基于改進YOLOv4-Tiny模型的紅外弱小目標檢測
2023-03-07 01:25:16蔡廣飛
無線電工程 2023年2期
李 揚,蔡廣飛
(1.江蘇商貿職業學院 電子與信息學院,江蘇 南通 226011;2.江蘇省物聯網與視覺智能處理工程技術研究開發中心,江蘇 南通 226011)
0 引言
光電檢測技術[1]在現代化戰爭中所扮演的角色愈發關鍵,同時在海事搜救、航空航天及農業生產等領域也發揮了積極的作用[2]。紅外熱成像設備具有隱蔽性好、機動性佳以及環境適應能力強等優點,成為光電檢測技術的一個研究熱點[3]。國際光學工程學會(Society of Photo-Optical Instrumentation Engineers,SPIE)[4]將占圖像面積比例小于 0.15%的目標定義為紅外弱小目標,致使紅外弱小目標缺少形狀、顏色以及紋理等視覺信息,為弱小目標檢測任務帶來了極大的困難與挑戰[5]。
當前主流的紅外弱小目標檢測方法大體可分為基于空間域[6]、基于變換域[7]與基于神經網絡[8]三大類別。基于空間域的檢測方法[6]通常采用圖像預處理技術使目標與背景分離,在此基礎上再增強目標特征并抑制背景噪聲。基于變換域的檢測方法[7]通常對紅外圖像進行濾波來預測目標可能出現的區域,然后在變換域對目標進行精細化預測。基于神經網絡的檢測方法[8]主要利用神經網絡強大的特征學習能力提取紅外圖像的特征,能有效解決基于空間域與基于變換域提取特征的局限性,再結合分類器對圖像中的目標進行檢測與分類。基于空間域與基于變換域的紅外弱小目標檢測方法具有檢測效率高、無需訓練的優點,但在復雜背景下的檢測虛警高、準確性低。基于神經網絡的紅外弱小目標檢測方法檢測準確性較高,但其訓練難度大且檢測效率較低[9-10]。
文獻[11]提出基于完全連接卷積神經網絡的紅外弱小目標檢測方法,利用完全卷積網絡初步檢測紅外弱小目標與抑制背景,利用分類網絡對候選目標點進行精細化選擇。文獻[12]提出基于完全卷積網絡和稠密條件隨機場的深度學習分割算法,利用全卷積網絡進行像素級別特征提取,使用稠密條件隨機場進行上下文信息優化的精確分割,最終對復雜背景下紅外弱小目標的檢測效果也較理想。分析文獻[11-12]的實驗結果可得出,基于完全卷積神經網絡的紅外弱小目標檢測方法通常由特征學習與分類器訓練2個階段構成,雖然能實現較高的查準率與查全率,但訓練難度大且耗時長。
