基于漸進生長Transformer Unet的遙感圖像建筑物分割
2023-03-07 01:26:06張青月
無線電工程 2023年2期
關鍵詞:模型
葉 寬,楊 博,謝 歡,朱 戎,趙 蕾,張青月,趙 杰
(1.國網北京市電力公司電力科學研究院,北京 100075;2.國網新源控股有限公司檢修分公司,北京 100067;3.北京大學 大數據分析與應用技術國家工程實驗室,北京 100871)
0 引言
高分辨率遙感圖像具有目標大小不一、紋理復雜多樣和樹木遮擋等不穩定因素,使得基于深度學習的目標分割任務具有較大挑戰,精確的遙感目標分割對于軍事、航天和城市規劃都有重要的意義。近年來,隨著深度卷積神經網絡的不斷發展,基于深度學習的目標檢測和物體分割應用越來越廣泛,如VGG[1]、基于殘差連接的ResNet[2]、改進了編碼解碼結構的SegNet[3]、帶有跳躍連接的編碼-解碼結構Unet[4]、帶有空間搜索的NAS-Unet[5]、具有嵌套和密集鏈接的UNet++[6]、具有深度監督的UNet 3+[7]以及帶有3D混合殘余注意力的RA-UNet[8]等,這些研究使得深度學習技術對圖像目標分割任務的結果不斷提升。
許多專家利用深度學習方法對遙感圖像的各種目標進行分割研究,不斷提升分割效果。韓彬彬等[9]將基于殘差密集空間金字塔的卷積神經網絡應用于城市地區遙感圖像分割任務,利用了遙感圖像不同尺度下的特征。范自柱等[10]通過在Unet網絡中添加特征金字塔結構,使用基于卷積神經網絡的圖像分割方法提取遙感圖像中典型土地光譜信息和空間信息來識別遙感衛星圖像。袁偉等[11]將不同尺度的Unet融合在一起提出一種多尺度自適應的遙感語義分割模型。劉航等[12]引入自適應感受野機制和通道注意力模塊可以減少背景特征的干擾,提升遙感圖像的分割精度。余帥等[13]提出一種基于多級通道注意力的遙感圖像分割模型,有效解決目標遮擋和小目標難分割問題。何青等[14]利用多層次編碼解碼結構提取不同尺度特征,提出一種基于殘差分組卷積的高分辨率遙感影像建筑物分割模型。
為進一步提高建筑物邊緣提取效果,有效解決不同大小目標和被遮擋目標分割錯誤等問題,本文提出了一種基于漸進生長機制的Transformer Unet(PGT-Unet)遙感圖像分割網絡,整個流程包括4個訓練階段。首先對輸入圖像進行下采樣處理,之后從(64 pixel×64 pixel)到(512 pixel×512 pixel)逐漸增大輸入圖像的分辨率,網絡模型也從1層Transformer Unet逐漸增大至4層Transformer Unet,每個階段模型收斂之后的參數直接遷移到下一階段的同樣卷積層中,使得模型在訓練初期能夠學習到大尺度的結構信息,后期的學習越來越集中到精確的細節特征,可以改善建筑物邊緣提取效果,提升被遮擋目標和不同大小目標的分割效果。
本文工作的貢獻總結如下:
① 提出了一個基于PGT-Unet的遙感圖像分割網絡來促進遙感圖像的語義分割精度,并獲得了顯著的性能;
