機器學習高效篩選用于CO2/N2選擇性吸附分離的沸石材料
2023-03-01 07:39:50王璐張磊都健
化工進展 2023年1期
王璐,張磊,都健
(大連理工大學化工學院化工系統工程研究所,遼寧 大連 116024)
隨著全球氣候變暖問題愈發嚴重,為減少CO2溫室氣體的排放,碳捕獲和儲存(carbon dioxide capture and storage, CCS)已成為全球石油和天然氣、能源政策與可持續發展的重要議題。煤等化石燃料燃燒時所產生的煙道氣是CCS的主要應用領域之一。目前主流的CO2捕獲技術主要有燃燒前捕獲、富氧燃燒捕獲和燃燒后捕獲三種方式。燃燒前的碳捕獲將二氧化碳從氣化或重整過程中去除,然后生產合成氣以制造氫氣,或在綜合氣化聯合循環發電廠發電。燃燒前碳氫化合物含量較高,因此燃燒前捕獲通常效率高,但需要的成本更高,而且其性能沒有得到很好的測試。在富氧燃燒捕獲過程中,燃料在氧氣而不是空氣中燃燒,因此煙氣主要由CO2和SOx等雜質組成,捕捉難度低。然而氧濃度過高將導致腐蝕、污垢、潛在泄漏、維護成本高等問題,需要非常嚴格的安全管理[1]。燃燒后的碳捕獲是一種簡單的方法,是CCS現有設施的基礎。對比燃燒前捕獲和富氧燃燒捕獲,燃燒后捕獲的適用范圍更大,經濟可行性更高,因此本文主要研究用于電廠排放的燃燒后煙道氣中的CO2捕集。
煙道氣的典型組成包括13%CO2、73%N2、10%H2O、3%O2和其他污染物質,因此有必要將CO2分離出來,以減少溫室氣體的排放。變壓吸附技術(pressure swing adsorption, PSA)在氣體分離領域得到了廣泛的應用,已成為CO2捕集的一個有前途的候選技術,尤其對于高純度氣體產品的生產[2]。然而基于吸附過程的碳捕集需要高性能吸附材料的支持,目前金屬有機框架材料(MOFs)、各類碳基吸附材料(碳分子篩與活性炭)和沸石等多孔材料已被廣泛用于CO2捕集過程。沸石由于其獨一無二的籠狀與孔道結構及穩定、廉價的優點,在氣體吸附方面的應用非常廣泛。例如,Wu等[3]發現納米L型沸石對CH4和N2、CO2混合物中的CO2具有較強的分離和捕獲性能。沸石是一種微孔結構規律分布的硅鋁酸鹽晶體,而在實際中一些已得到廣泛應用的沸石材料則十分接近于純硅結構[4]。鑒于存在大量潛在的吸附材料,因此尋找有效的方法來評估吸附材料是變壓吸附CO2捕集工藝的關鍵。然而在大范圍篩選吸附材料時,目標氣體的單組分吸附等溫線往往是唯一可以獲得的信息,因此吸附材料的評估指標[5?9]可依據吸附等溫線來計算得到。
傳統的氣體吸附等溫線的測定方法為實驗法,但實驗法普遍具有耗費時間、金錢、人力物力的缺點。理論模擬計算的方法在克服以上缺點的基礎上還可以觀察到實驗中無法直接觀察到的現象及細節,因此理論模擬方法在該領域得到了越來越廣泛的應用。其中,分子力學方法中的巨正則蒙特卡洛(grand canonical Monte Carlo, GCMC)方法常被用來模擬吸附材料對氣體的吸附行為,這是因為巨正則系綜要求溫度、體積和化學勢的恒定,較適合研究氣體吸附和分離現象。例如,Mahmoud等[10]發現吸收量和孔徑之間存在著很大的聯系,是通過在一定溫度下用巨正則蒙特卡洛方法對氫氣分子在不同沸石結構中的等溫吸附曲線進行模擬得到的。在模擬過程中,吸附分子可以利用隨機移動方式(平移和旋轉等)實現從系統中移除現有分子,或向系統內的隨機位置中嵌入新分子。但隨著材料種類數的不斷增加,GCMC 方法所帶來的計算量也隨之增大。近年來,機器學習方法(machine learning, ML)的提出為省時并高效地快速發現材料提供了一條新的發展道路。例如,Lin等[11]將巨正則蒙特卡洛(GCMC)模擬與機器學習(ML)方法結合,系統地篩選了50959 個純硅分子篩結構,并用4 種線型硅氧烷及其衍生物進行驗證,得到230個具有良好吸附性能的分子篩。
