雙向信息交互的道路場景全景分割網絡
2023-02-23 08:29:20劉博林黃勁松
導航定位學報 2023年6期
劉博林,黃勁松
雙向信息交互的道路場景全景分割網絡
劉博林,黃勁松
(武漢大學 測繪學院,武漢 430079)
為了進一步研究道路場景的全景分割功能,為自動駕駛車輛全面感知環(huán)境提供支持,提出一種雙向信息交互的全景分割網絡:通過主干網絡進行特征提取,并將特征分別輸入到語義分割分支和實例分割分支;然后在分支間增加實例增強信息模塊、語義增強信息模塊以增強信息交互;最后采用改進的融合算法將語義結果和實例結果融合,得到全景分割的預測結果。實驗結果表明,設計的雙向信息交互模塊能夠提高全景分割網絡的性能,在Cityscapes數(shù)據集上采用512×1 024個像素分辨率的圖像情況下得到了46.8的全景質量(PQ)分數(shù)。
全景分割;自動駕駛;多任務學習;信息交互;語義分割;實例分割
0 引言
全景分割[1]旨在識別圖像中的所有事物,賦予其類別標簽和實例標識(identification,ID)。在全景分割任務中,圖像類別標簽可分為2類,即things和stuff。things是可計數(shù)的物體,例如車輛、行人等。而stuff是由剩余類別組成,一般不可計數(shù),例如天空、道路和水。全景分割可以看作實例分割和語義分割結果的融合。語義分割與實例分割是計算機視覺中的經典任務,語義分割任務是將圖像中的每個像素分類,賦予每個像素類別標簽,既包含things類,也包括stuff類;實例分割更關注圖像中物體級別的檢測,其目標是檢測每個物體并用分割掩碼來表示,實例分割任務只關注圖像中存在的things類,而不考慮stuff類。
隨著圖像處理技術的發(fā)展,數(shù)字圖像已經成為日常生活中不可缺少的媒介,每時每刻都在產生圖像數(shù)據。對圖像中的物體進行快速準確的分割變得愈發(fā)重要[2]。在自動駕駛場景中,全景分割的結果可以為導航定位系統(tǒng)提供豐富的語義信息。通過將場景分割成不同的語義區(qū)域,可以識別出道路、建筑物、行人、車輛等重要的道路場景信息。這些信息可以幫助自動駕駛車輛全面地感知環(huán)境,從而幫助其進行場景理解和語義推理,為進行更高級別的決策和規(guī)劃提供支持。
2018年,文獻[1]首次提出了全景分割概念,使用了一種融合方法,將當時最好的實例分割網絡掩碼區(qū)域卷積神經網絡(mask region-convolutional neural network,Mask R-CNN)[3]和語義分割網絡金字塔場景解析網絡(pyramid scene parsing network,PSPNet)[4]的結果合并為全景分割結果,為后續(xù)研究提供基準。文獻[5]首次提出了統(tǒng)一的全景分割網絡框架,引入了公共特征提取網絡以減少計算量,在不降低精度的情況下縮短了推斷時間。