研究人員結合現有研究成果并加以組合,建立了單階段的目標檢測神經網絡模型YOLO[13],該模型在單幀目標檢測問題上的檢測速度快于Mask R-CNN[14]與Faster R-CNN[15]等兩階段的目標檢測網絡,而檢測性能好于SSD[16]與Detectnet[17]等單階段的目標檢測網絡,YOLO的最大優點是在檢測速度和檢測性能之間實現了較好的平衡。基于上述優點,研究了YOLO模型在紅外弱小目標檢測問題上的可行性。周薇娜等[18]提出了基于YOLOv3模型與YOLOv2模型的紅外弱小目標檢測方法,采用SELU激活函數替換原YOLO模型的激活函數,比原YOLO模型的檢測精度與檢測速度更高。Zhao等[19]提出了一種基于YOLOv3模型的紅外弱小目標檢測方法,采用Focal Loss(FL)函數替換原YOLO模型的損失函數來緩解弱小目標檢測的類不平衡問題,將YOLOv3的平均精度均值提高了4%。文獻[18-19]成功證明采用YOLOv3模型進行紅外弱小目標檢測的可行性,但也存在以下2點不足:① YOLOv3的計算成本高、檢測速度較慢;② 因紅外弱小目標的目標像素極少,YOLO模型提取特征圖的過程中忽略了弱小目標的部分視覺信息,導致紅外弱小目標的檢測性能受限。
YOLOv4模型是YOLOv3模型的改進版本,將YOLOv3模型平均檢測精度與檢測速度分別提高了10%和12%。YOLOv4-Tiny模型是YOLOv4網絡的輕量化版本,其網絡規模僅為YOLOv4模型的1/10。YOLOv4-Tiny包含21個卷積層與2個檢測層,因此其訓練速度更高且計算成本更低,可安裝于計算資源有限的移動無線設備。本文采用YOLOv4-Tiny模型作為紅外弱小目標檢測的骨干網絡,同時對YOLOv4-Tiny模型進行改進以提高對紅外弱小目標的檢測性能。對YOLOv4-Tiny模型的改進主要包括:① 在YOLOv4-Tiny模型的特征提取部分增加卷積層數與卷積核尺寸,以增加紅外圖像特征提取的信息量,避免忽略弱小目標的有用信息;② 將YOLOv4-Tiny模型的激活函數替換為SiLU激活函數,SiLU激活函數對細節的學習能力強于ReLU激活函數。改進后的模型記為IDSTD-YOLO,該模型能在保證檢測速度的同時,提高紅外弱小目標的檢測性能。
1 基于IDSTD-YOLO的紅外弱小目標檢測
1.1 IDSTD-YOLO目標檢測原理
IDSTD-YOLO是一種單階段的目標檢測模型,該模型檢測紅外弱小目標的原理如圖1所示。YOLO目標檢測模型主要包含以下2個步驟:① YOLO利用閾值法初步篩選目標邊框,如果邊框的估計概率C(p)低于該閾值,那么認為該網格中不可能存在目標邊框的中心;② 利用非極大值抑制算法處理所有的候選目標邊框,通過損失函數尋找最佳的目標邊框。
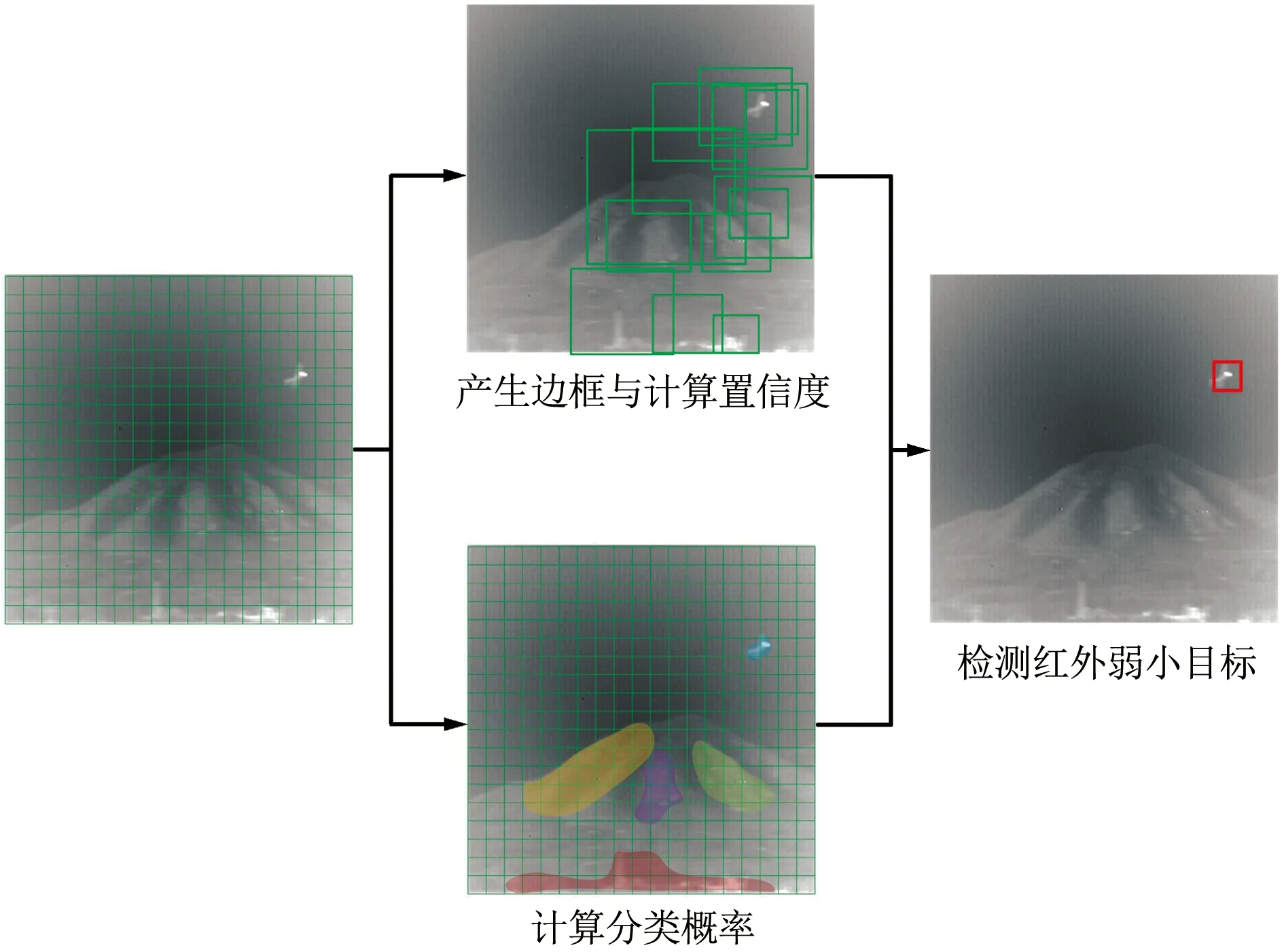