機器學習作為人工智能領域的一個重要分支,其本質是使用算法模仿人類學習的方式從數據中自動獲取規律并進行改進。根據數據類型(數據是否含有標簽),可分為監督學習與無監督學習。目前化工領域常用的機器學習模型主要集中在監督學習,其主流模型包括支持向量機(SVM)模型、人工神經網絡(ANN)模型以及決策樹(DT)模型[12]等。其中ANN模型能夠充分逼近復雜的非線性關系,具有很強的自學習和自適應能力[13],因此其被廣泛用于研究材料的宏觀性質(物理和機械性能)與其微觀結構之間的構效關系[14],這恰恰符合本文的沸石結構與其吸附特性之間的關系(即結構-吸附性關系,簡稱SAR)。
ANN 是受生物神經系統啟發的計算網絡,與人腦的結構一樣,神經網絡模型由復雜非線性形式的神經元組成[15]。最早Rosenblatt[16]定義了一種被稱為感知器的神經網絡結構,這是之后很多神經網絡模型的始祖。然而單層感知器僅可解決線性可分的分類問題,因此必須在輸入輸出層間添加隱藏層構成多層感知器來進一步增強。這種多層感知器理念最早是由Werbos[17]提出的。隨后Rumelhart等[18]提出一般型Delta法則,即用反向傳播算法(back propagation,BP)進行前饋式多層神經網絡的機器學習訓練,解決了中間層參數的確定問題。繼BP 算法以后,Broomhead等[19]將徑向基函數引入神經網絡設計中,形成了徑向基神經網絡(RBF),標志著神經網絡開始真正邁向實用化。此后又衍生出了循環(遞歸)神經網絡[20]及卷積神經網絡等模型[21]。2006年,由Hinton等[22]提出的深度神經網絡(deep neural network, DNN)概念又一次引發了對神經網絡的研發浪潮,深度模型與淺層模型相比具有更大的潛力。
因此,為克服實驗法與理論模擬計算耗時等缺點,本文提出了一種基于機器學習方法的吸附材料篩選框架。首先,從Iyer等[23]的文獻中獲取由GCMC方法計算得到的沸石的吸附數據,引入沸石的結構描述符,建立基于ANN模型的沸石SAR預測模型。由此,利用已建立的機器學習模型來預測文獻中的一些缺失數據,然后通過擬合純組分氣體的吸附等溫線來預測混合氣體的吸附等溫線,以此計算幾種吸附材料評估指標,篩選候選沸石材料。最后,利用GCMC方法對篩選結果進行驗證。
1 基于機器學習的沸石吸附材料篩選框架
本節提出了沸石吸附材料的篩選框架,包括三個階段(如圖1所示)。在第一階段中,構建了基于機器學習的SAR模型,通過沸石的結構描述符快速預測氣體吸附數據,然后選用合適的等溫吸附模型分別擬合兩種氣體的吸附數據,通過擬合得到的參數利用理想吸附溶液理論(ideal adsorbed solution theory, IAST)[24]預測混合氣體吸附等溫線。在該階段,選用的幾種吸附材料評估指標均由混合物吸附數據計算得出,以獲得作為給定應用吸附材料的最佳候選材料列表。最后,通過混合氣體的GCMC計算結果進一步驗證候選沸石材料的吸附特性。
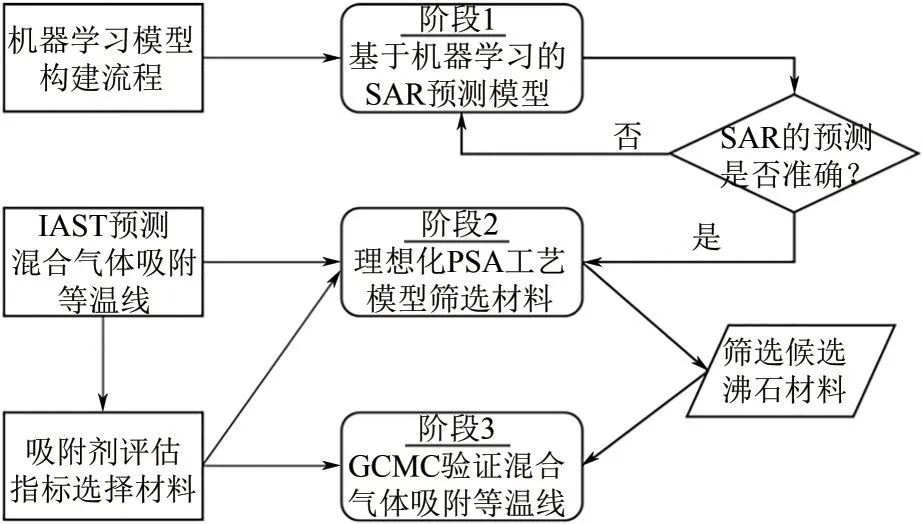
圖1 基于機器學習的沸石吸附材料篩選框架
1.1 基于機器學習模型的SAR預測模型
在第一階段,沸石的結構描述符與性質分別作為機器學習模型的輸入和輸出,將沸石骨架空腔、籠或孔道對應的天然構造單元(Natural Building Unit,NBU)[25]在模型中作為沸石的結構描述符。如圖2所示,LTA沸石骨架是由3種NBU以3∶1∶1的比例堆積而成的。模型的構建流程如圖3所示,可分為以下3個階段:數據收集及預處理、模型建立和模型測試。

