基于全階時間冪灰色預測模型的優化研究
2023-02-28 16:11:04孫竟耀
智能計算機與應用 2023年11期
孫竟耀,李 程
(上海工程技術大學航空運輸學院,上海 201620)
0 引 言
灰色系統理論是針對信息不完全或不確定的系統的控制理論,自上世紀八十年代創立以來,完善了對“小樣本數據”、“貧信息”的不確定性系統的研究。 隨著研究的深入,GM(1,1)也開發出許多分支模型。 但是,為了解決GM模型在實際應用過程中對不同數據類型適用性低,預測精度不理想的情況,寄希望以不同的初始值優化方法和不同的背景值取值方式提高GM 模型的適應性和分析預測精度。 在背景值求解方式的優化方面,蔣玉婷等學者(2020)[1]在背景值的求解方式上將牛頓插值法和柯特斯公式相結合進行計算,并在實例驗證中取得良好的效果。 王正新等學者(2008)[2]在非齊次指數序列擬合函數的基礎上重新推導背景值表達式。蔣詩泉等學者(2014)通過GM 模型背景值幾何意義的研究,給出了基于函數逼近理論和復合梯形公式的背景值優化公式。 張彬等學者(2013)[4]論證了基于背景值和邊值協同優化對GM 模型的預測精度提升有效。 高媛媛等學者(2020)[5]通過將背景值調整為連續化后的原始序列函數,從而提高了灰色微分方程和白化方程的適配度,給出了新的優化思路。 王承慶(2017)[6]在正弦變換和誤差最小化原理的前提下實現對GM 模型初始條件和背景值的優化,并在國內水產品總產量的預測問題上得到較好驗證。 龍釗等學者(2021)[7]計算三參數重構背景值,并進一步引入二次項優化灰色作用量,實現了背景值和灰色作用量的綜合優化。 張可等學者(2010)[8]基于粒子群算法對GM(1,1) 模型背景值系數動態尋優,實現了預測精度的提升。