② 使用一種漸進生長的機制進行網絡訓練,使得神經網絡可以由粗到細逐步學習不同尺度的目標結構信息;
③ 在模型的編碼器、解碼器和瓶頸模塊中引入了Transformer Block進行多尺度的特征提取和特征融合,進一步增強模型提取不同大小目標特征的能力,使網絡能夠更好地區分特征之間的重要程度,從而聚焦有用特征。
1 基本原理
1.1 漸進式增長機制
傳統的卷積核和可變形的卷積核都是同時提取所有尺度的目標信息,容易造成信息冗余,并且對于網絡結構較深的模型,勢必會造成很大的計算量和存儲的浪費。在傳統神經網絡模型的基礎上引入漸進式生長機制[15]的訓練方式可以達到不同尺度多級特征提取的目的。Transformer Block結構如圖1所示。

圖1 Transformer Block結構Fig.1 Illustration of Transformer Block
通過設置4個訓練階段,在第1個階段低分辨率(64 pixel×64 pixel)輸入圖像經過一層編碼模塊、瓶頸模塊和解碼模塊得到建筑物粗分割結果;在第2個階段增大輸入圖像的分辨率至(128 pixel×128 pixel),給模型增加一層編碼模塊和一層解碼模塊,將上一階段訓練所得參數直接遷移到新模型中的對應層中,并給已經訓練好的模型參數設置較小的學習速率,給新加的卷積層參數設置較大的學習速率,可以得到較大分辨率的建筑物精細分割結果;第3階段和第4階段以此類推,漸進式增大圖像的分辨率(256 pixel×256 pixel)與(512 pixel×512 pixel)和模型的深度,最終得到越來越精細的建筑物分割輪廓。
這種訓練方式允許網絡先學習大尺度的圖像粗結構信息,之后的階段將注意力集中到相鄰尺度的越來越細節的特征中,而不是讓網絡同時學習所有尺度的信息。在每個階段模型接收不同大小的輸入圖像,從而可以分步地學習到不同大小目標區域的多尺度信息,在不增加額外參數量和計算量的情況下,使得模型更快收斂,具有更強的泛化能力和穩定性。
1.2 Transformer Unet模型
漸進生長機制下的每個階段采用基于Transformer的U型架構——Transformer Unet模型進行遙感圖像特征提取和建筑物分割,模型由編碼器模塊、瓶頸模塊、解碼器模塊和跳過鏈接構成,基本單元是Transformer Block結構。編碼器模塊由一系列成組的下采樣模塊(步長為2的卷積層)和卷積模塊Transformer Block構成,進行特征提取學習全局上下文信息和局部細節信息。瓶頸模塊由2組卷積模塊Transformer Block構成,降低模型參數量,增加模型的非線性表達能力。解碼器模塊由一系列成組的卷積模塊Transformer Block和上采樣模塊(雙線性插值)構成,進行圖像重建和建筑物目標分割。跳過鏈接聯通編碼器和解碼器,提取的上下文特征通過跳躍鏈接與編碼器的多尺度特征融合,以彌補降采樣造成的空間信息丟失。
