一種針對維漢的跨語言遠程監督方法
2023-02-20 09:39:30楊振宇王磊馬博楊雅婷董瑞艾孜麥提艾瓦尼爾王震
計算機工程 2023年2期
楊振宇,王磊,馬博,楊雅婷,董瑞,艾孜麥提·艾瓦尼爾,王震
(1.中國科學院新疆理化技術研究所,烏魯木齊 830011;2.中國科學院大學,北京 100049;3.新疆民族語音語言信息處理實驗室,烏魯木齊 830011)
0 概述
關系抽取是自然語言處理領域的重要任務,主要是以深度學習模型為主。但是基于深度學習模型的性能通常受到訓練語料規模的限制,并且人工構造語料的過程成本過高。語料匱乏是低資源語言在關系抽取領域沒有得到有效發展的重要原因。遠程監督方法正是為了解決語料稀缺問題而提出的。
2009年,MINTZ等[1]將弱監督方法引入到語料構造中并提出了遠程監督方法,主要思想在于通過文字查找的方式將大量的無標注語料與現有少量的已標注語料進行實體對齊并向無標注語料遷移標記,以達到快速擴充語料的目的。遠程監督可以分為2 個步驟:通過實體文字查找的方式對齊語料并構造偽標注語料,以及利用有噪聲偽標注語料訓練性能較好的關系抽取模型。后續也有許多學者在這一領域做出了優秀的工作。例如:ZENG等[2]將多示例學習引入到遠程監督方法中,把偽標注語料分為幾個句包并讓句包作為新的數據單元,以減少偽標注語料中的噪聲對模型訓練的影響;LIN等[3]通過提出軟注意力機制有效提升了模型的性能。現有絕大部份工作都是圍繞著如何利用有噪聲的偽標注語料提升模型的性能。但是遠程監督的第一步仍有2 個缺陷:要求該語言已有部分標注語料,以及實體查找的對齊方式只能在單語種的問題中實現。這導致像維吾爾語這樣缺乏標注語料的語言無法使用該方法構建語料。
針對上述問題,本文提出一種針對維漢的跨語言遠程監督方法,在維語零語料的條件下利用已有的漢語標注語料實現自動擴充。在關系抽取任務中,帶有同一實體對并且為同一關系的2 個句子在語義表示層面要比其他的句子更加相似。因此,本文提出使用語義相似度計算替換傳統遠程監督方法中的實體查找,使遠程監督可以脫離語種的限制實現跨語言本文對齊。首先借助維漢已有的平行語料構造維漢相似度語料,用于訓練維漢相似度模型;然后向模型分別輸入維漢句子對,其中漢語是帶標注的句子而維語是無標注的句子。模型將2 個句子映射到同一語義向量空間,從句子語義和實體語義2 個層面綜合衡量雙語句子對是否包含同一三元組。當結果的概率超出閾值時,模型就認為漢維2 個句子包含同一關系,將漢語句子的關系標簽轉移到維語句子上以實現維語偽標注語料的構建。為了更有效地捕捉實體的上下文和隱藏語義信息,本文提出一種帶有門控單元的交互式語義匹配方法。在此方法中,融合層將編碼層和注意力層進行拼接融合以最大限度地獲取句子中間信息。此過程中添加的遺忘門和輸入門這2 個門控單元用于保留最有用的信息使模型更好地判斷語料是否對齊。
1 相關工作
本文將文本相似度計算方法與遠程監督的思想相結合,使遠程監督可以跨語言地構建偽標注語料。
1.1 遠程監督
