一種單樣本農作物病害識別方法
2023-03-07 01:46:44任維鑫曹新亮白宗文
無線電工程 2023年2期
任維鑫,曹新亮,白宗文
(延安大學 物理與電子信息學院,陜西 延安 716000)
0 引言
農作物發生病害會嚴重破壞其正常生理機能,極大減少產量,因此,農作物病害的識別、檢測和預警是保證農作物產量穩定、保障農民收益的重要手段。傳統的農作物病害識別主要依靠農業專家實地考察,隨著人工智能尤其是深度學習的快速發展,農作物病蟲害識別的相關研究也逐步進入新階段。目前,已經有許多研究成功地將深度卷積神經網絡應用到農作物病蟲害識別領域[1-6],并在其數據集上取得了相對理想的準確率。雖然已經有許多研究者著手構建農作物病害數據集,但是現有數據集依然很難滿足基于傳統深度學習的病害識別方法對數據量的需求,無法保證模型的通用性和泛化性。究其原因,一方面農作物病害數據集與自然場景數據集不同,自然場景下的通用數據集可以借助網絡等設備快速地收集與標注,但是農作物病害數據集由于其標注時需要許多專業知識,往往需要農業專家才能完成標注,這無疑會導致較高的人力物力成本;另一方面,農作物病害呈現種類多、單類樣本偶發,甚至有些病害發病與地域呈現強關聯性的特點,這導致構建一個巨大的、具有百億規模的、種類豐富完備的農作物病害數據集是十分困難的。因此,從小樣本檢測的視角出發研究解決農作物病害識別問題的方法具有非常重要的實際應用意義。雖然已經有研究者在這方面取得了一些進展[7],但主要是基于微調的方法,這種方法在極少樣本的情況下性能有所下降,且推理時需要通過微調更新模型參數。本文主要針對這一問題,開發了一種基于孿生網絡的度量學習方法,以解決單樣本農作物病害識別問題,該方法具有推理時需要特定病害樣本量小、不用更新模型參數的優點。
1 少樣本學習與對比學習
人類可以從很少的樣本中學習,但機器從少樣本中學習的能力與人的差距依然非常大,深度學習框架對于數據與算力有著海量的需求,在少樣本任務上,最先進的深度學習方法甚至不如簡單的機器學習模型。研究著重關注少樣本學習中的少樣本分類問題,對于少樣本分類,有以VBF[8]為代表的基于生成模型的方法,尋求借助中間變量z對后驗概率p(x|y)進行建模;有基于判別的方法,直接為少樣本分類任務T建模后驗概率p(x|y);最直接的方法就是使用任務T的數據訓練神經網絡模型。但是由于T的數據太少,這種方法一般容易陷入過擬合。第2種是基于度量學習[9],通過在輔助數據集DA上學習一個相似性度量S(·,·),從而遷移到任務T上。第3種是基于元學習的方法[10-11],它利用DA構造許多類似于任務T的任務,并采用跨任務訓練策略提取一些可轉移的模型、算法或參數。其中,Snell等[10]的方法可以看做是度量學習與元學習的結合,同時它也可以被理解為對比學習,其核心思想就是吸引正的樣本對,排斥負的樣本對,該方法是采樣同類樣本作為正樣本對,不同類的作為負樣本對。而另一種是基于自監督的對比學習方法[12-15],這種方法通過將每幅圖像看作不同的類別,一副圖像的多張數據增強圖像為同一類,與其他圖像以及其他圖像的數據增強圖像為不同類,從而構造類別標簽以監督模型訓練。Tian 等[16]揭示了在少樣本學習任務中一個好的嵌入是非常重要的,并基于此構建了不基于元學習框架且不用微調的少樣本分類基線。 Chowdhury等[17]使用一組預訓練的嵌入模型作為特征提取器庫,使用微調的方法達到了很好的跨域遷移少樣本分類效果。Wang等[18]發現了使用交叉熵損失的監督學習模型,其遷移性能不如自監督學習模型的原因是交叉熵損失監督的模型在特征提取之后沒有使用MLP進行特征映射,基于此觀察,構建了遷移性能更好的監督學習模型,并在少樣本分類任務上進行驗證。
2 方法
2.1 任務設置