Transformer Block主要由帶殘差連接和歸一化層的多頭注意力模塊以及多層感知機組成,多頭注意力模塊是Transformer Block重要的組成部分,由多個自注意力連接組成,自注意力表示為:
(1)
式中,Q,K和V分別表示Query,Key和Value;dhead為通道維數,具有相同的維度(HW×C)。采用2個多層感知器和1個3×3的深度可分離卷積層來獲得Transformer的Positional Encoding位置信息,表示如下:
Fout=MLP(GELU(Conv2D3×3(MLP(Fin))))+Fin,
(2)
式中,Fin是自注意力的特征圖;GELU代表Gaussian Error Linear Unit激活函數。
1.3 模型整體架構
針對遙感圖像建筑物分割任務,提出了一種基于PGT-Unet的卷積神經網絡模型,如圖2所示,漸進式的逐步增大模型的深度和輸入圖像的尺度,模型的輸入為遙感圖像,輸出為建筑物分割結果圖像。

圖2 網絡架構Fig.2 Illustration of network architecture
網絡模型的第1階段網絡由一個下采樣的編碼模塊和一個上采樣的解碼模塊構成,編碼模塊和解碼模塊之間通過瓶頸模塊連接,之后的第2階段、第3階段和第4階段分別漸進式增加編碼模塊和解碼模塊的深度,使上采樣和下采樣的個數增加為2,3,4,輸入圖像的分辨率也從低分辨率(64 pixel×64 pixel)開始,逐漸增大至第2階段(128 pixel×128 pixel)、第3階段(256 pixel×256 pixel)和第4階段(512 pixel×512 pixel),最終第4階段的Transformer Unet卷積神經網絡結構如圖3所示。每個階段模型收斂之后的參數直接遷移到下一階段的同樣卷積層中。在訓練過程的初始階段,模型首先獲得大尺度的結構信息和圖像分布,然后在訓練后期轉移注意力到越來越精確的細節特征,相比之下,傳統卷積神經網絡是同時提取所有尺度的信息。訓練過程中,為了避免每一次模型的變更對上個模型泛化能力的影響,對已訓練好的、待遷移參數的低分辨率卷積層設置一個較小的學習速率(1×e-6),對新加入的卷積層則設置了一個較大的學習速率(1×e-4),之后開始新一輪的訓練。
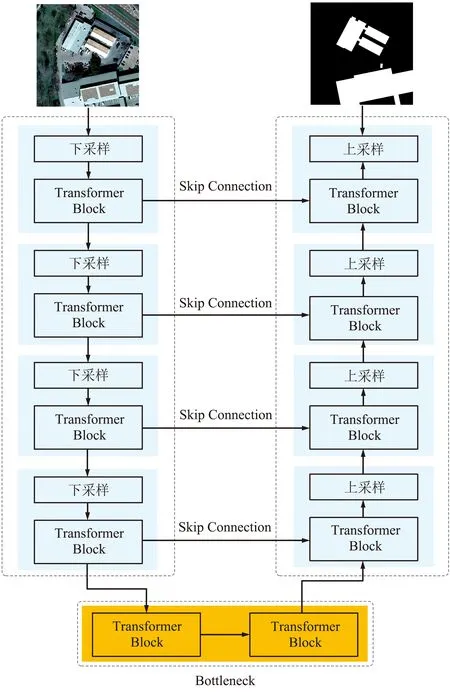
圖3 最后階段的Transformer Unet模型Fig.3 The last stage of Transformer Unet model
2 實驗與結果
2.1 數據預處理
本文方法在Inria Aerial Image Labeling數據集上進行實驗,該數據集是高分辨率遙感建筑物分割圖像數據集,覆蓋面積達810 km2,圖像覆蓋Austin,Chicago,Kitsap,Tyrol-w和Vienna等5個不同城市的建筑物,圖像分辨率大小為5 000 pixel×5 000 pixel,每個城市有36張圖像,該數據集共有180張圖像。考慮到原始圖像尺寸太大,將所有圖像裁剪為512 pixel×512 pixel,最終得到14 400張訓練樣本和3 600張測試樣本。由于原始圖像存在細節模糊和顏色失真問題,對所有數據進行基于雙邊濾波和對數域MSR增強的去霧處理。圖4(a)為原始分辨率為5 000 pixel×5 000 pixel的遙感圖像和建筑物標注圖像,圖4(b)為裁剪之后一些小塊的遙感圖像用于訓練和測試。
