面向入侵檢測的Taylor神經網絡構建與分析
2023-03-10 00:11:22王振東張林楊書新王俊嶺李大海
計算機與生活 2023年3期
關鍵詞:檢測
王振東,張林,楊書新,王俊嶺,李大海
江西理工大學 信息工程學院,江西 贛州341000
互聯網和計算機系統已經成為現代社會生活中的重要組成部分,隨之帶來的安全問題[1]成為影響社會穩定的關鍵因素。入侵檢測技術作為一種能夠檢測和抵御惡意軟件侵害的新型安全機制,逐漸發展成為保護網絡安全的關鍵技術。
國內外相關研究者對入侵檢測技術進行了深入研究,主流方法包括基于機器學習、數據挖掘和深度學習[2-4]等多種入侵檢測算法。文獻[5]提出一種加權樸素貝葉斯入侵檢測模型,結合粗糙集理論和改進粒子群算法來提升檢測能力,但機器學習算法模型訓練時間過長,計算成本偏高。文獻[6]采用了基于支持向量機的數據挖掘方法,使用粗糙集理論進行特征選擇,減少了手動分析任務的需要,但數據挖掘算法對大數據中的噪聲較為敏感,易出現過擬合現象。文獻[7]提出了一種結合信息增益和主成分分析的混合降維技術,并基于支持向量機、實例的學習算法和多層感知機的集成分類器來構建無監督學習的入侵檢測模型,但無監督學習方法對于噪聲和異常值敏感。文獻[8]使用強化學習方法將入侵檢測問題轉換為預測馬爾可夫獎勵過程的價值函數,使用線性基函數的時間差異算法來進行值預測,但是強化學習技術難以檢測較新和較復雜的分布式攻擊行為,導致模型檢測性能不佳。文獻[9]提出了一種基于四角星的可視化特征生成方法,用于評估五分類問題中樣本之間的距離,但入侵檢測可視化系統通常是在有限的區域內進行圖像展示,其擴展性差。而神經網絡通過模擬生物大腦的思維方式處理信息,具有自組織、自學習和自適應的特點,可以在保證性能的同時,控制算法中的參數量,降低計算成本[10]。
目前,研究者使用神經網絡如BP(back propagation)[11]、循環神經網絡(recurrent neural network,RNN)[12]、卷積神經網絡(convolutional neural networks,CNN)[13]、深度置信網絡(deep belief networks,DBN)[14]等設計了一系列入侵檢測算法。BP 神經網絡具有強大的自學習能力、泛化能力和非線性映射能力,文獻[11]將BP 神經網絡應用于入侵檢測,得到了較高的檢測率和較低的誤報率,但BP 算法權值閾值初始化隨機性較大,易陷入局部極值,導致訓練時間過長。RNN 神經網絡能夠挖掘出數據中的時序信息和語義信息,被廣泛用于序列相關的入侵檢測。文獻[12]結合RNN 和區域自適應合成過采樣算法來提升低頻攻擊的檢測率,得到了較優結果,但大多數攻擊數據不存在明顯的序列相關性,難以適用于入侵檢測系統。CNN 是一個典型的基于最小化預處理數據要求而產生的區分性深度結構,通常處理高度非線性抽象分類問題,文獻[13]將其與權值下降相結合應用于入侵檢測,保留數據間長期依賴關系,丟棄重復特征,有效避免了過擬合現象,然而CNN 計算過程復雜,導致運算時間及成本偏高;DBN 神經網絡可以有效解決高維數據的檢測問題。文獻[14]提出一種改進遺傳算法與DBN 的入侵檢測技術,通過遺傳算法自適應地生成最優隱藏層數和神經元數,以適應不同攻擊類型,然而攻擊數據通常是一維,將其用于入侵檢測存在明顯缺陷,并且DBN 的學習過程較慢,參數的選擇不當會導致結果陷入局部最優。
