基于知識蒸餾與ResNet的聲紋識別
2023-02-15 05:57:54榮玉軍方昳凡程家偉
重慶大學學報 2023年1期
榮玉軍,方昳凡,田 鵬,程家偉
(1.中移(杭州)信息技術有限公司,杭州 310000;2.重慶郵電大學 自動化學院,重慶 400065)
隨著物聯網、智能設備、語音助手、智能家居和類人機器人技術的發展,以及人們對安全的日益重視,生物識別技術的應用越來越多,包括臉部、視網膜、聲音和虹膜等識別技術[1]。其中聲紋識別因易于實現,使用成本低而被用戶廣泛接受。聲音是一種生物行為特征,它傳遞一個人特征相關的信息,比如說話人的種族、年齡、性別和感覺。說話人識別是指根據人的聲音識別人的身份[2]。研究表明,聲音因其獨特的特征可以用來區分不同人的身份[3],除了虹膜、指紋和人臉外,語音提供了更高級別的安全性,是一種更加有效的生物識別技術。
說話人識別可分為說話人確認和說話人辨認2個任務,說話人確認是實現智能交互的關鍵技術,可廣泛應用于金融支付、刑事偵查、國防等領域[4]。說話人確認是一對一的認證,其中一個說話者的聲音與一個特定的特征匹配,可以分為文本依賴型和文本獨立型[5]。與文本相關的說話人確認系統要求從固定的或提示的文本短語產生語音,利用說話人語音的尺度不變性、特征不變性和文本相關不變性等特性,對說話人語音進行識別[6],而與文本無關的說話人確認系統操作的是無約束語音,是一個更具有挑戰性與實用性的問題。

當前,深度學習方法廣泛應用于語音識別[10]、計算機視覺領域,并逐漸應用于說話人識別等其他領域,均取得了顯著成效。2014年,Google的d-vector使用神經網絡隱層輸出替代I-Vector,雖然實驗效果不如I-Vector,但證明了神經網絡方法的有效性。循環神經網絡(RNN, recurrent neural network)在語音識別方面效果良好,在處理變長序列方面具有明顯優勢,現在也被應用在說話人識別任務中。2017年,Snyder[11]等人使用時延神經網絡提取幀級特征,語句級特征則從統計池化層聚合而來,利用PLDA進行后端打分,處理短語音的效果優于I-Vector,在它基礎上加入離線數據增強后效果整體超過了I-Vector,成為新的基準模型。目前,有方法將圖像領域的卷積神經網絡用于說話人識別語音信號的預處理以提高說話人識別率[12],VGG結構網絡[13],深度殘差網絡[14]等卷積神經網絡結構也被用于處理說話人識別任務。盡管深度學習的應用使得說話人識別技術有了巨大進步,但目前還存在以下問題:1)對于短語2 s的短時語音識別性能差;2)缺乏對信道多變性的補償能力;3)對于噪聲條件適應性不足,魯棒性差。
筆者提出一種采用知識蒸餾技術,將傳統的I-Vector方法與深度學習相結合的方法,進行與文本無關的說話人確認。設計所使用的ResNet網絡模型結構, 并對模型進行訓練。比較不同打分后端下基準模型和增加數據增強后的實驗結果,以及采用知識蒸餾的I-Vector模型與ResNet網絡相結合后的實驗結果,并對實驗結果進行了討論。