同時,李守軍(2018)[8]對GM(1,1) 優化的模型結構進行整合提煉,增加冪函數項得到全階時間冪灰色預測模型FOTP-GM(1,1),在初始值序列的特征提取下實現模型結構和參數的動態改變,對近似非齊次指數序列具有較好的預測效果。 FOTPGM(1,1)模型較傳統GM(1,1) 模型在結構上用冪函數結構替換常數項b,隨著被模擬數列的特征變化,冪函數結構也隨之變形為DGM(1,1)、NGM(1,1,k)、NDGM、SAIGM 等模型。 由此可見,FOTP- GM(1,1) 模型能夠靈活變動結構,具有對不同序列數據的適應性。而FOTP- GM(1,1) 的背景值由于先連續化、后離散化的求解方式,因此在轉換求解過程中必然存在誤差,這也為預測精度的提升提供可能。
綜上,本文將著重在拓展模型FOTP-GM(1,1)上進行優化,構建時利用智能算法對背景值的系數設定動態尋優,將背景值系數設定為0 到1 之間的變量,利用粒子群算法在對應區間內動態尋優,實現提高FOTP-GM(1,1)模型精度的目的。
1 模型基礎及優化
1.1 傳統GM(1,1)模型
定義1設非負原始序列為X(0)=(x(0)(1),x(0)(2),…,x(0)(n)),其中x(0)(k) ≥0,k =1,2,…,n則稱X(1)=(x(1)(1),x(1)(2),…,x(1)(n)),其中:
稱Z(1)為X(1)的緊鄰均值生成序列,其中:
定義2設序列X(0),X(1)和Z(1)滿足定義1,則GM(1,1)模型的基本形式為:
1.2 FOTP-GM(1,1)的建模與求解
定義 3設非負初始值序列X0={x(0)(1),x(0)(2),…,x(0)(n)},n∈N+對應的1-AGO 序列定義為:
背景值序列定義為:
其中,z(1)(k +1)=αx(1)(k)+(1-α)x(1)(k +1),k =1,2,…,n -1。
定義4根據定義3,給出全階時間冪灰色預測的定義式:
其中,- a是模型背景值系數;bi(i =1,2,…,h) 是模型的灰色作用量;bith-i是模型的時間冪項;h為模型時間冪項的階數。
定義5根據灰導數信息覆蓋原理,這里定義FOTP-GM(1,1)模型的離散形式可轉換為連續的微分方程形式,稱之為FOTP-GM(1,1)模型白化方程:
就模型發展系數- a,灰色作用量bi的求解做出定義,若(a,b1,b2,…,bh)T是待估參數序列,則:
則FOTP-GM(1,1)模型的最小二乘估計滿足:
根據參數估計結果,整理后FOTP- GM(1,1)模型的時間響應函數為:
在一階累加序列x(1)(k) 和時間響應序列離差平方和最小的背景下,得模型最優迭代初值為:
為避免在參數求解過程中的矩陣病態性問題FOTP-GM(1,1)模型的階數h有固定的上限值,通過計算實對稱矩陣BTB的譜條件數cond(BTB)2。若cond(BTB)2|h =p <1012且cond(BTB)2|h =p+1>1012,則h =p。
2 FOTP-GM(1,1)模型背景值優化
2.1 FOTP-GM(1,1)模型誤差分析
以2 階模型h=2 為例,對定義5 中模型的式(8)白化方程在區間[k -1,k] 進行積分,并簡化后得:
與式(13)的h =2 階形式比較,可得:
根據積分的幾何意義分析,背景值的實際值曲線應是底邊長在區間[k -1,k] 上的曲邊梯形面積,而實際計算過程中因微分方程的求解過程中存在的誤差,此為誤差來源。
2.2 動態背景值a 粒子群算法尋優
粒子群算法(PSO)最早啟發于人類對鳥類覓食行為的思考,鳥類以單一個體進行單獨覓食,在一定區域內搜尋最近的食物位置,利用自身經驗判斷最佳位置,并在判斷的過程中不斷與鳥群共享信息,使得鳥群最終找到最佳覓食位置。
粒子群尋優算法的核心公式如下:
其中,ω是慣性因子,旨在對粒子的局部最優和整體區間最優兩者進行權重協調;c1和c2是分別是學習因子1 和2,學習因子調節每個粒子在尋優過程中的檢索步長;r1和r2為存在于[0,1]區間的隨機數。 綜合上述定義,粒子群尋優算法中,粒子群中由m個粒子組成的X =(x1,x2,…,xm),第i個粒子在空間中的位置表示為Xi =(xi1,xi2,…,xim),單一粒子尋優速度為Vi =(vi1,vi2,…,vim)T,每個粒子單體最佳位置為Pi =(pi1,pi2,…,pim)T,整體尋優后的最優位置為Pg =(pg1,pg2,…,pgm)T。