圖1 YOLO網絡的檢測流程Fig.1 Detection process of YOLO networks
IDSTD-YOLO的損失函數共包含3個部分:定位損失、置信度損失與分類損失。定位損失計算預測目標邊框與實際目標邊框之間的位置誤差;置信度損失計算預測邊框內包含目標的置信度。IDSTD-YOLO以最小化總損失為目標在訓練集上進行訓練,所訓練的模型能成功檢測紅外弱小目標。
基于YOLO模型的弱小目標檢測算法將輸入紅外圖像劃分成大小相等的網格,網格大小為S×S,如圖1所示。YOLO模型基于網格進行邊框估計與目標分類。首先,估計當前網格中包含目標邊框中心的概率,計算如下:
C(p)=P(p)×IoU(bp,b),
(1)
式中,P(p)表示紅外弱小目標是否在邊框中;IoU()表示預測邊框與目標邊框間的重疊度。
重疊度的計算方法如下:
(2)
式中,Bg為實際目標邊框;B為預測目標邊框。YOLO算法通過不斷地估計邊框來學習最合適的目標邊框,邊框估計的數學模型為:
(3)
式中,(x,y)為邊框中心坐標;(cx,cy)為邊框左頂點的坐標;pw與ph分別為邊框的長與高;bx,by,bw,bh定位了邊框的位置與大小。每個邊框估計的4個坐標為tx,ty,tw,th。
1.2 IDSTD-YOLO的網絡結構
1.2.1 YOLOv4-Tiny的網絡結構
YOLOv4-Tiny網絡是YOLOv4網絡的輕量化版本,共包含21個卷積層與2個YOLO檢測層,該網絡的目標檢測流程如圖2所示。

圖2 YOLOv4-Tiny網絡的目標檢測流程Fig.2 Target detection diagram of YOLOv4-Tiny networks
YOLOv4-Tiny網絡的詳細結構如圖3所示。

圖3 YOLOv4-Tiny網絡的詳細參數Fig.3 Detailed parameters of YOLOv4-Tiny networks
YOLOv4-Tiny網絡采用CSPDarkNet網絡[20]提取特征,使用2個YOLO檢測層產生大小為13×13×27與26×26×27的特征圖。采用C-IoU函數作為訓練的損失函數,采用貪婪非極大值抑制(Gready Non-maximum Suppression, GNMS)進行非極大值抑制。卷積層的激活函數為Leaky ReLU函數,YOLO檢測層的激活函數為線性函數。
1.2.2 IDSTD-YOLO的網絡結構