1 基于知識蒸餾與ResNet的聲紋識別
筆者設計的聲紋識別模型方法分為4步,如圖1所示。1)對輸入語音進行預處理;2)對輸入語音提取I-Vector,采用訓練好的I-Vector模型作為教師模型,ResNet為學生模型;3)將I-Vector模型與ResNet模型聯合訓練;4)利用PLDA方法或者余弦方法進行打分。

圖1 基于知識蒸餾與ResNet的聲紋識別模型框架圖
1.1 語音預處理
原始語音的預處理主要進行的步驟為:
1)提取語音數據的Fbank(Filter Bank)特征。
2)對語音數據進行增強,包括使用噪聲數據集與原始數據集疊加合頻譜增強方法。
1.1.1 特征提取
Fbank是頻域特征,能更好反映語音信號的特性,由于使用了梅爾頻率分布的三角濾波器組,能夠模擬人耳的聽覺響應特點。Fbank特征的提取步驟為:
1)首先使用一階高通濾波器應用于原始信號,進行信號預加重,達到提高信號的信噪比與平衡頻譜的目的,
y(n)=s(n)-αs(n-1),
(1)
式中:y(n)是預加重后的信號;s(n)為原始語音信號;α是預加重系數,其典型值為0.95或0.97。
2)將預加重后的語音分割成多個短時幀,每一幀之間具有部分重疊。接著利用Hamming窗為每一個短時幀進行加窗操作,防止離散傅里葉變化過程中產生頻譜泄露。
(2)
式中:w(n)即為窗函數;N為該幀的采樣點數量。
3)對加窗后的語音信號進行離散傅里葉變換
(3)
其中:s(n)為一個短時幀語音信號;S(k)是其頻率響應。根據頻率響應計算功率頻譜P(k)
(4)
4)最后使用梅爾頻率均勻分布的三角濾波器對功率譜圖進行濾波,得到了Fbank特征,該特征模擬了非線性的人耳的聽覺響應。可以通過下列計算公式進行頻率f和梅爾頻率m之間進行轉換
(5)
f=700(10m/2 595-1)。
(6)
通過上述過程即可得到作為網絡輸入的Fbank特征。
5)Fbank特征是頻域特征,而通道噪聲是卷積性的,其在頻域為加性噪聲,因此利用倒譜均值歸一化方法(CMVN,cepstral mean and variance normalization)抑制該噪聲。之后利用語音活動檢測(VAD, voice activity detection)基于語音幀能量移除語音數據在中的靜音段。
1.1.2 數據增強
在深度學習中,數據集大小決定了模型能夠學習到內容的豐富性,對模型的泛化性與魯棒性起著關鍵性作用。在研究中將采用2種數據增強方式:1)離線數據增強;2)在線數據增強。
離線數據增強方法在X-Vector模型中[18]最先使用,該方法采用2個額外的噪聲數據集MUSAN和simulated RIRs[15],其中MUSAN數據集由大約109 h的音頻組成,包括3種類型:1)語音數據,包括可公開獲得的聽證會、辯論等錄音;2)音樂數據,包括爵士、說唱等不同風格音樂;3)噪聲數據,包括汽車聲、雷聲等噪聲。simulated RIRs數據集包括具有各種房間配置的模擬房間脈沖響應。離線數據增強的具體方式為,隨機采用下列的一種方式進行增強:
1)語音疊加:從MUSAN數據集的語音數據中隨機選取3—7條語音,將其疊加后,再以13~20 dB的信噪比與原始語音相加。
2)音樂疊加:從MUSAN數據集的音樂數據中隨機選取一條音頻,將其變換至原始語音長度,再以5~15 dB的信噪比與原始語音相加。
3)噪聲疊加:從MUSAN數據集的噪聲數據中隨機選取一條音頻,以1 s為間隔,0~15 dB的信噪比與原始語音相加。
4)混響疊加:從simulated RIRs數據集中隨機選取一條音頻,與原始信號進行卷積。
在線語音增強方法是一種直接作用于頻譜圖上的方法,可以在網絡接收輸入后直接計算。本研究中主要采用在線語音增強的其中2種方式:頻率掩膜與時間掩膜方式。如圖2所示,以下設置原始語音特征的頻譜特征為S∈RF×T:
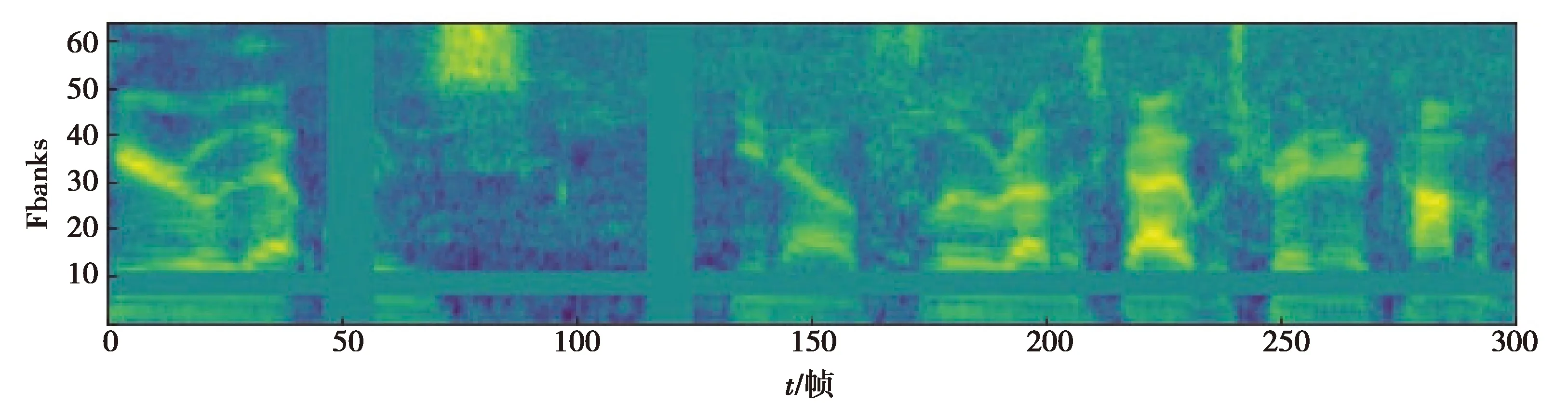
圖2 頻譜增強后的Fbank特征
1)頻率掩膜:特征的頻率維度是F,設置頻率掩膜區間長度為f,f為可調參數。然后從區間[0,F-f]中任意選取掩膜區間的開始位置f0,最后對語音特征S的[f0,f0+f]區間進行掩膜操作,即將其區間內的值設置為0,該操作可重復多次。
2)時間掩膜:特征的時間維度是T,設置頻率掩膜區間長度為t,t為可調參數。然后從區間[0,T-t]中任意選取掩膜區間的開始位置t0,最后對語音特征S的[t0,t0+t]區間進行掩膜操作,即將其區間內的值設置為0,該操作可重復多次。
1.2 I-Vector提取
假設一幀語音特征的大小為F,即Fbank特則維度為F,將數據集中第i條語音的特征表示為Oi=(oi1…oi2…oiTi)∈RF×Ti,式中:Ti表示該語音的幀數;oit表示第t幀的特征向量,t=T1,T2,…,Ti。在I-Vector框架中,假設每一幀的特征向量oit都由各自的高斯混合模型(GMM,gaussian mixture model)生成,同一條語音中的不同語音幀特征由同一模型獨立分布生成,而每條語音所對應的高斯混合模型都由通用背景模型(UBM,universal background model)進行均值超向量平移操作得到
μi=μ(b)+Twi,
(7)
式中:μi,μ(b)∈RCF,μi為第i條語音對應的GMM的均值超向量,μ(b)為UBM的均值超向量;C為GMM模型分量的數目;T∈RCF×D為I-Vector提取器,定義了總變化矩陣;wi∈RD為總變化空間內服從標準高斯分布的隱變量,對其進行MAP估計,即可得到I-Vector。
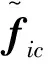
(8)
(9)
式中,γc(oit)為第c個高斯分量的后驗概率
(10)
接著可通過以下計算得到I-Vector
(11)
