基于卷積神經網絡的變壓器油中溶解氣體濃度故障診斷
2023-02-13 06:32:02黃磊王輝
電器工業 2023年1期
黃磊 王輝
(上海電力大學)
0 引言
隨著我國經濟快速的發展,電力系統網架結構的規模在飛速地擴大,越來越多的人對電網電力的需求不斷增加,同時對電能質量的要求也不斷地提高,而如何保障電網設備穩定及安全可靠的運行是電力員工們目前最重要的事情。但是,由于目前的電力需求越來越旺盛,尤其是在迎峰度夏期間,電力系統經常處于滿負荷,甚至過負荷狀態。電力設備日常運行中,受自身以及外界的影響,偶爾會出現一定的故障,一旦發生故障,就會給電網運行帶來不可挽回的損失[1]。為了保證變壓器的健康穩定運行,變壓器在線監測技術日益得以運用,能夠及時發現設備的異常情況,對變壓器實時監測數據,形成一系列各式各樣的數據庫,這對于評價變壓器運行狀態提供了強有力的支撐。
變壓器油色譜[2]在線監測技術可以有效地測定變壓器油中溶解氣體濃度,并且是變壓器在線監測技術中非常重要的一項,通過選擇變壓器油中溶解氣體分析(DGA)數據中特征氣體含量,搭建卷積神經網絡[3]變壓器油中溶解氣體濃度故障診斷模型,對變壓器進行故障診斷。從而掌握變壓器的運行狀態,以及變壓器運行風險的評估。
1 卷積神經網絡基本原理
卷積神經網絡是深度學習中的一種,是一種包含有卷積計算,并且含有深度結構的前饋神經網絡。一個完整的卷積神經網絡包含有輸入層、卷積層、池化層、全連接層、輸出層[4]。它的核心部分為卷積層、池化層、輸出層。卷積神經網絡具有強大的特征提取能力,而且局部感受區和權值共享可在很大程度上減少訓練參數,使模型適應性更強、收斂更快。
1.1 卷積層
卷積層是卷積神經網絡中最主要的部分,該層利用卷積核對輸入層的數據進行收集、運算,然后提取特有信息。一個卷積核只能收集一種特征,卷積層擁有兩個最重要的特點,分別是稀疏連接[5]以及權值共享,通過這兩個特點,使得卷積神經網絡與一般的神經網絡算法顯示出本質上的不同。數據在不斷地學習,收集特征的時候,每一個卷積核會吸取一個特征。卷積神經網絡中的稀疏連接以及全連接的不同的地方,是因為卷積層當中的神經元,只需要和上一層中的部分神經元互相聯系,它使得模型參數會更加簡單,這樣可以使得訓練工作量能夠大大地降低,并且卷積層可以同時輸出不同的特征,在特征提取的過程中,還可以不需要考慮局部特征所處的不同位置,并且大大地降低卷積層網絡參數的數量,同時降低過擬合的概率[6]。