全景特征金字塔網絡(panoptic feature pyramid networks,Panoptic FPN)[6]在實例分割網絡Mask R-CNN的基礎上增加了語義分支全卷積網絡[7](fully convolutional networks,F(xiàn)CN),通過融合FCN的語義分割結果和Mask R-CNN的實例分割結果得到全景分割結果。這種利用子網絡獨立分割,再對結果進行融合的方法成為一種十分經典的方法。但上述方法未考慮子任務間存在的相關性。由于語義分割和實例分割任務間存在一定的互補性,一些研究提出利用任務間的信息交互來改善全景分割結果。文獻[8]提出了2個實例增強信息模塊,利用實例分支的物體結構信息補充語義分支,有效利用了實例分支的背景信息,提升了全景分割質量。文獻[9]針對道路場景提出了一種使用語義信息增強實例分支的網絡,利用語義分支的像素信息增強實例分支的識別能力。文獻[10]提出了一種信息聚合的網絡,利用語義分割和實例分割間進行的特征交流,提升了全景分割效果。文獻[11]設計了一個分支間加入了結果一致性(things and stuff consistency,TASC)模塊的方法,用實例分割結果和語義分割結果融合來監(jiān)督任務的一致性,一定程度上解決了子分支間的沖突問題。上述網絡表明多任務全景分割網絡分支間必要的信息交互能有效改善全景分割結果,但這些方法大多是單向的信息交互方法。一些研究方法從其他方面入手改善全景分割網絡性能。文獻[12]基于圖卷積網絡提出了一種全景分割網絡,利用邊界信息來增強監(jiān)督信息并幫助區(qū)分相鄰對象。文獻[13]提出一種基于分組卷積進行特征融合的全景分割算法,提升了網絡的運算速度。文獻[14]將圖卷積網絡和傳統(tǒng)全景分割網絡相結合,研究前景things和背景stuff的關系,提出了雙向圖形連接模塊(bidirectional graph reasoning module),它可以在前景物體和背景區(qū)域之間進行信息傳遞和交互。文獻[15]提出了一種無參數(shù)的全景分割頭來融合語義和姿態(tài)分割預測以代替?zhèn)鹘y(tǒng)的啟發(fā)式方法,借助其全景分割頭,產生了一個高性能的分數(shù)。文獻[16]基于文獻[15]在殘差網絡和特征金字塔之間添加一種三重態(tài)注意力機制,提升了網絡性能。文獻[17]提出了空間排序模塊,以解決分數(shù)較高的物體對分數(shù)較低物體的覆蓋問題。
本文針對多任務全景分割網絡中語義分割和實例分割子網絡間的信息交互問題,設計一種雙向信息交互的全景分割網絡,網絡通過引入語義增強信息和實例增強信息模塊實現(xiàn)分支間的信息交互。該網絡并行進行語義分割、實例分割,最終通過改進的融合算法將二者結果合并為全景分割結果。
1 網絡結構
對于一幅輸入圖像,首先提取特征;然后將提取的特征輸入語義分割與實例分割的子任務分支進行處理,產生語義分割與實例分割輸出;最后是子任務融合,將語義與實例分支產生的結果通過適當?shù)牟呗赃M行融合,產生最終的全景預測。