YOLOv4-Tiny模型在紅外弱小目標檢測任務上存在2點不足:① YOLOv4-Tiny特征提取器生成的特征圖大小為13×13×512,容易忽略紅外弱小目標的部分重要信息;② YOLOv4-Tiny的2個YOLO檢測層的特征圖尺寸分別為13×13×27與26×26×27,難以準確檢測紅外圖像中的弱小目標。為解決上述問題,本文為YOLOv4-Tiny模型提出2點針對性修改措施,如圖4所示。
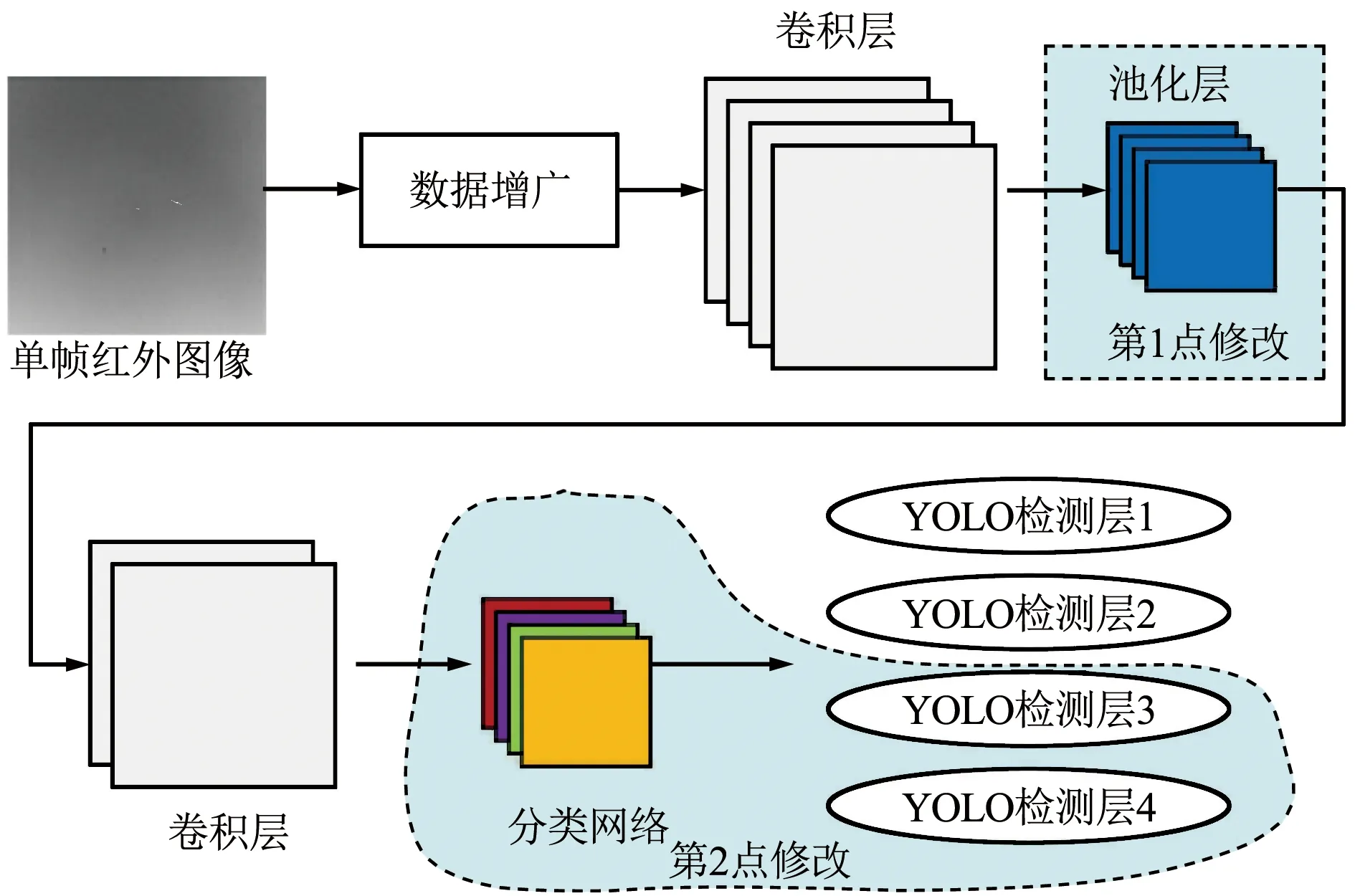
圖4 IDSTD-YOLO網絡的主要結構Fig.4 Main structure of IDSTD-YOLO networks
修改的相關細節如下:
① 在YOLOv4-Tiny模型的卷積層(3)與卷積層(4)之間增加一個密集網絡塊,密集網絡塊的詳細參數如圖5所示。該網絡塊包括4個最大池化層:3×3,5×5,7×7,9×9,作用是將第15個卷積層輸出的特征圖由13×13×512擴大為13×13×2 560,通過增加特征圖尺寸來提高紅外弱小目標的信息量。
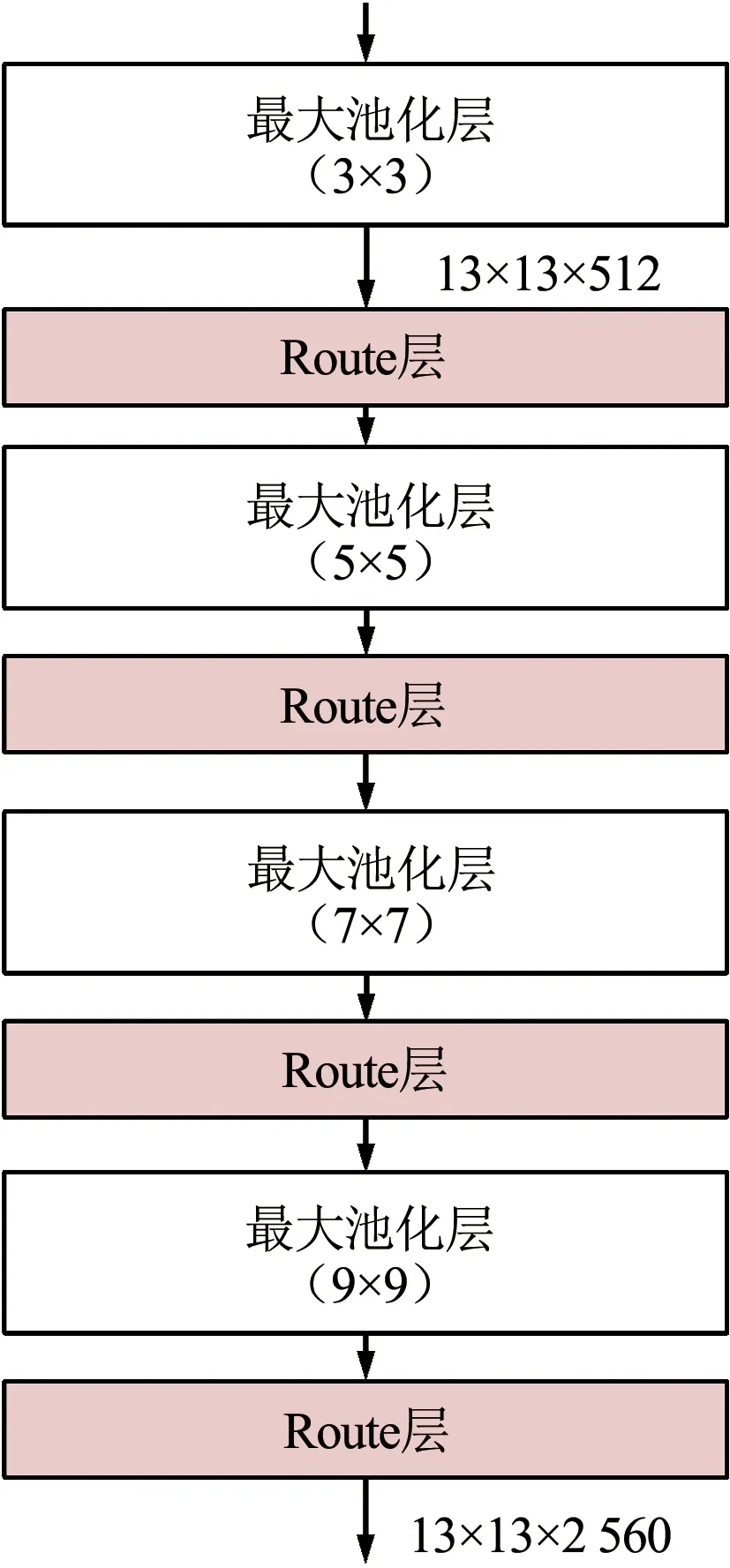
圖5 密集網絡塊的網絡結構Fig.5 Network structure of dense block
② 為YOLOv4-Tiny模型增加2個YOLO檢測層,以增強對紅外弱小目標的檢測能力,檢測層的詳細參數如圖6所示。增加的2個YOLO檢測層編號為第3檢測層與第4檢測層,YOLO檢測層(3)的卷積尺寸分別為512,128,256,512,27,YOLO檢測層(4)的卷積尺寸分別為27,64,128,256,27。第1~4個YOLO檢測層的特征圖尺寸分別為13×13×27,26×26×27,52×52×27,104×104×27。
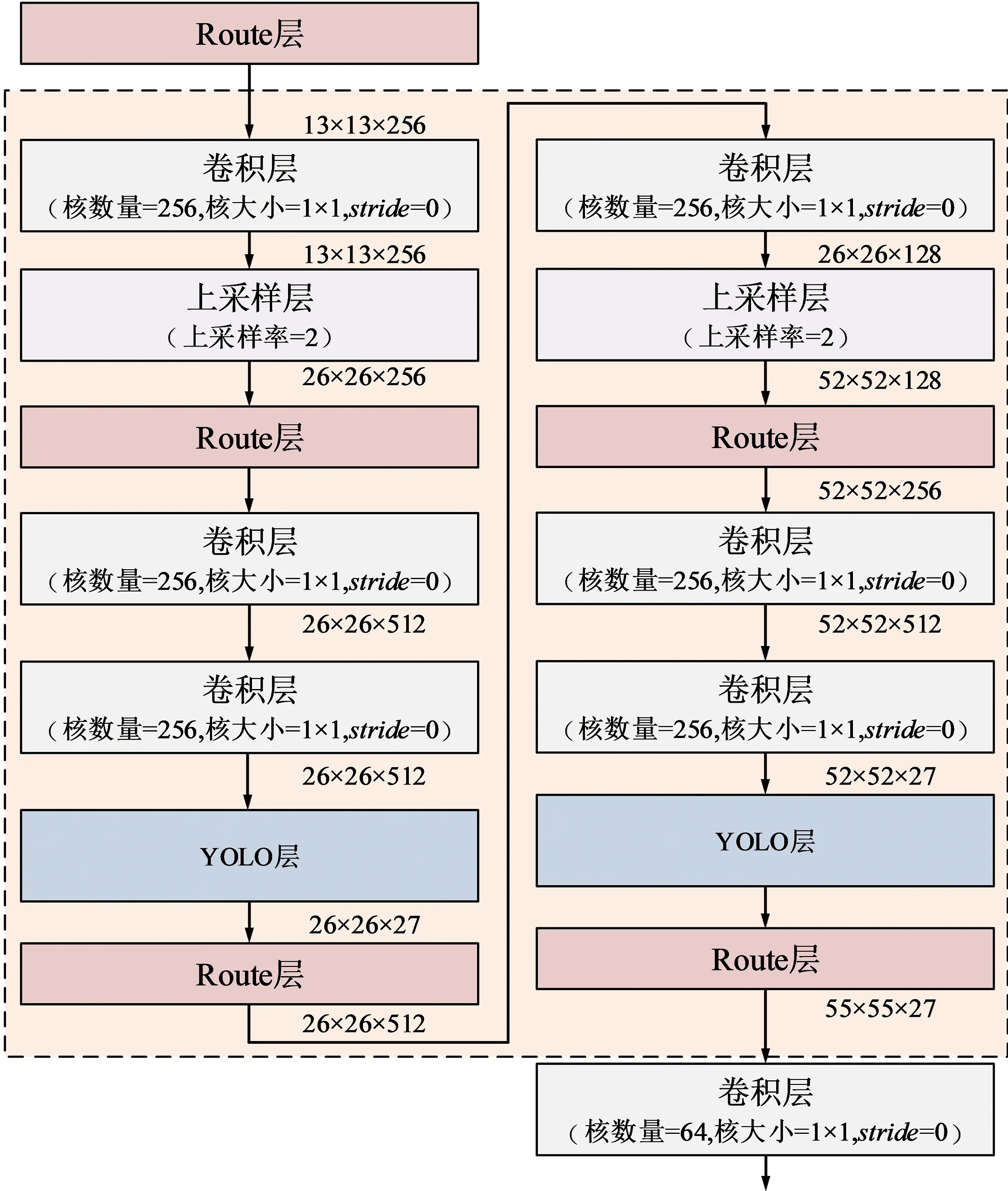
圖6 YOLO檢測層的網絡結構Fig.6 Network structure of YOLO detection layer
1.2.3 損失函數
本文ETL-YOLOv4網絡使用貪婪NMS進行非極大值抑制,將紅外弱小目標檢測視為一個邊框回歸問題。在目標檢測算法中,損失函數為目標位置、目標分類與目標置信度損失函數的總和,基于IoU的損失函數可定義為:
ΓIoU=1-IoU。
(4)
CIoU在IoU基礎上考慮了目標邊框與預測邊框之間的距離,CIoU損失在邊框回歸任務上的收斂速率更快且性能更好,因此本文采用CIoU損失。基于CIoU的損失函數可定義為:
(5)
式中,b為預測邊框B的中心點;bgt為目標邊框Bgt的中心點;p()為歐氏距離;c為2個邊框間的對角長度;v為長寬比的一致性;α為正的權衡因子。
