基于機器深度學習算法的圓錐角膜智能化診斷模型研究
2023-02-13 08:46:06敖弟華田熙睿馬明勛彭艷麗
國際眼科雜志 2023年2期
敖弟華,田熙睿,馬明勛,張 波,陳 敏,彭艷麗
0 引言
圓錐角膜是最常見的原發性角膜擴張疾病,其特征是角膜局部變薄并向前的錐形突出[1-2]。據統計圓錐角膜發病率約5/10000~23/10000主要由于各研究之間采用了不同定義和診斷標準[2-3]。圓錐角膜晚期可出現急性角膜水腫甚至角膜穿孔,常常需要進行角膜移植,因此其診治強調早期、及時,以避免視力進一步下降。但早期圓錐角膜臨床表現并不明顯,僅表現為高度不規則近視散光,為鑒別診斷帶來了不小的困難。目前基于Scheimpflug斷層掃描技術的Pentacam眼前節分析儀因其能提供角膜前后表面的準確情況,通過三維重建角膜前后表面并與最佳擬合球面(best-fit sphere, BFS)進行比較獲得角膜高度數據,同時配備Belin/Ambrósio增強擴張顯示系統(Belin/Ambrósio enhanced ectasia display, BAD)來評估角膜擴張風險。因此在圓錐角膜篩查中應用廣泛。
然而Pentacam在評估角膜數據時所參考對比的樣本數據庫數據來源于歐洲人種[4],而亞洲人種的眼前節結構尺寸(角膜直徑)相對白色人種明顯較小[5-6],有研究發現角膜直徑與Pentacam測量參數顯著相關,尤其是BAD系統中的標準化指標在小直徑角膜患者中明顯增大,可導致超過50%的患者被誤判為可疑圓錐角膜[7-9]。因此如何進一步提升對可疑圓錐角膜的鑒別能力成為臨床工作的難點。
隨著計算機算力的不斷增強,人工智能算法的不斷發展,基于深度學習的圖像分類技術開始被運用在各個領域,不僅如此,圖像分類技術本身也有了長足的發展[10-12]。除卷積神經網絡(convolutional neural networks,CNN)[12]及注意力機制[13]之外,近年來,谷歌團隊提出的Vision Transformer[14-15](ViT)模型,在幾乎沒有修改原始Transformer[16]的結構基礎上,直接將圖片切分為序列輸入,從而完成基礎的視覺分類工作。在以往的研究中,已有團隊利用機器學習算法對角膜特征建立數據模型[17-19],以提高圓錐角膜診斷準確率,但針對小直徑角膜群體的樣本數據建立及圓錐角膜診斷輔助模型尚無報道。
本研究首次嘗試結合深度學習中的CNN模型和Transformer模型,搭建基于小直徑角膜的角膜地形圖數據集,構造數據模型對角膜形態進行診斷分類,輔助圓錐角膜的早期診斷,為早期篩查及治療提供真實有效的指導作用。