圖2 LTA沸石骨架示意圖

圖3 機器學習模型構建流程圖
1.1.1 數據收集及預處理
原始數據主要由以下兩部分數據組成:第一,從IZA?SC[26]沸石數據庫中獲取186 種沸石的NBU組成。經統計,數據庫中大多數沸石由2種或3種NBU組合而成,80%的沸石結構由不超過5種NBU構造得到。另外,如圖4所示,對數據庫中的沸石結構,在3種溫度與11種壓力下通過GCMC模擬,得到了186種沸石對于氣體N2和CO2的吸附量(mol/kg)。

圖4 沸石吸附數據的來源組成
第二,在機器學習模型建立過程中,數據的分布應盡可能均勻,因此對吸附數據進行最小值-最大值線性歸一化,將數據映射到0~1 范圍內,如式(1)所示。
式中,Qmax和Qmin分別是平衡吸附量的最大值和最小值;Q是某個沸石(在一定溫度和壓力下)對某種氣體的平衡吸附量;Q?是該值歸一化后的數值。在對數據進行預處理后,為了避免在機器學習模型訓練時可能出現的過擬合現象[27],還需要對數據進一步劃分,并使用外部測試數據集來檢測已訓練的模型是否出現過擬合。
1.1.2 模型的建立
模型建立過程可以分為如圖5所示的4個子步驟:a.選擇合適的模型類型;b.設置參數構建模型;c.對模型進行訓練調參;d.驗證迭代后的模型是否符合要求。首先根據數據集大小、屬性類型和數量以及模型應用任務類型等特點,選擇合適的機器學習模型。具體地,本文采用淺層神經網絡而非深度神經網絡,這是因為數據庫中的沸石結構和氣體吸附量間關系相對明顯,使用太過復雜的模型是沒有必要的。圖6是一個簡單的三層神經網絡示意圖,圖中每一個基本組成單元是一個M?P神經元[28](圖7),單個神經元中的處理過程依據式(2)進行計算,其由n個輸入神經x和1 個輸出神經y組成,輸入和輸出神經分別伴有連接權重w與閾值偏差b。

