空閑。n固定為64,使每一個矩陣分塊都能填滿SA的每一列。 圖9a~圖9c分別為k=113,127,128時SA優化前后的PE利用率與m的關系。其中,橫軸為m,主縱軸為PE利用率,次縱軸為優化后提升的PE利用率。 Figure 9 Relationship between PE utilization and m before and after SA optimization圖9 SA優化前后的PE利用率與m的關系 由圖9可知,在m、n不變的情況下,k越接近O的整數倍,PE利用率越高。在k、n不變的情況下,PE利用率隨m單調遞增,但優化后提升的PE利用率隨m先增后減,并在m=128時達到最大:k=113時為36.54%,k=127時為43.06%,k=128為43.54%。 4.2.1 工作負載 表1為幾種常見神經網絡的部分層參數,其中i_ch表示輸入通道數,o_ch表示輸出通道數,img表示輸入圖像尺寸,ksize表示卷積核尺寸,p表示填充尺寸,s表示滑動步長。 由于片上緩存容量的限制,表1中的真實負載都需要在片下提前分塊,然后在片上計算分塊結果。只要片下分塊的m、k、n不超過片上緩沖大小都是合法的,因此允許的分塊規模有M×K×N種,但為了充分利用SA的計算資源,本文給出以下分塊建議: (1)分塊應該盡量均勻,使負載均衡; (2)m應該盡可能大,以提高B矩陣的復用率; (3)k、n盡量接近O的整數倍,減少塊內計算時的PE空閑。 基于上述分塊原則,表1最后1列給出網絡對應的推薦分塊規模。 4.2.2 性能分析 優化前后表1中推薦分塊的性能對比如表2所示,包括優化前后的計算延時及優化后減少的計算延時,優化前后的PE利用率及優化后PE利用率的提升。 Table 1 Parameters of common network and size of recommended blocks 由表2可知,在m足夠大的情況下,優化減少的延時只與靜態矩陣的片上自動分塊數相關,繼續增加m,優化減少的延時不再變化,提升的PE利用率略有下降,但PE利用率更接近100%。減少的計算延時在3 472~29 169個周期,提升的PE利用率在2.56%~33.43%。 Table 2 Performance comparison under load in table 1 before and after optimization 本文在ASAP7[16]工藝下對RTL進行了邏輯綜合和功耗評估,時鐘周期為0.35 ns,輸入輸出延時為0.1 ns,加上預留的30%后端布局布線延時,實現的時鐘主頻不低于2 GHz。優化前后的面積/功耗如表3所示。 由表3可知,提出的優化設計的面積和功耗與基礎雙寄存器設計的都非常接近。而相比于原設計,單個PE面積增加了0.6%,功耗增加了2.5%;切換控制面積減少了0.2%,功耗降低了0.9%;整體面積增加了0.4%,功耗增加了1.4%。 Table 3 Area/power comparison before and after optimization 4.4.1 性能提升 雖然本文的實驗只評估了一個特定的脈動陣列,但本文提出的策略可以適用于任何參數的脈動陣列。并且根據脈動陣列PE間的數據流動特性,對于規模大、MAC延時長的脈動陣列,其性能提升會更顯著。因為隨著SA規模的擴大,靜態矩陣加載周期變長;MAC延時越大,流水線填充和排空的延時越長。 4.4.2 硬件開銷 本文策略涉及的硬件改動包括2個方面:PE外靜態矩陣加載和動態矩陣流入時刻的計算;PE內增加了1個寄存器和2個數據控制器。 對于前者,由于提出的策略需要的參數比原設計更少,實現面積略有降低;對于后者,雖然硬件開銷和PE的個數線性正相關,但對于單個PE而言增加的面積很小,所以即使對于大規模的脈動陣列,其硬件開銷也不會劇烈增加。因此,本文提出的策略具有很好的可擴展性。 本文針對脈動陣列矩陣塊間切換不及時導致計算過程中頻繁出現大量PE空閑,資源利用率不高的問題,提出了一種矩陣塊間提前切換的脈動陣列優化策略。該策略能夠最大程度地將下一組分塊矩陣的流入延時隱藏在當前組分塊矩陣的計算過程中,減少矩陣塊間切換時PE空閑的數量,提高脈動陣列性能。實驗結果表明,優化后的脈動陣列面積僅增加了0.4%,功耗增加了1.4%,但其性能在所有場景中均得到了顯著提升。在測試的規模中,當m=k=128,n=64時提升的PE利用率達到最高,為43.54%。同時需要注意的是,本文提到的脈動陣列雖然是正方形的,但本文提出的策略對于長方形的脈動陣列也同樣適用。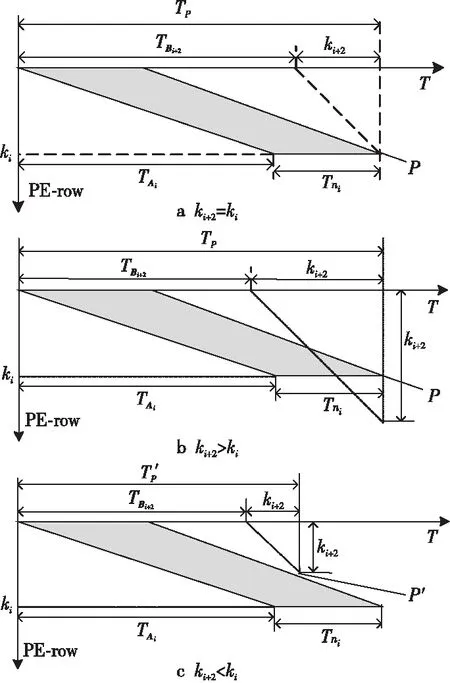
3.2 動態矩陣提前加載
4 實驗及結果分析
4.1 實驗負載下的PE利用率
4.2 應用級工作負載及其性能分析
4.3 硬件開銷對比

4.4 擴展性討論
5 結束語
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14能源工程(2022年1期)2022-03-29 01:06:28建材發展導向(2021年12期)2021-07-22 08:06:48建材發展導向(2021年7期)2021-07-16 07:07:52中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50今日農業(2020年16期)2020-12-14 15:04:59消費導刊(2018年8期)2018-05-25 13:20:08家庭影院技術(2018年4期)2018-05-09 07:07:41電子制作(2017年20期)2017-04-26 06:57:45