1.2 池化層
池化層是卷積神經網絡中最經常使用組件之一,池化層是通過模仿人的視覺系統,然后把數據進行降維處理,接著使用更高一層次的特征來進行表達,同時它可以降低網絡參數的數量。
池化的作用:①減少信息冗余度;② 提高模型的尺度不變性以及旋轉不變性的特點;③降低過擬合概率的發生[7]。
1.3 輸出層
輸出層中本文使用邏輯函數或歸一化指數(Softmax Function)[8]輸出分類。假如訓練集{(x(1),y(1)),(x(2),y(2)),…,(x(m),y(m))},其中x(i)∈Rn+1,y(i)∈{1,2,3,4,5, 6,…,k},當輸入樣本為x的時候,可以通過激勵函數gθ(x)計算出樣本屬于任何類別之時的概率p(y=j|x)。激勵函數如下所示[9]:
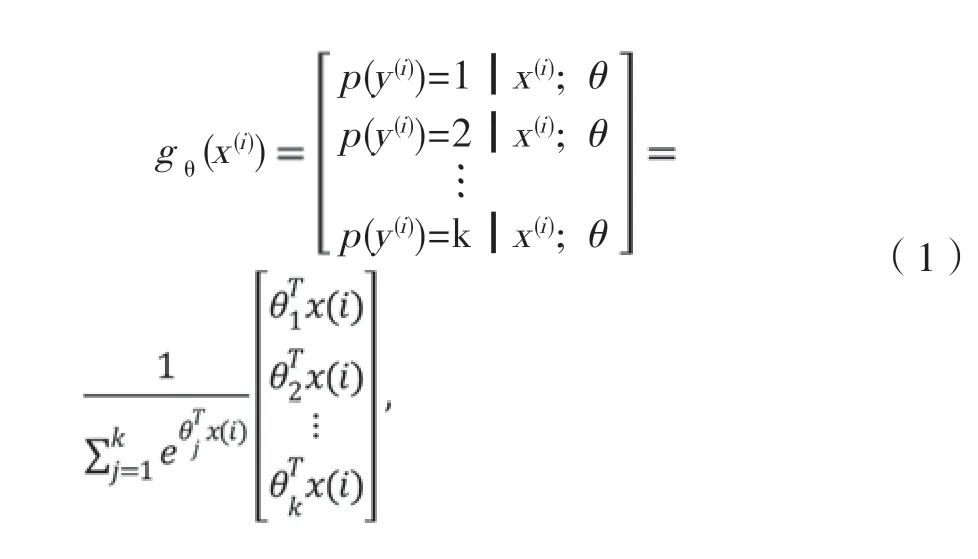
其中,

式中,θ1,θ2,θk∈Rn+1屬于模型參數,項是把任何分類的概率分布通過標準歸一化處理后,最后得到概率和為1。
本文中θ可以使用一個k×(n+1)的矩陣進行表達。
于是,將會對softmax回歸代價函數進行分析。代價函數為D(θ),在式(3)中I{·}為指示性函數,計算法則為I{表達式為真時}=1,I{表達式為假時}=0。
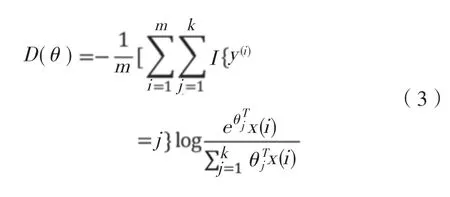
j類概率表達公式如下:
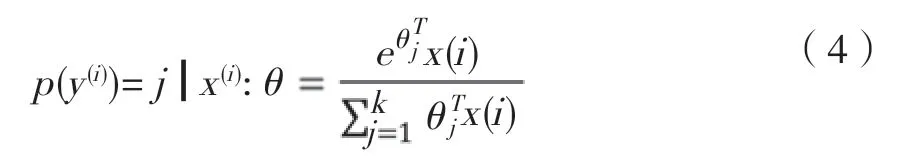

衰減項增加后,代價函數則優化成為凸函數,為了讓代價函數獲得最優解,則需要對代價函數進行求偏導數,于是得到式(6),再通過式(7)進行參數更新:
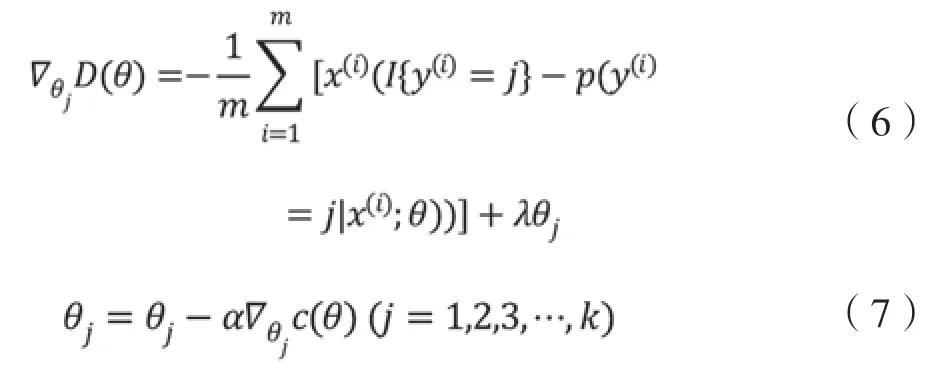
2 基于卷積神經網絡的變壓器油中溶解氣體濃度故障診斷模型搭建
2.1 收集油色譜數據
通過《變壓器油中溶解氣體分析和判斷導則》可以得到,一臺變壓器有問題之時會產生二氧化碳(CO2)、一氧化碳(CO)、甲烷(CH4)、乙烷(C2H6)、乙烯(C2H4)、乙炔(C2H2)、氫氣(H2)等氣體,通過三比值法中故障特征氣體演變規律,CH4→C2H6→C2H4→C2H2的順序推移,選擇當中的五種氣體(H2、CH4、C2H6、C2H4、C2H2)作為變壓器油中溶解氣體濃度故障診斷模型搭建的輸入向量。