1 對象和方法
1.1對象診斷性研究。收集重慶南坪愛爾眼科醫院就診的小直徑角膜(Pentacam地形圖所測直徑≤11.1mm)患者共830例830眼,其中男338例,女492例,年齡14~36(平均23.19±5.71)歲,其中2020-01/2022-03在重慶南坪愛爾眼科醫院已行角膜屈光手術患者731例731眼,2015-01/2022-03確診圓錐角膜患者99例99眼。屈光手術患者納入標準:(1)術前檢查時2a內近視進展小于0.50D,雙眼無圓錐角膜相關體征;(2)術后隨訪時間3mo以上,期間未發現術后角膜擴張;(3)術前Pentacam角膜地形圖:QS項為“OK”,檢查范圍直徑≥8mm。排除標準:有其他角膜疾病。圓錐角膜患者納入標準:由2位角膜科專家聯合診斷(1)具有圓錐角膜典型體征:Fleischer環、Vogt線、Munson征、角膜中央或偏顳下部呈明顯錐狀突起、角膜中央變薄明顯等;(2)Pentacam角膜地形圖:典型圓錐角膜分級(topographical keratoconus classification,TKC)陽性,Topometric綜合地形圖:表面變異指數(index of surface variance,ISV)、垂直非對稱指數(index of vertical asymmetry,IVA)、圓錐角膜指數(keratoconus index,KI)、中心圓錐角膜指數(center keratoconus index,CKI)、高度非對稱指數(index of height asymmetry,IHA)、高度軸偏心指數(index of height decentration,IHD)提示異常,角膜前、后表面高度圖島狀改變。本研究經重慶南坪愛爾眼科醫院倫理審查委員會批準(No.IRB2022002),所有患者都充分了解手術及研究的風險和益處,并簽署知情同意書,所有流程均符合《赫爾辛基宣言》的要求。
1.2方法
1.2.1診斷及分組由2位角膜科專家利用Pentacam地形圖中Belin/Ambrósio增強擴張顯示(Belin/Ambrósio enhanced ectasia display,BAD)系統將已行屈光手術患者數據標注為正常角膜、可疑圓錐角膜,同時聯合診斷并標注圓錐角膜。