式中:Li為
(12)

估計總變化矩陣T的過程即為I-Vector模型的訓練過程,使用EM算法訓練模型,其中E步驟為
〈wi|Xi〉=ui,
(13)
(14)
M步驟為
(15)
式中,N為數據集中包含的語音總數。利用I-Vector模型解決短時語音與信道失配問題,并學習到信息“教”給基于ResNet的聲紋識別模型。
1.3 基于ResNet的聲紋識別設計
筆者設計的基于ResNet聲紋識別模型結構如表1所示。

表1 ResNet的具體結構
在表1中,[·,·,·]表示卷積的卷積核的大小、通道數、卷積步長。輸出大小中T為輸入特征的幀數。在每一個殘差塊后都接有批量歸一化層與ReLU激活函數。
從表1的結構中,網絡輸入是大小為(1,T,64)的張量,Fbank特征維度為64,網絡結構中的卷積層、殘差塊2、殘差塊3對輸入采取了通道數翻倍、頻率維度減半、時間維度減半的操作。全連接層1的輸出即為提取的聲紋特征,全連接層2為分類層,僅僅在訓練過程中使用,1211為訓練數據集包含的人數。
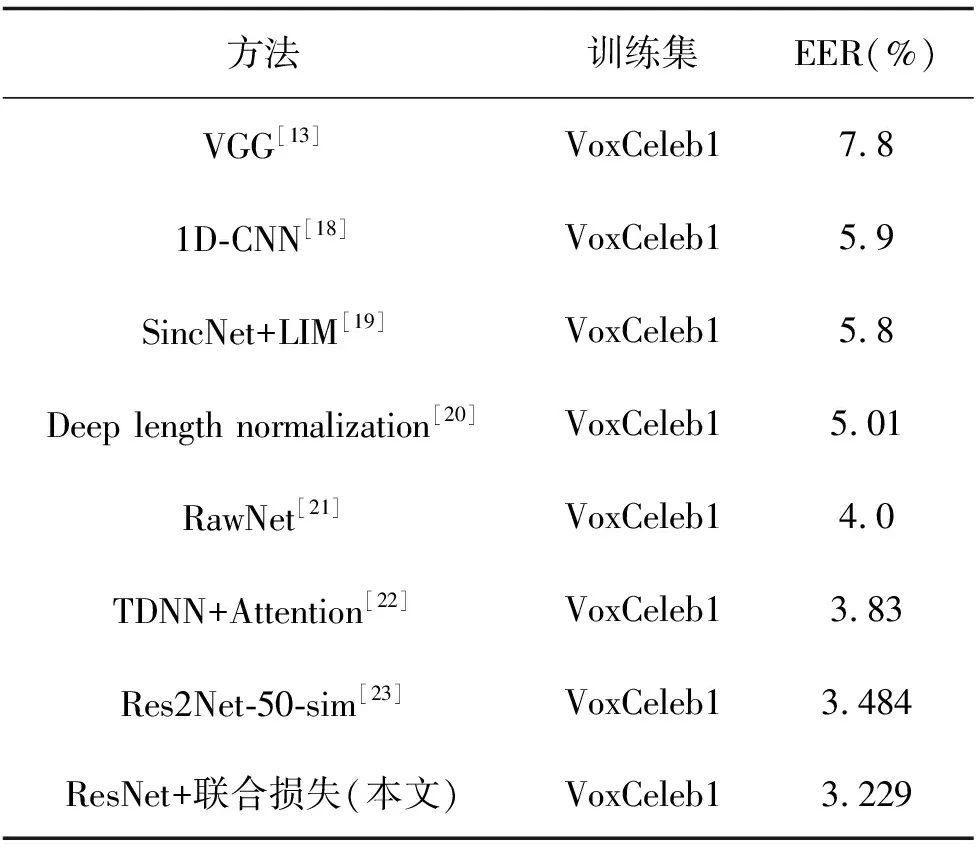
統計池化層(statistics pooling)是聲紋識別模型中所特有的結構,用來處理語音輸入序列變長問題。卷積層也可以接收不定大小的輸入,但對于不同大小的輸入,其輸出大小也會不同,但在聲紋識別任務中,需要將不同大小的特征映射至固定維度大小的聲紋特征。殘差塊將維度為F0的Fbank特征變為形狀為X∈RC×F×T的多通道特征,其中:C為通道數;F和T對應于網絡原始輸入O∈R1×F0×T0中的特征維度F0和T0,F 圖3 注意力統計池化層結構 首先為每個幀級特征計算標量分數scoret scoret=vTf(WRCt+b)+k, (16) 式中:f()表示非線性激活函數;RCt為第t個通道的特征;v,W,b,k為要學習的參數,接著利用softmax函數在所有的幀上做歸一化操作,得到歸一化分數αt: (17) (18) 通過這種方式,利用加權平均提取到的語句級特征將關注到信息量更豐富的幀,接著使用加權標準差將統計池化與注意力機制相結合 (19) 將加權平均值與加權標準差拼接后作為全連接層的輸入,提高了語句級聲紋特征的可區分性。將ResNet提取到的聲紋特征記為Embedding。 1.4.1 后端打分 使用2種后端打分策略:PLDA打分后端與余弦打分后端。 1)PLDA打分計算過程:記2條語音的I-Vector分別為u1,u2,使用對數似然比進行打分 lnN(u1|m,∑+VVT)-lnN(u2|m,∑+VVT), (20) 式中:p(u1,u2|H1)為2條語音來自同一說話人的似然函數,p(u1|H0)與p(u2|H0)分別為u1和u2來自不同說話人的似然函數。 