遠程監督一直受到自然語言處理領域學者的廣泛關注。多示例學習是遠程監督的一個主流方法,其基本思想在于將同一關系的所有句子放在一個句包中,并以句包作為數據單位進行預測。HOFFMANN等[4]提出的多示例學習方法將每個句子分配關系數量的隱變量用于進行錯誤標簽的預測。SURDEANU等[5]在HOFFMANN 方法的基礎上進行了改進,通過計算句包與各個關系之間的相似度代替關系預測,并使用貝葉斯模型對參數進行學習。JAT等[6]在傳統的多實例學習基礎上添加了單詞級別的注意力,對句子中每個單詞分配權值,使模型可以利用更加細粒度的信息完成關系預測。YANG等[7]認為實體和關系信息可以互相幫助,并提出了使用矩陣整合實體和關系信息的方法以提升模型的性能。YE等[8]改進了JAT 的注意力方法,在單詞注意力的基礎上添加了句包之間的注意力機制,進一步提升了模型的性能。除多示例學習外,對抗學習也是遠程監督的重要方法,其可將訓練集中存在錯誤標記的句子進行排除以提升模型的訓練效果。WU等[9]將正確的數據樣本與對抗樣本同時輸入到模型進行對抗訓練,使模型可以辨別出正確樣本以減少語料的噪聲。LI等[10]在WU 等思想的基礎上通過實體鏈接技術引入外部知識幫助模型確定是否為正確的樣本。HAN等[11]則通過后處理的方式改善WU 等的方法,其將偽標注語料分成了置信集和非置信集并將模型判斷置信度高的數據不斷補充到置信集中,直到2 個數據集都不發生變化為止。
1.2 文本相似度計算
文本相似度計算旨在脫離文本的表示形式并根據文本的語義特征來確定句子之間是否具有某種關系,是語言處理領域重要的基礎任務。有許多研究人員在這一領域取得了優秀的成果。HUANG等[12]提出了深層結構的潛在語義模型,將文本對投影到一個公共的低維空間中以計算它們之間的距離。SEVERYN等[13]將傳統相似度方法與深度學習模型相結合,把卷機神經網絡引入到相似度計算中使模型可以更加準確地獲得文本特征并對所有候選的文本對重新排序。YIN等[14]在SEVERYN 卷積網絡的基礎上添加了注意力機制,提出了將3 種注意力機制與卷積神經網絡進行融合的方法,使注意力機制可以在不同的層面帶來不同的作用以提升模型的性能。WANG等[15]改變了之前大多數模型從單一的角度去匹配文本的方法,采用4 個角度進行雙向匹配,并采用了matching-aggregation 的結構對2 個句子之間的單元做相似度計算。CHEN等[16]基于鏈式LSTM 的推理模型改善了之前工作復雜的模型結構,利用遞歸架構設計模型的邏輯順序以在局部推理建模和組合推理方面優化模型。GONG等[17]對CHEN 等的工作進行了改進,在模型的輸入層添加了字向量、詞向量以及多種額外特征以提升模型性能。KIM等[18]受到DenseNet網絡[19]的啟發,在GONG 等工作的基礎上提出了一種密集連接的共同注意力遞歸網絡,將每一層的注意力信息都進行串聯,使當前注意力層都能遞歸地得到先前層的隱藏信息,并使用自編碼器緩解串聯過多導致的數據維度過大的問題。
2 維漢跨語言遠程監督