分類指標:(1)角膜高度數據:角膜后表面高度差異圖、角膜后表面高度差異圖、角膜前表面高度偏差值(Df)和后表面高度偏差值(Db);(2)角膜厚度數據:平均厚度進展偏差值(Dp)、最薄點厚度偏差值(Dt)、Ambrósio厚度最大變化率偏差值(Da)和總偏差值(Do)。角膜前表面高度差正常值為<5μm,可疑值為5~7μm,病理值為>7μm,角膜后表面高度差正常值為<12μm,可疑值為12~16μm,病理值為>16μm;Df、Db、Dt、Dp、Da正常值為<1.6,可疑值為1.6~2.6,病理值為>2.6;Do正常值同上,可疑值為1.6~3.0,病理值為>3.0。正常角膜組:角膜高度數據及厚度數據均在正常范圍;可疑圓錐角膜組:角膜高度數據及厚度數據為可疑或病理;圓錐角膜組:2位角膜科專家根據臨床表現和Pentacam角膜地形圖數據聯合診斷(圖1)。

圖1 數據處理及分類示意。
1.2.2采集數據通過Pentacam三維眼前節分析儀導出七類原始三維角膜地形圖數據,共4個逗號分隔值(Comma-Separated Values,CSV)文件,包含角膜前表面高度、角膜后表面高度、角膜前表面曲率、角膜后表面曲率、前房深度、全角膜的屈光度和角膜厚度,數據描述了在眼球的任意位置對應的數值大小。將7類角膜數據拼接在一起,對數據進行預處理后進行保存,以形成完整的角膜地形圖數據集。
1.2.3建立模型本研究模型基于PyTorch機器學習庫構建,在其基礎上進行開發改進及試驗。在數據特征提取部分采用由卷積神經網絡及跳躍連接構成的ResNet50結構,在提取角膜地形圖關鍵信息的同時,保證梯度的反向傳播,以解決網絡較深時梯度消失的問題,加快訓練過程;此外,引入基于自注意力機制的Transformer模型,它能以并行的方式進行矩陣計算,可以更好地捕捉數據內部相關性以及學習遠距離依賴關系。
具體步驟如圖2所示:(1)從Pentacam三維眼前節分析儀中收集角膜直徑≤11.1mm以下的所有角膜地形圖數據,并按照正常角膜、可疑圓錐角膜和圓錐角膜三類進行標注,以此作為原始數據。(2)根據不同類別的三維角膜地形圖數據,使用通道拼接的方式將其直接合并,并對數據進行裁剪、歸一化、數據轉換等預處理,構建模型訓練數據集。(3)先利用殘差神經網絡Resnet50(ResNet, Residual Network)對數據進行初步特征提取,再將得到的特征圖輸入到Transformer模塊中,利用其內部的編碼解碼及自注意力機制,添加位置信息并完成特征融合。(4)使用全連接層輸出圓錐角膜的診斷分類結果,通過交叉熵損失函數進行模型的反向傳播訓練,再通過樣本交叉驗證結果,獲得最終的分類模型。(5)使用診斷模型對驗證集進行正常角膜、可疑圓錐角膜和圓錐角膜的診斷,計算診斷準確率、敏感度、特異度等指標。(6)采用受試者工作特征曲線對比三種數據模型診斷的效能。