在模型的常規求解過程中1-AGO 背景值序列系數a通常取值0.5,這種賦值情況經過諸多案例證明可以得到較為理想的預測精度,但賦值仍缺少有力依據。因此在FOTP- GM(1,1) 模型的背景值劃定取值范圍在[0,1]區間,利用粒子群算法在區間內進行尋優。
尋優依據為計算輸出模擬數據的平均相對百分誤差(MAPE),以平均相對百分誤差最小值為篩選標準,MAPE計算公式為:
3 實證分析
FOTP-GM(1,1)模型可以完成對存在指數變化規律的序列數據進行模擬預測。 本節將在四階FOTP-GM(1,1)模型的基礎上參考李守軍[1]設定的4 組典型指數序列進行實證分析。 數據序列包括齊次指數序列,帶有常數項的非齊次指數序列、帶有速度項和常數項的非齊次指數序列以及帶有加速度、速度和常數項的非齊次指數序列、實證分析環節將上述四種序列數據類型均作為輸入數據在傳統GM(1,1)模型和四階FOTP-GM(1,1)模型進行模擬,然后利用粒子群算法在[0,1]范圍內對四階模型進行背景值系數尋優,最后對4 種模型的模擬數據和預測數據計算平均相對百分誤差并綜合比較,論證背景值優化后的模型預測精度。
3.1 初始數據處理
(1)設定齊次指數序列X1:x(0)=0.9×1.8k,k =1,2,…,15。X1數據序列k =1,2,…,10 作為初始值數據用于建模,經1-AGO 后得到序列X(1)1 ,緊鄰均值系列Z(1)1 :
(2)設定帶常數項非齊次指數序列X2:x(0)=1.2×1.9k +1.5,k =1,2,…,15。X2數據序列k =1,2,…,10 作為初始值建模,經1-AGO 后得到序列,緊鄰均值系列:
(3)設定帶有速度項和常數項的非齊次指數序列X3:x(0)=1.6×2.1k +0.5k +1.2,k =1,2,…,15,X3數據序列k =1,2,…,10 作為初始值建模,經1-AGO 后得到序列,緊鄰均值系列:
(4)設定帶有加速度、速度和常數項的非齊次指數序列X4:x(0)=1.2×1.5k +0.3k2+1.5k +1.1,k =1,2,…,15。X4數據序列k =1,2,…,10 作為初始值建模,經1-AGO 后得到序列,緊鄰均值系列:
3.2 模型參數估計與背景值尋優
得到上述數據后,運用式(9)建立矩陣Y和B利用最小二乘估計法求解(a,b1,b2,b3,b4)T=BTB-1)BTY得到模型參數,經粒子群算法尋優后背景值參數見表1。

表1 四階FOTP-GM(1,1)模型參數估計表Tab. 1 Parameter estimation table for the fourth-order FOTP-GM(1,1) model
3.3 模型精度對比
將參數估計結果和粒子群算法尋優后,利用得到的優化后的背景值系數帶入建模分析。 劃定序列數據k =1,2,…,10 為初始值測試集數據,k =10,…,15 為預測集數據。 4 組指數序列數據經過傳統GM(1,1)模型FOTP-GM(1,1)模型和基于背景值改進的FOTP-GM(1,1)模型,計算模擬數據和預測數據相對誤差,對k =1,2,…,15 模擬相對誤差計算平均相對模擬百分誤差,計算結果整理見表2 ~表5。
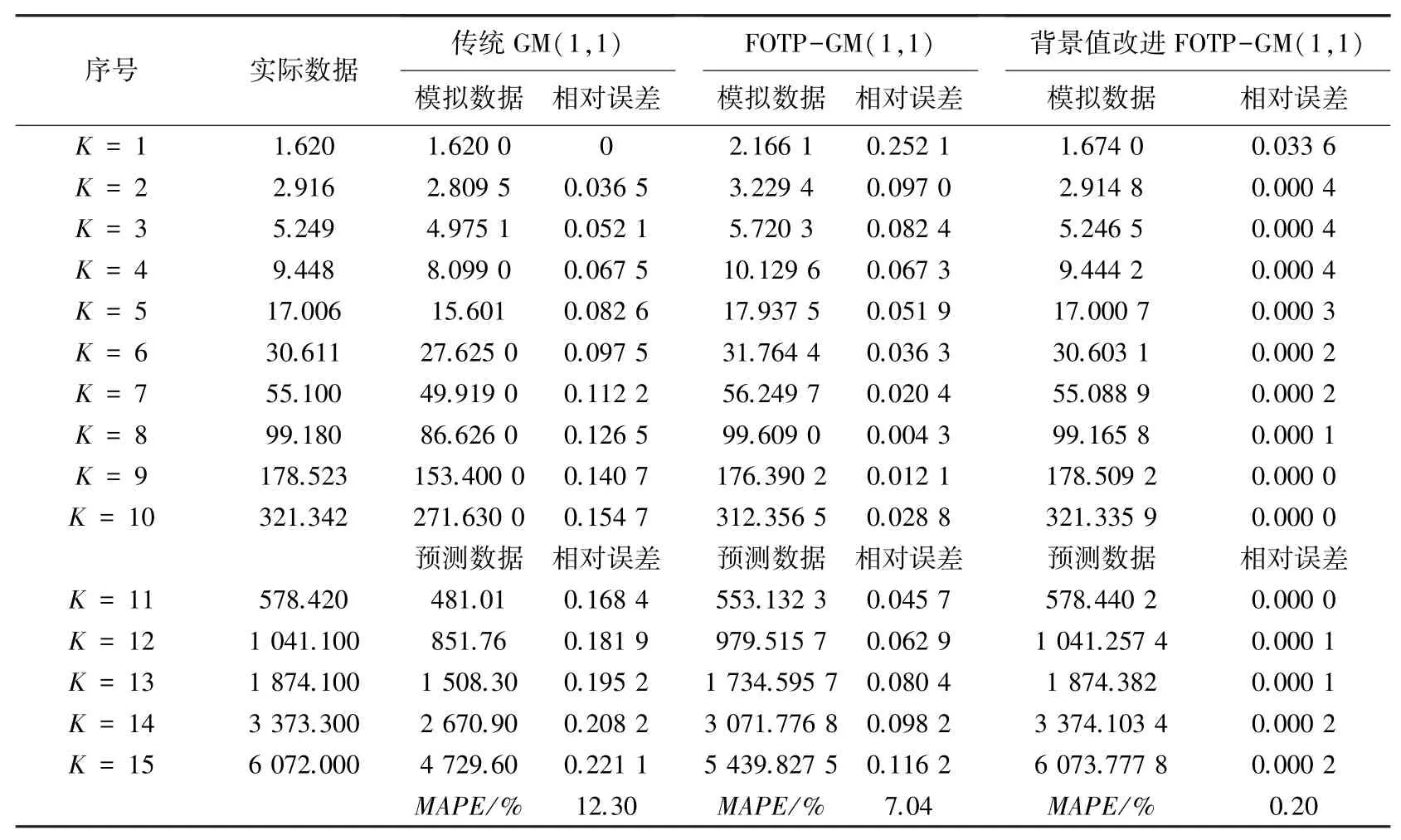
表2 齊次指數數序列計算結果Tab. 2 Calculation results of chi-square exponential number series
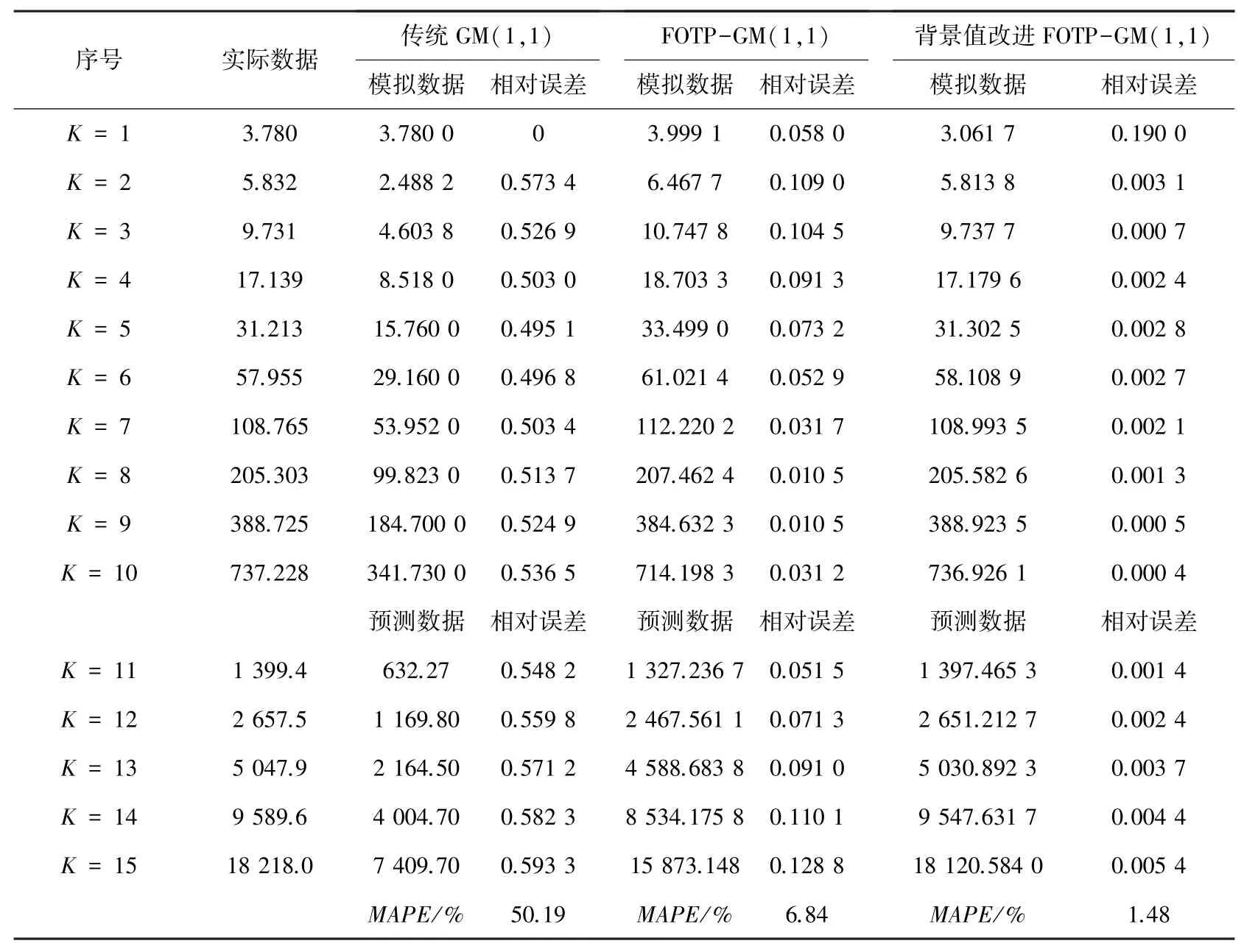
表3 帶常數項的非齊次指數數序列計算結果Tab. 3 Calculation results of non-simultaneous exponential number series with constant terms

表4 帶速度項和常數項的非齊次指數數序列計算結果Tab. 4 Calculation results of non-simultaneous exponential number series with velocity term and constant term