2.2 算法
2.2.1 模型與損失函數
本文所提出的框架結構如圖1所示。將來自圖像x的2個隨機數據增強的視圖xa,和xb作為孿生網絡的輸入。這2個視圖由主干網絡(使用卷積神經網絡)和MLP實現的投影器組成的編碼器網絡f處理。編碼器f在2個視圖之間共享參數。MLP實現的預測器h將一個視圖的輸出變換到另一個視圖域。分類頭c作為訓練輔助器的角色存在,具體地,在訓練過程中,經過編碼器f處理之后的2個視圖的特征還會送入分類頭以獲得類別向量,推理時分類頭將被舍棄。訓練與推理的實現細節將在2.2.2節予以說明。

圖1 模型架構Fig.1 Model architecture
對于相似性匹配,使用余弦相似度作為度量。具體地,將2個輸入向量表示為p1=h(f(xa))和z2=f(xb),p2,z1同理。使用自監督的對比學習和基于構造監督標簽與二值交叉熵的距離損失2部分進行優化。
在對比學習部分,最小化其負余弦相似度加常數項:
(1)
式中,‖·‖為l2歸一化,該式值域為[0,2]。與BYOL[14]和SimSiam[15]一致,構造對稱損失:
(2)
在batch維度上對每一對樣本使用該公式并在batch維度上取平均值作為總損失。
和SimSiam一致,對比學習中對孿生網絡的其中一支使用停止梯度操作,則將式(1)修改為:
D(p1,stopgrad(z2)),
(3)
式中,stopgrad()表示停止梯度操作,這意味著z2在這一項中被當作常數。類似地,式(2)被修改為:
(4)
從表達式看,L1損失只拉近正樣本之間的距離,未能拉遠正樣本與負樣本之間的距離,對比學習的經典方法MoCo[12]和SimCLR[13]的對比損失都有拉遠正樣本與負樣本之間距離的能力,但MoCo引入了動量編碼器組件,SimCLR需要大批量才能正常工作,對顯存有極高的要求。為了使損失具有拉遠正負樣本之間距離的能力且不引入其他限制,本文設計了基于構造監督標簽與二值交叉熵的距離損失。
為了與對比學習損失更好地兼容,基于構造監督標簽與二值交叉熵的距離損失依然沿用余弦相似度作為距離度量,考慮映射函數σ,使得σ(D(·,·))的值域空間落入[0,1],簡便起見,取σ為常系數0.5。
此外,設計出shuffle和equal兩個組件,具體為:
z3,z4,y′=shuffle(z1,z2,y)。
(5)
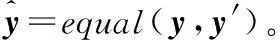
(6)
綜上,基于構造監督標簽與二值交叉熵的距離損失被表示為:
a=σ(D(p1,stopgrad(z4))),
(7)
(8)
b=σ(D(p2,stopgrad(z3))),
(9)
(10)
(11)
Tian 等[16]證明了使用交叉熵損失對模型進行監督學習可以學到不錯的特征提取能力,因此本文設計了分類頭c(圖1中的虛線部分)進行輔助學習,對于分類頭的設計,遵循Wang等[18]的設置,使用2層MLP做特征映射,使用一層MLP做輸出,這區別于He等[19]傳統卷積模型在卷積之后只使用一層MLP作為輸出層的設置。其分類損失函數表達式為:
(12)
式中,CrossEntropy( )表示交叉熵損失。訓練模型時使用的損失函數表示為:
L=λ1L1+λ2L2+λ3L3,
(13)
式中,λi為損失加權系數。
2.2.2 訓練與推理方法:
訓練過程遵循常規的有監督深度學習模型訓練范式:每個epoch以批量的形式(默認批量大小為512)從DA中不放回地采樣數據,經過數據增強后送入圖1所示的模型,以式(13)作為損失函數,使用動量隨機梯度下降法(Stochastic Grdient Descent with Momentum,SGDM)優化模型參數,迭代多個epoch(默認為100)。使用的數據增強方式包括:隨機裁剪;隨機改變圖像亮度、對比度、飽和度、色調;隨機高斯濾波;隨機水平反轉;隨機轉為灰度圖。本文默認使用ResNet18[19]作為主干網絡(Backbone)。訓練完成之后保存模型結構和參數,作為預訓練模型。
推理流程為:加載預訓練模型,刪掉分類頭,剩余部分作為相似性度量器S(·,·), 此時,該孿生網絡的輸入為一對圖像,輸出為這一對圖像之間的余弦相似度,范圍為[-1,1],相似度越接近1,表明2個圖像之間越相似。將Dtrn作為支持圖像集Su,將Dtst中的圖像作為查詢圖像q,于是,任意Dtst中的圖像的類別為:
(14)
即:將支持圖像集中與查詢圖像q相似度最高的圖像s對應的類別分配給q。
3 實驗
3.1 數據集
本文使用AI Challenger 2018病蟲害分類數據集[20]作為DA,它是由上海新客科技為競賽提供的農作物葉子圖像數據集:標注圖片5萬張,包含10種植物(蘋果、櫻桃、葡萄、柑桔、桃、草莓、番茄、辣椒、玉米和馬鈴薯)的27種病害,合計61個分類(按“物種-病害-程度”分)。其中與蘋果有關的類別有:蘋果健康、蘋果黑星病一般、蘋果黑星病嚴重、蘋果灰斑病、蘋果雪松銹病一般以及蘋果雪松銹病嚴重。
本文從周敏敏[21]創建的蘋果葉片數據集中采樣DT。該蘋果葉片病理數據集數據集由西北農林科技大學制作,分別在西北農林科技大學白水蘋果試驗站、洛川蘋果試驗站和慶城蘋果試驗站進行采集。數據集主要在晴天光線良好的條件下獲取,部分圖像在陰雨天進行采集,不同的采集條件進一步增強了數據集的多樣性。數據集包括斑點落葉病、褐斑病、花葉病、灰斑病以及銹病等5種常見的蘋果葉面病理圖像數據,數量分別為:斑點落葉病5 343張,褐斑病5 655 張, 灰斑病 4 810 張,花葉病 4 875 張, 銹病 5 694 張。采樣方法為:每類隨機采樣1張作為Dtrn,剩余圖像中選取與Dtrn的拍攝場景一致的11 727張圖像作為Dtst,共同構成DT。其樣例如圖2所示。