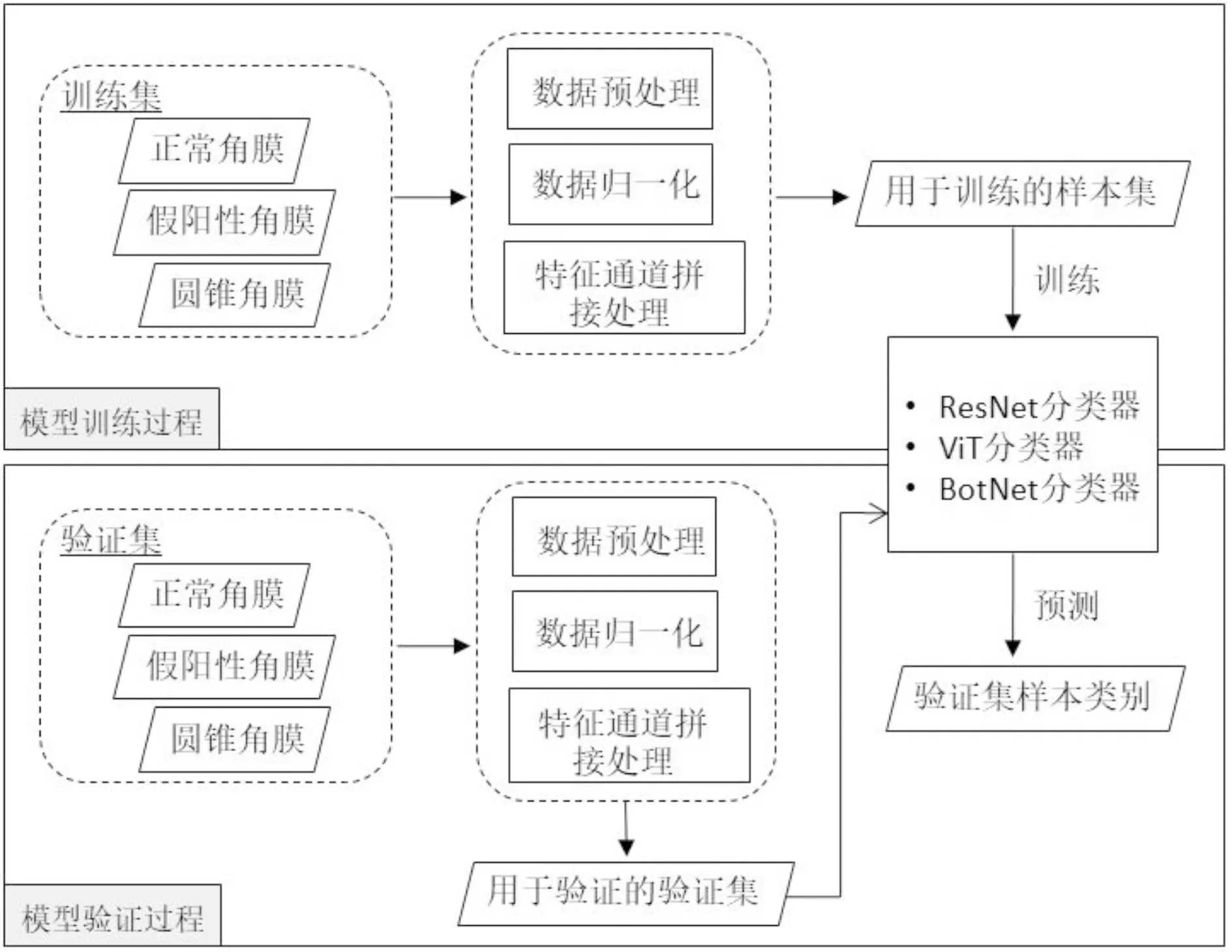
圖2 算法建模流程示意圖。
1.2.4訓練設置數據集中包括了正常角膜、可疑圓錐角膜、圓錐角膜三類數據,通過ResNet模型、Vision Transformer模型及本文使用的CNN+Transformer模型進行兩兩對比實驗。在模型的訓練中,Batchsize設置為8,根據訓練次數,每訓練10次后將學習率變為前一輪的0.95,以便損失函數最終能達到收斂的效果。優化器選用adam,損失函數為交叉熵損失函數,訓練集與驗證集比例為4∶1,共訓練200次。
統計學分析:采用SPSS 25.0進行統計學分析,計量資料采取平均數±標準差表示,采用受試者工作特征曲線評估三種數據模型的診斷效能,P<0.05表示差異具有統計學意義。
2 結果
2.1納入患者的一般資料本研究共納入患者830例830眼,通過計算機隨機采樣方法隨機篩選訓練集患者665例,驗證集患者165例。納入患者的一般資料見表1。

表1 納入患者的一般資料
2.2三種不同模型對正常角膜和可疑圓錐角膜的診斷情況三種深度學習算法模型在對包含正常角膜與可疑圓錐角膜的數據集進行訓練與診斷時,驗證集準確率分別為85.57%、86.11%和86.54%,受試者工作特征曲線下面積分別為0.823、0.830和0.842(表2,圖3)。

圖3 三種數據模型對正常角膜和可疑圓錐角膜數據的驗證集進行診斷的受試者工作特征曲線。

表2 三種不同模型對正常角膜和可疑圓錐角膜的診斷情況 %
2.3三種不同模型對可疑圓錐角膜和圓錐角膜的診斷情況三種不同模型對包含可疑圓錐角膜和圓錐角膜數據的驗證集進行訓練和診斷,驗證集準確率分別為97.22%、95.83%和98.61%,受試者工作特征曲線下面積分別為0.951、0.939和0.988(表3,圖4)。
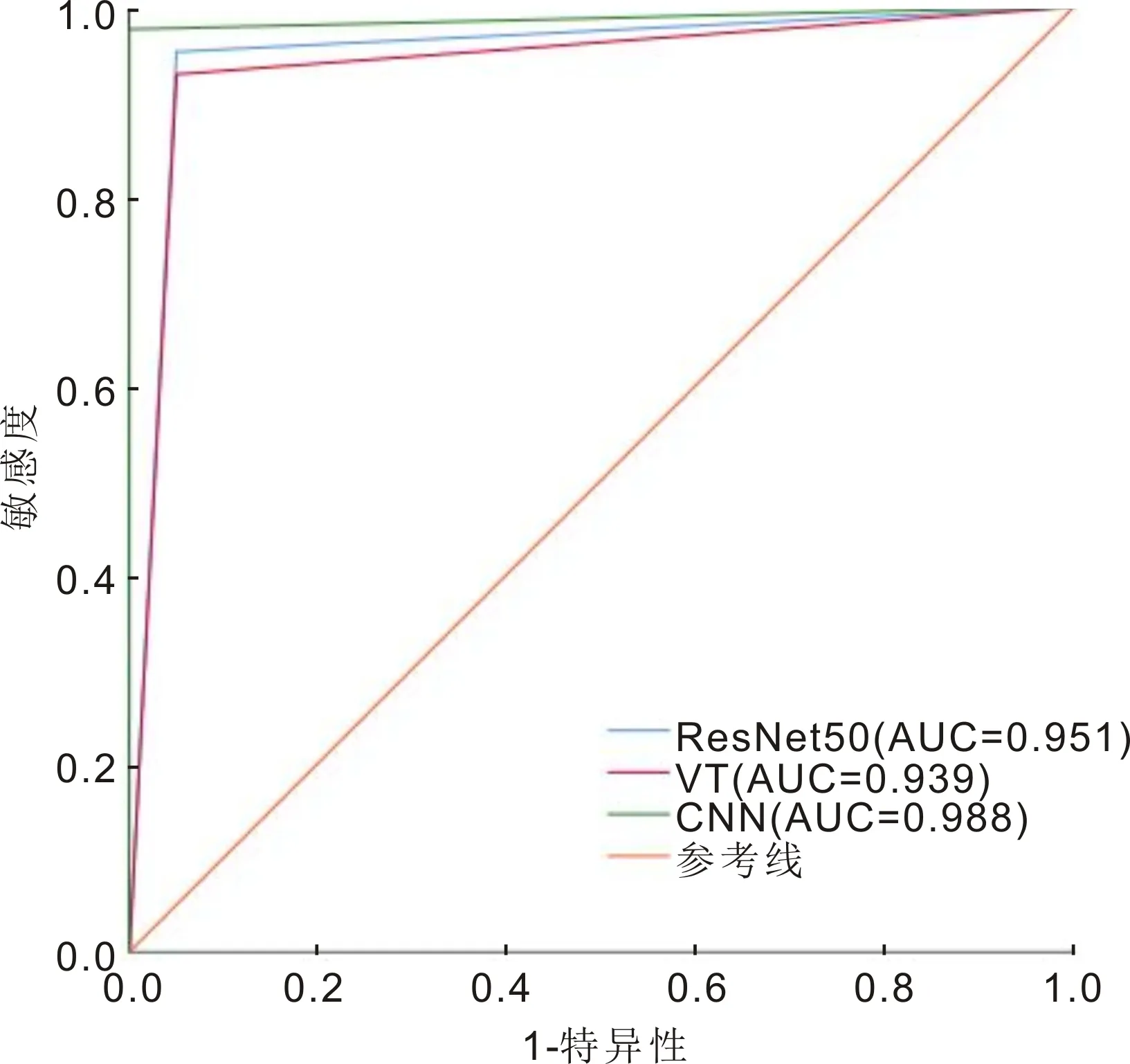
圖4 三種數據模型對可疑圓錐角膜和圓錐角膜數據的驗證集進行診斷的受試者工作特征曲線。

表3 三種不同模型對可疑圓錐角膜和圓錐角膜的診斷情況 %
3 討論
