EMD與XGBoost組合算法對(duì)門診量預(yù)測(cè)的研究與分析
2023-03-06 12:06:14陳娜郁曉晨
微型電腦應(yīng)用 2023年1期
陳娜, 郁曉晨
(上海市第六人民醫(yī)院,財(cái)務(wù)處, 上海 200233)
0 引言
在醫(yī)院的日常管理中,門診量無疑是重要的影響要素之一,在一定程度上反映了醫(yī)院的規(guī)模、醫(yī)療水平。因此,若能正確的預(yù)測(cè)門診量,提前做好醫(yī)生、護(hù)士的調(diào)控分配,不僅可以很好的提高醫(yī)院的工作效率,也可以大幅度提升病人的醫(yī)療體驗(yàn)感。
本文以給醫(yī)院管理者提供決策支持為目的,對(duì)醫(yī)院門診量進(jìn)行預(yù)測(cè),為醫(yī)療衛(wèi)生資源的合理配置提供依據(jù)。傳統(tǒng)的門診量預(yù)測(cè)通常使用灰色模型[1]、差分整合移動(dòng)平均自回歸模型(ARIMA)[2]等算法,或者將ARIMA模型與其他模型進(jìn)行簡(jiǎn)單的組合[3-4],但是時(shí)間顆粒度較粗(通常為周、月、季度或年),預(yù)測(cè)效果仍有提升空間。本文考慮到醫(yī)院的門診量有著明顯的時(shí)間特征,首先將其時(shí)間特征納入考慮范疇,通過歷史門診量可以發(fā)現(xiàn)門診量數(shù)據(jù)并不平穩(wěn),尤其是以天為單位的門診量,波動(dòng)尤為劇烈,因此我們利用EMD對(duì)門診量序列進(jìn)行分解。以往結(jié)合EMD的組合算法[5]一般只考慮了時(shí)間序列的特征,并未考慮外部因素。一些外部特征與門診量可能存在一定程度的相關(guān)性,因此在本文中,我們同時(shí)考慮了門診量也受到天氣、溫度等外部特征的影響,提出了EMD分解[6]和XGBoost[7]的組合算法,利用上海某醫(yī)院門診情況來構(gòu)建門診量預(yù)測(cè)模型,分別預(yù)測(cè)未來1天、7天、30天的門診量之和。
1 數(shù)據(jù)與方法
1.1 數(shù)據(jù)來源
本文門診數(shù)據(jù)來源于上海某醫(yī)院2016年1月至2019年1月門診報(bào)表,部分?jǐn)?shù)據(jù)見表1。
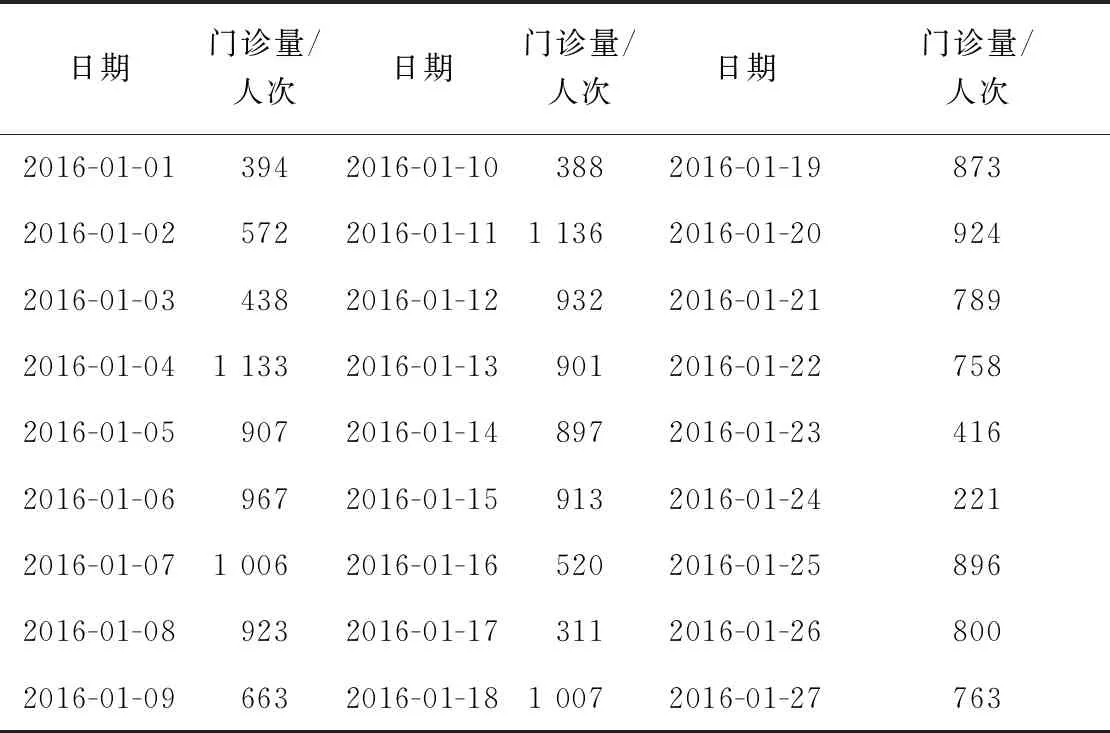