圖5 模型建立流程

圖6 三層前饋神經網絡結構示意圖

圖7 M?P神經元模型
模型訓練階段目的是獲得一個優化的模型,其過程的目標是利用學習算法F來最小化模型M的代價函數fcost,可用式(3)表示。
式中,P是M模型的超參數;x'和y'分別代表經過預處理的輸入數據與輸出數據。由于超參數數量眾多,容易出現組合爆炸的問題,且在追求更高的模型性能的同時,參數的調整常常會造成過擬合的現象,因此本文采用一種貪心式調參策略來避免這一問題。如圖5所示,在模型訓練過程中,應首先使用神經網絡貪心式調參策略來配置具有一個隱含層的神經網絡的超參數。選定目標參數后,接下來確定初始值、上限和下限值以及增量/步長。之后基于上述配置,調整參數Pi,并使其他參數保留其初始值。當模型性能訓練達到最優狀態時,即可確定參數Pi的最佳值,再繼續調節下一個參數,直至確定所有參數的數值。
模型驗證階段主要是評估模型是否過擬合。一方面如果模型的性能經驗證后并不理想,則可以不斷添加隱含層,并調整相應的參數,除非模型發生過擬合。另一方面,如果模型發生過擬合,則建議在所構建的模型中添加正則化系數或丟棄部分神經元。
1.1.3 模型的測試
在模型經訓練和驗證之后,進一步通過預先劃分、與交叉驗證中所使用的訓練集不同的數據集測試該模型。在該階段,如果測試性能能夠達到期望值,則證明所構建的模型是有效的;否則,將使用新的結構描述符來關聯性質。
1.2 基于理想化PSA 工藝模型的沸石吸附材料篩選
本文采用了Ga等[2]提出的理想化PSA工藝模型,由于理想化PSA的模擬僅需要吸附材料的等溫線數據,不需要傳質速率、熱容和內部孔隙率這些需通過復雜、耗時的實驗來獲得的數據,因此可以更加方便、快速地進行吸附材料的篩選。針對文獻中提出的假設[2],繪制了如圖8 所示的理想化PSA 工藝模型示意圖:在等溫操作條件下,假設T=298K,該模型的進料采用摩爾分數(yi)為0.14/0.86的CO2/N2二元混合物,包括理想的吸附(ads)和解吸(des)兩個循環,組分S(strongly)和W(weakly)分別表示強吸附物質和弱吸附物質。模型對解吸步驟中產生的氣體組分的摩爾分數(y*i)進行數值求解,由此獲得在給定解吸條件下的吸附量(Qdes*i)。過程建模所需的基本信息為混合物的吸附平衡,本文采用理想吸附溶液理論(IAST)來預測在給定的摩爾分數及溫度下不同壓力的混合物吸附平衡。此外,本文采用的所有吸附材料評估指標均由混合物吸附數據(Qi)獲得。

圖8 理想化PSA工藝模型示意圖
1.2.1 理想吸附溶液理論(IAST)
Myers和Prausnitz[29]在1965年提出的理想吸附溶液理論(IAST)是一個被廣泛使用的熱力學框架,可從相同溫度下的純組分吸附等溫線來預測得到多組分吸附等溫線。該理論的基本假設條件是被吸附物質可以形成理想的混合物,IAST 的預測結果與各種氣體混合物和不同非均相吸附材料的實驗數據在數量上是一致的,這在許多文獻中被證實[29?33]。在這些適用的情況下,IAST可以省時省力地進行混合氣體吸附測量,即使對于分子模擬,模擬純組分吸附等溫線和應用IAST 也可能比運行多組分巨正則蒙特卡羅模擬更為迅速[34]。

a. Langmuir:
b. Dual-site Langmuir:
c. Quadratic:
d. Brunauer-Emmett-Teller (BET):
e. Temkin Approximation:
f. Henry’s law:
以IZA?SC[26]沸石數據庫中的WEI 沸石為例,利用pyIAST,在溫度T=298K下,通過擬合CO2與N2的GCMC 模擬數據,求出在總壓為35bar(1bar=105Pa)、物質的量組成為0.14/0.86時的CO2/N2混合物吸附數據。由圖9可知,經IAST預測得到的混合物吸附平衡時的CO2和N2的吸附量(mmol/g)與GCMC模擬計算得到的數據非常相近,這說明可以用IAST 來預測混合物的吸附平衡數據,從而使用1.2.2節中的評估指標來對吸附材料進行排序。