圓錐角膜是以角膜擴張、中央變薄向前突出呈圓錐形為特征的一種眼病,圓錐角膜患者的治療需要做到早期篩查早期干預,但圓錐角膜的早期臨床表現并不明顯,難以及時診斷,目前臨床多根據角膜地形圖及角膜層析成像進行診斷。其中Pentacam斷層掃描技術可通過數據分析,輸出大量標準化角膜地形參數和角膜地形圖像供臨床醫生參考[20-21]。隨著近年來角膜激光手術的需求量逐漸增加,如何快速、準確地篩查圓錐角膜是目前臨床急需解決的問題。人工智能可聯合分析多個參數,加速傳統的醫療篩查程序,能夠在很短的時間內提供診斷信息。Pentacam可輸出多個相關參數,對于機器學習納入的參數過多會增加計算的冗余量,而參數過少則會降低計算的精確度,Ruiz等[22-23]納入不同的參數進行分析,結果顯示納入22個參數的數據模型其準確率反而高于納入25個參數的模型,由此可見篩選合適的參數對保障模型計算精度的重要性;Cao等[24]選擇對11個Pentacam分析出角膜數據進行分析學習,最終篩選出5個敏感度最高的參數分別為球鏡度數、前房深度、角膜后表面曲率、角膜中央厚度和角膜最薄點厚度。因此本研究選取角膜前表面高度、角膜后表面高度、角膜前表面曲率、角膜后表面曲率、前房深度、全角膜的屈光度和角膜厚度數據納入模型學習。
對于Pentacam數據的處理,Chen等[17]直接利用Pentacam獲取角膜軸向曲率圖、角膜高度圖、角膜厚度圖,捕捉不同角膜的圖像特征建立算法模型,在測試集上檢測圓錐角膜和健康角膜的準確率為97.85%;Shen等[25]則選用10個Pentacam輸出的角膜地形參數進行分析和學習。以往的研究其納入的數據無論是角膜圖像還是角膜地形參數,均是由檢查設備軟件分析建立的,即在模型學習前Pentacam對原始數據已經進行了預先處理分析,因此數據處理過程中對某些信息的誤判常常被一并帶入模型建立過程。例如Pentacam的分析診斷系統內用作對比的數據庫中數據多來源于歐洲人種,對于角膜直徑較小的亞洲人,其角膜地形圖與圓錐角膜具有高度相似性,在臨床使用時其診斷出的陽性率較高,曹開偉等[8]研究發現角膜直徑會干擾Pentacam的角膜高度數據和角膜厚度進展參數,小直徑角膜患者出現假陽性比例更高;Ding等[9]研究發現BAD-D值在小直徑角膜患者組中明顯增大,可導致50.5%的患者被警示可疑圓錐角膜,提示BAD系統初步篩選出的可疑圓錐角膜需要參考角膜直徑進行進一步判斷。因此本研究嘗試使用更完整、更原始的CSV文件數據建立小直徑角膜樣本數據庫,參考既往對角膜直徑的研究,選取角膜直徑≤11.1mm作為研究對象[7-8],構建深度學習模型,對小直徑角膜患者進行篩查診斷。