表1 上海某醫(yī)院部分門診量數(shù)據(jù)
本文天氣數(shù)據(jù)來源于互聯(lián)網(wǎng),根據(jù)該醫(yī)院所在區(qū)域檢索歷史天氣情況,簡(jiǎn)單處理后部分?jǐn)?shù)據(jù)見表2。
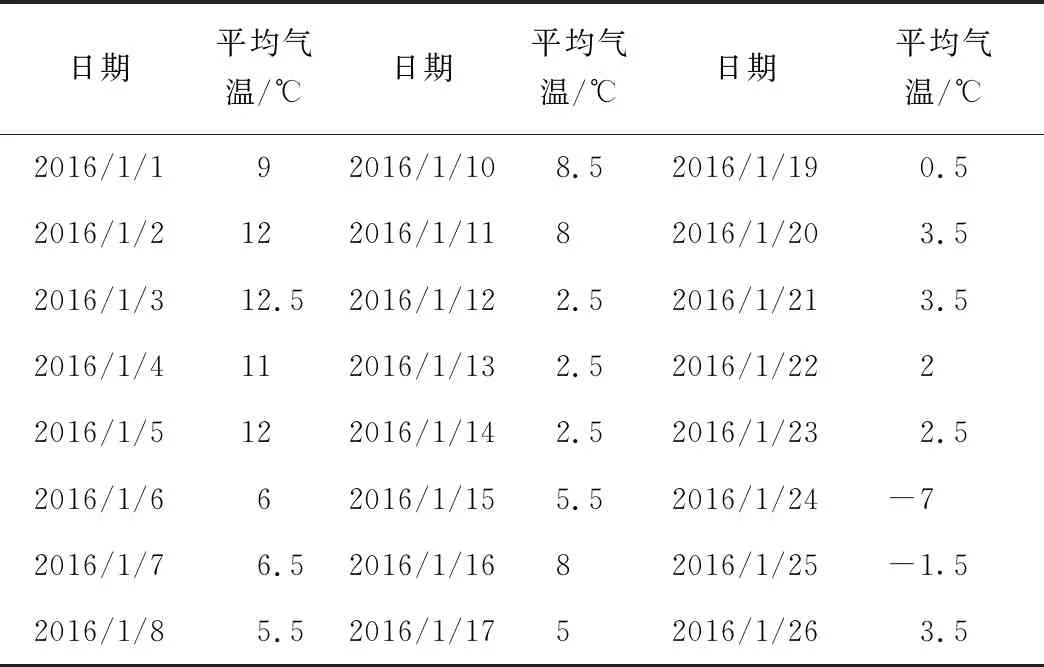
表2 上海某地區(qū)部分天氣數(shù)據(jù)
1.2 相關(guān)技術(shù)
1.2.1 經(jīng)驗(yàn)?zāi)B(tài)分解(EMD)
經(jīng)驗(yàn)?zāi)B(tài)分解(EMD)是由黃鍔等[8]提出的一種創(chuàng)造性的、新型自適應(yīng)信號(hào)時(shí)頻處理方法。基于該方法來處理非平穩(wěn)非線性序列有著優(yōu)良的數(shù)值效果,目前已經(jīng)在地球物理學(xué)領(lǐng)域、生物醫(yī)學(xué)領(lǐng)域、結(jié)構(gòu)分析領(lǐng)域、設(shè)備診斷領(lǐng)域、成像領(lǐng)域等得到應(yīng)用。
EMD分解方法基于以下假設(shè)條件:數(shù)據(jù)至少有兩個(gè)極值,一個(gè)最大值和一個(gè)最小值;數(shù)據(jù)局部時(shí)域特性由極值點(diǎn)間的時(shí)間尺度唯一確定;如果數(shù)據(jù)沒有極值點(diǎn)但有拐點(diǎn),則可通過對(duì)數(shù)據(jù)微分一次或多次求得極值,然后再通過積分獲得分解結(jié)果。
設(shè)有時(shí)間序列,EMD分解可以將非線性、非平穩(wěn)的數(shù)據(jù)序列分解為多個(gè)平穩(wěn)單一的序列,即,其中為本征模函數(shù)。本征模函數(shù)必須滿足以下兩個(gè)條件:極值和過零點(diǎn)的數(shù)目必須相等,或者至多差一個(gè);在任意數(shù)據(jù)點(diǎn),局部最大值的包絡(luò)和局部最小值的包絡(luò)的平均必須為零。時(shí)間序列的分解過程如下。
設(shè)有時(shí)間序列X(t),EMD分解可以將非線性、非平穩(wěn)的數(shù)據(jù)序列X(t) 分解為多個(gè)平穩(wěn)單一的序列,即X(t)=∑imf(t)+bias,其中imf(t)為本征模函數(shù)。本征模函數(shù)必須滿足以下兩個(gè)條件:極值和過零點(diǎn)的數(shù)目必須相等,或者至多差一個(gè);在任意數(shù)據(jù)點(diǎn),局部最大值的包絡(luò)和局部最小值的包絡(luò)的平均必須為零。時(shí)間序列X(t)的分解過程如下:
(1) 確定時(shí)間序列X(t)的所有局部極值點(diǎn),分別用曲線連接所有的極大值點(diǎn)和極小值點(diǎn),如此得到時(shí)間序列的上下包絡(luò)線,令上下包絡(luò)線的平局值為m(t);
(2) 令h1(t)=X(t)-m(t),對(duì)h1(t)重復(fù)上述步驟,直至滿足本征模函數(shù)的條件,即h1(t)是一個(gè)基本模式分量,這時(shí)得到新的序列X1(t)=X(t)-h1(t);
(3) 對(duì)新的時(shí)間序列X1(t)重復(fù)上述步驟,分別提取出n個(gè)基本模式分量。此時(shí),時(shí)間序列Xn(t)變?yōu)橐粋€(gè)單調(diào)序列,不包含任何模式的信息,即為原始序列的余項(xiàng),bn=Xn(t)。至此,原始時(shí)間序列被分解為多個(gè)imf分量和一個(gè)殘差序列。
1.2.2 XGBoost算法
XGBoost是一種在Gradient Boosting框架下實(shí)現(xiàn)的的機(jī)器學(xué)習(xí)算法,由于其出色的效率,被數(shù)據(jù)科學(xué)家廣泛的使用。
對(duì)于給定有m個(gè)特征、大小為n的數(shù)據(jù)集D={(Xi,yi)}(|D|=n,Xi∈Rm,yi∈R),樹型集成模型(即第i個(gè)實(shí)例的預(yù)測(cè)值)可以表示為
(1)
其中,H={f(X)=ωq(X)},(q:Rm→T,ω∈RT),K表示樹的數(shù)量,q表示將實(shí)例映射到相應(yīng)的葉子節(jié)點(diǎn)上的樹的結(jié)構(gòu),T表示樹的葉子數(shù)量,ω表示葉子節(jié)點(diǎn)的分?jǐn)?shù)。我們最小化以下正則化目標(biāo)函數(shù)來得到模型需要的函數(shù):
(2)
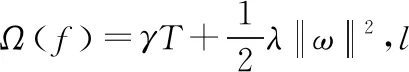
(3)
即式(3)表示第i個(gè)實(shí)例在第t次迭代時(shí)的誤差函數(shù)。根據(jù)式(2),這就意味著需要增加最能改進(jìn)模型的ft。將式(3)泰勒展開得到:
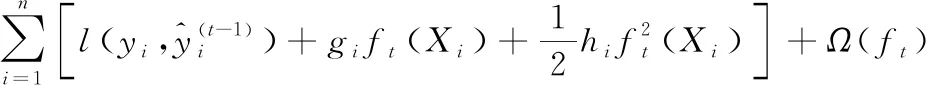
(4)
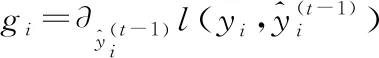
(5)
令I(lǐng)j={i|q(Xi)=j},表示在葉子節(jié)點(diǎn)上的實(shí)例集合。因此式(5)可以變換為
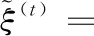
(6)
(7)
帶入目標(biāo)函數(shù)可以得到最優(yōu)解:
(8)
式(8)可以用來衡量樹結(jié)構(gòu)q好壞的指標(biāo)。一般來說,枚舉所有的樹結(jié)構(gòu)q是不可能的,因此這里用一個(gè)貪婪算法,它從一個(gè)葉子開始,迭代地向樹中添加分支。設(shè)IL和IR分別是分支后左節(jié)點(diǎn)和右節(jié)點(diǎn)的集合,且I=IL∪IR,則一次分支后誤差函數(shù)為
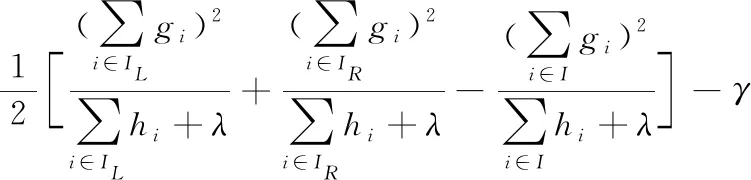
(9)
根據(jù)式(8),利用上式作為分支的評(píng)價(jià)指標(biāo),不斷重復(fù)分支,即得到最終的樹。
1.3 評(píng)價(jià)指標(biāo)
本文采用兩種不同的指標(biāo)對(duì)預(yù)測(cè)模型進(jìn)行評(píng)價(jià),分別為均方根誤差(RMSE)以及平均絕對(duì)百分比誤差(MAPE)。RMSE和MAPE越小,說明模型效果越好。
RMSE和MAPE的計(jì)算式如下:
(10)
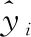
1.4 特征選擇
本文的特征選擇從天氣特征以及時(shí)間特征兩個(gè)方面出發(fā),具體如下。
(1) 天氣特征:天氣的變化會(huì)影響身體狀況,因此可能對(duì)醫(yī)院門診量也有影響。若溫度驟降會(huì)引起感冒發(fā)燒的病人增多,或從冬天過渡到春天時(shí),溫度上升,各種植物和粉塵增多,會(huì)引起過敏的病人增多,因此醫(yī)院的門診量也會(huì)相對(duì)應(yīng)的有所上升。
(2) 時(shí)間特征:從已有的數(shù)據(jù)可以看出,門診量存在某些周期性,因此本文也相應(yīng)的構(gòu)建了時(shí)間特征,例如是一周內(nèi)第幾天、前一天門診量等。
2 預(yù)測(cè)模型
2.1 模型原理