鑒于神經網絡具有較優自學習和自適應能力,本文提出一種基于Taylor 神經網絡的入侵檢測算法。Taylor 公式在逼近多項式函數值等方面具有顯著優勢,本文將網絡入侵數據樣本的特征值視為Taylor 公式的輸入,利用Taylor 公式挖掘出特征值間所隱藏的函數映射關系。為了使Taylor 公式能夠有效運行,本文利用神經網絡逼近Taylor 公式的各個展開項系數,有效提高神經網絡的入侵檢測性能。同時,為了有效選擇Taylor 公式的展開項數目,設計了基于高斯過程的人工蜂群算法。實驗結果表明,基于一元Taylor神經網絡的入侵檢測算法(Simple_TNN)與基于多元Taylor 神經網絡的入侵檢測算法(Multi_TNN)均具有較優性能。
1 Taylor神經網絡基本結構
傳統神經網絡通過為不同特征數據分配不同權值,達到區分樣本的目的,而忽略了樣本特征數據與最終標簽的函數映射關系。為提升神經網絡算法對數據的區分和鑒別能力,在神經網絡運行過程中引入函數映射關系。具體操作如下:利用Taylor 公式作為映射關系的載體,使用神經網絡逼近Taylor 公式的展開項系數,從而挖掘出樣本特征數據與樣本標簽間的函數關系。
Taylor 公式分為帶佩亞諾型余項的泰勒公式以及帶拉格朗日余項的泰勒公式。前者對函數f(x)的展開要求較低,只需在點x0處n階可導即可,而不需要連續可導,更無須在x0的鄰域內存在n+1 階可導,因此本文采用帶佩亞諾型余項泰勒公式。其構建的一元及多元Taylor 神經網絡(Taylor neural network,TNN)結構如圖1、圖2 所示。
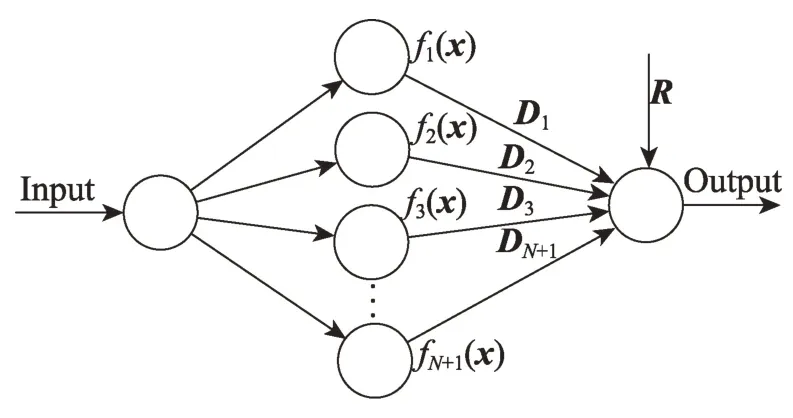
圖1 一元Taylor神經網絡的基本結構Fig.1 Basic structure of univariate Taylor neural network
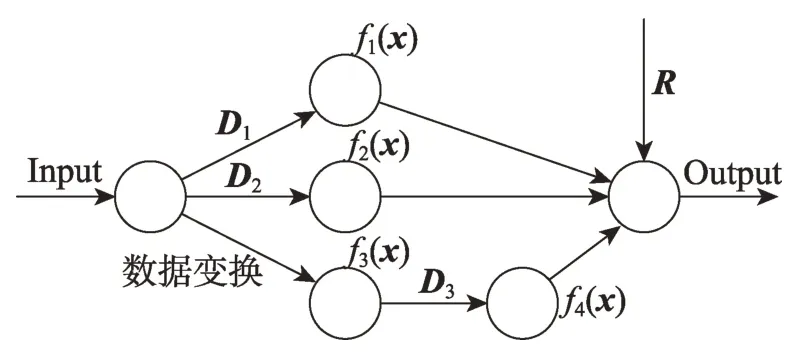
圖2 多元Taylor神經網絡基本結構Fig.2 Basic structure of multivariate Taylor neural network
其中,x為一條樣本的特征數據;N是Taylor 函數的展開項數目;fN+1(x)是對輸入數據x作變換,以適應一元Taylor公式的輸入;微分分量D為Taylor 公式展開項的系數;R為麥克勞林分量;F(x)為一元Taylor展開式。微分分量D和麥克勞林分量R通過神經網絡(全連接神經網絡,其結構見實驗部分)優化所得。
同樣,x為輸入的特征數據,fi(x)是對輸入數據x作變換,使輸入的特征數據能夠更方便完成多元Taylor 展開式的運算,詳見式(9);微分分量D為Taylor 公式展開項的系數;R為麥克勞林分量;式(8)中的F(x1,x2,…,xn) 為多元函數在xk處的泰勒展開式;F(x)為Taylor展開式的矩陣形式。其中D、H(xk)與R都由神經網絡(全連接神經網絡,其結構見實驗部分)優化得到,基于工程簡單且易于實現,取xk為一條零向量,得到式(10)。
2 面向入侵檢測的Taylor神經網絡模型