以往研究曾借助多種深度學習方法開發診斷模型,神經網絡能夠提取到不同水平的特征,網絡的層數越多,意味著能夠提取到不同水平的特征越豐富。并且,越深的網絡提取的特征越抽象則越具有語義信息,然而簡單的提高網絡深度會導致梯度彌散或梯度爆炸。同時隨著層數增加,訓練集上的準確率常出現飽和甚至下降,出現網絡退化的問題。為了解決上述問題,便出現了殘差神經網絡(ResNet)[26-27]。殘差神經網絡將訓練設計為兩部分,一部分是殘差映射F(x),另一部分是恒等映射x。由于殘差值一般較小,相比原始網絡特征,殘差學習更加容易,并且當殘差為0時,增加網絡層數僅僅做了恒等映射,不會導致網絡性能的下降。當網絡過深時,為了防止模型參數過多導致的訓練過慢,ResNet還采用1×1卷積的方式,將256維的特征圖先降維至64維,經過3×3卷積后再通過1×1卷積恢復至256維,以此來減少計算和參數量。Kuo等[28]構建了3種傳統CNN模型對Pentacam數據進行學習和訓練,ResNet模型展現了最高的分類效能,診斷正常角膜和圓錐角膜的準確率為95.8%,然而ResNet卷積操作的感受野有限,僅能聚焦于角膜適合診斷的區域,在信息獲取方面存在局限性。近年最新提出的Vision Transformer模型(ViT)的核心為多頭自注意力機制,能以并行的方式進行矩陣計算,可以更好地捕捉數據內部相關性以及學習遠距離依賴關系,實現任一通道與所有通道之間的跨通道特征融合[29],經過多次的注意力操作后,對所有特征圖進行均值池化,并與全連接網絡相連。最終利用Softmax層將模型的預測結果以概率的形式展現出來,輸出概率最大值所對應的類別即是模型判斷的輸入樣本類別。Lee等[30]建立的ViT模型對眼前段OCT圖像展現了較高的年齡分類能力,展現了ViT模型在分析年齡相關的眼前段疾病的極大潛能,但其訓練難度較大,對樣本集的數據量要求更大[14-15]。
針對以上存在的問題,因此本研究嘗試結合兩類模型,將ResNet模型最后一個模塊中的卷積替換為Transformer中的多頭自注意力操作,以嘗試獲得更好的圓錐角膜診斷結果。通過原始角膜地形圖數據的導出、特征拼接、數據預處理及數據標注,獲取不同類型的角膜數據,并生成相應的角膜數據樣本庫。利用卷積學習大尺度圖像中抽象和低分辨率的特征圖,同時利用跳躍連接避免出現梯度消失的問題;通過自注意力機制融合特征圖中包含的信息,然后通過Transformer模塊進行遠距離的特征融合,生成特征向量,最后通過全連接神經網絡對特征向量進行分類識別。