v的計算如下:
(6)
α的計算如下:
(7)
1.2.4 激活函數
YOLOv4-Tiny模型默認的激活函數為Leaky ReLU激活函數,ReLU激活函數的檢測速度快、正則化能力強且防止過擬合效果好,但學習的特征圖信息量不足,對復雜模式的學習能力不足。為提高IDSTD-YOLO對紅外弱小目標的特征提取能力,將YOLOv4-Tiny模型的激活函數由Leaky ReLU替換為SiLU函數。
SiLU函數是一個基于強化學習的近似函數,定義如下:
σk(s)=zkσ(zk),
(8)
式中,s為輸入向量;zk為第k個隱藏層的輸入。
第k個隱藏層的輸入可描述為:
(9)
式中,bk為第k個神經層的偏置;wik為第k層第i個神經元的連接權重。
SiLU函數與ReLU函數曲線如圖7所示,SiLU函數能提取紅外圖像的細節視覺信息,可提高對紅外弱小目標的檢測能力。

圖7 SiLU函數與ReLU函數的曲線Fig.7 Curves of SiLU and ReLU function
2 實驗結果與討論
實驗計算機的硬件為Intel Core i7處理器,其主頻為2.5 GHz,內存容量為16 GB;顯卡為NVIDIA GeForce GTX 1660,顯存容量為6 GB;操作系統為Ubuntu16.04,神經網絡的訓練環境為TensorFlow框架。
2.1 紅外序列特點
為了觀察本文方法對不同場景的兼容性,選取4個不同場景的紅外圖像數據集,第1個序列來自于https:∥github.com/YimianDai/sirst,第2~4個序列來自于中國科學數據庫。紅外弱小目標檢測實驗的圖像樣本如圖8所示。紅外實驗序列的相關特點如表1所示。觀察圖中紅外弱小目標的樣本可看出,這些目標既昏暗又渺小,同時背景紋理復雜且成像質量低下。實驗中將每個序列幀按80%,10%,10%隨機分成訓練集、驗證集與測試集,采用labelImg工具對紅外序列1進行標注,紅外序列2~4采用數據集作者提供的標注數據。

(a)紅外序列1

(b)紅外序列2

(c)紅外序列3

(d)紅外序列4

表1 紅外實驗序列的相關特點Tab.1 Relative characters of infrared experimental sequences
2.2 性能評價標準
實驗將IoU重疊率大于50%視為命中目標,選取檢測精度(P)、召回率(R)及受試者工作特征(Receiver Operating Characteristic, ROC)曲線客觀評價紅外弱小目標檢測的性能。
P的計算如下:
(10)
式中,TP為真陽性樣本數量;FP為假陽性樣本數量。