圖2 蘋果病害樣例Fig.2 Sample images of apple diseases
3.2 試驗
本文使用模型在下游特定任務T的測試集Dtst上的準確率作為衡量方法性能的指標。
構建比較基線:在DA上使用交叉熵損失監督與本方法相同的主干網絡進行訓練獲得預訓練模型。
不微調的基線(基線1):加載預訓練模型后刪掉分類頭,將其作為圖像到向量的編碼器,得到編碼向量后,使用歐幾里得距離作為距離度量,其分類方式為:
(15)
式中,‖·,·‖表示2個向量之間的歐幾里得距離,值域為[0,+∞],越接近0表示2個向量越相似。
微調的基線(基線2):加載預訓練模型后修改分類頭使之適應任務T,在Dtrn上使用微調的方法更新7個批次,批量大小為5,將此分類模型作為微調法[7]的比較基線。
與之類似,本文算法在Dtrn上使用微調的方法更新7個批次(批量大小為5)之后再執行推理,作為本文算法使用微調法獲得的結果。
本文所提算法的結果及消融試驗如表1所示。

表1 算法結果及消融試驗Tab.1 Algorithm results and ablation test 單位:%
在以上試驗中,對于式(7)中的加權系數,均使用1。

4 結束語
本文提出了一種基于孿生網絡的度量模型,并使用對比學習損失,基于構造監督標簽與二值交叉熵的距離損失,交叉熵損失聯合訓練,經過測試檢驗,在單樣本農作物病害識別任務上取得了很好的性能,具有對特定任務的數據需求量少、不用在特定任務上重新訓練的優點,具有實際應用的潛力。但本文方法依然無法識別出與任務T相關但未在Dtrn中出現的類別,下一步將致力于研究開放世界的少樣本農作物病害識別問題。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