圖9 WEI在298K和35bar總壓下CO2/N2混合物平衡時的IAST驗證
1.2.2 吸附材料評估指標
為了評估材料作為捕獲氣體吸附材料的性能,許多研究者們從目標氣體的吸附等溫線出發,陸續提出了一些評估吸附材料性能的指標[5,7?9,35?36],如表1所示。

表1 吸附材料評價指標
式中,擺動能力?QCO2定義為在吸附壓力和解吸壓力下氣體捕獲能力之間的差異。混合物吸附選擇性(Sadsads,CO2/N2/Sdesads,CO2/N2)定義為在吸附壓力Ptotal,ads或解吸壓力Ptotal,des下,各組分的吸附容量與體相中各組分摩爾分數yi之比。吸附材料選擇參數SSP,CO2/N2和吸附材料性能分數APSCO2/N2以不同的方式結合了目標組分與競爭組分的擺動能力以及吸附和解吸壓力下的吸附選擇性。此類指標旨在反映擺動能力和吸附選擇性之間存在的權衡關系。最后一個指標再生能力R,即在吸附壓力下,擺動能力與強吸附物質的吸附量之比。該參數估計解吸步驟中能夠再生的吸附位點的分數。以上所有吸附材料評估指標均根據混合物吸附數據(Qi)計算得出。
1.3 使用GCMC方法對沸石篩選結果進行驗證
對于已篩選出來的候選沸石材料,使用分子模擬軟件RASPA[37]中的GCMC方法,計算沸石在給定溫度壓力下對CO2/N2二元混合物的平衡吸附量。GCMC模擬需要設置的參數如表2所示,用于描述范德華作用力的Leonard?Jones相互作用參數是從純硅沸石的Garcia?Perez力場[38]中獲得的。為了獲得具有統計學意義的結果,模擬了50000個平衡和50000個循環周期。CO2和N2使用統一的分子類型,且各種隨機移動(平移、旋轉、重新插入)的概率相等,并將交換操作中的插入和刪除的概率設為1。此外,在不考慮因堵塞使得分子無法進入孔的情況下,選取一個3×3×3的晶格單位(晶胞)進行模擬,并且采用了周期性邊界條件。將模擬結果與通過IAST 預測的混合物吸附數據作比較,驗證沸石對CO2/N2的分離性能。

表2 GCMC模擬參數設置
2 算例分析與討論
本節使用燃燒后煙道氣的處理作為算例,煙道氣主要由CO2與N2組成,為減少溫室氣體的排放,主要目標是從CO2/N2混合物中捕獲CO2。雖然真實的煙道氣中除了CO2與N2,還包含H2O、O2、CO、SOx、NOx和Hg等雜質,但現在還沒有足夠的信息來準確預測這些微量雜質對吸附過程產生的影響。且已有研究表明,通過適當的設計手段,可以實現干煙氣進料[39]。因此,該算例可簡化為從摩爾分數為0.14/0.86且不含其他成分的干散裝CO2/N2二元混合物中吸附分離CO2。
首先,建立SAR模型。基于Iyer文獻[23]數據庫中個別值的缺失,首先則需要對CO2及N2的吸附數據進行剔除空白值操作,然后將所有數據按9折交叉驗證法劃分為訓練集、驗證集和外部測試集,具體見表3。最后以回歸系數R2[見式(14)]和均方根誤差RMSE[見式(15)]為指標來評估ANN模型的性能。

表3 SAR模型的數據劃分
在模型訓練過程中,應首先使用神經網絡貪心式調參策略來配置具有1層隱含層的神經網絡模型,隨后又增加到了2層隱含層,發現模型性能沒有顯著地提高,因此本文最終選用了僅有1層隱含層的三層前饋神經網絡。不斷增加神經元數量,CO2、N2的模型性能分別如表4、表5所示,其中的R2和RMSE值均為交叉驗證中的9組不同數據組合的平均值。從表4的結果可知,神經元個數等于9時,CO2的預測模型性能最佳,即訓練集、驗證集及外部測試集的RMSE值最小,R2值最接近于1。同樣地,對于N2的預測模型,神經元個數為13時,效果最好,由此給出了如圖10 所示的最優神經網絡結構下的CO2及N2的訓練結果圖。綜上所述,對于CO2和N2,驗證集和外部測試集的預測結果說明模型沒有出現過擬合且泛化能力較好,因此用NBU 描述符來預測沸石的吸附性是有效的。