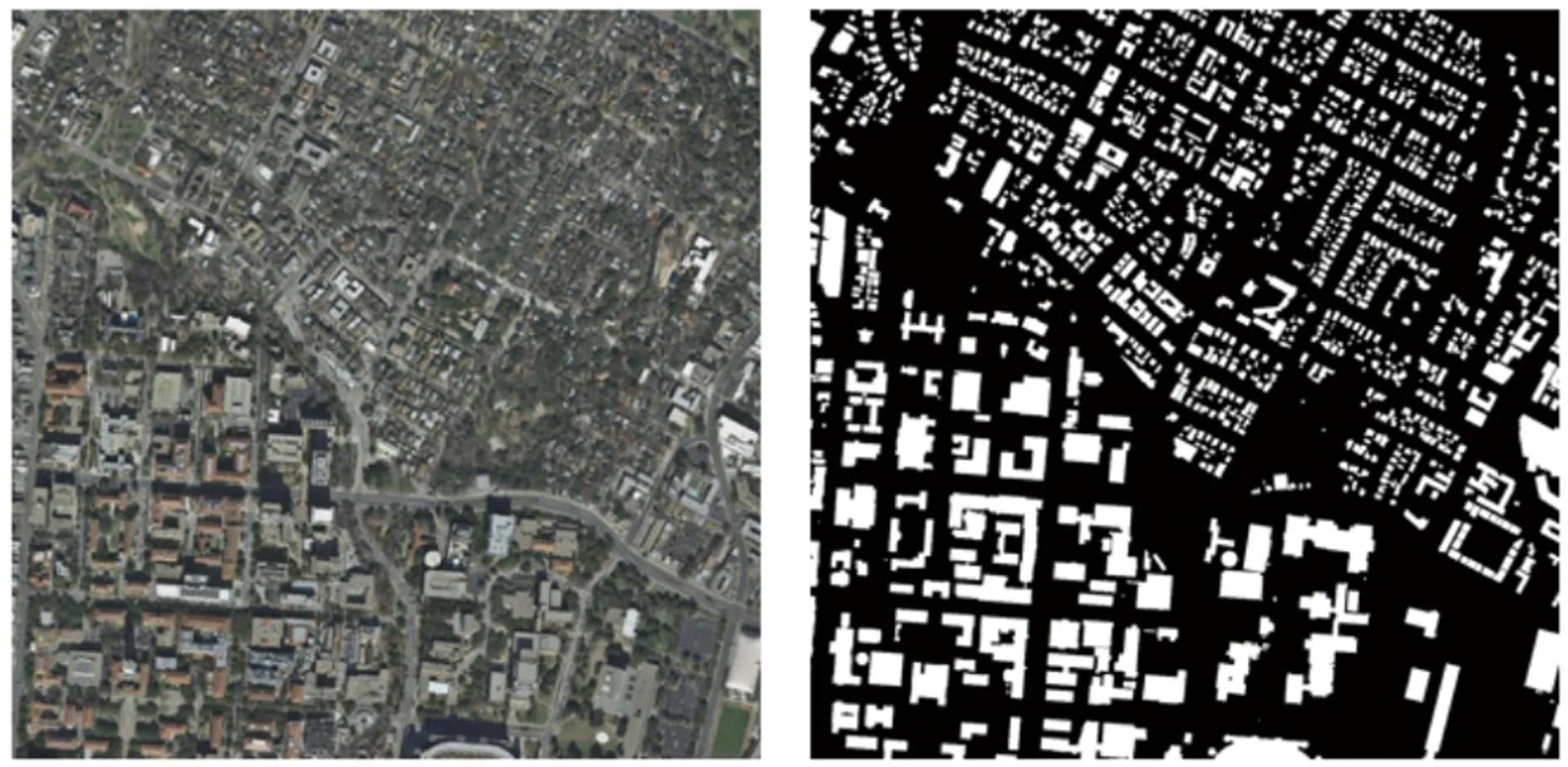
(a)原始圖像

(b)切塊圖像圖4 原始數據和切塊圖像Fig. 4 Raw data and patch images
2.2 損失函數
采用了Dice_loss和交叉熵損失相結合的綜合損失函數對PGT-Unet模型進行訓練學習,Dice_loss為一種集合相似度的度量函數,代表預測的分割結果與標注的建筑物的偏差,公式如下:
(3)
式中,TP表示神經網絡模型的建筑物分割結果與手動標注結果的重疊區域;FP表示與手動標注結果相比神經網絡模型的建筑物分割的錯誤區域;FN表示與手動標注結果相比神經網絡模型未能自動分割出的建筑物區域。因此,Dice_loss的值越小,說明神經網絡模型分割結果越準確。
交叉熵損失可以評估神經網絡模型建筑物分割結果和手動標注結果2個分布之間的距離,使用交叉熵來評估當前訓練得到的建筑物分割概率分布與真實手動標注結果分布的差異情況,公式如下:
(1-qi)×lg(1-pi),
(4)
式中,q為真值概率;p為預測概率。
2.3 試驗結果分析
在1個NVIDIA TESLA V100 GPU上進行模型的訓練和測試,分辨率為(512 pixel×512 pixel)的去霧增強遙感圖像作為模型的輸入,輸出為建筑物分割結果圖像,batch size為12,訓練的epoch為500。通過對比模型自動分割結果和建筑物標注圖像,采用平均交并比(Intersection over Union, IoU)進行分割準確性評價,遙感圖像建筑物分割的IoU為0.775。對比Inria Aerial Image Labeling數據集目前分割性能較好的模型,同樣使用IoU作為評價指標,結果如表1所示。對比實驗結果可以看出,本文提出的方法IoU值是最優的,表明此模型對不同大小目標、有遮擋目標的分割效果具有優勢。
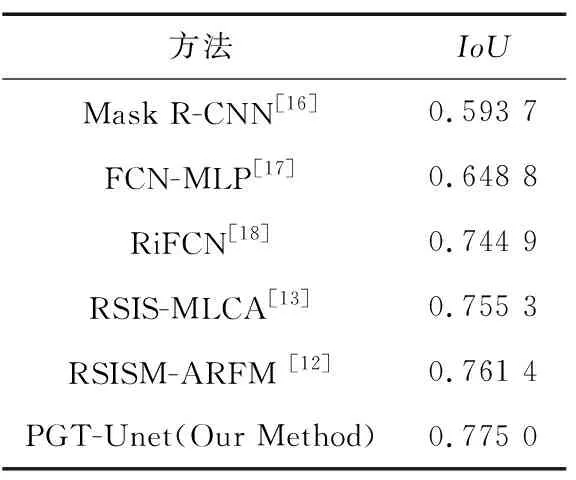
表1 現有方法在Inria Aerial Image Labeling數據集的建筑物分割結果對比Tab.1 Comparison of building segmentation results of existing methods in Inria Aerial Image Labeling dataset
2.4 消融實驗
為了驗證該模型的優越性,對提出的模型進行消融實驗,所有模型采用相同的數據集和服務器環境,消融實驗結果如表2所示。在Unet結構基礎上增加Transformer模塊的分割結果為0.760,在Unet結構基礎上增加漸進生長機制的分割結果為0.754,同時引入漸進生長機制和Transformer的PGT-Unet分割結果為0.775。