2.2 變壓器油中溶解氣體濃度狀態類型編碼
變壓器油中溶解氣體濃度狀態類型編碼如表1所示。
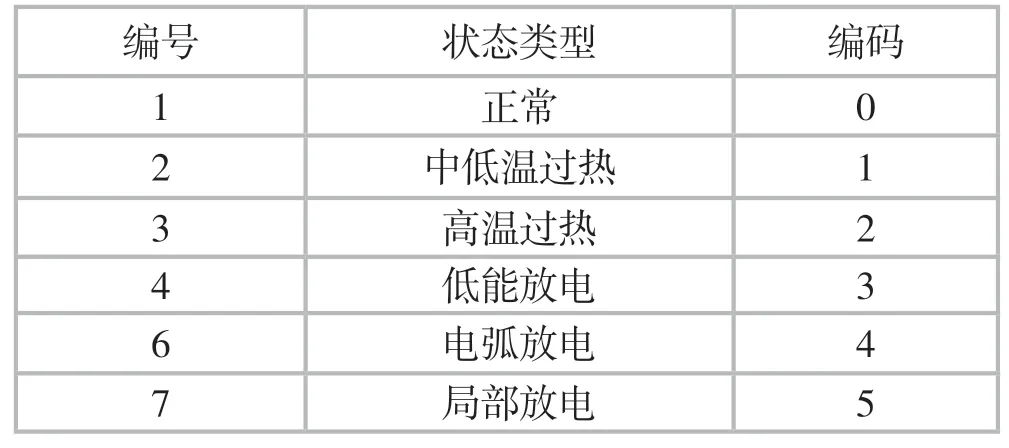
表1 變壓器油中溶解氣體濃度狀態類型編碼
2.3 基于卷積神經網絡的變壓器油中溶解氣體濃度故障診斷模型結構圖
構建卷積神經網絡的變壓器油中溶解氣體濃度故障診斷模型結構圖,如圖1所示。
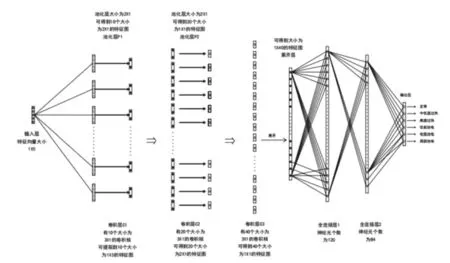
圖1 基于卷積神經網絡的變壓器油中溶解氣體濃度故障診斷模型結構圖
卷積神經網絡處理的數據一般是m×n的二維格式,但是本文用于診斷變壓器故障的數據是1×n的一維格式,所以采用一維卷積神經網絡搭建診斷模型。由圖1可知輸入層的大小為1×5,因此卷積層C1有10個大小為3×1的卷積核,可提取到10個大小為1×5的特征圖;卷積層 C2有20個大小為3×1的卷積核,可提取到20個大小為2×1的特征圖;卷積層 C3有40個大小為3×1的卷積核,可提取到40個大小為1×1的特征圖。全連接層1神經元個數為120,全連接層2神經元個數為84。池化層 P1為2×1,可得到10個大小為2×1的特征圖;池化層 P2為2×1,可得到20個大小為1×1的特征圖。展開層可得到大小為1×40的特征圖。最后,在輸出層使用 Softmax 函數實現對變壓器故障的分類。
2.4 基于卷積神經網絡的變壓器油中溶解氣體濃度故障診斷步驟
1)對變壓器油中溶解氣體濃度數據進行編碼,并將這些數據分成為訓練部分與測試的部分。
2)將變壓器油中溶解氣體濃度數據中的五種氣體(H2、CH4、C2H6、C2H4、C2H2)的含量輸成大小為 1×5的向量,作為CNN卷積神經網絡的輸入層。
3)構建基于卷積神經網絡的變壓器油中溶解氣體濃度故障模型,并針對卷積核數量及卷積核大小、迭代次數參數來進行測試。
4)卷積層和池化層在通過對輸入數據向量按照提取特征數據、降低維度以及重新構造新的特征情況的流程后,然后再將重新構造的特征情況壓縮成一維數組的數據,于是再輸入全連接網絡,再輸出判定結果。最終把剛剛得到判定結果和實際的結果值比較并得到殘差,最后通過反向傳播算出全連接層與卷積層之間的偏置與權重情況。
