基于強化學習的循環自動展開研究
2023-02-28 16:11:02李居垚何先波
智能計算機與應用 2023年11期
李居垚,何先波
(西華師范大學電子信息工程學院,四川 南充 637009)
0 引 言
當下新架構芯片問世的頻率遠超以往,這需要縮短芯片編譯的開發周期來進行適配。 在編譯器中許多關鍵決策是由抽象模型來決定的,雖然這些模型能夠有效地解決問題,但是開發編寫一個精確的抽象模型需要耗費大量的人力物力;所以使用新技術來縮短編譯器開發的成本和周期是有必要的。
編譯優化中的循環展開有著承上啟下的作用,因為循環展開從多維度間接影響了系統性能,同時也會為其他優化(如SLP)帶來契機,所以開發一種有別于傳統的新技術來對編譯器循環展開進行自動化是必要的。 本文將使用人工智能技術提出一個模型來對編譯器循環展開工作中的至關重要的展開因子(Unroll Factor,UF)進行自動生成,已達到循環展開工作自動化減少編譯器開發工作量和成本的目的。
1 相關理論及方法
1.1 循環展開
循環展開是一種常用的編譯優化策略,開啟后編譯器會通過既定的抽象模型啟發式地將目標循環進行多次復制。 循環展開主要用于為其他優化提供機會,例如,展開會創建與動態執行相對應的多個靜態內存單一操作指令,可以重新安排這些指令以利用內存局部性[1]。 如果循環訪問連續迭代中的相同內存位置,引用還可以用標量進行消除。 循環展開是暴露相鄰內存引用的關鍵,展開完成后后續的優化可識別到這些引用并將其合并為一個寬引用[2]。
由于循環展開的主要影響集中在次級效應上,所以選取最優的展開因子進行循環展開是困難的。循環展開也可以被歸納為空間換時間的一種手段,這很容易造成一種循環展開總能提升性能的誤解。不合適的循環展開都會造成以下性能損失:會降低指令緩存的性能,會造成內存的溢出和重新加載,如果編譯器選擇推測性的訪問展開內存會造成動態沖突[3]。 循環展開會增加編譯時間,所以通過暴力搜索等手段獲取循環展開因子是低效的,圖1 展示了不同循環展開因子選擇對編譯耗時的影響。
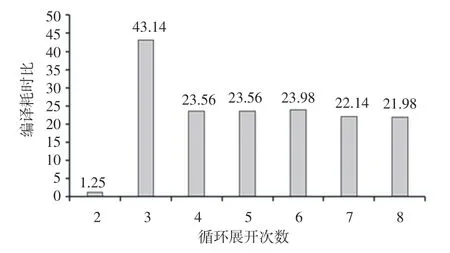
圖1 TSVC 中s3111.c 設置不同循環展開次數的編譯耗時比Fig. 1 Compilation time ratio of s3111. c with different loop unwinding times in TSVC
使用暴力搜索的方式來尋找最優的展開因子是效率低下的,如圖1 所示。 圖1 中,以不進行展開的耗時為基準。 近年來,隨著機器學習技術不斷發展成熟,許多學者希望利用機器學習來解決復雜的編譯器優化問題,即構建一個機器學習模型去預測編譯器優化參數和編譯選項等[4]。 本文將會嘗試使用強化學習來預測的循環展開因子。
1.2 強化學習
強化學習通過和環境動態交互不斷試錯來得到較優解的方法。 在這種方法中智能體通過不斷和環境交互來進行學習[5],強化學習想要直接訓練得到策略函數或者價值函數是比較困難的,對此引入神經網絡來近似目標函數是一種常用的策略。
在強化學習中智能體通過對環境的“觀察”來采取行為動作,行為會產生新的環境并根據當前環境得到一個獎勵的分值作為行為好壞的評判,整個學習過程的目的是獎勵達到數學期望的最大化并得到相映的決策函數(π?):
強化學習有很多巧妙的算法,本文選用PPO(Proximal Policy Optimization)算法[6]。 PPO 算法的優勢在于每次進行梯度更新時能夠使得成本最小化,并且能夠很好地消除和上一次梯度更新的偏差。
1.3 代碼嵌入
使用代碼詞嵌入能夠使輸入的源程序更好地通過強化學習進行訓練,代碼詞嵌入的最終目標是有效地將源程序和強化學習所需要的向量進行映射。在本文中,選擇IR2Vec 作為代碼嵌入。