本文提出的全景分割網絡包括特征提取部分、實例分割分支、語義分割分支和融合模塊4部分,為了增強實例和語義信息之間的交互,在語義分支和實例分支間引入了實例增強信息模塊和語義增強信息模塊,實現(xiàn)了雙向信息傳遞和融合。整體框架結構如圖1所示,圖中RPN為區(qū)域提議網絡(region proposal networks),ROI為感興趣區(qū)域(region of interest)。

圖1 本文全景分割網絡框架
輸入圖像首先通過帶有特征金字塔網絡(feature pyramid networks,F(xiàn)PN)[18]的主干網絡殘差網絡(residual network,ResNet)進行特征提取;其次每層的特征圖分別輸入于語義分割分支和實例分割分支;接下來先將提取的多尺度特征輸入至RPN輸出ROIs,同時利用RPN豐富的前景背景信息采用實例增強信息模塊提取上下文信息,并與語義分支的特征融合,進行語義預測,語義分支采用普通的FCN以實現(xiàn);然后將語義結果通過語義增強信息模塊增強實例特征表示,實例分支則遵循經典的Mask R-CNN方法進行實例預測;最后將得到的語義掩碼和實例掩碼經過改進的融合算法得到最終的全景分割結果。
1.1 實例增強信息模塊
在Mask R-CNN中,RPN能夠為檢測任務提供預測的二值標簽(things和stuff標簽)和包圍框(bounding box)坐標。這表示在RPN中蘊含著豐富的前景和背景信息,這些上下文信息能夠提供額外的語義分割類別信息,減少語義分支的分類錯誤。因此設計了實例增強信息模塊來增強語義分支。
實例增強信息模塊使用RPN分支的上下文信息和語義分支進行信息交互。首先提取RPN的上下文信息,計算公式為

式中:R為R×"×"維度第層的RPN輸入特征圖,其中R為RPN層通道(channel,C),"、"分別為第層RPN特征圖的寬(width,W)、高(height,H);θ,1θ,2為卷積層的參數(shù);(?)為卷積(convolution,Conv)操作;1為修正線性單元(rectified linear unit,ReLU)激活函數(shù);2為S型(Sigmoid)激活函數(shù);M為RPN的上下文信息權重。
為了突出第層RPN的上下文信息M對語義分支的影響,將M與來自第層的語義特征圖S進行計算。計算公式為
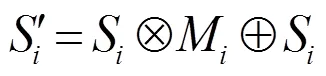

為了減少無用的背景層對語義分割結果的影響,受文獻[19]啟發(fā),設計了一個重加權模塊以降低上下文信息M中無用權重的影響。重加權模塊計算公式為
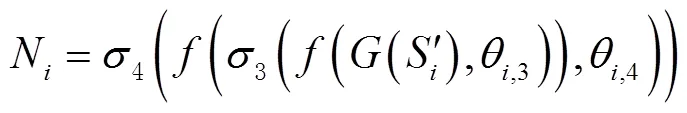
式中:(?)為全局平均池化(global average pooling,GAP);θ,3、θ,4為卷積層的參數(shù);3為ReLU激活函數(shù);4為Sigmoid激活函數(shù);N為重新加權的結果。
最終將重加權結果N和實例增強后的語義特征圖相乘得到語義結果,計算公式為