入侵檢測數據特征間函數映射關系不明顯,因此引入TNN 挖掘出其中隱藏的特征映射關系。TNN以一條數據樣本的某個特征值作為Taylor 公式的展開點,但一條網絡入侵數據樣本中可能存在多個特征值。為適應網絡入侵數據樣本,本文設計了Taylor神經網絡層(Taylor neural layer),使其能夠對一條數據中的各個特征值同時處理。在TNL 中,將網絡入侵數據的各個特征值作為各Taylor 公式的展開點,并利用神經網絡逼近微分分量和麥克勞林分量,從而計算各Taylor 公式的函數值,此時函數值是考慮了樣本特征值函數關系后的更深層次的樣本特征。最后,將函數值輸入到深度神經網絡(deep neural network,DNN,其結構見實驗部分)中實現分類,Taylor 神經網絡模型結構如圖3 所示。
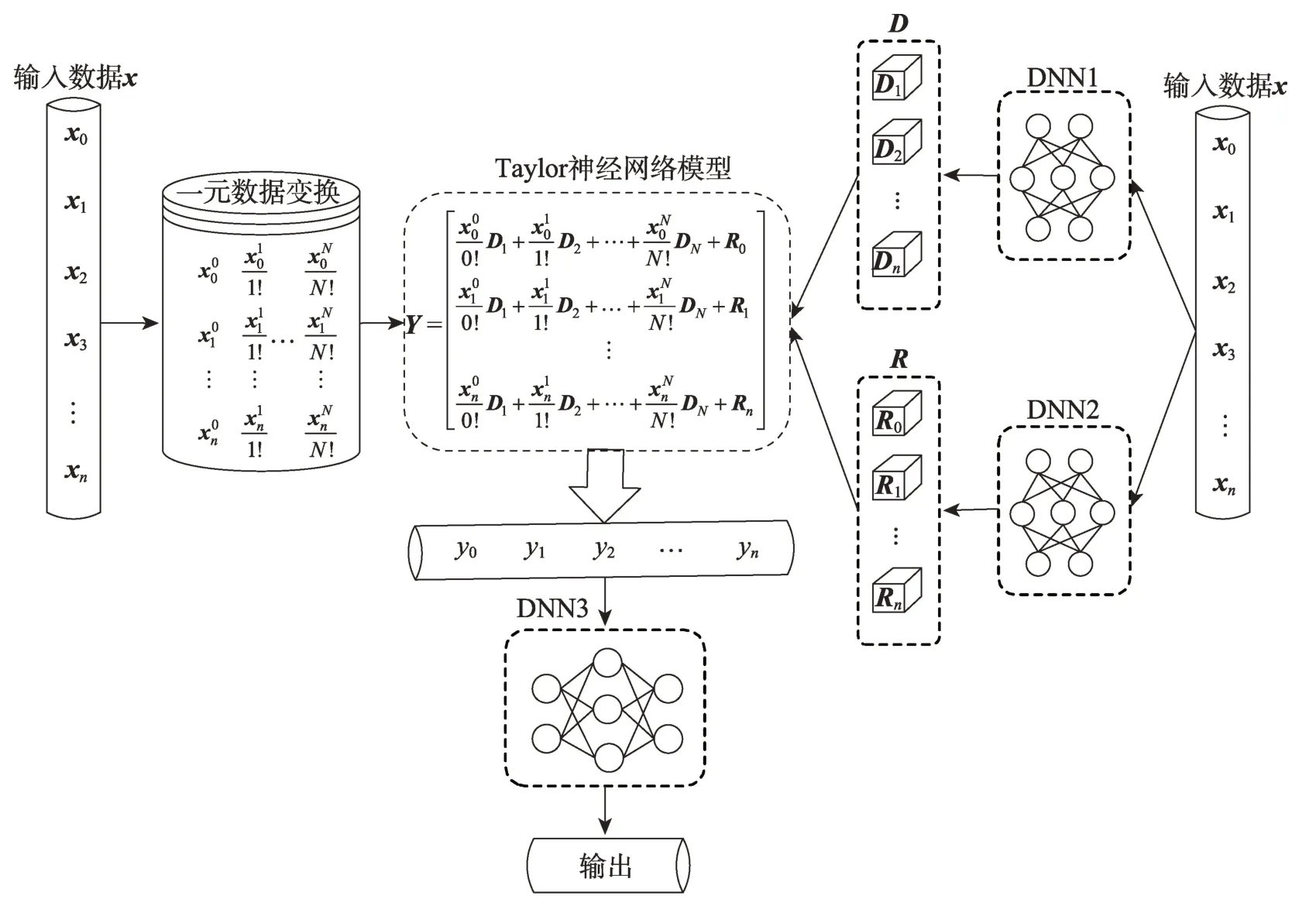
圖3 Taylor神經網絡模型Fig.3 Taylor neural network model
為了獲取微分矩陣D和麥克勞林矩陣R,本文利用兩個DNN對f(0)、f′(0)、f″(0)…f(n)(0)和R0,R1,…,Rn進行逼近,上述兩個DNN 的輸入均為網絡入侵檢測數據樣本x。最終獲得D與R的矩陣形式,詳見式(12)和式(13),其中n為數據的維數,N為Taylor公式展開的項數,為f(x)在第N次求導后x=0時的函數值。
為滿足Taylor 神經元的輸入條件,將入侵檢測數據樣本x做如下變換得到X(n×N)。
將變換后的X與矩陣D的轉置進行點乘:
以上為一元Taylor 神經網絡層運算過程,輸出數據是n×1 維數據。多元Taylor 神經網絡層與一元Taylor 神經網絡層相同,使用神經網絡計算出D、H(xk)和麥克勞林分量R,再代入輸入數據X即可。
再考慮Taylor 網絡層至第一層DNN 中信息的運算:
其中,Y是Taylor 網絡層的輸出;X1為第一層DNN的輸出;W1為第一層DNN 的權重;B1為第一層DNN 的偏置;σ1為第一層DNN 的激活函數。
DNN 中運算過程為:
式中,Xl-1為第l-1 層DNN 的輸出,同時也是第l層DNN 的輸入;Xl為第l層DNN 的輸出;Wl為第l層DNN 的權重;Bl為第l層DNN 的偏置;σl為第l層DNN 的激活函數。
通過上述分析可知,在DNN 前加一個Taylor 網絡層可以有效挖掘入侵數據特征值中所隱藏的函數關系,利用這種關系能夠有效地提升算法的檢測精度。然而,Taylor 展開式持續展開至N項并不現實,不僅會占據大量內存空間且得不到較好結果。因此,本文提出一種基于高斯過程的人工蜂群算法,對展開項數N進行優化。
3 基于高斯過程的人工蜂群算法
人工蜂群算法(artificial bee colony,ABC)[15]由Karaboga 于2005 年提出,該算法用蜜源所在位置表示問題的解,用蜜源產出的花粉數量表示解的適應度值。根據分工的不同,算法將蜜蜂劃分為引領蜂、跟隨蜂以及偵察蜂三種。其中,引領蜂發現食物源并以一定的概率將其分享給跟隨蜂;跟隨蜂根據引領蜂分享的概率選擇蜜源;偵察蜂在蜂巢附近尋找新的蜜源。算法迭代運行,對蜂群和蜜源位置初始化后,對三種蜂的位置迭代更新以尋找問題的最優解。人工蜂群算法魯棒性強,通用性好,但是局部開采能力較差,易陷入“早熟”,因此本文設計了基于高斯過程的人工蜂群算法對Taylor 公式的展開項數進行優化。