時(shí)間序列問題的預(yù)測(cè),其主要思想是利用歷史時(shí)序數(shù)據(jù)進(jìn)行統(tǒng)計(jì)分析,找到變化規(guī)律,通過建模將該規(guī)律應(yīng)用到預(yù)測(cè)未來上。對(duì)于門診量的預(yù)測(cè),不僅在一定程度上遵循時(shí)間變化規(guī)律,并且還受到天氣、溫度等因素的影響,因此,本文將預(yù)測(cè)門診量的特征分為兩個(gè)部分:一是將歷史時(shí)間特征進(jìn)行EMD分解,得到包含各個(gè)時(shí)間尺度特征的基本模式分量;二是包含天氣等因素的非時(shí)間特征,然后對(duì)各分量結(jié)合非時(shí)間特征利用XGBoost算法進(jìn)行建模,各分量預(yù)測(cè)結(jié)果加和得到最終門診量的預(yù)測(cè)值,如圖1所示。
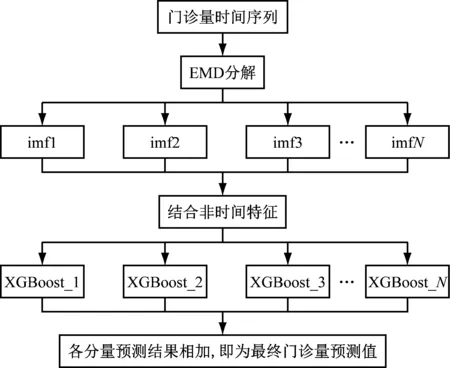
圖1 EMD+XGBoost組合算法示意圖
2.2 建模過程
設(shè)門診量時(shí)間序列為X(t)={x1,x2,x3,x4,x5,…,xn},對(duì)序列X(t)進(jìn)行EMD分解,共得到N個(gè)分量{imf1,imf2,imf3,imf4,imf5,…,imfN}和一個(gè)殘差序列bN,對(duì)N個(gè)分量和殘差序列分別建立XGBboost模型進(jìn)行預(yù)測(cè),即產(chǎn)生N+1個(gè)XGBboost模型,然后將預(yù)測(cè)結(jié)果相加,即為最終門診量的預(yù)測(cè)值。
在進(jìn)行預(yù)測(cè)前,因?yàn)楦鱾€(gè)特征的量綱不同,因此需要先進(jìn)行標(biāo)準(zhǔn)化,使模型預(yù)測(cè)更加合理、準(zhǔn)確。預(yù)測(cè)時(shí),將每一個(gè)分量imfi,i=1,…,N,作為一個(gè)特征,用前x天來預(yù)測(cè)x+1天(或x+7、x+30天);另外,由于門診量還受到天氣等非時(shí)間因素的影響,因此在建立模型時(shí),也將這些作為特征考慮。
3 模型結(jié)果及分析
我們對(duì)門診量時(shí)間序列進(jìn)行EMD分解,數(shù)據(jù)為從2016年每日門診量,分解結(jié)果如圖2所示。

圖2 部分門診量數(shù)據(jù)EMD分解示意圖