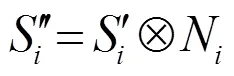
實例增強信息模塊的整體流程如圖2所示。圖中s為語義分支通道。

圖2 實例增強信息模塊
1.2 語義增強信息模塊
在針對某些things的預測中,語義分割的預測結果會優(yōu)于實例分割對該things的預測結果;而在本文所示的網絡結構中,如圖1所示,為避免2個分支對things預測的沖突,只選擇實例分割分支的結果作為things類別的預測。因此這種算法會導致語義分割分支的某些潛在的有價值信息的損失,從而導致模型性能降低。所以在這些原因的啟發(fā)下,本文添加了一個額外的模塊,其采用語義分支豐富的上下文信息以提高實例分支對things類別預測的精度。
提出一個語義增強實例模塊來實現(xiàn)上述想法。首先在語義分支結果部分和ROI階段增加了一個額外的信息交互通道,該通道首先提取語義結果信息,計算公式為
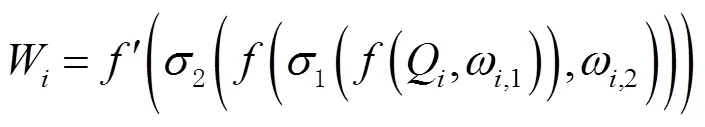

然后將第層得到的語義分支權重W和來自實例分支的第層的特征圖P進行計算,計算公式為

同樣地,考慮到實例分支只關注things類別的檢測和分支,為了減少無用的背景信息對實例分支精度的削弱,設計了一個與1.1節(jié)相同的重加權模塊以降低W無用權重的影響,計算公式為

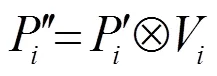

語義增強信息模塊的整體流程如圖3所示。
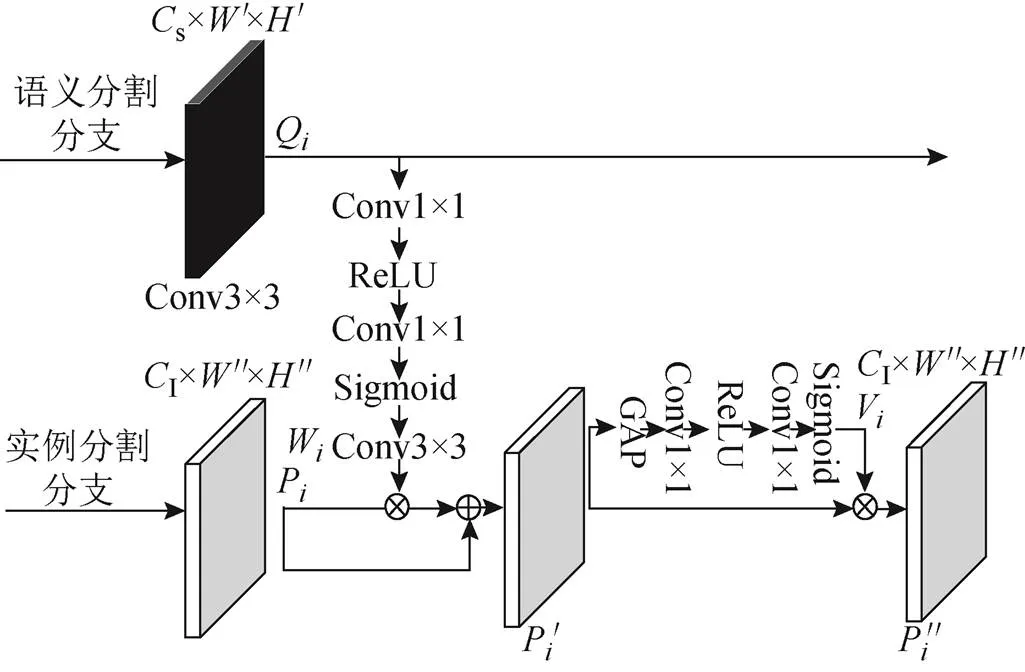
圖3 語義增強信息模塊
1.3 融合模塊
由于本文的網絡是并行獨立地輸出語義分割結果和實例分割結果,因此需要進行后處理操作以將2種預測結果合并為全景分割結果。全景分割結果分為2部分,即類別標簽和實例ID。在進行融合時,需要處理2個問題,即重疊問題和沖突問題。本文在傳統(tǒng)啟發(fā)式方法的基礎上做出改進。
重疊問題:實例分割會出現(xiàn)同一個像素點可能被多個實例或者類別同時覆蓋的結果。對于目標檢測、實例分割任務來說,像素點的重疊問題不會影響預測結果,而對于全景分割任務,需要對于單一像素輸出單一類別及唯一實例ID,因此掩碼重疊問題是全景分割任務必須解決的問題。本文采用文獻[1]提出的基準方法,該方法流程與非極大值抑制(non-maximum suppression,NMS)方法類似,即按分類置信度分數(shù)對實例分割結果進行降序排序,選擇分數(shù)最高的預測結果,計算與其他預測框的交并比(intersection over union,IOU),當IOU大于設定閾值時,去除該預測結果,直到沒有剩下的預測結果為止。一般地,閾值設置為0.5。
沖突問題:對于stuff的類別預測,僅需要語義分支結果;對于things類別的預測,實例分支、語義分支都進行了不同的預測,因此2種預測結果不可避免地存在預測沖突。而考慮到語義分支的預測結果不能有效區(qū)分同一類別的不同實例,不能直接對2種預測結果進行比較。本文在文獻[1]的方法上做出改進,對于things類別預測,優(yōu)先選擇實例分割預測而不是語義分割預測結果,同時為了避免不必要的信息損失,將語義分割預測分數(shù)最高的things類別替換為預測分數(shù)最高的stuff類別。