R的計算如下:
(11)
式中,FN為假陰性樣本數量。
ROC曲線的橫坐標為召回率R,縱坐標為虛警率F。虛警率的計算如下:
(12)
式中,TN為真陰性樣本數量。ROC曲線下方的面積越大,目標檢測性能越好。
2.3 神經網絡訓練
IDSTD-YOLO訓練的實驗結果如圖9所示。

(a)IDSTD-YOLO訓練階段的目標檢測性能

(b)IDSTD-YOLO訓練階段的CIoU損失曲線圖9 IDSTD-YOLO訓練的實驗結果Fig.9 Experimental results of IDSTD-YOLO training
深度學習算法在TensorFlow框架與Keras深度學習庫上編程實現,非深度學習算法在Mablab 2019B上編程實現。IDSTD-YOLO的輸入圖像大小統一為256 pixel×256 pixel,batch大小為16,訓練動量為0.9,衰減率為0.5,學習率為0.031。神經網絡訓練過程中最大epoch次數為500,YOLO的IoU閾值設為50%,分類的置信度閾值為0.48。
IDSTD-YOLO訓練的平均精度與平均召回率曲線如圖9(a)所示,觀察圖中曲線可知,檢測精度與召回率大約經過300次epoch達到收斂。IDSTD-YOLO訓練的CIoU損失曲線如圖9(b)所示,觀察圖中曲線可知,YOLO的損失函數大約經過300次epoch達到收斂,與圖9(a)的結論一致。
2.4 對比實驗與結果分析
本文提出的IDSTD-YOLO模型對YOLOv4-Tiny的骨干網絡進行了修改,以期提高紅外弱小目標的檢測能力。在此將IDSTD-YOLO模型與YOLOv4-Tiny模型在4個紅外序列上的檢測效果進行比較,評估本文工作的有效性。YOLOv4-Tiny模型與IDSTD-YOLO模型的訓練環境與參數配置相同,如2.3節所示。
為了進一步驗證本文方法的優劣,實驗選擇了5個同類型算法作為對比方法,包括引言部分討論的SELU_YOLOv3[18],FL_YOLOv3[19]以及3DModel[21],AttLCNet[22],MultiScaleNet[23],上述對比方法的參數值選取原作者的推薦值。3DModel是一種基于三維信息抽取模型的紅外弱小目標檢測方法,該方法引入粒子群優化算法搜索三維信息抽取模型的最佳參數值,以提高對紅外弱小目標的特征學習能力。AttLCNet與MultiScaleNet是2種基于深度神經網絡的紅外弱小目標檢測方法,分別通過注意力機制與多尺度特征提取機制增強對紅外弱小目標的細節捕捉能力與判別能力。
2.4.1 視覺效果實驗