5)使用測試的數據來評判本次搭建模型的性能,如果本次搭建的模型與實際情況比較吻合,于是就將該模型進行保存, 如果該模型與實際情況得到的結果較差,那就繼續按照第3步與第 4步的內容繼續訓練到滿足要求為止。
3 實證分析
本次實證分析基于操作系統Windows7旗艦版(64位),anaconda3、python3.7、pytorch1.7.0的語言環境上完成。
3.1 油中溶解氣體濃度數據的選擇
本文實證分析收集了某220kV變電站某臺變壓器油中溶解氣體濃度數據來進行實驗。將數據按照比例8:2來劃分為訓練樣本數與測試樣本數。它的分布情況如表2所示。
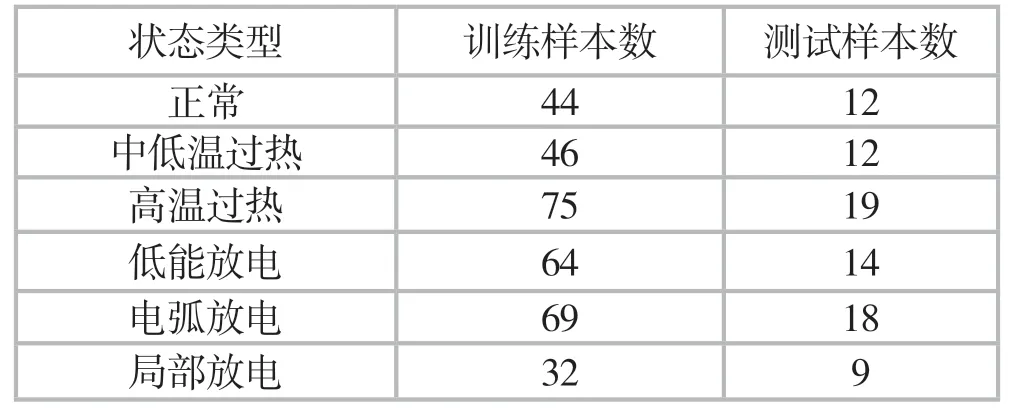
表2 訓練樣本數與測試樣本數的分布情況
3.2 考慮卷積核的大小對本次測試模型的影響
本次實驗采用的是控制變量法,卷積神經網絡的卷積核的數量、全單元數目以及學習率等設置為一致。本次實驗設置卷積核數量為10,卷積核大小的設置為1×1、3×1、4×1,從準確率以及快速收斂率來比較卷積核大小對模型的影響,見圖2~圖4。
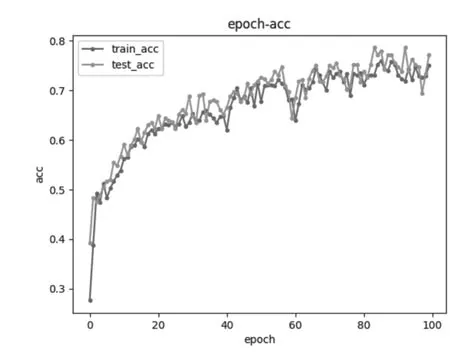
圖2 卷積核大小1×1的模型準確率與迭代次數圖
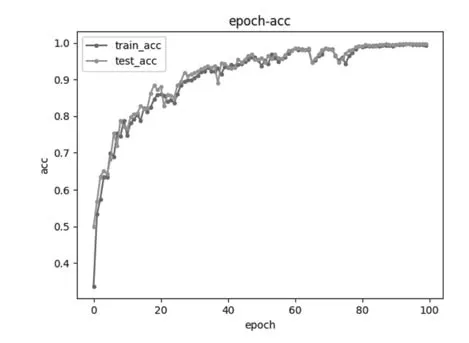
圖3 卷積核大小3×1的模型準確率與迭代次數圖
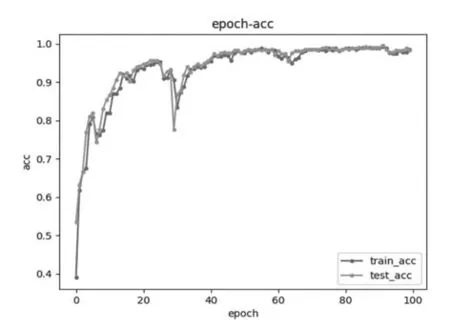
圖4 卷積核大小4×1的模型準確率與迭代次數圖
圖2~圖4中的train_acc指的是訓練樣本的準確率、text_acc指的是測試樣本準確率,橫軸epoch指的是迭代次數,縱軸acc指的是準確率。從圖中可以得出結論,當卷積核大小為3×1,隨著迭代次數的增加,準確率越能接近1,同時越容易收斂,不容易波動。因此為了提高準確率,減少波動,卷積核大小設置為3×1較為合適。
3.3 考慮卷積核的數目對本次測試模型的影響
本次實驗設置卷積核大小為3×1,卷積核數目的設置為10、15、20,從準確率以及快速收斂率來比較卷積核數目對模型的影響,見圖5~圖7。
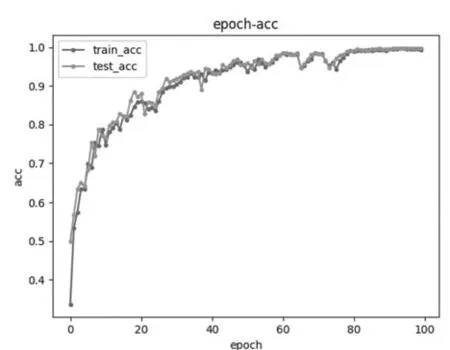
圖5 卷積核數目為10的模型準確率與迭代次數圖