融合策略如圖4所示。對于實例分支預測,首先采用類似NMS的方法去除實例預測重疊,得到實例掩碼;對于語義分支預測,先將所有的things預測替換為stuff預測,最終將二者獲得的預測結果合并,得到全景分割結果。
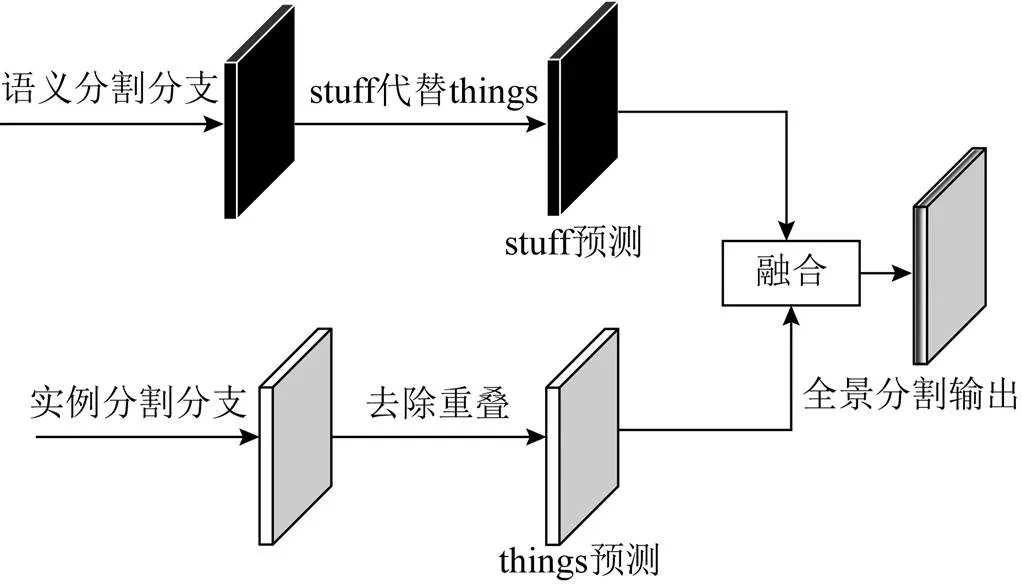
圖4 融合策略
1 實驗與結果分析
1.1 數(shù)據集、評價指標及實驗環(huán)境
1.1.1 數(shù)據集
本文使用自動駕駛數(shù)據集城市景觀數(shù)據集Cityscapes[20]作為實驗數(shù)據集。Cityscapes是道路場景的常用數(shù)據集,包含了50個歐洲城市,春夏秋3季數(shù)個月的街道場景,人工選擇出視頻中含有的大量動態(tài)物體、不同的場景布局、不同背景的幀,不包含黑夜、惡劣天氣環(huán)境等場景。
數(shù)據集包括5000張精細標注的全局語義分割圖片(訓練集2975張、驗證集500張、測試集1525張)和20000張粗略標注的圖片。在本文的實驗中,選擇5000張精細標注的圖片,包括8個things類別、11個stuff類別。所有圖像的分辨率均為1024×2048個像素,實驗中將輸入圖像調整為512×1024個像素。本節(jié)的實驗結果是訓練后的網絡在驗證集上的測試結果。
1.1.2 評價指標
實驗使用全景質量(panoptic quality,PQ)作為主要評價指標。PQ可以衡量全景分割結果的分割準確度,定義為
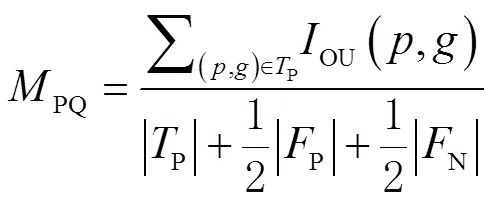
在二分類或多分類任務中,常常需要計算模型預測結果和真實標簽的差異,可以分為TP、FP、FN、真陰性(true negative,TN)4種,其中TP、FP、FN分別表示預測標簽和真實標簽中的已匹配部分、不匹配的預測部分和不匹配的真值部分。IOU計算只包含已匹配的部分(即為TP的部分);當IOU大于0.5時,一般定義為匹配。如圖5所示為區(qū)分TP、FP、FN的原理。
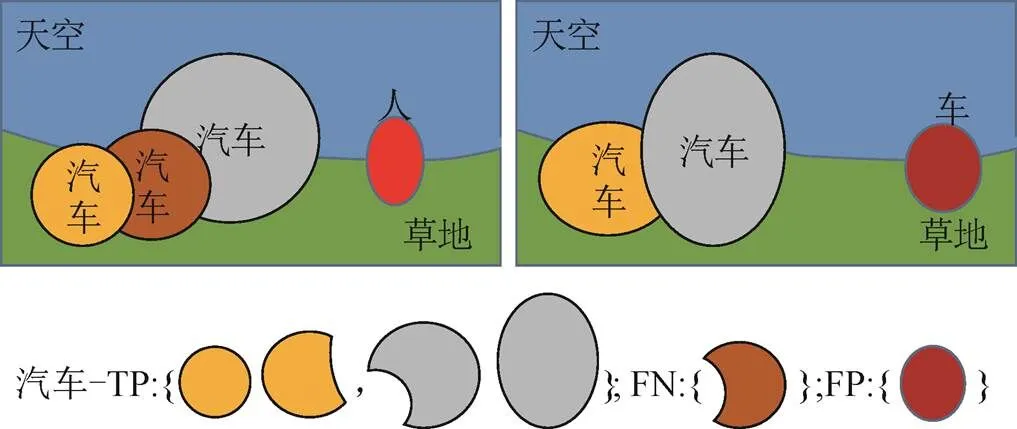
圖5 TP、FP、FN概念
PQ同時可以分解為分割質量(segmentation quality,SQ)和識別質量(recognition quality,RQ)的乘積,計算公式為
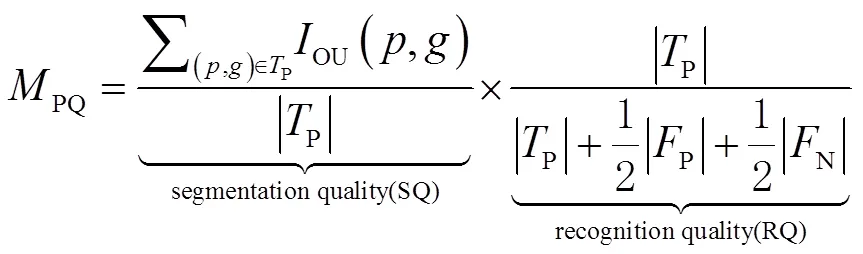
式中:SQ能體現(xiàn)模型對正確預測的匹配物體實例分割的準確度,RQ用來衡量所有類別物體的檢測準確度。
1.1.3 損失函數(shù)
為了實現(xiàn)單一網絡的聯(lián)合訓練,在訓練階段,使用一個聯(lián)合損失函數(shù)對網絡進行優(yōu)化。聯(lián)合損失函數(shù)分為6個部分,計算公式為