3.1 高斯過程
高斯過程(Gaussian processes,GP)[16]是一種常見的非參數模型,其本質是通過一個映射將自變量從低維空間映射到高維空間(類似于支持向量機中的核函數將低維線性不可分映射為高維線性可分)。高斯過程是多元高斯概率分布的一種泛化形式,通過先驗知識確定參數的后驗分布,從而確定一組任意且有限的輸入數據和目標輸出之間的函數關系。如同高斯分布一樣,可以用均值和方差來刻畫,如下:
其中,m(x)為均值函數,通常取m(x)=E[f(x)];k(x,x′)為核函數,通常取k(x,x′)=E[(f(x)-m(x))(f(x′)-m(x′))]。為方便計算,取m(x)=0,0 均值高斯過程直接由其核函數決定。
給定輸入數據X=x1,x2,…,xn。目標輸出通常包含高斯噪聲,且與真實值之間相差ξ,即:
其中,K為協方差矩陣。此時,n個訓練樣本的目標輸出Y和測試數據的預測值f*構成了聯合高斯先驗分布:
其中,K*=[k(x*,x1)k(x*,x2)…]k(x*,xn),K**=k(x*,x*),x*為預測輸入。取f*的邊緣分布,并根據聯合高斯分布的邊緣分布性質可得到如下預測分布:
其中,f*若為標量,那么
3.2 基于高斯過程的人工蜂群算法
由于人工蜂群普遍存在收斂速度慢,局部開采能力差,易陷入“早熟”等缺點,引入高斯過程對其進行優化,過程如下:
初始化蜜源階段:
其中,i=1,2,…,m,m為蜜源個數;j=1,2,…,n,n為問題的維數;η是一個介于(0,1)之間的隨機數;uj和lj分別是xij的最大和最小邊界值。
引領蜂位置更新階段:
其中,j是介于[1,m]之間的隨機整數,i,k∈{1,2,…,m},且k≠i;xkj為隨機選取的蜜源;將?ij改為服從高斯分布的隨機數,相對于均勻分布的隨機數,可以提供相對集中的搜索區域,從而加快收斂速度,擴大搜索范圍,增加種群多樣性。
跟隨蜂階段:
其中,pm為跟隨蜂通過輪盤賭機制選擇某個蜜源而更新位置的概率,如果該值大于隨機產生的一個數,那么跟隨蜂就依附到此蜜源。
偵察蜂階段:當引領蜂和跟隨蜂搜索完整個空間時,一個蜜源的適應度函數值在給定的有限次數內沒有提高,則將該蜜源丟棄,該蜜源相對應的引領蜂從而變成偵察蜂,并使用公式搜索新的可能解。
適應度函數:將神經網絡的損失值作為算法的優化目標。
3.3 基于高斯過程的人工蜂群算法步驟
基于高斯過程的人工蜂群算法(artificial bee colony algorithm based on Gaussian process,GABC)步驟如下:
步驟1初始化種群數、最大迭代次數以及搜索空間,并利用式(27)更新種群位置。
步驟2利用式(33)計算并評估每個初始解的適應度函數值,根據適應度函數值確定極值以及最好最差的位置。
步驟3利用式(33)進行貪婪選擇,如果vi的適應度優于xi,則用vi代替xi,將vi作為當前最好的解,否則保留xi不變。
步驟4設置循環條件開始循環。
步驟5利用高斯過程更新引領蜂位置,詳見式(28)~(31)。
步驟6利用式(32)更新跟隨蜂位置。