signal為原始門診量時(shí)間序列,imf1到imf6為原始序列被分為的6個(gè)分量,由上圖可以看出其波動(dòng)性逐漸減弱,平穩(wěn)性逐漸增強(qiáng),res為趨勢(shì)線。
本文預(yù)測(cè)了三種情形下的2018年門診量:未來1天門診量;未來7天門診量之和;未來30天門診量之和。從預(yù)測(cè)結(jié)果的RMSE來看,組合算法在第1種情況下效果最好,平均RMSE 為71.315,此時(shí)MAPE為6.691%,RMSE 和MAPE最小達(dá)到0.281和0.018%;從MAPE來看,組合算法在第2種情況下效果最好,平均MAPE為4.050%,此時(shí)RMSE為353.106,RMSE和MAPE最小達(dá)到9.214和0.110%;綜合來看,組合算法更適合在第1種情形下運(yùn)行。
當(dāng)然,若預(yù)測(cè)一周日平均和一月日平均門診量,可以看出RMSE有所下降,甚至比預(yù)測(cè)未來1天門診量表現(xiàn)的更好(RMSE分別下降了29.27%和31.02%)。這是因?yàn)槿臻T診量受到外部因素的影響更大,因此波動(dòng)性也大;而周門診量與月門診量從一定程度上削弱了外部因素的影響,它們更加穩(wěn)定(若因?yàn)槟承┰蚯耙惶斓牟∪吮绕饺蛰^少,但是這部分病人會(huì)在第二天或者后面幾天來醫(yī)院),所以平均到每日效果會(huì)更好。
為了進(jìn)一步的體現(xiàn)EMD+XGBoost組合算法的性能,我們還對(duì)應(yīng)的用單XGBoost算法作為對(duì)照。通過結(jié)果對(duì)比可以看出,加入了EMD分解后,模型的預(yù)測(cè)結(jié)果得到了顯著提高,在三種情形下RMSE分別提高了16.87%、20.34%和4.00%,MAPE分別提高了18.74%、18.35%和0.80%。這里可以看出,在情形3)下EMD+XGBoost組合算法與單XGBoost算法的差距很小,這也是因?yàn)樯衔乃f,30天門診量的波動(dòng)性較小,而EMD更善于處理平穩(wěn)性差的時(shí)間序列上。也從側(cè)面說明,組合算法更適合第1種情形。
綜上,EMD+XGBoost組合算法在處理日門診量預(yù)測(cè)和周門診量預(yù)測(cè)時(shí),優(yōu)于單XGBoost算法。