本文跨語言遠程監督方法的基本思想是從句子語義和實體語義2 個層面來衡量維漢句子對是否包含同一三元組,可以使維語語料在零資源情況下借助已標注的漢語語料進行自動擴充。句子語義層面的方法使用具有豐富知識的多語言預訓練模型獲取句子的語義信息。在實體語義層面,本文提出了帶有門控機制的交互式匹配方法,可以控制迭代過程中信息的保留,并且更有效地獲取實體之間的隱藏信息。
2.1 問題表述和模型概述
下面給出遠程監督問題的形式化描述。給定一個已標的語料庫:G=(T1,R,T2),其中,T1表示語料中的頭實體集合,R表示實體之間的關系集合,T2表示語料中的尾實體集合。現有一個無標記文本S和文本中的實體對h1、h2。若同時滿足h1∈T1、h2∈T2、(h1,r,h2)∈G,則認為語料庫中的三元組(h1,r,h2)與無標記文本S對齊,其中r∈R。
在傳統的遠程監督方法中,主要是用實體文字查找的方式判斷條件h1∈T1和h2∈T2是否成立。這種判斷方法也導致遠程監督只能應用于同一語種,而本文的方法使用文本相似度計算代替文字查找。圖1 顯示了本文跨語言遠程監督方法的整體框架。模型包括3個關鍵部分:1)帶有實體信息的維漢相似度語料構建;2)句子層次語義相似度計算;3)實體層次語義相似度計算。
2.2 帶實體信息的維漢相似度語料構建
語料對基于深度學習的方法來說十分重要,但是維漢句子相似度語料十分稀少,特別是模型所需要的語料是帶有實體信息的句子相似度語料。然而維漢有比較成熟的維漢平行語料,這也是本文工作為何針對維漢的重要原因。AZMAT等[20]發現,使用“《》”框住漢語句子中的實體并翻譯成維語,翻譯后的維語依然保留實體周圍的“<>”符號。這一方法可以將漢語的實體識別結果遷移到維語平行句子中。受到這一工作的啟發,本文方法使用機器翻譯領域已有的維漢平行句子進行相似度語料的自動構建,步驟如下:
1)使用已有的維漢平行語料訓練出一個機器翻譯模型。
2)使用漢語命名實體識別工具將用于訓練的維漢平行語料中漢語句子所包含的實體識別出來,并用“《》”進行包裹。
3)為了保證機器翻譯的準確性,步驟1)中的機器翻譯模型對帶有“《》”符號的漢語句子進行翻譯,得到使用“<>”包裹實體的維語句子。因為是翻譯已經訓練過的漢語句子,所以結果的準確度會很高。
4)為了保證實體翻譯的準確性,翻譯后的實體在已準備好的維語的字典中進行查找,若找到則認為翻譯正確。
2.3 句子層面的語義相似度計算
句子編碼器的目標是從句子對的信息中提取特征并輸出每一個單詞的特征編碼以對結果進行預測。為了將維漢2 個句子特征映射到同一個空間中,本文方法使用了多語言預訓練模型作為句子層面語義編碼器以提取句子對的特征。向編碼器輸入的文本為:C=ScSu,其中,Sc表示漢語句子,Su表示維語句子。在訓練過程中,預訓練模型隨機掩蔽或替換一些單詞,并通過上下文預測來學習單詞的深層表征。本文將預訓練語言模型表示為R(x)并將模型的每一層表示為T(x),具體操作過程可以表示為:

模型的每一層操作可以表示為:
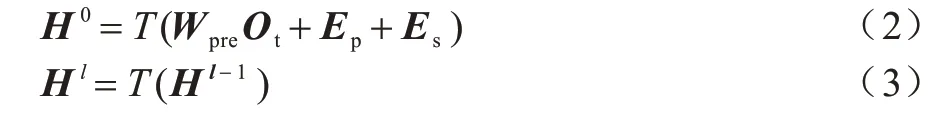