步驟7若一個食物源經過數次迭代后仍未被更新,那么就將其放棄,則此引領蜂轉成一個偵察蜂,由式(27)產生一個新的食物源。
步驟8記錄目前為止的最優解。
步驟9判斷是否滿足循環終止條件,若滿足,循環結束,輸出最優解,否則返回步驟4 繼續搜索。
4 基于人工蜂群的Taylor 神經網絡入侵檢測算法
眾所周知,泰勒公式逼近某一函數數據的精度,很大程度上取決于泰勒公式展開項的多少。一般而言,展開項越多,泰勒公式逼近函數數據的精度越高。但實際上,利用數據集中的樣本訓練神經網絡去擬合泰勒公式中展開項的系數,數據集中總會存在一些噪聲信息。此時,如果盲目地增加泰勒公式展開項的數目,追求泰勒公式逼近數據的精度,極有可能造成過擬合現象;而泰勒公式展開項數目不足也將導致欠擬合現象。手動合理地選擇泰勒公式展開項的數目需要大量的經驗支撐,為了避免手動選擇展開項數的局限性,有效提高入侵檢測模型的性能,采用人工蜂群算法對泰勒公式展開項數目進行尋優,但傳統人工蜂群算法存在的局部開采能力較差,易陷入“早熟”等問題,因此引入基于高斯過程的人工蜂群算法,有效避免了傳統人工蜂群中存在的問題,其模型描述如下:
使用基于高斯過程的人工蜂群算法優化TNN 的基本思路是,首先求出適應度函數最好的一組蜂群位置,迭代結束后,將該位置作為TNN 的最優展開項數建立入侵檢測模型,模型訓練過程及結構如圖4所示。
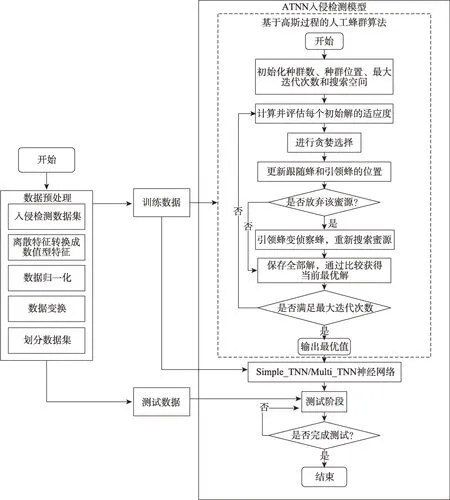
圖4 基于GABC 的TNN 入侵檢測算法框架Fig.4 TNN intrusion detection algorithm framework based on GABC
步驟1初始化人工蜂群算法的種群數目、蜜源位置、最大迭代次數和搜索空間。
步驟2對原始數據x進行預處理:
(1)將數據集中的離散特征轉換為數值型特征;
(2)將數值型特征進行歸一化處理,使其都是分布在[0,1]之間的實數。
步驟3將歸一化后的數據特征進行變換,使其滿足Taylor神經網絡層的輸入條件。
步驟4將變換后的數據劃分為訓練集x_train、測試集x_test。
步驟5將訓練數據x_train 輸入至TNN 中,并對其進行訓練。
步驟6計算并返回訓練數據的損失值,并將其作為GABC 的優化目標,更新相關參數。
步驟7反復執行步驟5 至步驟6,直至觸發GABC 的迭代終止條件,獲得TNN 的最優展開項數。
步驟8傳遞參數至TNN 并對其進行訓練,訓練完成后在測試集上進行測試。
5 實驗設計與分析
為驗證Simple_TNN 和Multi_TNN 入侵檢測算法的性能,采用NSL-KDD[17]和UNSW-NB15[18]數據集對其進行驗證,其中NSL-KDD 包含41 個特征屬性和1 個類別標簽,如表1 所示。較NSL-KDD 而言,UNSW-NB15 數據分布更平衡,不包含冗余數據;NSL-KDD 將攻擊類型分為Dos、Probe、R2L、U2R 共4大類攻擊。UNSW-NB15包含49 個特征屬性,更能真實地反映現代網絡數據;UNSW-NB15 將攻擊分為Fuzzers、Analysis、Backdoors、DoS、Exploits、Generic、Reconnaissance、Shellcode、Worms 共9 大類攻擊。本文所使用的數據分布如表1 所示。