表2 消融實驗結果對比Tab.2 Comparison of ablation experimental results
消融實驗的部分測試結果如圖5和圖6所示。圖5和圖6中,(a)為裁剪的分辨率為512 pixel×512 pixel的遙感圖像,(b)為對應遙感圖像手動標注結果,(c)為集成Unet和Transformer Block模型的建筑物分割結果,(d)為集成漸進生長機制的Unet模型建筑物分割結果,(e)為集成漸進生長機制和Transformer Block模塊的PGT-Unet模型建筑物分割結果。

圖5 PGT-Unet模型在樹木遮擋樣本的分割消融實驗結果Fig.5 Segmentation and ablation experimental results of the PGT-Unet model in tree shelter samples

圖6 PGT-Unet模型在不同大小目標樣本的分割消融實驗結果Fig.6 Segmentation and ablation experimental results of the PGT-Unet model in different size of object samples
由圖5可以看出,第1行和第3行遙感圖像主要為被樹木遮擋的建筑物目標,第2行和第4行分別為上一行遮擋目標的局部放大,遮擋目標的分割是比較困難的,本文方法可以較好地學習遮擋目標的上下文特征信息,對樹木遮擋的建筑物分割效果明顯。
由圖6可以看出,第1行和第2行遙感圖像主要為成塊建筑物,這樣不規則的成塊建筑物邊緣輪廓較難分割,本文方法對不規則成塊目標的分割效果更有優勢。第3行和第4行遙感圖像為小目標建筑物,小目標建筑物很容易被忽視,且目標邊界很難準確分割,本文方法可以學習到小目標建筑物的細節特征。通過消融實驗可以驗證提出的基于PGT-Unet的卷積神經網絡模型方法能提取到豐富的目標上下文特征,對有部分遮擋目標和不同大小目標建筑物的分割效果有很大提升。
3 結束語
本文提出了一種基于漸進生長機制的Transformer Unet卷積神經網絡的遙感圖像建筑物分割方法,在編碼階段和解碼階段之間引入Transformer Block模塊進行多尺度特征提取和融合,獲得更多目標互補特征信息,使網絡能夠更好地區分特征之間的重要程度,從而聚焦有用特征。通過漸進式生長機制漸進式地增大輸入圖像的分辨率和模型的深度,并不斷遷移每個階段的模型參數,使模型在訓練初期先學習大尺度粗結構的特征信息,在后面的訓練階段逐漸學習越來越精細的細節結構信息,逐漸改善建筑物邊緣分割效果,可以增強不同大小目標建筑物和遮擋目標建筑物邊緣分割的完整性,對Inria Aerial Image Labeling數據集的建筑物分割具有很好的泛化能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