其中:Et是單詞編碼;Ep是位置編碼;Es是分句編碼;Ot是輸入詞的一個one-hot 編碼;Wpre是預訓練模型的編碼的權重。
2.4 實體層面的語義相似度計算
與普通的句子相似度計算不同,遠程監督不僅要考慮句子的關系信息,而且也要確定三元組中的頭實體和尾實體是否對齊。為了更好地獲取實體的上下文信息和隱藏信息,本文提出了帶有門控機制的交互式匹配方法,分為4 個重要的部分:1)帶有相對位置信息的注意力層;2)共同注意力層;3)帶有門控機制的信息融合層;4)池化層。下面將詳細介紹每一層的操作。
2.4.1 維語實體標記
由于是在無標簽的維語句子中構造偽標注語料,因此需要將維語句子中的實體標記出來。在實體標記過程中,模型采用二進制分類器,對每一個維語單詞分配一個二進制標記(0/1)來分別檢測實體的開始和結束位置,該標記指示當前標記是否對應于實體的開始或結束位置,并且為了防止句子存在復雜三元組使模型的性能下降,模型在標記實體的過程中保留了可能性最大的2 個頭實體和2 個可能性最大的與頭實體相對應的尾實體。換言之,標記結果保留了4 個候選三元組以提高模型的召回率。頭實體標記器的具體操作如下:

其中:Ph_start和Ph_end分別表示維語句子中單詞為頭實體的開始和頭實體的結尾的概率,當預測的結果超出規定的閾值,此位置的值為1,否則值為0;Wh_s和Wh_e代表標記器的權重;bs和be代表偏移量。同理,模型在頭實體標記的基礎上對尾實體進行標記,具體操作如下:
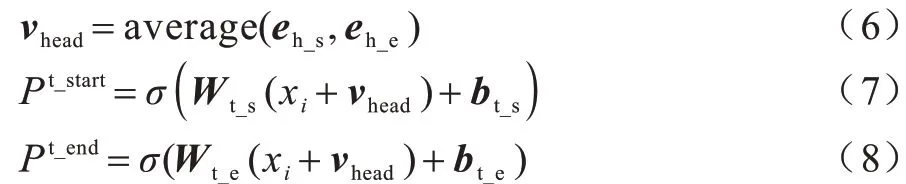
其中:Pt_start和Pt_end分別表示維語句子中單詞為與式(4)、式(5)得到的頭實體對應的尾實體的開頭和頭實體的結尾的概率;eh_s和eh_e分別表示頭實體開頭和結尾的單詞特征向量;Wt_s和Wt_e代表標記器的權重;bt_s和bt_e代表偏移量。
2.4.2 帶有相對位置信息的注意力層
在維語和漢語的句子中,單詞語序是一致的,只不過漢語是從左到右書寫而維語則相反。因此,實體的相對位置信息對于模型判斷實體對是否匹配至關重要。受機器翻譯中相對位置表示[21]的啟發,本文方法在漢語和維語句子編碼器的輸出層中添加了一個帶有可學習相對位置信息的注意層。
在注意機制的基礎上,雙語句子對增加了頭實體與尾實體的相對位置信息。具體來說,為了獲得更全面的位置信息,模型通過2 個向量來表示每個單詞之間的相對位置編碼,并在計算實體單詞的注意編碼時學習字符級別的相對位置信息。為了描述簡練,本文使用漢語句子中的實體作為例子進行描述,維語實體采用完全相同的操作。本文使用向量和來表示頭實體H和其他單詞之間的相對位置信息,同理,使用和表示尾實體的信息。相對位置向量<,>和<,>分別添加到注意力中的鍵和值的計算過程中。頭實體具體操作如下,尾實體采用相同的操作:
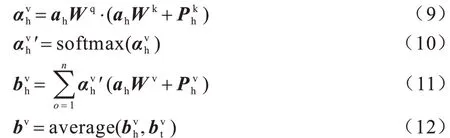
其中:Wq、Wk、Wv分別表示注意機制中查詢、鍵和值的權重矩陣;ah是頭實體的單詞編碼;是帶有相對位置信息的尾實體特征表示。相對位置有一個限制,即當單詞的相對距離超過設置的最大長度時將其視為最大距離。本文方法設定的最大距離是50,具體操作如下:

其中:Lmax代表最大距離;h代表頭實體的位置;o代表其他實體的位置。
2.4.3 實體對共同注意力(Co-Attention)層
如果文本對中出現語義高度相似的實體,計算注意力權重時這個實體會獲得比其他普通單詞更大的權重。受到LU等[22]圖片-文本匹配工作的啟發,模型利用共同注意力機制計算漢語與維語實體對中單詞的注意力權重。首先將同一語言的頭實體和尾實體進行拼接以得到漢語的實體對表示矩陣V和維語的實體對表示矩陣U;然后計算漢維實體對的親和矩陣C;最后使用softmax 函數進行歸一化得到注意力權重。但是不同于LU 等對圖像-句子對分別加權求和,本文通過注意力權重使2 種語言的實體對相互表示,具體操作如下:
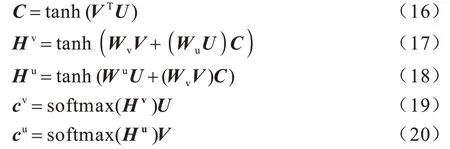
其中:Wv和Wu分別表示計算相似度時的權重;cv和cu分別為注意力操作之后的漢語和維語實體特征向量。
2.4.4 帶有門控機制的信息融合層
為充分利用模型信息傳遞隱藏信息,本文在模型中設置了一個帶有門控機制的信息融合層。融合層分別將帶有相對位置信息的實體特征和共同注意力層輸出的實體特征進行融合。具體來說,融合層計算bv和cv的差值和點乘結果以幫助增強實體中元素之間的隱藏信息。
為更準確地挑選出有用的信息,本文方法在信息融合后添加了2 個門控單元對信息進行處理。具體來說,本文在信息融合層中設置了一個輸入門和一個遺忘門,其中輸入門用于決定什么值將要更新;遺忘門用于決定什么值將要遺忘,并使用一個tanh函數創建新的候選向量。門控單元的結構在圖2 中展示,具體操作如下:
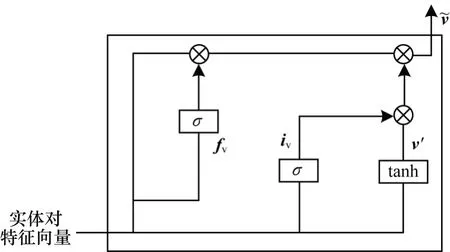
圖2 門控單元結構Fig.2 Structure of the gate unit
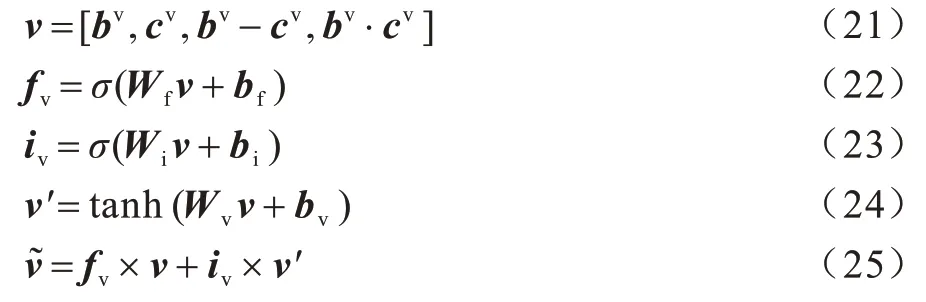
其中:fv和iv分別表示遺忘門和輸入門的結果;Wf和Wi分別輸入門和遺忘門的權重。使用同樣的方法得到維語實體特征向量進行融合后的結果。
2.5 池化層
為全面地提取實體的特征,模型通過平均池化和最大池化來提取維語和漢語每個實體對的特征。為使實體特征融合句子的全局特征而不是周圍單詞的特征,模型將多語言預訓練模型中的句子特征作為維漢句子對的特征連接到實體向量中再進行分類。模型通過句子對相似的概率來表示分類結果,具體操作如下:
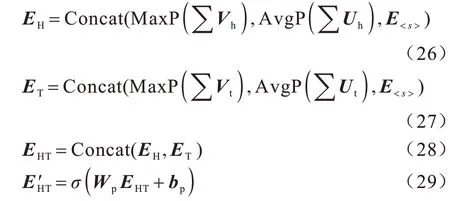
其中:MaxP 表示最大池化;AvgP 表示平均池化;Vh和Vt分別表示漢語句子中的頭實體和尾實體特征向量;Uh和Ut分別表示維語句子中的頭實體和尾實體特征向量;E<s>表示預訓練模型輸出的句子對特征向量。
3 實驗與結果分析
3.1 數據準備
通過實驗驗證本文方法的有效性。實驗數據準備如下:
1)維漢平行語料數據集:為獲得高質量的維漢雙語語料來訓練語義相似度計算模型,本文工作所用到的維漢平行語料數據集分別來自于CWMT2013官方語料,其中包含109 000 個平行句子,在此基礎上,使用2.2 節中介紹的方法構造67 000 條帶有實體信息的維漢相似度正樣本語料,并且為了更好地訓練模型,本文從正樣本語料中隨機挑選出包含不同三元組的句子對構造70 000 條負樣本語料。
2)詞典:本文使用漢維雙語詞典翻譯實體,該詞典包含32.8 萬個獨特的中文術語和53.1 萬個獨特的維吾爾術語。
3)維語無標注語料:為了獲得規范的維語單語語料,本文從天山網站(http://uy.ts.cn/)抓取30 萬條維語句子作為構造偽標注語料的基礎。
3.2 實驗結果
本文研究的目的是在沒有維語關系抽取語料的條件下,利用漢語已有的標注語料實現維語語料的自動填充。為了證明本文方法的有效性,選取15 種關系的三元組并且人工標記3 500 條維語句子和600 條漢語句子。每個關系的三元組分別分配帶有此關系三元組的200 條維語句子和40 條漢語句子,另外500 條沒有包含范圍內的三元組,將其作為負樣本。在測試中,將漢語句子和維語句子兩兩組合計算相似度并將模型結果對比人工標記以判斷模型結果是否正確。實驗使用精確率(Precision,Prec)、召回率(Recall-weighted,Rec)、F1 值(F1-weighted,F1)3 個指標綜合評價模型性能。
3.2.1 多語言預訓練模型對比結果
為獲知哪種多語言預訓練模型更加適合本文的方法,分別挑選3 種同時帶有漢語和維語信息的多語言預訓練模型作為句子編碼器:LASER,XLM,XLMRoberta。
1)LASER[23]是ARTETXE 等為了使低資源語言有效利用其他語言的資源所提出的多語言模型。模型中使用BiLSTM[24]作為編碼器與輔助解碼器相結合并讓所有語言共享一個BPE 詞匯表。LASER 包含93 種低資源語言并使這些語言的模型在豐富資源語言的基礎上達到更好的效果。
2)XLM[25]是由LAMPLE 等在BERT[26]模型的基礎上針對多語言進行優化的編碼器。XLM 可以使各個語言的詞匯共享同一特征空間。XLM 在訓練過程中輸入2 種語言的句子并用一個語言的上下文信息去預測另一個語言被遮住的token。
3)XLM-Roberta[27]是由CONNEAU 等提出的大體量多語言預訓練模型,其使用2.5 TB 的文本數據進行訓練包含了100 種語言,其中維語文本為0.4 GB。這一模型繼承了XLM 的訓練方法,也借鑒了Roberta[28]的思想,將掩碼單詞的學習作為唯一目標而舍棄了對下一句的預測。
計算結果在表1 中展示,加粗表示最優值,從表1 的結果中可以看出,使用XLM-Roberta-large 預訓練模型得到了更好的效果,但是由于XLMRoberta-large 模型的參數體量比較大,訓練過程需要花費更多的時間和更好的設備。反觀XLM-Robertabase 訓練代價較低也可以取得較好的成果。而XLM 和LASER 的結果并不理想。
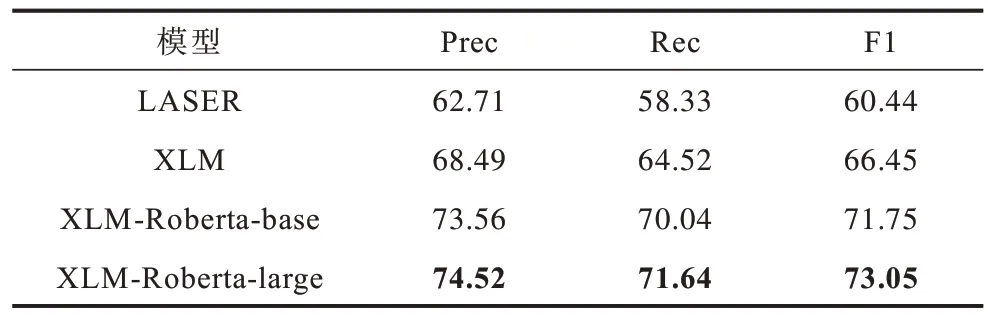