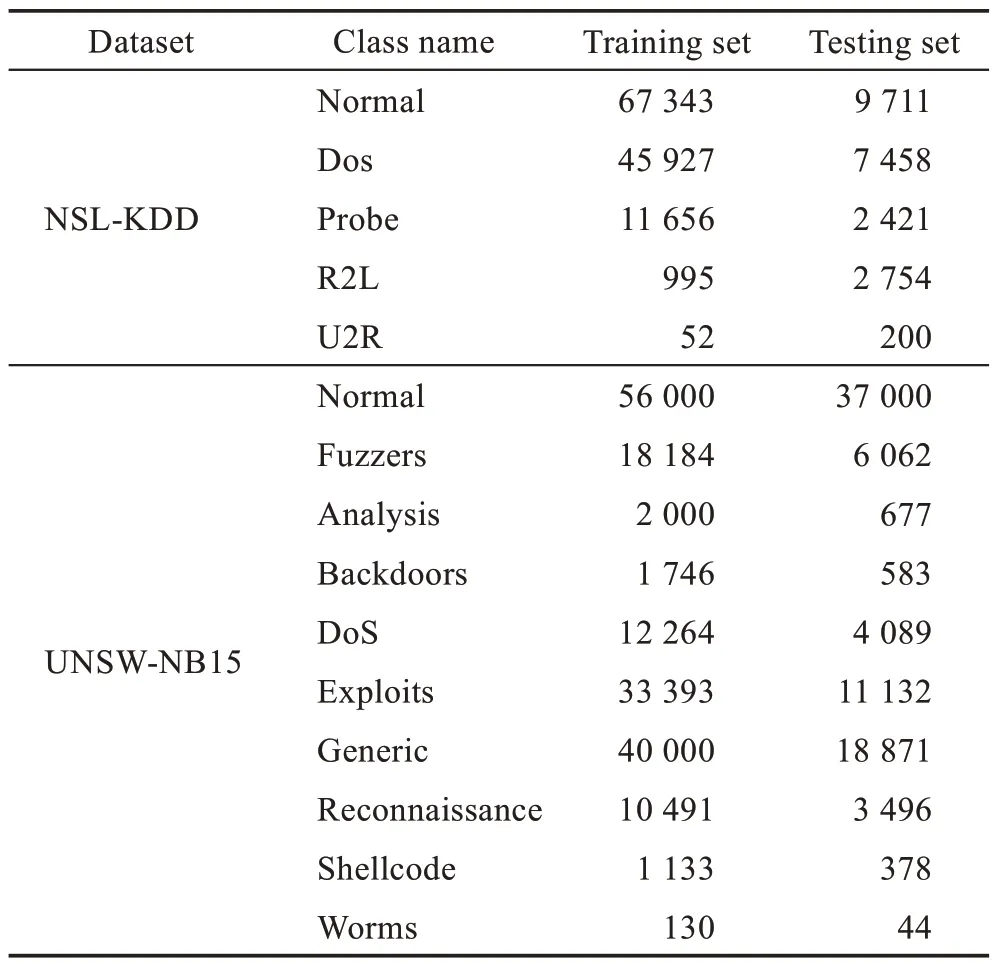
表1 數據分布Table 1 Data distribution
5.1 性能指標
兩種數據集無論是正常行為和攻擊行為之間,或是各類攻擊行為之間都存在數據不平衡等問題,因此除準確率外,還需要引入精確率、召回率和F1 值對算法進行評價,參數定義如表2 所示。

表2 參數定義Table 2 Parameter definition
準確率(Accuracy),預測對的樣本數占樣本總數的比例,其數學表達式如下:
精確率(Precision),預測為正的樣本中有多少是真正的正樣本,其數學表達式如下:
召回率(Recall),樣本中的正例有多少被預測正確,其數學表達式如下:
F1-score 是基于召回率和精確率計算的,其數學表達式如下:
5.2 與經典機器學習算法的比較
本文所使用的Taylor 神經網絡模型結構如表3所示。其中DNN1 用來優化麥克勞林分量R,DNN2用來優化微分分量D,DNN3 用來對TNL 的輸出進行更深層次的分析處理并完成分類,參數設置如表3所示。
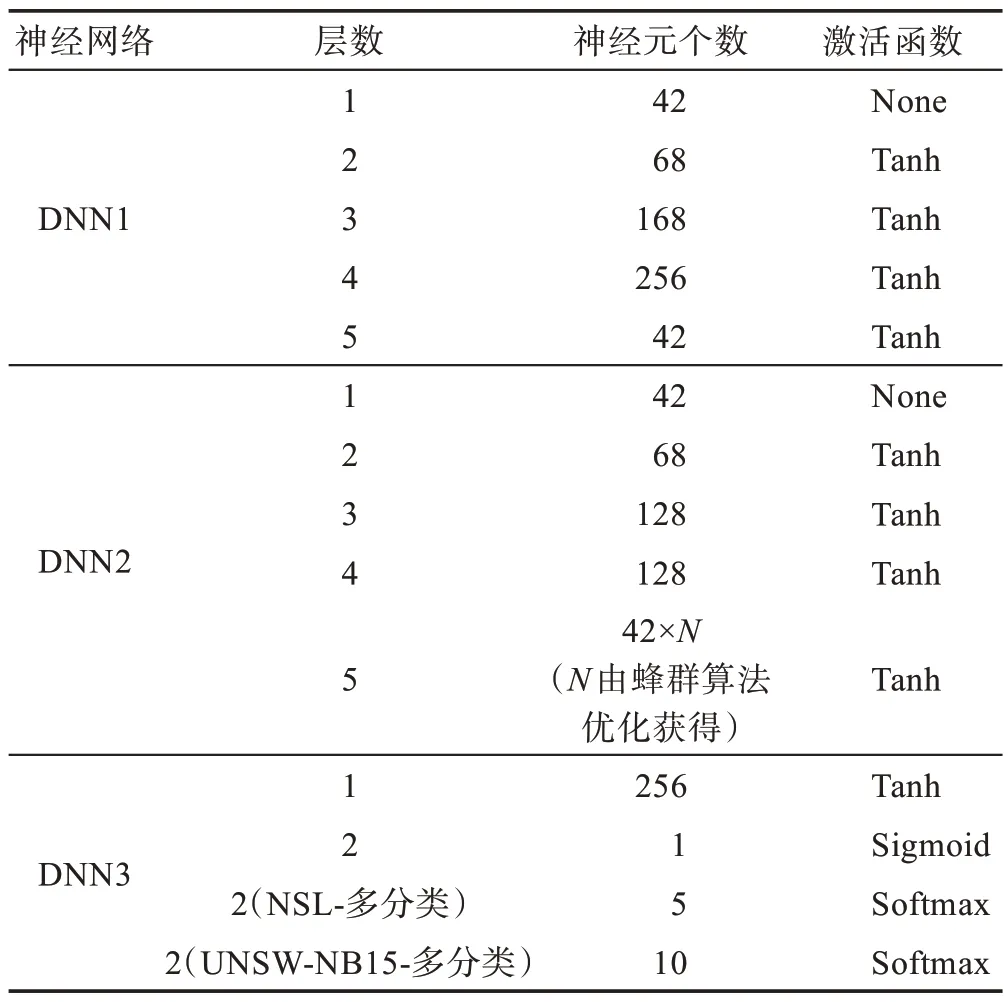
表3 Taylor神經網絡模型結構Table 3 Taylor neural network model structure
5.2.1 二分類實驗結果
二分類實驗結果如表4 所示,將其與經典的機器學習算法和神經網絡進行對比。顯然,在幾種算法中,不論是NSL-KDD 數據集還是UNSW-NB15 數據集,所提出的Simple_TNN 和Multi_TNN 效果總是最優的,分別是97.6%、99.6%和96.8%、97.3%。在NSLKDD 數據集上,SVM 的Accuracy 為53.4%,Recall和F1-score 僅僅只有0.1%,說明SVM 在此數據集上完全失效;相較于機器學習算法,神經網絡算法在此數據集上表現更好,CNN的Precision甚至達到了98.8%,僅僅與Simple_TNN 差了0.1 個百分點;而Simple_TNN 的Recall卻比CNN低了4.3個百分點,說明Simple_TNN 在分類正樣本時的性能較CNN 差,總是將一部分正樣本錯誤地預測為負樣本;Multi_TNN的四種性能指標分別達到了99.6%、99.7%、99.4%和99.5%,是幾種算法中性能最佳的。在UNSW-NB15數據集上,CART 的Precision 最差,僅僅只有70.4%,但Recall 卻是最高,達到了99.8%,說明CART 在分類正樣本時,性能較優;相較于神經網絡算法,機器學習算法反而在此數據集上表現更好,KNN 是幾種經典算法中性能最優的,但是較Simple_TNN 和Multi_TNN 的Precision 而言,還是低了3.2 個百分點和2.0個百分點;再觀察Simple_TNN 和Multi_TNN 可看出,雖然Multi_TNN 的Accuracy 比Simple_TNN 高了0.5 個百分點,但是Precision 卻低了1.2 個百分點,說明Multi_TNN 將部分負樣本預測為了正樣本,這樣會給網絡安全帶來更大的威脅。ROC 曲線圖反映真正率和假正率之間的關系,曲線將整個區域劃分成兩部分,曲線下部分的面積被稱為AUC,用來表示預測準確性。從圖5 可以看出,在各算法中,無論是正常數據還是攻擊數據,所提Simple_TNN 和Multi_TNN 算法的AUC 均較優,充分說明引入Taylor 的必要性。