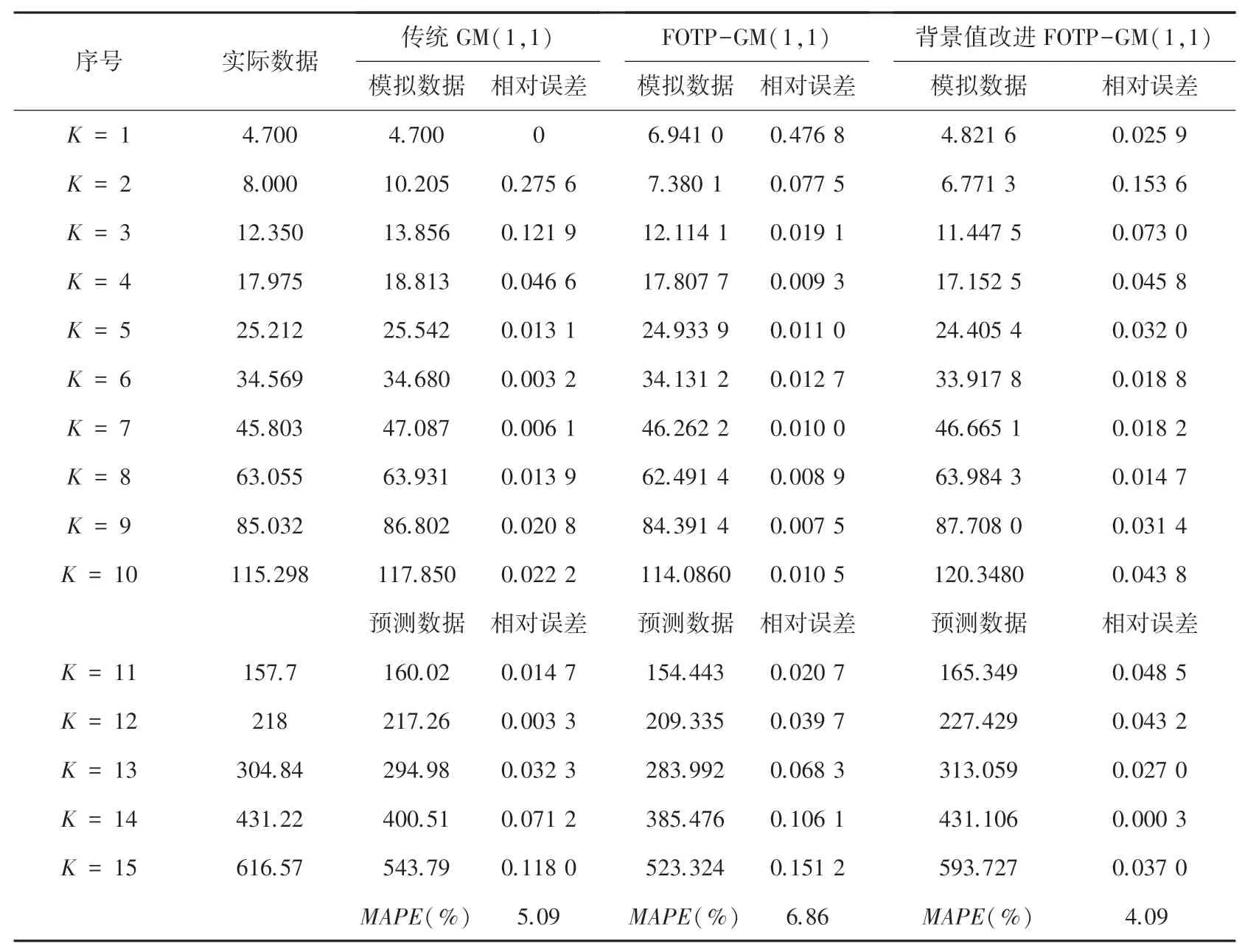
表5 帶加速度、速度、常數項的非齊次指數序列計算結果Tab. 5 Calculation results of non-simultaneous exponential series with acceleration,velocity,and constant terms
從上述表2~5 可以分析得到,經過背景值優化后的四階FOTP-GM(1,1)模型在預測精度上得到明顯提高,齊次指數序列預測精度較前2 種模型精度分別提高了98.37%和97.15%;帶常數項非齊次指數序列預測精度較前2 種模型精度分別提高了97.05%和78.36%;帶速度項、常數項非齊次指數序列預測精度分別提高了97.65%和85.21%;帶加速項、速度項、常數項非齊次指數序列預測精度提高了19.64%和40.37%,精度均得到了顯著提升。 將3 種模型按照輸出結果繪制模擬數據序列曲線和相對誤差曲線如圖1~圖8 所示。
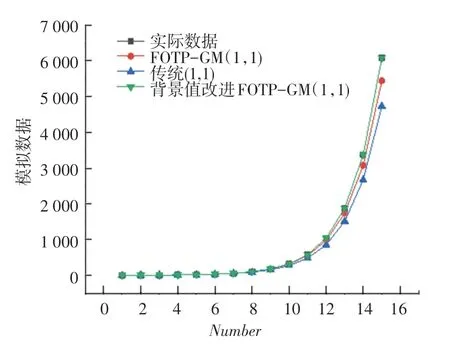
圖1 3 種灰色模型對齊次指數序列模擬曲線Fig. 1 Simulation curve of chi-square exponential series
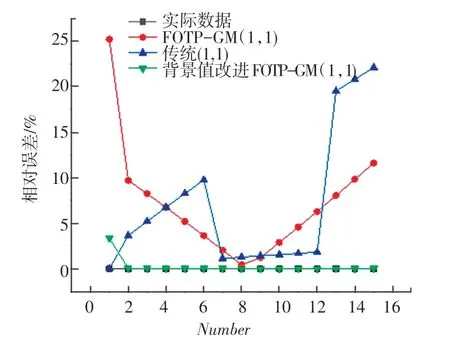
圖2 3 種灰色模型對齊次指數序列模擬相對誤差曲線Fig. 2 Simulation of relative error curves
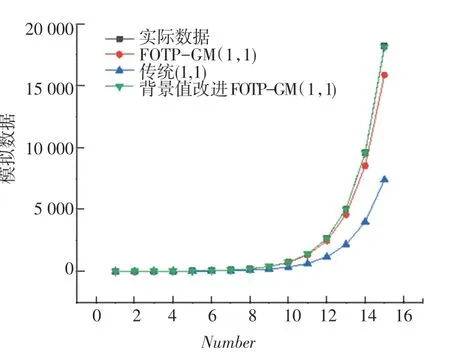
圖3 3 種灰色模型對帶常數項非齊次指數序列模擬曲線Fig. 3 Simulation curve of non-simultaneous exponential series with constant terms
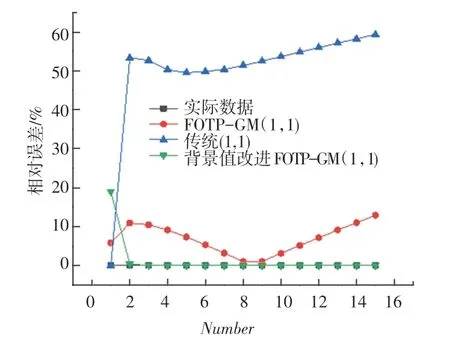