表1 主流多語言預訓練模型相似度計算結果 Table 1 Similarity calculation results of mainstream multi-lingual pre-training models %
3.2.2 與傳統遠程監督對比結果
為使本文方法可以與傳統的遠程監督方法在跨語言情況下進行對比,以證明其有效性,設計了2 種可以跨語言的傳統遠程監督方法:
1)將已標注漢語語料中的實體通過谷歌翻譯系統(translate.google.cn/)得到維語的實體表示,然后再用傳統遠程監督方法在3 500 條維語測試集中進行實體查找。若查找成功則將結果與人工標簽對比以驗證結果是否正確。
2)使用2.2 節構建的維漢平行語料訓練GIZA++實體對齊工具[29]。GIZA++可以得到雙語句子對中單詞的對應關系以實現實體對的查找。同樣將對齊結果與人工標記相對比驗證是否正確。
表2 給出了以上2 種基線方法與本文跨語言遠程監督方法的對比結果,加粗表示最優值。
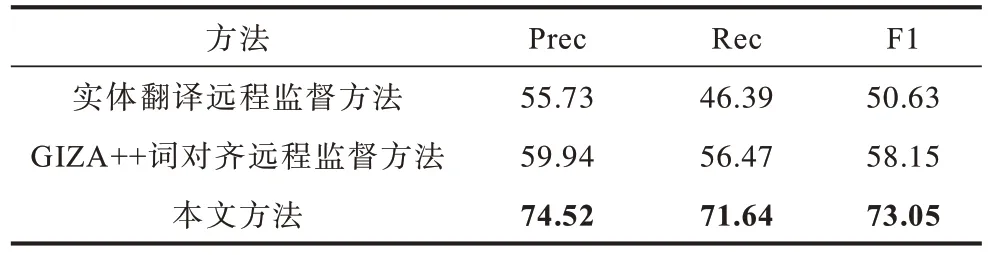
表2 遠程監督方法對比結果 Table 2 Comparison results of distant supervision methods
從表2 的結果中可以看出,實體翻譯的遠程監督和詞對齊的遠程監督方法都有著明顯的缺陷。實體翻譯的遠程監督結果的錯誤主要因為:漢語實體在翻譯過程中對應多種維語的表現形式,很難準確翻譯到維語句子中的實體;維語是黏著語導致維語實體單獨的拼寫和句子中的拼寫是不一致的,這也增加了單詞查找的困難。詞對齊的遠程監督結果的錯誤主要因為訓練對齊工具的語料無法覆蓋所有的測試集,當出現未知實體時對齊結果往往是錯誤的。以上的分析說明了本文的跨語言遠程監督方法在維漢三元組匹配場景下有明顯的優勢。
3.2.3 單一關系匹配結果
為了更加全面地檢測模型的性能,將包含15 種關系的三元組的語料分別作為測試集,以測試模型對單一關系的三元組的識別性能,具體結果在圖3中進行展示。圖3 的結果表明,本文所提出的跨語言遠程監督模型在漢語和維語句子對匹配方法上也取得了較好的結果。從具體的關系種類的角度可以看出,當關系為“國籍”、“首都”、“面積”等時,模型會得到較好的效果。筆者認為是因為在上述關系的三元組中存在明顯的實體,比如“國籍”關系中一定會有一個國家在三元組中出現,“面積”關系中也一定會有一個數字與之對應。但是反觀模型在“導致”、“創始人”、“組成”等關系的三元組識別上取得了較低的效果,這也是因為這些關系的三元組中并沒有一個明確的實體出現,也增加了模型中匹配時的難度。因此,識別這一類三元組也是今后工作的一個重點。
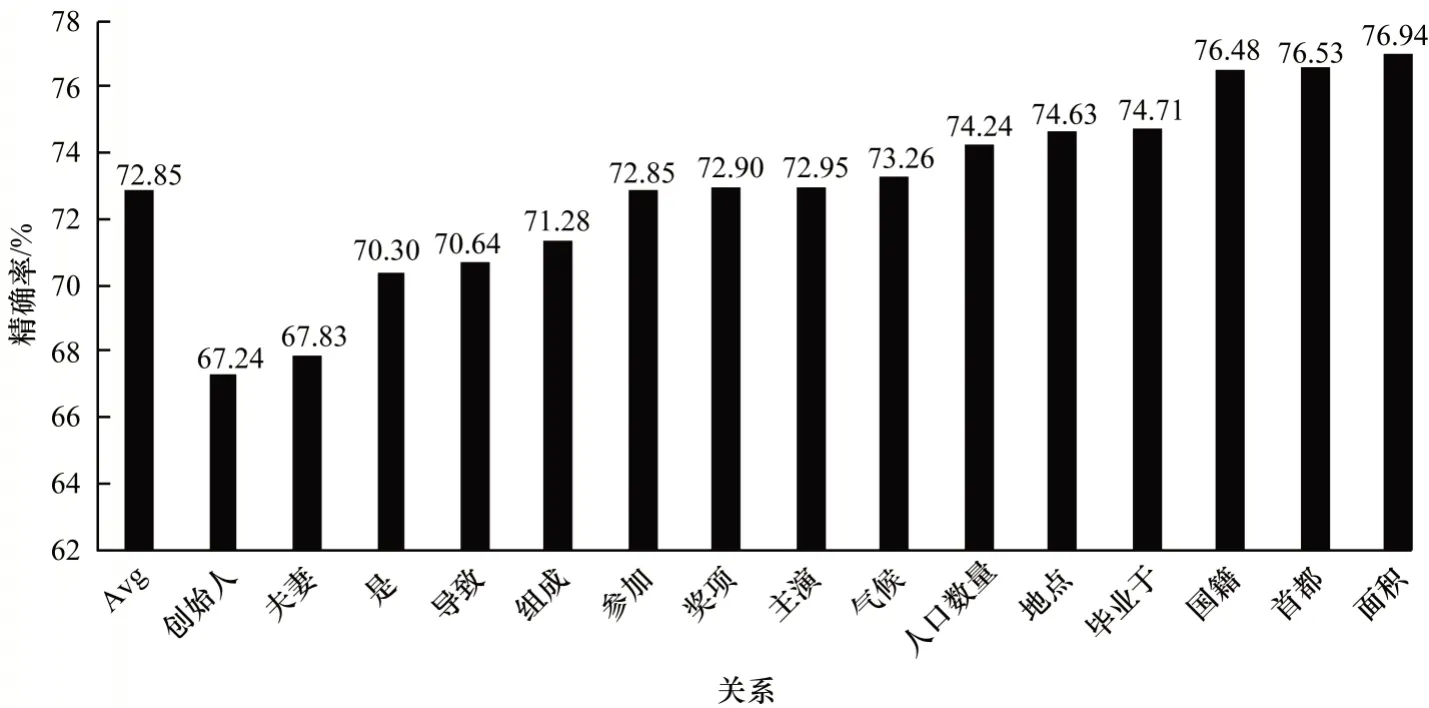
圖3 使用XLM-Roberta-large 語言模型的跨語言遠程監督精確率Fig.3 Cross-lingual distantly supervised precision using the XLM-Roberta-large language model