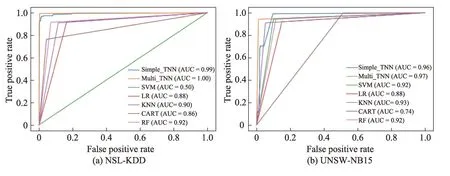
圖5 二分類ROC 曲線Fig.5 Two-classification ROC curve
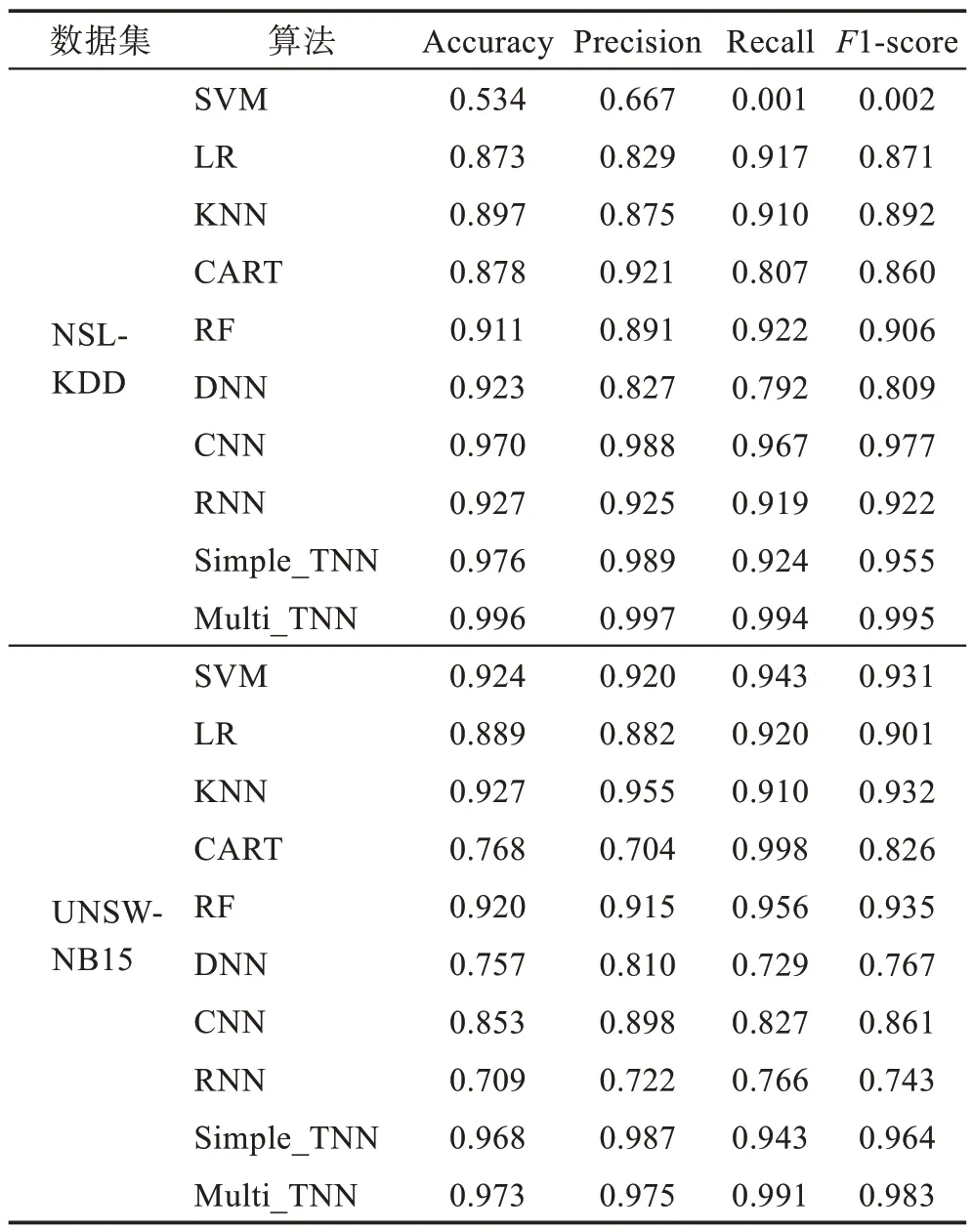
表4 二分類實驗結果Table 4 Two-classification experiment results
5.2.2 多分類實驗結果
多分類實驗結果如表5 所示,將其與經典的機器學習算法和神經網絡進行對比,可看出不論是NSLKDD 數據集還是UNSW-NB15 數據集,Multi_TNN性能總是最佳的。在NSL-KDD 數據集上,與機器學習算法相比,神經網絡算法較優;SVM 如二分類一樣,效果極差,Accuracy 只有53.5%,Precision 也只有37.6%,相當于把大部分正樣本預測為負樣本,大部分負樣本預測為正樣本;其他幾種經典算法幾乎都達到了80%以上,性能較優;然而Simple_TNN 算法性能下降,Accuracy 低于CNN 算法3.9 個百分點,說明Simple Taylor 在處理NSL-KDD 數據時,不如CNN效果好;但是Multi_TNN 卻比CNN 的Precision 高2.7個百分點,說明Multi Taylor 在該數據集上更具有優勢。在UMSW-NB15 數據集上,較機器學習而言,神經網絡算法的多分類性能明顯下降;SVM 在幾種算法中位居首位,Accuracy 達到了80.5%,僅僅比最好的Multi_TNN 差了3.8 個百分點;SVM 與其他幾種機器學習算法的Precision 相差不大,但是Recall 卻高約5 個百分點,說明SVM 在預測正樣本時比其他幾種經典算法更具有優勢;CNN 卻是性能最差的,Precision 只有53%,相當于接近一半的負樣本預測為正樣本,這將給網絡安全帶來更嚴重的危害;其他幾種經典算法幾乎都達到了70%以上,相對較優,但與Multi_TNN 還是差了10 個百分點左右。微平均ROC和宏平均ROC 曲線圖直觀地反映算法在大量數據和少量數據中的檢測性能,如圖6 所示,不論是NSLKDD 數據集,還是UNSW-NB15 數據集,也無論是大量數據還是少量數據,所提出的Simple_TNN 和Multi_TNN 的AUC 總是最優的。
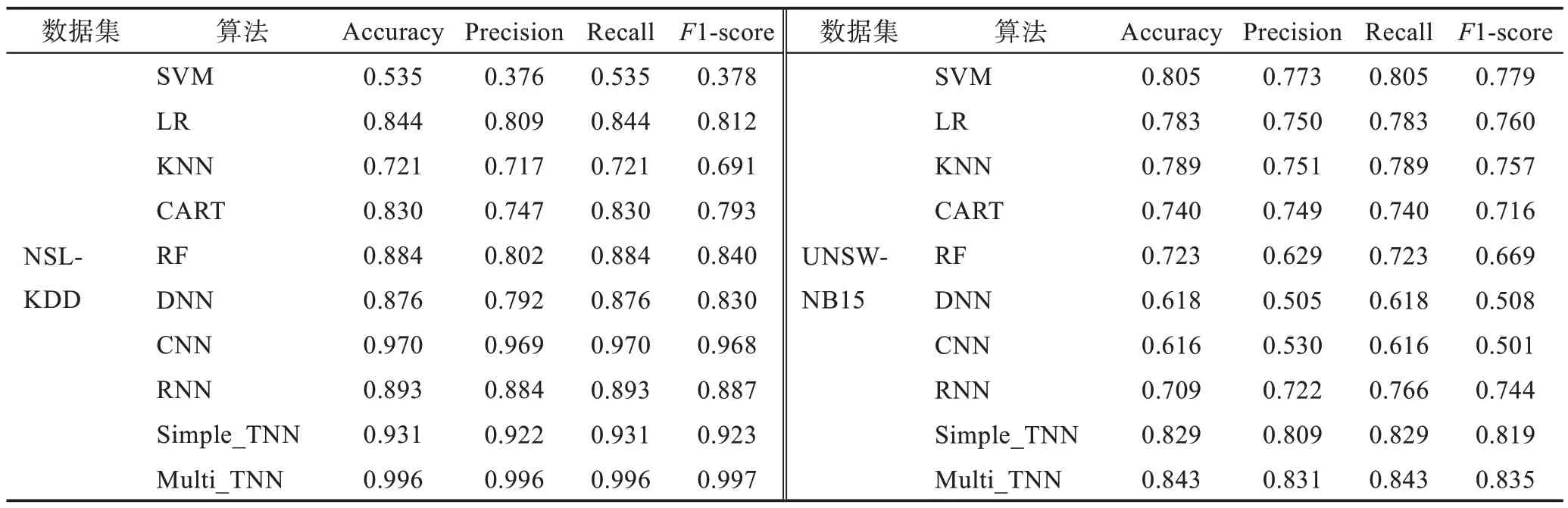
表5 多分類實驗結果Table 5 Multi-classification experiment results
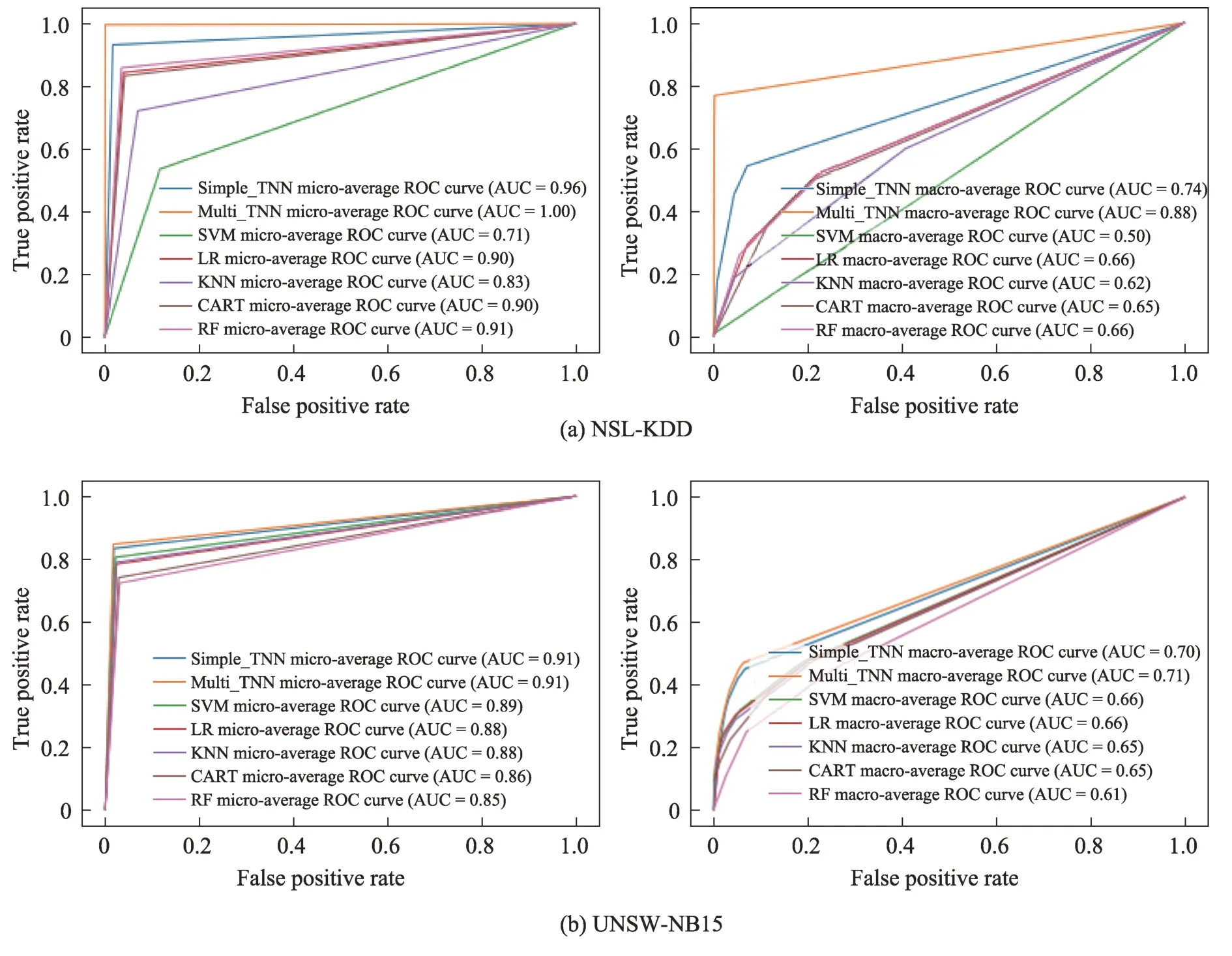
圖6 多分類微平均和宏平均ROC 曲線Fig.6 Multi-class micro-average and macro-average ROC curves
5.3 時間性能分析