2)余弦打分后端計算過程:記2條語音的Embedding分別為x1,x2,使用2向量的余弦距離計算得分 (21) 1.4.2 訓練損失函數 研究使用的第一種損失函數是蒸餾損失,它是I-Vector與經ResNet提取到的Embedding之間的均方誤差(MSE,mean squared error),將一個批次中的第i個樣本的I-Vector記為ui∈RD,ResNet提取到的Embedding記為xi∈RD,兩者之間的損失由以下公式計算 (22) 式中B表示一個批次的大小。通過優化這一損失,可以使ResNet提取到的Embedding向I-Vector學習,由于I-Vector服從高斯分布,與PLDA中的假設相符,所以使用這種損失可以提高以PLDA為打分后端時的聲紋識別模型性能。 第二種損失為度量學習損失,采用的為additive margin softmax(AM-Softmax)損失,它的計算過程為 (23) 最終,筆者提出一種將2種損失相結合的基于知識蒸餾的聯合損失函數 Lcombine=γLm+(1-γ)Ld, (24) 式中,γ為超參數,0≤γ≤1,可以控制2種損失之間的比例。 當單獨使用蒸餾損失MSE時,相當于使用無監督訓練,I-Vector直接與Embedding計算損失;單獨使用度量學習損失AM-Softmax時,僅使用ResNet模型訓練,未有監督訓練,未利用I-Vector進行知識蒸餾;使用聯合損失時,既使用了蒸餾損失MSE,也使用了度量學習損失AM-Softmax進行訓練。3種損失都用來更新ResNet網絡的權值。 筆者所提出的模型使用VoxCeleb1[17]公開數據集進行訓練,該數據通過一套基于計算機視覺技術開發的全自動程序從開源視頻網站中捕捉而得到,完全屬于自然環境下的真實場景,說話人范圍廣泛,場景多樣。其中包括一個驗證集和一個測試集,分別用于模型的訓練和測試,數據集的數量統計如表2所示,此外,從測試集中隨機抽取了37 720對語句用于模型的驗證。在擁有了原數據后,使用離線增強和在線增強方法對原數據進行數據增強,對比分析數據強化對實驗結果的影響。數據增強策略中的離線增強方式增加的樣本數量為100 000個,在訓練之前加入數據集;另一種是在線增強方式,頻率掩膜參數設置為10,重復次數為1次,時間掩膜參數為15,重復次數為2次,即參數F,Nf,T,Nt分別被設置為10, 1, 15和2。 表2 模型數據集統計 基準模型用于和本實驗中所設計的模型進行性能比較,從而證明本實驗中的模型有效性。實驗使用的基準模型包括I-Vector、X-Vector,2種模型均使用Kaldi框架實現。I-Vector模型的語音特征使用24維的梅爾頻率倒譜系數(MFCC, mel frequency cepstral coefficents),經過了二階差分處理、基于滑動窗口的CMN和VAD處理后為72維,所用的UBM模型具有2048個高斯分量,所得的I-Vector維度為400。X-Vector模型的語音特征使用30維MFCC,并經過了基于滑動窗口的CMN和VAD,網絡結構為5層的TDNN,說話人特征為512維,其使用了離線增強方式的數據增強方法,增強的樣本數量為100 000個,并在訓練之前加入數據集,網絡訓練所用的損失函數為交叉熵損失。