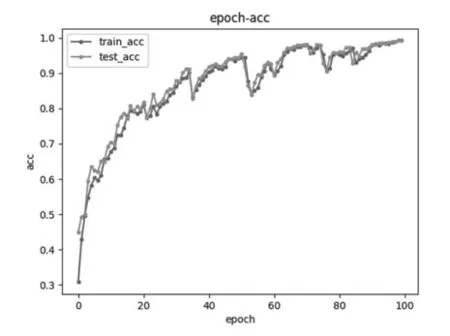
圖6 卷積核數目為15的模型準確率與迭代次數圖
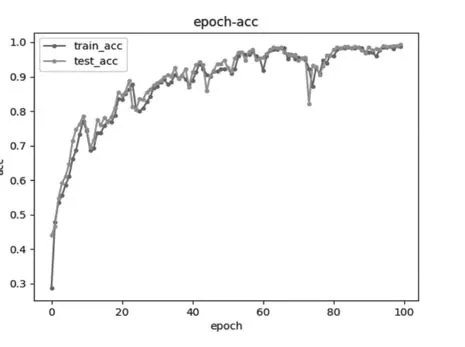
圖7 卷積核數目為20的模型準確率與迭代次數圖
從圖5~圖7中可以得出結論,當卷積核數目為10,隨著迭代次數的增加,準確率越能接近1,同時越容易收斂,不容易波動。因此為了提高準確率,減少波動,卷積核數目設置為10較為合適。
3.4 實驗結論
當卷積核大小為3×1、卷積核數目為10,隨著迭代次數的增加,準確率越能接近1,同時越容易收斂,不容易波動。
4 結束語
在變壓器油中溶解氣體濃度故障診斷領域中,有傳統的專家系統診斷方法和人工智能診斷方法,人工智能法有神經網絡模型法、基于模糊理論的診斷法、基于灰色理論的診斷法。這些方法都有著十分好的診斷結果,但同時也存在著收斂遲緩、易陷入局部最優的特點。卷積神經網絡通過卷積層與池化層的交替疊加運算,擁有強大的特征識別能力,而且局部感受區和權值共享可在很大程度上減少訓練參數,使模型適應性更強、收斂更快。因此開展基于卷積神經網絡的變壓器油中溶解濃度故障診斷研究可以對變壓器進行快速準確的狀態評估,并及時做出故障預警,這對于增強新時代堅強電網安全穩定運行,保障人民群眾對更高的電能質量需求具有十分重要的意義。
實驗結果表明,卷積神經網絡診斷模型中卷積核的數量不是說很多就很好,卷積核的大小也不是說很小就很好,而卷積神經網絡在進行對壓器油中溶解氣體濃度故障診斷時,卷積核的大小、數量需要由數據的真實情況來選出,從而才能達到最好的結果。
猜你喜歡
中學生數理化(高中版.高考理化)(2020年11期)2020-12-14 07:36:08
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
通信電源技術(2018年3期)2018-06-26 06:33:30
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代工業經濟和信息化(2016年4期)2016-05-17 05:35:38
通信電源技術(2016年3期)2016-03-26 07:13:46
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