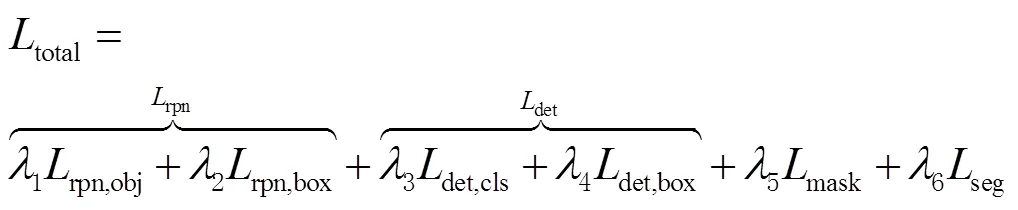
式中:total為聯(lián)合損失函數(shù);rpn為RPN損失;rpn,obj為RPN類別的交叉熵(crossentropy loss)損失函數(shù);rpn,box為RPN平滑的最小絕對值偏差損失函數(shù)(smooth1 loss);det為檢測損失;det,cls為目標檢測任務的分類損失,使用交叉熵損失函數(shù);det,box為目標檢測任務的包圍框回歸損失,使用smooth1 loss;mask為實例掩碼的二分類交叉熵(binary crossentropy loss)損失函數(shù);seg為語義分割任務損失,使用交叉熵損失函數(shù);1、2、3、4、5、6分別表示對應損失函數(shù)權重。
1.1.4 實驗環(huán)境及設備
本文基于深度學習框架Pytorch1.10實現(xiàn)網絡結構。實驗以8個批量大小訓練模型,損失權重根據式(11)1~6分別設置為1、1、1、1、1、0.75,優(yōu)化器選擇隨機梯度下降(stochastic gradient descent,SGD),動量(momentum)設置為0.9,權重衰減1×10-4,初始學習率0.01,迭代100個歷元,學習率在第66、88個歷元時衰減10倍。
1.2 消融實驗
為了檢驗本文提出的信息交互模塊的效果,在確保相同的實驗環(huán)境和配置的條件下,針對1.1、1.2節(jié)提出的2個信息交互模塊設計消融實驗以驗證其有效性:1)不包含2個模塊的基準網絡;2)僅加入語義增強信息模塊;3)僅加入實例增強信息模塊;4)包含2個模塊的雙向信息交互網絡。分別在Cityscapes數(shù)據集進行訓練,并在Cityscapes驗證集評估結果,結果如表1所示。為了驗證各個模塊對對應任務的促進作用,另統(tǒng)計PQth、PQst指標,其中PQth、PQst分別為PQ在things、stuff類別上的結果。
如圖6所示為雙向信息交互網絡的損失函數(shù)和學習率隨歷元變化的情況,圖中紅色的曲線表示訓練損失變化,左邊的縱坐標為損失函數(shù)值,藍色的線條表示訓練學習率的變化,右邊縱坐標為學習率值,橫坐標表示訓練的歷元個數(shù)。

圖6 Cityscapes數(shù)據集上損失函數(shù)收斂曲線
如表1所示為不同模型在Cityscapes驗證集中的實驗結果。對比基準網絡,提出的網絡在PQ分數(shù)上得到了3.1%的提高。可以看到語義增強信息模塊、實例增強信息模塊均有效地提升了網絡全景分割質量。語義增強信息模塊使用了語義分支的結果信息為實例分支的目標檢測器提供了更多的細節(jié)信息,提升了檢測器對things類別的分類能力,在things分支的PQ提高了2.2%。實例增強信息模塊相較于基準網絡提升了1.8%,表明該模塊通過RPN中的二值標簽為語義分割任務提供了更多的上下文信息識別things和stuff。