2種模型均采用PLDA打分后端,并在PLDA前,使用LDA將離線增強后的數據維度降至200維并進行了L2歸一化。 本次實驗使用基于PyTorch的深度學習框架構建了所需要的ResNet模型,使用單個NVIDIA Tesla P100顯卡訓練30個迭代。使用Kaldi框架提取64維的Fbank作為輸入特征,并經過了基于滑動窗口的CMN和VAD。Cosine和PLDA打分被用于模型結果評估,其中均采用等錯誤率(EER,equal error rate)和最小檢測代價功能(minDCF, minimum detection cost function)來衡量模型的性能,等錯誤率是指當決策閾值變化時,錯誤接受率(FAR,false acceptance rate)與錯誤拒絕率(FRR, false rejection rate)相等時FAR或FRR的值,檢測代價是說話人識別中常用的一種性能評定方法,定義式為DCF=Cfr×FRR×Ptarget+Cfa×FAR×(1-Ptarget),其中Cfr和Cfa為錯誤拒絕和錯誤接受的懲罰權重,取Cfr=Cfa=1,Ptarget為目標說話人在總人群中的比例,最小檢測代價即閾值變化時,檢測代價的最小值。2種指標的值越小,表明模型性能越強。在 AM-Softmax損失函數中,縮放因子α和附加距離m分別設置為30和0.2。在訓練中,輸入被截斷或填充為3 s的長度,以形成大小為128的小批量數據。使用初始學習率為0.001的Adam優化器,將驗證集數據用于檢驗訓練效果,當驗證集上的結果沒有得到改善時,將學習率衰減到之前的1/2。 如表3所示。其中DCF(0.01)表示檢測代價函數中的p-target參數為0.01,基準模型都使用了交叉熵損失函數。 表3 基準模型實驗結果 ResNet基準模型的性能具有較好的穩定性,在余弦打分后端和PLDA打分后端下的結果相差不大,在余弦打分下的實驗結果相較X-Vector和I-Vector模型有很大的提升。ResNet基準模型采用在線增強后,PLDA打分下的實驗結果優于ResNet基準模型,而余弦打分下的實驗結果變化不大。ResNet基準模型采用離線增強后,在2種打分方式下,所有性能指標相較于ResNet基準模型都有了很大的提升,并且同樣優于采用在線增強方式的ResNet基準模型。因此對于同樣的數據處理流程,離線增強方式更為復雜,但能獲得更好的結果,在線增強方式計算速度快,仍然值得嘗試。 采用知識蒸餾技術的ResNet模型使用了MSE損失函數,基于度量學習的ResNet模型損失函數使用AM-Softmax,從表4可以看出,針對知識蒸餾技術優化的損失方法,ResNet模型結果明顯優于I-Vector基準模型,因為ResNet是從I-Vector中提取和學習部分相關參數且得到了更好的結果,這證明了ResNet方法和蒸餾損失方法結合的有效性。