由上節分析可知,Simple_TNN 與Multi_TNN 算法均具有良好的檢測性能。為檢驗其運行速度,繼續在UNSW-NB15 數據集上與各入侵檢測算法進行對比,結果如表6 所示。可以看出,在相同迭代次數下(50 次),無論二分類還是多分類,Simple_TNN 與Multi_TNN 所用時間均非最少,主要是因為模型使用了3 個DNN(如表3 所示)輸出所需的Taylor 系數。而本文采用了3 個DNN 串行的方式并使用梯度下降法分別訓練DNN,導致Simple_TNN、Multi_TNN 消耗時間較長。對比算法中,決策樹算法用時最短,是因為決策樹算法通過計算信息熵來衡量各次劃分樣本的信息增益,再利用信息增益的最大化實現對決策樹的訓練,參數相對于其他算法較少,且信息熵、信息增益的計算量也較低,但決策樹算法準確率卻較低。RNN 響應時間雖較短,但準確率相比Simple_TNN、Multi_TNN 差距較大,是因為RNN 易出現梯度消失等問題。CNN 的時間性能與Multi_TNN 相差不大,但準確率遠低于Multi_TNN。事實上,Simple_TNN 與Multi_TNN 作為一種新型神經網絡架構,其結構還存在較大的優化空間。后續考慮設計Simple_TNN 與Multi_TNN 中DNN 的并行訓練方法,并開發輕量級的Simple_TNN 與Multi_TNN 以進一步降低運行速度。
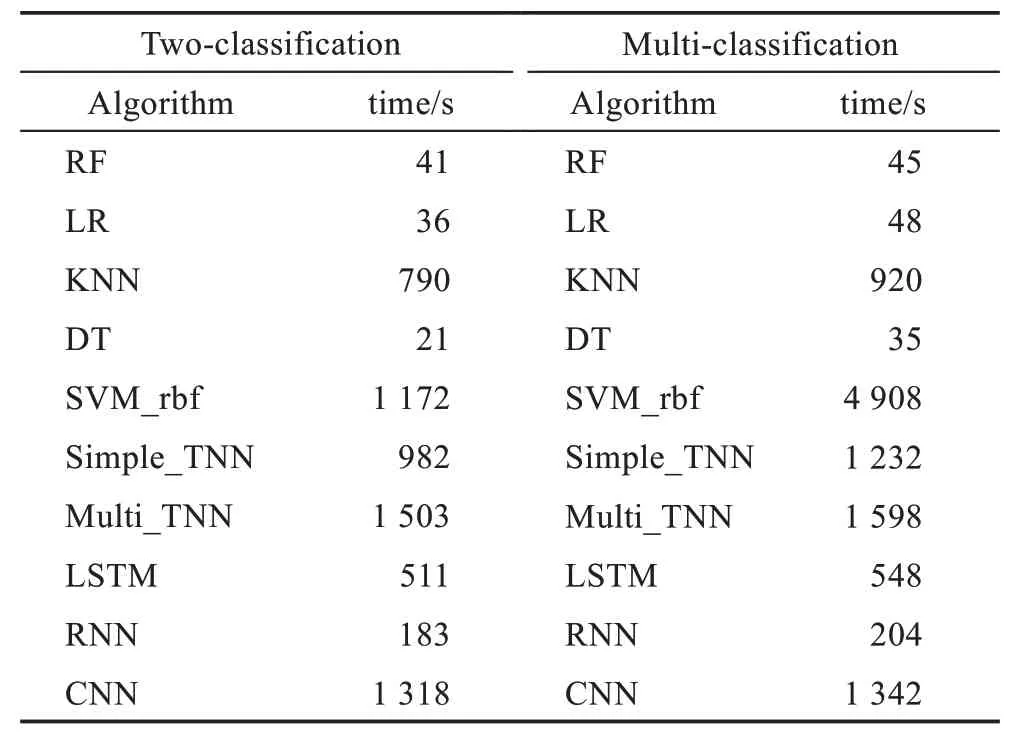
表6 時間性能Table 6 Time performance
5.4 與現階段最新入侵檢測算法的比較
Simple_TNN 和Multi_TNN 與現階段最新的入侵檢測算法進行實驗對比,如圖7 所示(由于每篇論文給出的性能指標都不相同,只對Accuracy 進行比較)。文獻[19-22]對數據特征進行選擇后再分類;文獻[23-24]基于規則檢測;文獻[25-28]為多步驟分類;文獻[29-30]對現有入侵算法進行了改進;文獻[31-33]對神經網絡結構優化后再分類。上述所得到實驗結果較優,但并沒有一種算法是針對攻擊數據而專門提出的入侵檢測算法。因此,本文提出基于Taylor 公式的神經網絡,較其他算法而言性能總為最優,充分說明了Simple_TNN 和Multi_TNN 入侵檢測算法的有效性。
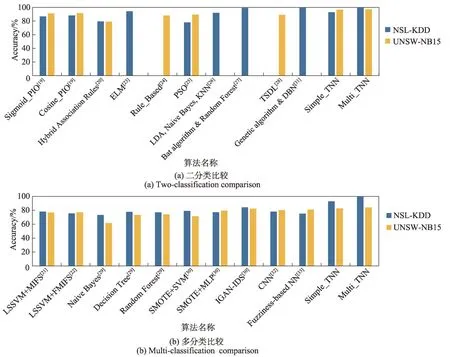
圖7 算法比較Fig.7 Comparison of algorithms
6 結束語
本文提出了一種基于Taylor 神經網絡的入侵檢測算法。利用Taylor 神經網絡結構挖掘網絡入侵檢測數據特征背后所隱藏的函數映射關系,并利用這種映射關系對網絡入侵行為進行有效的檢測。為了將Taylor 神經網絡應用到入侵檢測領域,設計了Taylor 神經網絡層(TNL),并針對Taylor 公式展開項難以通過經驗確定的難題,設計了一種基于高斯過程優化的人工蜂群算法(GABC)。使用GABC 有效選擇TNL 中Taylor 公式的展開項數目。實驗結果表明,Taylor 神經網絡模型在入侵檢測領域具有良好的性能,后期將對Taylor 神經網絡模型進行更深入的研究,實現其對于惡意代碼、病毒等相關安全威脅的高效檢測。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