圖4 3 種灰色模型對帶常數項非齊次指數序列相對誤差曲線Fig. 4 Simulation of relative error curves
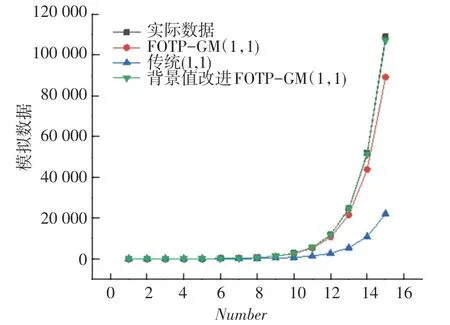
圖5 3 種灰色模型對帶速度項、常數項非齊次指數序列模擬曲線Fig. 5 Simulation curve of non-simultaneous exponential series with velocity term and constant term
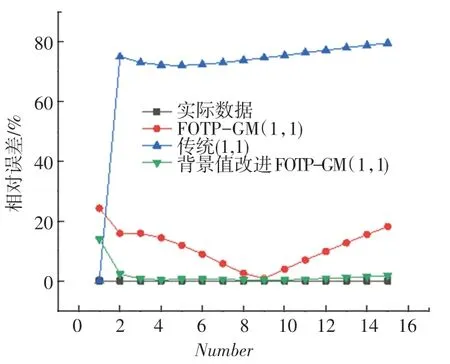
圖6 3 種灰色模型對帶速度項、常數項非齊次指數序列相對誤差曲線Fig. 6 Simulation of relative error curves with velocity term and constant term
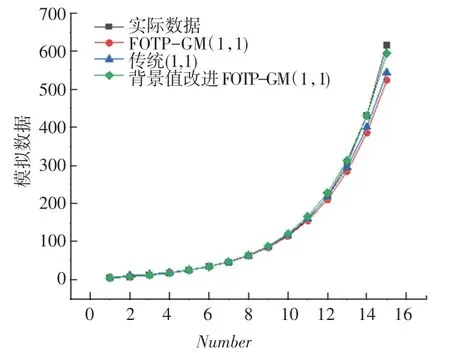
圖7 3 種灰色模型對帶加速度項、速度項和常數項非齊次指數序列模擬曲線Fig. 7 Simulation curve of non-simultaneous exponential series with acceleration,velocity and constant terrms
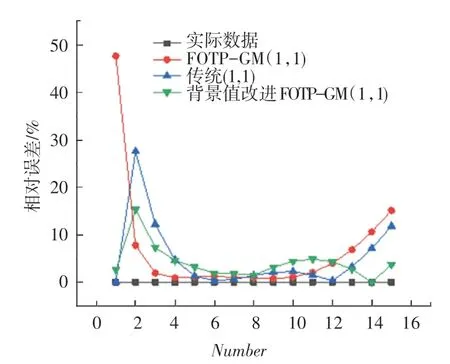
圖8 3 種灰色模型對帶加速度項,速度項,常數項非齊次指數序列相對誤差曲線Fig. 8 Simulation of relative error curves with velocity term and constant term
從上述圖1 ~8 分析可得背景值優化后的FOTP-GM(1,1)模型與實際曲線更貼合,相對誤差曲線較傳統GM(1,1)模型和FOTP-GM(1,1)模型波動更小,背景值優化效果得到體現。 通過精度對比,以誤差精度小于10%為標準進行篩選,得數據序列類型與灰色模型之間的適配關系見表6。
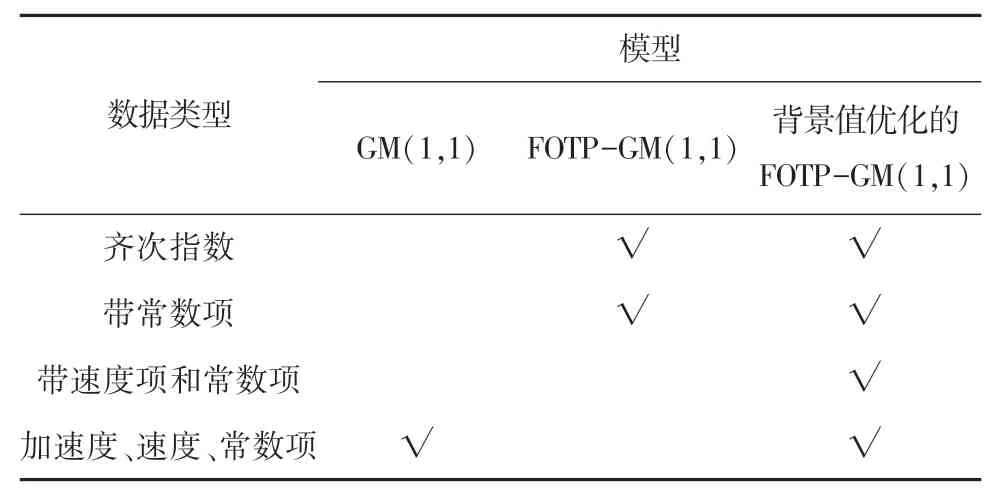