圖10 CO2及N2的訓練集、驗證集和外部測試集的訓練結果

表4 CO2的模型性能

表5 N2的模型性能
其次,根據純組分的吸附等溫線通過IAST 來預測CO2與N2混合物平衡吸附數據,然后使用表1中的吸附材料評估指標對154種沸石(具有完整的GCMC模擬數據)進行表征,引入圖11的材料選擇策略來篩選候選沸石材料。其中,擺動能力是在CO2分壓為2.7bar(PCO2,ads)和0.1bar(PCO2,des)時的CO2容量差來計算得到的,它的下限設定為3mol/kg。吸附選擇性則是考慮將吸附相中CO2的摩爾分數下限設定為0.9。但高選擇性吸附材料不能保證高再生性,故將再生能力下限設為75%。

圖11 吸附材料評估指標篩選材料
最佳吸附材料為滿足所有這些約束條件的候選吸附材料(Ⅰ組),并考慮了滿足部分但非全部約束條件的材料(Ⅱ、Ⅲ、Ⅳ組)。表6為篩選得到的Ⅰ、Ⅱ、Ⅲ、Ⅳ組沸石名稱列表。第Ⅲ組的沸石具有較高的CO2選擇性,但CO2擺動能力不太大,例如MVY 沸石的CO2/N2選擇性高達2986,但?QCO2只有1.9mol/kg。第Ⅱ組沸石與第Ⅲ組正好相反。第Ⅳ組沸石GIS、SIV、WEI除了再生能力不高外,CO2擺動能力及選擇性都比較大。進一步根據指標吸附材料選擇參數SSP,CO2/N2和吸附材料性能分數APSCO2/N2來對Ⅰ組沸石進行排序,具體結果與各項指標如表7所示。

表6 篩選得到的不同組別沸石列表
對于缺失模擬數據的32 種沸石材料,首先利用前面所建立的機器學習模型進行預測得到完整的吸附數據,同樣地,再利用IAST與吸附材料評估指標篩選出符合圖11中各項約束條件的沸石有VSV、RSN 及KFI,3 種沸石的各項指標數值如表7 最后三行所示。


表7 Ⅰ組沸石的吸附材料指標數值


圖12 GCMC模擬驗證候選沸石的混合物吸附等溫線

3 結論
日益增長的材料種類使得通過實驗法與理論模擬計算的方法來快速發現具有優異性能的理想材料變得十分困難。因此,本文提出了一種基于機器學習的吸附材料篩選框架,用于高效地選擇具有良好CO2捕集能力的沸石材料。通過建立機器學習模型,證明了沸石結構描述符(即NBU 描述符)能夠很好地預測其吸附性能(訓練集、驗證集及外部測試集的R2值均在0.99以上)。此外,理想吸附溶液理論可以將純組分的吸附等溫線轉化為更為精確表征氣體分離問題的混合物吸附等溫線,并舉例證明了IAST 的預測結果與GCMC 模擬的計算結果在數值上是高度一致的。由此可通過混合物吸附數據來計算擺動能力、吸附選擇性、再生能力等吸附材料評價指標來選擇候選沸石材料,最后用GCMC方法進行了驗證。本文將該框架應用于溫度T=298K、摩爾分數為0.14/0.86 的CO2/N2吸附分離CO2過程中,成功地從154種沸石材料中篩選出了滿足所有吸附材料指標約束條件的8種沸石材料,另外的32種材料的純組分吸附數據由機器學習模型補充,從而篩選得到了3種高性能候選沸石材料,證明了本文所提框架的可行性與有效性。該方法有望通過機器學習模型預測更多沸石材料的吸附特性,加速具有目標吸附特性的材料發現過程。同時可通過改變二元混合物的摩爾分數,篩選適應于不同氣體分離背景下的吸附材料。
符號說明


猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
云南化工(2021年10期)2021-12-21 07:33:24
煤氣與熱力(2021年9期)2021-11-06 05:22:56
湖南飼料(2021年3期)2021-07-28 07:06:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
石油化工(2015年9期)2015-08-15 00:43:05
應用化工(2014年1期)2014-08-16 13:34:08