圖10(a)~(g)分別為YOLOv4-Tiny,SELU_YOLOv3,FL_YOLOv3,3DModel,AttLCNet,MultiScaleNet以及IDSTD-YOLO模型在序列1上的檢測視覺樣本,IoU重疊率分別為78%,66%,72%,75%,88%,79%,86%。該紅外圖像中背景簡單且紅外弱小目標較突出,通過視覺可直觀發現紅外弱小目標。各檢測算法均成功發現紅外弱小目標,且達到了較高IoU重疊率。

圖10 序列1的紅外弱小目標檢測視覺效果Fig.10 Visual effect of infrared dim and small target detection of sequence 1
圖11(a)~(g)分別為YOLOv4-Tiny,SELU_YOLOv3,FL_YOLOv3,3DModel,AttLCNet,MultiScaleNet以及IDSTD-YOLO模型在序列4上的檢測樣本。YOLOv4-Tiny,SELU_YOLOv3,FL_YOLOv3以及IDSTD-YOLO成功檢測出紅外弱小目標,IoU重疊率分別為53%,62%,68%,70%。該紅外圖像中背景復雜,大量樹木與復雜地面環境對紅外弱小目標造成了極大的干擾,導致3DModel發生虛警,而AttLCNet與MultiScaleNet發生漏檢。
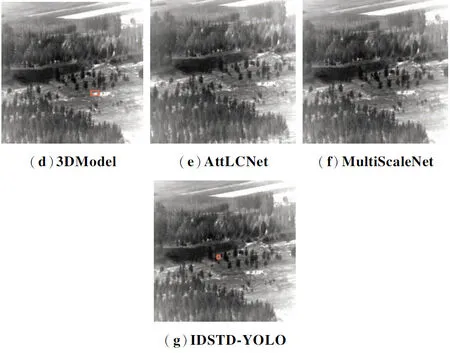
圖11 序列4的紅外弱小目標檢測視覺效果Fig.11 Visual effect of infrared dim and small target detection of sequence 4
總體而言,紅外序列中高亮度邊緣與雜波對于紅外弱小目標檢測產生嚴重干擾,導致一些目標檢測算法發生虛警與漏檢。本文通過對YOLOv4-Tiny模型的特征提取部分進行修改,增加卷積層數與卷積核尺寸來增加紅外圖像特征提取的信息量,避免忽略弱小目標的有用信息。通過上述視覺實驗結果可證明本文方法的有效性。
2.4.2 量化實驗分析
為定量評估紅外弱小目標檢測的性能,總結了各檢測算法在4個測試序列上的平均精度與召回率結果,如表2所示。將表中YOLOv4-Tiny模型與IDSTD-YOLO模型的檢測精度與召回率結果進行對比,本文對YOLOv4-Tiny模型的特征提取部分進行修改,通過增加卷積層數與卷積核尺寸來增加紅外圖像特征提取的信息量,IDSTD-YOLO模型在4個紅外序列上的檢測精度與召回率均明顯高于YOLOv4-Tiny模型。
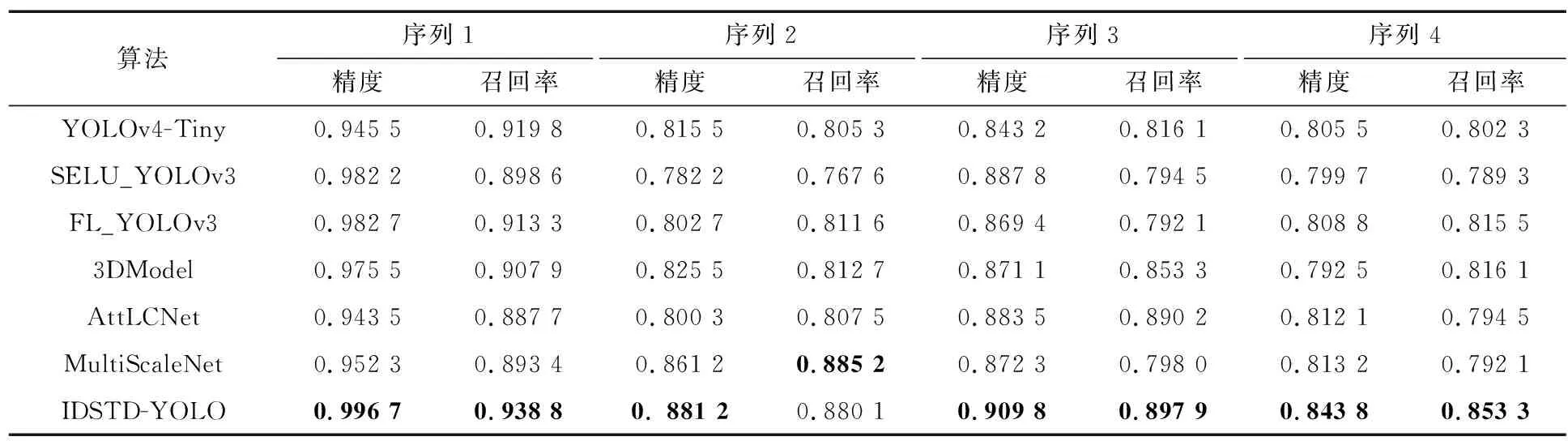