表6 模型與數據類型適配表Tab. 6 Model and data type adaptation table
4 結束語
全階時間冪灰色預測模型因為其自身的結構特點使得對近似非齊次指數特征的數據序列具有較好的預測精度。 但是在背景值構造過程中缺少理論依據,因此模型精度存在提高的可能。 本文將模型背景值α =0.5 更新為[0,1]內的動態值,利用粒子群優化算法在動態變化范圍內按照相對百分誤差最小為原則進行尋優,以尋求得到最合理的背景值α。得到最優背景值α后,帶入模型進行擬合輸出并與傳統GM(1,1)模型和未優化背景值的FOTP-GM(1,1)模型比較預測精度的變化情況。 以齊次指數序列、帶常數項的非齊次指數序列、帶速度項、常數項的非齊次指數序列和帶加速度項、速度項和常數項的非齊次指數數列為例,分別進行背景值的粒子群算法優化。 結果表明,經過背景值優化后4 種不同類型數據序列模擬精度以及預測精度均得到提高,齊次指數序列、帶常數項非齊次指數序列預測精度提升最為明顯,背景值優化后平均相對百分誤差只有0.02%和1.48%,帶加速度項、速度項、常數項的非齊次指數序列預測精度也得到了提升。 所以,FOTP-GM(1,1)模型本身可以適用于上述4 種數據類型,而這種將固定參數轉變為一定范圍內的動態值利用粒子群算法進行尋優,可以實現預測精度的顯著提升,也為相關灰色預測模型的改進優化提供了思路和研究方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
汽車工程師(2021年12期)2022-01-17 02:29:54
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
當代陜西(2020年14期)2021-01-08 09:30:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
貴州師范學院學報(2016年4期)2016-12-01 03:54:07