IR2Vec[4]是一種基于源碼中間表示形式(LLVM IR)的代碼嵌入,這種代碼嵌入的方法具有簡明和可伸縮的特點,IR2Vec 通過表征學習和流信息相結合的方式捕獲程序的語法和語義將程序表示為連續空間中的分布式嵌入。 IR 的表示被轉化為一個種子嵌入詞匯表,并且有2 種編碼模式:符號編碼和流感知編碼。 由于本文主要針對的是源代碼中循環部分的工作,控制流的信息至關重要,所以本文使用IR2Vec 的流感知編碼模式。
2 相關工作
2.1 實驗平臺
實驗平臺信息見表1。

表1 實驗平臺信息Tab. 1 Experimental platform information
2.2 實驗內容
本次實驗所使用的模型如圖2 所示,源程序作為初始的輸入會通過腳本識別代碼中的循環并插入循環展開指令設置循環展開因子,然后使用Clang\LLVM 將源代碼轉為中間表示形式(IR),而后將IR輸入到IR2Vec 中生產長度為300 的向量嵌入到強化學習的智能體中,同時編譯運行使用LLVM 基準(LLVM-O3)的可執行文件并收集運行時間。 下一階段使用策略函數輸出的新因子作為參數,再次進行編譯并運行,2 次運行的性能差異將作為模型的獎勵,這意味著本模型的獎勵不需要手動進行設置,獎勵的值也不是固定不變的。 模型中一輪迭代后會將預測出的循環展開因子作為下一輪的學習所需要的編譯選項參數,獲得新的IR、新的向量嵌入智能體,以此往復訓練出預測循環展開因子的模型。
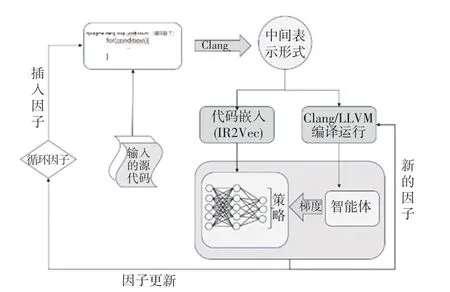
圖2 本文提出的自動循環展開框架Fig. 2 The automatic loop unrolling framework proposed in this article
本次實驗將會采取上述的模型和方法進行,代碼嵌入使用的IR2Vec 開源工具并根據設定的任務要求進行改造,研究中選用其流感知模式來更好地識別循環中的控制流信息。 在搭建強化學習模型的過程中,使用了RLlib[6]和Tune[7],RLlib 和Tune 都能在強化學習的開源庫里找到。 這樣一來,研究所搭建的模型會更加規范,便于進行參數的調整和對模型的擴展。
在實驗中使用Ray[8]框架,因此對于提前設置好的3 種不同的學習率可以同時進行,這極大地縮短了訓練所需的時間。 同時,為了與本次研究搭建的強化學習模型進行對比,還準備了暴力搜索來鎖定最優循環展開因子。
2.3 參數設置
實驗選用PPO 算法,設置了3 個學習率:5-e3、5-e4、5-e5。 本模型的獎勵將以LLVM11 -O3 編譯后的運行時間作為基準,將其進行如下定義:
對于循環展開因子的取值,本文設立一個數組array[1、2、4、…、8],此后隨機從中取值作為強化學習的動作。
表2 是本文構建的強化學習模型具體的參數設置。

表2 強化學習模型參數Tab. 2 Parameters of reinforcement learning model
2.4 數據集
實驗所使用的訓練集是在向量化測試套件(TSVC)的基礎上進行篩選和拓展組成的訓練集。TSVC 最初由Callahan 等人開發后由Maleki 等學者[9]將其從Fortran 轉換為C 進行了擴展。 擴展版本有151 個內核。 本次研究選擇這個基準測試是因為其中提供了一些相對簡單的循環的集合,這些循環可以在許多科學用途的C 語言代碼中找到,同時TSVC 中的循環能夠根據其測試的用途進行適當分類,對結果分析有很大的幫助。 通過腳本將TSVC中每個函數提取出去生成獨立的C++文件;TSVC的數據量對強化學習來說還是偏小了,本實驗將會在TSVC 原有的循環上進行增加,手段主要是改變變量名稱使得數據的總量倍增;同時,對不同分類的TSVC 函數進行隨機抽取用來構建測試集。 構建訓練集和其中一個測試集如圖3 所示。