表2 紅外弱小目標檢測的量化評價結果Tab.2 Quantitative evaluation results of infrared dim and small target detection
因序列1的背景較簡單,目標面積較大,因此SELU_YOLOv3,FL_YOLOv3,3DModel,AttLCNet與MultiScaleNet等檢測算法均取得了較高的檢測精度與召回率。序列2~4的背景復雜,目標面積較小,SELU_YOLOv3,FL_YOLOv3,3DModel,AttLCNet與MultiScaleNet等檢測算法的檢測精度與召回率均有所下降。總體而言,本文IDSTD-YOLO模型在4個紅外序列上的目標檢測能力優于其他6個對比方法。
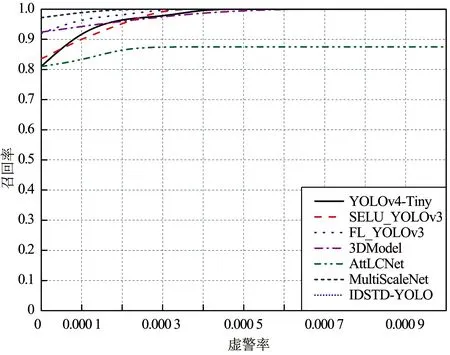
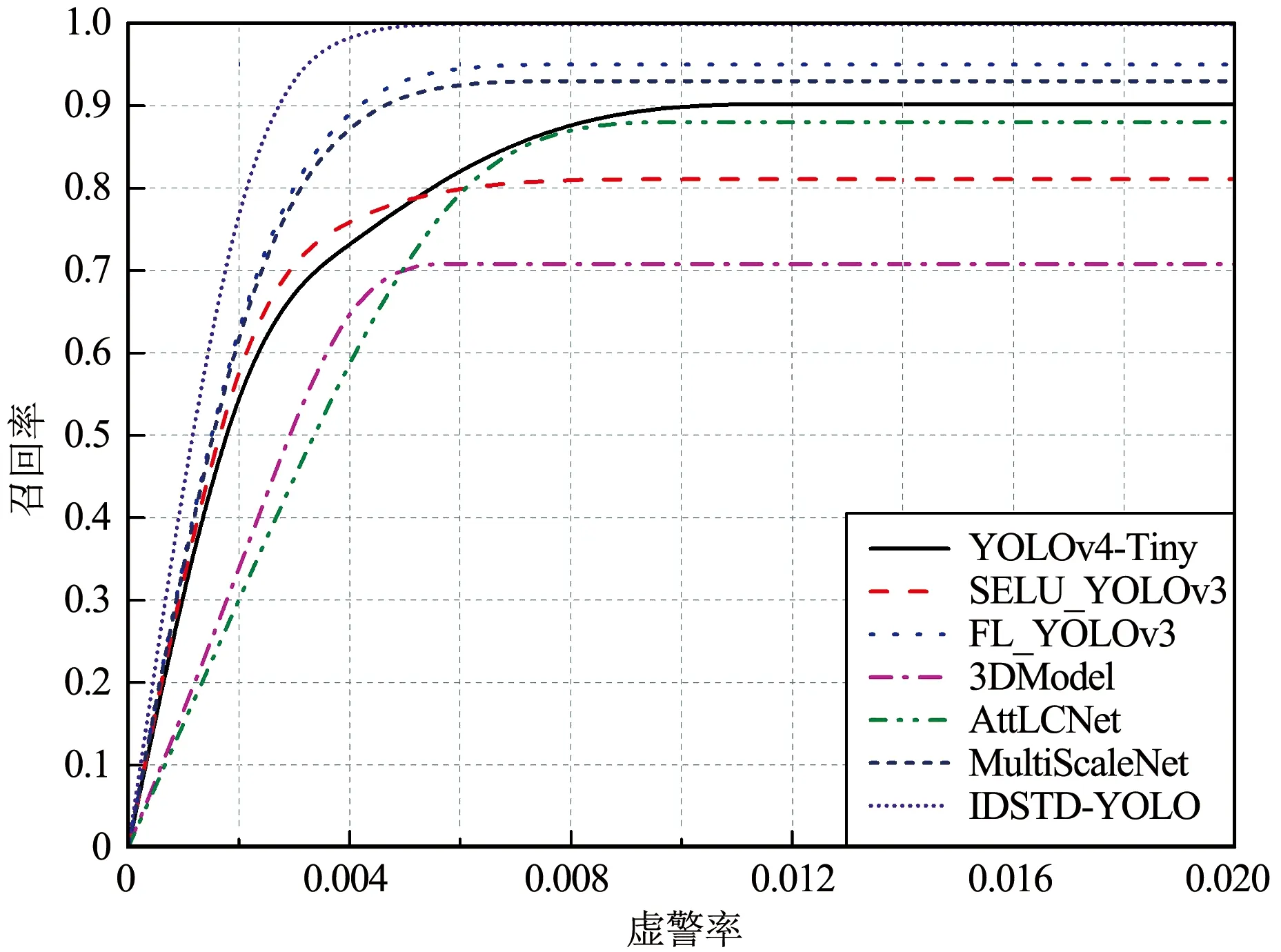
各檢測算法在4個紅外序列上的ROC曲線如圖12所示。
(a)紅外序列1
(b)紅外序列2
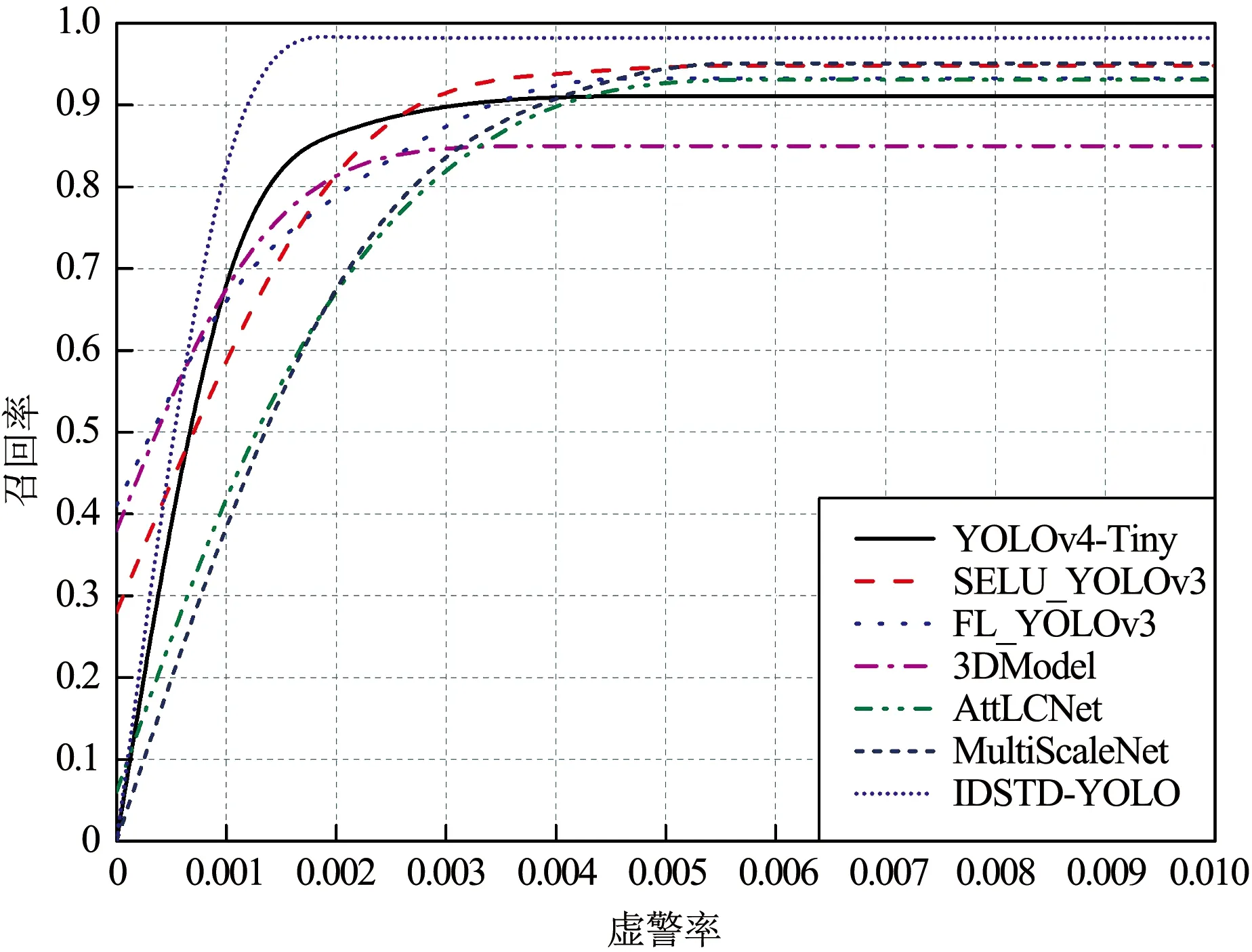
(c)紅外序列3
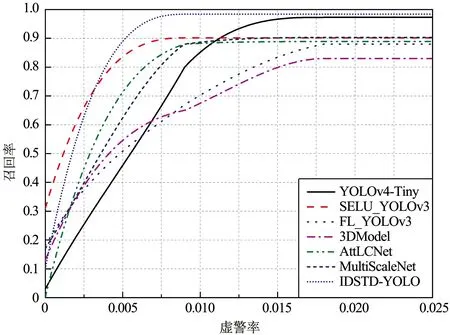
(d)紅外序列4圖12 紅外弱小目標檢測的ROC曲線Fig.12 ROC curves of infrared dim and small target detection
圖12(a)顯示各檢測算法在紅外序列1的ROC曲線均較好,說明檢測性能較高。觀察圖12(c)~(d)可知,3DModel的AUC值較小,但依然大于0.5。因為深度學習技術是屬于數據驅動型技術,在訓練數據充足的情況下具有較好的魯棒性,因此SELU_YOLOv3,FL_YOLOv3,AttLCNet與MultiScaleNet四個基于神經網絡的檢測算法達到了較穩定的性能。總體而言,本文IDSTD-YOLO模型在4個紅外序列上的AUC值優于其他6個對比方法,該結論與檢測精度、召回率的結果一致。
3 結論
本文提出一種單階段的目標檢測模型IDSTD-YOLO,該模型對YOLOv4-Tiny模型的特征提取部分進行修改,通過增加卷積層數與卷積核尺寸來增加紅外圖像特征提取的信息量,避免忽略弱小目標的有用信息。此外,將YOLOv4-Tiny模型的激活函數替換為SiLU激活函數,以提高對弱小目標的細節學習能力。對比實驗結果表明,該檢測模型的目標檢測精度、召回率與視覺效果均取得了較好的結果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