同時注意到2個模塊均使得PQth、PQst獲得了提升,這表明聯(lián)合訓練中的信息交互能夠為網絡訓練提供更多的細節(jié)信息,有效地減少了things和stuff的錯誤分類。實驗表明,提出的網絡有效地利用了多任務全景分割網絡的信息間交互,通過設計語義增強信息、實例增強信息模塊提高了網絡各分支對things和stuff的識別能力。

表1 不同模型在Cityscapes驗證集的實驗結果 %
1.3 結果分析
如圖7~圖9所示為在Cityscapes驗證集上節(jié)選的全景分割可視化結果對照。考慮到呈現(xiàn)的全圖結果圖由于圖片壓縮某些目標較小不容易對比,本節(jié)在展示出全圖可視化結果的同時,將圖像的部分裁剪出來以便更直觀地進行對比。可以看到:相比基準網絡,圖像1裁剪部分中,信息交互網絡對交通標志、交通燈信息的分割更加細節(jié)、規(guī)則,同時檢測出較小目標的自行車,表明提出的網絡在things和stuff類別的信息交互上均取得了一定的效果;圖像2中對欄桿的分割更好,同時行人和路面、欄桿等stuff類別的邊界問題處理得更自然;圖像3對汽車的邊界分割更加精細,還能利用信息交互模塊提供的額外信息檢測出道路中的行人,這表明網絡對于細節(jié)信息和相鄰物體的邊界問題處理得更好,噪聲更小,證明提出的信息交互模塊提供的額外信息能夠有效地提升全景分割效果。

圖7 示例圖1
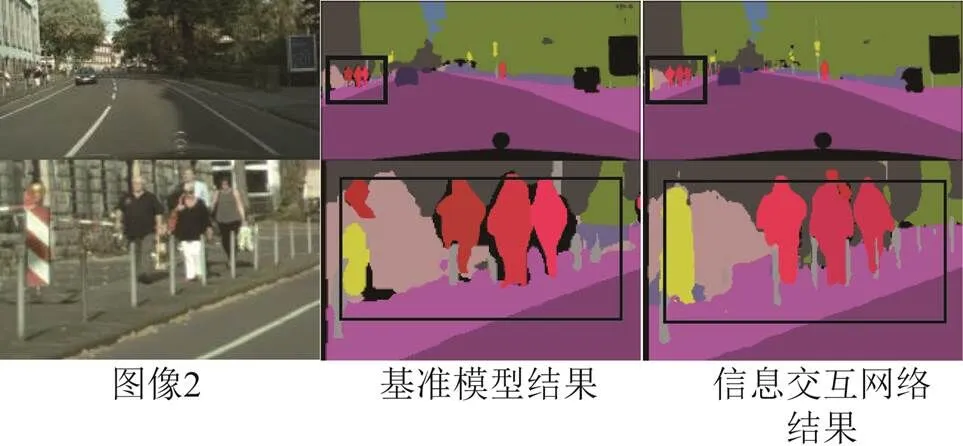
圖8 示例圖2
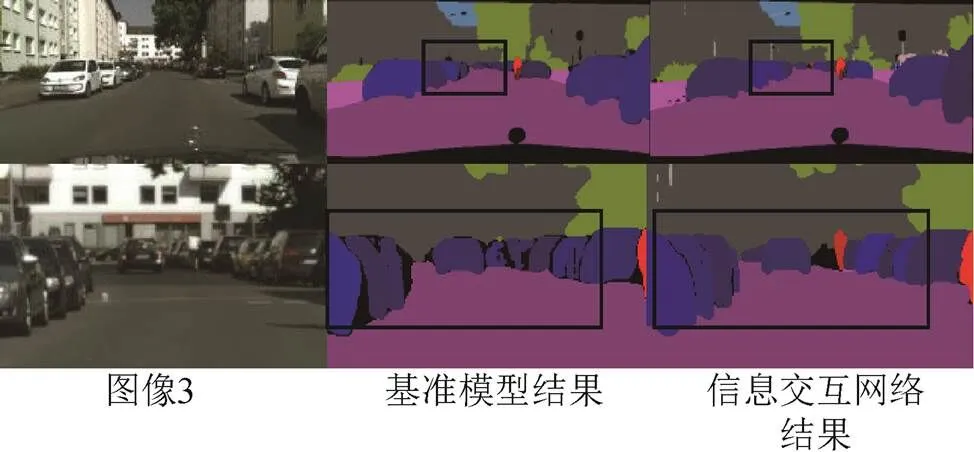
圖9 示例圖3
2 結束語
本文針對自動駕駛車輛全面感知環(huán)境的需求提出了一種基于信息交互的全景分割網絡,網絡由實例分割和語義分割2個任務組成。考慮到2個任務間進行信息交互的互補性,提出了語義增強信息、實例增強信息模塊,通過RPN、語義分割結果分別為對應任務提供了物體級別和像素級別的隱式信息,能夠更好地捕捉圖像中的實例和語義信息。通過實驗驗證了提出的雙向信息交互網絡能夠有效提高全景分割的性能,獲得更精確的全景分割結果。對于多任務的全景分割網絡,傳遞互補的信息對于各個模塊通常是有益的,額外信息能幫助各任務更好地理解場景。提出的全景分割網絡更加高效、魯棒和精確,在道路場景中能夠有效識別出各類信息,這些信息能夠為自動駕駛提供更精確的定位、導航等功能,還可應用于事后建圖、圖像標注等自動駕駛相關領域。
[1] KIRILLOV A, HE K, GIRSHICK R, et al. Panoptic segmentation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 9404-9413.
[2] 徐鵬斌, 瞿安國, 王坤峰, 等. 全景分割研究綜述[J]. 自動化學報, 2021, 47(3): 549-568. DOI:10.16383/j.aas.c200657.