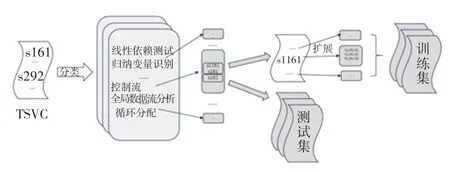
圖3 TSVC 訓練集和測試集構建流程Fig. 3 TSVC training and testing set construction process
為了測試本文構建的強化學習循環展開化器能否很好地推廣到新代碼,并且測試其對于循環復雜程度的敏感程度,選擇使用Ameer 等學者[10]構建的循環結構簡單的數據集Tests、分離出的TSVC 內核和PloyBench[11]三個測試集進行推廣性能的測試。這3 個測試集中,Tests 的循環結構最簡單,其次是TSVC,PloyBench 的循環結構最為復雜其主要由循環構成,即由多個benchmark 組成。 本次研究選用其中的2mm、bicg、atax、gemm、gemver、choleshy 來進行測試。
3 實驗結果
強化學習循環展開器、LLVM 基準模型和暴力搜索的性能對比如圖4 所示。 在Tests 基準上本文提出的循環展開器比LLVM 基準模型有1.19x 的性能提升;在TSVC 基準上,有1.13x 的性能提升;在Polybench 基準上,有1.09x 的性能提升。 可以看到,隨著循環復雜度的提升,循環展開器的性能也隨之下降,可見在面對復雜循環時本文提出的循環展開器還有進一步的優化空間。
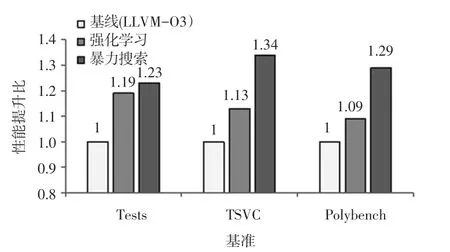
圖4 歸一化后強化學習循環展開器、LLVM 基準模型和暴力搜索的性能比Fig. 4 The performance ratio of reinforcement learning loop unroller,LLVM benchmark model and brute force search after normalization
雖然本文提出的循環展開器性能上要弱于暴力搜索的結果,但是在運行速度上大幅領先暴力搜索,如圖5 所示:在Tests 基準上,本文提出的循環展開器比暴力搜索快5.97x;在TSVC 基準上,快6.23x 的性能提升;在Polybench 基準上快5.61x 的性能提升。
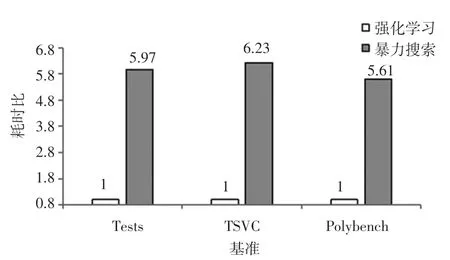
圖5 歸一化后強化學習向量器和暴力搜索編譯所需時間比Fig. 5 Time ratio between reinforcement learning vector machineand brute force search compilation after normalization
4 結束語
針對編譯開發成本急需縮減的問題,本文提出了一個基于強化學習的循環展開器來對編譯開發中循環展開進行自動化。 通過代碼嵌入的方式來表征循環代碼,然后使用強化學習模型來對展開因子進行預測以達到輸入新代碼能快速自動地進行循環展開的目的。 實驗表明,本文提出的循環展開器相比于LLVM -O3 的基準模型有更好的效果,同時有比暴力搜索更快的編譯速度。 但根據本文選取的3 個測試集的實驗結果,本文提出的向量化器在復雜場景中會效果下降,在未來的工作中會考慮更多復雜應用場景,將謂詞加入到控制流的識別當中、將多面體模型和強化學習進行結合以提升循環展開器的性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
核科學與工程(2015年4期)2015-09-26 11:59:03