3.2.4 消融實驗
為了評估模型各部分對結果的貢獻,本文在測試集上進行了消融實驗。從完整的模型開始,每次移除模型的部分結構并觀察該結構對結果的影響:1)去除帶有相對位置信息的注意力層,只保留從多語言與訓練模型獲取詞向量信息;2)去除共同注意力層并直接將維漢2種語言的實體向量進行拼接;3)去除門控單元對數據的過濾,并改為拼接后的實體信息直接輸出;4)將原來的Maxpooling和Averagepooling替換為直接拼接實體中的單詞嵌入。消融實驗的結果如表3所示。
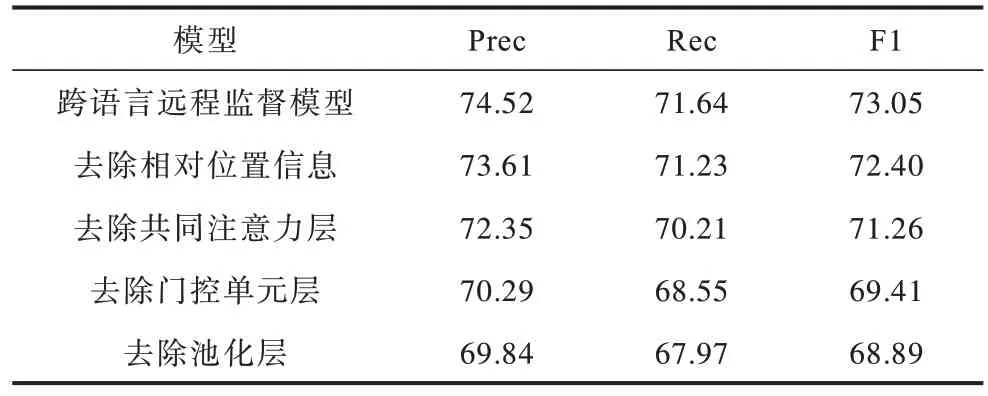
表3 針對維漢的跨語言遠程監督模型消融實驗結果 Table 3 Ablation experiment result of cross-lingual distant supervision model for Uyghur and Chinese %
3.2.5 維語偽標注語料構建結果
本文所提出的跨語言遠程監督方法的目的是在維語沒有關系抽取語料的情況下,利用漢語已有的標注語料自動構建維語偽標注數據。所構建的偽標注語料會對維語關系抽取技術的發展起到一定的推動作用。
為了展示本文工作中語料構建的最終結果,實驗以之前獲取的30 萬條維語無標注語料為目標,通過本文提出的跨語言遠程監督方法識別維漢對齊語料并將已有的漢語語料的標簽遷移到維語無標注語料中,以實現維語偽標注語料的自動構建。在構建過程中,本文針對15 種關系進行漢語與維語的語料對齊。最終的實驗結果是構建了由97 949 條維語句子組成的偽標注語料。維語偽標注語料的結果在圖4 中進行展示。
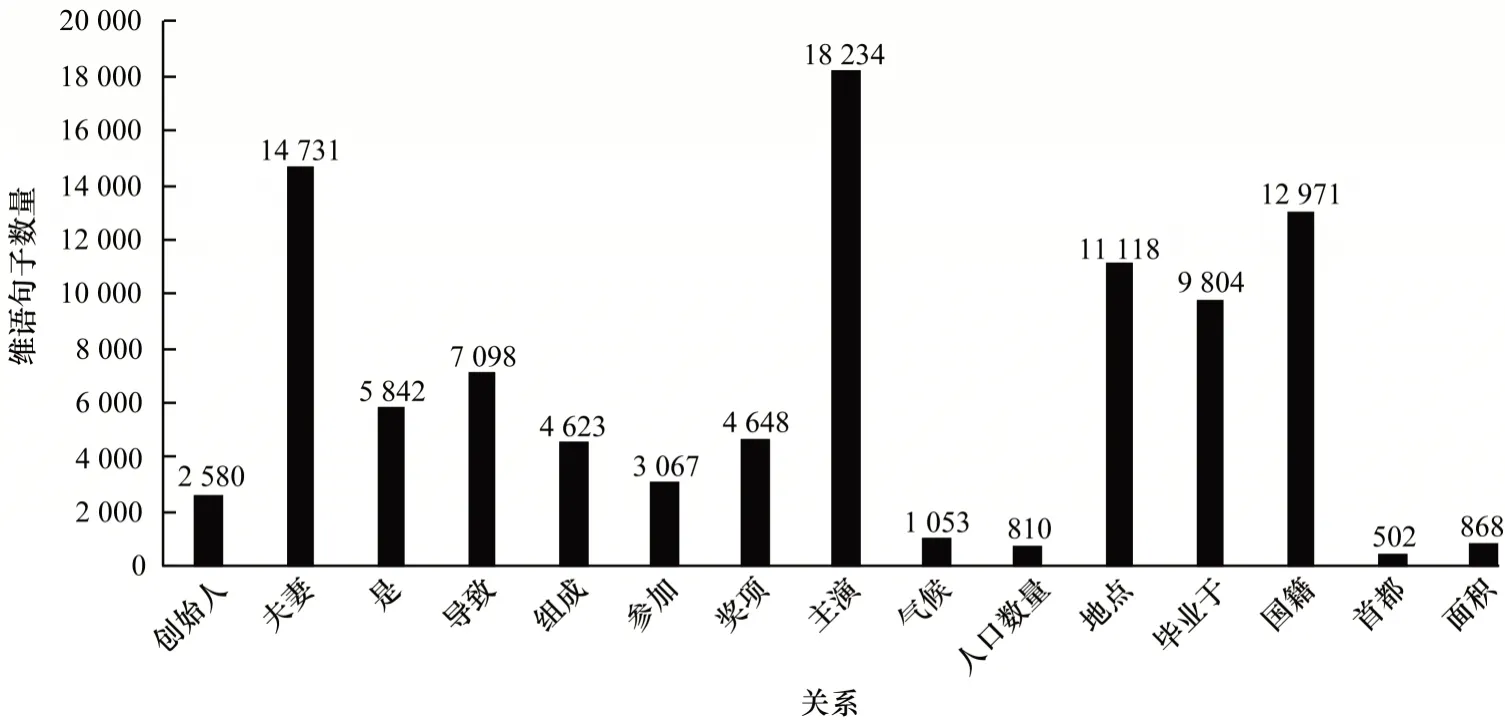
圖4 維語偽標注語料構建結果Fig.4 Results of Uyghur Pseudo-labeled corpus construction
4 結束語
本文提出了針對維漢的跨語言遠程監督方法用于緩解維語缺少關系抽取語料的問題,主要難點是如何利用語義相似度來實現遠程監督任務中三元組對齊的功能。為了得到準確的維語偽標注語料,本文利用維漢平行語料構建帶有實體信息的相似度語料,并且在句子相似度和實體對相似度2 個層面對雙語句子對的三元組是否對齊進行打分。在實體對相似度計算中,提出使用門控機制保留最有用的特征信息。實驗結果表明,本文方法可以較好地完成維漢三元組對齊工作。模型成功通過該方法在15種關系上構建了97 949條維語關系抽取偽標注語料。由于相似度語料的限制,本文只在維漢跨語言領域進行實驗。后續的工作是將本文方法應用于更多的語言以證明其有效性,并且考慮到語義相似度計算會引入更多的噪聲,因此也會將降噪的思想加入到模型中。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2020年4期)2020-05-30 12:35:30
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