EMD+XGBoost組合算法及單XGBoost算法在三種預(yù)測(cè)情形下的RMSE和MAPE如下圖3、圖4所示。
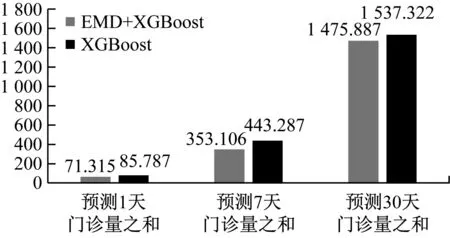
圖3 EMD+XGBoost組合算法與單XGBoost算法RMSE對(duì)比
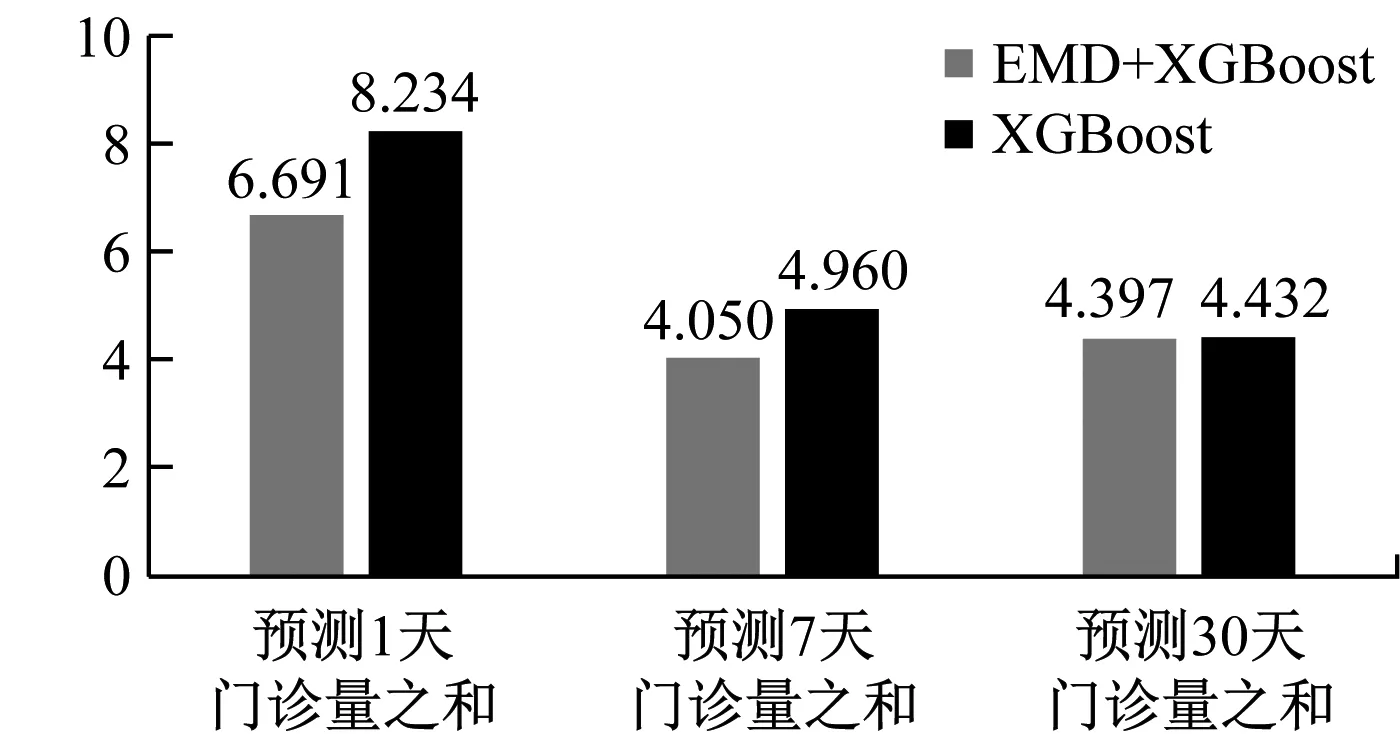
圖4 EMD+XGBoost組合算法與單XGBoost算法預(yù)測(cè)MAPE對(duì)比
4 總結(jié)
本文提出了一種EMD+XGBoost的組合預(yù)測(cè)算法。針對(duì)門診量時(shí)間序列,通過EMD對(duì)時(shí)間序列進(jìn)行平穩(wěn)性處理,再結(jié)合XGBoost進(jìn)行預(yù)測(cè)。相比較傳統(tǒng)的利用灰色模型、差分整合移動(dòng)平均自回歸模型(ARIMA)等,組合預(yù)測(cè)算法更好的結(jié)合了EMD和XGBoost兩個(gè)算法的優(yōu)點(diǎn),在預(yù)測(cè)時(shí),不僅僅只依據(jù)時(shí)間特征,并且加入考慮了外部因素,在預(yù)測(cè)日門診量時(shí)表現(xiàn)的更好,細(xì)化了門診量預(yù)測(cè)的時(shí)間顆粒度,使得模型更加仿真,得到的預(yù)測(cè)值也更接近于真實(shí)值。
本文雖然考慮了天氣的外部因素,但是在真實(shí)情況下,影響門診量的因素更多,也更為復(fù)雜,比如醫(yī)院的地理位置,區(qū)域人口等。加入這些因素,將提高模型的泛化能力。但是,當(dāng)外部因素增多時(shí),其與時(shí)間因素在模型中的權(quán)重如何控制是一個(gè)難題,若某一方的權(quán)重過大,可能會(huì)適得其反,使模型結(jié)果變差。因此,在門診量預(yù)測(cè)的問題上,還有進(jìn)一步研究的空間。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
兒童繪本(2018年10期)2018-07-04 16:39:12
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
小朋友·快樂手工(2016年5期)2016-05-14 17:18:34
中國(guó)衛(wèi)生(2015年8期)2015-11-12 13:15:20