[3] HE K, GKIOXARI G, DOLLáR P, et al. Mask r-cnn[C]// Proceedings of the IEEE International Conference on Computer Vision. 2017: 2961-2969.
[4] ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 2881-2890.
[5] DE GEUS D, MELETIS P, DUBBELMAN G. Panoptic segmentation with a joint semantic and instance segmentation network[J]. arXiv Preprint arXiv:1809.02110, 2018.
[6] KIRILLOV A, GIRSHICK R, HE K, et al. Panoptic feature pyramid networks[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 6399-6408.
[7] LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 3431-3440.
[8] LI Y, CHEN X, ZHU Z, et al. Attention-guided unified network for panoptic segmentation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 7026-7035.
[9] DE GEUS D, MELETIS P, DUBBELMAN G. Single network panoptic segmentation for street scene understanding[C]// 2019 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2019: 709-715.
[10] CHEN Y, LIN G, LI S, et al. Banet:Bidirectional aggregation network with occlusion handling for panoptic segmentation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 3793-3802.
[11] LI J, RAVENTOS A, BHARGAVA A, et al. Learning to fuse things and stuff[J]. arXiv Preprint arXiv:1812.01192, 2018.
[12] ZHANG Xiaoliang, LI Hongliang, WANG Lanxiao, et al. Real-time panoptic segmentation with relationship between adjacent pixels and boundary prediction[J]. Neurocomputing, 2022, 506: 290-299.
[13] 馮興杰, 張?zhí)鞚? 基于分組卷積進行特征融合的全景分割算法[J]. 計算機應用, 2021, 41(7): 2054-2061.
[14] WU Y, ZHANG G, GAO Y, et al. Bidirectional graph reasoning network for panoptic segmentation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 9080-9089.
[15] XIONG Y, LIAO R, ZHAO H, et al. Upsnet:A unified panoptic segmentation network[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 8818-8826.
[16] 雷海衛(wèi), 何方圓, 賈博慧, 等. 基于注意力機制的全景分割網絡[J]. 微電子學與計算機, 2022, 39(1): 39-45. DOI:10.19304/J.ISSN1000-7180.2021.0263.
[17] LIU H, PENG C, YU C, et al. An end-to-end network for panoptic segmentation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 6172-6181.
[18] LIN T Y, DOLLáR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 2117-2125.
[19] HU J, SHEN L, SUN G. Squeeze-and-Excitation networks[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 7132-7141.
[20] CORDTS M, OMRAN M, RAMOS S, et al. The cityscapes dataset for semantic urban scene understanding[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 3213-3223.
Road scene panoptic segmentation network with two-way information interaction
LIU Bolin, HUANG Jingsong
(School of Geodesy and Geomatics, Wuhan University, Wuhan 430079, China)
In order to further study the panoptic segmentation function of road scenes, supporting for autonomous driving vehicles to fully perceive the environment, the paper proposed a panoptic segmentation network with two-way information interaction: the features were extracted through the backbone network, and input into the semantic segmentation branch and the instance segmentation branch, respectively; then, an instance enhancement information module and a semantic enhancement information module were added between the branches to enhance information interaction; finally, semantic results and instance results were fused by using an improved fusion algorithm, and the prediction results of panoramic segmentation were obtained. Experimental result showed that the proposed bidirectional information interaction module would help improve the performance of the panoptic segmentation network, and a panoptic quality (PQ) score of 46.8 could be gained on the Cityscapes dataset using 512×1024 pixel resolution images.
panoptic segmentation; autonomous driving; multi-task learning; information interaction; semantic segmentation; instance segmentation
劉博林, 黃勁松. 雙向信息交互的道路場景全景分割網絡[J]. 導航定位學報, 2023, 11(6): 49-56.(LIU Bolin, HUANG Jingsong. Road scene panoptic segmentation network with two-way information interaction[J]. Journal of Navigation and Positioning, 2023, 11(6):49-56.)DOI:10.16547/j.cnki.10-1096.20230607.
P228
A
2095-4999(2023)06-0049-08
2023-03-13
劉博林(1998—),男,河北唐山人,碩士研究生,研究方向為深度學習。
黃勁松(1969—),男,湖南長沙人,博士,副教授,研究方向為自主移動機器人技術。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
中華手工(2017年2期)2017-06-06 23:00:31
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中外會展(2014年4期)2014-11-27 07:46:46
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
當代修辭學(2010年1期)2010-01-23 06:35:10
建筑創(chuàng)作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