采用基于度量學習的損失函數AM-Softmax得到的模型結果優于I-Vector基準模型和采用知識蒸餾技術得到的模型結果。因此,考慮采用聯合訓練的方式來提升實驗效果。 表4 三種模型的對比實驗 在聯合訓練中,使用的模型都是ResNet模型,采用在線增強進行數據增強,從上表可看出,γ分別取0.2、0.1、0.05,γ控制這2個損失之間的比例,通過減小γ來強調蒸餾損失。結合表4和表5可以看出,針對損失函數,使用MSE損失和AM-Softmax損失聯合訓練的方法能夠很大程度的提升模型的結果,實驗結果還表明,AM-Softmax損失有助于提高模型在Cosine打分下的性能,而MSE損失有助于提高模型在PLDA打分下的性能。 表5 聯合訓練實驗結果 模型集成是指通過分數融合的方式,集成采用MSE損失函數和AM-Softmax損失函數的2種模型,2種模型使用離線增強,將它們測試集的打分結果進行加權平均,然后再計算EER等性能指標。 從表6中可以看出,在余弦打分后端與PLDA打分后端下,模型集成的性能均略低于聯合訓練方式,2種訓練方式實驗結果相差不大,但相比于模型集成需要訓練多個模型進行集成,而聯合訓練只需要一個模型,節約了計算資源,更加高效。 表6 模型集成的實驗結果 結合以上實驗可以得出性能最好的是采用數據增強和聯合損失的網絡結構,表7展示了和其他論文中同樣使用VoxCeleb1數據集的說話人識別方法的實驗結果的比較。 表7 與其它方法對比的實驗結果 從表7可以看出,提出的方法與其他方法對比,EER最低降低了8%,達到了3.229%,性能均優于表中提到的其他方法。 提出了一種基于知識蒸餾與ResNet的聲紋識別方法。將傳統無監督聲紋識別方法與基于深度學習的聲紋識別方法相結合,用蒸餾損失MSE約束ResNet聲紋特征和I-Vector的差異,提高了聲紋識別的準確率。此外,研究進一步采用了2種不同數據增強方式對數據集進行擴充,增強了模型對噪聲環境的適應性,提高了系統的魯棒性,驗證了2種增強方式在聲紋識別任務中的有效性。設計的ResNet模型包括了注意力統計池化,結合知識蒸餾損失與度量學習損失設計了新的聯合訓練損失,相較于模型集成的方法,在2種打分后端下,聯合訓練方法的EER均低于模型集成方法。構建了端到端的聲紋識別模型,與大多數基于深度學習的方法相比,能夠將EER進一步降低為3.229%。
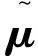
1.4 基于知識蒸餾的聯合訓練

2 實驗與結果分析

2.1 基準模型
2.2 模型訓練
2.3 主要實驗結果分析


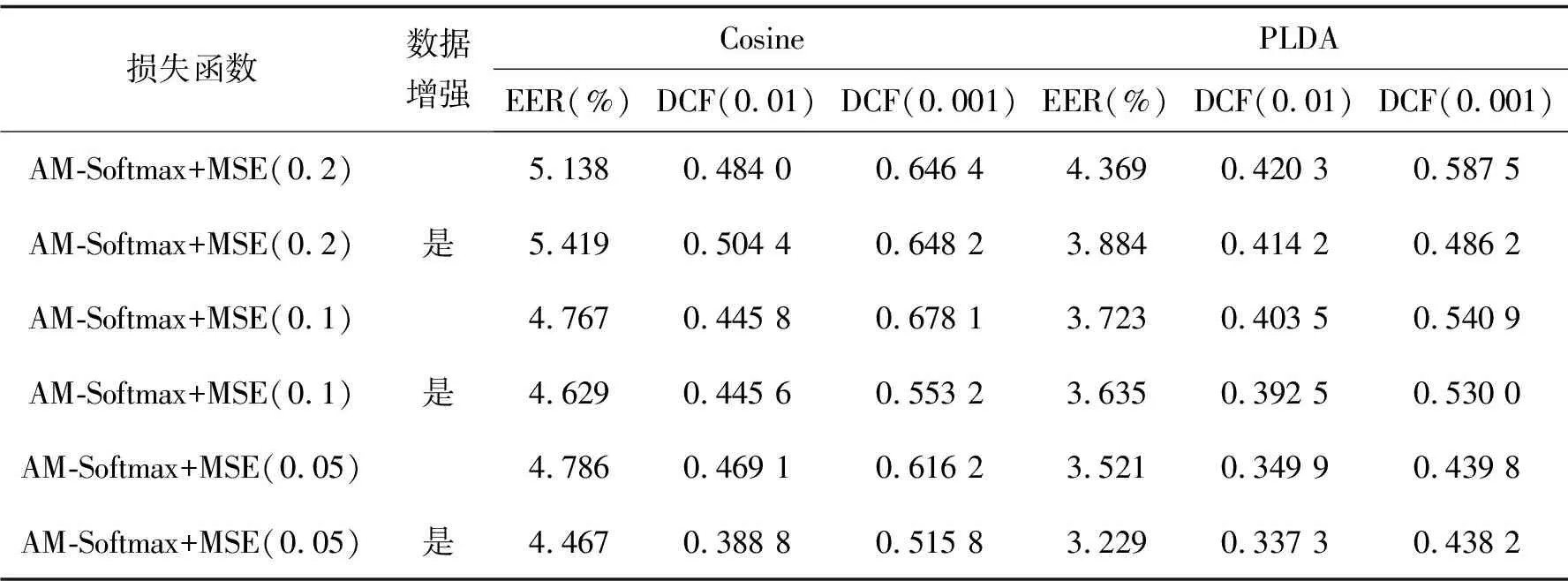
2.4 聯合訓練與模型集成的對比

2.5 與其他方法的對比
3 結 語
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