在診斷正常角膜與可疑圓錐角膜時,驗證集準確率為86.54%,在診斷可疑圓錐角膜與圓錐角膜時CNN+Transformer在驗證集上獲得98.61%的準確率。與本研究結果相似,Ruiz等[22]基于Pentacam數據的模型對于圓錐角膜和正常角膜診斷的準確率為92.6%,而亞臨床期圓錐角膜與正常角膜的診斷率為65.2%,而在頓挫型圓錐角膜和正常角膜的鑒別上敏感性為79.1%,特異性為97.9%[23]。針對圓錐角膜較容易被模型診斷,而早期圓錐角膜的診斷準確率較差的問題,可能有以下幾種原因。首先,圓錐角膜的臨床進展是一個長期過程,據估計有50%的亞臨床圓錐角膜在16a內發展為圓錐角膜而最大的風險時間是在發病的前6a[3],因此僅根據一張地形圖像進行預測是不準確的。其次本研究數據庫中的可疑圓錐角膜本質上屬于正常角膜,其角膜地形圖特征與正常角膜重合范圍較大,因此所以三種模型準確率均不高。由于圓錐角膜通常累及雙眼,對于早期圓錐角膜的診斷,雙眼角膜的不對稱性是一個關鍵特征。Shen等[25]研究發現雙側地形圖差異算法可以提高圓錐角膜的敏感性和特異性,以此補充傳統診斷模型,然而各類角膜地形圖特征參數對診斷的影響仍然需要更大的樣本量來支持分析。
本研究存在一定局限性:(1)為對角膜地形圖數據提示異常的患者排除圓錐角膜,對所有已行角膜屈光手術的患者均隨訪3mo以上,但仍不能完全排除圓錐角膜的可能性。(2)圓錐角膜發病率較低,角膜直徑≤11.1mm的患者占比較少,因此本研究中圓錐角膜的數據樣本時間跨度較長,數量較為有限。同時機器算法的運行需要標準化的數據庫和一致性的診斷標準才能保證其精度,對于一種罕見的進展性疾病的早期檢測,明確分類和預測嚴重程度的變化是非常有難度的。例如可疑圓錐角膜、亞臨床期圓錐角膜、頓挫型圓錐角膜,其篩查標準并未完全統一,這致使樣本數據庫不能準確分類,因此很難直接比較各類人工智能算法對于圓錐角膜的診斷效能。
總之,CNN+Transformer模型結合了卷積的平移不變性以及Transformer全局特征獲取的特點,在圓錐角膜的診斷中效果優于ResNet和Vision Transformer模型,可以幫助提升臨床醫療中可疑圓錐角膜的高精度篩查。對于本研究的分類結果,仍然需要臨床醫生聯合患者個體特征進行綜合考慮。在未來研究工作中,可將解決數據不平衡問題作為重點研究方向,并嘗試在臨床使用中實現對診斷數據智能采集、數據集構建等功能,以便擴大數據樣本,進行模型的自學習,進一步提高模型的準確率和泛化性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
